论文阅读 : High-Resolution Image Synthesis with Latent Diffusion Models
code :https://github.com/CompVis/latent-diffusion
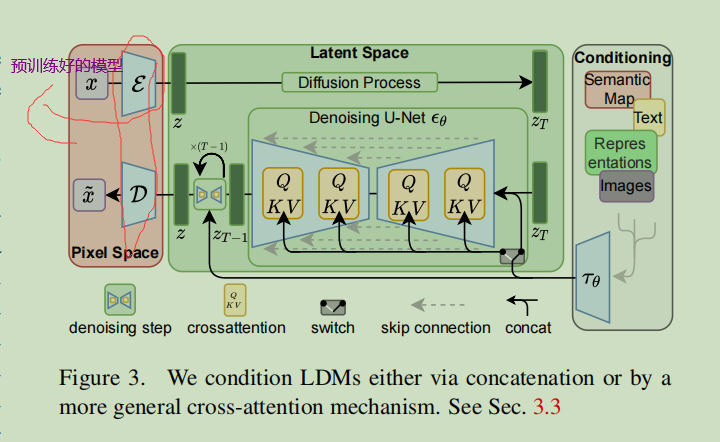
==目的:==能够在有限的计算资源上进行扩散模型训练,同时保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜在空间中。
- 结构变化 引入了 across-attention层,我们将扩散模型转化为强大而灵活的生成器,用于一般条件输入,如文本或边界框,以卷积方式和高分辨率的合成成为可能。
现状:
- 首先,训练这样的模型需要大量的计算资源,只可用于该领域的一小部分,并留下巨大的碳足迹
- 其次,评估一个已经训练过的模型在时间和内存上也很昂贵,因为相同的模型架构必须连续运行大量的步骤(例如,25 - 1000步
任何基于似然的模型可以分为
-
首先是一个感知压缩阶段,它去除高频细节,但仍然学习到很少的语义变化。
-
在第二阶段,实际的生成模型学习数据的语义和概念组成(语义压缩)。
因此,我们的目标是首先找到一个感知上等价的,但计算上更合适的空间,在这个空间中,我们将训练扩散模型的高分辨率图像合成
按照常见的实践,我们将培训分为两个不同的阶段:
- 首先,我们训练一个自动编码器,它提供了一个低维(因此有效的)表示空间,它在感知上等价于数据空间。
- 降低的复杂性也提供了有效的图像生成从潜在空间与单一的网络通道。我们将所得到的模型类称为潜在扩散模型(LDMs)
总之,我们的工作做出了以下贡献:
与纯粹的基于转换器的方法[23,64]相比,我们的方法可以更优雅地扩展到更高维的数据,因此可以
- )与纯粹的基于转换器的方法[23,64]相比,我们的方法可以更优雅地处理更高维数据,因此(a)可以在压缩级别上工作,从而提供比以前的工作更可靠和详细的重建,提供比以前的工作更忠实和详细的重建和应用于百万像素图像的高分辨率合成
- 我们在多个任务(无条件图像合成、内绘制、随机超分辨率)和数据集上实现了具有竞争力的性能,同时显著降低了计算成本。与基于像素的扩散方法相比,我们也显著降低了推理成本。
- 我们表明,与之前的工作[90]相比,它同时学习编码器/解码器架构和基于分数的先验,我们的方法不需要重建和生成能力的精细加权。这确保了非常忠实的重建,并且只需要很少的潜在空间的正则化。
- 我们发现,对于超分辨率、内画和绘制等密集条件任务的语义合成,我们的模型可以以卷积的方式应用,并渲染~10242 px的大型一致图像。
- 此外,我们还设计了一种基于交叉注意的通用条件反射机制,从而实现了多模态训练。我们使用它来训练类条件的模型、文本到图像的模型和布局到图像的模型。
- 最后,我们在https : / / github .com/CompVis/latent-diffusion 上发布了预先训练好的**潜在扩散和自动编码模型。**比较/潜在扩散,除了训练dm[78]外,还可以重复用于各种任务。
-
优势
一个新的优势是我们只需要训练一个通用的编码器,然后重复使用它用来多个扩散模型的训练,或者探索可能完全不同的任务。
两阶段图像合成(本文方法)
输入图像:$ x \in \mathbb{R}^{H \times W \times 3} $
编码器: E \mathcal{E} E 提前训练好的模型
潜在表示: z = E ( x ) z=\mathcal{E}(x) z=E(x)
解码器:D 提前训练好的模型
