ЧАЧщЛиЙЫ
дкжЎЧА,ЮввбОгаНщЩмЙ§КСУзВЈРзДядк2DЪгОѕШЮЮёЩЯЕФвЛаЉОЕфЭјТч[здЖЏМнЪЛжаРзДягыЯрЛњШкКЯЕФФПБъМьВтЙЄзї(ЖрФЃЬЌФПБъМьВт)ећРэ - Naca yuЕФЮФеТ - жЊКѕ],змНсИХРЈЖјбд,ЦфБОжЪЩЯЖМЪЧЖдЪгОѕШЮЮёЕФвЛжжЬсЩ§КЭИЈжњ,жївЊЕФЙЄзїдкгкШчКЮНЯКУЕидкFOVЪгНЧжаШкКЯСНжжФЃЬЌ,ЦфжаВЛЗІгаconcate\add\productСНИіФЃЬЌЕФЬиеї,ЛђепЪЙгУradarЖдЪгОѕОжВПЬиеїдіЧП,ЦфжаБШНЯжЊУћЕФЙЄзїCRFNetОГЃгУРДзїЮЊbaseline,ЦфВЂУЛгаЖдКСУзВЈетИіФЃЬЌзіЬиЪтЕФДІРэ,НіЪЧзїЮЊЪгОѕЬиеїЕФВЙГфШкШыЕНДЋЭГЕФ2DМьВтpipelineжа,ЕЋЪЧЦфЯћШкЪЕбщЬсГіСЫаэЖржЕЕФПМТЧЕФгХЛЏЗНЯђ:АќРЈдыЩљТЫГ§ЁЂBlackInетСНИі,вЛИіДњБэСЫЖдгкКСУзВЈетРргаНЯЖрдыЩљЕФЪ§ОнНјааЁАРэЯыЛЏЁБЕФдыЩљЙ§ТЫ,НсЙћЬсЩ§СЫНгНќ10ИіЕуЁЃЖўЪЧЭЈЙ§BlackInЖдгкШѕФЃЬЌ-КСУзВЈЕудЦМгДѓбЇЯАШЈжи(ЭЈЙ§ЖдбЕСЗЪБЭМЯёЕФШБЪЇ)РДЬсИпЭјТчЖдгкИпдыЩљШѕФЃЬЌЕФФтКЯФмСІвВФмЬсЕуЁЃ
дкНќаЉФъ,2DМьВтШЮЮёдкALЕФШШЖШЕнМѕ,ШЁЖјДњжЎЕФЪЧ3DШЮЮё,БЯОЙЯждкЕФЪЕМЪГЁОАвЛжБЖрЪЧЛљгк3DГЁОАЁЃЕЋЪЧдк3DМьВтЛђепЗжИюЕШШЮЮёжа,РзДяИГгшСЫвЛИіВЛвЛбљЕФНЧЩЋ,дкжЎЧАFOVЪгНЧжа,КСУзВЈЕудЦДѓЖрЮЊСЫгыFOVЬиеїШкКЯ,ЖМЪЧЭЈЙ§ЭЖгАетвЛжжЗНЗЈ,ЖјЗХЕН3DГЁОАжа,здШЛОЭгаLIdarЕФЯрЙиНЧЩЋИГгшКСУзВЈРзДя,ЯргІЕФ,КСУзВЈЕФНЧЩЋДгFOVЕНСЫBEV,ЫќЕФЯТгЮШЮЮё,вВДгИЈжњЮЊжїЕНBEVЯТЕФЗжИюЁЂЩюЖШЙРМЦЁЂЩњГЩУмМЏЕудЦЕШЁЃ
етвВЪЧЮветЦЊЮФеТЕФжиЕу,ЮФеТЕФжївЊЙЄзїЗХдкКСУзВЈНЧЩЋЕФзЊЛЛжа,Дг3DМьВтЁЂЩюЖШЙРМЦЁЂGAN(ЗЧжиЕу),ЗжИю(ЗЧжиЕу)МИИіЗНУцСаОйЮвПДЕНЕФвЛаЉЙЄзїВЂзіМђЕЅНщЩмКЭзмНс,ЭЌЪБЖдКСУзВЈЫуЗЈЕФЗЂеЙЬсГіздМКЕФвЛаЉзОМћ,гЩгкИіШЫФмСІгаЯо,ЮоЗЈЭЈЙ§вЛЦЊЮФеТОЭАбradarЕФТіТчЪсРэГіРД,ЫљвдКѓУцЛЙЛсМЬајвдИїИізгеТНкЯИЛЏ,зщГЩЯЕСаЮФеТЁЃ
НщЩмЕФЙЄзїЖМБШНЯРфУХ,КмЩйгадДТыПЊЗХ,вђДЫЖдвЛаЉЯИНкЗжЮіПЩФмВЂВЛЕНЮЛ,ЛЖгДѓМвдкЦРТлЧјЬжТл,ЬсГіздМКЕФБІЙѓвтМћ,жИе§ЮвЕФвЛаЉЦЋМћЁЃ
вЛЁЂ3D Detection
1.1 GCN:ЭМОэЛ§гУгкКСУзВЈФПБъМьВт
1.1.1 GCNгУгкКСУзВЈЕудЦ
Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data(2021 IEEE Radar Conference)
жЎЧАЮвЗЂЙ§вЛЦЊЮФеТ:гУгкКСУзВЈРзДяЕФGNN:Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data - Naca yuЕФЮФеТ - жЊКѕ
1.1.2 GCNгУгкдЪМКСУзВЈаХКХ
Graph Convolutional Networks for 3D Object Detection on Radar Data (2021 ICCVW)
НЈвщдкдФЖСетЦЊЙЄзїЧА,ЯШдФЖСвЛЦЊЙигкРзДяЪ§ОнДІРэЕФЮФеТвдСЫНтRDКЭRadarPointCloudЕФЧјБ№:
КСУзВЈРзДя:аХКХДІРэ - ЮзЦХЫўРяЕФЙЄГЬЪІЕФЮФеТ - жЊКѕ https://zhuanlan.zhihu.com/p/524371087
- Abstract:зїепНшМјGCN,ЛљгкКСУзВЈдЪМЪ§ОнRange-beam-Dropler tensorНјаа3DФПБъМьВт,ЯрБШзїепздЩшЖЈЕФbaseline(grid-based-convolutional baselineвВОЭЪЧvoxelетРрЗНЗЈ)ЬсЩ§дМ10%,ЭЌЪБзїепдкецЪЕЛЗОГЯТбщжЄФЃаЭаЇЙћ,ЯрБШгкЦфЫћФЃЬЌ,зїепЬсГіЕФЭјТчМьВтОрРыФмЙЛДяЕН20m-100m,ДѓЗљЖШЬсЩ§МьВтЗЖЮЇЁЃ
- ЭјТчНсЙЙ:
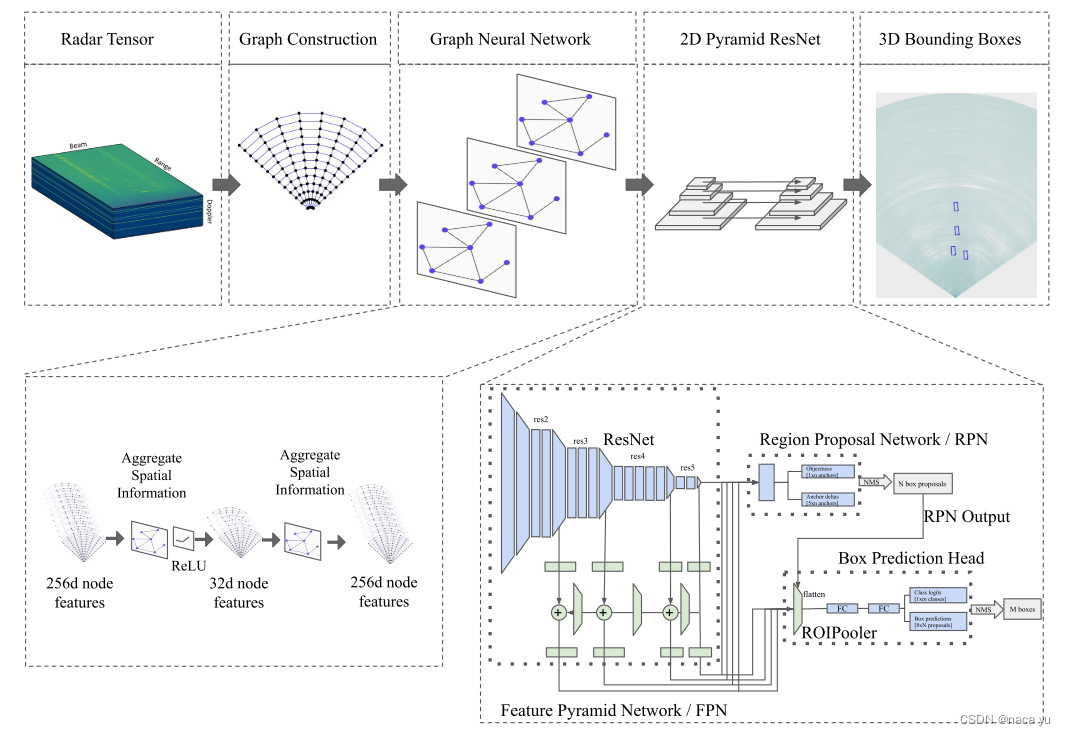
етЯюЙЄзїЕФЪфШыЪ§Он,ВЂВЛЪЧГЃМћЕФРзДяЕудЦаЮЪН,етРрЕудЦЪЧОЙ§CFARЕШЫуЗЈДІРэКѓЕФНсЙћ,етРрЫуЗЈДІРэКѓЕФНсЙћЛсЕМжТдЪМаХЯЂЖЊЪЇЕФЮЪЬт(ВПЗжЙЄзїНЋCFARИќЛЛЮЊDLФЃаЭКѓФмЙЛгааЇНЕЕЭЕудЦдыЩљ),НќЦкЕФвЛаЉЙЄзїР§ШчCRUWЪ§ОнМЏ,ЬсЙЉЕудЦЕФЩЯВуЪ§Он-Range-DopplerЪ§Он,етРрЪ§ОнФмЙЛвдНЯаЁЫ№ЪЇЕФЬѕМўЯТБЃСєНЯЖрЕФдЪМаХЯЂ,ЕЋЪЧ,ЯрЖдЕудЦдЪМЪ§ОнЮоЗЈжБНгНЋЪ§ОнгУгкМьВтЕШЯжгаШЮЮёВЂЧвЪ§ОнЕФжБЙладКЭНсЙЙЛЏНЕЕЭЁЃдкGCNжа,RDВЛФмЙЛжБНггУгкЙЙНЈGraph,зїепНЋЦфДІРэЮЊrange-beam-dopplerзјБъЯЕЯТЕФvoxelгУгкЙЙНЈНкЕу,edgeдђВЩгУСНжжЗНАИ:ИљОнНкЕуЕФОрРыШЗЖЈКЭЙЬЖЈШЈжиЁЃ - живЊВПЗж:
(1) МЋзјБъКЭЕбПЈЖћзјБъЯЕ

