? ? ? ? КУ,НгЯТРДвЊЩцМАЕФВПЗжФи,ОЭЪЧMG-GANЕФжїЬхВПЗжСЫ,ЭМвЛгаЪОвтЫЕКьЩЋОиаЮПђжаЕФВПЗжОЭЪЧЮвУЧНёЬьвЊаДЕФЖЋЮїЁЃЮвУЧПЩвдДгMG-GANЕФНсЙЙЭМжаПДЕНЫЕ,УЛгаИјГіDiscriminatorВПЗж,ЩѕжССЌЮФеТЬсГіЕФClassifier?вВУЛгаИјГіЁЃЖјЮвУЧжЊЕР,GANЕФбЕСЗЭљЭљЯШДгDПЊЪМ,ФЧУЛгаDiscriminatorВПЗжКЭClassifier?
ИУдѕУДАьФи?вЛИіКмжБНгЕФЯыЗЈОЭЪЧЯШПДТлЮФ,дйПДДњТы,НЋЮФеТЮДЛдкЭМжаЕФВПЗжздМКБэЪіГіРДЁЃФЧЮве§ЪЧетУДзіЕФ,ЫљвдВЉПЭЕФжЪСПИпвВЪЧЧщРэжЎжаЕФЪТСЫЁЃ
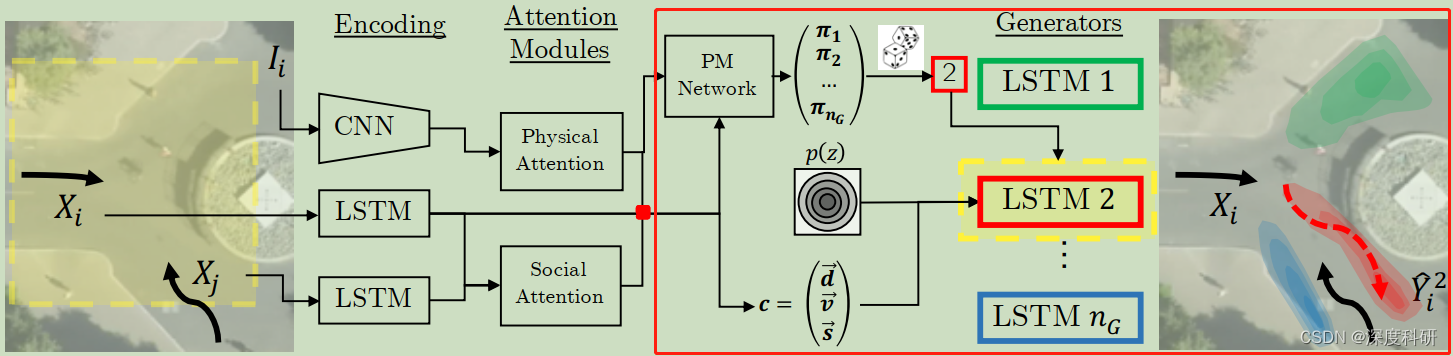
? ? ? ?дк(вЛ)жаНсЮВДІЮвУЧЫЕЕН:АбЕУЕНЕФЦДНгдквЛЦ№,ЕУЕН
([6,192] / [120,192] for D,[6,128] for G)ЁЃЖдХаБ№ЦїDРДЫЕ,
жаЕФУПвЛааАќКЌСЫИУааШЫ20жЁЕФЙьМЃаХЯЂ(ЙлВт8жЁ+дЄВт/GT12жЁ)ЁЂЫћИќдИвтГіЯждкГЁОАжаЕФФФаЉЮЛжУ,вдМАЫћЖджмдтФФаЉааШЫБШНЯдквтЁЃФЧетбљвЛИізлКЯСЫЖрЗНУцЕФаХЯЂЕФОиеѓ,ЖЊИјЮвУЧЕФХаБ№ЦїD,ОЭФмЕУЕНдЄВтааШЫЙьМЃЕФецМй;ЛђепНЋЦфЖЊИјclassifier?
