基于三个影像处理的观察
第一个观察是,要生成一个pattern(侦测是否有某一类pattern出现),不要看整张的image,只需要看image的一小部分。(不需要fully connected)
第二是,通用的pattern会出现在一张图片的不同的区域,可以参数共享以减少参数量。
第三个是,可以做subsampling(拿掉图像奇数行,偶数列的像素变成十分之一大小不会影响我们对image的理解),因此采样以减少参数。
一二点――convolution,三――max pooling
CNN架构
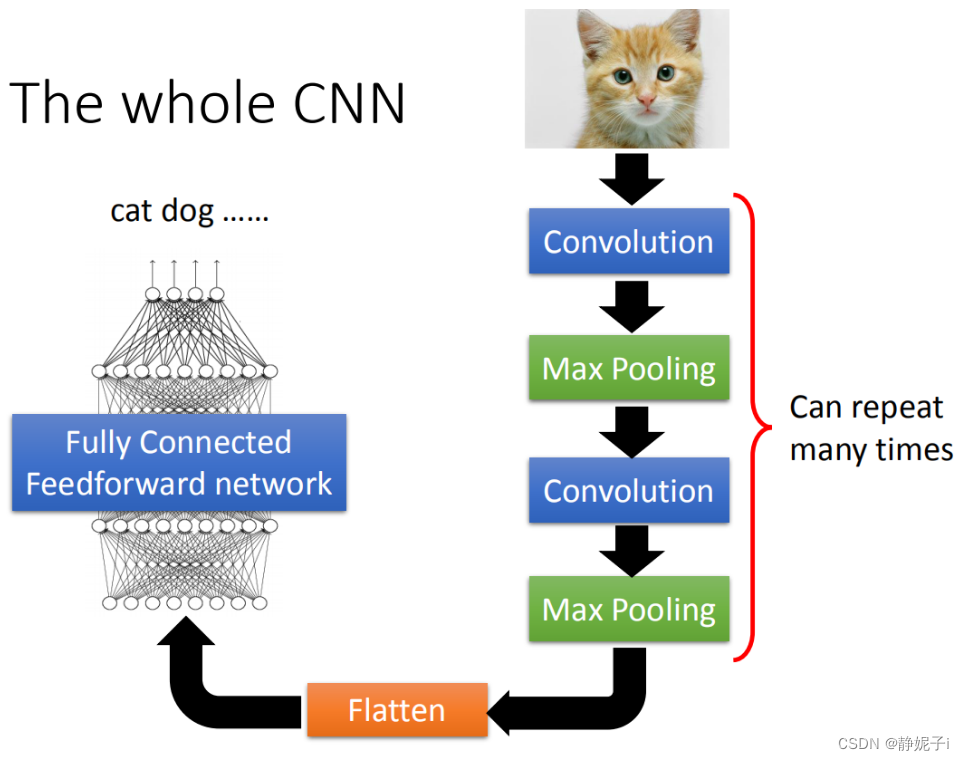
首先input一张image以后,这张image会通过convolution layer,接下里做max pooling这件事,然后在做convolution,再做max pooling这件事。这个process可以反复无数次,反复的次数你觉得够多之后,(但是反复多少次你是要事先决定的,它就是network的架构(就像你的neural有几层一样),你要做几层的convolution,做几层的Max Pooling,你再定neural架构的时候,你要事先决定好)。