Conformer(��ASR���WeNet������������?)
������Ҫ���WeNet����Conformer,����ϸ�ڿ��Կ�ԭ��Ŷ
����WeNet���������Բ鿴֪�� ����;С���ס�
1��Conformer����
conformerԭ��:��Conformer: Convolution-augmented Transformer for Speech Recognition��
��һ�´����֪��transformerԭ�ġ�attention is all you need��,conformer����transformer�ṹ�϶����һ��convolution�����ġ�
2��Conformer�ṹ
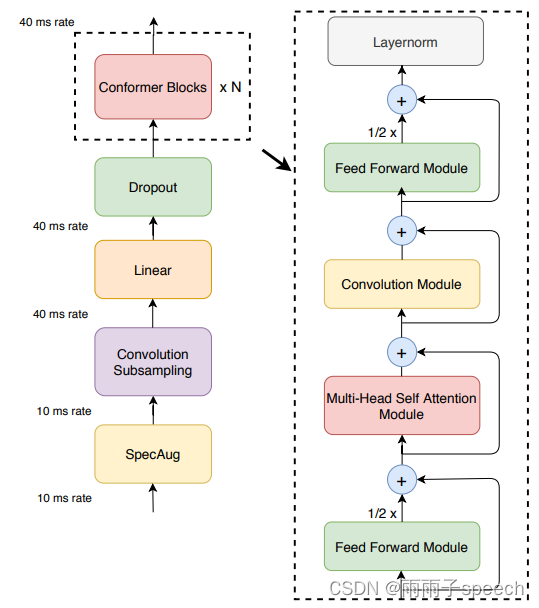
Conformer����ṹ:SpecAug��ConvolutionSubsampling��Linear��Dropout��ConformerBlocks��N��
ConformerBlock�ṹ(N���ýṹ):Feed Forward Module��Multi-Head Self Attention Module��Convolution Module��Feed Forward Module��Layernorm������ÿ��Module����ǰ��һ��Layernorm���һ��Dropout,�Ҷ��вв�������,�в�����Ϊ�������ݱ�����
�������ṹ:���Կ���ConformerBlock�����������ṹ,������һ����Feed Forward Module�м����Multi-Head Self Attention Module��Convolution Module��
3��Conformer��WeNet�������
����ʶ����WeNet��encoder�ṹ��ѡ��Conformer,��ͨ���ٷ��ļ����Կ���,��conformer��Ϊencoder�ṹ��transformer�и��õ�Ч������������wenetѵ��ʱ����������conformer��Ϊencoder�ṹ��
��Ҫ�������encoder.py��subsampling.py��embedding.py��encoder_layer.py��positionwise_feed_forward.py��attention.py��convolution.py��
3.1����ConformerBlockǰ�Ĵ���
WeNet��������ȡ��������֮��,�Ὣ�����뵽encoder�С�
3.1.1��SpecAug
�ڴ�������ʱ����
3.1.2��Convolution Subsampling
������:encoder.py�C>subsampling.py&embedding.py
a�����������ݽ����²���,WeNet���ж���ѡ��,��subsampling.py���ᵽ��Conv2dSubsampling4��Conv2dSubsampling6��Conv2dSubsampling8.