,ОЭФмЕУЕНдЄВтЕФЙьМЃаХЯЂРДздФФвЛИіgeneratorЁЃЖдЩњГЩЦїGРДЫЕ,
жаЕФУПвЛааАќКЌСЫИУааШЫЧААЫжЁЕФЙлВтаХЯЂЁЂЫћИќдИвтГіЯждкГЁОАжаЕФФФаЉЮЛжУ,вдМАЫћЖджмдтФФаЉааШЫБШНЯдквтЁЃФЧетбљвЛИізлКЯСЫЖрЗНУцаХЯЂЕФОиеѓМгЩЯдыЩљ,ЖЊИјЮвУЧЕФЩњГЩЦїG,ОЭФмЙЛЪфГіааШЫЙьМЃЕФдЄВтНсЙћ;ЛђепЖЊИјТлЮФМмЙЙжаЕФPM Network,ОЭФмЕУЕНУПИіgeneratorЕФМгШЈИХТЪЁЃетЪЧвЛИіЗЧГЃОЋСЖЕФзмНс,ЙЙГЩСЫНгЯТРДЮвУЧа№ЪіЕФПђМмЁЃЪВУДвтЫМФи?ЛЛОфЛАЫЕ,ЖСепВЛБидйЮЊgeneratorЛђепPM NetworkЕФЪфШыЪЧЪВУДЖјРЇЛѓСЫ,ЮвУЧжЛашвЊдйЭкОђGANЕФВПЗжЪЧдѕбљдЫзїЕФ,ФЧMG-GANОЭбЇЯАЭъСЫЁЃ
? ? ? ЮЊСЫЗНБуа№ЪіЮвУЧАДееДњТыЕФТпМРДЪщаДЁЃдкdiscriminator_stepНзЖЮ,злКЯСЫИїЗНУцаХЯЂЕФОиеѓЛсБЛЫЭШыХаБ№Цї
КЭЗжРрЦї?classifier?
?жа,discriminatorЕФзїгУЪЕМЪЩЯЪЧИіЗжРрЦї,ЫќгЩМђЕЅЕФвЛаЉЯпадВуЙЙГЩЁЃФЧетРяЮЊЪВУДвЊЛЙвЊдіМгвЛИіЗжРрЦїЗжжЇ
Фи?
? ? ? ?дкДЋЭГЕФGANжа,ЮвУЧЪфШывЛИіЬѕМўword:c,дйЪфШывЛИіДгдЪМееЦЌжаsampleГіРДЕФЗжВМz,ОЙ§generatorКѓ,ЪфГівЛИіimage:x,ЮвУЧЯЃЭћетИіxОЁПЩФмЕиЗћКЯЬѕМўcЕФУшЪі,ВЂЧвЩњГЩЕФееЦЌзуЙЛЧхЮњ;ЮЊСЫБЃжЄxЕФжЪСП,ЮвУЧв§ШыСЫdiscriminator,гУРДХаЖЯЪфШыЕФxЪЧецЪЕЕФЭМЦЌЛЙЪЧЮБдьЕФЭМЦЌ,МД:

ЭМЖў:ДЋЭГGAN ? ? ? ?ФЧДЋЭГGANЛсДјРДвЛИіЪВУДЮЪЬтФи?ДЋЭГGANжЛФмБЃжЄШУxОЁПЩФмЕиЯёецЪЕЭМЦЌ,ЕЋЪЧКіТдСЫШУxЗћКЯЬѕМўУшЪіcЕФвЊЧѓЁЃгкЪЧ,ЮЊСЫНтОіетвЛЮЪЬт,CGANБуБЛЬсГіСЫЁЃCGANЕФФПЕФЪЧ:МШвЊШУЪфГіЕФЭМЦЌецЪЕ,вВвЊШУЪфГіЕФЭМЦЌЗћКЯЬѕМўcЕФУшЪі,DiscriminatorЪфШыБуБЛИФГЩСЫЭЌЪБЪфШыcКЭxЁЃЪфГівЊзіСНМўЪТЧщ,вЛИіЪЧХаЖЯxЪЧЗёЪЧецЪЕЭМЦЌ,СэвЛИіЪЧxКЭcЪЧЗёЦЅХфЁЃОйР§РДЫЕ,дкЯТУцетИіЧщПіжа,ЬѕМўcЪЧtrain,ЭМЦЌxвВЪЧвЛеХЧхЮњЕФЛ№ГЕееЦЌ,ФЧУДDЕФЪфГіОЭЛсЪЧ1;МДБуЪфГіЭМЦЌЧхЮњ,ЕЋВЛЗћКЯЬѕМўc,ЛђепЪфГіЭМЦЌВЛецЪЕ,етСНжжЧщПіжаDЕФЪфГіЖМЛсЪЧ0ЁЃ