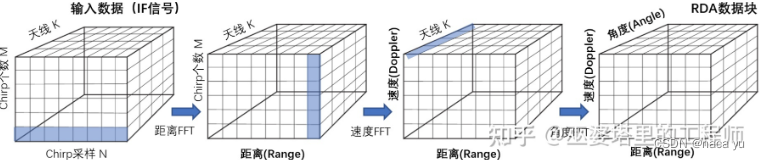
етРяМђЕЅСФвЛЯТКСУзВЈЪ§ОнЕФзЊЛЛЙ§ГЬ,ОпЬхПЩвдВЮПМ:КСУзВЈРзДя:аХКХДІРэ,ШчЩЯЭМЫљЪО,ДгзѓЕНгвОЙ§Ш§ДЮFFTБфЛЛ,ДгдЪМЕФДЋИаЦїВЩМЏЕНЕФMNKЮЌЖШЕФIFаХКХЕНзюКѓЕФRDЪ§Он,ОЭЪЧЮвУЧЫљашвЊЕФдЪМРзДяЪ§Он,ЖдRDЪ§ОнНјвЛВНДІРэ,ЕУЕНЕудЦЪ§ОнаХЯЂ,ЮвУЧашвЊЕФЪЧЩЯЭМжазюКѓвЛИіЪ§ОнЕФаЮЪНЁЃ
(2)ЭМЕФЙЙНЈ
- БпЕФЖЈвх
ЪзЯШ,Radar-Doppler-TensorзїЮЊЪфШыЪ§Он(HWC),ШЛКѓНЋЪфШыЧаЗжГЩrange-beamЮЊЕЅЮЛЕФcellзїЮЊЛљБОЕЅдЊ,УПИіcell(256 channels doppler)зїЮЊnode feature,етбљОЭЭъГЩСЫНкЕуЕФдЪМЬиеїЖЈвхЁЃЖдгкedgeЕФЖЈвхШчЯТ(ЭМЕФБпдђСЌНгЯрСкrangeЛђепЯрСкangleЕФНкЕу,БпЕФШЈжигыХЗЪНПеМфжаНкЕуОрРыГЩЗДБШ(ЪЕбщжЄУїетИіШЈжиЕФЩшжУВЂВЛживЊ):

- ЕуЕФЖЈвх
ЪзЯШ,Radar-Doppler-TensorзїЮЊЪфШыЪ§Он(HWC),ШЛКѓНЋЪфШыЧаЗжГЩrange-beamЮЊЕЅЮЛЕФcellзїЮЊЛљБОЕЅдЊ,УПИіcell(256 channels doppler)зїЮЊnode feature,етбљОЭЭъГЩСЫНкЕуЕФдЪМЬиеїЖЈвхЁЃЖдгкedgeЕФЖЈвхШчЯТ(ЭМЕФБпдђСЌНгЯрСкrangeЛђепЯрСкangleЕФНкЕу,БпЕФШЈжигыХЗЪНПеМфжаНкЕуОрРыГЩЗДБШ(ЪЕбщжЄУїетИіШЈжиЕФЩшжУВЂВЛживЊ):

4. ЪЕбщ:
ШчЯТ,зїепВЩМЏздецЪЕГЁОАЕФЪ§ОнМЏИїЯюВЮЪ§:

ШчЯТ,Ъ§ОнМЏжаЖдгкФПБъМьВтФбЖШЕФЖЈвх:ДгОрРыКЭекЕВГЬЖШСНепПМТЧ

зїепЬсГіЕФbaseline(RT-Net):НЋЩЯЪіЕФСНВуЭМОэЛ§ЭјТчЬцЛЛЮЊЦеЭЈЕФ2DОэЛ§,МЄЛюКЏЪ§ЕШЩшжУЯрЭЌ,зїепФЃФтЕФЪЧВЛЭЌgrid-based-method(voxel)КЭgraph-based-methodСНепЕФвьЭЌЁЃ

- ПЩвдПДЕН,зїепЩшжУСЫСНжжЖдБШ,GRT-NetМДзїепЬсГіЕФФЃаЭ,ЕкЖўШ§ИіФЃаЭЕФedgeШЈжиЪЧВЛЭЌЕФ(cartesian-basedКЭidentical edge weights),ЭЈЙ§12ЪЕбщЖдБШ,ПЩвдЕУЕН,graph-based-methodЕУЕНСЫШЋУцЕФадФмЬсЩ§,23ЪЕбщЖдБШ,identicalЕФedge weightsЪЧгагХЪЦЕФЁЃ

