GAN�����о�֮ע����������
����Ŀ¼
ǰ��
����NICE-GANģ�����õ������,����ֻ�ǽ���ԭ���ϵļ���,����Ϊʲôʹ����Щ���,������ô�����õ�,����Ҫ��Դ˷,����SN-GAN���״����spectral normalization�����µ�Ȩ�ع�һ���������ȶ��б�����ѵ��,����U-GAT-ITģ�������ͨ��CAM(Class Activation Map)ʵ��ע��������,(GAP �� \rightarrow �� CAM �� \rightarrow �� Attentional Net)
һ��Class Activation Mapping
�״����CAM(Class Activation Mapping)��������������ġ�Learning Deep Features for Discriminative Localization ��(2016CVPR)�С�
����˵,��ƪ������Ҫ�������������ļ���:
GAP(Global Average Pooling Layer) �� CAM(Class Activation Mapping)
1. GAP
�ػ���ı�����һ���²���,��Ϊ���ݾ�������֮��ά��Խ��Խ��,��������ͼû�ж��ı�,�������������֮��,�����һ���ܴ�IJ�����,�����������������ѵ�����Ѷ�,��������ɹ���ϵ�����,����ͨ�����ھ�����֮���һ���ػ�������ݽ���ѹ��,����ά��,���ٲ��������ػ������ܹ�����һ�������ͼ�����ں�,��Ϊ��������IJ������н�ǿ�Ĺ�����,���ܹ���ֹ�������������
pooling�Ľ����ʹ����������,��������,��pooling��Ŀ�IJ��������ڴˡ�
poolingĿ����Ϊ������ij�ֲ�����(��ת��ƽ�ơ�������)
�����������,������ȡ�������Ҫ������������:
(1)�����С������ɵĹ���ֵ��������;
(2)��������������ɹ�����ֵ��ƫ����
һ����˵
average-pooling�ܼ�С��һ�����(�����С������ɵĹ���ֵ��������),���������ͼ��ı�����Ϣ��
max-pooling�ܼ�С�ڶ������(��������������ɹ��ƾ�ֵ��ƫ��),���������������Ϣ��
��һ�����GAP����뷨��,��һƪ������Network in Network�������ġ���ƪ���ķ�����GAP����ȫ���Ӳ�,�������Խ���ά��,��ֹ�����,���ٴ�������,���������Ҳ�ܲ�����
�����ھ������ʹ��GAPģ��:
we directly output the spatial average of the feature maps from the last mlpconv layer as the confidence of categories via a global average pooling layer
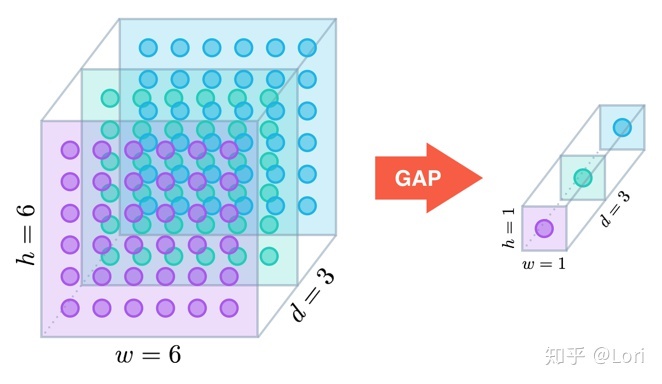
���������ġ�Learning Deep Features for Discriminative Localization ����,���Ƿ�����GAP��һ������,�������ռ���Ϣ���Ҷ�λ(localization)
2. CAM
ʹ��ȫ�־�ֵ�ػ�����CAM�IJ���:������Ҫ�ɾ��������,���������������֮ǰ, �ھ�������ͼ�Ͻ���ȫ��ƽ���ػ�,����ȫ���Ӳ㡣����ͨ����������Ȩ��ͶӰ����������ͼ����ʶ��ͼ���������Ҫ��,�ü�����Ϊ�༤��ӳ��(class, activation mapping)��

W
1
W_{1}
W1? ��
W
n
W_{n}
Wn? ΪGAP�������ȫ���ӵ�Ŀ�����(��ͼĿ�����Ϊ��)��Ȩ��,����GAP����������ֱ������������ͼ(���Թ�ϵ),��˸�Ȩ�ؿ���Ϊ����ͼ��Ŀ�����score�Ĺ��׳̶�,���м�Ȩ��ͼȿ��Ի�ȡCAM��
M c ( x , y ) = �� k w k c f k ( x , y ) M_{c}(x,y) = \sum_{k}w_{k}^{c}f_{k}(x,y) Mc?(x,y)=k��?wkc?fk?(x,y)
