��ΪInterspeech2022�����»,Զ��˵������֤��ս�� (FFSVC)?����ɽ�ſ˴�ѧ���¼��¹�����ѧ���ϼ��ݴ�ѧ��ϣ������������֯,��Ҫ��ע������ս�Ե�Զ��˵����ȷ������2020��ٰ�ĵ�һ��FFSVC������Ҫ��ע��ͨ������˵����ȷ������ [1]������ڶ���FFSVC����[2]������ͨ��˵����ȷ�ϵĿ�������,�����Ϊ��������,����һ��Ҫ��ע��ȫ�ල��˵����ȷ��,��������ʹ��VoxCeleb��FFSVC��������Ϊѵ����;�����������ල������Զ��˵����ȷ��,������˵ֻ������VoxCeleb���ݵ�˵���˱�ǩ,������ʹ��FFSVC���ݵ�˵���˱�ǩ��������ַΪ:https://ffsvc.github.io/��
���Ľ�������������Ƶ���������Դ����о����뻪Ϊ�ƺ����ύ��FFSVC2022�ϵ�˵����ȷ��ϵͳ��FFSVC2022����ս����Ҫ��������������:(1) ��������ֻ����ʹ��VoxCeleb����[3],VoxCeleb��һ���������ʵ�����ɼ���Ӣ������,����������FFSVC����Ӣ���ӵ���˷����С�IPhone��IPAD¼�Ƶ�����,����ζ��������ѵ��������������ѵ����֮��������֡��������豸����ƥ������;(2)���Լ���ע��Ͳ��Դ���ͬ�Ա𡢿����֡����豸����������ƥ�����⡣
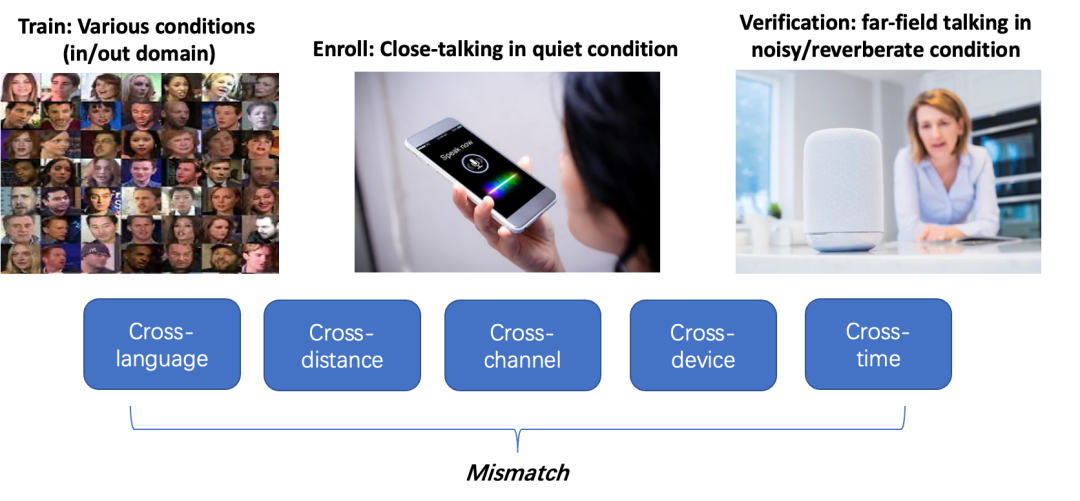
ͼ1 ˵����ȷ�������ж�����ƥ������
Ϊ�˽����������,���������һ������Ǩ��ѧϰ�����������˵,�ڵ�һ��,���Dz���˵���˸�֪Ȩ��Ǩ�Ʒ���,ʹ�� FFSVC ���ݼ��� VoxCeleb ���ݼ���һ���ֶ�Ԥѵ��������ģ�ͽ�������˵���˸�֪��ͨ�� VoxCeleb Ԥѵ��������ģ���������� FFSVC ���ݵķ���ȷ������õ�,Ŀ����������ģ���б�����ǿ���˵���������������ڵڶ���,������ʦ��ѧϰ�����ʹ��˵��������Ǩ��ѧϰ������ѧϰ�����˵���˱����ռ䡣������˵,��������ѵ���Ľ�ʦģ�͵�˵���˱����ռ���ʹ�� FFSVC ���ݽ���ѵ���ڼ�ָ��ѧ��ģ�͵�ѧϰ������,���Dz���ģ����(model soup)������ƽ�����ģ�͵�Ȩ�ء�����Ӧ�ԳƷ�����һ�� (as-norm) �Լ������ں�����ģ�����ܡ��ۺ���������,�ύϵͳ(NPU-HC)�ڴ˴ξ�����ȡ����˫�����ڶ���������ɼ���

ͼ2?������֤��
??������Ŀ:NPU-HC Speaker Verification System for Far-field Speaker Verification Challenge 2022
??�����б�:����, ��Խ, ������, ����, л��
??������ַ:https://ffsvc.github.io/assets/pdf/npu_22.pdf

ͼ3?���Ľ�ͼ
1����������
������,��������������˵����ȷ�ϼ�������Կɿس�����ȡ����Խ�����ܡ�������ʵ��Ӧ�ó�����,���ڲ��ɿصĻ��������������豸����������������Զ������˥�������������졢����ע����Զ����֤����ƥ�䡢����ѵ��������Զ���������ݲ�ƥ��(domain mismatch)�����ⶼ�ᵼ��˵����ȷ��ϵͳ���ܵĴ�����½�������������,��������ǰ�����˵����ȷ���н�����Զ���Ķ�㼶Ǩ��ѧϰ�����Ļ�����,���ǽ�һ������,��������ε�Ǩ��ѧϰ���,�ÿ�ܲ�������ע�������Ͳ�������֮�����ƥ������,������������Զ����������ѵ����������������ݼ�֮��IJ�ƥ�����⡣�������,��һ���ǽ���������VoxCelebѵ����ģ��Ǩ�Ƶ���������FFSVC��,�ڶ������ڽ�ʦ-ѧ�� (teacher-student) �����,���ø������Ľ�������˵���˱�������Զ������˵���˱�����ѧϰ��
2������Ǩ��ѧϰ
����Ǩ��ѧϰ������ͼ5��ʾ���ڵ�һ��,����ʹ��������������һ���� IPhone¼�Ƶ������ϱ������õĽ�ʦģ�͡�����������,���Dz���˵���˸�֪Ȩ��Ǩ����ʧ������˵����Ƕ����ȡ����������˵,����ģ����������Ĵ���˵�������ݼ�VoxCelebѵ����,����������������������ѵ����ģ��ʱ,���ǵ�Ŀ���DZ�����ǿ���˵����ʶ������,�����ֲ�����ϵ���������������,������������˵���˸�֪��Ȩ��Ǩ����ʧ��ʵ��ģ�ͷ���ͬʱ��ֹ�����������ڵڶ���,����ʹ��˵��������Ǩ��ѧϰ������ӳ�����Խ�ʦģ�ͺ�ѧ��ģ�͵�˵���˱��������ǸĽ���֮ǰ�Ķ༶Ǩ��ѧϰ����[4],�ڽ�ʦ-ѧ��Ǩ��ѧϰ�����,��ʦģ���ɵ�һ��ѵ��������ģ�ͳ�ʼ��,��ͨ������(iPhone¼��)���������������Ļ���˵���˱����ȵ���˵���˱������б���������³��,�������ǶԽ������ݾ������õ�˵����ʶ������������ͨ������˵���˱�ǩƽ�����˵����Ƕ��� iPhone ����������˵��������Ƕ��ռ䡣����ʹ�����Խ�ʦģ�͵�˵����Ƕ��ռ���ָ��ѧ��ģ��ѧϰ,�����˵��������ת����ʧ��
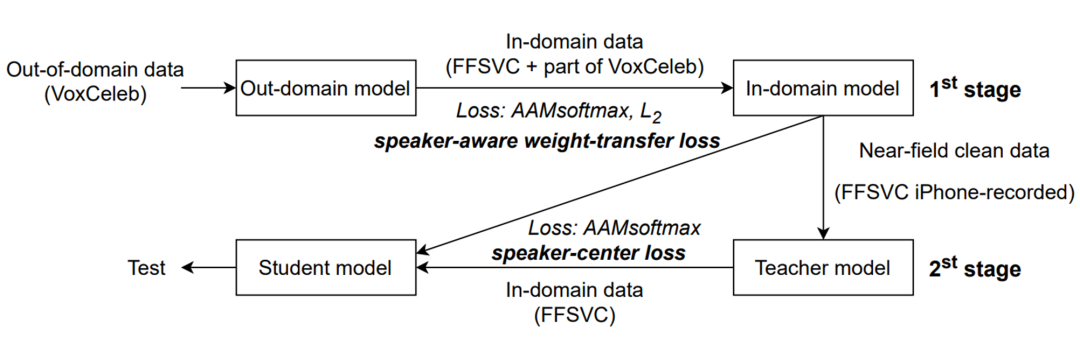
ͼ5?����Ǩ��ѧϰ����������
˵���˸�֪Ȩ��Ǩ��
�ڵ�һ��,˵���˸�֪��Ȩ�ش�����ʧ������Ԥѵ��ģ�ͺ���ģ�͵�Ȩ��֮��ľ��롣����ʧ����˵���˷�����ʧ AAMSoftmax [5]��Ȩ�ش�����ʧ�ͳ��õ� L2 ������ʧ��
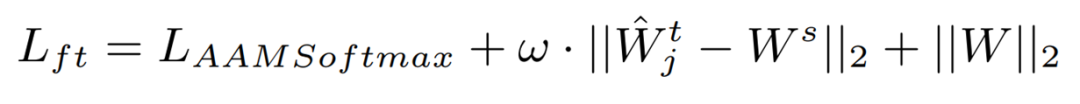
�� ��˵���߸�֪Ȩ��,��ʾÿ���о����˲����Ŀ�ת�Ƴ̶ȡ�����,������VoxCeleb Ԥѵ��������ģ��,�������һ��������滻Ϊһ���²�,�ò�Ľڵ������� FFSVC ���ݼ���˵���˵�����,Ȼ������ֻ�� FFSVC����ѵ���µķ���㡣����ʹ�����ģ��������ÿһ����ÿ�������˲�����˵���˷���ȷ�ȵ�Ӱ�졣������˵,�������ζ�ÿ�������˵IJ�����������,������������ʧ������֮ǰ����ʧ�����IJ�ֵ�����,���ֲ�������˾����˵����� FFSVC ���ݵĿ�Ǩ���ԵĴ�С����ͨ�� softmax ������һ����һ��,����˵���˸�֪�����.