- вдЩЯНсЙћЪЧIoU=0.3ЕФЧщПіЯТ,Ш§РрбљБОЕФPRЧњЯпЁЃ

вдЩЯзїепжЛгыbaselineНјааСЫЖдБШ,ЦфЫћЕФЙЄзїжЛЪЧСаОйСЫЫћУЧЕФЪЕбщЯИНк,вВПЩвдДгетвЛНкПДГі,дкЗЧКСУзВЈЕудЦЪ§ОнЕФЙЄзїжа(ЕБШЛЕудЦЪ§ОнМЏвВШдШЛУЛгаИпЖШЙЋШЯЕФ),ЛЙУЛгаДѓВПЗжЙЄзїЖМШЯЭЌЕФЪ§ОнМЏ,ЮвВТВт:вЛЪЧВЛЭЌКСУзВЈДЋИаЦїжЎМфЕФЪєадВюБ№ДѓФбвдЭГвЛЁЂЖўЪЧКСУзВЈЕФТлЮФПЊдДЙЄзїНЯЩй,ФПЧАЮвевЕНЕФДѓВПЗжЙЄзїЖМЪЧжЛгаТлЮФ,ЯИНкУшЪіВЛЧх,вђДЫФбвдИДЯжГідБОЕФадФмЁЃШ§ЪЧПЊдДЕФДѓаЭЪ§ОнМЏНЯЩйЁЃЯЃЭћЮДРДДѓМвФмЙЛНЋздМКЕФЙЄзїПЊдД,жСЩйЫЕУїзуЙЛИДЯжЕФЯИНкЁЃ
змНс
GCNКЭVoxelСНРрЭјТчЖдБШ:дкИДдгЖШЗНУц,graph-basedЕФМЦЫуИДдгЖШгыЕудЦЪ§СПГЪЯпадЯрЙиад,Жјgrid-basedЗНЗЈМьВтадФмВЛНіЪмЕНgridДѓаЁ,ДѓСПЕФvoxelЕШгк0жЕдьГЩМЦЫузЪдДРЫЗб,ВЂЧввВЪмЕНМьВтОрРыЕФЙиЯЕЖјашвЊдкМьВтОЋЖШКЭаЇТЪжЎМфзіtrade-offЁЃдкжааФЬиеїМЦЫуЗНУц,radar pointcloudЕФЕудЦЙ§гкЯЁЪш,аэЖрЧАОАФПБъНіЭЖгАИіЮЛЪ§ЕФЕудЦ,ЭЈЙ§voxelЕШЗНЗЈЛсдьГЩЙ§ЖШНЕВЩбљКЭжааФЬиеїЖЊЪЇЁЃЕБЧАИїРрАёЕЅЩЯgrid-basedЗНЗЈФмЙЛгааЇБмУтpointЪ§СПЙ§ДѓЕМжТЕФИДдгЖШЙ§ИпЕФЮЪЬтЖјГЩЮЊжїСїГЌдНpoint-wiseЕФЗНЗЈ,ЕЋЪЧгЩгкradarЕФЯЁЪшад(NuscenesжаradarКЭlidarДѓИХЪЧ50:1ЕФЙиЯЕ),ВЩгУpoint-wiseЕФЗНЗЈВЂВЛЛсЕМжТКмДѓЕФбгГйЁЃ
RadarМьВтгХСг:гХЪЦ:СэвЛЗНУц,radarгЩгкЦфГЄВЈгХЪЦ,ЬНВтЕФОрРывВНЯДѓ,ЖдгкИпЫйЙЋТЗетРрМьВтФПБъЕЅвЛЧвЗНЯђЕШЪєадНЯЮЊЕЅвЛЕФГЁОАЯТ,radarгазХНЯДѓЕФгХЪЦЁЃСгЪЦ:гЩгкСНИіЙЄзїВЂВЛЪЧЭЌвЛЪ§ОнМЏ,ЫљвдСНепЮоЗЈКсЯђЖдБШ,ФмЙЛЕУЕНЕФМИЕуЪЧ:КСУзВЈЫљАќКЌЕФаХЯЂЪЧФмЙЛЖРСЂЕиНјаа3DМьВт,ЕЋЪЧНіЖдгкГЕСО(ПЈГЕЁЂЦћГЕЁЂНЈдьГЕСОЕШ)ДѓаЭЗДЩфадСМКУЕФФПБъНјааМьВт,ЖјЖдгкШѕЗДЩфЕФНЛЭЈФПБъдђМьВтаЇЙћНЯВюЁЃ
СНжжЪ§ОнЖдБШ:ЛљгкradarЕудЦЕФМьВтЖМЪЧашвЊдЄЖЈвхУПИіашвЊМьВтЕФРрЕФbouding boxДѓаЁ,КСУзВЈдкБцБ№ЮяЬхЪБгавЛЖЈЕФгХЪЦ,ЕЋЪЧдкЮяЬхЕФregressionШЮЮёЩЯШБЗІПЩВЮПМЕФГпДчЬиеї(НігаRCS),дкЛиЙщШЮЮёЩЯашвЊдЄЩшДѓаЁЁЃЯрБШжЎЯТ,дкRDдЪМЪ§ОнжаЯдЪОЕиДјгаСЫФПБъЕФКсНиУцЛ§ЗДЩфЧПЖШЕШаХЯЂ(Doppler),ЙЄзї2**(днЖЈУЛгадЄЩшГпДч)**ПЩвддкУЛгадЄЩшГпДчЧщПіЯТНЯКУЛиЙщФПБъЪєадЁЃЕЋЪЧ,дкИпЖШЪєадЕШЕиУцДЙжБЗНЯђЪєаддЄВтЩЯ,РзДяетжжЦНУцЪ§ОнЮоЗЈгааЇдЄВтЁЃ
1.2 Reference to Lidar
етРрЙЄзїжївЊЖдLidar BasedЗНЗЈНјааИФНј,гУгкRadarЁЃ
1.2.1 Point-wise ЕФМьВтЗНЗЈ
2D Car Detection in Radar Data with PointNets (2019 IEEE Intelligent Transportation Systems Conference)
ГіЗЂЕу: дкpoint-levelНшМјfrustum-pointnetКЭpointnetНјаа3DФПБъМьВтЁЃ

зїепЛљгкFrustum-PointnetКЭPointnetНјааСЫИФНј,ЬсГівЛжжpoint-wiseЕФ3DФПБъМьВтЭјТчЁЃ
ећИіФЃПщЗжЮЊШ§ИіВПЗж:
- ЕквЛВПЗжЛљгкЯжгаЕФradar pointsЩњГЩ2DЕФPatch Proposals,ЯрЕБгкFrustumPointnetжаЕФFrustum,гУгкОлКЯОжВПЬиеї,ЯжЖЈФГИіpatchФкВПЕФpointЕуЪ§ЮЊn,ЯрЕБгкЖдУПИіpatchФкВПЕФЕузівЛЯЕСаЕФВйзї,Patch ProposalЕФЪфШыЮЊn x 4(2D spatial data, ego motion compensated Doppler velocity and RCS information.)ЁЃ
- ЕкЖўВПЗжНЋproposalФкВПЕФЕудЦЬсШЁОжВПКЭШЋОжЬиеї,ОЙ§ЖдclutterКЭradar-targetЕФЕудЦЙ§ТЫ,ЪфГіmx4ЕФЩИбЁКѓЕФradar targetsЯђСП(гыдЪМЪ§ОнвЛжТ)ЁЃ
- зюКѓвЛВПЗж,НЋЩИбЁГіРДЕФЕуОЙ§ДЋЭГЕФT-NETКЭBox-EstimationЪфГізюКѓЕФИїЯюЪєадЁЃ
ЯТУцЪЧИќЯъЯИЕФНсЙЙЭМ:

1.3 ЖрФЃЬЌШкКЯ
1.3.1 point-wise fusionКЭobject-wise fusion(feature-level & decision level)МЏКЯгУгкЖрФЃЬЌМьВт
Bridging the View Disparity of Radar and Camera Features for Multi-modal Fusion 3D Object Detection (2021 8дТ arxiv ЧхЛЊ)
ГіЗЂЕу: дкBEVПеМф,дкpoint levelКЭobject levelСНИіВуУцЪЕЯжЭМЯёЬиеїКЭЕудЦЬиеїЕФШкКЯЁЃ
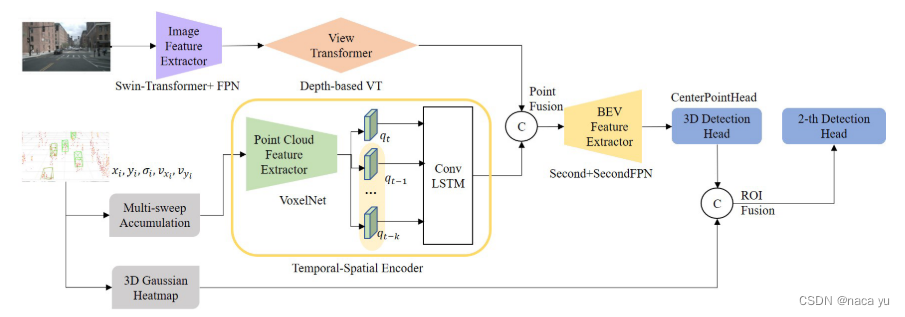
- ИУФЃаЭжївЊНтОідк3DМьВтжа,КСУзВЈКЭЯрЛњЪ§ОнЕФвьЙЙШкКЯМьВтЮЪЬт,ЬсГіСЫвЛжжPoint-fusionКЭROI fusionСНжжШкКЯВЂДцЛЅВЙЕФЯыЗЈЁЃ
- ФЃаЭМмЙЙ:
- ЭМЯёЗжжЇ:ЭЈЙ§LSSЕФЗНЗЈНЋЭМЯёЬиеїзЊЛЛЕНBEVПеМф,ВЂЭЈЙ§ConvLSTMШкКЯЖржЁЕФКСУзВЈgrid-basedЬиеїзїЮЊЪБађradarЬиеї,гыЭМЯёBEVЬиеїНјааpoint-wiseЕФconcateКѓ,ЭЈЙ§BEVЬиеїБрТыЦїЭъГЩФЃЬЌШкКЯВЂЛљгкДЫНјааheatmapЩњГЩЁЃ
- radarЗжжЇ:ЭЈЙ§ЖдradarЬиеїЭМЕФheatmapЩњГЩВЂгыЭМЯёЕФheatmapНјааШкКЯ,ЫЭШызюжеМьВтЭЗдЄВтЁЃ
- ШкКЯЗжжЇ:ВЩгУpoint-wise fusionКЭobject-wise fusionСНжжШкКЯМцЙЫЕФЗНЪНЁЃ
- ФЃаЭЯИНк:
(1) point-fusionКЭROI fusionСНжжШкКЯВЂДцЛЅВЙЕФЯыЗЈ;
(2) two-stage-fusionЗНЗЈ:СНИіФЃЬЌЗжжЇИїздЭъГЩheatmapЩњГЩКѓ,дйДЮНјааШкКЯ,дкЬиеїЯИСЃЖШКЭШЋОжаХЯЂШкКЯЩЯЖМгаПМТЧЕН,ШкКЯНсЙЙШчЯТЫљЪО:дкШкКЯжЎЧА,ВЛгУБЃГжЗжБцТЪЕФвЛжТ,дкpoint-wiseШкКЯЪБСНИіВЛЭЌЗжБцТЪЕФФЃЬЌвЊЗжБ№ОЙ§ЩЯЯТВЩбљЭГвЛКѓШкКЯЁЃ

(3) дкradarЩЯЪЙгУconv-lstmетРрЗНЗЈНјааЪБађРзДяаХЯЂШкКЯ,зїепвдДЫНтОіЕудЦЕФВПЗждыЩљЮЪЬт:дгВЈКЭЪ§ОнЯЁЪш,ЕЋЪЧУЛгаЭЈЙ§ЯћШкЪЕбщжЄУїlstmНсЙЙЕФКЯРэад;
(4) РзДяЪ§ОнДІРэ:temporal-spatial feature encoder
- УПвЛжЁЕФРзДяЕудЦЖМОЙ§зЊЛЛЕНcurrent frame,ЪфШыЕФraw radarАќКЌ:x, y, vr, RCS;
- ПеМфЬиеїЬсШЁ:ЪЙгУГЃгУЕФvoxelnetЛђепpointpillars;
- ЪБађЬиеї:ConvLSTM,ЖдПеМфЬиеїЬиеїЭМЬсШЁЪБађЬиеїЕНTemporal Encoderжа,ОпЬхНсЙЙПЩВЮПМШчЯТНсЙЙ,НЋОэЛ§КЭlstmНсКЯЦ№РД,ЪЙЕУФЃаЭЭЌЪБОпгаЬсШЁПеМфКЭЪБађЬиеїЕФФмСІ,етИідкЬьЦјдЄВтгавЛаЉгІгУ;

(5) ЭМЯёЬиеїЬсШЁ:LSS

КЭBEVDetЕФЗНЗЈвЛжТ,ЬсШЁfeature-mapКѓ,ОЙ§вЛЯЕСаЕФзЊЛЛ(lift)НЋЬиеїзЊЛЛЮЊЛљгкЪгзЖЗжВМЕФЩюЖШЬиеїЭМ,КѓЭЈЙ§poolingЕФЗНЪН(splat)ЬиеїЕНBEVПеМфЁЃ
- ЦРМлзмНс

зїепдкBEVПеМфжавдtop-downЕФаЮЪНМьВт,УЛгав§ШыЯШбщЕФФПБъГпДчаХЯЂ,ЖјЪЧЭЈЙ§жааФЕуЛиЙщЦфЫћаХЯЂЁЃ

- baselineЖдБШ:
ЯрБШЮДв§ШыЪБађаХЯЂЕФbevdet,RCBEVдкећЬхадФмЬсИпЕФЛљДЁЩЯ,дкmAVEЩЯгШЦфУїЯд,КСУзВЈРзДяЕФв§Шы,ЪБађЬиеїЕФЬсШЁЖдЭјТчЕФЫйЖШадФмЬсЩ§ЗЧГЃДѓ,ЯрБШBEVFORMERКЭBEVDET4DдЄВтЫйЖШ,ЭЈЙ§ШкКЯКСУзВЈРзДяФмЙЛдкБмУтЖржЁЭМЯёЕФМЦЫуИДдгЖШдіМгЕФЭЌЪБ,ЬсИпЫйЖШЕФдЄВтФмСІЁЃЕЋЪЧЭЈЙ§conv-lstmЕФЗНЗЈЭъГЩРзДяЪБађЬиеїЕФЬсШЁЯрЖдЦфЫћЗНЗЈВЂУЛгаЬхЯжГіЦфгХЪЦ,етИіПЩвдЖдБШФПЧАЕФcamera+radarжїСїЗНЗЈЕФmAVEРДПДЁЃ

