1.案例背景
情感分析在自然语言处理NLP领域是复杂的,有主观的,也有客观的。之前,我们使用机器学习各类算法在个人信息数据、借贷数据、手写数字等比较直观的数据集上进行建模。本篇我们将对于电影评论数据进行建模分析,来预测影评是积极的还是消极的;并且,分别演示Tensorflow和Keras使用LSTM在数据集上的建模效果,并与传统的机器学习随机森林RF、决策树DT等算法进行比较,突出LSTM算法的优秀之处。
2.数据预处理
首先导入我们所需要的包,包括传统机器学习库sklearn,深度学习框架Tensorflow和Keras.
import tensorflow as tf
import numpy as np
from string import punctuation # 判断标点符号
from collections import Counter #计数
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense, LSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
导入我们的原始文本数据review.txt和labels.txt,并预览我们的原始数据集
评论数据是来自于《Bromwell High》系列动画喜剧影片的观后影评,每条数据都对应一个积极的或者消极的标签。我们 将对数据集进行特征向量的处理和标签的编码。
def Load_Data():
with open('reviews.txt', 'r') as f:
reviews = f.read()
with open('labels.txt', 'r') as f:
labels = f.read()
return reviews, labels
reviews, labels = Load_Data()

观察原始数据,reviews是n段影评数据集合,labels代表了数据标签。
接下来,对数据进行预处理,方便我们后续对文本数据进行编码
def dataProprecess(reviews_str):
# 通过列表推导式将reviews_str字符串里的包含各种标点符号去掉,并返回一个字符组成的数组
# 然后通过join()函数将数组里的元素都连接成一个长长的字符串
all_text = "".join([review for review in reviews_str if review not in punctuation])
reviews_list = all_text.split('\n') ## 将该字符串通过\n换行符分割成数组
all_text = ' '.join(reviews_list)#将数组里的元素通过空格连接起来,形成一个长长的字符串
word = all_text.split()#使用split()函数的默认分隔符-空格来将字符串分割成一个个单词的数组,方便后续对数据进行编码
return reviews_list,all_text,word
reviews,all_text,word = dataProprecess(reviews)
分别看看reviews,all_text,word,看看我们处理的结果。
reviews[:2]
all_text[:3000]
word[:10]


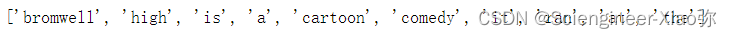
传递给神经网络的值应该是数值,但是影评是一个个文本,因此需要对影评的单词字符串进行编码处理。我们将创建一个字典,映射单词到整数值。
接下来,我们对word里面的所有影评的单词进行统计计数
word_counter = Counter(word)
word_counter

word_counter已经对所有的单词进行了统计,如上图所示,我们可以看看最多的10个单词
word_counter.most_common(10)

得到了这么多词汇,我们需要对每个单词进行编码,后面我们导入算法里面的回事一系列数字,而不是文本。编码完成之后,对所有的文本影评进行处理,我们将得到的不再是文本,而是算法可以识别的数字。如下
#创建单词对应的索引关系字典
vocab_to_int = {word:i for i,word in enumerate(sorted_vocab)}
reviews_ints = []
for review in reviews:
reviews_ints.append([vocab_to_int[word] for word in review.split()])
print(reviews_ints[:2]

将所有的特征数据处理完,我们可以看看数据评论的数量(25001)条,影评字符串数最大值为2514,最小值为0,因此我们需要提出字符串为0的数据,并且为了统一起见,选取每条评价前200个字符串为特征向量,长度不足200的,前面将使用0来填充。
reviews_len = Counter([len(x) for x in reviews_ints])
non_zero_idx = [i for i,review in enumerate(reviews_ints) if len(review) != 0]#过滤掉字符串为0的评论
labels = labels.split("\n")
labels = [1 if label == "positive" else 0 for label in labels]#将标签转化为0,1
reviews_ints = [reviews_ints[i] for i in non_zero_idx]
labels = np.array([labels[i] for i in non_zero_idx])
#创建一个特征向量feature vector
seq_len = 200
features = np.zeros((len(reviews_ints),seq_len),dtype=int)
for i,row in enumerate(reviews_ints):
features[i,-len(row):] = np.array(row)[:seq_len]
labels[:10]
features[0]
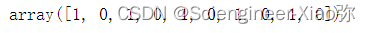