ЭМЖў:CGAN ? ? ? ?ФЧCGANгжЛсДјРДЪВУДЮЪЬтФи?ЮвУЧжЊЕРЫЕдкЪЕМЪбЕСЗжа,ЮвУЧгЕгаЕФвбХфЖдЕФЪ§Он(c,x)ЭљЭљЪЧЗЧГЃЩйСПЕФ,ВЂЧвDашвЊзіСНМўЪТЧщ:МШашвЊКЭGНјааВЉоФ,вВОЭЪЧХаБ№ЪфШыЕФбљБОЪЧРДздецЪЕЪ§ОнЗжВМЛЙЪЧЩњГЩЦї,ЛЙашвЊдЄВтЪ§ОнЕФРрБъЧЉ,вВОЭЪЧЪфГіЬѕМўcЁЃФЧЭЌЪБзіетбљСНИіШЮЮёdiscriminatorЭљЭљСІВЛДгаФ,жЛФмЙизЂЕНЪ§ОнЕФвЛВПЗжаХЯЂ,МДЪ§ОнЕФРДдД,ЖјЮоЗЈПМТЧЕНЪ§ОнЕФРрБъЧЉаХЯЂЁЃЮЊСЫНтОіетИіЮЪЬт,ЮвУЧПЩвддіЬэвЛИіclassifier
ШЅбЇЯАШчКЮИјЭМЦЌxБъзЂХфЖдЬѕМўc,етбљОЭФмМѕЩйdiscriminatorЕФбЙСІ,аЮГЩБШНЯКУЕФбЕСЗЪ§ОнЁЃФЧЮвУЧАбетжжGANНазіTriple GANЁЃTriple GANЕФПђМмОЭЪЧЯТУцетбљЭМЕФбљзг:xЪЧЭМЦЌ,yЪЧЬѕМў(вВОЭЪЧc),(x,y)ЙЙГЩвЛИіХфЖдЁЃДгЭМжаПЩвдПДГі,TripleGANгЩШ§ИіВПЗжзщГЩ,ЕквЛИіЪЧclassifier
,ВЂНЋетИіХфЖдаХЯЂ
ећКЯГЩвЛИіаТЕФХфЖд
ДЋЕнИјdiscriminator;ЖјЕкЖўИіВПЗжdiscriminatorОЭашвЊбЇЛсМјБ№ЪфШыЕФХфЖдЪЧРДздецЪЕЪ§Он,ЛЙЪЧgenerator,ЛЙЪЧclassifierЁЃзюжедкdiscriminatorЕФАяжњЯТ,
ЁЂ
ЖМЛсдНРДдННгНќ
;жСгкЕкШ§ИіВПЗжgenerator,ОЭгыCGANжаЕФgeneratorвЛФЃвЛбљСЫ,ЪфШывЛИіЬѕМўyКЭЯШбщЗжВМz,ВњЩњвЛИіЪфГіЭМЦЌxКЭЬѕМўyЕФХфЖдЁЃ
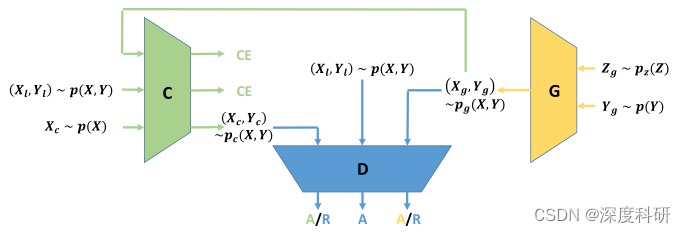
ЭМШ§:Triple GAN ЦфЪЕЕНетРя,ЮвУЧвбОПЩвджЊЕРЮЊЪВУДвЊдіМгclassifier?
?СЫЁЃФЧШчЭЌЫљгажЛгаЕЅИіgeneratorЕФGANвЛбљ,Triple GANвВДцдкФЃаЭБРЫњЕФЮЪЬт(mode collapsing problem)ЁЃmode collapseЪЧжИGanВњЩњЕФбљБОЕЅвЛ,ЦфШЯЮЊТњзуФГвЛЗжВМЕФНсЙћЮЊtrue,ЖјЦфЫћЮЊFalseЁЃ ФЧНтОіетвЛЮЪЬтжївЊЕФВпТдОЭЪЧгІгУЖрИіgenerator,етбљзіВЛНіжЄУїЖдИВИЧЪ§ОнФЃЪНЕФЖрбљадгааЇ,ВЂЧвФмЙЛПЫЗўФЃаЭБРЫњЕФЮЪЬт,ВЂШЁЕУSOTAЕФЪЕбщНсЙћЁЃвЛИізюжБНгЕФгІгУЖрЩњГЩЦїЕФФЃаЭОЭЪЧMGANЁЃЫќЕФЭјТчНсЙЙШчЯТЭМЫљЪО:

ЭМЫФ:MGAN

КУ,ФЧЮвУЧЯждкжЊЕРдіМгclassifier?ЕФдвђЪЧЗжЕЃХаБ№ЦїЕФЙЄзї,ШУdiscriminatorжЛашвЊЙизЂЪфШыбљБОЕФецМй,ЖјВЛашвЊдйЖдбљБОРрБ№НјааЗжРр,етвЛВПЗжЙЄзїгЩ?classifier?