b��ʵ���в���Conv2dSubsampling6��Conv2dSubsampling8ѵ��1wh���ݻ����lossΪnan����,�������ѡ��Conv2dSubsampling4��ΪConvolution Subsampling��
c��ʹ��Conv2dSubsampling4���������ݽ����²���,����������Ϊ���������������ξ�����Ϊ3��3,����Ϊ2��Conv2d,�������Ժ��������ݽ������ı��²�����
d��Convolution Subsampling���ִ���,ʵ�����������ά�ȼ�odimΪ512,batch_sizeΪ14��
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, odim, 3, 2),
torch.nn.ReLU(),
torch.nn.Conv2d(odim, odim, 3, 2),
torch.nn.ReLU(),
)
e��ʵ�������ݵ�shape����
Conv2dSubsampling4֮ǰ
(Pdb) p xs.shape
torch.Size([14, 975, 80])
Conv2dSubsampling4֮��
(Pdb) p xs.shape
torch.Size([14, 243, 512])
���Կ�������Conv2dSubsampling4֮��ά��1��975�任��243,���������ı��²�����
3.2��ConformerBlock�ṹ�빫ʽ
������:conformerblock: encoder.py�C>encoder_layer.py
a������ǰ��Ĵ�������ʽ���뵽conformerblock��,ʵ����ʹ����N=12���conformerblock�ṹ��
b��conformerblock��ʽ����,����Ͳ�����,���Ǹ���conformerblock�ṹ�����Ĺ�ʽ��
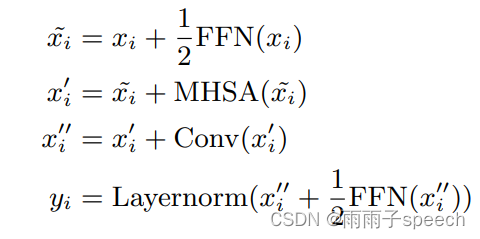
3.3��Feed Forward Module Code
������:Feed Forward Module: encoder.py�C>encoder_layer.py�C>positionwise_feed_forward.py
a���ṹ
������ʾ,��ҪΪ�������Բ�,���м����Ϊswish��conformerblock�а�������Feed Forward Module,�����ṹ��һ���ġ�

b������
self.w_1 = torch.nn.Linear(idim, hidden_units)
self.activation = activation
self.dropout = torch.nn.Dropout(dropout_rate)
self.w_2 = torch.nn.Linear(hidden_units, idim)
Feed Forward Moduleǰ
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
tensor([[[ -0.9448, -1.6156, 0.8714, ..., -0.6092, 8.3108, -4.7808],
[ -1.9032, -0.7550, 0.0000, ..., 0.0000, 8.4346, -5.1248],
[ 0.0000, 0.1946, 1.7132, ..., 0.1049, 0.0000, 0.0000],
...,
[-12.1167, -2.8028, -9.4789, ..., -7.2485, 8.0067, -7.4645],
[ -0.5737, -3.4279, -2.4972, ..., -3.8395, 7.2618, -7.5300],
[ -0.0902, -1.9239, -0.6181, ..., 1.2788, 5.7042, 0.0000]],
[[ 0.0000, -3.5419, 0.0000, ..., -4.7302, 0.7809, -0.7692],
[ -4.9884, -1.4948, 0.4247, ..., -3.1005, 0.0594, 0.2251],
[ -5.3625, 0.0000, -1.1701, ..., -2.4318, -1.0293, 1.1975],
...,
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, 0.0000],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ 0.0000, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113]],
[[ 0.7055, 2.6856, -5.1106, ..., 0.6471, -5.7998, 7.7951],
[ 4.6700, 3.8121, -4.1586, ..., 0.9645, -5.9060, 7.7761],
[ 0.0000, 1.8728, -3.5463, ..., 1.7811, -5.1110, 8.0430],
...,
[ -9.5743, 0.0000, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., 0.0000, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113]],
...,
[[ -5.9051, 0.0000, 0.0000, ..., -1.7656, 1.2541, -2.9259],
[ -7.2387, 0.0000, -1.9941, ..., -1.9837, 3.7928, -3.0524],
[-11.5061, 4.6892, -2.9696, ..., -3.9930, 0.2395, -1.5693],