到这里,我们完成了数据的预处理过程,得到了特征向量(25000,200)和标签值(25000,),下面,我们将对数据进行建模分析。
3.建模分析
train_x,test_x,train_y,test_y = train_test_split(features,labels,test_size=0.2,random_state=0)
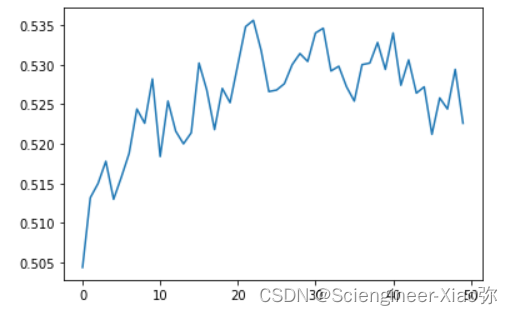
随机森林算法模型分类效果展示
import matplotlib.pyplot as plt
mi = []
for i in range(50):
rfc = RandomForestClassifier(n_estimators=i+1,random_state=0)
rfc.fit(train_x,train_y)
mi.append(rfc.score(test_x,test_y))
plt.plot(range(50),mi)
plt.show()
决策树算法模型分类效果展示
dtc = DecisionTreeClassifier(random_state=0).fit(train_x,train_y)
dtc.score(test_x,test_y)
得到的结果:0.5192
Keras-LSTM算法模型分类结果展示:
# 创建模型
embedding_vecor_length = 32
review_max_length = 200
model = Sequential()
#添加输入嵌入层
model.add(Embedding(100000,32,input_length=200))
#添加lstm隐藏层
model.add(LSTM(100))
#添加输出层,二分类问题,使用sigmoid激活函数
model.add(Dense(1,activation='sigmoid'))
#编译模型,二分类问题,使用二进制交叉熵来计算损失
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=["accuracy"])
#输出模型架构
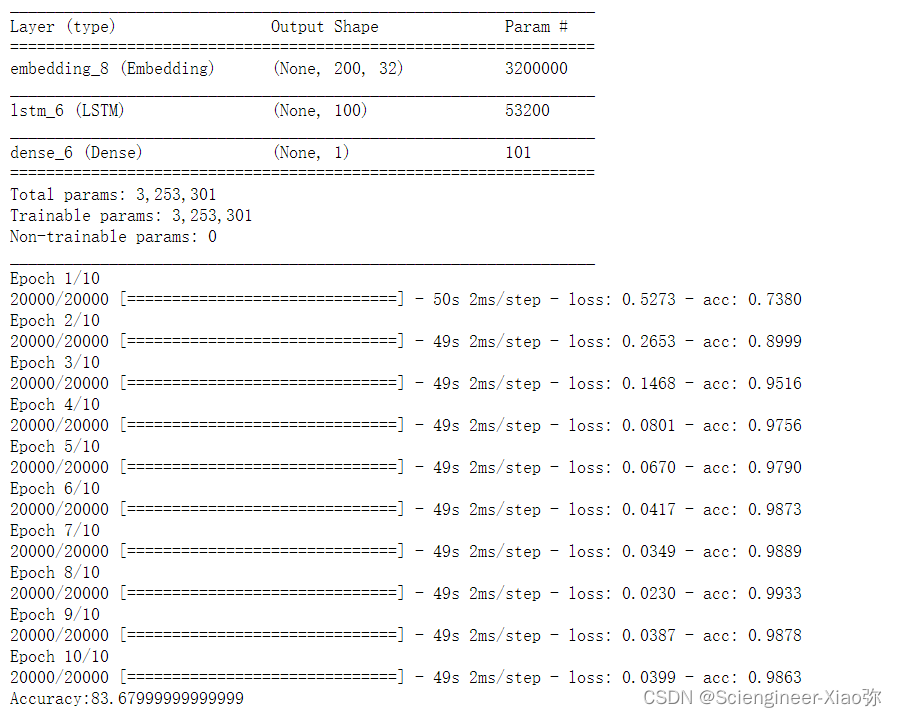
model.summary()
#训练模型,所有的训练数据集都要经过30次训练,每次训练时的批次大小为64个
model.fit(train_x,train_y,epochs=10,batch_size=64)
#模型评估
scores = model.evaluate(test_x,test_y,verbose=0)
print("Accuracy:{}".format(scores[1]*100))
Tensorflow-LSTM算法模型分类效果展示
lstm_size = 256
lstm_layers = 2
batch_size = 512
learning_rate = 0.01
n_words = len(vocab_to_int) + 1
# 创建默认计算图对象
tf.reset_default_graph()
# 给计算图上的张量的输入占位符添加一个前缀inputs
with tf.name_scope('inputs'):
# 输入特征占位符
inputs_ = tf.placeholder(tf.int32, [None, None], name="inputs")
# 输入标签占位符
labels_ = tf.placeholder(tf.int32, [None, None], name="labels")
# 保留率占位符
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
# 嵌入向量的大小
embed_size = 300
# 给计算图上的张量的嵌入层变量和查找表添加一个前缀Embeddings
with tf.name_scope("Embeddings"):
# 均匀分布初始化嵌入层的变量,范围是-1到1之间
embedding = tf.Variable(tf.random_uniform((n_words, embed_size), -1, 1))
# 将输入特征占位符传入嵌入查找表
embed = tf.nn.embedding_lookup(embedding, inputs_)
def lstm_cell():
# 创建基础LSTM cell
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.get_variable_scope().reuse)
# 添加dropout层到cell上
return tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob)
# 给graph上的tensors的RNN层添加一个前缀RNN_layers
with tf.name_scope("RNN_layers"):
# 创建多个LSTM层
cell = tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(lstm_layers)])
# 获取一个初始化状态,默认值都是0
initial_state = cell.zero_state(batch_size, tf.float32)
with tf.name_scope("RNN_forward"):