ЕЃШЮЁЃФЧ?classifier?
ЕФЪфГіЪЧЪВУДФи?classifier?
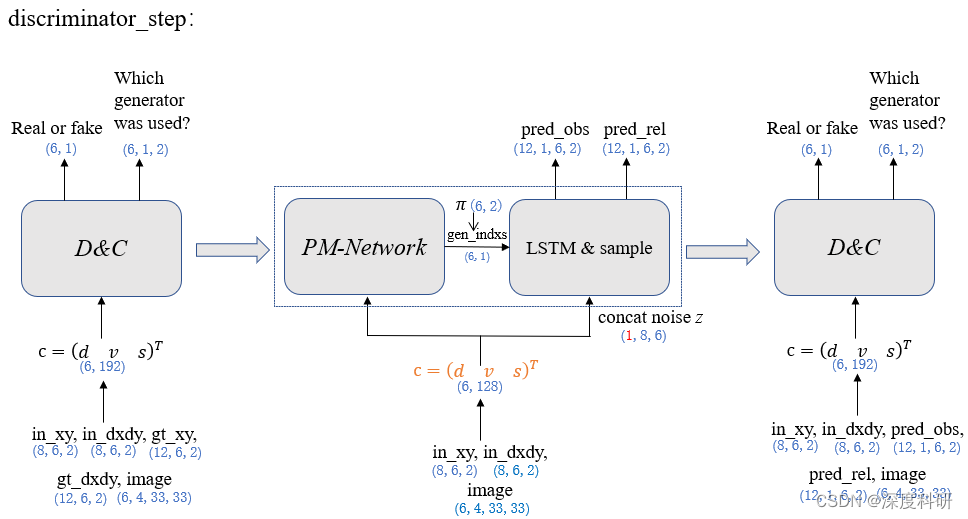
?ЕФМмЙЙЪЕМЪЩЯЪЧгЩСНВуШЋСЌНгВуЙЙГЩ,ЦфНЋЮЌЖШгЩ192гГЩфЕН96,дйгГЩфЕН2ЁЃЫљвдвЛИізлКЯСЫИїЗНУцаХЯЂЕФОиеѓ
[6,192](Лђ[120,192])ЪфШыЕН?classifier?
?,ЪфГівЛИіЮГЖШДѓаЁЮЊ[6,2](Лђ[120,2])ЕФОиеѓ,ОЮЌЖШЕїећКѓБфЮЊ[6,1,2](Лђ[6,20,2])(batch_size, n_samples, dim)ЁЃФЧ?classifier?
?ЕФЪфГіОиеѓБэЪОЪВУДКЌвхФи?вдЪфГіОиеѓДѓаЁЮЊ[6,1,2]ЮЊР§,ЦфДњБэЕФКЌвхЪЧ:ЖдУПЮЛааШЫдЄВт1ЬѕдЄВтЙьМЃ,етвЛЬѕЙьМЃРДздФФИіgenerator(ЙВ2Иі,ЩшжУЮЊ2)ЕФИХТЪ;ЭЌРэПЩЭЦ,[6,20,2]БэЪОЕФОЭЪЧ:ЖдУПЮЛааШЫдЄВт20ЬѕдЄВтЙьМЃ,УПЬѕЙьМЃРДздФФИіgenerator(ЙВ2Иі,ЩшжУЮЊ2)ЕФИХТЪЁЃ
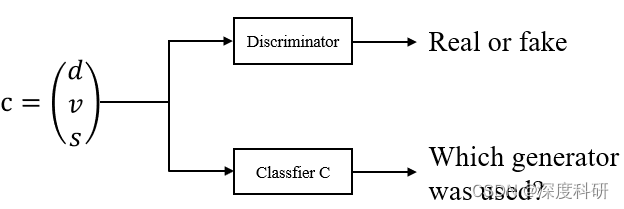
ЫЕСЫетУДЖр,ЦфЪЕжЛЯыИцЫпЖСепСНМўЪТ:1.classifier??ЪЧХаБ№ЦїDЕФвЛИіЗжжЇ;2.classifier?
?ЪфГіОиеѓЕФКЌвхЁЃФЧгУЭМЪОвтОЭГЄЯТУцетбљ:
? ? ? ?
