���
��ҳ:https://lolnerf.github.io/
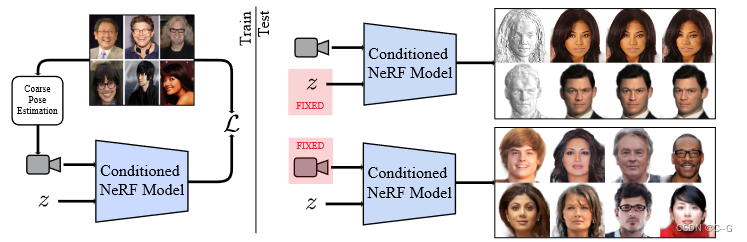
����ͨ���ڹ���DZ�ڿռ�(��)������ʹ�õ�һ�������ع������ĵ���ͼͼ����ѧϰ��״����۵Ŀռ䡣��������ͼ������ȡһ����άģ��,�����µ��ӽǽ�����Ⱦ(��)
����
- �����һ�ִӵ���ͼͼ����ѧϰ��ά�ؽ�Ŀ�����ķ���,��ѵ�����Ӷ���ͼ��ֱ��ʽ���;
- ����������ͼ������û���κμ��μල�������ѧϰ�������ļ���Ԥ��(�������)
- ������ͨ���ؽ��̶���ͼ�����ӱ����ͼ����ʾѧϰ����������۷��泬���˶Կ�������
ʵ������
NeRF�ع�
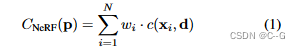
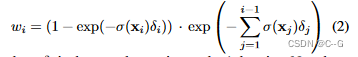
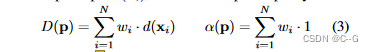
�Զ�������
�Զ�������,Ҳ����Ϊ����DZ�Ż�(GLO),��һ������ģ��,����ʹ�ñ����������������ѧϰ,ͨ��Ϊѵ�����ݼ��е�ÿ����ͬԪ�ط���һ�д������ֱ��ѧϰ����,��Щ������ģ�Ͳ��������ಿ����Ϊ��ѧϰ��������Эͬ�Ż���
LOLNeRF
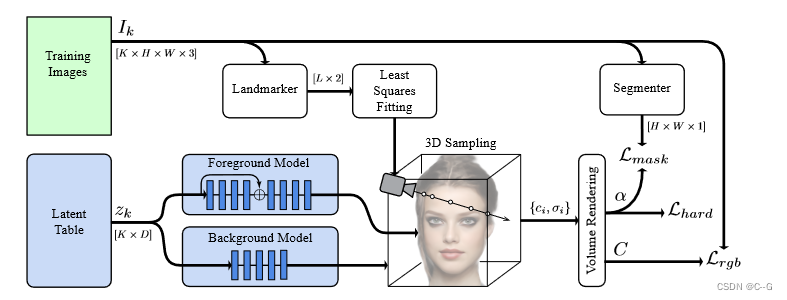
ѧϰÿ��ͼ���DZ�ڴ����,�Լ�ǰ���ͱ���nerf�������Ⱦ���������ÿ��ѵ�����ص�ÿ����RGB��ʧ,�Լ����ͼ��ָ�����alphaֵ��������Ķ����ǴӶ�ά�ر�������ض���ı�3D�ؼ������С�������������������
��С��������ʧ�ļ�Ȩ����ѵ�����������DZ��Z
ѵ��ͼ��
I
k
I_k
Ik? �ı� L2 ����ؽ���ʧ�������� prgb
Lrgb
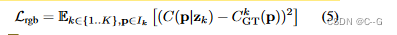
��չ��NeRF�ġ���������(�������/����)��ʽ,ͨ������һ���Զ��������ܹ���֧��ѧϰ��״��DZ�ڿռ�
�����ָĽ�����ϵ�ṹ��,��ҪNeRF�Ǹ������������ÿ�������DZ�� z �� R D z��R^D z��RD,�Լ� l άλ�ñ��� �� L ( x ) ��^L(x) ��L(x)
�ܶȺͷ��亯������ʽ�� ��(x|z) �� c(x|z)
����һ����ʽ,�������Ȳ�����ͼ���� d �ĺ���
��ЩDZ����DZ�� Z �� R K �� D Z��R^{K��D} Z��RK��D �е���,��DZ����ʼ��Ϊ 0 K �� D 0^{K��D} 0K��D,���� K Ϊͼ����
���ּܹ�ʹ�þ�ȷ�ع�ѵ��ʾ����Ϊ����,������Ա�����ģ�ͽ��д�������ļ�����ڴ�,�������˴�ѵ��ͼ������ȡ3D��Ϣ��Ҫ��������
ѵ����ģ����ѭ�뵥����NeRF��ͬ�Ĺ���,�������ݼ��е����� K ��ͼ���г�ȡ�������,����ÿ��������ͼ���в��������Ӧ��DZ�ڴ����������
Foreground-Background Decomposition
ʹ��һ��������ģ������������ϸ�ڵ�����,ʹ��һ����������ģ��
C
b
g
(
d
�O
z
)
C_{bg}(d|z)
Cbg?(d�Oz)��Ϊ����,��Ԥ��ÿ�����ߵ�����,��ϱ�����ǰ��ɫ,ʹ��NeRF�ܶȺ���������ֵ������Ⱦ
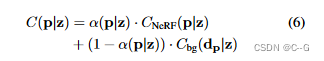
�ලǰ��/�������벢�����DZ�Ҫ��

�Ӵ�ɫ������ɫ��360?����ͷ�ֲ�����Ȼ��ѧϰ��ǰ���ֽ�
��Ԥ��ѵ����ģ�������Ԥ��ѵ��ͼ���ǰ���ָ�ʱ,��Ӧ��һ���������ʧ������NeRF��������������Ԥ��һ��
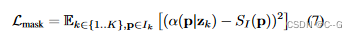
S
I
(
?
)
S_I(��)
SI?(?)��Ӧ����ͼ��
I
k
I_k
Ik? �������� p ��������Ԥѵ��ͼ��ָ���
���������ݼ��Ͻ���ѵ��ʱ,��(7)�е�Ԥѵ��ģ��ʹ��MediaPipe���ķָ�,�� ����=1.0��
Hard Surfaces
�����㹻������ͼ����㹻����������,����ͼһ���Խ������ڴ����ӿյ�ʵ��Ӳ����,�������ڵ�����ͼ����²���������Ϊ��Ӧ��ÿ��DZ��ij�����ֻ��һ���ӵ�ල,��ͨ���ᵼ�����ӵ㷽��ı���ģ��

��Ȩ�� w ��Ϊ������˹�ֲ��Ļ�Ϸֲ��ĸ���ʩ������,����һ����ȨֵΪ 0 ������ģ̬,��һ����ȨֵΪ 1 ������ģ̬:
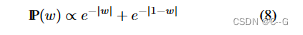
�÷ֲ��Ƿ�ֵ��,��������һ��ϡ���,���п�������(0,1)�е��κ�ֵ w ���Dz�������,��������ת��Ϊ��ʧ

�����Լ�������� ��(x) �Ĵ�Сȡ���ڲ����ܶ�,�����ܶȲ���һ�����ݺ���,�ú���������һ�����������ڱ��Ͳ���Ȩֵ,ͨ������,���ʺ��ڱ���ģ�����Ĺ�ģ
Camera Parameters
�������Ҫ���������ÿ�����������ڼ�������λ�õ����������,�������ͨ���˶��ṹ������ͼ���й���,����ͼ����,�������ģ��,���Dz����ܵ�.
ʹ�����뵥��ͼͼ�����,ʹ����MediaPipe Face MeshԤѵ��������ģ������ȡ�����ڶ������һ��λ�õ�2D�ر�

�ر�ͷֶ���-(�����������ʶ�ĵر�ͷֶ��������������в�������ɫԲȦ(?)��ʾ��ʶ�ĵرꡣ��������������ر��ʾ���������
Ȼ��,���á���״ƥ�䡱��С�����Ż�����Щ�ر�λ�����3D�ر�λ�õ�ͶӰ���ж���,�Ի����������Ĵ��Թ���
Conditional Generation
����һ��Ԥ��ѵ����ģ��,�����ҵ�һ��DZ�ڵĴ��� z,�������ؽ�ѵ�����в����ڵ�ͼ��,����DZ��������NeRFģ�Ͳ�������ѧϰ��,���Խ���һ������ΪDZ�����ж���һ�е����Ż�,��һ�б���ʼ��ΪDZ�������е�ƽ��
��
Z
��_Z
��Z?,��ʹ������ģ����ͬ����ĺ��Ż��������Ż�

����ÿ�ַ���,չʾ��һ���ʺ���ѵ������������:���ڦ�-GAN,һ����ѵ���ֲ��в�����DZ������,�������ĵ�,һ��ѧϰ�����ؽ�ѵ��ͼ���DZ�����롣�����ڸ��߷ֱ��ʵ�ͼ���Ͻ���ѵ��,���ĵķ����ָ��˸�������ϸ�ڡ�
���������ַ����ؽ���ͬһͼ�������ͼ�ıȽ�

Unconditional Generation
Ϊ�˴�ģ��ѧϰ���Ŀռ��ж��¶�����в���,����DZ�� Z ���ж���ľ���ֲ� Z �ж�DZ����в����� �� Z ��ģΪһ����Ԫ��˹,ͨ���� Z ���н������ɷַ����������ֵΪ �� Z ��_Z ��Z?,Э����Ϊ �� Z ��_Z ��Z?����������������ģ�Ͷ�DZ����ʹ�ø�˹����,����������ֲ���ֵ��Զʱ, �۲쵽�����Ķ����Ժ�����֮���Ȩ�⡣���, ����GAN�г��õġ��ضϼ��ɡ�����������Ȩ�⡣