���Ļ�˵���˱���Ǩ��
Ϊ�˻���ע��-���Բ�ƥ�� (���������еĿ��ŵ�������롢��ʱ�䲻ƥ��), ������������Ļ�˵���˱���Ǩ�Ʒ�������������������:
��һ��:ͨ����ʦģ����ȡ iPhone ¼��������˵����Ƕ��,Ȼ�����˵���˱�ǩ������˵����Ƕ�����ƽ��,�õ�ÿ��˵���˵�˵�������ġ�
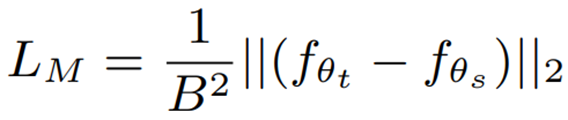
�ڶ���:�������Խ�ʦ��ѧ��ģ�͵�˵���˱���֮��� MSE �ͽǶȾ�����ʧ

����L_M �� MSE ������ʧ,L_A �ǽǶ���ʧ,�ֱ�Ϊ:
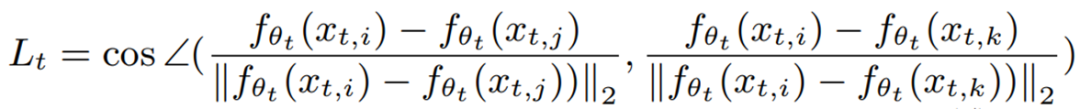

3���ںϷ���
Ϊ�˽�һ����������˵����ȷ��ϵͳ������,���Dz����������ںϷ���,ģ����(model soup)�ںϺͷ����ں�,�����ڷ����ں�֮ǰ��������Ӧ�Գƹ�һ����
ģ���ں�
ģ������һ����Ч��ģ���ںϲ���[6],����ģ�͵��ں���ͨ����ģ�͵�Ȩ�ؽ���ƽ�����������ÿ����������������ɵġ�����ڴ˴���ս����,���Dz���̰�����������ģ���ںϵ����ܡ�������˵,����ѵ�������е�ÿ�����͵�������ģ��,��������Կ�������ʵ���а��� minDCF �Ľ����ģ�ͽ�������,��ѡ��ǰ 5 ��ģ�ͽ����ںϡ�Ȼ��ͨ�����ǰ5��ģ���е�ÿ��ģ������Ϊ���е�DZ�ڳɷ�������̰����,����������ڿ������ϵ����ܱ����������,���Ǽ�������ģ�������С����ս��������е�ģ�Ͳ������ֵ�õ�����ںϺõ�ģ�͡�
�����ں�
�ڷ����ں�ǰ,���Dz���������Ӧ�Գƹ�һ��[7]��֮�����Ǹ���ģ���ڿ������ϵ�Ч������Ȩ��,����ѡģ�͵ķ����ں���һ��
4��ʵ��
ʵ������
���ݼ����õ���VoxCeleb��FFSVC 2020 & 2022����˴�ַ�ʽ�����Ҿ��롣��FFSVC2022������,���ǰ��ձ� 1 ��ģ������ѵ�����ĸ�ģ�͡�
��1 ģ������
| ģ������ | �������� |
| ECAPA_TDNN (1024) [8] | ֡������������ 1024 ��ͨ�� �ػ�����ע����ͳ�Ƴػ�(ASP) [10] �����ڶ����˵���˱�����СΪ 192 |
| ECAPA_TDNN (2048) | ֡������������ 2048 ��ͨ�� �ػ�����ע����ͳ�Ƴػ�(ASP) �����ڶ����˵���˱�����СΪ 256 |
| ResNet34SE (256) [9] | ֡������������ 1024 ��ͨ�� �ػ�����ע������ͳ�Ƴػ�(SAP) [11] �����ڶ����˵���˱�����СΪ 192 |
| ResNet34SE (512) | �в���ͨ������Ϊ {64, 128, 256, 512} �ػ�������ע�����ػ�(SAP) �����ڶ����˵���˱�����СΪ 512 |