? ? ? ?КУ,DКЭCжЎКѓФи,ОЭЪЧЮвУЧЕФЩњГЩЦїGСЫЁЃЩњГЩЦїgeneratorЕФШЮЮёЪЧИљОнЙлВтЕФЧААЫжЁЙьМЃ,ЪфГіКѓЪЎЖўжЁдЄВтЕФЙьМЃвдМАЩњГЩЦїЕФЫїв§ЁЃетМўЪТдѕУДРэНтФи?ФуПЩвдЯыЫЕ,ЯждкгаСНИіgenerator(ЕБШЛФуПЩвдЩшжУЫФИіgenerator,ЫцФуЕФаФвт),ЮвНЋзлКЯСЫИїЗНУцаХЯЂЕФОиеѓ[6,128](ФЧетРяЮЊЪВУД
ЕФЮЌЖШЪЧ128,вдМА
ДњБэСЫЪВУДКЌвх,дк(вЛ)жавбОЯъЯИЫЕУї,ВЛУїАзЕФЖСепПЩвдвЦВНЯШШЅСЫНт)гыдыЩљ
?concatЦ№РД,зїЮЊgenerator LSTMЕФ?
(
?ГѕЪМЛЏ),ааШЫЧААЫжЁЕФЯрЖдЙьМЃзїЮЊgenerator LSTMЕФinput?
,ЭЌЪБЖЊЕНСНИіgeneratorжа,ВњЩњдЄВтЕФЯрЖдЙьМЃ
[12,6,2]гы
[12,6,2]ЁЃФЧШчЙћЮвУЧжЛашвЊЁА1ЬѕЙлВтЙьМЃВњЩњ1ЬѕдЄВтЙьМЃЁБЕФЛА,
ЁЂ
ЕФЮЌЖШОЭБфЮЊ[12,1,6,2]ЁЃНєНгзХЮвУЧНЋ
ЁЂ
ЕФНсЙћstackЦ№РД,ОЭЕУЕН[12,1,2,6,2](seq_len, n_sample, num_gens, batch, dim)ЁЃНЋЦфЕїећЮЌЖШ,БфЮЊ[12,2,6,2](seq_len, n_sample x num_gens, batch, dim)ЁЃе§ШчЮвУЧжЎЧАЫљЫЕЕФ,ЮвУЧВЂВЛашвЊШЋВПgeneratorВњЩњЕФЫљгаЙьМЃ,ЖјЪЧДгШЋВПgeneratorВњЩњЕФЫљгаЙьМЃжа,ЬєГі6ЬѕзюЗћКЯдЄВтНсЙћЕФЙьМЃЁЃФЧЁАЬєЁБетМўЪТгУЪВУДзМдђРДЯожЦФи?Д№АИЪЧТлЮФжаЬсМАЕФPM-NetworkЁЃФЧPM-NetworkЕФЭјТчМмЙЙГЄЪВУДбљФи?ЫќЕФЭјТчМмЙЙгЩШ§ВуШЋСЌНгВуЙЙГЩ,НЋЮЌЖШгЩ128гГЩф16,дйгГЩфЕН16,зюКѓгГЩфЕН2ЮЌЁЃФЧPM-NetworkЕФЪфШыЪЧЪВУДФи?ЫќЕФЪфШыОЭЪЧЮвУЧЕФОиеѓ
[6,128]ЁЃЕЋЪЧФуПЩФмЛсЫЕ,ТлЮФдЭМжадкPM-NetworkФЃПщДІгаСНИіМ§ЭЗ,ДњБэзХЫќгІИУгаСНИіЪфШыВХЖдАЁ?етвЛЕуФи,ЮвПЯЖЈгазЂвтЕН,вђЮЊВЉПЭОЭЪЧЮваДЕФЖдВЛЖдЁЃЕЋЪЧДњТыЪЕЯжЙ§ГЬжа,PM-NetworkНівд
ЮЊЪфШы,ЪфГівЛИіДѓаЁЮЊ[6,2]ЕФОиеѓ
ЁЃФЧдѕУДРэНтетИіЪфГіОиеѓ
ЕФКЌвхФи?ОйР§РДЫЕ,PM-NetworkЕФЪфГіОиеѓ[6,2]ДњБэСЫУПИіааШЫбЁдёgenerator 1ЛЙЪЧgenerator 2ЕФИХТЪЁЃЙтгаИХТЪЛЙЪЧЁАЦхВювЛВНЁБ,вђЮЊЮвУЧЯыОпЬхжЊЕРФФИіШЫгІИУДгФФИіgeneratorжабЁдёФЧЬѕЙьМЃЁЃФЧдѕУДзіФи?