你做完决定要做的convolution和Max Pooling以后,你要做另外一件事,这件事情叫做flatten,再把flatten的output丢到一般fully connected feedforward network,然后得到影像辨识的结果。
convolution
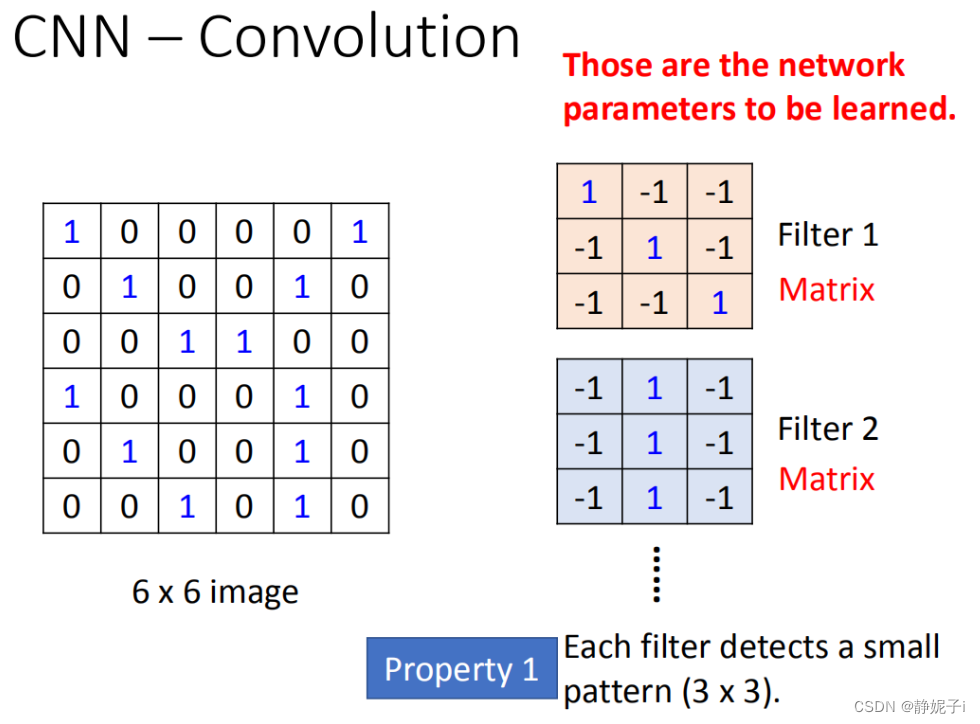
每个卷积核侦测一个pattern,其参数通过学习习得
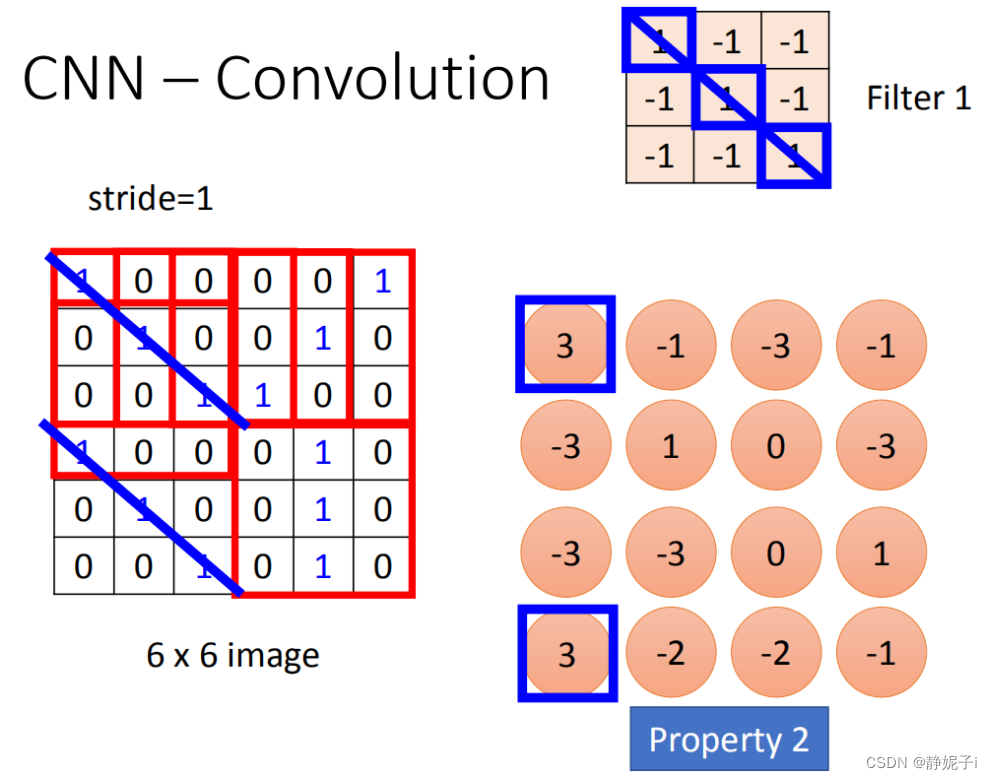
6 *6的matrix,经过convolution process就得到4 *4的matrix。如果你看filter的值,斜对角的值是1,1,1。所以它的工作就是detain1有没有1,1,1(连续左上到右下的出现在这个image里面)。比如说:出现在这里(如图所示蓝色的直线),所以这个filter就会告诉你:左上跟左下出现最大的值