...,
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., 0.0000, 12.7505, -7.8113],
[ -9.5743, 0.0000, -13.6071, ..., -5.8194, 12.7505, -7.8113]],
[[ -4.0918, 1.2283, -3.7218, ..., -4.6928, 4.6370, -4.9392],
[ 0.0000, 2.6892, -2.0451, ..., -0.4186, 3.7887, -2.1638],
[ 0.0000, 3.7681, -0.6485, ..., -1.5094, 1.3679, -2.6088],
...,
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113]],
[[ -5.7208, 0.5752, -3.4696, ..., -3.7705, 11.7755, 1.7834],
[ -7.1437, 0.8723, -4.2169, ..., -3.9519, 11.1012, 1.8506],
[ -7.0842, 0.5833, -3.3386, ..., -3.5101, 11.4416, 1.6952],
...,
[ -9.5743, -7.7568, -13.6071, ..., 0.0000, 0.0000, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, -7.8113],
[ -9.5743, -7.7568, -13.6071, ..., -5.8194, 12.7505, 0.0000]]],
device='cuda:0', grad_fn=<FusedDropoutBackward0>)
Feed Forward Module��
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
7.2815e+00, -7.6011e+00],
[ 3.1489e-02, -1.8858e+00, -4.5769e-01, ..., 1.3952e+00,
5.6306e+00, -3.0690e-02]],
[[-6.3229e-03, -3.4414e+00, -4.1966e-02, ..., -4.7639e+00,
6.3168e-01, -8.2709e-01],
[-4.9884e+00, -1.4948e+00, 4.0035e-01, ..., -2.9774e+00,
-6.4502e-03, 1.0855e-01],
[-5.3848e+00, 2.1896e-02, -1.2273e+00, ..., -2.4318e+00,
-1.0881e+00, 1.1193e+00],
...,
[-9.5743e+00, -7.6100e+00, -1.3619e+01, ..., -5.6579e+00,
1.2705e+01, -1.1259e-01],
[-9.4011e+00, -7.7079e+00, -1.3600e+01, ..., -5.7637e+00,
1.2693e+01, -7.8329e+00],
[ 1.6623e-01, -7.7410e+00, -1.3594e+01, ..., -5.7195e+00,
1.2776e+01, -7.9591e+00]],
[[ 7.0553e-01, 2.7021e+00, -5.1429e+00, ..., 6.9559e-01,
-5.9345e+00, 7.7479e+00],
[ 4.8407e+00, 3.8736e+00, -4.2463e+00, ..., 1.0054e+00,
-5.9870e+00, 7.6246e+00],
[ 1.0486e-01, 1.9964e+00, -3.6064e+00, ..., 1.7598e+00,
-5.1110e+00, 7.9280e+00],
...,
[-9.3324e+00, 1.0171e-01, -1.3625e+01, ..., -5.7424e+00,
1.2724e+01, -7.9598e+00],
[-9.3546e+00, -7.6776e+00, -1.3659e+01, ..., 0.0000e+00,
1.2747e+01, -7.9354e+00],
[-9.3427e+00, -7.7067e+00, -1.3743e+01, ..., -5.8194e+00,
1.2808e+01, -7.8516e+00]],
[[-3.8864e+00, 1.2016e+00, -3.7942e+00, ..., -4.6340e+00,
4.6085e+00, -5.0171e+00],
[ 1.6116e-01, 2.6320e+00, -2.1391e+00, ..., -4.4683e-01,
3.7133e+00, -2.2118e+00],
[ 1.1952e-01, 3.7163e+00, -7.2823e-01, ..., -1.5372e+00,
1.3950e+00, -2.6756e+00],
...,
[-9.3344e+00, -7.7682e+00, -1.3643e+01, ..., -5.6883e+00,
1.2767e+01, -7.9511e+00],
[-9.4534e+00, -7.7568e+00, -1.3671e+01, ..., -5.6858e+00,
1.2750e+01, -7.9653e+00],
[-9.3937e+00, -7.6900e+00, -1.3694e+01, ..., -5.7628e+00,
1.2702e+01, -7.8852e+00]],
[[-5.4615e+00, 5.6451e-01, -3.4696e+00, ..., -3.7742e+00,
1.1608e+01, 1.5476e+00],
[-7.1437e+00, 8.0560e-01, -4.2403e+00, ..., -3.9945e+00,