- ФЃЬЌЯћШкЪЕбщ:
ЯрБШЧчЬь,гъЬьКСУзВЈРзДяДјРДЕФЬсЩ§ИќДѓ,вВФмжЄУїетжжШкКЯЗНЪНЕФТГАєадЁЃдкЙтееЖдБШЩЯ,АзЬьДјРДЕФЬсЩ§ИќМгУїЯд,змЬхЩЯ,БОЦЊЙЄзїШЗЪЕдкЖрИіМЋЖЫЬьЦјЯТДяЕНСЫСМКУЕФадФмЁЃ
1.3.2 гУЭМЯёЗжИюдіЧПКСУзВЈЕудЦЕФМьВтаЇЙћ
RadSegNet: A Reliable Approach to Radar Camera Fusion (2022 Фъ 8дТ)
ГіЗЂЕу: гУгявхЗжИюНсЙћфжШОЕудЦЭМ,ЖдКСУзВЈЕудЦв§ШыЭМЯёгявхаХЯЂгУгк3DМьВтЁЃ
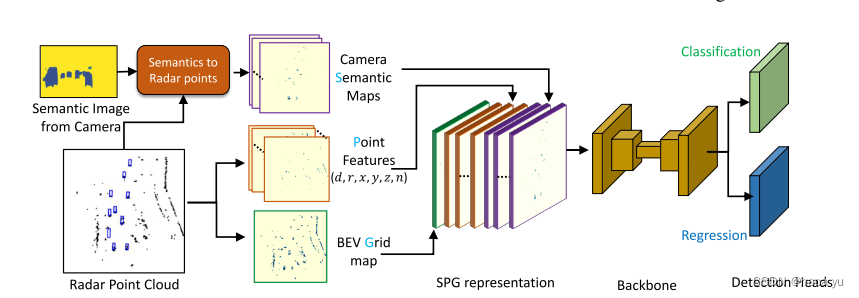
- ФЃаЭМмЙЙ:
етРяШкКЯЕФЗНЪНВЂВЛИДдг,вђДЫВЛзіЙ§ЖрНщЩм,етЦЊЮФТлЕФОЋВЪжЎДІЮвШЯЮЊдкгкSPG representationЕФЧАУц:
РрБШгыpointpaintingЕФЗНЪН,НЋРзДяЕудЦИГгшгявхаХЯЂ(ЭМЯёОЙ§pretrained maskrcnnЕФЗжИюКѓЕФШЋОАЗжИюЭМЯё),ЩњГЩsemantic mapгУгкфжШОЭЖгАЕНFOVКѓЖдгІЕФКСУзВЈЕудЦ,ШЛКѓЗжБ№гыЖдгІЕФЕудЦЕФЬиеїКЭBEV occupy mapНјааЕўМг,ЕНДЫЭъГЩЬиеїЕФЖдЦыКЭВЛЭЌЬиеїЯђСПЕФЕўМгЁЃКѓРћгУUNetЭјТчЬсШЁЖрГпЖШЬиеї,ЗжБ№ЫЭШыЗжРрКЭЛиЙщМьВтЭЗЁЃ
-
ФЃаЭЯИНк:
(1) ЕудЦфжШО

ЭЈЙ§ЖдБШ,ПЩвдПДГідкгявхЭЈЕРжа,КСУзВЈЭЈЙ§гявхЗжИюфжШОКѓЕФЕудЦДјгаЭМЯёБОЩэЕФгявхаХЯЂ,ФмЙЛжБЙлЗДгГСЫЦфФмЙЛУжВЙКСУзВЈШБЩйРрБ№ЬиеїЕФСгЪЦЁЃ(2)МьВтЭЗ

- зюКѓСНИіМьВтЭЗЗжБ№дЄВтNC128128вВОЭЪЧNИіanchorЕФРрБ№,ЖјСэвЛИіЪфГіЮЊ7N128128,7ЮЊУПИіanchorЕФЪєад,АќРЈx, y, z, w, h, l, thetaет7ИіЪєадЁЃ
(3)ЬьЦјФЃФт
зїепЪЙгУЭМЯёдіЧППтФЃФтдіМгМЋЖЫЬьЦј:ДѓЮэЁЂДѓбЉЕШЬьЦј,ПЩвдПижЦбЉЛЈДѓаЁЁЂЯТНЕЫйЖШЕШВЮЪ§ФЃФтецЪЕЛЗОГЁЃ
(4)ФЃаЭЪфШы:- ЗжЮЊBEV occupy grid, RadarPoint Feature, Semantic Maps,ЙВМЦ22 dims,дкЪфШыФЃаЭЧАШЋВПЭЈЙ§concateЭъГЩgrid-levelЕФЬиеїЖдЦыЁЃ
- зїепНЋЕудЦИёЪНЛЏЮЊgrid-based feature map,ШчЙћЖрИіЕуЭЖгАЕНЭЌвЛgrid,ФЧУДОЭМЦЫуЦНОљжЕ,ЭЌЪБyЩшжУЮЊ7ИіchannelДњБэВЛЭЌЕФИпЖШ,УжВЙКСУзВЈРзДяВЛКЌгаИпЖШаХЯЂЕФШБЕу,nБэЪОЕудЦЭЖгАЕНgridЕФИіЪ§ЁЃЪ§ОнгЩI(u,v)ЮЊ0ЁЂ1ДњБэЪЧЗёЮЊПе,d,rДњБэdroplerКЭintensityЁЃ

-
ЗжЮізмНс

зїепдкAstyx datasetЪ§ОнМЏЭъГЩбЕСЗШЮЮё,дкRADIATEНјааВтЪдЁЃRADIATEЯрБШбЕСЗЕФЪ§ОнМЏ,МЋЖЫЛЗОГЕФеМБШИќЖр,ЖдФЃаЭЕФТГАєадвЊЧѓИќИпЁЃ
(1)дкAstyxЪ§ОнМЏЖдБШжа:baselineбЁШЁPerspective-view-basedЗНЗЈЕБЪБЕФSOTA-CenterfusionНјааБШНЯ,ЮЊСЫБЃГжЙЋЦН,НЋдЄбЕСЗЕФcenternetЮЂЕїЕНаТЪ§ОнМЏжа,ЪЕбщНсЙћвВжЄУїЮЂЕїКѓЕФЭјТчБШfrom-scratchЕФcenternetЭјТчБэЯжИќКУ,зїепЛљгкДЫЖдcenternetНјааСЫЮЂЕїВЂгУгкcenterfusionЁЃcenterfusionадФмЯТНЕКмЖр,ЕЋЪЧзїепУЛгаИјГізуЙЛЕФЯИНк,ЮвФмЭЦВтГіРДЕФ:RadSegNetдкBEVЯТ3DМьВтЕФНсЙћгыCenterfusionЕФFOVМьВтНсЙћЯрБШНЯЁЃ
(2)зїепЪЙгУsegmentationКѓЕФНсЙћфжШОpoint,ЫљвдШкКЯЕФаЇЙћбЯживРРЕгкЗжИюЕФаЇЙћ,дкМЋЖЫЬьЦјЯТЕФЗжИюаЇЙћШчЯТЭМЫљЪО,ЕудЦЕФгявхЬиеїЛсбЯжиЭЫЛЏ;