就代表说这个filter要侦测的pattern,出现在这张image的左上角和左下角,这件事情就考虑了propetry2。同一个pattern出现在了左上角的位置跟左下角的位置,我们就可以用filter 1侦测出来,并不需要不同的filter来做这件事。
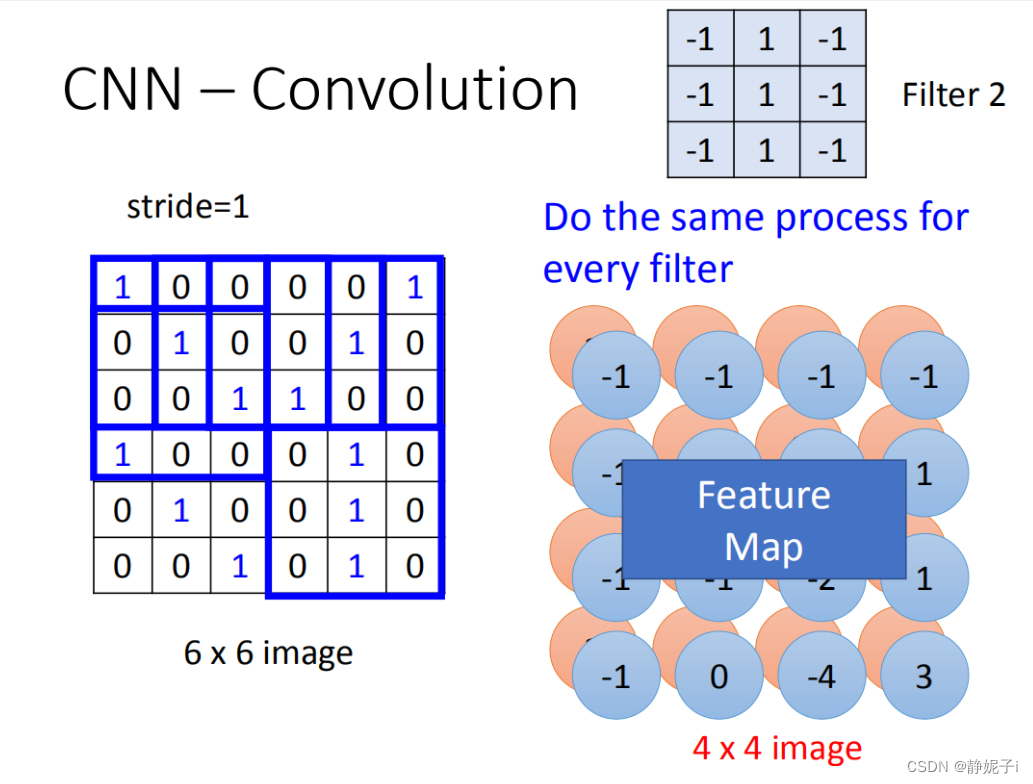
在一个convolution layer 里面会有很多的filter(刚才只是一个filter的结果),那另外的filter会有不同的参数(图中显示的filter2),它也做跟filter1一模一样的事情,在filter放到左上角再内积得到结果-1,依次类推。你把filter2跟 input image做完convolution之后,你就得到了另一个4*4的matrix,红色4 *4的matrix跟蓝色的matrix合起来就叫做feature map,看你有几个filter,你就得到多少个image(你有100个filter,你就得到100个4 *4的image)
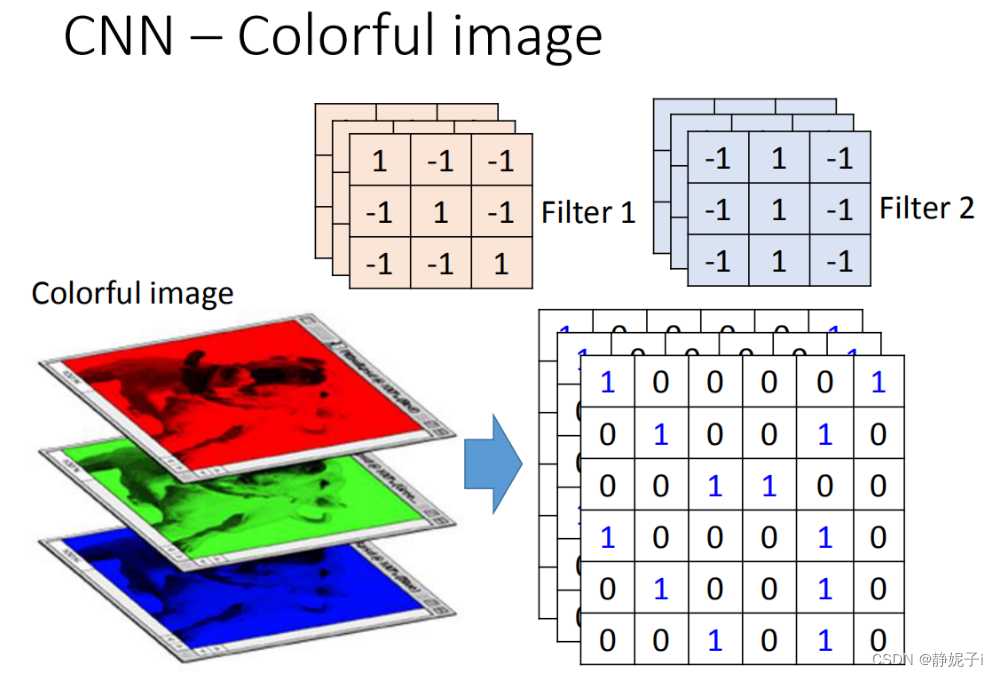