1.0934e+01, 1.6021e+00],
[-6.8293e+00, 5.6961e-01, -3.4408e+00, ..., -3.4578e+00,
1.1293e+01, 1.3934e+00],
...,
[-9.3903e+00, -7.7132e+00, -1.3642e+01, ..., 1.5418e-01,
-6.0617e-02, -7.9958e+00],
[-9.5743e+00, -7.7289e+00, -1.3659e+01, ..., -5.7391e+00,
1.2684e+01, -7.9137e+00],
[-9.3177e+00, -7.7448e+00, -1.3654e+01, ..., -5.8194e+00,
1.2788e+01, -1.5587e-01]]], device='cuda:0', grad_fn=<AddBackward0>)
���Կ�������Feed Forward Module֮������ά�Ȳ��������ı�,������layer norm�ȴ�����,���ݵĴ�С�����˸ı䡣ͬ��,����һ��Feed Forward Module��Ҳ��ͬ���IJ�����
3.4��Multi-Head Self Attention Module Code
������:Multi-Head Self Attention Module: encoder.py�C>encoder_layer.py�C>attention.py
��һ���ֻῪһƪ�µ�����ϸ˵˵
a���ṹ
Multi-Head Self Attention Module��Ҫ�ɴ������λ�ñ����ͷ��ע����(Multi-Head Self Attention with relative positional embedding)��ɡ�ʵ�����õ���ͷΪ8����ע����ģ�顣

b������
��������Ϊattention.py����,ϸ�ڱȽ϶�,�Ὺһƪ�µ�˵˵��
Multi-Head Self Attention Moduleǰ
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
1.2808e+01, -7.8516e+00]],
[[-3.8864e+00, 1.2016e+00, -3.7942e+00, ..., -4.6340e+00,
4.6085e+00, -5.0171e+00],
[ 1.6116e-01, 2.6320e+00, -2.1391e+00, ..., -4.4683e-01,
3.7133e+00, -2.2118e+00],
[ 1.1952e-01, 3.7163e+00, -7.2823e-01, ..., -1.5372e+00,
1.3950e+00, -2.6756e+00],
...,
[-9.3344e+00, -7.7682e+00, -1.3643e+01, ..., -5.6883e+00,
1.2767e+01, -7.9511e+00],
[-9.4534e+00, -7.7568e+00, -1.3671e+01, ..., -5.6858e+00,
1.2750e+01, -7.9653e+00],
[-9.3937e+00, -7.6900e+00, -1.3694e+01, ..., -5.7628e+00,
1.2702e+01, -7.8852e+00]],
[[-5.4615e+00, 5.6451e-01, -3.4696e+00, ..., -3.7742e+00,
1.1608e+01, 1.5476e+00],
[-7.1437e+00, 8.0560e-01, -4.2403e+00, ..., -3.9945e+00,
1.0934e+01, 1.6021e+00],
[-6.8293e+00, 5.6961e-01, -3.4408e+00, ..., -3.4578e+00,
1.1293e+01, 1.3934e+00],
...,
[-9.3903e+00, -7.7132e+00, -1.3642e+01, ..., 1.5418e-01,
-6.0617e-02, -7.9958e+00],
[-9.5743e+00, -7.7289e+00, -1.3659e+01, ..., -5.7391e+00,
1.2684e+01, -7.9137e+00],
[-9.3177e+00, -7.7448e+00, -1.3654e+01, ..., -5.8194e+00,
1.2788e+01, -1.5587e-01]]], device='cuda:0', grad_fn=<AddBackward0>)
Multi-Head Self Attention Module��
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
tensor([[[-1.0271e+00, -1.9463e+00, 1.7051e+00, ..., -6.3574e-01,
8.7831e+00, -4.8254e+00],
[-1.7611e+00, -7.7109e-01, -9.2721e-02, ..., -6.5186e-02,
8.9391e+00, -5.1968e+00],
[-1.4328e-01, -1.5383e-01, 2.4761e+00, ..., -4.7934e-02,
5.2762e-01, -4.3704e-02],
...,
[-1.2330e+01, -3.0957e+00, -8.8320e+00, ..., -7.2978e+00,
8.4464e+00, -7.7051e+00],
[-5.8125e-01, -3.7171e+00, -1.6540e+00, ..., -3.8881e+00,
7.7412e+00, -7.6324e+00],
[ 3.1489e-02, -1.8858e+00, 3.3470e-01, ..., 1.2515e+00,
5.6306e+00, -4.4427e-02]],