? ? ? ОпЬхЕФзіЗЈЪЧ:НЋОиеѓЭЈЙ§вЛИіУћНаCategorical(probs)ЕФКЏЪ§,ИУКЏЪ§ЕФзїгУЪЧДДНЈвдВЮЪ§probsЮЊБъзМЕФРрБ№ЗжВМ,бљБОЪЧРДзд ЁА0 Ё K-1ЁБ ЕФећЪ§,Цфжа K?ЪЧprobsВЮЪ§ЕФГЄЖШЁЃвВОЭЪЧЫЕ,АДееДЋШыЕФprobsжаИјЖЈЕФИХТЪ,дкЯргІЕФЮЛжУДІНјааШЁбљ,ШЁбљЗЕЛиЕФЪЧИУЮЛжУЕФећЪ§Ыїв§ЁЃИќОпЬхЕФгУЗЈ,ЖСепПЩвдВЮПМЯрЙиВЉПЭЁЃЯТУцгУЭМЪОЕФЗНЗЈИцЫпФуЫЕ,
ОиеѓЭЈЙ§CategoricalКЏЪ§КѓЕУЕНвЛИіdistОиеѓ,ИУОиеѓРяУцЕФжЕЖдгІИХТЪжЕЕФЫїв§ЁЃЖСепШчЙћвЛПЊЪМРэНтВЛСЫ,ПЩвдНЋ
ОиеѓгыdistОиеѓЧАКѓЕўдквЛЦ№ПДЁЃгаСЫdistКѓ,ЮвУЧИљОн
ОиеѓЕФИХТЪжЕЖдdistОиеѓНјааВЩбљ,ВЩбљЕФДЮЪ§гЩВЮЪ§n_sampleОіЖЈЁЃетРяМйЩшn_sample=1,втЮЖзХУПааВЩбљ1ДЮЁЃФЧдѕУДНјааВЩбљФи?ОйР§РДЫЕ,ЖдdistЕквЛааВЩбљЕУ1,ЖдdistЕкЖўааВЩбљЕУ1,....? ЮвУЧдѕУДПДД§distОиеѓЕФКЌвхФи?ДгааРДПД,ЫќЕФУПвЛааЦфЪЕДњБэСЫвЛЮЛааШЫ;ДгСаРДПД,ЫќЕФУПвЛСаДњБэСЫgenerator 1ЛЙЪЧgenerator 2ЁЃФЧУДдкВЩбљЙ§Кѓ,ЕУЕНЕФОиеѓЮвУЧГЦзї:sampled_gen_ids[6,1]
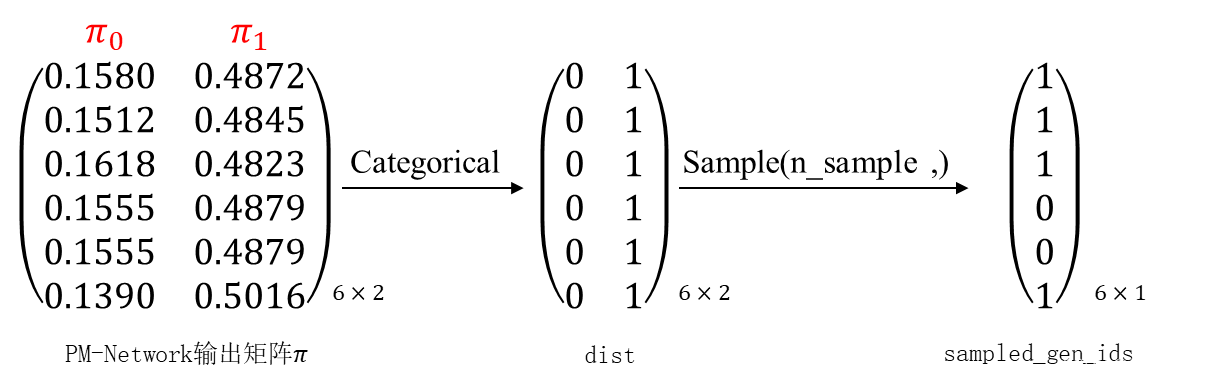
?ЖСепашвЊзЂвтЕФЪЧ,ШчЙћn_sample=20,гЩЩЯЪіПЩжЊ,ЦфДњБэдкdistОиеѓУПвЛаажаВЩбљ20ДЮ,зюКѓЕУЕНЕФsampled_gen_idsОиеѓЕФДѓаЁЮЊ[6,20]ЁЃsampled_gen_idsОиеѓЕФЮяРэКЌвхЮЊ:вдЕквЛаа[1,20]ЮЊР§,ЦфБэЪОааШЫЂйЕФ20ЬѕдЄВтЙьМЃЗжБ№ЪЧгЩФФИіgeneratorВњЩњЁЃ
злЩЯЫљЪі,ШчЙћЖСепШдШЛБЃГжЧхабЕФЛА,ећИіdiscriminator_stepНзЖЮПЩвдгУЯТЭМНјааИХРЈ:
? ? ? ?