(3) lidar vs radar


зїепНЋpointcloudЛЛГЩlidarНјааСЫЖдБШЪдбщ,ПЩвдПДГі,дкНќДІМЄЙтРзДяЕФаЇЙћвЊгХгкКСУзВЈ,дкдЖДІЗЂЩњСЫФПБъЕФжиЕўВЂЧвlidarЕудЦЕФУмЖШМБОчЯТНЕ,зїепМЦЫуСЫВЛЭЌЕФИажЊОрРыЩЯЯоЯТадФмЕФБфЛЏ,ПЩвдПДГіradarдкдЖОрРыМьВтЕФгХдНадЁЃКСУзВЈзїЮЊГЄВЈ,ЯрБШМЄЙтРзДя,дкДЉЭИадКЭИажЊОрРыЩЯЖМвЊИќгХ,ЕЋЪЧЭЌЪБвВЕМжТСЫКСУзВЈРзДяЕФЖрТЗОЖИЩШХЕШЮЪЬтЁЃ
(4) ЯрБШnuscenes,зїепЪЙгУЕФетСНИіВЩМЏздецЪЕГЁОАЕФЪ§ОнМЏгЩгкЦфМЋЖЫЛЗОГЕФеМБШНЯИп,вђДЫЖдгкЫуЗЈЕФТГАєадвЊЧѓИќИп,дкnuscenesЪ§ОнМЏЩЯ,ЕудЦЙ§гкЯЁЪшЭЌЪБМЋЖЫЕФЛЗОГеМБШВЂВЛИп,вђДЫдкбщжЄradarЕФТГАєадЕШзїгУЪБ,ЦфЫћОпгаГэУмЕудЦЛђепМЋЖЫЬьЦјБШР§НЯИпЕФЪ§ОнМЏвВПЩвдПМТЧ,діМгЮвУЧЕФЪЕбщбЯНїадЁЃ
ЖўЁЂDepth Estimation
2.1 КСУзВЈРзДяИЈжњЪгОѕНјааЩюЖШЙРМЦ
ЬтФП:Depth Estimation From Monocular Images and Sparse Radar Using Deep Ordinal Regression Network (ICIP,2021,ОХдТ)
зїепГіЗЂЕу: ЫцзХlidar-basedЕФЩюЖШЙРМЦЗНЗЈгУгк3DФПБъМьВт(BEVDepth),radar-basedЗНЗЈвВЭЈЙ§ИФНј,ИљОнradarЬиадЩшМЦСЫвЛаЉЩюЖШЙРМЦЕФЗНЗЈЁЃзїепНсКЯDORNЭјТчВЂНјааИФНј,в§ШыradarЗжжЇгУгкЩюЖШМьВтЁЃ
дДДњТы:https://github.com/lochenchou/DORN radar
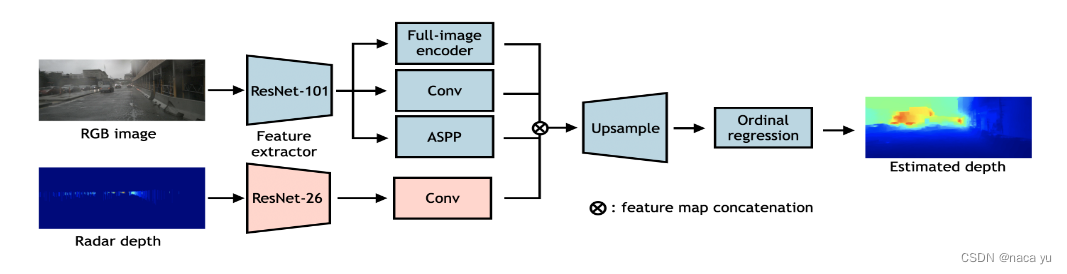
-
ЭјТчМмЙЙ:гЩЭМПЩвдПДГі,СНИіФЃЬЌдкFOVЗжБ№ЭЈЙ§resnetЬсШЁfeatureКѓ(вЊзЂвт,ДЫЪБЕФradarВЂВЛЪЧraw data,ЖјЪЧЭЈЙ§ТЫВЈКѓЕФЩюЖШжЕ),ЗжБ№ЭЈЙ§DORNЩюЖШЙРМЦЭјТчКЭЦеЭЈЕФОэЛ§НјааБрТы,ЫцКѓconcateВЂЩЯВЩбљ,зюКѓЭЈЙ§ађЪ§ЛиЙщЖдЩюЖШНјааЙРМЦ,ЦфжаРЖЩЋВПЗжгыDORNБЃГжвЛжТ,жЛЪЧНЋЩюЖШЙРМЦЮЪЬтБфГЩЗжРрЮЪЬт(ordinal regression)ЁЃећЬхНсЙЙВЂВЛИДдг,живЊЕФЪЧзїепШчКЮНЋradarгУгкЩюЖШЙРМЦЕФСїГЬЁЃ
-
жївЊДДаТЕу:вЛИіЪЧНЋЕудЦРЉеЙИпЖШБфГЩline,ЬсИпКСУзВЈЕудЦЕФ"ИаЪмвА",діЧПЩюЖШЙРМЦаЇЙћЁЃвЛИіЪЧНЋЖрФЃЬЌв§ШыЕЅФЃЬЌЩюЖШЙРМЦDORNЭјТчЁЃ
-
ФЃаЭЯИНк
(1) зїепНЋКСУзВЈРзДяЕФРЇФбЖЈвхЮЊ:ЯЁЪшЁЂдыЩљБШДѓЁЂЮоИпЖШаХЯЂ(гАЯьЕФИпЖШЗЖЮЇгаЯо),ЭЈЙ§дЄДІРэ,ЩњГЩвЛИіheight-extended multi-frame denoised radarЁЃ
(2) РзДядЄДІРэСїГЬШчЯТ:1. ИпЖШРЉеЙ,РрЫЦгкcrfnet,НЋЕудЦРЉеЙ0.25~2mЕФЗЖЮЇФк,БфГЩвЛЬѕжБЯп;2. ТЫВЈ:НЋВЛЗћКЯЩюЖШуажЕЕФКСУзВЈЕудЦТЫГ§,уажЕЖЈвхШчЯТ,ТЫВЈЙ§ГЬКЭЩњГЩradar-depthЬиеїЕФЙ§ГЬПЩВЮПМ[Depth Estimation from Monocular Images and Sparse Radar Data]ЁЃ -
змНс
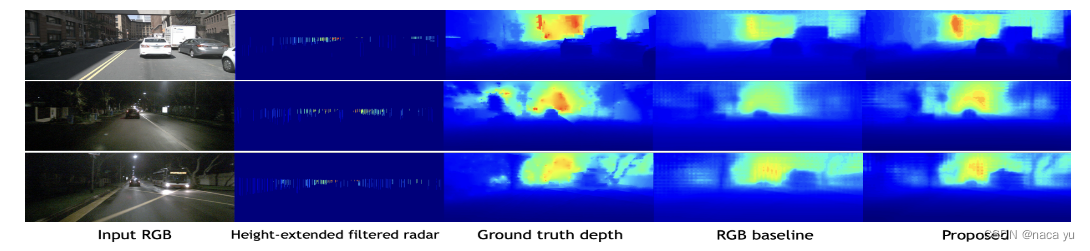
ПЩвдПДГі,ЬсГіЕФЗНЗЈБШbaselineдкЩюЖШдЄВтЩЯИќНгНќецЪЕжЕЁЃ

- ЦРМлжИБъ:
ЕквЛИіЦРМлжЕДњБэЩюЖШЙРМЦжЕКЭецЪЕжЕЕФзюДѓВювь
RMSEЪЧЦНОљЩюЖШВюжЕ
ABSRELЪЧЯрЖдЕФЦНОљЩюЖШВюжЕ