彩色的image是由RGB组成的,所以,一个彩色的image就是好几个matrix叠在一起,就是一个立方体。如果要处理彩色image,这时候filter不是一个matrix,filter而是一个立方体。如果今天是RGB表示一个pixel的话,那input就是3*6 *6,那filter就是3 *3 *3
在做convolution的话,就是将filter的9个值和image的9个值做内积(不是把每一个channel分开来算,而是合在一起来算,一个filter就考虑了不同颜色所代表的channel)
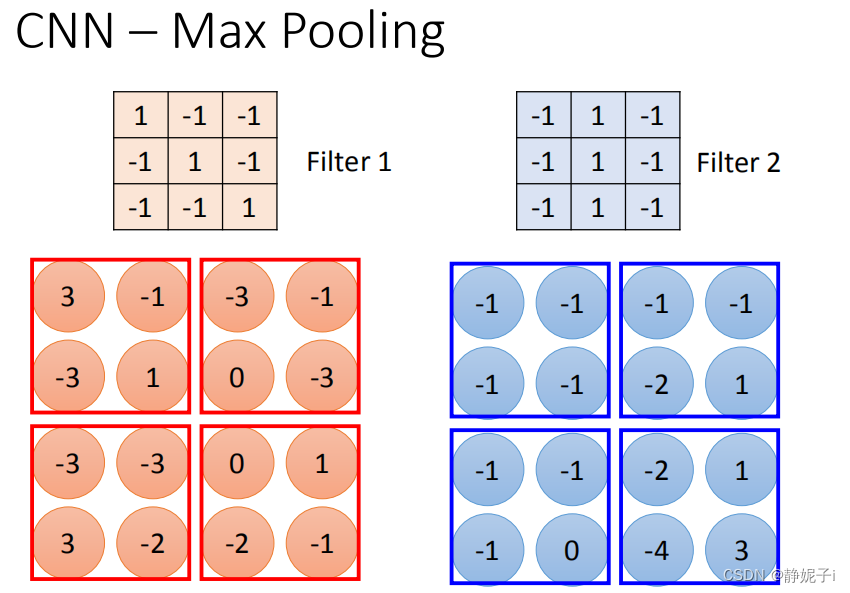
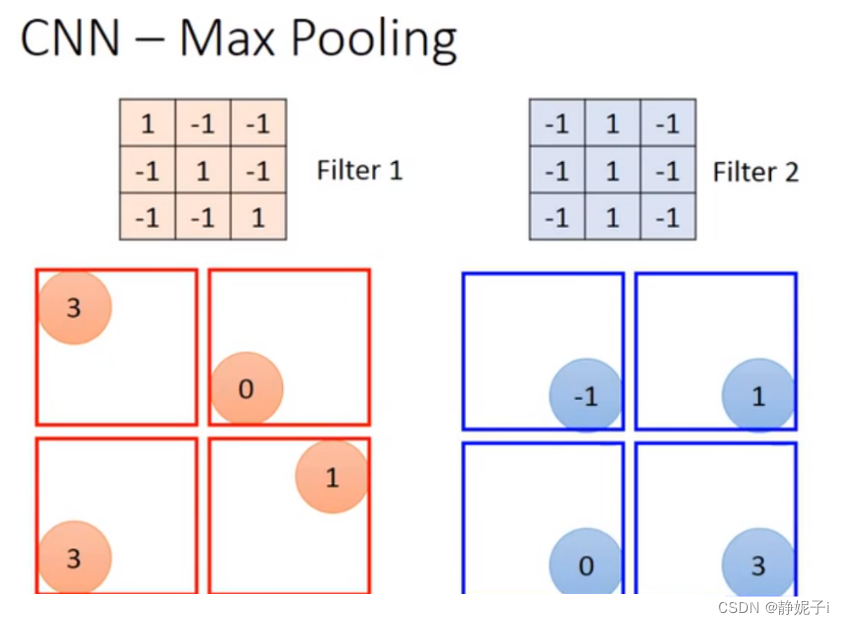
max pooling
repeat
做完一个convolution和一次max pooling,就将原来6 * 6的image变成了一个2 *2的image。这个2 *2的pixel的深度depend你有几个filter(你有50个filter你就有50维),得到结果就是一个new image but smaller,一个filter就代表了一个channel。