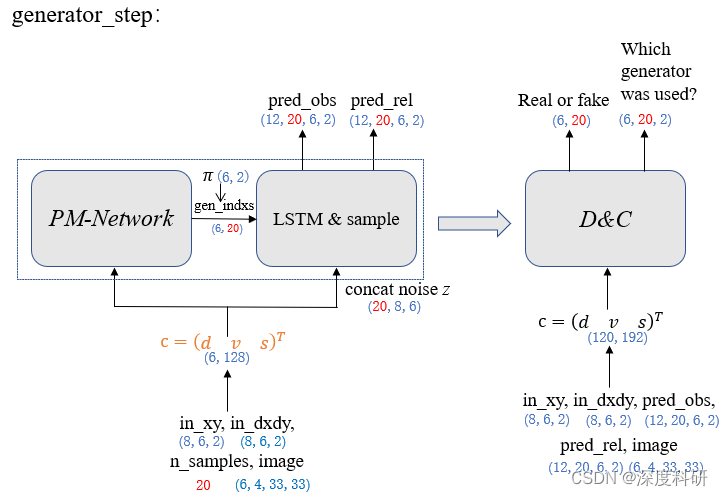
? ? ? ?ФЧЦфЪЕЕНетРя,ЮвУЧЕФGANВПЗжОЭПьвЊНсЪјСЫЁЃЮЊЪВУДетУДЫЕФи?вђЮЊЮвУЧвбОАбDЁЂCЁЂGЪЧдѕУДдЫзїЕФИјНВЭъСЫ,?ЪЃЯТЕФgenerator_stepНзЖЮЖдгкDЁЂCЁЂGРДЫЕжЛЪЧЪфШыВЛЭЌЖјвб,ЦфЫќЗНУцЭъШЋвЛбљЁЃФуПЩвдгУЩЯУцЕФЫМЯыДјШыgenerator_stepЕФЙ§ГЬ,вЛДЮадАбMG-GANИјХЊУїАзЁЃШчЩЯЫљЪі,ећИіgenerator_stepНзЖЮПЩвдгУЯТЭМРДИХРЈ:
ЫФЁЂLoss?
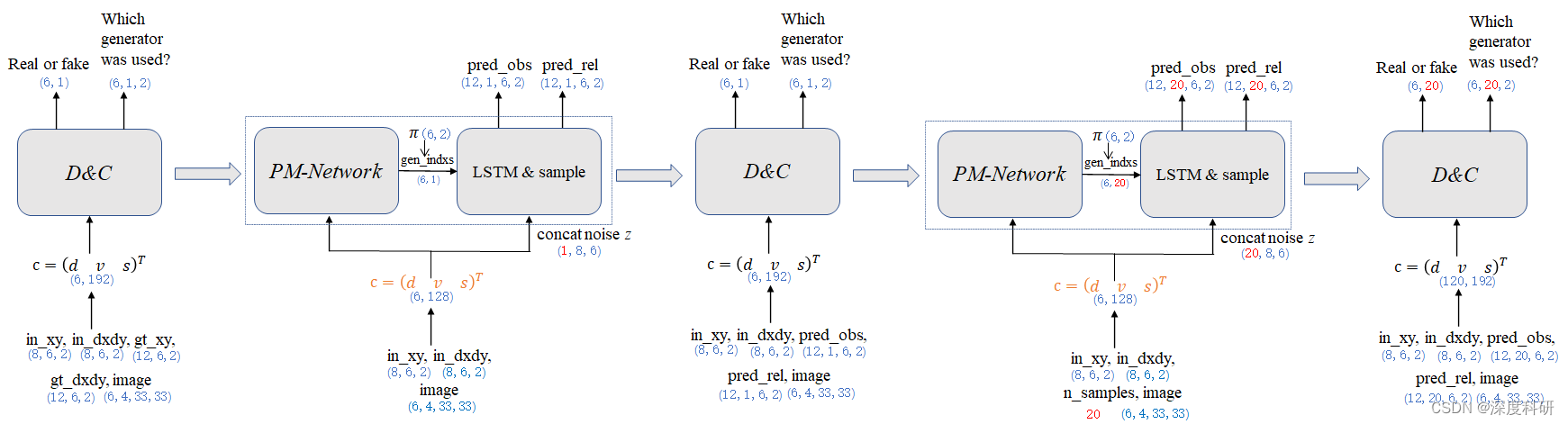
?ФЧдкНВLossжЎЧАФи,ЮвУЧЯШећРэвЛЯТMG-GANЕФећЬхМмЙЙ:?
?