ʵ����
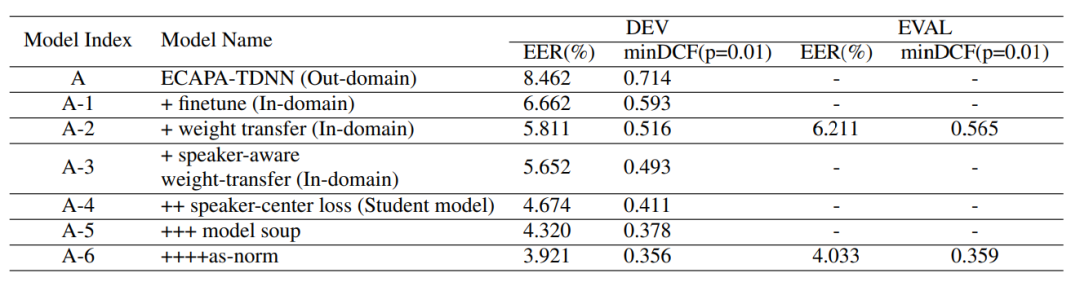
���������� ECAPA-TDNN (1024) ģ������֤���������������Ч��,����ܽ��ڱ� 2 ���ӱ�2 �е�����ʵ�������Կ���,��������ĸ��ַ����ڿ�����(DEV)�Ͼ�ȡ�����������档�������еķ���,ECAPA-TNDD (1024)�����ڿ������ϵ���� EER/minDCF �ֱ�Ϊ 3.921%/0.356 �� 4.033%/0.359��
��2 ����ķ���������һ�Ŀ����Ͳ��Լ��ϵ�Ч��,˵���˱�����ȡģ����ECAPA-TDNN (1024)
֮��,���ǽ�����ķ���(ʹ�����з���)Ӧ���� ECAPA-TDNN (2048)��ResNet34SE-256 �� ResNet34SE512��ʵ������� 3 ��ʾ�����ǿ��Կ���,��õĵ�һģ���� ECAPA-TDNN (2048),��������(EVAL)�ϵ� EER/minDCF Ϊ 3.708%/0.339���ں����� ECAPA-TDNN (1024)��ECAPATDNN (2048)��ResNet34SE-256 �� ResNet34SE-512 �ķ�����,���յ� EER �� minDCF ���������Ϸֱ�Ϊ 3.470% �� 0.319,��Ϊ�����ύ������һ�����շ�����
��3?����ķ���������һ�Ŀ����Ͳ��Լ��ϵ�Ч��,������ͬģ�ͺ�ģ���ںϵĽ��

����������,��������ʹ�� k-means [12] ����α˵���˱�ǩ,Ȼ��ʹ�ÿ�����Ⱥ���ĵĸ����ŶȻ�����������ģ�͡��ڵõ�����ģ�ͺ�,���Ǵ�����ģ����ѡ��ÿ��˵���˵�ʮ��������ȷ������ʵľ��������˵��������Ƕ��ռ䡣���,˵��������Ƕ��ռ�����ָ��ʹ�� FFSVC ���ݼ�����ѧ��ģ��ѵ�����������Ľ����� 4 ��ʾ�����Կ���,�ں����� ECAPA-TDNN (2048) �� ResNet34SE (512) �ķ����������� EER/minDCF ( 5.342%/0.545),��������ϵͳ���������ϵ����շ�����
��4 ����ķ������������ϵı���

5������
���������� NPU-HC �Ŷ��ύ�� FFSVC2022 ��ϵͳ���ھ�����,���������һ������Ǩ��ѧϰ�����������ƥ�����⡣������˵,����˵���˸�֪Ȩ��ת�������ѵ�����ݲ�ƥ������,���û���˵��������Ǩ����ʧ�Ľ�ʦ-ѧ����������ע��-���Բ�ƥ�����⡣ʵ��֤���������������Ǩ��ѧϰ��������Ч�ԡ�����,ģ�����ںϺ�����Ӧ�ԳƷ�����һ����ϵͳ��������Ҳ�а�����ͨ����������,����ϵͳ���������е� EER/minDCF ����������һ���������Ϸֱ�Ϊ 3.470%/0.319 �� 5.342%/0.545,���ջ����˫�����ڶ����ijɼ���
6�������
[1] Xiaoyi Qin , Ming Li , Hui Bu , Rohan Kumar Das, Wei Rao, Shrikanth Narayanan , Haizhou Li. "The FFSVC2020 evaluation plan." INTERSPEECH (2020).
