论文题目(Title):Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling
研究问题(Question):任务和预训练领域之间的不连续以及模态的信息之间的不连续引入端到端finetune所带来的计算量过大的问题。
研究动机(Motivation):上述问题并非是一个新的问题,关于如何用更少的内存进行时序建模在action classification领域已经有了很久的研究历史,在近两年仍有新的建模方法被不断提出,有研究的空间。
主要贡献(Contribution):作者提出了一个通用框架CLIPBERT,该框架通过使用稀疏采样,在每个训练步骤中只使用一个或几个稀疏采样的视频短片段,从而为视频和语言任务提供了负担得起的端到端学习。
文章验证了科学假设:
1、因为连续的片段通常含有来自连续场景的相似语义,所以稀疏采样的clips已经蕴含了视频中的关键视觉和语义信息,因此少量的clip就足以代替整个视频用来训练。
2、pre-traning中使用image-text的数据集学习到的也可以在video-text的任务中起到作用。
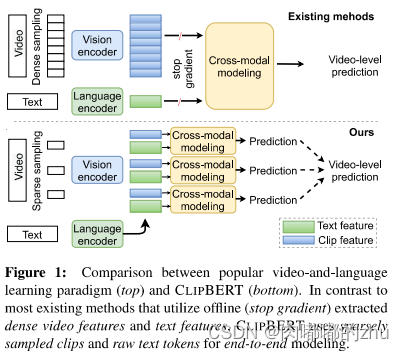
研究思路(Idea):首先从预先训练的视觉模型中提取视频特征,并从预先训练的语言模型中提取文本特征,然后应用多模态融合在共享的嵌入空间中将这些固定的表示形式组合在一起。之后分别进行预测,并将各自预测结果结合起来。
研究方法(Method):
?
一个视频V我们可以把它分成N个clips即[c_1.....c_n],那么以往的范式可以写作,
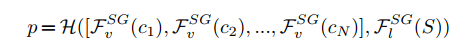
下标是v的代表视频的特征,l代表text的特征,SG是stop gradient的缩写,表示我们用的都是预训练模型,H是一个学习两种模态间相似度的模块,那给定一个ground truth的话,损失函数就可以写成如下形式了。

在本文中,作者把SG去掉了(也就是端到端的意思)

对于它这个稀疏采样的可行性,作者认为它是一种数据增强的手段,视频中不同clips的帧用于训练的话就和图片训练时的random cropping一样。(这里蕴含了一个假设,这个帧/clip是能代表整个视频信息的,事实上我们都知道这个假设是不可能的。)
?研究过程(Process):
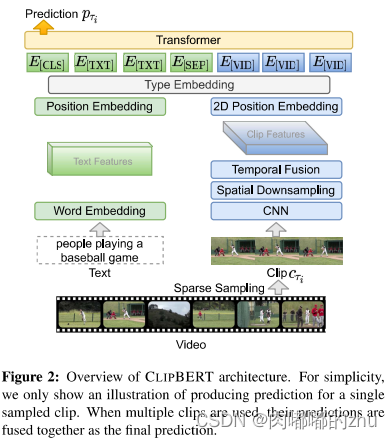
图片特征提取部分是folling pixel-Bert的,文本特征提取用的是 BERT-base model,获得文本和视频特征后,加入类型embedding和position embedding 送到一个12层的transformer中学习cross-modal fusion。
实验设计了消融部分:
对稀疏采样的分析:image size对实验结果的影响、采样帧数对实验结果的影响、clips对训练、推断两阶段实验结果的影响
系统级别与其他state-of-the-art模型的比较
对端到端和预训练的分析
? ? ? ? 1.数据集(Dataset):MSRVTT、DiDeMo、ActivityNet Captions
? ? ? ? 2.评估指标(Evaluation):准确度(ACC)
? ? ? ? 3.实验结果(Result)
? ? ? ? ? ? a.性能会随着image-size的提升而提升;
? ? ? ? ? ? b.更多的clip可以带来性能的提升,但是会随着数量逐渐饱和;
? ? ? ? ? ? c.比较了Mean pooling、Max-pooling以及LogSumExp之间的性能,LogSumExp性能较? ? ? ? ? ? ? ? ? ? ?好,更多的clips带来更好的性能提升;
? ? ? ? ? ? d.密集均匀采样和随机稀疏采样对比:随即稀疏采样4帧时性能已经和均匀采样16帧性能相? ? ? ? ? ? ? ? ?似了;
? ? ? ? ? ? e.端到端训练实验:不进行端到端训练时为8.0,仅训练语言模型提升到9.0,联合训练视? ? ? ? ? ? ? ? ? ?觉与语言提升到10.2(缺少只训练视觉模型的实验);
? ? ? ? ? ? ?f.预训练权重:预训练的比较好的2DCNN可以有效提升视频检索的性能。
总结(Conclusion):本文探讨了运用稀疏采样进行端到端学习的可能性,并证明了端到端训练可以对模型带来的提升。实验部分有缺失,不足以证明可以用随机采样的帧来替换视频是可行的。后续可研究方向:探索大规模预训练模型中对视频时序建模的方法(动作分类方法迁移)。