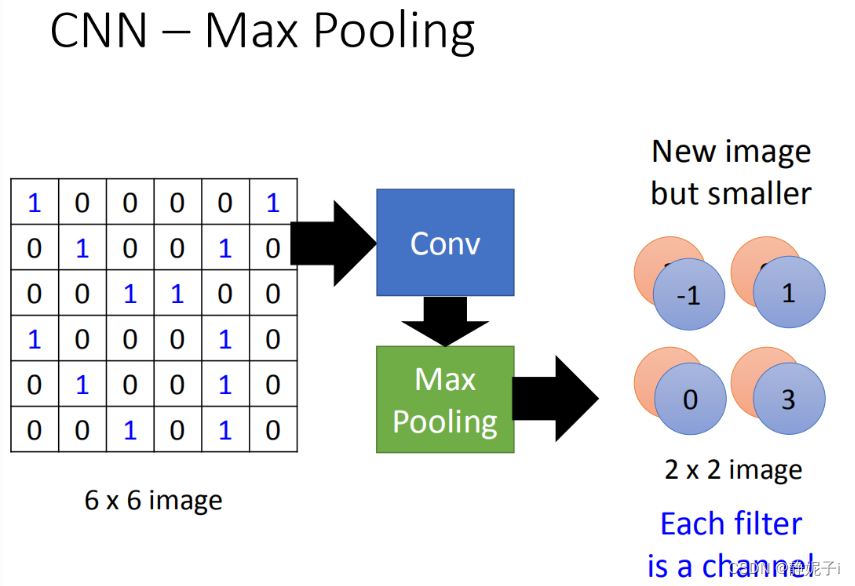 这件事可以repeat很多次,通过一个convolution + max pooling就得到新的 image。它是一个比较小的image,可以把这个小的image,做同样的事情,再次通过convolution + max pooling,将得到一个更小的image。
这件事可以repeat很多次,通过一个convolution + max pooling就得到新的 image。它是一个比较小的image,可以把这个小的image,做同样的事情,再次通过convolution + max pooling,将得到一个更小的image。
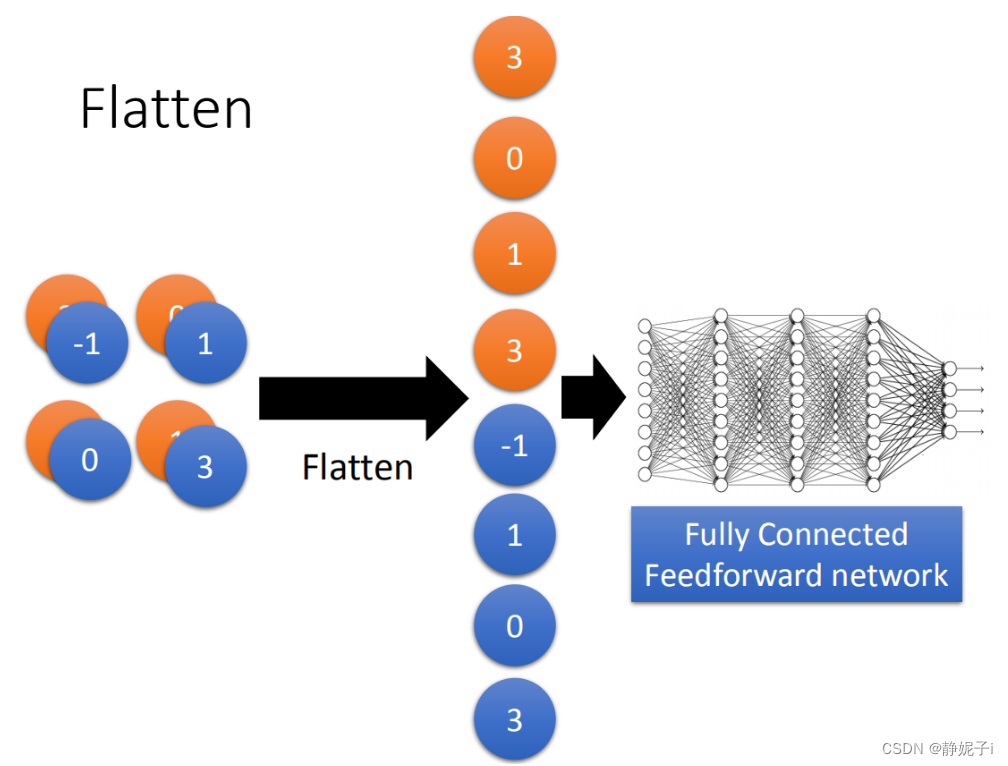
flatten
flatten就是feature map拉直,拉直之后就可以丢到fully connected feedforward netwwork,然后就结束了。
CNN 学到了什么
 分析input第一个filter是比较容易的,因为一个layer每一个filter就是一个3*3的matrix,对应到3 *3的范围内的9个pixel。所以你只要看到这个filter的值就可以知道说:它在detain什么东西,所以第一层的filter是很容易理解的。
分析input第一个filter是比较容易的,因为一个layer每一个filter就是一个3*3的matrix,对应到3 *3的范围内的9个pixel。所以你只要看到这个filter的值就可以知道说:它在detain什么东西,所以第一层的filter是很容易理解的。
在第二层我们也是3 *3的filter有50个,但是这些filter的input并不是pixel(3 *3的9个input不是pixel)。而是做完convolution再做Max Pooling的结果。所以这个3 *3的filter就算你把它的weight拿出来,你也不知道它在做什么。另外这个3 *3的filter它考虑的范围并不是3 *3的pixel(9个pixel),而是比9个pxiel更大的范围。