����
����ڹ��ں����˽����֪Զ�Ŷ��˳�����Ƶ�γ̡���ģ�ͽ������ֿΡ�,����Ŀ¼���ò���,��˰ݶ�һ�¡�
�ۿ���ַ: https://www.bilibili.com/video/BV1UG411p7zv
Ŀ¼:
- ��Ȼ���Դ���&��ģ�ͻ���
- ���������
- Transformer&PLM
- Prompt Tuning & Delta Tuning
- ��Чѵ��&ģ��ѹ��
- ���ڴ�ģ�͵��ı�����������
- ��ģ��������ҽѧ
- ��ģ���뷨������
- ��ģ�����Կ�ѧ
����
���������Ѿ��и��ָ�����Ԥѵ������ģ��,��Щģ�͵������ѵ�������ر��,�õ������ݺ��������Ҳ��ͬ,�����Ǹ����ʹ��������?

���ǵ�NLP����Ҳ�ر��,������һЩ�д����Ե�����
һ��Ԥѵ���õ�ģ��,�����Ѿ�����һЩͨ�õ�֪ʶ,��������ΰ��������Ӧ�õ���������,���Ǻ��п���Ҫ��ÿ�������Dz�ͬ����,�������������ǵĹ��������Ǻܷ��ء���Ϊ�����ƺ�Ҳ��Ҫ��ÿ�������趨���ص�ѵ������,�������ǿ�����Ԥѵ��ģ�����ﵽ�ܺõij�ʼ��,����û��ʵ��NLP��һͳ�ij�����
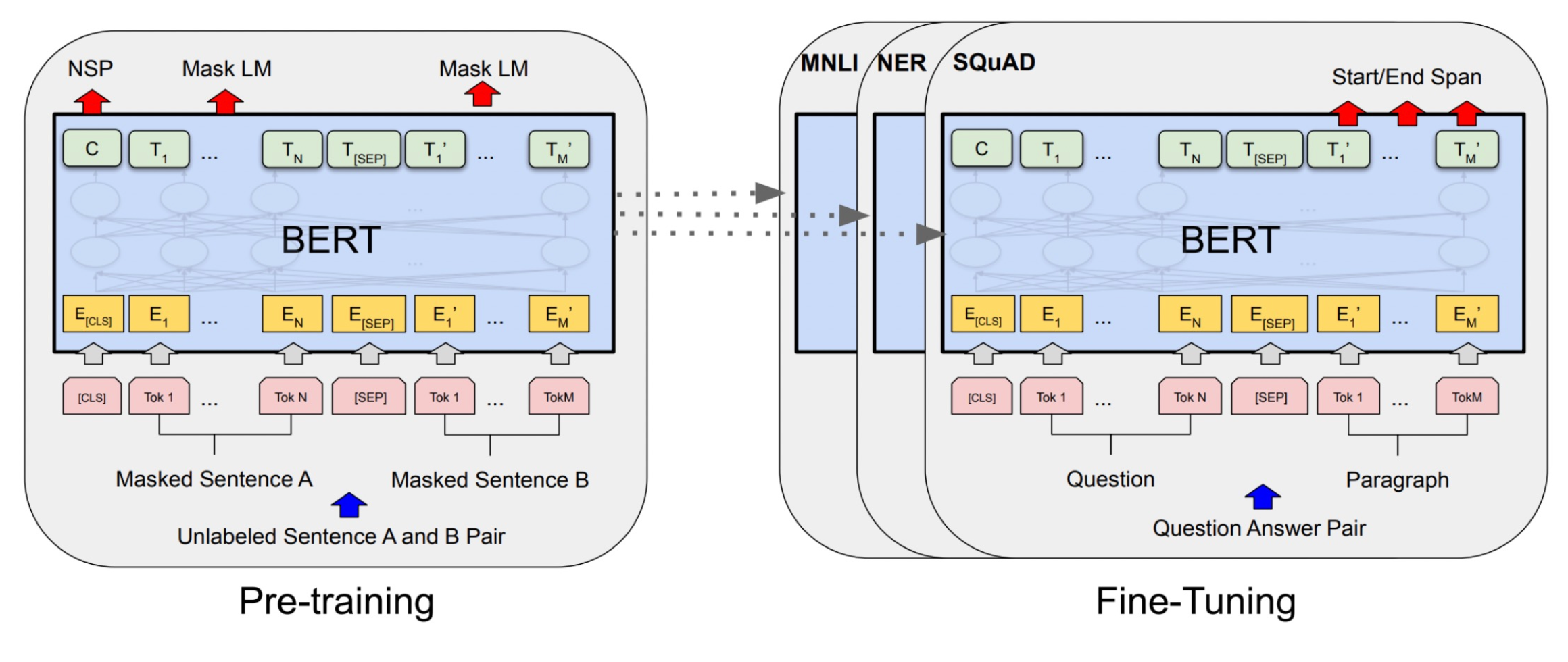
��BERTΪ��,BERT���������ǵ��仹������,��ʵ���ϻ��ÿһ��token����һ������,��Щ�������Խ��з��ࡣ
���������token����ķ�������,����NER,��ô��Щtoken�ı������͵�һ���������,����ÿ��token���з��ࡣ
��������Ǿ��Ӽ���ķ�������,��ôһ�������[CLS] token,�������Ӽ�������,�͵�������С�
Ҳ����ʱ��,BERT���ڲ�ͬ������,�Ὣ��ͬ�ı����͵��������ȥ,�ȴ���ѧϰ��������Ч����úܶࡣ
�����ù�ϵ��ȡ����һ�����ӡ�
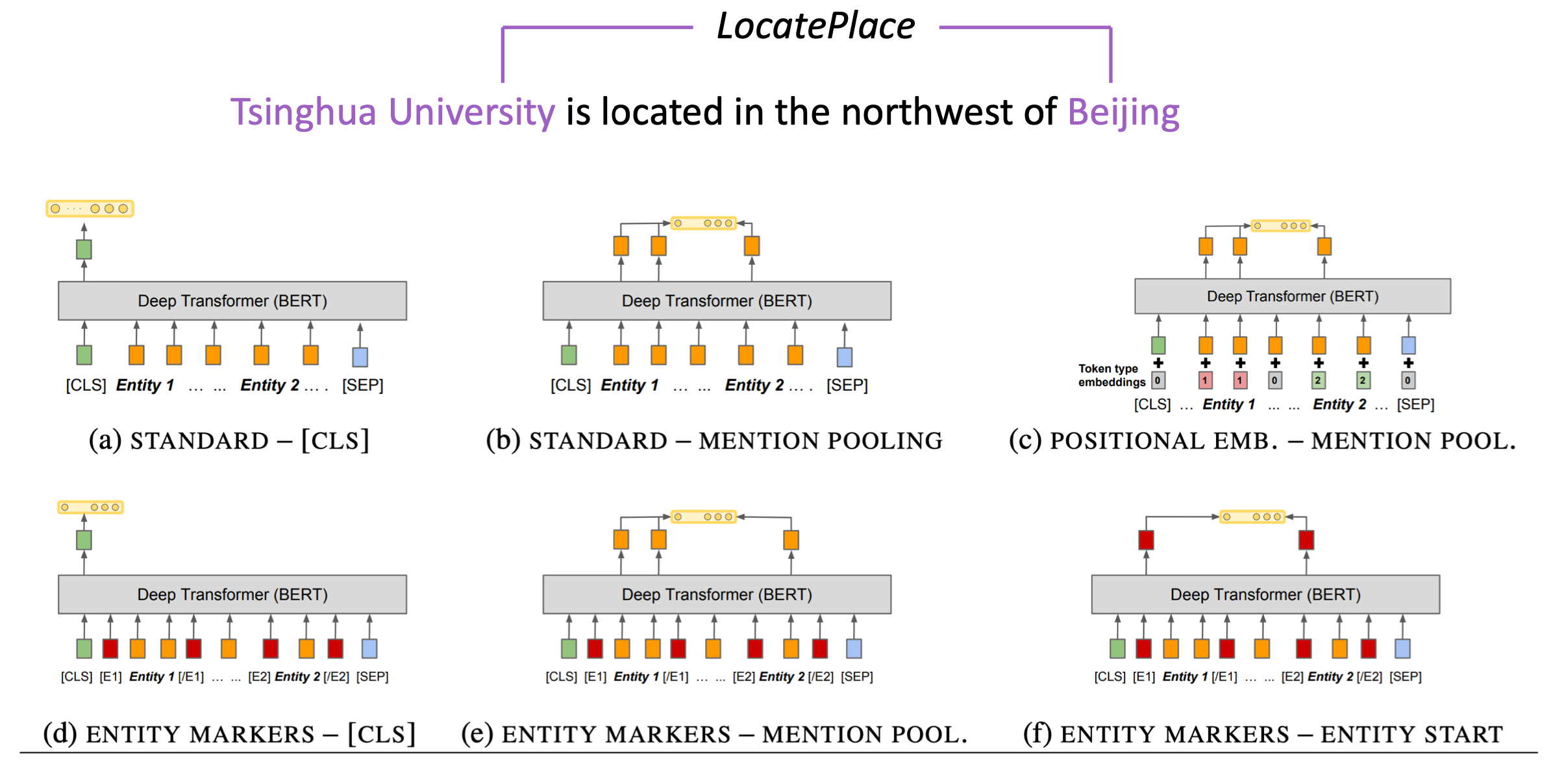
��ϵ��ȡ����:���ݾ����Լ������е�����ʵ��,�Ʋ������ʵ��֮��Ĺ�ϵ��������ͼ�еľ��ǡ��廪��ѧ��λ�ڡ���������
��ô��BERT��ʵ�ֵĻ�,��������������������
�����һ��(a)����������,������ʵ��λ����Ϣ,ֱ��ȡ�����������з���(ʵ��Ĺ�ϵ)��
���Կ�����Щ�����Ƿdz������Ե�,����û����ôֱ��,������Ƕ���Ҫȥѵ��һ��������,����Ҫ�����ʼ��һ������㡣���õ��ı���ι����,�ٺ�ģ��һ����ѵ����
���ַ�ʽԽ��������Ӧ���������ڵ�ʱ����
����GPT����

GPT��һ������ģ��,���ɵ�
n
n
n��tokenȡ����ǰ
n
?
1
n-1
n?1��token�ĸ��ʡ���ô������������ء�
P
(
y
�O
x
1
,
?
?
,
x
m
)
=
softmax
(
h
l
m
W
y
)
P(y|x^1,\cdots,x^m) = \text{softmax}(h^m_l W_y)
P(y�Ox1,?,xm)=softmax(hlm?Wy?)
�������һ��token�ı��� h l m h^m_l hlm?���Ϸ��������������ܵ�ʱһ����Կ�Ҳ����ȥ����Щģ��,���������о�������,������Ʒ����˸ı䡣
����ı��Ǵ�T5��ʼ��,T5ѵ����һ��110�ڲ�����ģ��,��ʱ�������ȿ�ʼ���˴�ģ��,���IJ��Է�����һЩ�仯��
�����������е�����ӳ���Ϊһ��seq2seq����ʽ,��������ѵ��һ��������,����ȥѵ��һ��������-������ģ�͡�
����Ҫ����з�������,��ʱ���������0��1����û�к���ı�ʾ������ֱ�����һ�����Դ�����еĵ���,����positive,��������ࡣ
���������ĺô�����,����������ķ�ʽͳһ��һ��ѵ���Ŀ��,��seq2seq��
Ϊ�����ֲ�ͬ������,T5�����˼�demonstration��

������ͼʾһ��QNLI������,����һ��question��һ��sentence��ɡ�������ι��T5��ʱ��,�����һЩ����,�����˵qnli question��ʲô,sentence��ʲô��Ȼ��ԭ����target��0,���ڸij��˾���ĵ���entailment��
����������ѵ�������������Ҫ�ĵ���,����������������Ҫ���Ǹ��ࡣ����ͨ����Щ��demonstration�Ͱ���Щ����ӳ�����seq2seq֮��,T5ģ�;Ϳ���ѵ����,���Dz�����Ҫ����ķ������������ѵ���ˡ�
��������������һ�����ơ�
Ȼ������������GPT-3,��ǧ��(1750��)����Ĵ�ģ�͡�
��ѵ������ôһ����Ȼ����,Ҫ���ʹ������������?
GPT-3���о�����������Լ���һ������
����,������һ����˴��ģ���Dz���ʵ�ġ���ôҪ������䵽����������ȥ�ء�
�����������в�����ȥ�����κβ�����,��zero-shot��,�����һ�������������
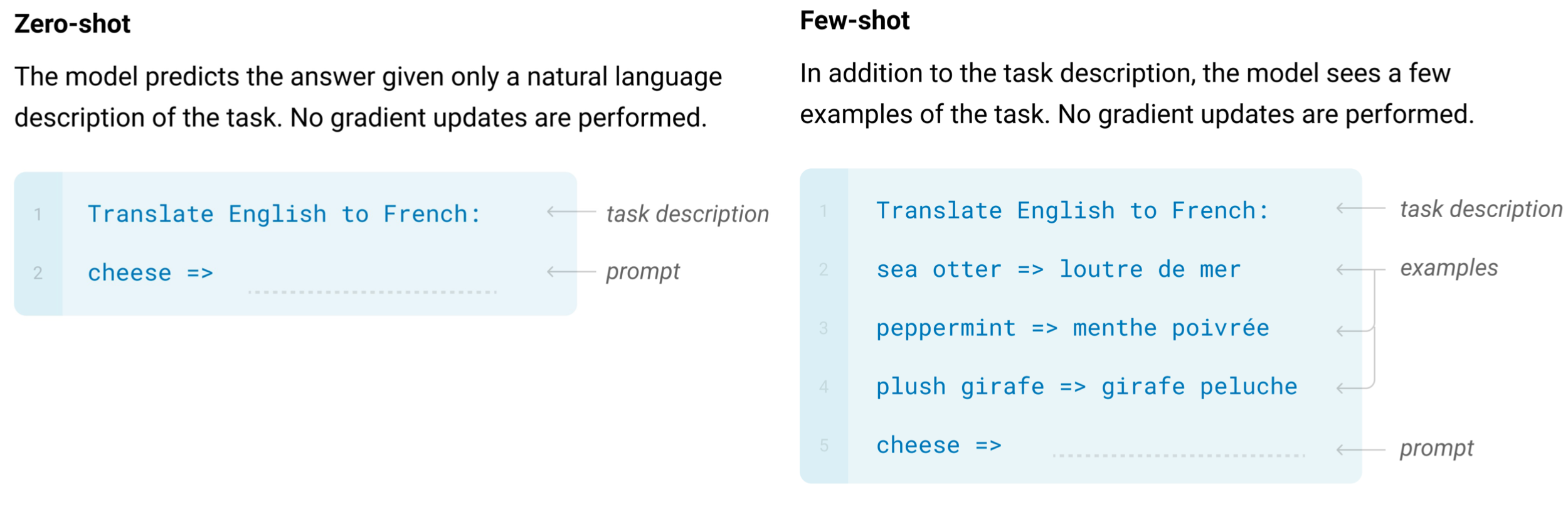
������ͼ�еİ�Ӣ���ɷ���,Ȼ�����һЩprompt,�������cheese =>��
����few-shot�л���zero-shot�Ļ����ϸ���һЩ��������,Ȼ��Ҳ����prompt��
ע��������������,��û���κβ����������ġ�����������Ϊin-context learning�����ô�ģ���ȿ���������,������û�б�����,������ͨ��ǰ�濴������Щ����,�������ҳ�����һ�ַ�ʽ���������Ӧ������Ķ�����
��������in-context learningΪʲô��������,��������ȫ�ؽ��������
��ʱ���ǾͿ��Է���һ������,�������ģ��ͨ�����и��õı��֡�
ͬʱ�������������㹻��,����������ѧϰһЩ�µ�֪ʶ,�������ǰ�����ڻ���ѧϰ�д�δ������ĸ��������������WebGPT��������ģ�����������IJ���,����ȥ����������֮ǰ�ܶ�ģ�ͻش��˵Ĵ𰸡�
����ģ��Խ��Խ���������,���ǻ����Կ���ģ��Խ��Խ��������Ϊ��Ҫ�������еIJ���,����110�ڲ������е�ģ�Ͷ��Dz���ʵ�ġ�
������ʵ����,Ϊÿ��������һ��ģ��,��Ϊ����������ҪΪÿ������/ÿ�����ݼ��洢һ�����õ�ģ�͡�
������������ǵ�����,��Ч������ģ�͡�
���������ĸ�Ч��Ϊ��������,�ֱ��������Ż��ĽǶȡ�������Ҫ���ܵļ�������prompt-learning��ʵ���Ͼ��Ǹ�ģ������һЩ�����������,Ȼ����������������Ҫ��һЩtoken������������Щtoken���к����Ĵ����������������ɵȡ�
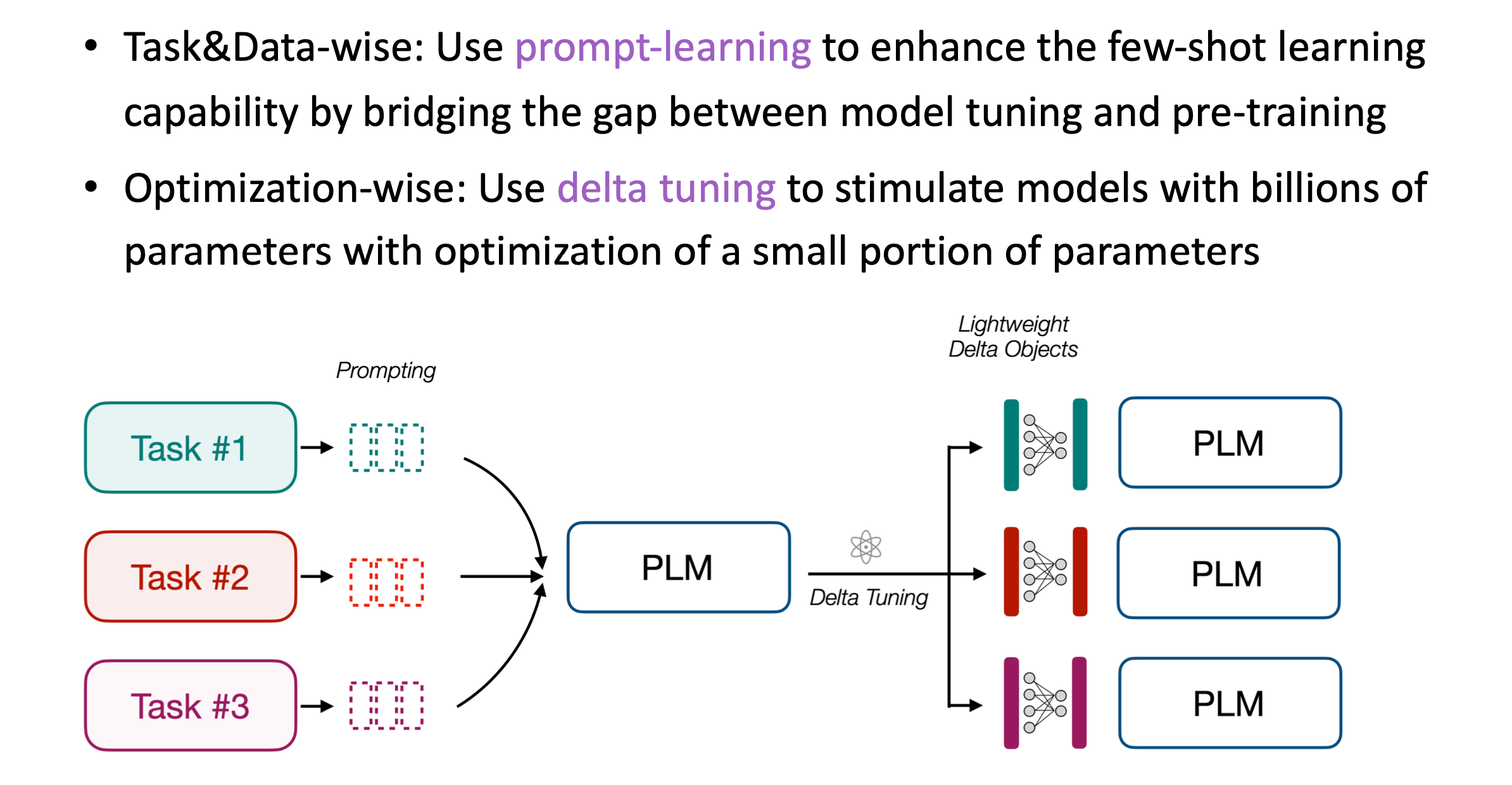
��Ҫ�ĺ��ľ���������֯����,��������prompt��
T5�����ܼ�һЩdemonstration����GPT-3��ȻҲ�����һЩprompt,�������Ƕ�û�ж����prompt������,�Լ������������ɵ����token��ô���д��������и���������о�����Ҳ�����һ����������,��prompt-learning��
�����Ѿ���һЩ��Ϊ����ķ���,����������promptȥ������ģ�͡�
���Ż��ĽǶȳ���,����Ҫ�˽����delta tuning��ʵ�������Ƿ���,��ģ���ر���ʱ��,���ǿ�����С�������Ż�ȥ������ģ��,�����Dz���Ҫȥ�Ż�100�ڻ�1000�ڵIJ���,���ǿ���ֻ��Ҫ�Ż�����ǧ��֮һ�����֮һ�IJ���,Ҳ�ܴﵽ��ȫ����������Ч����
Prompt-learning
�������
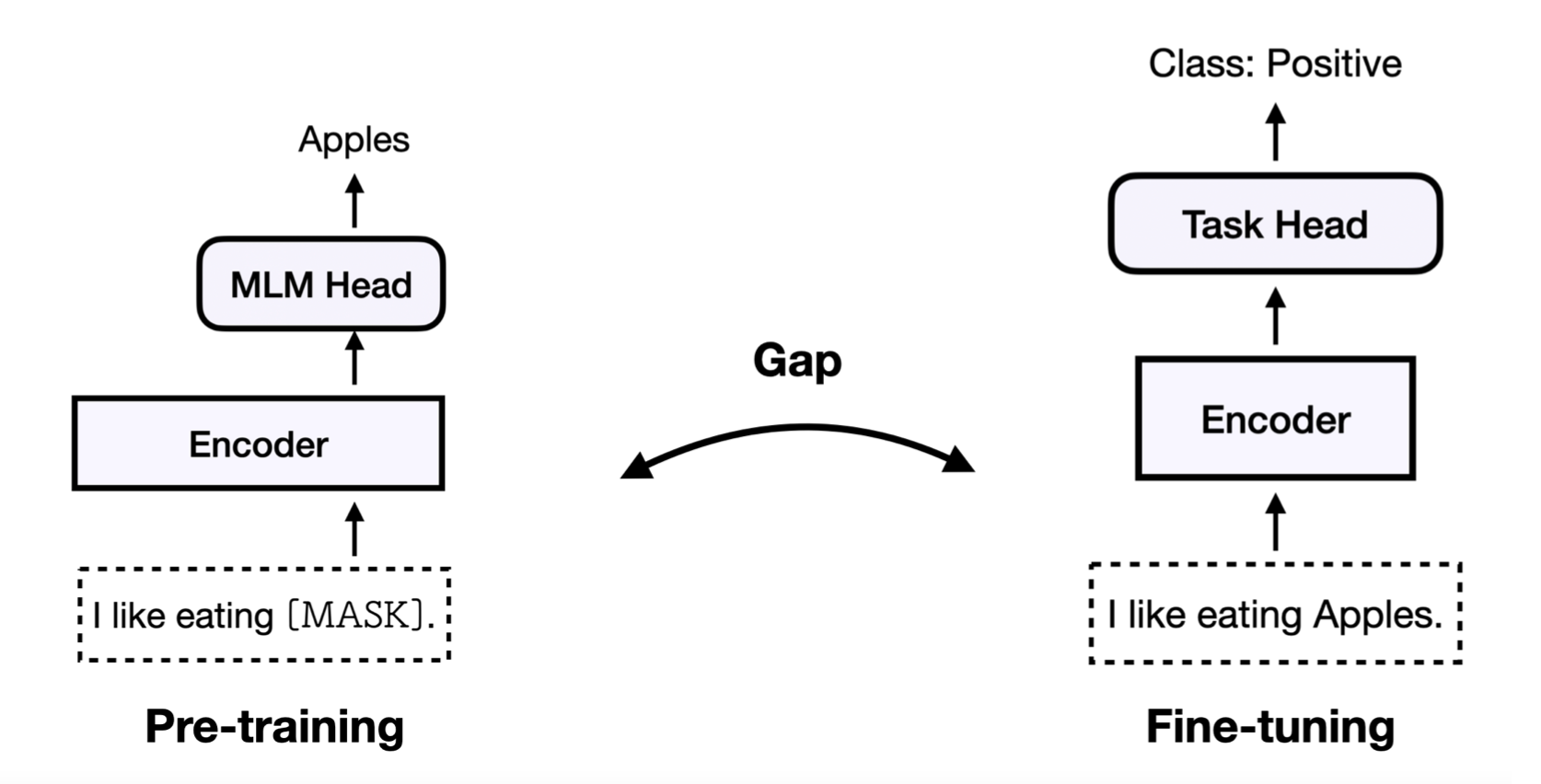
���ǻع������Ļ�����ʽ,����Ԥѵ���б�����һ��MaskԤѵ������,����һЩ�������ǻ�mask��,Ȼ����MLM Head��Ԥ�ⱻ�ڸǵĵ�����ʲô��
����������˵,���ǰѸþ������뵽Ԥѵ���õ�ģ����,Ȼ��ͨ��һ������������ʼ���ķ�����,ȥѵ�����������ΪPositive���
�������ǿ��Կ���,Ԥѵ������֮����һЩGap(����),��Ϊ�������IJ�����ͬһ���¡�������Ԥѵ�����������Dz���֪���ں��滹Ҫ��һ������,��ʵԤѵ������ֻ��ȥԤ�����maskλ�õĵ��ʶ��ѡ�
����������,����û��ȥԤ������mask�ĵ���,Ȼ�����Ǹ�����һ���µķ����,��ģ��ȥԤ�⡣
����gap���ǿ��Ժ���Ȼ����promptȥ�ֲ����������������
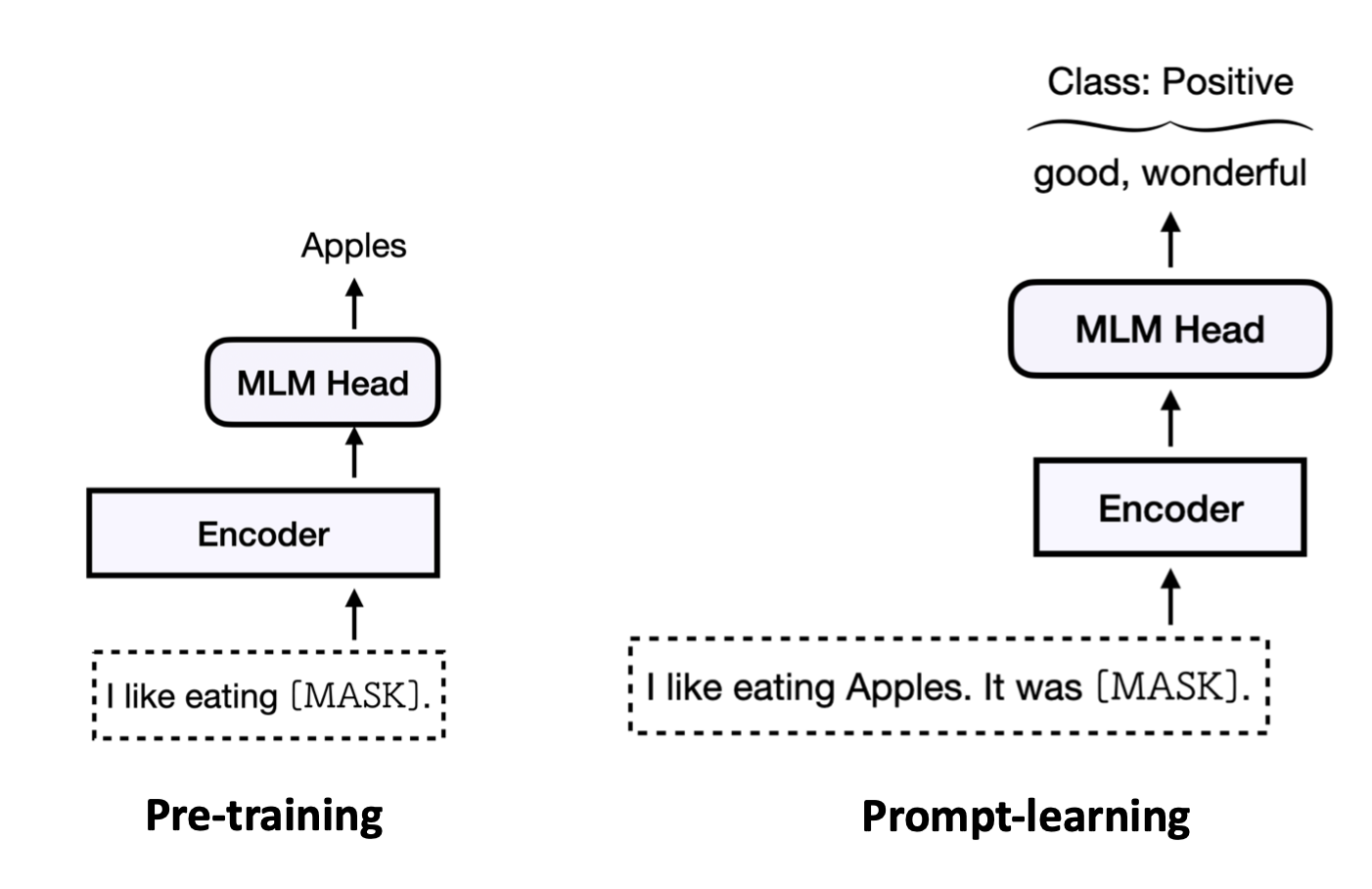
����һ�������ʵ��,���Ǹ�����һ�仰��"it was [mask]",��һ��prompt,ͬʱ����Ҳ������֤��һ����Ԥѵ������һ������ʽ������Ԥѵ���е�MLM����,��������Ҳ��mask����ʽ,��ģ��ȥԤ���maskλ�õĵ��ʡ������Ԥ�����Ԥѵ����һ���Ķ���,�����ʵĸ��ʷֲ���Ȼ�����Ǹ��������������ʱ��ϵķֲ�,ֻȥ��ȡ����������Ҫ�Ĵʡ�
����˵��һ����з�������,��ô���ܻ���һ��������ࡣ��ô��������,����good��wonderful�����ִ�����������;��bad��terrible���ִ����������ࡣ
�������ǵõ��������ʱ��ϵĸ��ʷֲ�,��ʱֻ��Ҫ�Ƚ�����ʵĸ��ʺ���ʵĸ���,�����ĵ������Ƕ�����Ҫ����,���ǾͿ���֪�����������ֳ�����һ�ࡣ
�������Ƕ������ӵ����������(��it wat [mask]��)���dz�֮Ϊģ��(template);
�ѱ�ǩӳ�䵽��ǩ���ʵ�ӳ������Ϊverbalizer;
��ʱ���ǿ��Ժ���ȷ�ؿ���,��ֱ����,���ƺ���Ԥѵ������֮���gap���ֲ������ˡ�
��Ϊ,����prompt-learning֮��,������������,����Ҳ����MLM����������Ԥѵ���������ġ�
ʵ����,������������һ���ô���,���Dz�����Ҫ���Ǹ�������֮�������ͬ��һ������,����prompt���õIJ�ͬ,����verbalizerѡ��IJ�ͬ,��ô���Ѳ�ͬ�������Dz�ͬ�ķ��ࡣ
�����Ϳ������еķ���,����������������ͨ��prompt������֯��ͬ��һ����ʽ��
����֮ǰ˵��BERT,����һ��˫��ע�������������������ɵ�,�����ǿ��������ַ�ʽ,����һ������һ�����ʵ�ȥ���ɡ�
����˵GPT�������ɵ�,��̫�ʺ���������������Ҳ�ǿ��Ը��������ɵ��Ǹ�mask����֮��Ĵ���,��verbalizer���ȡ�����õ���,�������ﵽһ������ȥ�����Ŀ�ġ�
����
��ͨ��ģ�����prompt
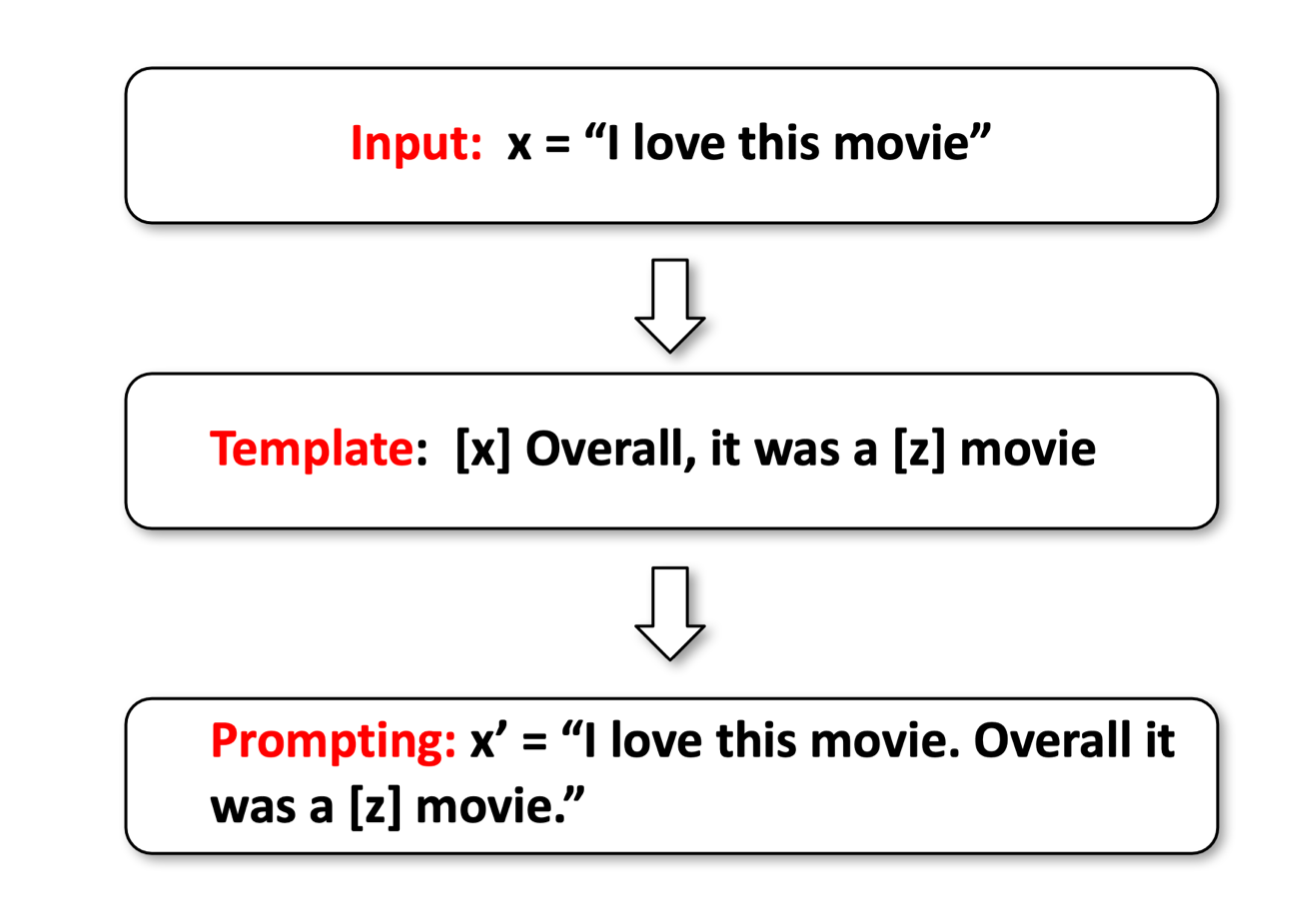