гЩЩЯЭМ,ПЩвдПДГіТЫВЈЕФгааЇад

гЩЩЯЭМПЩвдПДГідЄДІРэжаКСУзВЈИпЖШРЉеЙЕФгааЇад
Ш§ЁЂSegmentation
3.1 ЖрФЃЬЌШкКЯЕФmapЗжИю
A Simple Baseline for BEV Perception Without LiDAR(2022, MIT)
зїепЕФГіЗЂЕу: дкBEVЩЯЭЈЙ§BEVFORMERЕФЗНЪН"ЮоВЮЪ§ЛЏ"ЕиЭъГЩLiftВйзї(НЋЭМЯёЬиеїзЊЛЛЕНBEVПеМф),ШкКЯРзДяЕудЦЬиеїЭМ,гУгкЗжИюШЮЮё,адФмГЌдНСЫжЎЧАЕФЗжИюФЃаЭЁЃ
- ЭјТчНсЙЙ:
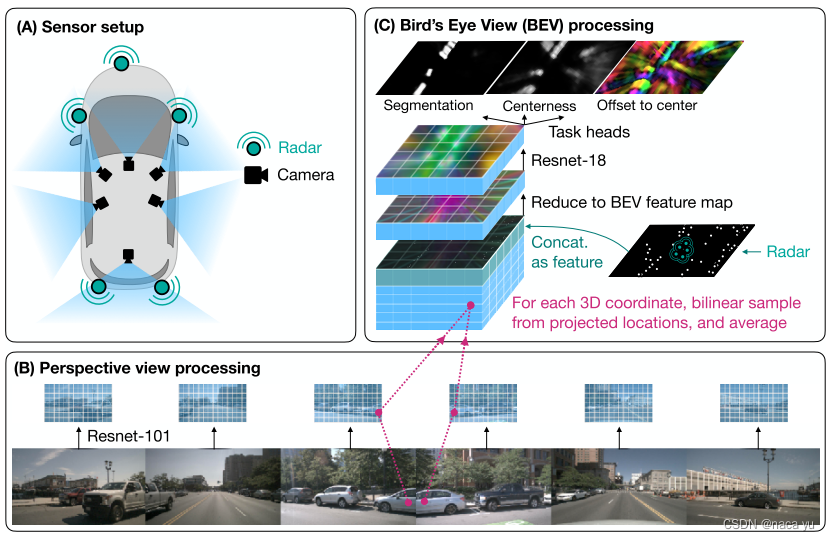
- ТлЮФШчЦфУћ,ЭјТчНсЙЙБШНЯМђЕЅ,ПЩвдПДГіКмЖрТлЮФЕФгАзг(Р§ШчBEVFORMER),зїепОЭЪЧЭЈЙ§ЯдЪНЕФBEVqueriesВЩбљЭМЯёЬиеї,ВЂЧвconcateРзДяЬиеїВЂЭЈЙ§ОэЛ§НјааФЃЬЌЖдЦыгыШкКЯ,КѓУцгУгкЗжИюШЮЮёЁЃ
- змНсЗжЮі:
-
РзДяаХЯЂДІРэ:

гЩЖрИіЬиеїЮЌЖШЙЙГЩ:0\1ЕФoccupy map,nuscenesЬсЙЉЕФЫљгаЬиеї(RCS,X,Y,Z,VЁ)зїЮЊЪфШыconcateЕНвЛЦ№зїЮЊЪфШыЬиеїЁЃМьВтЗЖЮЇЪЧ[-100, 100m],ЭјИёЕФДѓаЁЪЧ200x200ЁЃ -
адФмЬсЩ§

КЭжїСїЕФЙЄзїЯрБШ,зїепЕФШЗдкЗжИюЩЯЬсЩ§ЗЧГЃДѓ,зїепНЋетЙщЙІгкКСУзВЈЕФЙІРЭ, -
ЯћШкЪЕбщ

змНсЮЊШ§Еу:ЖдгкЗжИюШЮЮё,ЪфШыЙ§ЖрЕФЪєадЬсЩ§ВЛУїЯд(occupy onlyвбОДяЕН53),Ждmulti-pathЕФКСУзВЈРзДяЕуТЫГ§ЗДЖјЕМжТадФмЯТНЕ(втСЯжЎжа,вђЮЊmulti-pathЕФКСУзВЈЫфШЛЛсЕМжТдыЩљ,ЕЋЪЧЦфЩЈУшЕНЕФЮяЬхПЩФме§ЪЧЮЛгкБЛекЕВЕФЧјгђ),діМгsweepsЕФЪ§СПадФмвВЛсЬсЩ§(БЯОЙЕудЦУмЖШДѓСЫ)ЁЃ
ЫФЁЂDense Pointcloud Generation
4.1 GAN
4.1.1 ЭЈЙ§УмМЏЕудЦМрЖНradarЩњГЩУмМЏЕудЦ
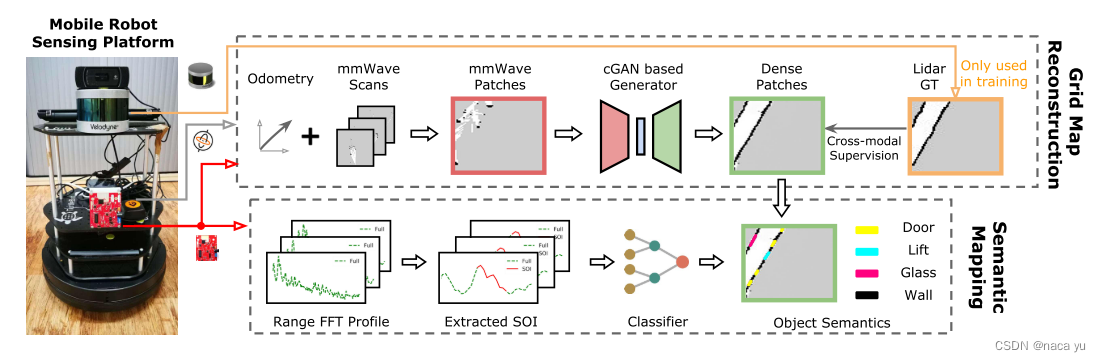
See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar (2020, ЫЙЬЙИЃ)
4.2 Lidar Supervision
4.2.1 МЄЙтРзДяЕудЦМрЖНКСУзВЈЩњГЩoccupy grid map
Radar Occupancy Prediction With Lidar Supervision While Preserving Long-Range Sensing and Penetrating Capabilities
зїепЕФГіЗЂЕу: ЭЈЙ§lidarетжжЪ§ОнжЪСПНЯИпЕФФЃЬЌ,МрЖНКСУзВЈРзДяЩњГЩжЪСПНЯИпЕФеМОнеЄИёЕиЭМ,НтОідкетИіЙ§ГЬжаЕФСНИіЮЪЬт:вЛНтОіoccupyЭјИёЩњГЩДцдкгкДЋИаЦїжЎМфЕФФкЩњадЮЪЬт:ДЋИаЦїИажЊОрРыВЛвЛ,ДЋИаЦїДЉЭИадВЛвЛЮЪЬт;ЖўНтОіГЄОрРыЭјИёЩњГЩЮЪЬт;ЩњГЩЕФoccpy grid mapПЩгУгкЯТгЮЕФТЗОЖЙцЛЎЕШЮЪЬтЁЃ
- БОЮФвЛаЉЛљБОЖЈвх:
-
МЋзјБъЯЕгыЕбПЈЖћзјБъзЊЛЏ
зїепвдЕбПЈЖћзјБъЯЕЕФx,yжааФЮЊМЋзјБъЯЕЕФжааФ,ЕбПЈЖћзјБъЯЕЕФвЛжмЕШЭЌгкМЋзјБъЯЕЕФвЛЖЮ(ШчЯТЭМЫљЪОЕФРЖЩЋКьЩЋЖдгІЙиЯЕ)

-
зїепНЋradarжаlidarЕФИажЊЧјгђЖЈЮЛtrainning-region,НЋЦфЫћЗЖЮЇФкЕФКСУзВЈЕудЦзїЮЊinferenceЕФЪфШы,ШчЯТЭМЫљЪО

-
КСУзВЈРзДядыЩљРДдД:
multipath reflection, speckle noise, receiver saturation, and ring-shaped noise -
БОЮФИїРрбеЩЋКЌвх