[[-6.3229e-03, -3.3921e+00, 4.8096e-01, ..., -4.8776e+00,
7.2262e-01, -1.3703e+00],
[-5.3446e+00, -1.4451e+00, 9.1622e-01, ..., -3.1011e+00,
7.9614e-02, -4.2886e-01],
[-5.7261e+00, 6.9976e-02, -7.1110e-01, ..., -2.5597e+00,
-9.9130e-01, 5.8256e-01],
...,
[-9.9296e+00, -7.5594e+00, -1.3619e+01, ..., -5.6579e+00,
1.2793e+01, -6.5060e-01],
[-9.7484e+00, -7.6608e+00, -1.3076e+01, ..., -5.8727e+00,
1.2796e+01, -8.3650e+00],
1.2876e+01, -8.1519e+00]],
[[-3.8864e+00, 8.1121e-01, -3.2379e+00, ..., -4.6340e+00,
4.5953e+00, -5.4232e+00],
[-1.0173e-01, 2.2622e+00, -1.6064e+00, ..., -7.8868e-01,
3.7027e+00, -2.6075e+00],
[-1.6345e-01, 3.3597e+00, -1.9494e-01, ..., -1.8532e+00,
1.3767e+00, -3.0669e+00],
...,
[-9.6426e+00, -8.1642e+00, -1.3643e+01, ..., -6.0016e+00,
1.2767e+01, -8.3592e+00],
[-9.6984e+00, -8.1595e+00, -1.3115e+01, ..., -6.0114e+00,
1.2719e+01, -8.3549e+00],
[-9.6625e+00, -8.0812e+00, -1.3120e+01, ..., -6.0365e+00,
1.2702e+01, -8.2902e+00]],
[[-5.4615e+00, 7.9916e-01, -3.4321e+00, ..., -3.8729e+00,
1.1705e+01, 1.5476e+00],
[-6.9851e+00, 1.0249e+00, -4.2206e+00, ..., -4.0995e+00,
1.1052e+01, 1.2745e+00],
[-6.6968e+00, 8.0111e-01, -3.4151e+00, ..., -3.5240e+00,
1.1393e+01, 1.0780e+00],
...,
[-9.2554e+00, -7.4362e+00, -1.3618e+01, ..., 1.5418e-01,
5.9763e-02, -8.3539e+00],
[-9.4399e+00, -7.4798e+00, -1.3644e+01, ..., -5.8081e+00,
1.2792e+01, -8.1860e+00],
[-9.1668e+00, -7.5268e+00, -1.3658e+01, ..., -5.9279e+00,
1.2788e+01, -4.8667e-01]]], device='cuda:0', grad_fn=<AddBackward0>)
���Կ�������Multi-Head Self Attention Module����ά�Ȳ������ı�,ֻ������һϵ�е���ѧ���㡣
3.5��Convolution Module Code
������:Convolution Module: encoder.py�C>encoder_layer.py�C>convolution.py
a���ṹ
��ͼ�п��Կ���,Convolution Module����������������һ����Ⱦ���,��һ�������ʹ��Glu,�ڶ��������ʹ��Swish,�м������һ��batch norm��������Ϊ������Ϊ1��1,����Ϊ1��Conv1d,��Ⱦ���Ϊ������Ϊ31��31,����Ϊ1��Conv1d��

b������
x = self.pointwise_conv1(x)
x = nn.functional.glu(x, dim=1)
# 1D Depthwise Conv
x = self.depthwise_conv(x)
if self.use_layer_norm:
x = x.transpose(1, 2)
x = self.activation(self.norm(x))
if self.use_layer_norm:
x = x.transpose(1, 2)
x = self.pointwise_conv2(x)
# mask batch padding
if mask_pad.size(2) > 0:
x.masked_fill_(~mask_pad, 0.0)
Convolution Moduleǰ
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
1.2876e+01, -8.1519e+00]],
[[-3.8864e+00, 8.1121e-01, -3.2379e+00, ..., -4.6340e+00,
4.5953e+00, -5.4232e+00],
[-1.0173e-01, 2.2622e+00, -1.6064e+00, ..., -7.8868e-01,
3.7027e+00, -2.6075e+00],
[-1.6345e-01, 3.3597e+00, -1.9494e-01, ..., -1.8532e+00,
1.3767e+00, -3.0669e+00],
...,
[-9.6426e+00, -8.1642e+00, -1.3643e+01, ..., -6.0016e+00,
1.2767e+01, -8.3592e+00],