���� f k ( x , y ) f_{k}(x,y) fk?(x,y) Ϊ���һ������ͼλ�� ( x , y ) (x,y) (x,y) ��ֵ, w k c w_{k}^{c} wkc? Ϊ���c��ȫ����Ȩ��
- ���Ĵ���
����ʵ�ֲ�������, ��ȡ������ͼ��Ŀ�����ȫ���ӵ�Ȩ��,ֱ�Ӽ�Ȩ���,�پ���relu����ȥ����ֵ,����һ����ȡCAM# ��ȡȫ���Ӳ��Ȩ�� self._fc_weights = self.model._modules.get(fc_layer).weight.data # ��ȡĿ������Ȩ����Ϊ����Ȩ�� weights=self._fc_weights[class_idx, :] # ����self.hook_aΪ���һ������ͼ����� batch_cams = (weights.unsqueeze(-1).unsqueeze(-1) * self.hook_a.squeeze(0)).sum(dim=0) # relu����,ȥ����ֵ batch_cams = F.relu(batch_cams, inplace=True) # ��һ������ batch_cams = self._normalize(batch_cams)
3. Attentional network
U-GAT-IT�е�ע��������ֻ�Ƕ�CAM������һ��С�Ľ�,���GAP,GMPѵ��ѧϰԴ�������Ȩ��
w
k
w_{k}
wk?,�õ�ע��������
��
\omega
����


- ��ӦԴ���е���������������
def forward(self, input):
x = self.DownBlock(input) #�õ������������,��Ӧ;��encoder feature map
gap = torch.nn.functional.adaptive_avg_pool2d(x, 1) #ȫ��ƽ���ػ�
gap_logit = self.gap_fc(gap.view(x.shape[0], -1)) #gap��Ԥ��
gap_weight = list(self.gap_fc.parameters())[0] #self.gap_fc��Ȩ�ز���
gap = x * gap_weight.unsqueeze(2).unsqueeze(3) #�õ�ȫ��ƽ���ػ��ӳ�Ȩ�ص�����ͼ
gmp = torch.nn.functional.adaptive_max_pool2d(x, 1) #ȫ�����ػ�
gmp_logit = self.gmp_fc(gmp.view(x.shape[0], -1)) #gmp��Ԥ��
gmp_weight = list(self.gmp_fc.parameters())[0] #self.gmp_fc��Ȩ�ز���
gmp = x * gmp_weight.unsqueeze(2).unsqueeze(3) #�õ�ȫ�����ػ��ӳ�Ȩ�ص�����ͼ
cam_logit = torch.cat([gap_logit, gmp_logit], 1) #���gap��gmp��cam_logitԤ��
x = torch.cat([gap, gmp], 1) #������ֳػ��������ͼ,ͨ����512
x = self.relu(self.conv1x1(x)) #����һ��������,ͨ����512ת��Ϊ256
heatmap = torch.sum(x, dim=1, keepdim=True) #�õ�ע��������ͼ
if self.light:
x_ = torch.nn.functional.adaptive_avg_pool2d(x, 1) #���������Ⱦ���һ��gap
x_ = self.FC(x_.view(x_.shape[0], -1))
else:
x_ = self.FC(x.view(x.shape[0], -1))
gamma, beta = self.gamma(x_), self.beta(x_) #�õ�����Ӧgamma��beta
for i in range(self.n_blocks):
#������Ӧgamma��beta���뵽AdaILN
x = getattr(self, 'UpBlock1_' + str(i+1))(x, gamma, beta)
out = self.UpBlock2(x) #ͨ���ϲ������ģ��,�õ����ɽ��
return out, cam_logit, heatmap #ģ�����Ϊ���ɽ��,camԤ���Լ�����ͼ

����spectral normalization
ԭ�� GAN ��Ŀ�꺯���ȼ����Ż��������ݵķֲ� p g p_{g} pg? ����ʵ���ݵķֲ� p r p_{r} pr? ֮��� J-S ɢ�� (Jensen�CShannon Divergence)���ڵ����ڵ��������б���ѵ��Խ��,�������ݶ���ʧԽ���ء�
??WGANʹ������������ Wasserstein distance ����ԭ�� GAN �е� J-S ɢ�ȡ� Ȼ������KR��żԭ���� Wasserstein distance���������ת��Ϊ������ŵ�����ϣ���������������⡣ Ϊ��ʹ���б��� D ��������ϣ��������,����ʹ�á��ݶȲü���������IJ���ֱ�Ӳü���һ����ֵ���¡�
??���ǿ�����������:�ֲ���С�㸽�������ƽ̹(flatness)�Ļ�(б����Լ��),��ô�䷺�������ܽ��Ϻ�,��֮,���Dz�ƽ̹(sharpness)�Ļ�,��һ��䶯,�������ϴ�仯,���䷺�����ܾͲ���,Ҳ�Ͳ��ȶ���
Spectral normalization for generative adversarial network�� (���¼�� Spectral Norm) ʹ��һ�ָ����ŵķ�ʽʹ���б��� D ��������ϣ��������,�����˺����仯�ľ��ҳ̶�,�Ӷ�ʹģ���ȶ���
1. Lipschitz ������
Lipschitz ���������˺����仯�ľ��ҳ̶�,���������ݶȡ���һά�ռ���,�������� y=sin(x) �� 1-Lipschitz��,�������б���� 1

�� GAN ��,����������һ���б���
D
:
I
��
R
D: I \rightarrow R
D:I��R ,����
I
I
I ��ͼ��ռ䡣����б����� K-Lipschitz continuous ��,��ô��ͼ��ռ��е����� x �� y,��:
��
D
(
x
)
?
D
(
y
)
��
<
=
K
��
x
?
y
��
\lVert D(x) - D(y)\rVert <= K\lVert x - y \rVert
��D(x)?D(y)��<=K��x?y��
��� K ȡ����Сֵ,��ô K ����Ϊ Lipschitz constant
2. SVD�ֽ�
Spectral Normalization��������ʵ�ܼ�: ���������ÿһ��IJ��� W W W �� SVD �ֽ�,Ȼ������������ֵ��Ϊ1,����1-Lipschitz����, �����,��ÿһ�θ��� W W W ֮���� W W W ��������ֵ�� ����,ÿһ������� x x x ��������ϵ�����ᳬ�� 1��
���� Spectral Norm ֮��,�������ÿһ�� g l ( x ) g_{l}(x) gl?(x) Ȩ��,������
g
l
(
x
)
?
g
l
(
x
)
x
?
y
<
=
1
\frac{g_{l}(x) - g_{l}(x)}{x - y} <= 1
x?ygl?(x)?gl?(x)?<=1
�������������� ��ȻҲ����������ϣ�������ԡ�
����ͼ����ÿ��λ�õľ�������,���ÿ��Կ�����һ������˷������,����ֻ��ҪԼ����������˵IJ��� ,ʹ���� 1-Lipschitz continuous ��,�Ϳ������������������ 1-Lipschitz continuity���������Ѿ�֪��,���þ������� 1-Lipschitz continuous,ֻ��Ҫ��������Ԫ��ͬʱ���������������ֵ,����˵������ spectural norm��
�ܽ�
- ���˶���ע�������Ƶ�����
??���ڲ�ͬ������,���粻ͬͨ������Ӧͼ�̶��Dz�һ����,���ܶ���ijһ���ض�����,���ͨ����һ���������Ӧ,�Ǹ�ͨ��û����Ӧ�����ʱ����GAP���ǿ���ÿ��ͨ��ѹ��,�����͵õ���һ��ͨ����������ע���������� �� \omega �� ������������� �� \omega �� ��feature map���м�Ȩ���Ӷ��õ����ͼ,ʵ��ע�������ơ���NICE-GANֻ���ڴ˻����ϼ��˸��в������γɲв�ע��������
�����
Learning Deep Features for Discriminative Localizatiion
paper / blog
CAM
note /
CAMϵ�й���һ��
Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation (U-GAT-IT)
paper / note