prompt-learning����������ͼ��ʾ,����������һ������x = 'I love this moive'��Ȼ�����Ǹ�����һ��prompt,��� [x] Overall, it was a [z] movie������[z]����ҪԤ��Ĵ𰸡����վ���prompt֮������ݱ����x'='I love this moive. Overall it was a [z] movie.'��
��Ԥ���
Ȼ�����ǰ�������ι��ģ�͡�
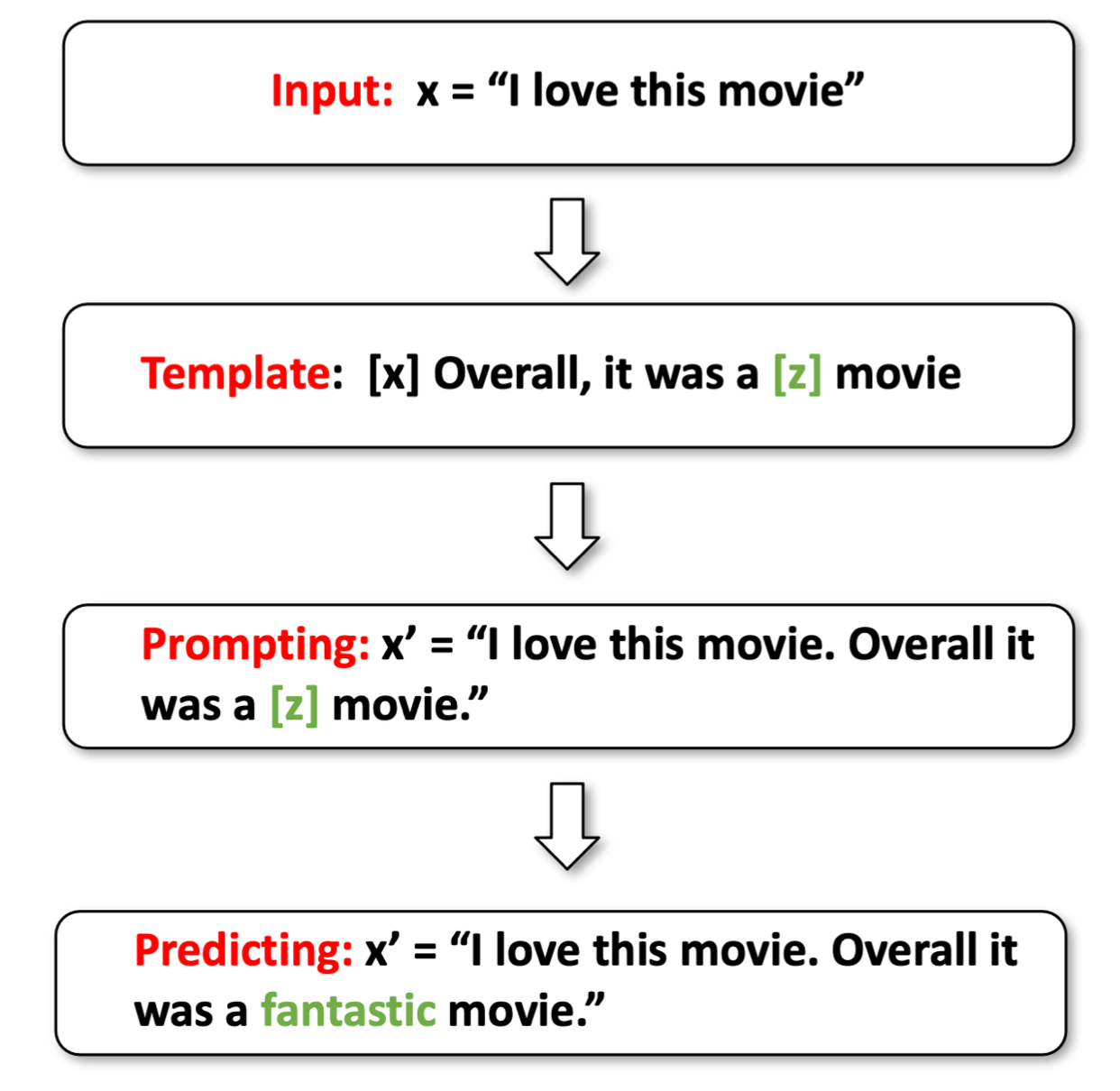
��ʱģ�ͻ����һ���ʱ��ϵĸ��ʷֲ�,������ֻѡ����Ҫ�ĸ������ı�ǩ����,��������ʱfantastic��
��ͨ��Verbalizer����ǩ����ӳ��Ϊ��ǩ��
����������Ϊfantastic��һ��positive���ࡣ
�������Ǿ�ͨ��prompt-learning�����з����pipeline��

���Կ���,������������Ҫ���Ǻܶණ����
��������,����Ҫ����ѡ��ʲô����ѵ��ģ�͡����ǿ��Ը�����Щģ��Ԥѵ���ķ�ʽ��ѡ,������GPTϵ�к������OPT�����Իع�ķ�ʽ����ѵ��һ��������,��������Ȼ��һ������һ�����ʵز������,����ȥ���ɱ�ǩ���ʡ�
����BERT��RoBERTa����ѵ���ı������õ���˫���ע����,������ȥ���������м�mask�ĵ���,��ͬʱ����ǰ��ͺ�������������������ɡ�
ֱ��������,���Իع�ķ�ʽ�и��õ���������,����BERT�����и��õ�����������
������Ƚ��µ���T5��BART���ֱ�����-������ģ��,�ڱ�����������˫��ע���������е�������ע�һ��,Ȼ�����ý�����ȥ�Իع�����ɡ�
����Ԥѵ�����Ե�Ŀ��,����ͬʱ��Ҫ����ģ��ʹ����ʲô��������ȥԤѵ����,�����������˺ܶ�֪ʶͼ��Ԥѵ��ģ��,�������ƺ����ʺ�ȥ���������εĹ�ϵ��ȡ��ʵ��������ִ�������֪ʶ������
�����ڽ������������ҽѧ����ȥѵ����ģ��,�����������ȥ�������ض��������������
������ѡ��Ԥѵ������ģ������������DZȽϹؼ��ġ�
���ģ��Ҳ�кܶ��ַ�ʽ,�����˹��ع���,Ҳ�����Զ���ȥ����,���������Զ���ʽ����һЩ�Ľ���
����Verbalizer��˵,����������˵��һ����ǩӳ�䵽һ�����ʵĹ���,ʵ������������Ҳ�ܶࡣ�����˹���ȥ�����, Ҳ�����ö����֪ʶ(�ⲿ��֪ʶ)ȥ��������
Ԥѵ��ģ��ѡȡ
Auto-regressive
���ѡ������Իع������ģ��,����GPTϵ�к�OPT�ȡ�
��ʱ��promptģ��,һ����mask�ʷŵ����:

�����Ļ�,�����ܲ�һ���������ر��ı����������ڼ��������ģ��,�����������Իع�ķ�ʽȥѵ���ġ�����ѵ����ʽ�dz������ڳ���ģ�͡�
�������������ɷ�ʽ�������Ķ���,����DZ���Ƿdz����,������������ʽ�Իع��ģ�������ij�Ϊ��������
������Ҫ��������ģ��,��ômaskλ��Ӧ�÷ŵ����
MLM
�����Ҫ�����������ķ�������,���ܸ��õİ취��һ��BERT��RoBERTa��
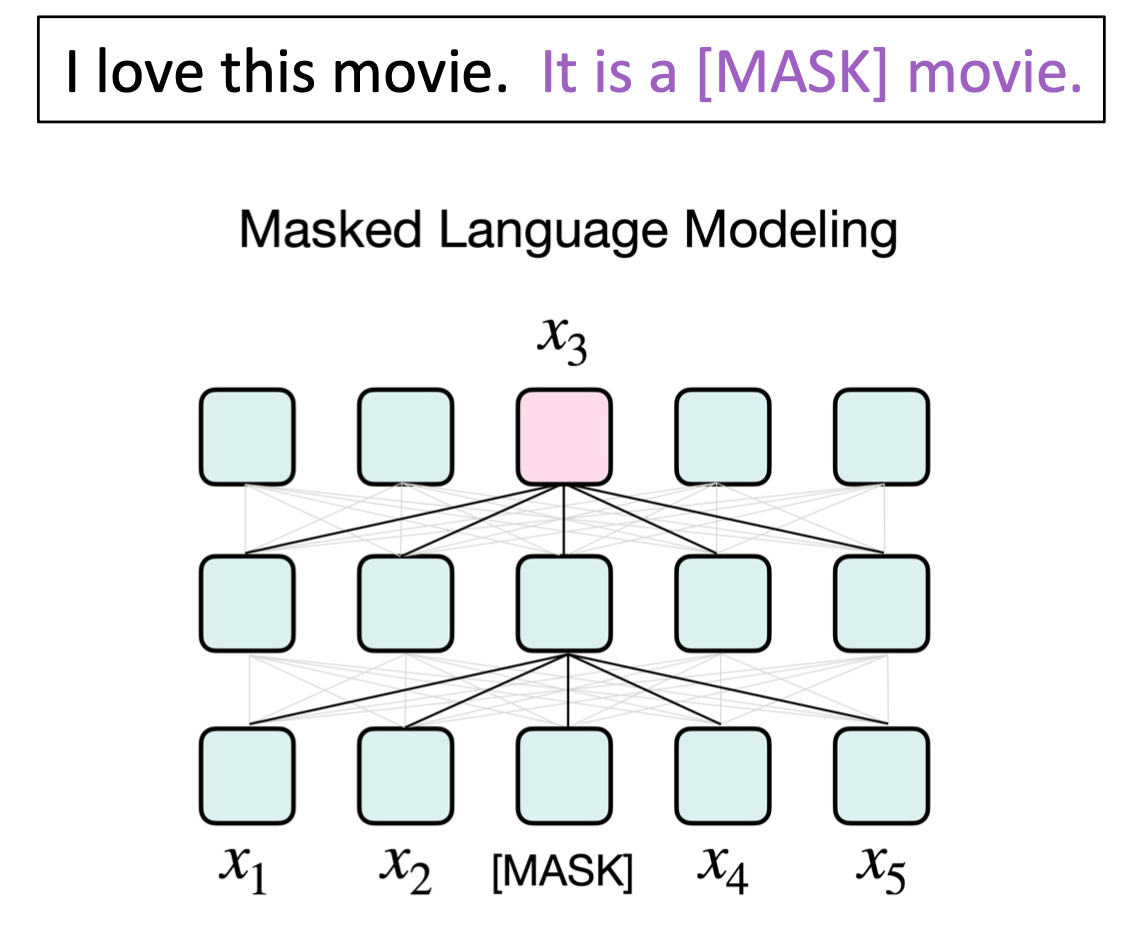
����ģ�ͱȽ���������Ȼ��������,��ʱmask��λ�ÿ������м�,Ȼ��ע��ǰ��������ġ�
�����������ģ��ķ�ʽ�Ͳ��þ�����mask�����λ�á�
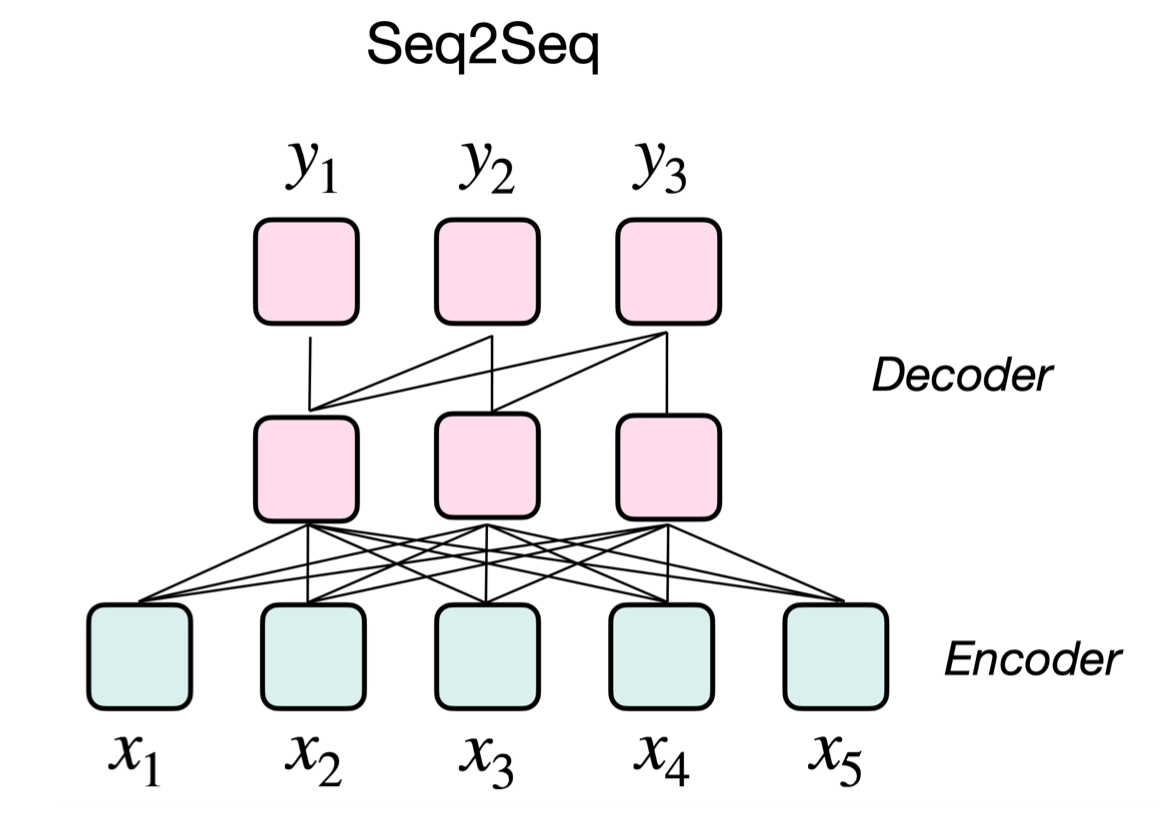
Encoder-Decoder
Ȼ����T5ģ��,ʵ������ѵ����ʱ��,���Ѿ�����һЩ��ν�ıȽϼ�prompt��
��û������������,��ϸ��ָ�����prompt���Գ�ʲô����Ҳû��˵������������������Щ����֮��,���ɲ���������һ���ش�����
T5ģ����һ���ô��DZȽ�ͨ��,û��˵���Իع�ģ��������ô���ó�������,�ֲ���BERTģ���������ó������ɡ�
Template����
���Ǹղ�˵����Щģ��(template)��������Ϊ����ġ�ȷʵ,���ǿ���ȥ��Ϊ����ģ��,������ʵ֤��,��Ϊ�����ģ��Ч��һ�㶼ͦ�á�
��ʱ����Ҫ���������������ʲô,�����ϵ��ȡ���ı����ࡢ�Ի��ȵ�,����Ҫ������������������첻ͬ��ģ��,��ʱ������Ҫ���˵�����֪ʶ��
�����˹��ع���,���ǻ�����ѡ���Զ����ɡ����������ɻ������㷨��������Щģ�塣
���ǻ�������ģ�����ʽ�������ı�,��ģ�岻һ�����ı���,������������һ��û��������ַ������û��������ַ���Ƕ������,Ȼ������ͨ��ѵ�����Ƕ����ʹ�����бȽϴ�����塣
��������������ģ����нṹ��Ϣ,���ߴ����������֪ʶ�������Ǹ��������ģ������ӡ�
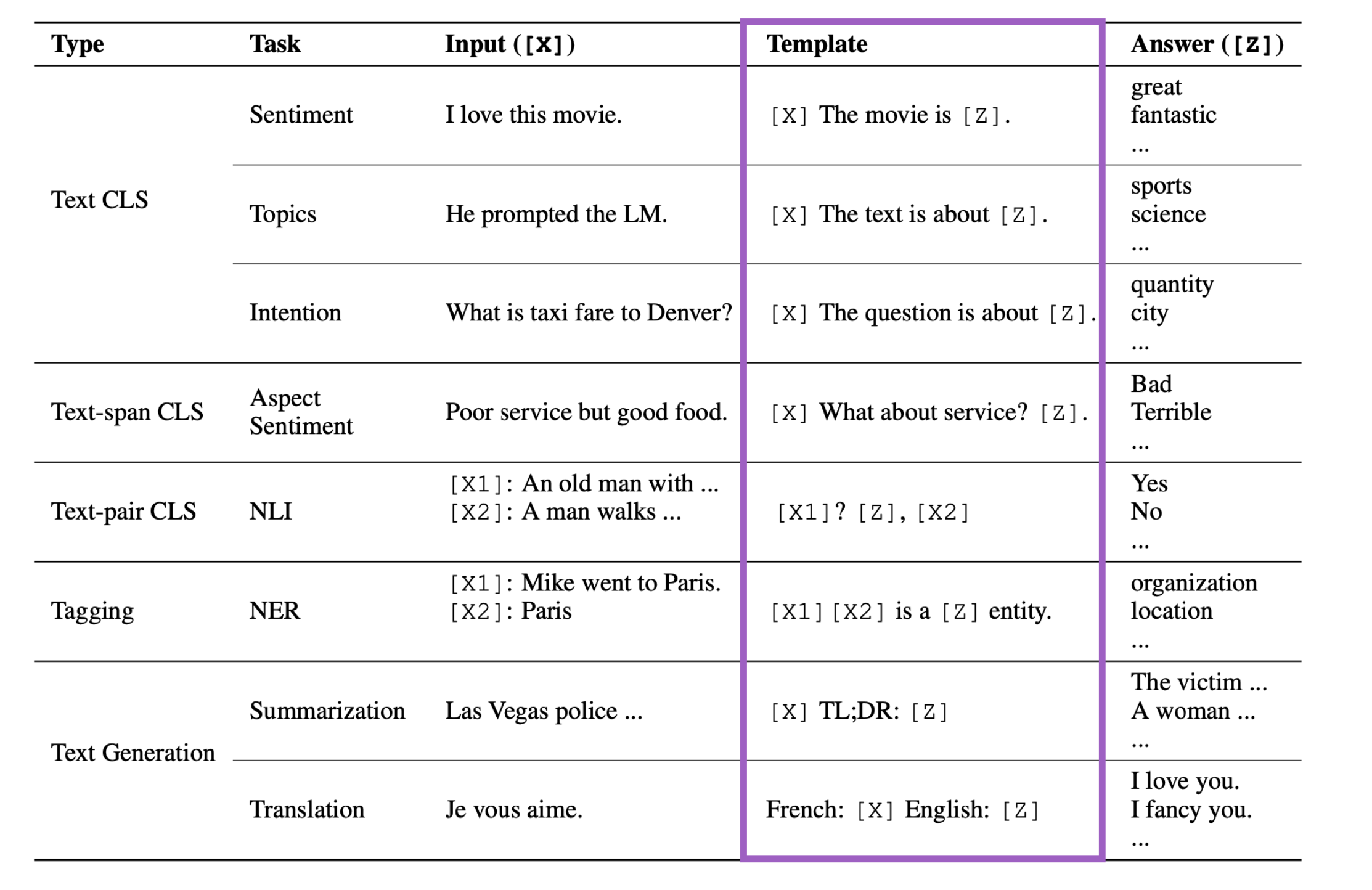
���Կ���,���ڲ�ͬ������,����ȷʵ�����������������֪ʶ���趨��ͬ��ģ�塣
�������ı���������(Text CLS)�е�Topic(�������),���ǵ�ģ�����˵"The text is about [Z]"��
��Щģ�嶼��������ݲ�ͬ���͵������������ġ�
ʵ��������ģ����淨�Ѿ��ر���ˡ�

������ڹ�ϵ���������,����������"London is one of the biggest cities in the world."
����Ҫ��һ��ģ��,���ǿ���"London"���Ƶ�ģ����ȥ,Ȼ�����"is a [mask]",����ģ��"London"��ʲô���
��������ÿ������,��ģ�忪ͷ�ĵ��ʶ���һ��,��ʾ��ͬ��ʵ�塣���������ʵ�����,�Ӷ��ﵽ��ȡ����֪ʶ��Ч����
ͨ����������,��������/�����������ϱ����ر�á�
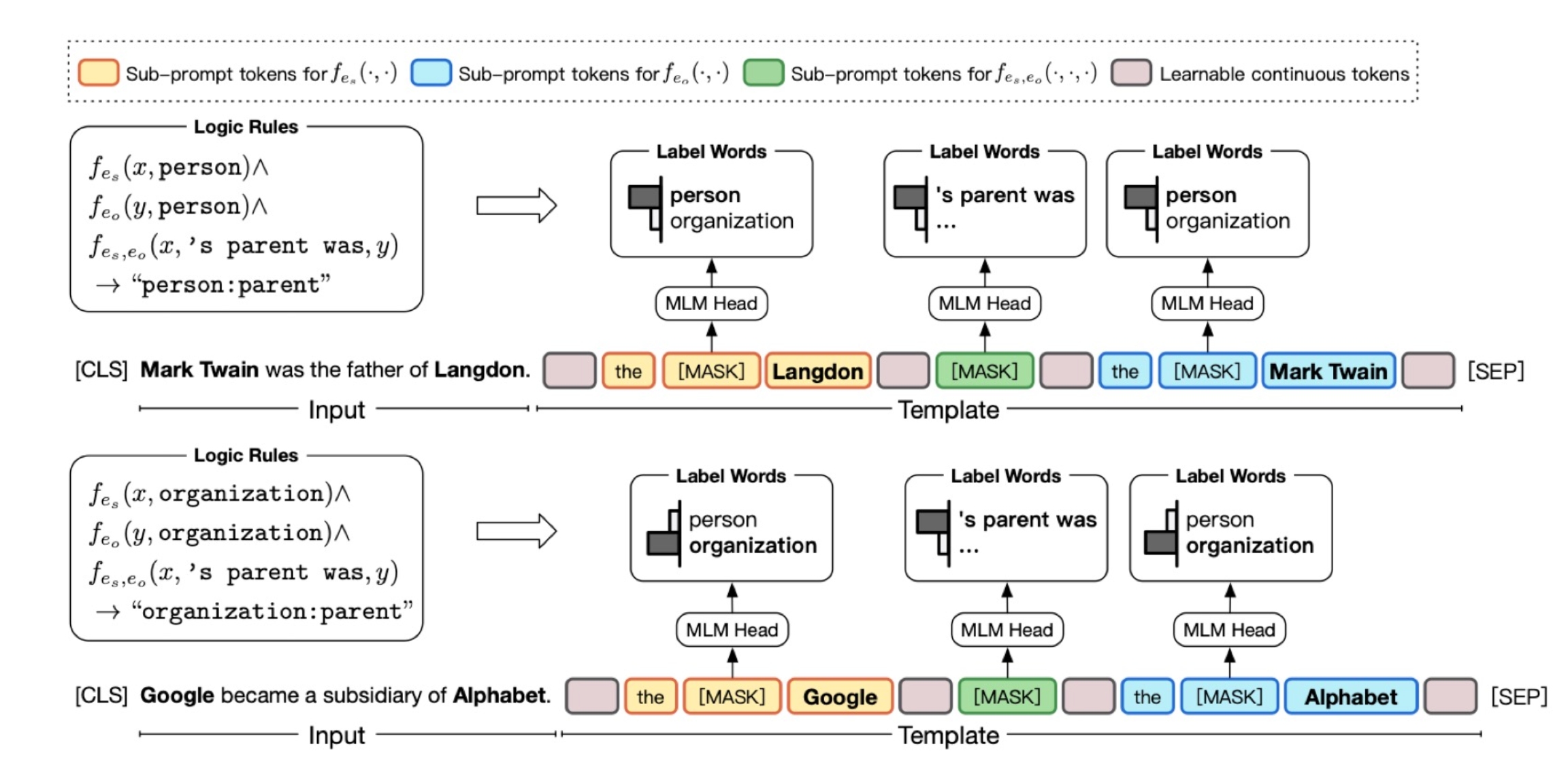
Ҳ������ģ���÷dz�����,���������Ҫ��ȡ"Mark Twain"��"Langdon"�Ĺ�ϵ��
�������prompt��ʱ�������һЩ��Ϊ���ƵĹ���,���Ҫ��֤ʵ��֮���ϵ�����,����Ҫ��֤����ʵ�屾��������ȷ�ԡ��������������һЩ��Լ,�Ӷ��������չ�ϵ��ȡ�����ȷ�ȡ�������ͼ�е�"x��s parent was y",����Ҫ��֤x��y����person��
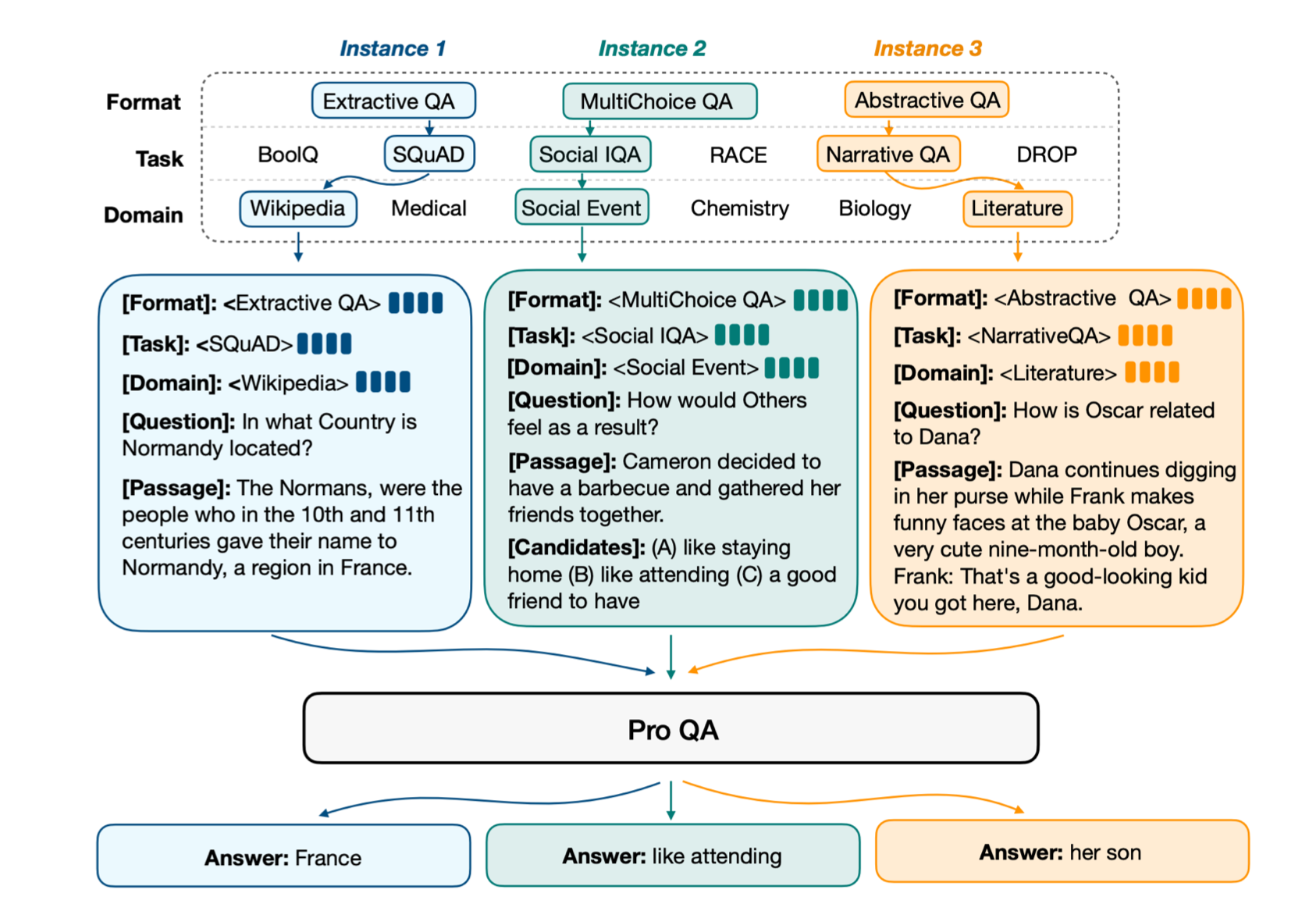
�����Խ�һ���ظĽ�,�������һ���ṹ�������ݡ����ʴ�����Ϊ��,��ʵ�ʴ��������кܶ����ʽ����Щ�Ǵ��ı��г��һ�λ�,��Щ�Ǹ������ѡ��,����Щ��ժҪʽ�ġ�
��ʱ���ǿ�����Щprompt������֯,�����������һЩ��ֵ�ԡ����ȶ���һ��[Format]��ʾ��ʽ��������,Ȼ����һ��[Task]��ʾ���ݼ�����ô��,������[Domain]��ʾ����;Ȼ����[Question]��[Passage]��
�������е����붼�Ǽ�ֵ�Ե���ʽ,��ô���ĺô���,����ģ��Ӧ����ʲô��ͨ����������,Ȼ�������,���Ը��õ���ģ���ڲ��Բ�ͬ��������һ������,�Ӷ��������������ԵĴ𰸡�

�ղ������˽�Ķ�ֻ��һ��ģ��,ʵ���϶�ͬһ������,���ԾۺϺܶ��ģ�塣Ȼ������Щģ���[MASK]��������,���ϵķ�ʽ��ƽ���ͼ�Ȩƽ����
����Ϊֹ,�����˽��prompt�����˹�����ġ���ô�Զ�������prompt���������ء�
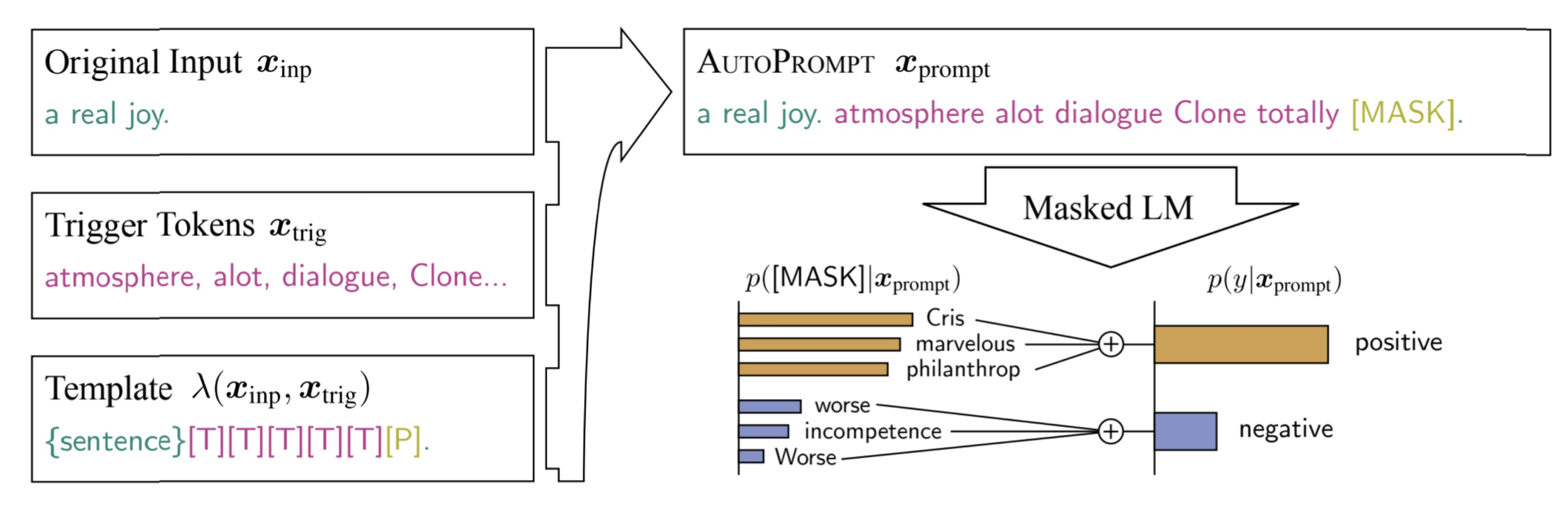
������������,������һЩ��������,Ȼ����һ��promptģ��,����ÿ�����ʶ�����mask����ʼ��,ͨ��������ǩ�ĸ������Ż���Щprompt��Ƕ��,Ȼ�����Щ�����������ҵ����Ż����Ƕ������Ӧ�ĵ��ʵ���prompt����ᵼ��������ɵ�ģ�忴����û��ʲô���庬��(���岻ͨ),������������Ч��,���������ඨ���prompt������Ч��
���������һЩ��ʾ,����ͨ��prompt��Ŀ���Ǵ���������Ҫ�ĵ���,ʵ�����Ⲣ��һ����Ҫ�����ֱ�������塣Ҳ����˵,��������˵����õ�,��ģ�Ͳ�һ������õġ�
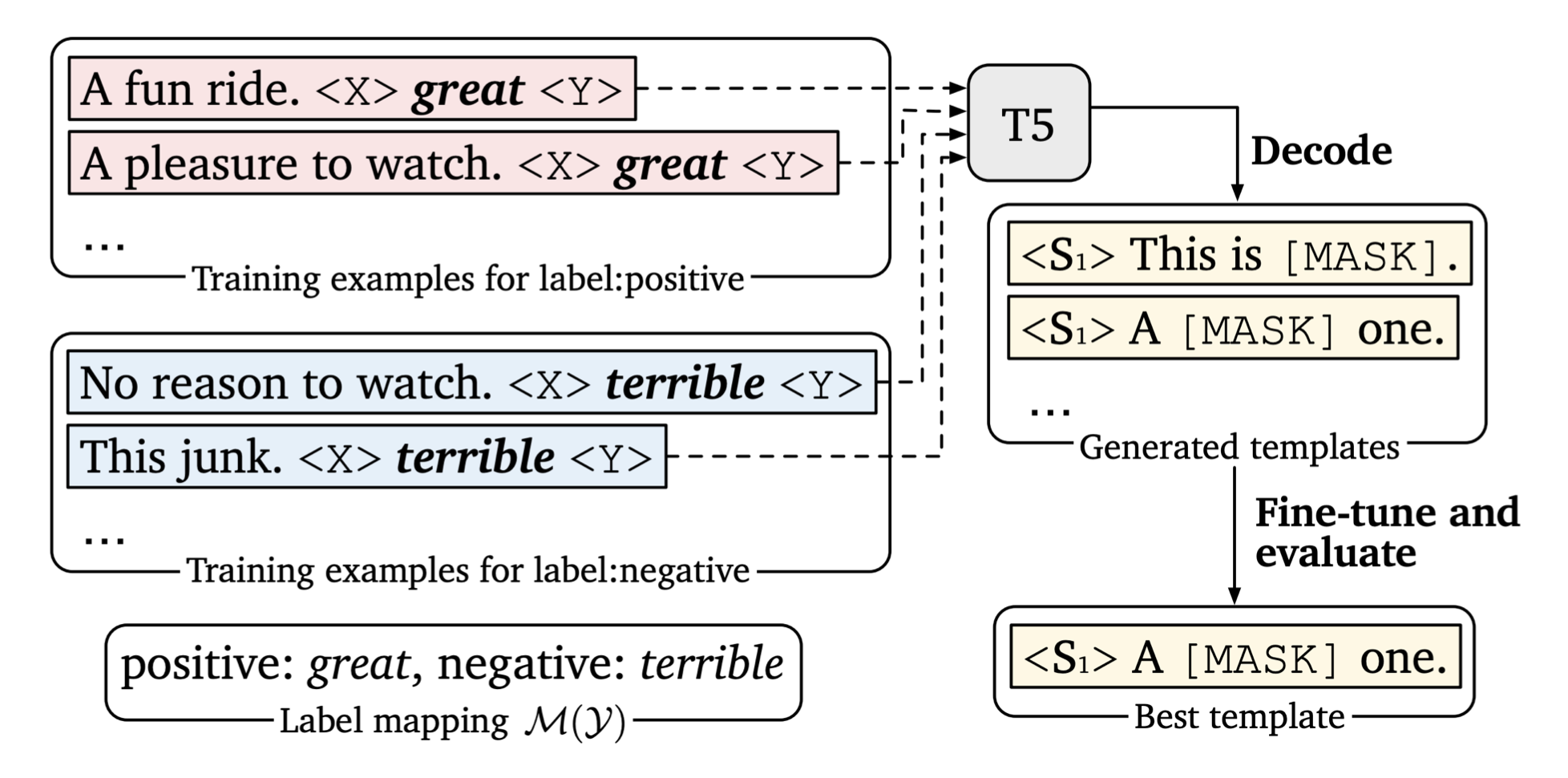
����һ�����������ö����ģ��������prompt,�������һЩ��з���������ֱ��ι��T5,Ȼ����Щprompt������Щ���ݺ�õ���ȷ����ߡ�ѡ����ߵ���Ϊ���յ�ģ�塣
����������˵��prompt�����ı�,����Ҳ����ͨ��������ַ�������prompt��
����֪���ʵ���ÿ�����ʶ���һ��ID,��ʱ��������һЩ�µ�ID,��Щ��ID���ڵ�Ƕ������þ�ID��ȥ��ʼ��,���ҿ�������ѵ��������,�Ӷ�������һ������ģ���ĺ���,�����prompt learning��
Verbalizer����
Verbalizer���ǰѱ�ǩӳ��ɱ�ǩ���ʵĹ��̡�

���ǿ��ѱ�ǩ����Ϊһ��������,����Ƕ���ʵĻ�, ��ô������Щ�ʸ��ʵ�(��Ȩ)ƽ��ֵ��Ȼ��Ƚ����֮��ĸ��ʡ�
�𰸵���������һ����,Ҳ�����Ƕ���ʡ�
��������chunk:�ɶ������ɵ�һ���ַ�����
�������������ⳤ�ȵľ���(����ģ��)��
�����ķ�ʽҲ������:�˹����Զ����ɡ�
��ô�˹����컹����ҪһЩ����֪ʶ��
- ���ȴ�һ����ǩ�ʿ�ʼ,Ȼ��ͨ��ͬ���ȥ������,ʹ�����һ����ı�,��Խ���ݴ��ʾ���,�����ܴ��������������
- Ҳ�Ǵ�һ����ǩ�ʿ�ʼ,Ȼ����Ҫһ�������֪ʶ��ȥ��������
- Ҳ����һ����ǩ�ֳɶ�����ʡ�
- ������ʹ�ÿ����Ż���ǩǶ������ⵥ�ʡ�
Verbalizer�ı����ǽ�����ʹ��ģ��Ԥ��ֲ�������,����ɷ������������
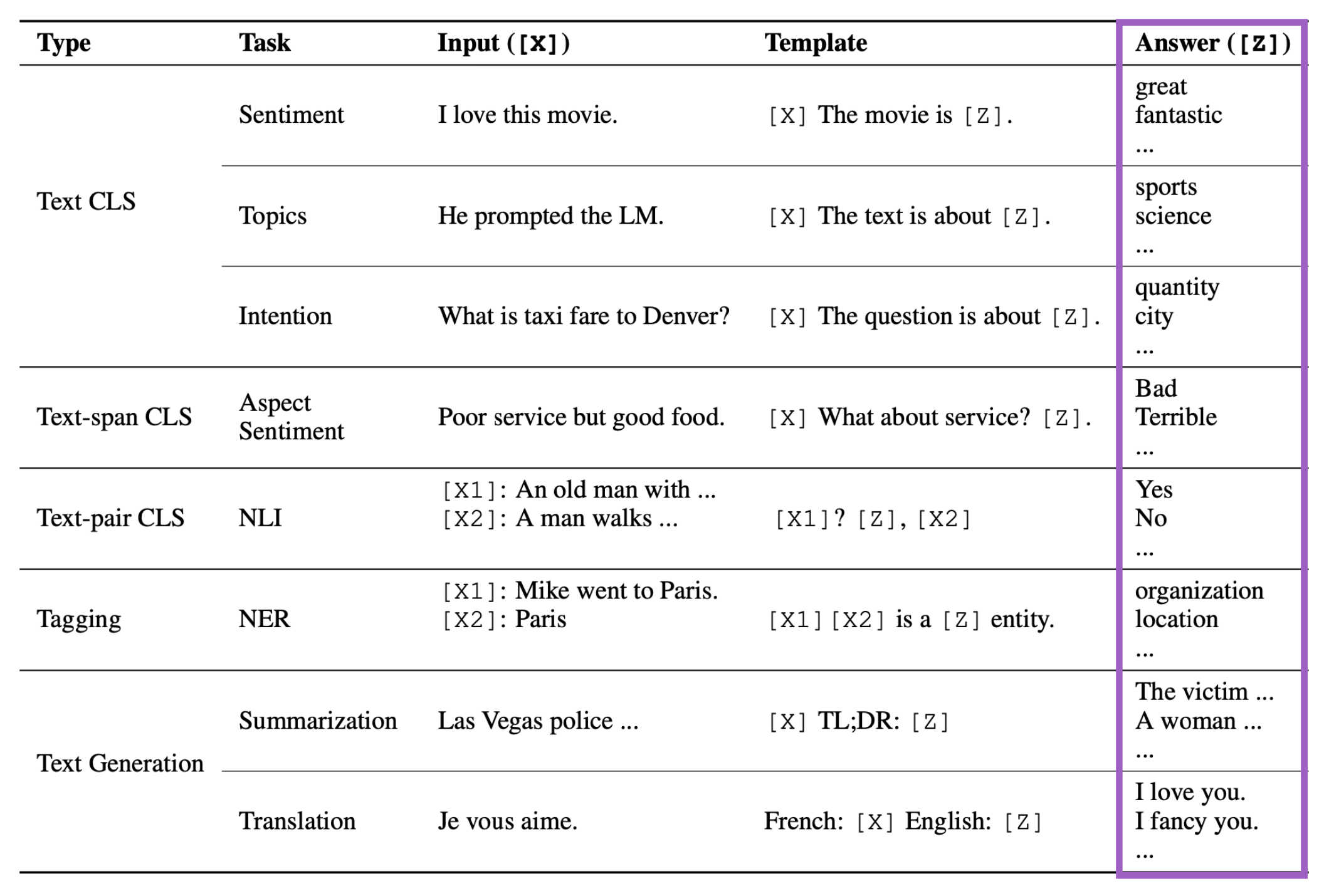
���Ǹղ��Ǹ�����,�������ǹ�ע���ɵĴ𰸡����ڷ�������(Text CLS),��Щ�𰸵��ʶ��Ƿdz�ֱ�۵ġ�������������,��ʵ��Щ�𰸾��������ɵ��ı���
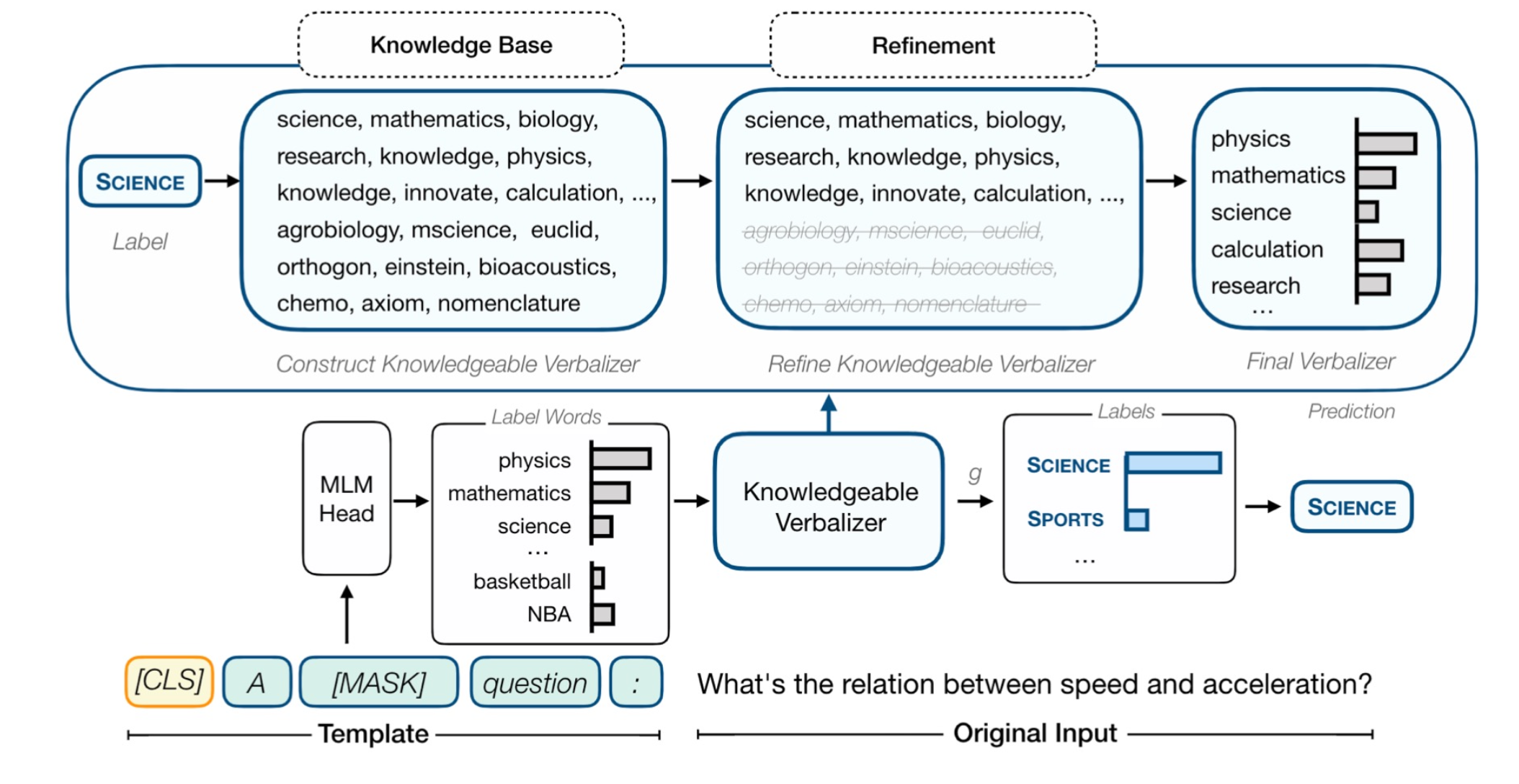
������Ϊ�Ķ���,���ǻ��������ⲿ��֪ʶȥ��������
������һ������:�ٶ�����ٶ�֮��Ĺ�ϵ��ʲô? Ȼ���һ��ģ��,xx question�����MASK��Ԥ����Ϊ����ı�ǩ���ʵĸ���,������ѧ(mathematics)���˶�(basketbal)�����ǵ�ͬ��ʡ�
���Ŷ���һ��verbalizer,�ȸ�����ǩ,���������ǿ�ѧ(SCIENCE)��Ȼ����һ��֪ʶ��ȥ������,����ȥ��������,��ȥѡ��������Ҫ�ĵ��ʡ�
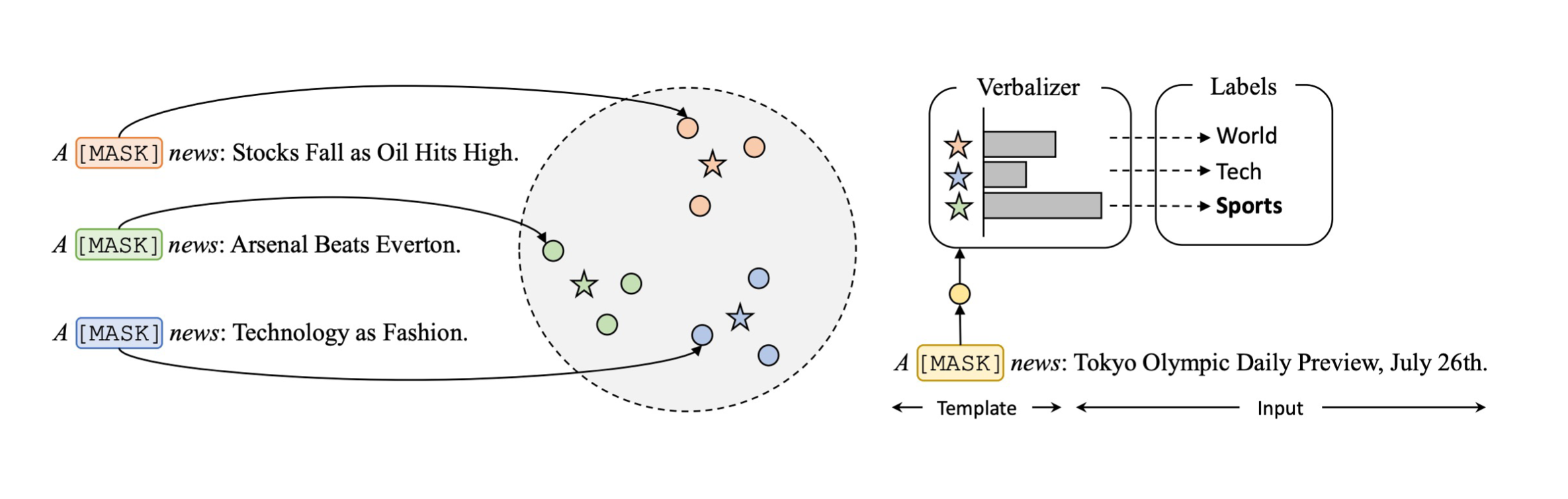
��������������ı�������֮��,������������������ⵥ������ʾ��ǩ���ʡ��������ÿ������ӦMASK������״̬���о���,�ò�ͬ�����ѧ����ͬ�Ĵ�,����Щ���м��Ƕ������ʾ���յı�ǩ�ʡ�
ѵ�����·�ʽ
prompt-learning���������ǵ�ѵ����ʽ�����������ĸı���?