# 通过dynamic_rnn可以返回每一步的输出和隐藏层的最后状态
outputs, final_state = tf.nn.dynamic_rnn(cell, embed, initial_state=initial_state)
with tf.name_scope('predictions'):
# 创建输出层,由于我们预测的输出是1或者0,所以sigmoid激活函数是最好的选择
predictions = tf.contrib.layers.fully_connected(outputs[:, -1], 1, activation_fn=tf.sigmoid)
with tf.name_scope('cost'):
# 定义均方差训练损失函数
cost = tf.losses.mean_squared_error(labels_, predictions)
with tf.name_scope('train'):
# 定义训练优化器
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
with tf.name_scope('validation'):
# 计算验证精确度
correct_pred = tf.equal(tf.cast(tf.round(predictions), tf.int32), labels_)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
def get_batches(x, y, batch_size=100):
# 计算得出有多少个批次,这里是整除,所以假如x的总数不能被batch_size整除,
# 那么会剩下很小的一部分数据暂时会被丢弃
n_batches = len(x)//batch_size
# 然后再次确定x和y的数据集的数据
x, y = x[:n_batches*batch_size], y[:n_batches*batch_size]
# 通过for循环,使用yield关键字构建生成器函数
for ii in range(0, len(x), batch_size):
yield x[ii:ii+batch_size], y[ii:ii+batch_size]
epochs = 8
# 创建检查点保存对象
saver = tf.train.Saver()
# 创建一个TensorFlow会话
with tf.Session() as sess:
# 初始化全局变量
sess.run(tf.global_variables_initializer())
iteration = 1
# 开始迭代
for e in range(epochs):
# 首次计算初始化状态
state = sess.run(initial_state)
# 将所有的数据都进行训练,get_batches()函数会获取数据生成器,然后进行迭代
for ii, (x, y) in enumerate(get_batches(train_x, train_y, batch_size), 1):
feed = {inputs_: x,
labels_: y[:, None],
keep_prob: 0.5,
initial_state: state}
loss, state, _ = sess.run([cost, final_state, optimizer], feed_dict=feed)
# 每训练5次时,打印一次训练日志
if iteration%5==0:
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Train loss: {:.3f}".format(loss))
iteration +=1
# 每批次时都记录检查点
saver.save(sess, "checkpoints/sentiment.ckpt")
# 当所有的数据迭代训练完毕后,最后记录一次检查点
saver.save(sess, "checkpoints/sentiment.ckpt")
test_acc = []
with tf.Session() as sess:
# 从检查点恢复已训练的模型
saver.restore(sess, "checkpoints/sentiment.ckpt")
# 在计算测试集数据前,先创建一个空的状态
test_state = sess.run(cell.zero_state(batch_size, tf.float32))
# 获取测试集数据生成器
for ii, (x, y) in enumerate(get_batches(test_x, test_y, batch_size), 1):
feed = {inputs_: x,
labels_: y[:, None],
keep_prob: 1,
initial_state: test_state}
# 开始批次计算测试集数据
batch_acc, test_state = sess.run([accuracy, final_state], feed_dict=feed)
# 将每个批次的得分保存到数组
test_acc.append(batch_acc)
# 最后输出测试得分均值,即精确度
print("Test accuracy: {:.3f}".format(np.mean(test_acc)))
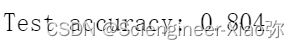
通过以上算法结果展示,随机森林和决策树的效果为50%左右,LSTM很容易就可以使分类效果达到了80%以上,可见,LSTM非常适合用于处理与时间序列高度相关的问题。