[-9.6984e+00, -8.1595e+00, -1.3115e+01, ..., -6.0114e+00,
1.2719e+01, -8.3549e+00],
[-9.6625e+00, -8.0812e+00, -1.3120e+01, ..., -6.0365e+00,
1.2702e+01, -8.2902e+00]],
[[-5.4615e+00, 7.9916e-01, -3.4321e+00, ..., -3.8729e+00,
1.1705e+01, 1.5476e+00],
[-6.9851e+00, 1.0249e+00, -4.2206e+00, ..., -4.0995e+00,
1.1052e+01, 1.2745e+00],
[-6.6968e+00, 8.0111e-01, -3.4151e+00, ..., -3.5240e+00,
1.1393e+01, 1.0780e+00],
...,
[-9.2554e+00, -7.4362e+00, -1.3618e+01, ..., 1.5418e-01,
5.9763e-02, -8.3539e+00],
[-9.4399e+00, -7.4798e+00, -1.3644e+01, ..., -5.8081e+00,
1.2792e+01, -8.1860e+00],
[-9.1668e+00, -7.5268e+00, -1.3658e+01, ..., -5.9279e+00,
1.2788e+01, -4.8667e-01]]], device='cuda:0', grad_fn=<AddBackward0>)
Convolution Module��
(Pdb) p x.shape
torch.Size([14, 243, 512])
(Pdb) p x
[ -9.7045, -8.1045, -13.0602, ..., -0.5921, 12.8330, -8.4895],
[ -9.6829, -8.1501, -13.1456, ..., -6.4132, 12.8319, -8.3690]],
...,
[[ -6.7102, 0.1239, 0.1389, ..., -1.9504, 1.5525, -3.0805],
[ -7.8718, -0.4553, -1.8495, ..., -1.8900, 4.1916, -3.3994],
[-11.9641, 4.3714, -2.5728, ..., -4.5918, 0.2353, -1.9963],
...,
[ -9.9326, -8.3047, -12.9756, ..., -5.7134, 12.7981, -8.2065],
[ -9.8994, -8.2996, -13.6337, ..., 0.1135, 12.7336, -8.2202],
[ -9.7145, -0.6672, -12.9155, ..., -5.7244, 12.8760, -8.1519]],
[[ -3.7198, 1.2760, -3.5933, ..., -4.8444, 4.7165, -5.4366],
[ -0.0161, 2.6363, -1.8160, ..., -1.1275, 3.7269, -2.8670],
[ 0.0800, 3.8032, -0.1034, ..., -1.9010, 1.3917, -3.0669],
...,
[ -9.6426, -8.1642, -13.6431, ..., -6.0016, 12.7671, -8.3592],
[ -9.6984, -8.1595, -13.1149, ..., -6.0114, 12.7185, -8.3549],
[ -9.6625, -8.0812, -13.1198, ..., -6.0365, 12.7020, -8.2902]],
[[ -5.7886, 1.3010, -3.4402, ..., -3.9976, 12.0589, 1.7659],
[ -6.8290, 1.5354, -4.4869, ..., -4.4033, 11.0707, 1.5978],
[ -6.7460, 0.8011, -3.4777, ..., -3.5240, 11.3933, 1.4383],
...,
[ -9.2554, -7.4362, -13.6181, ..., 0.1542, 0.0598, -8.3539],
[ -9.4399, -7.4798, -13.6437, ..., -5.8081, 12.7918, -8.1860],
[ -9.1668, -7.5268, -13.6582, ..., -5.9279, 12.7876, -0.4867]]],
device='cuda:0', grad_fn=<AddBackward0>)
���Կ�������convolution֮������ά��δ�����ı�,���ݴ�С�ھ������ξ������������������˸ı�
4���ܽ�
����ΪConformer��Ϊencoder�ṹ��WeNet�е�ʹ��,wenet������ṹ��conformer����һ��,��������������������ݳ��Ȳ��ȵ�����,����ڴ�������ʱ������mask�IJ���,maskҲ�Ǻ���Ҫ��,������Խ�ϴ�����в鿴��
��С������:Conformer�ṹ�������ܴ�,δ�����Կ��Ƕ�conformer�е�Multi-Head Self Attention Module��Convolution Module���ֽ����Ż�,���ٲ������Լ�Сģ�ʹ�С��
�Ż�ģ��Ч��:confomerblock�нṹ��Ϊǰ��Layernorm���Dropout,�Ҵ��вв�����,δ���ɿ��ǶԲв����ӽ�����,�ܲ������ʶ��ȷ��?���߶���loss����,�Ƿ��б�ĸĽ�?
���wenet�е�Conformer���кܶ���ԸĽ��ĵط�,�ڴ��������һ�����ۡ