[2] Xiaoyi Qin, Ming Li, Hui Bu, Shrikanth Narayanan, Haizhou Li . "Far-field Speaker Verification Challenge (FFSVC) 2022: Challenge Evaluation Plan." ?INTERSPEECH (2022).
[3] Nagrani, Arsha, Joon Son Chung, and Andrew Zisserman. "Voxceleb: a large-scale speaker identification dataset." INTERSPEECH (2017).
[4] Li Zhang, Q Wang, Kong Aik Lee, Lei Xie, Haizhou Li. "Multi-level transfer learning from near-field to far-field speaker verification." INTERSPEECH (2021).
[5] Yi Liu, Liang He, Jia Liu, ��Large Margin Softmax Loss for Speaker Verification,��INTERSPEECH, 2019, pp. 2873�C2877.
[6] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, Ludwig Schmidt., ��Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,�� PMLR, 2022.
[7] Pavel Matejka, Ondrej Novotny, Oldrich Plchot, Lukas Burget, Mireia Diez Sanchez, Jan ��Honza�� ?Cernocky, ��Analysis of score normalization in multilingual ` speaker recognition.�� INTERSPEECH , 2017, pp.
[8] Desplanques, Brecht, Jenthe Thienpondt, and Kris Demuynck. "ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification." INTERSPEECH (2020).
[9] Hee Soo Heo, Bong-Jin Lee, Jaesung Huh, Joon Son Chung. "Clova baseline system for the voxceleb speaker recognition challenge 2020." INTERSPEECH (2020).
[10] K. Okabe, T. Koshinaka, and K. Shinoda, ��Attentive Statistics Pooling for Deep Speaker Embedding,�� ?INTERSPEECH. 2018.
[11] Weicheng Cai, Jinkun Chen and Ming Li, ��Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System,�� Odyssey 2018, 2018, pp. 74�C81.
[12] K. Krishna and M. N. Murty, ��Genetic k-means algorithm,�� IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 29, no. 3, pp. 433�C439, 1999.