ЮЊСЫГЦКєЗНБу,НЋЩњГЩЕФoccupy grid mapжаЕФunitЭГГЦЮЊЕудЦ,Цфжа,ТЬЩЋДњБэФЃаЭЩњГЩЕФе§ШЗЕудЦ,КьЩЋДњБэlidarМьВтЕНЕЋЪЧФЃаЭУЛгаЩњГЩЕФЕудЦ,РЖЩЋДњБэФЃаЭЩњГЩЕЋЪЧGTВЛДцдкЕФЕудЦЁЃ
- ФЃаЭМмЙЙ:ЪЙгУДЋЭГЕФUNetЩњГЩoccupy grid map,ЪфШыЪЧBEVБэЪОЯТЕФRadarЕФЕудЦ,ЪфГіЮЊoccupy gridЁЃ
- ФЃаЭЯИНк:
-
ЮЊЪВУДдкМЋзјБъЯЕЯТМьВт?
зїепЬсЕН,CNNЖдгкГпЖШБфЛЏЕФТГАєадвЊЧПгкЖдЗНЯђаЮзДЕФТГАєадБфЛЏЁЃЯТЭМЫљЪО,дкpolar spaceжаТЗПэЯрНЯгкcartesian spaceБфЛЏИќДѓ,ЕЋЪЧcartesian spaceЕФСНВрЕудЦГіЯжСЫblurЁЃ

-
КСУзВЈЪ§ОндЄДІРэ
ПМТЧЕНетбљвЛИіЮЪЬт:КСУзВЈБОРДМьВтВЛЕНЕФФПБъ,ЪЧЗёгІИУЧПжЦЪЙЦфМьВт?
Д№АИПЯЖЈЪЧЗё,вђЮЊКСУзВЈКЭlidarЕФаджЪВювь,ЖдгкЪїФОЕШвЛаЉЗДЩфадЯрЖдНЯВюЕФФПБъ,КСУзВЈЪЧМьВтВЛЕНЕФ,ЭЌЪБradarМьВтЕНБЛекЕВЕФЮяЬх,ДЫЪБlidarгжЪЧМьВтВЛЕНЕФ,СНИіДЋИаЦїжЎМфЕФВювь,ШчЙћЧПжЦМьВт,ЛсЕМжТЯрЕБЖрЕФFPдЄВт,вђЖјЛсНЕЕЭадФм;
вђДЫ,ЭЈЙ§Ъ§ОндЄДІРэ,ЪзЯШЙ§ТЫЗДЩфЧПЖШЕЭгкФГИіуажЕЕФЕудЦ,ШЛКѓНЋlidarЬсЙЉЕФGTЪ§ОнжаradarЮоЗЈМьВтЕНЕФЪ§ОнТЫГ§,ЕУЕНбЕСЗЪ§ОнЁЃ

ШчЩЯЭМЫљЪО,гЩЪЕбщЕУЕН,ЭЈЙ§дЄДІРэ,ФЃаЭЕФFPДѓДѓНЕЕЭ; -
ШчКЮНтОіДЋИаЦїМьВтОрРыВювьЮЪЬтФи?
POLAR SLIDING WINDOW INFERENCE:НЋlidarМьВтЧјгђФкЕФЕудЦзїЮЊGTгУзїtraning region,ШЛКѓж№ВНЛЌЖЏДАПк,УПДЮДАПкЫљАќКЌЕФradarЕудЦНізїЮЊinference,ЩњГЩoccupy mapЁЃМђЕЅРДЫЕ,ОЭЪЧlidarФкЕФгаЯоЪ§ОнгУгкбЕСЗ,ЖјlidarЭтЕФradarгУгкЭЦРэЩњГЩoccupy mapВЂЦДНгЩњГЩзюжеЕФдЖОрРыoccupy mapЁЃ
СїГЬШчЯТЭМЫљЪО,етРяЕФФкЭтдВжЎМфЕФОрРыЪЧМьВтЕФЗЖЮЇ,вВОЭЪЧЛЌЖЏДАПк,бЕСЗЪЧЭЈЙ§ЖдБШВЛЭЌЕФЛЌЖЏДАПкЕФФкШнгыЭјТчдЄВтЕФЭЌаФдВжЎФкЕФМьВтНсЙћНјааЖдБШбЕСЗЁЃ
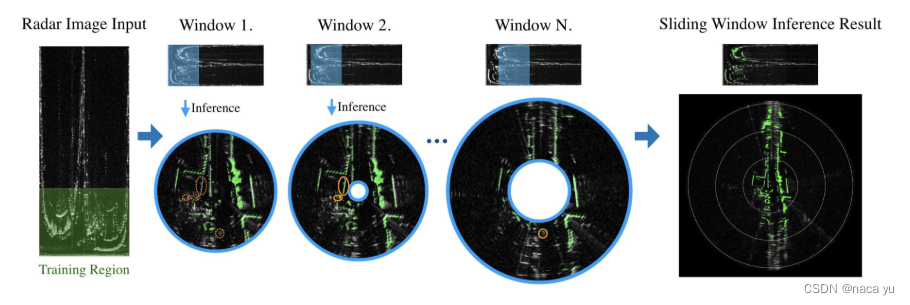
-
ШчКЮБЃГжradarЕФЭИЪгадФм?
ЭЈЙ§ЩЯУцЫљЪіЕФЛЌЖЏДАПк,ПЩвдЭъУРНтОіlidarМрЖНЪ§ОнЯТ,lidar-invisibleЕФФПБъЕЋЪЧradar-invisibleЕФФПБъЕудЦУЛгаЪфШыЖјЕМжТЕФЭИЪгадФмЩЅЪЇЮЪЬт,вђЮЊдкtДАПкВЛФмПДЕНЕФЕудЦ,ПЩвддкБ№ЕФДАПкПДЕНЁЃ
- змНс:

вдЩЯЪЧаЇЙћЭМ,ПЩвдПДЕН,дБОЕФradarЪфШыЪЧЗЧГЃЛьТвЕФ,ДјгаЗЧГЃЖрЕФдыЩљ,ЕкЖўСаЪЧбЕСЗЪ§ОнПЩвдПДЕНlidarЕФЕудЦЗЧГЃЙцдђФмЙЛЗДгГЧјгђФкБШНЯЭъећЕФМИКЮаХЯЂ,ЕкШ§СаЪЧЪфГіЕФНсЙћ,ЭЈЙ§lidarЪ§ОнЕФМрЖН,ФмЙЛдкlidarЧјгђвдЭт,ЩњГЩдыЩљНЯаЁ,ФмЙЛЗДгГТЗУцЗжВМЕФЕудЦЭМЁЃЕкЫФСаЪЧШЫЙЄБъзЂЕФGT,зюКѓЩњГЩЕФresultгыGTЯрНЯradarИќЮЊНгНќЁЃ

вдЩЯЪЧаЇЙћЭМ,ПЩвдПДЕН,дБОЕФradarЪфШыЪЧЗЧГЃЛьТвЕФ,ДјгаЗЧГЃЖрЕФдыЩљ,ЕкЖўСаЪЧбЕСЗЪ§ОнПЩвдПДЕНlidarЕФЕудЦЗЧГЃЙцдђФмЙЛЗДгГЧјгђФкБШНЯЭъећЕФМИКЮаХЯЂ,ЕкШ§СаЪЧЪфГіЕФНсЙћ,ЭЈЙ§lidarЪ§ОнЕФМрЖН,ФмЙЛдкlidarЧјгђвдЭт,ЩњГЩдыЩљНЯаЁ,ФмЙЛЗДгГТЗУцЗжВМЕФЕудЦЭМЁЃЕкЫФСаЪЧШЫЙЄБъзЂЕФGT,зюКѓЩњГЩЕФresultгыGTЯрНЯradarИќЮЊНгНќЁЃдкBEVDepthЖдЭјТчдЄВтЩюЖШМрЖНЪБ,ЩюЖШБОЩэЕФФЃЬЌЮоЙиЕФаХЯЂ,ВЛМгИФБфЕиМрЖНЩюЖШдЄВтЭјТчЪЧПЩааЕФ,ЕЋЪЧЖдгкradarКЭlidarСНжжФЃЬЌ,ИїздгаИїздЕФЬиад,ЧПжЦЕиАбвЛжжФЃЬЌЕиЬиеїМрЖНСэвЛжжФЃЬЌЖјВЛМгБфЛЏ,ЪЦБиЛсЕМжТБОЮФжаГіЯжЕФащОЏЕШЧщПі,