ФуПЩвдПДЕНЫЕ,MG-GANЕФећЬхМмЙЙОЭЪЧdiscriminator_stepгыgenerator_stepЕФзщКЯЁЃ?ФЧдкlossЕФДІРэЩЯ,НшМјЭЌбљЕФЫМЯы,ЮвУЧвВПЩвдДгетСНИіЙ§ГЬжаПњЪгlossЕФзщКЯ:
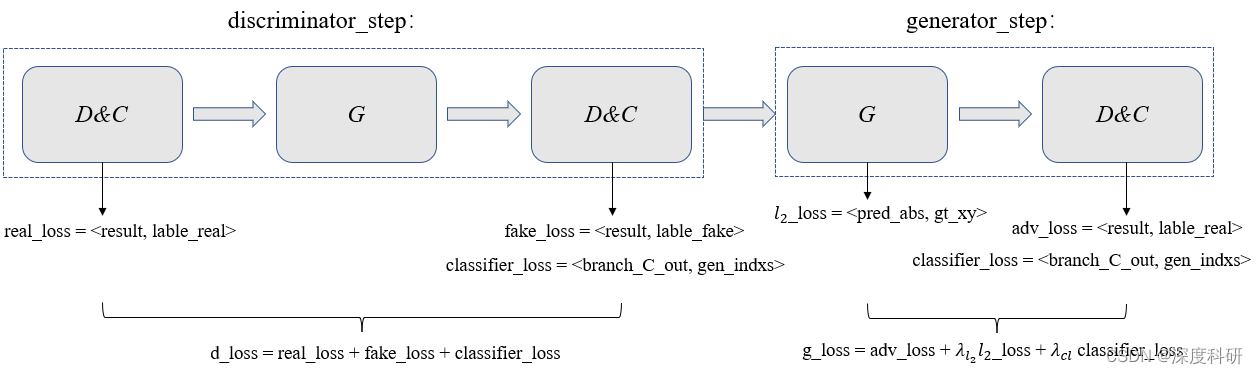 дкdiscriminator_stepНзЖЮ,гУreal_lossШЅХаБ№ХаБ№ЦїЗжРрецбљБОЕФИХТЪ,real_lossдНаЁдННгНќгкvalidЁЃдкНгЯТРДЕФЙ§ГЬжа,гУfake_lossШЅХаБ№ХаБ№ЦїЗжРрМйбљБОЕФИХТЪ,feak_lossдНаЁдНдННгНќгкfakeЁЃВЂЧв,гЩгкЗжРрЦї
дкdiscriminator_stepНзЖЮ,гУreal_lossШЅХаБ№ХаБ№ЦїЗжРрецбљБОЕФИХТЪ,real_lossдНаЁдННгНќгкvalidЁЃдкНгЯТРДЕФЙ§ГЬжа,гУfake_lossШЅХаБ№ХаБ№ЦїЗжРрМйбљБОЕФИХТЪ,feak_lossдНаЁдНдННгНќгкfakeЁЃВЂЧв,гЩгкЗжРрЦїГаЕЃСЫЗжРрБъЧЉ(гУСЫФФИіgenerator)ЕФШЮЮё,ЫљвдгУclassifier_lossРДХаБ№ЗжРрБъЧЉЕФИХТЪ,ВЂЙФРјУПИіЩњГЩЦїЩњГЩгыЦфЫћЩњГЩЦїЩњГЩЕФЪ§ОнЯрЗжРыЕФЪ§ОнЁЃећИіdiscriminator_stepНзЖЮЕФбЕСЗЫ№ЪЇПЩвдБэЪОЮЊ:? ? ? ? ? ? ? ? ? ? ? ? ? ? ??

дкgenerator_stepНзЖЮ,гУ?lossХаБ№дЄВтЙьМЃгыЩњГЩЙьМЃжЎМфЕФВюОр,
?lossдНаЁ,ЫЕУїдЄВтЕФЙьМЃдНЗћКЯецЪЕЙьМЃЁЃдкНгЯТРДЕФЙ§ГЬжа,?гУadv_lossРДХаБ№дЄВтЕФааШЫЙьМЃЁАЕНЕзгаЖрецЁБ,adv_lossЕФжЕдНаЁ,ЫЕУїХаБ№ЦїЖддЄВтЕФааШЫЙьМЃдНПЯЖЈ;НєНгзХЕФclassifier_lossгыdiscriminator_stepНзЖЮЕФclassifier_lossзїгУЯрЭЌ,ОЭВЛзИЪіСЫЁЃФЧећИіgenerator_stepНзЖЮЕФбЕСЗЫ№ЪЇПЩвдБэЪОЮЊ:
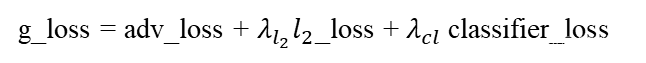
ФЧЕНетРя,MG-GAN ЕФНтЖСОЭИцвЛЖЮТфЁЃ