������������ѵ����ʽ���ݻ�����:
- ��ͳ��: �����ʼ�������ѵ��
- BERT֮��: Ԥѵ��-��
- T5: �����ı�-�ı���ʽ��Ԥѵ��-��
- GPT: Ԥѵ��Ȼ��ʹ��prompt&in-contextʵ����/������ѧϰ
������prompt-learning֮��,���ǿ����������
- Ԥѵ��,��prompt��֯����,�����в���(��������С��ģ�͡�����������)
- Ԥѵ��,����soft prompt,�̶�ģ�Ͳ����Ż�propmtǶ��(delta tuning�Ƕ�)
- ��prompt����һ��Ԥѵ��,��������������
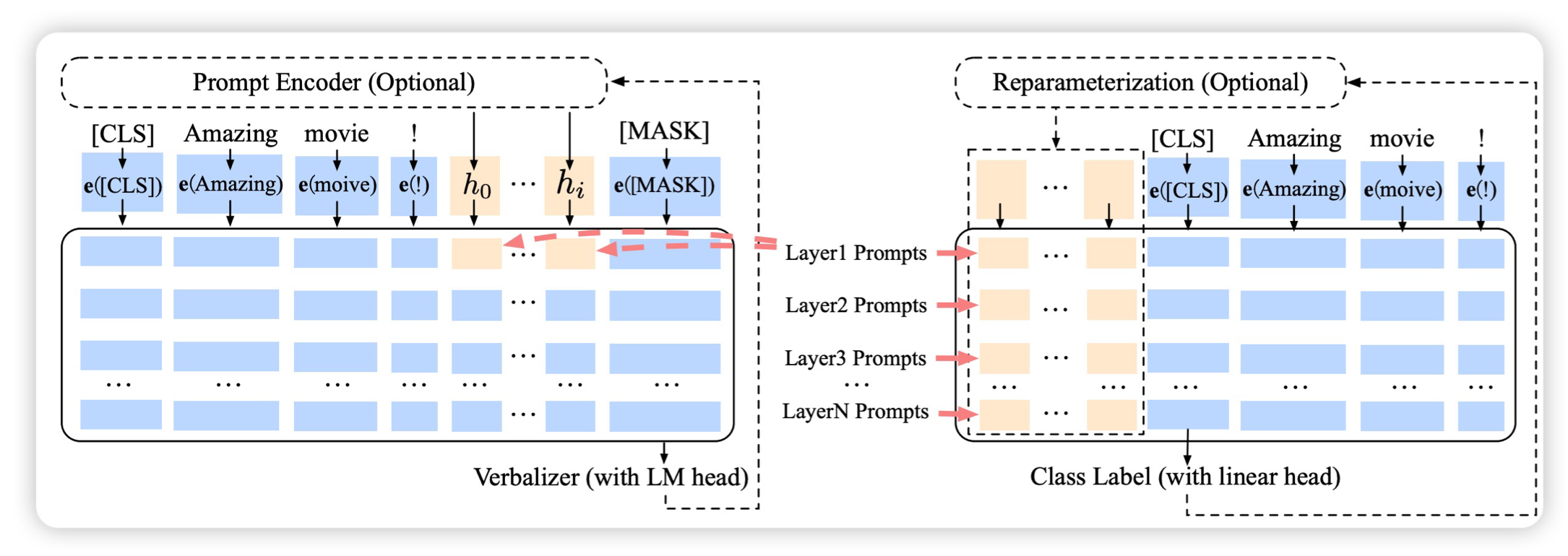
����������prompt-tuning��ͼʾ:
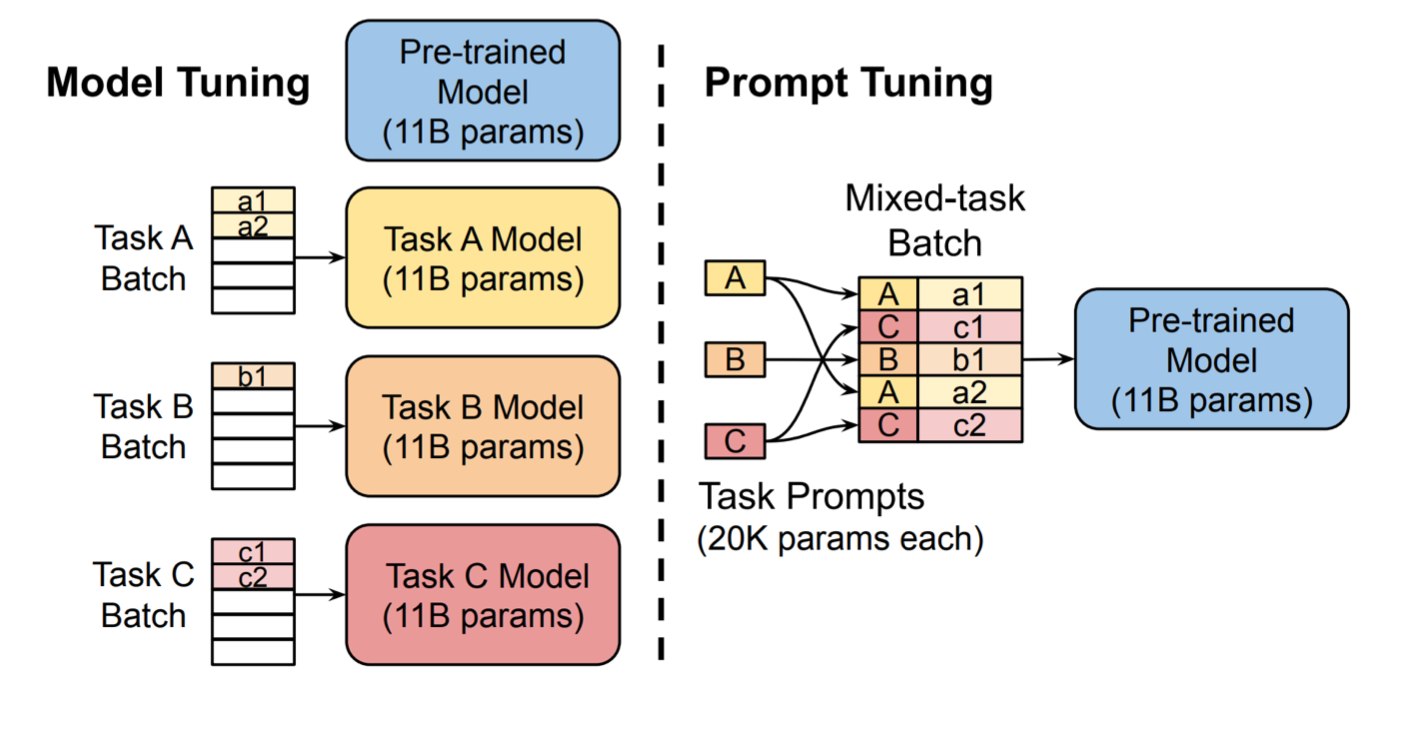
����ע��һЩsoft promptǶ�뵽�����,������ͼ��a1,a2��Щtoken;
Ȼ��ͬ����������ݻ������,ι��Ԥѵ����11B����ģ�͡�
ֻѵ����Щ��promptǶ�롣
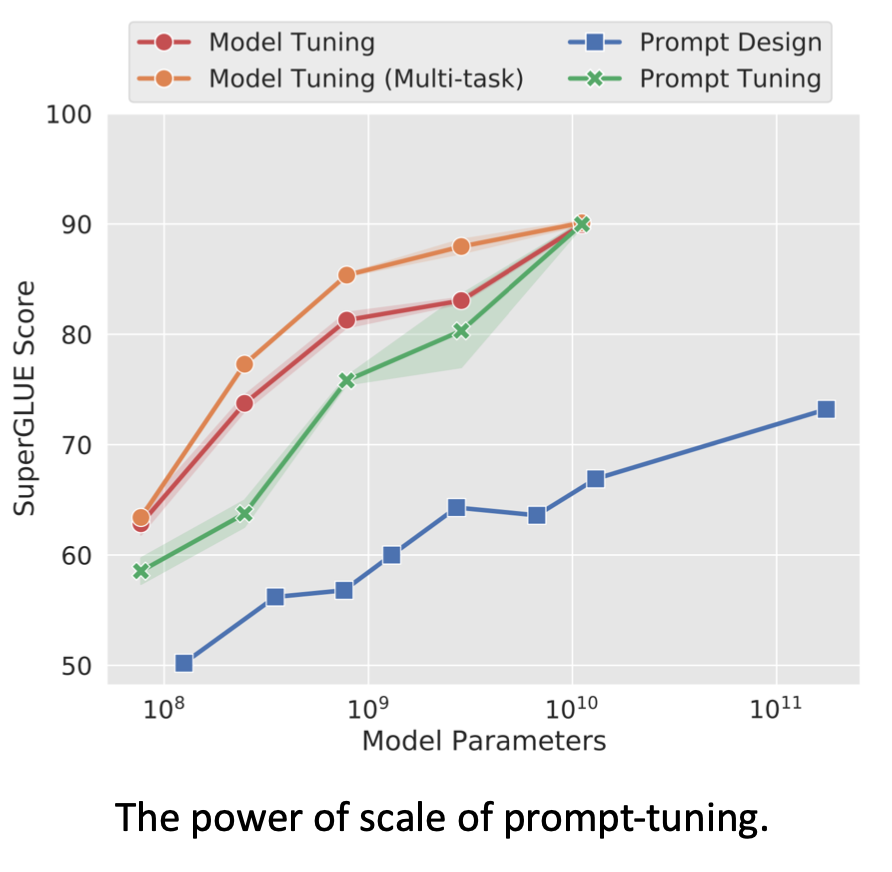
����10B����(
1
0
10
10^{10}
1010)ģ����Ч����ȫ������һ�����Ӷ�ʵ����С����������ģ�͡�
������С��ģ����Ч������ȫ��������
Ҫע�����,����˵��prompt-tuing�������һ��delta tuning�ķ�������prompt��ֱ�����ֲ�Ԥѵ������������֮��IJ���,ͨ���������������ʾģ�͡�����ģ�Ͷ���ס,ֻѵ��prompt�Ļ�,ʵ�������ⷽ���ϵ�Ч����������һЩ��
���ǻ�����soft prompt�ӵ�Ԥѵ����,���������������Ը��õس�ʼ��,�Ӷ������������ϱ��ֵø��á�
�ص��ı������prompt,Ҳ�������Ǽӵ�Ԥѵ���С�
��1300�ڵ�ģ����ȥѵ��60������,Ϊÿ�������ռ�һЩprompt,Ȼ�������δ�����������Ͻ���������
����ͬ�ڹ�������T0��������,��35��������ѵ���˹��趨��prompt,Ȼ����δ������������������
Ӧ��
prompt-learning��Ӧ��:
- ����� NLP������:NLU�����ɡ���Ϣ��ȡ��QA�������
- ����NER������Ҫλ������Ե�������Ӧ���ر��
���ܷ�Ӧ�õ���ģ̬����Ϣ����ҽѧ������
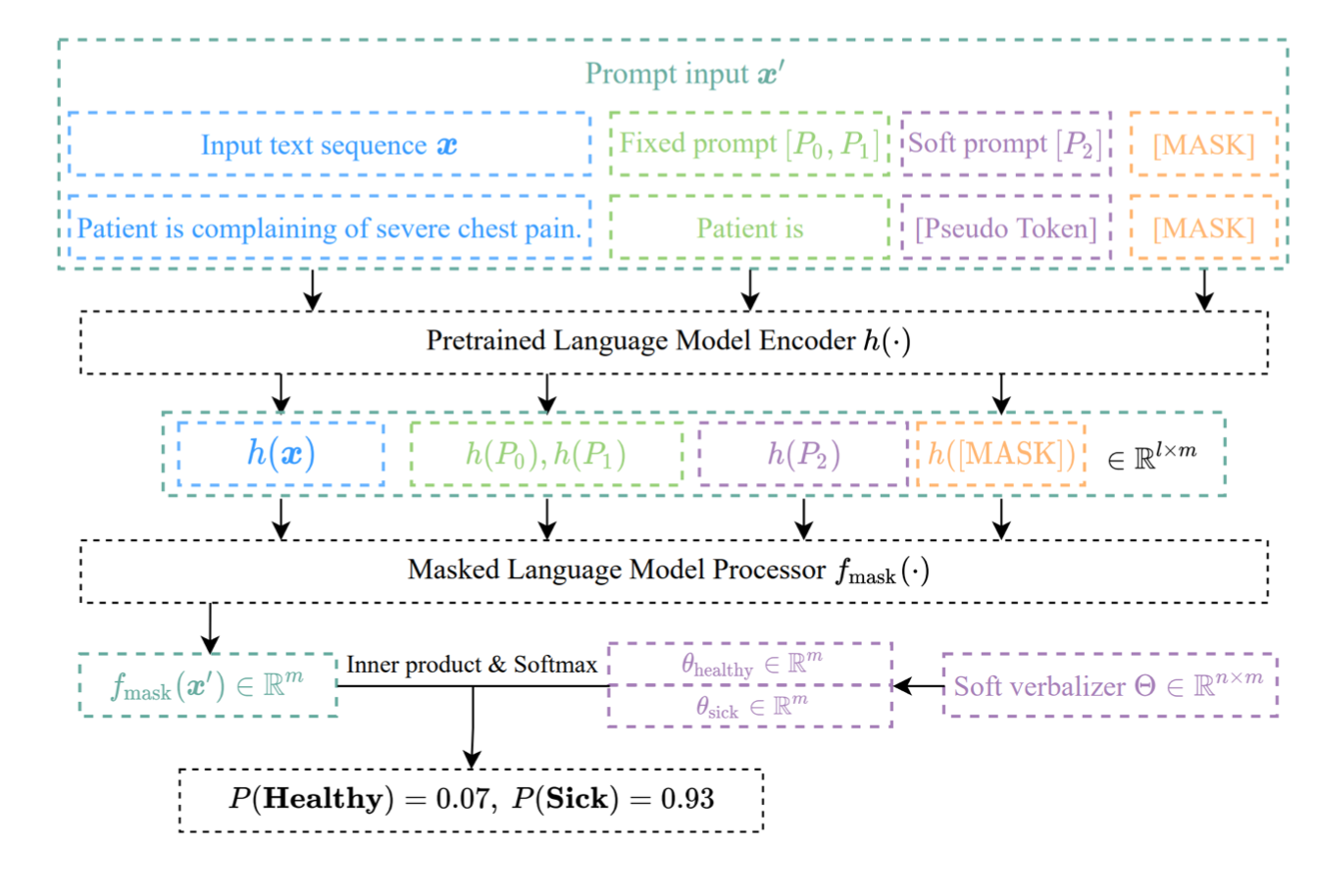
���ǿ��������һЩsoft token,Ȼ������˹������ҽѧ�����prompt,����������Сģ��Ҳ����������ҽѧ������ֵ��ر�á�
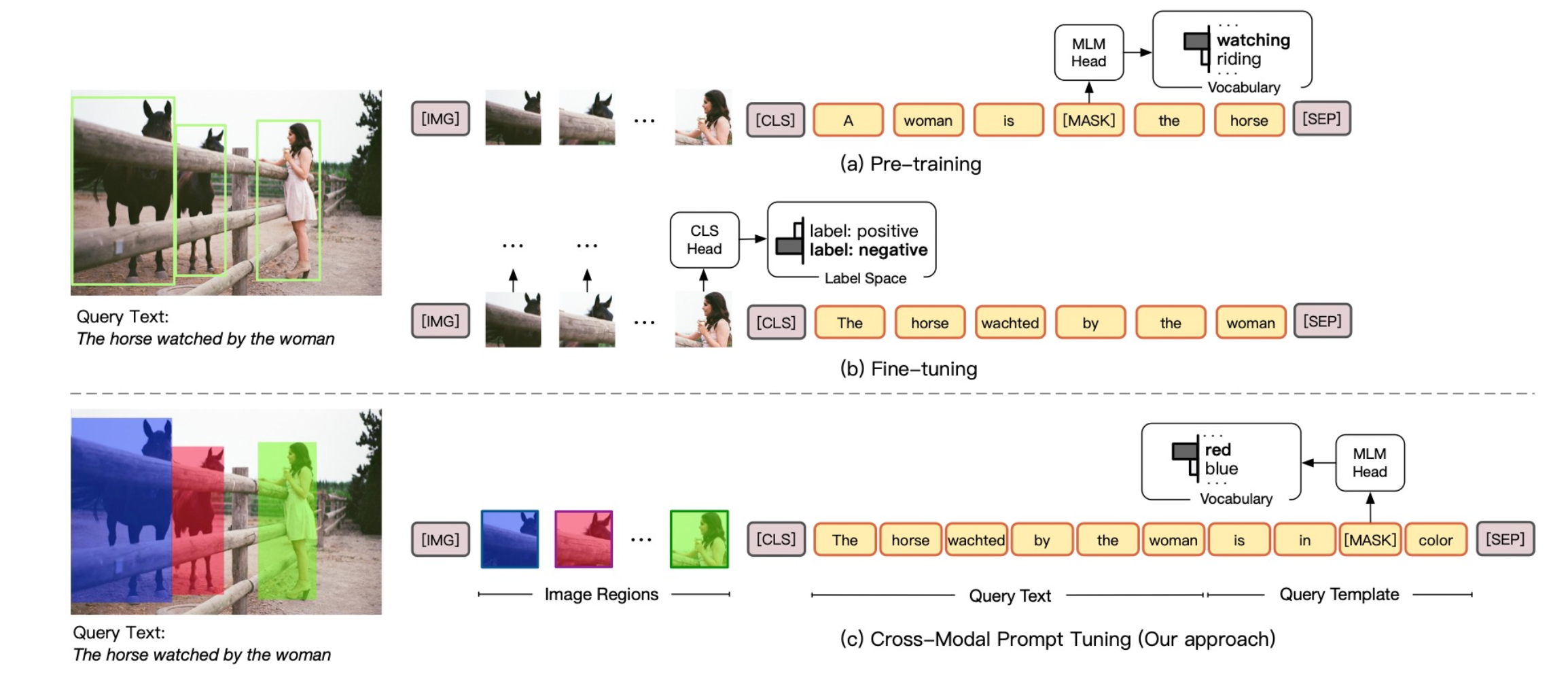
������Ӧ�õ���ģ̬��,��������ѵ��ͼƬ���ı�֮������⡣�������
���ȸ�ͼƬ�ж�����,Ȼ�������ɫ,Ȼ�����ı�����,�������Ů�˱�����ʲô��ɫ���ģ��Ԥ����ɫ��ʲô����,�Ӷ���ģ�ͽ�����ɫ�����ֵ����⡣
�ܽ�
- һ���dz��ۺϵĿ��,������PLM�������������������֪ʶ
- ����ģ���Verbalizer�dz���Ҫ
- �������������б����ر��,������ģ���ѡ�������߷���
- ʵ���Ͽ���Ӧ�õ����ָ����ij���
Delta Tuning
��prompt-learning��ͬ,delta tuning�Ǵ���һ���Ƕ�����Ч����ģ�͡�
˼����ģ�;��ֲ�������,ֻ��һС����ģ��,����������ģ�͡�
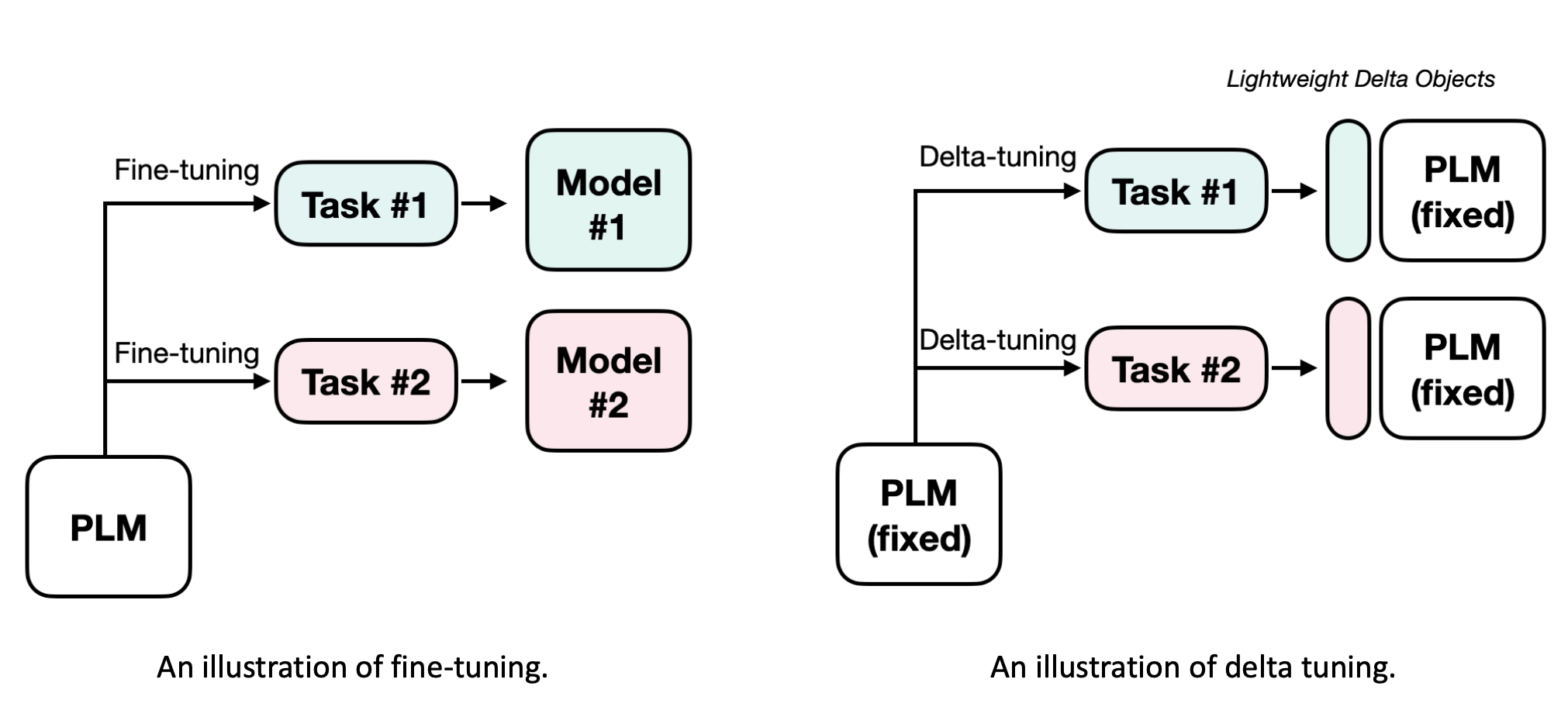
���������
����֮ǰ����ÿ������,���ǿ�����Ҫ��һ����ͬ��ģ�͡����ģ�ͺܴ�Ļ�,��ô������Щģ�͵IJ���Ҳ����һ�����⡣
��delta tuning,����ÿ������ֻ�Ż�С���ֲ���,��֮Ϊdelta����,���ǿ����и��ָ����Ľṹ����Щdelta�������������������IJ�������ʾ��ʵ������Щ������ռ�ռ��С,��ô��û����Դѹ����
ʵ����Ҫ���ǵĵط�Ҳ�кܶ�,����ģ�͵�ѡ��delta���������Ƶȵȡ�

�������Ƕ�һ��BERT,����С�ĸĶ�,���������ڸ��ָ���������
��������Ҫ����Ϊʲô������Ч���������õġ�
ʵ�����ڹ�ȥ�Dz�����ʵ�ֵ�,��Ϊ��ȥ���е�����������������ʼ���ġ���Ϊ��������Ԥѵ��֮��,���˴�ģ��֮��,������delta tuning�ķ�ʽ��
��Ϊ��ģ��ͨ���ල�ķ�ʽѧϰ��ͳһ֪ʶ,�ܶ�����Ϊ���������������,ֻ�ǰ����ͳһ֪ʶ��������������������������,��û��ѧϰ�����֪ʶ,���Ǽ����Ѿ�ѧ����֪ʶ��
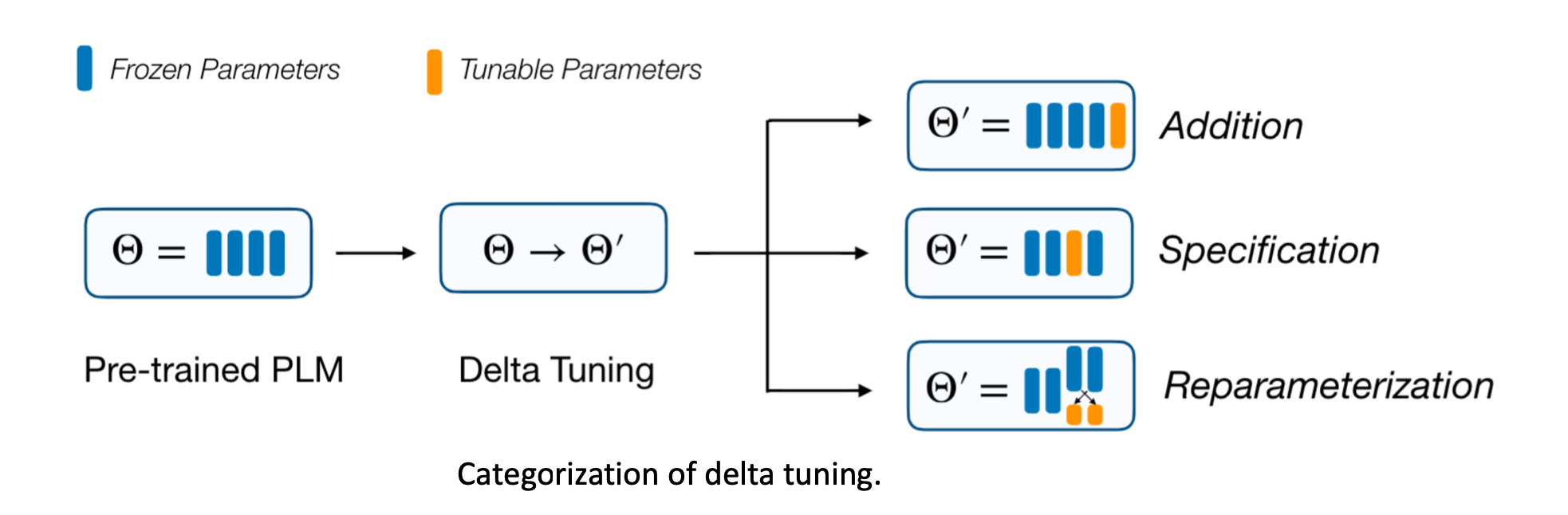
delta tuing�е�delta��ʲô����
- Addition-based ����ʽ�ķ����²���ģ��ԭ�������ڵIJ���,Ȼ��ֻѵ����Щ�������IJ�����
- Specification-based ָ��ʽ�ķ���ָ��ģ����Щ��������ѵ��,��Щ�̶���
- Reparameterization-based �ز�����ʽ�����õ�ά�ӿռ�������ز�����ԭ�����ڵIJ�����
����ʽtuning
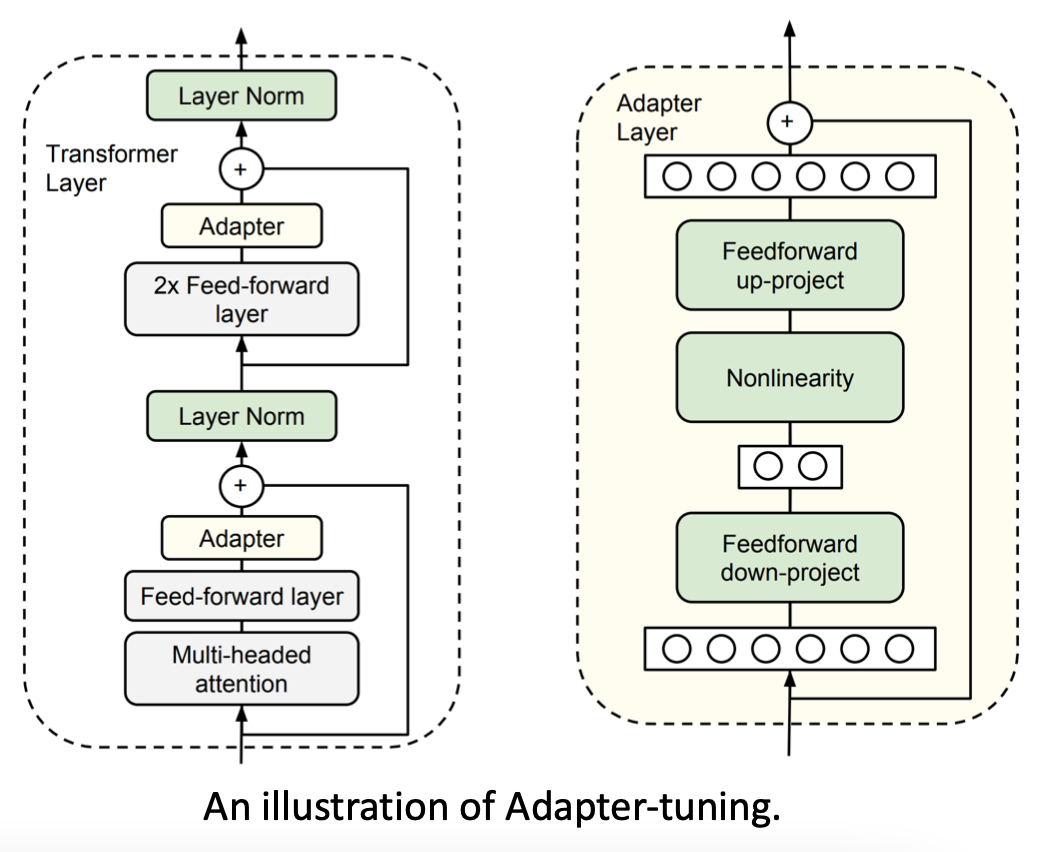
������Ҫ����Adapter��
adapter-tuning
- ΪTransformer������С��adapter(��ͼ�ұߵ�����ģ��)
- ʵ������һ����˫��������,����С�ٷ�����,�ٻ�ԭ: h �� f ( h W d ) W u + h h \leftarrow f(hW_d) W_u + h h��f(hWd?)Wu?+h(���вв�����)
- �̶���������,ֻ����Щadapter
- ��ѵ������ֻ������ģ�͵�0.5%~8%
�������Դﵽ��ȫ����ģ�ͼ�����ͬ��Ч����
����ʽ�ķ�������һ��,����prefix-tuning,����prompt��Щ��ϵ��
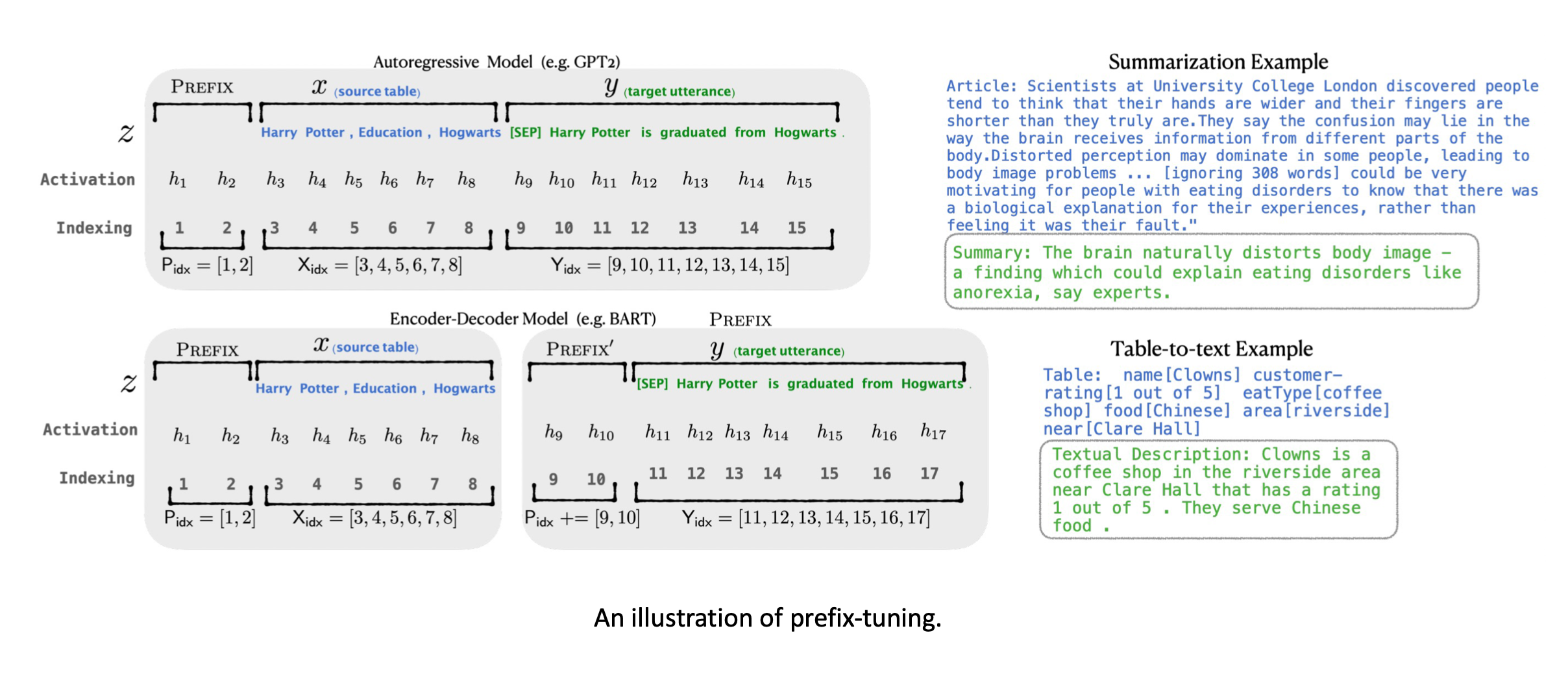
����ÿ�������״̬ǰ����soft token,Ȼ��ֻ�Ż���Щsoft token��
ָ��ʽtuning
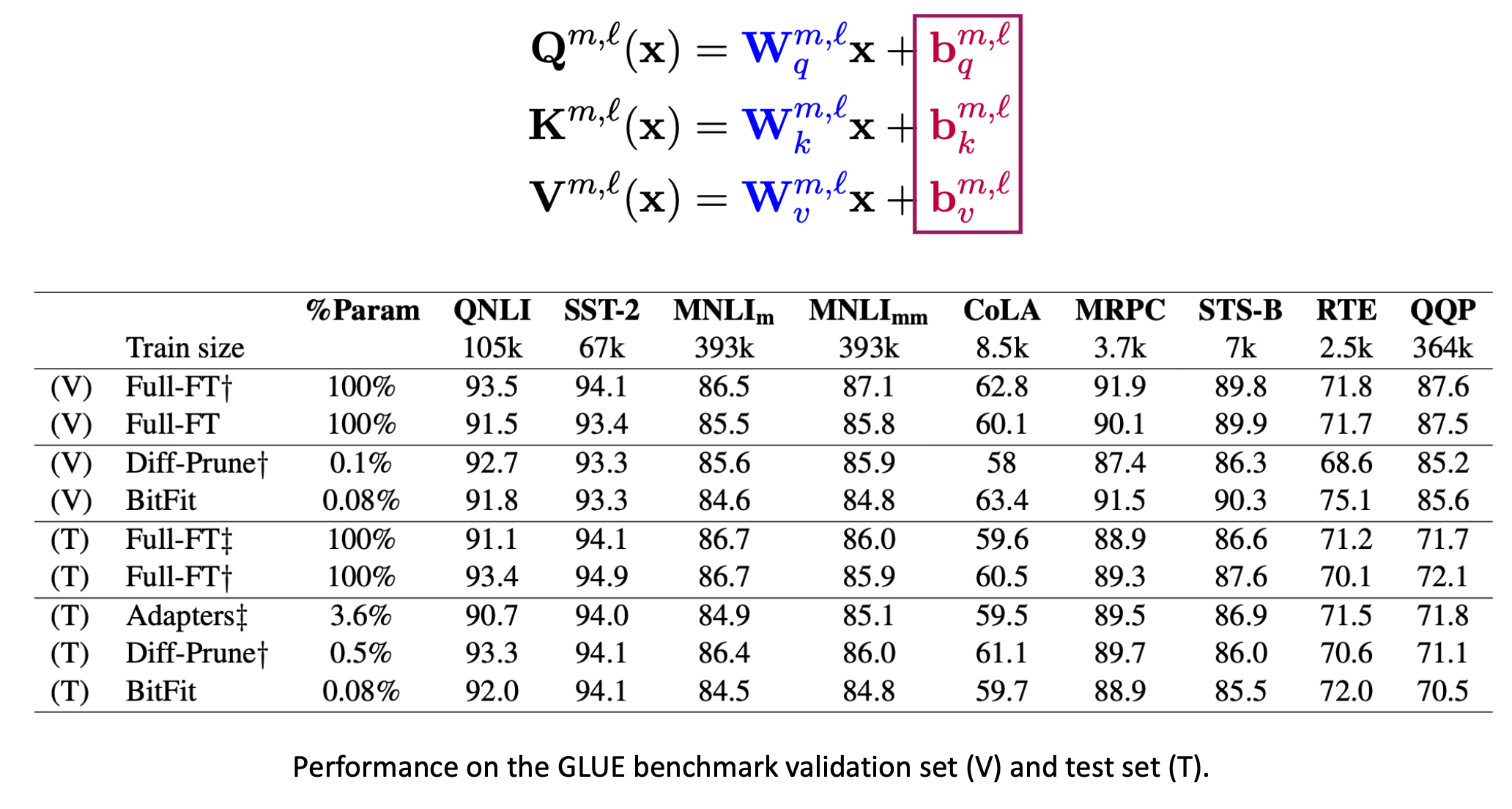
�������һ����ΪBitFit�ķ���,��ֻ��ȥ������ƫ��(bias),Ҳ�ܴﵽ��ȫ����������Ч��(������)��
�ز�����tuning
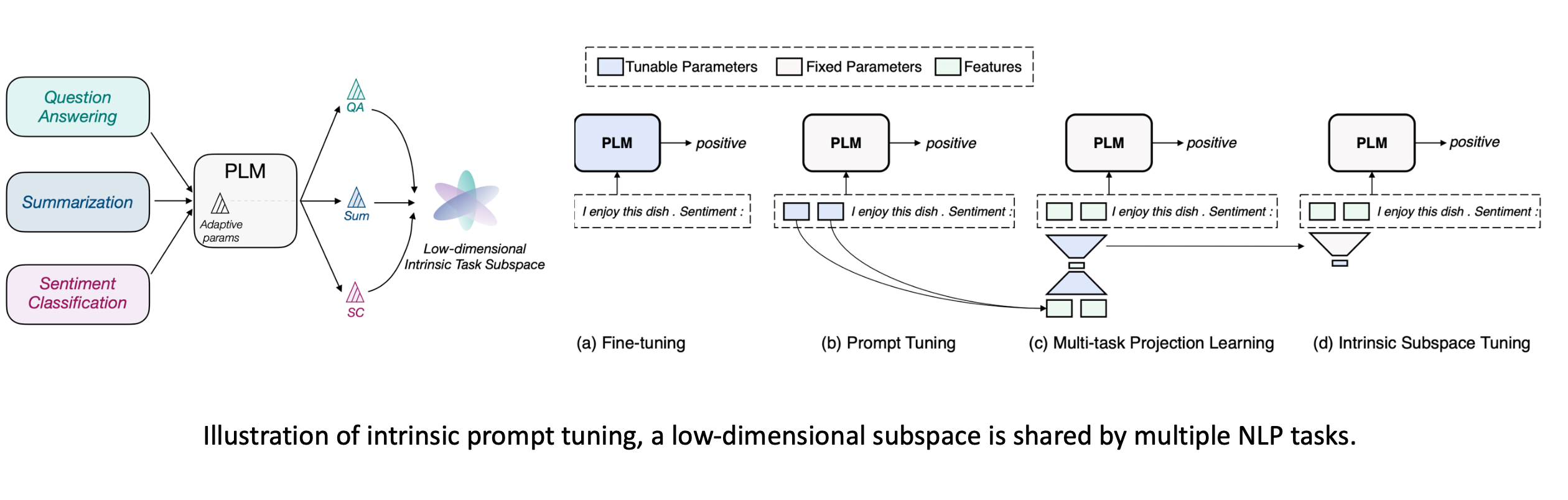
�ز���������Ϊ�Ż����̿����ڵ�ά�Ŀռ����,��120��������Ż�ѹ������ά���ӿռ��������һ����ά�Ŀռ���ѵ��,Ȼ��ԭ��ԭ���IJ������ʱ���Է����ڵ�ά�ռ��ҵ��Ľ�,������120�������ϱ��ֵĺܺá�
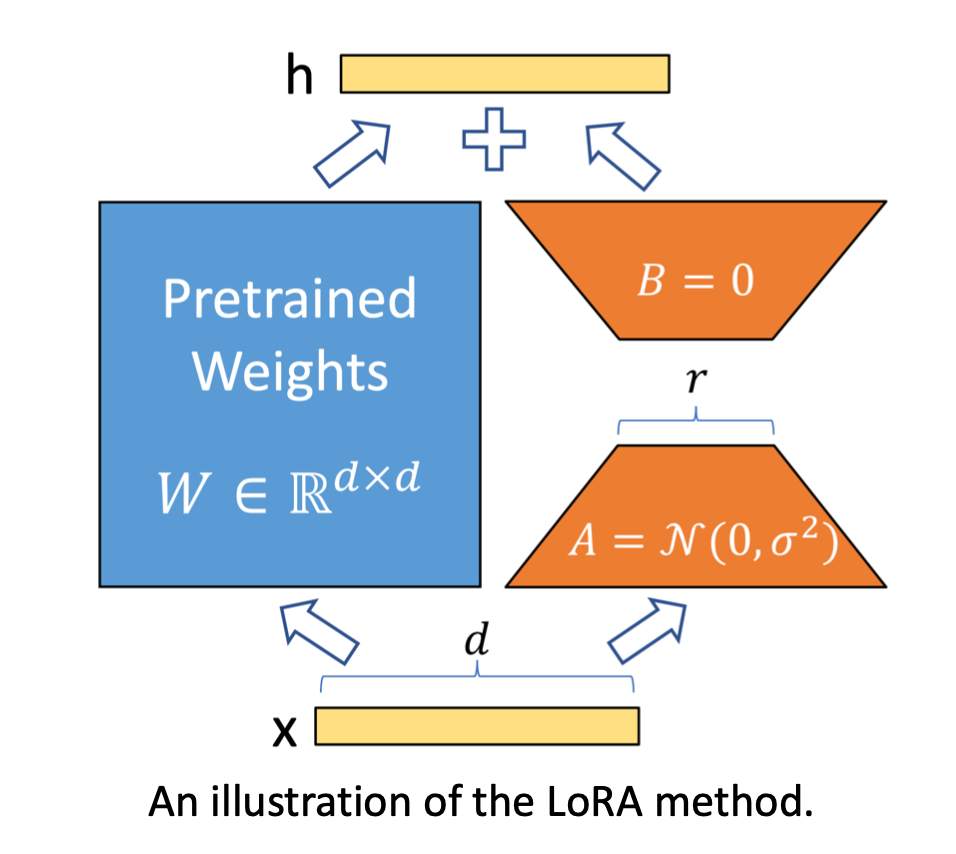
����һ�ַ���LoRA��ΪҪ�Ż��ľ��������ǵ��ȵ�,��Ȼʵ���ϲ����ǵ��ȵ�,�����ǿ���ǿ�������ȷֽ�,����
1000
��
1000
1000 \times 1000
1000��1000�ֽ�Ϊ
1000
��
2
1000 \times 2
1000��2��
2
��
1000
2 \times 1000
2��1000��,�������Լ��ٺܶ��������
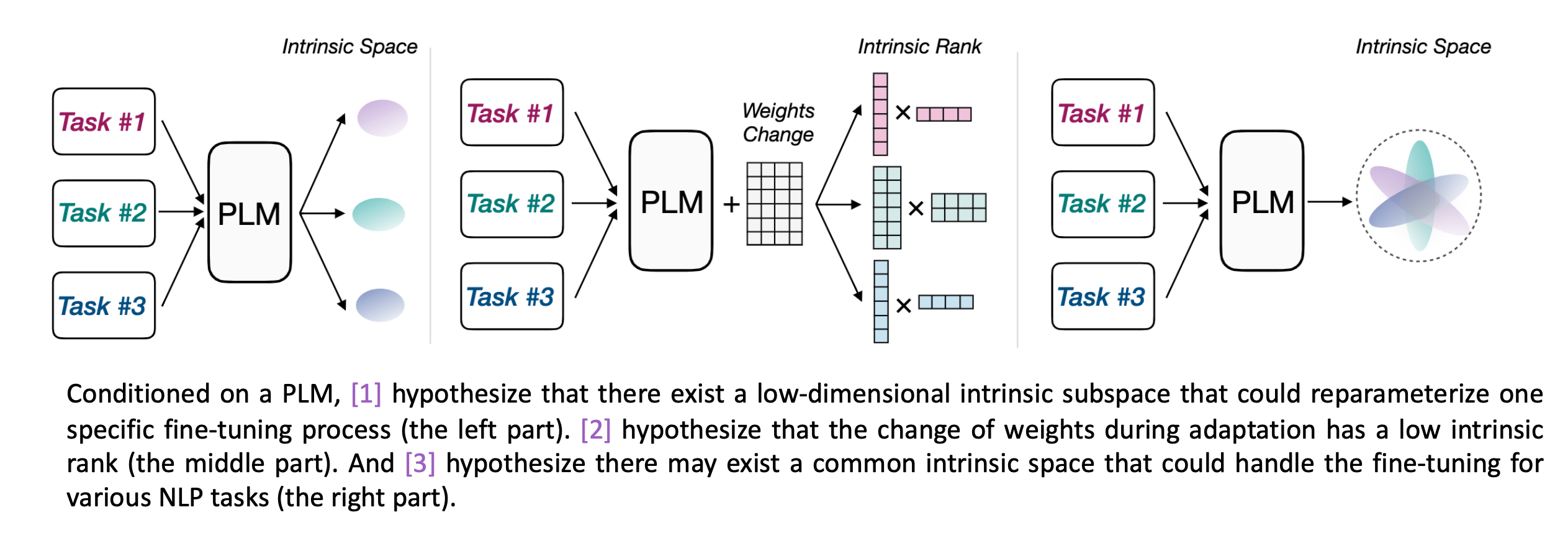
���ǿ��Կ�����Щ�ز������ķ�������������һЩ��ϵ��,����˵���Ƕ��������Ƶļ���,ģ�͵��Ż������ú��ٴ�������ɡ����ǿ�����ӳ�䵽һ����ά����ȵĹ���,��һ���ܼĹ���ȥ������ģ�͵��Ż���
ͳһtuing
������ϵ���ǿ�����չ������ķ���,������˽�����һ��ͳһ���,�������ַ�ʽ��ϵ������
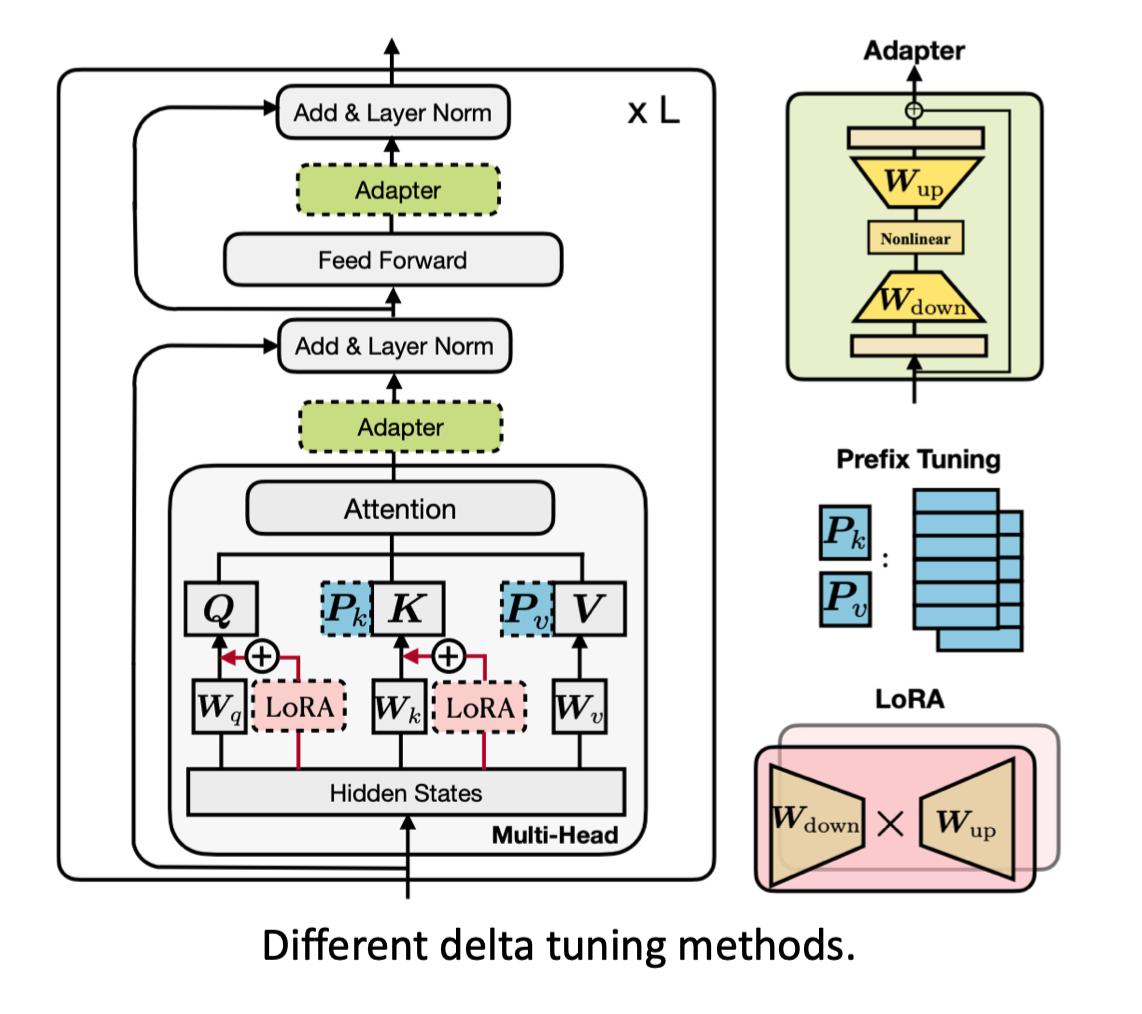
��Ϊ���DZ����Ͽ�������ͬһ�����顣
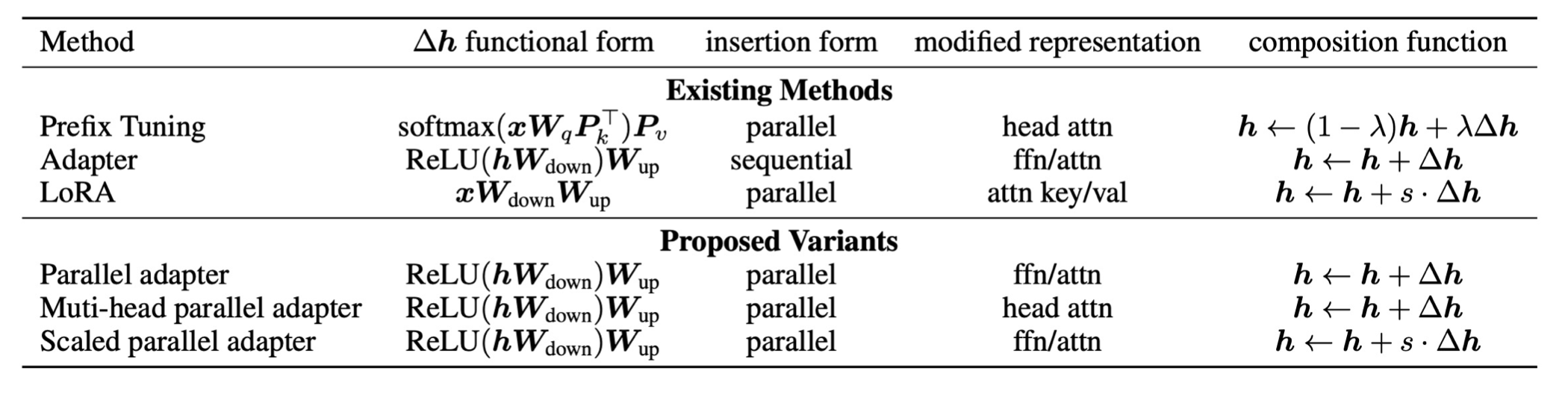
ʵ�������Ƕ��ǹ̶���ģ�Ͳ���,ֻ����С���ֵ�delta����
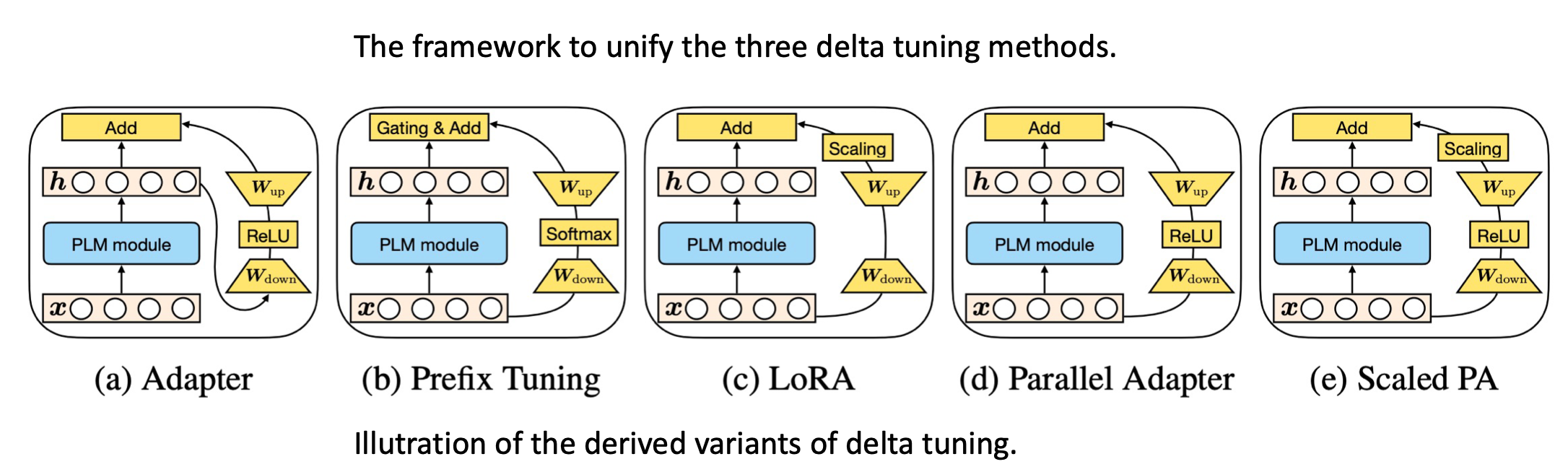
������ǿ����Ƶ�������ͨ�õ�delta tuning���塣
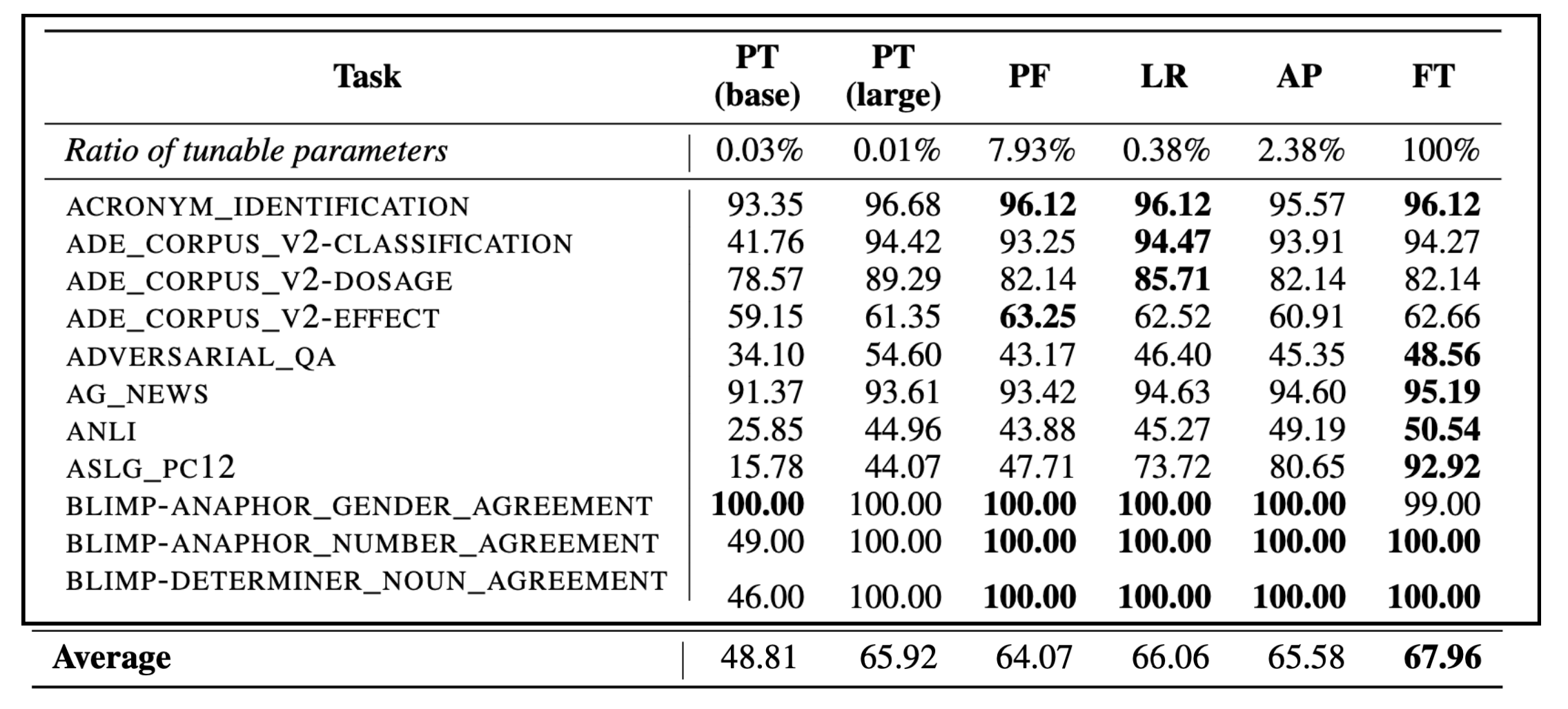
��100���NLP�����Ͻ�����ʵ�����,delta tuningȷʵЧ���ȽϺ�,����LoRA(LR)��100���������ֻ����0.38%�IJ������ܴﵽƽ����ȫ������(FT)����Ч����
Ȼ���Է��ֲ�ͬ�����������ڲ�ͬ�Ľṹ,��ô�Ƿ����һ�����Žṹ�ء�
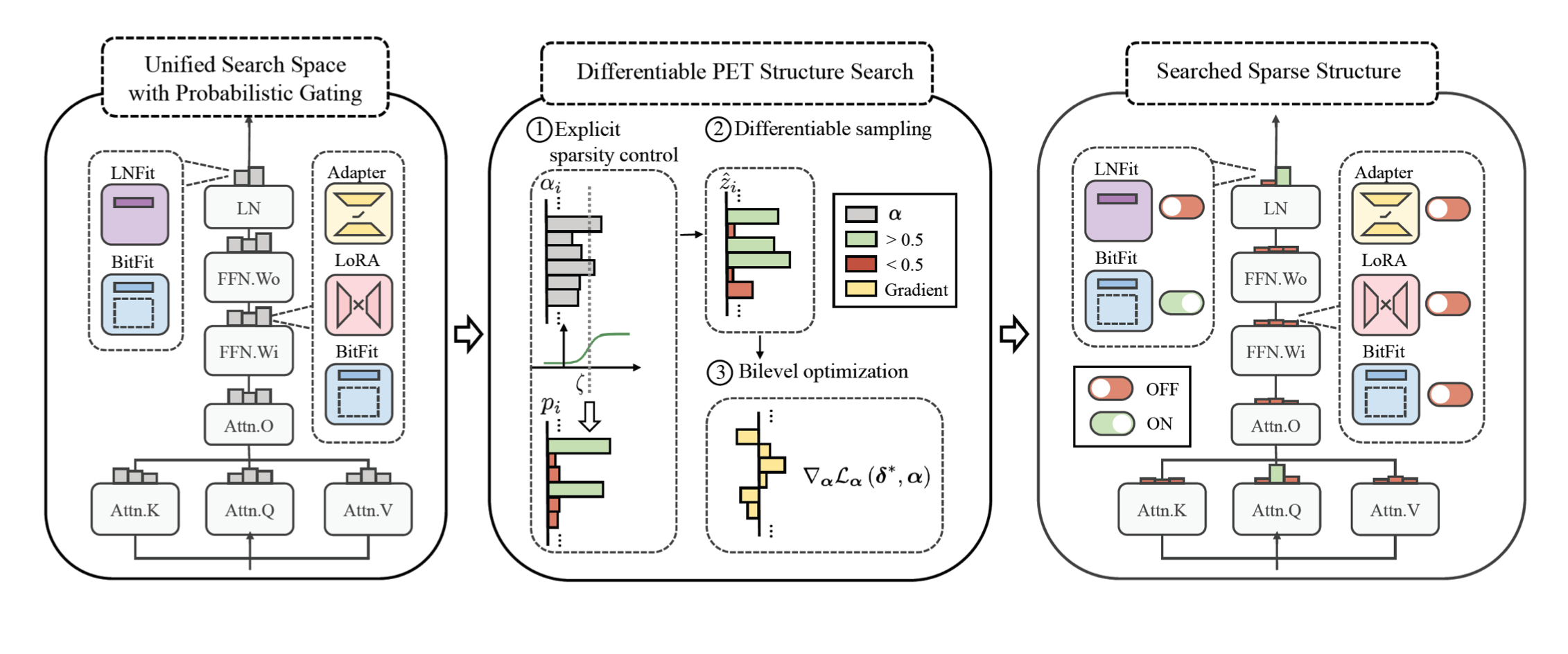
����������Զ�����ѧϰ�ķ�������������ṹ,��ÿ��λ���趨һ������,��ʾʹ������delta tuning��ʽ���������Ǿ����ҵ�һ���Ƚ�ϡ��Ľ�,����ģ�͵�Ч���ر�á�
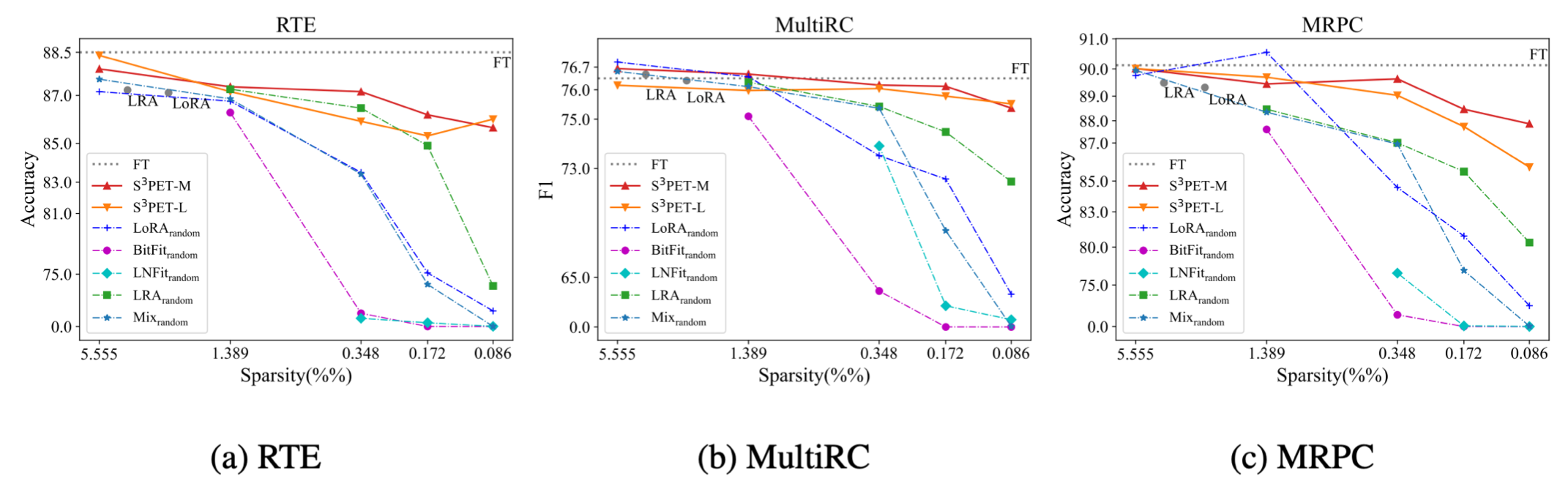
��ͼ�����ʾ��������ϡ��̶�(�ɶ����),�������ȷ�ʡ������������ٵ����֮һ��ʱ��,������delta tuning���������������½�,��ͨ���Զ����������õ��Ľ�����Ч����ȫ���������DZ�������
ͨ���Զ������ķ����ø��ٵIJ���ȥ̽��һ�ּ��ޡ�
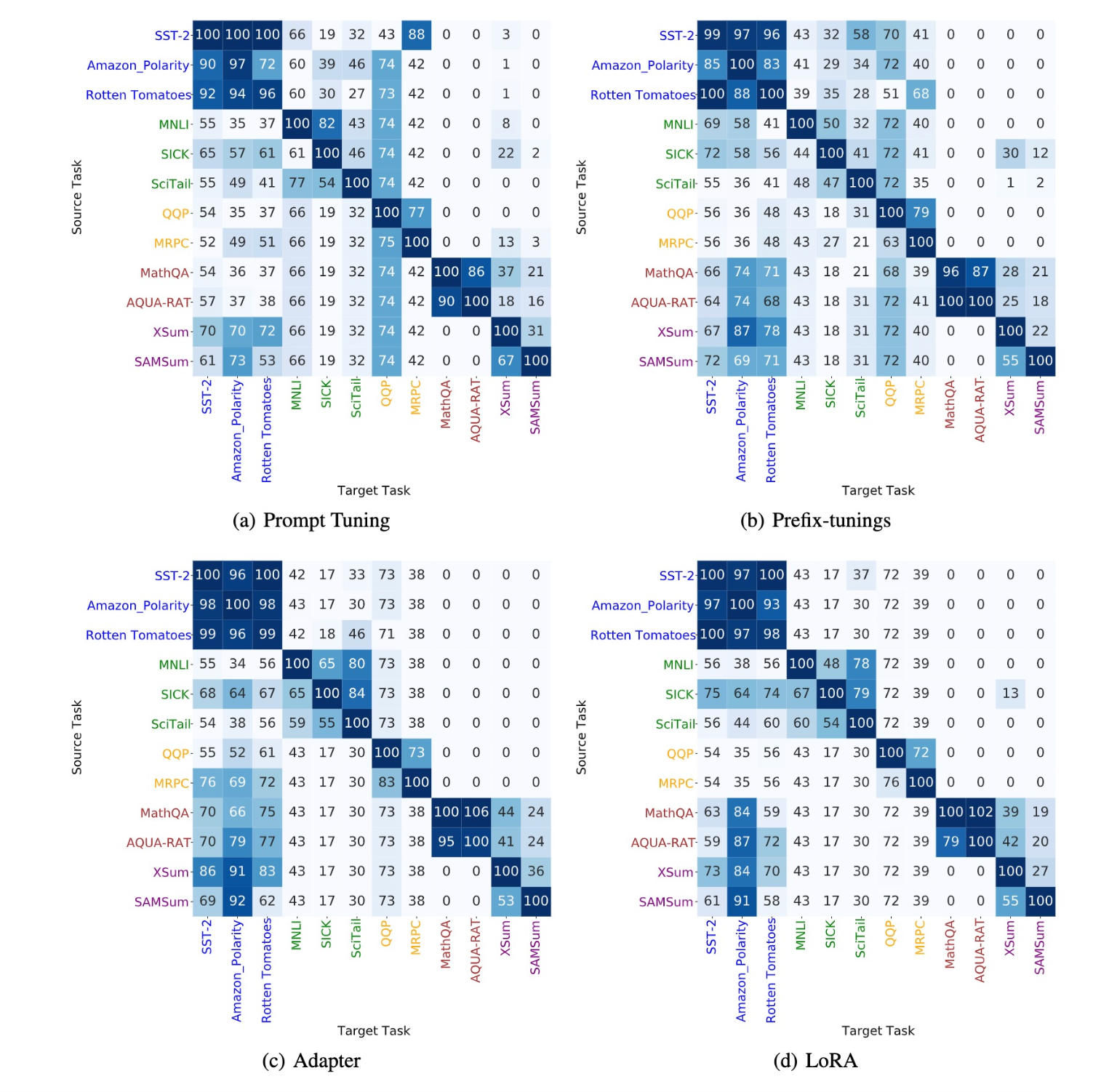
ͬʱdelta tuning���߱��dz��õĿ�Ǩ����,�⼸��delta tuning�ڲ�ͬ�������ϵõ���ͼ���ࡣ
�ܽ�
- delta tuning�ڳ����ģ��ģ���Ϸdz���Ч
- ���Ľṹ����ģ�͵����ӱ��Խ������Ҫ
�����������˽��·ֱ�Ϊprompt learning��delta tuning��ƵĹ��ߡ�
OpenPrompt����
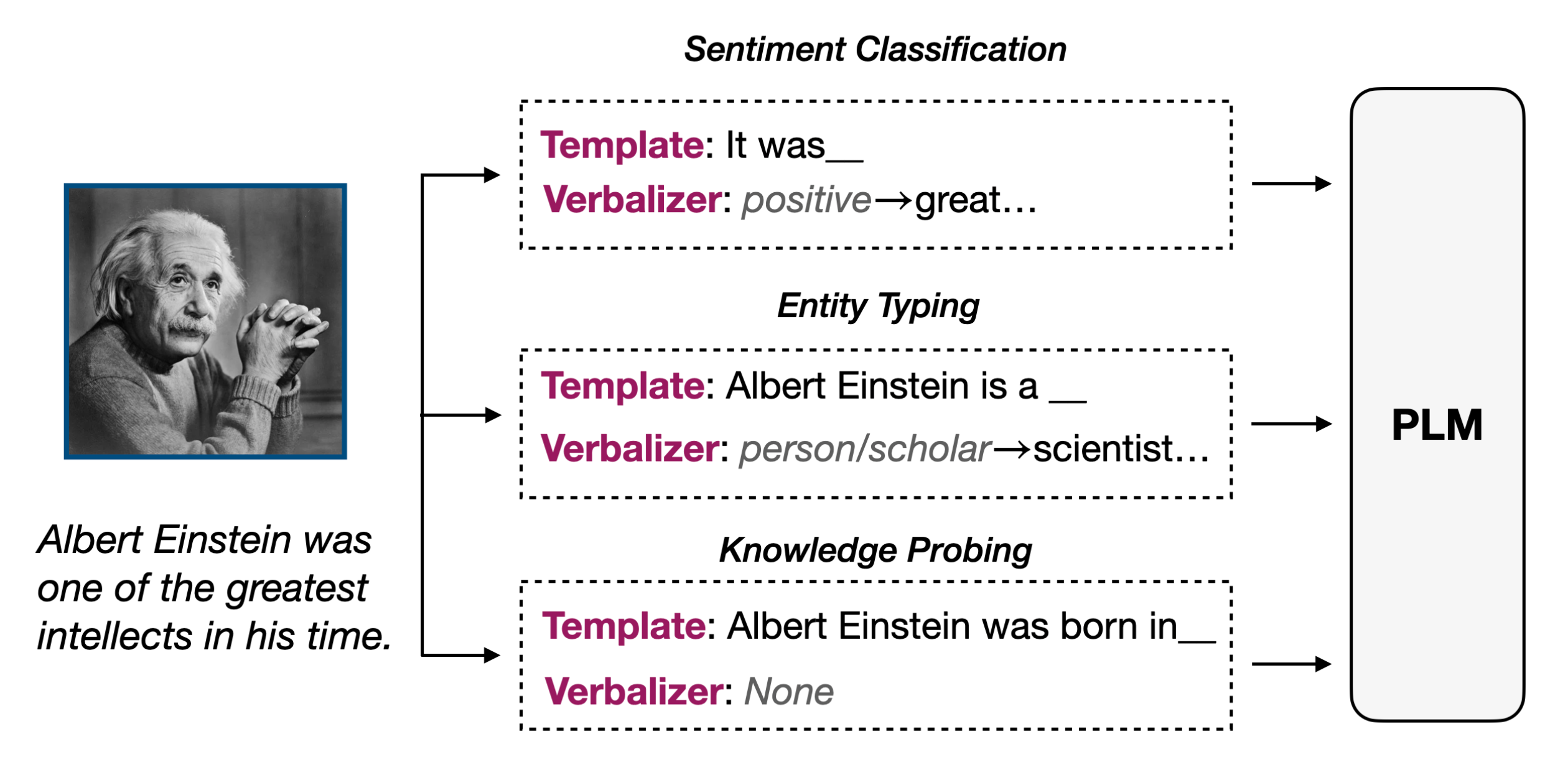
Prompt��ʵ�����Զ���ܶͬ��ģ��/verbalizer,����һ����ͨ����з�������,ģ�������it was__��
ģ����ܲ�ͬ,maskλ�ÿ��ܲ�ͬ,verbalizerҲ���ܲ�ͬ��
֮ǰͨ����ģ��д����������,���������dz��Բ�ͬ��ģ��,Ҳ�������ҵ�mask��λ�á�
OpenPrompt���߰���Ŀ���ǽ��������˵������,����ͳһ��prompt tuning��ʽ,ʹ�ò�ͬ��ģ��,���岻ͬ��verbalizer,ȥʵ�ֲ�ͬ������
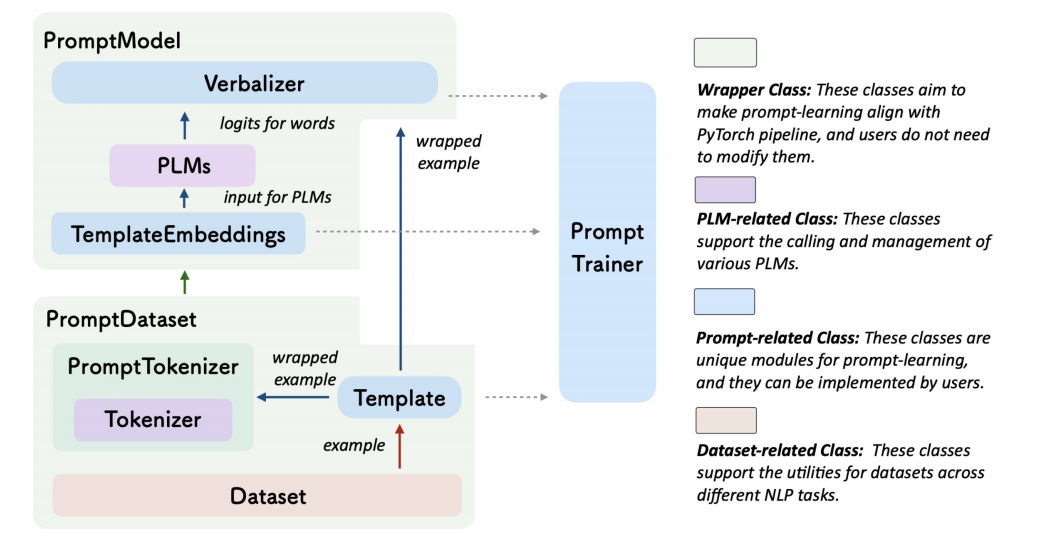
��ͼ��API������PromptDataset�������һ��Tempate,����������֮��,��PromptTokenizer�ִʳɿ�������ģ�͵����ݡ�PromptModel�Ѹ������е�soft tokenת����TemplateEmbeddings,������Ԥѵ��ģ��(PLM),����mask��λ�õ���������,��Verbalizer����Ԥ�⡣
����֮��,ͨ��PromptTrainer���ṩ�˲�ͬ��ѵ����ʽ��
�����һ�����ʹ��OpenPrompt��
- ����һ������
- ѡ��Ԥѵ��ģ��
- ����һ��Template
- ����һ��Verbalizer
- ����һ��PromptModel
- ѵ��������
һЩTemplate������:

������һ��ʵ����������ʾ��
���Ȱ�װ��Ҫ�İ�
!pip install transformers --quiet
!pip install datasets==2.0 --quiet
!pip install openprompt --quiet
!pip install torch --quiet
�������ݼ�
from datasets import load_dataset
raw_dataset = load_dataset('super_glue', 'cb', cache_dir="../datasets/.cache/huggingface_datasets")
raw_dataset['train'][0]
{'premise': 'It was a complex language. Not written down but handed down. One might say it was peeled down.',
'hypothesis': 'the language was peeled down',
'idx': 0,
'label': 0}
���鿴������
�������ģ�ͺͷִ���:
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("t5", "t5-base")
��������,��Ԭ�����ݼ�������OpenPrompt����ʹ�õĸ�ʽ:
from openprompt.data_utils import InputExample
dataset = {}
for split in ['train', 'validation', 'test']:
dataset[split] = []
for data in raw_dataset[split]:
input_example = InputExample(text_a = data['premise'], text_b = data['hypothesis'], label=int(data['label']), guid=data['idx'])
dataset[split].append(input_example)
print(dataset['train'][0])
{
"guid": 0,
"label": 0,
"meta": {},
"text_a": "It was a complex language. Not written down but handed down. One might say it was peeled down.",
"text_b": "the language was peeled down",
"tgt_text": null
}
���Կ���,��һ���ֽ�text_a,��һ���������text_b�����иղ��ᵽ��meta��Ϣ��
�������ǿ��Զ���ģ���ı�:
from openprompt.prompts import ManualTemplate
template_text = '{"placeholder":"text_a"} Deduction: {"placeholder":"text_b"}. Is it correct? {"mask"}.'
mytemplate = ManualTemplate(tokenizer=tokenizer, text=template_text)
���ǵ�ģ�嶨��������ʾ,��maskλ�����������Ҫ�Ĵ𰸡�
Ϊ�˸��õ�����ģ�������ʲô,���ǿ�һ������
wrapped_example = mytemplate.wrap_one_example(dataset['train'][0])
wrapped_example
[[{'text': 'It was a complex language. Not written down but handed down. One might say it was peeled down.',
'loss_ids': 0,
'shortenable_ids': 1},
{'text': ' Deduction:', 'loss_ids': 0, 'shortenable_ids': 0},
{'text': ' the language was peeled down',
'loss_ids': 0,
'shortenable_ids': 1},
{'text': '. Is it correct?', 'loss_ids': 0, 'shortenable_ids': 0},
{'text': '<mask>', 'loss_ids': 1, 'shortenable_ids': 0},
{'text': '.', 'loss_ids': 0, 'shortenable_ids': 0}],
{'guid': 0, 'label': 0}]
shortenable_ids��ʾ�Ƿ��ѹ��,loss_ids��ʾ�Ƿ���Ҫ������ʧ��
�������������������:
wrapped_t5tokenizer = WrapperClass(max_seq_length=128, decoder_max_length=3, tokenizer=tokenizer,truncate_method="head")