解码器D重构图像: x ~ = D ( z ) = D ( E ( x ) ) \tilde{x}=\mathcal{D}(z)=\mathcal{D}(\mathcal{E}(x)) x~=D(z)=D(E(x)),$ z \in \mathbb{R}^{H \times W \times c} $
重要的是,编码器对图像的进行了下采样分析 f = H / h = W / w f=H / h=W / w f=H/h=W/w,下采样因子 f f f是超参数,可以被随意设置。
为避免任意高方差的潜在空间,对潜在空间应用的正则化:
- *KL-reg.*对学习到的潜在变量,施加一个对标准正常的轻微kl惩罚,类似于VAE [45,67]中的VQ-reg,在解码器内使用矢量量化层[93]。
- VQ-reg,该模型可以解释为一个VQGAN [23],但量化层被解码器吸收。
因为我们随后的DM被设计用于学习潜在空间 z = E ( x ) z = E (x) z=E(x)的二维结构,我们可以使用相对温和的压缩率,并实现非常好的重建。
隐扩散模型
通过我们训练过的由E和D组成的感知压缩模型,我们现在可以获得一个高效的、低维的潜在空间,在这个空间中,高频的、难以察觉的细节被抽象出来。与高维像素空间相比,该空间更适合于基于可能性的生成模型,因为它们现在可以(i)关注数据的重要语义位,以及(ii)在低维、计算效率更高的空间中进行训练。
Conditioning Mechanisms
τ θ ( y ) ∈ R M × d τ \tau_{\theta}(y) \in \mathbb{R}^{M \times d_{\tau}} τθ?(y)∈RM×dτ?: 一个域特定的编码器,它将y投射到一个中间表示,然后通过交叉注意层实现 Attention ? ( Q , K , V ) = softmax ? ( Q K T d ) ? V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right) \cdot V Attention(Q,K,V)=softmax(d?QKT?)?V。 Q = W Q ( i ) ? φ i ( z t ) , K = W K ( i ) ? τ θ ( y ) , V = W V ( i ) ? τ θ ( y ) Q=W_{Q}^{(i)} \cdot \varphi_{i}\left(z_{t}\right), K=W_{K}^{(i)} \cdot \tau_{\theta}(y), V=W_{V}^{(i)} \cdot \tau_{\theta}(y) Q=WQ(i)??φi?(zt?),K=WK(i)??τθ?(y),V=WV(i)??τθ?(y)
φ i ( z t ) ∈ R N × d ? i \varphi_{i}\left(z_{t}\right) \in \mathbb{R}^{N \times d_{\epsilon}^{i}} φi?(zt?)∈RN×d?i?表示UNet ? θ \epsilon_{\theta} ?θ?实现的一个(扁平的)中间表示,
L L D M : = E E ( x ) , y , ? ~ N ( 0 , 1 ) , t [ ∥ ? ? ? θ ( z t , t , τ θ ( y ) ) ∥ 2 2 ] L_{L D M}:=\mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t}, t, \tau_{\theta}(y)\right)\right\|_{2}^{2}\right] LLDM?:=EE(x),y,?~N(0,1),t?[∥???θ?(zt?,t,τθ?(y))∥22?]
总结
本文的创新主要是把图像转换到特征空间中,减少扩散模型对计算量的消耗。编码器和解码器是提前训练好的。其次,通过用一个转换网络转换,扩展了应用范围。