# or
from openprompt.plms import T5TokenizerWrapper
wrapped_t5tokenizer= T5TokenizerWrapper(max_seq_length=128, decoder_max_length=3, tokenizer=tokenizer,truncate_method="head")
# You can see what a tokenized example looks like by
tokenized_example = wrapped_t5tokenizer.tokenize_one_example(wrapped_example, teacher_forcing=False)
print(tokenized_example)
print(tokenizer.convert_ids_to_tokens(tokenized_example['input_ids']))
print(tokenizer.convert_ids_to_tokens(tokenized_example['decoder_input_ids']))
{'input_ids': [94, 47, 3, 9, 1561, 1612, 5, 933, 1545, 323, 68, 14014, 323, 5, 555, 429, 497, 34, 47, 158, 400, 26, 323, 5, 374, 8291, 10, 8, 1612, 47, 158, 400, 26, 323, 3, 5, 27, 7, 34, 2024, 58, 32099, 3, 5, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'decoder_input_ids': [0, 32099, 0], 'loss_ids': [0, 1, 0]}
['�xIt', '�xwas', '�x', 'a', '�xcomplex', '�xlanguage', '.', '�xNot', '�xwritten', '�xdown', '�xbut', '�xhanded', '�xdown', '.', '�xOne', '�xmight', '�xsay', '�xit', '�xwas', '�xpe', 'ele', 'd', '�xdown', '.', '�xDe', 'duction', ':', '�xthe', '�xlanguage', '�xwas', '�xpe', 'ele', 'd', '�xdown', '�x', '.', '�xI', 's', '�xit', '�xcorrect', '?', '<extra_id_0>', '�x', '.', '</s>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
['<pad>', '<extra_id_0>', '<pad>']
�������Ƕ��������ݼ����д���:
model_inputs = {}
for split in ['train', 'validation', 'test']:
model_inputs[split] = []
for sample in dataset[split]:
tokenized_example = wrapped_t5tokenizer.tokenize_one_example(mytemplate.wrap_one_example(sample), teacher_forcing=False)
model_inputs[split].append(tokenized_example)
���湹�����ݼ�����:
from openprompt import PromptDataLoader
train_dataloader = PromptDataLoader(dataset=dataset["train"], template=mytemplate, tokenizer=tokenizer,
tokenizer_wrapper_class=WrapperClass, max_seq_length=256, decoder_max_length=3,
batch_size=4,shuffle=True, teacher_forcing=False, predict_eos_token=False,
truncate_method="head")
����ģ��֮��,���ǻ�Ҫ����Verbalizer:
from openprompt.prompts import ManualVerbalizer
import torch
# for example the verbalizer contains multiple label words in each class
myverbalizer = ManualVerbalizer(tokenizer, num_classes=3,
label_words=[["yes"], ["no"], ["maybe"]])
print(myverbalizer.label_words_ids)
logits = torch.randn(2,len(tokenizer)) # creating a pseudo output from the plm, and
print(myverbalizer.process_logits(logits))
����ָ����������ǩ����,�ֱ��Ӧ����������濴verbalizer�ӹ������״:
Parameter containing:
tensor([[[4273]],
[[ 150]],
[[2087]]])
tensor([[-2.6867, -0.1306, -2.9124],
[-0.6579, -0.8735, -2.7400]])
���涨��һ������Pipeline��
from openprompt import PromptForClassification
use_cuda = torch.cuda.is_available()
print("GPU enabled? {}".format(use_cuda))
prompt_model = PromptForClassification(plm=plm,template=mytemplate, verbalizer=myverbalizer, freeze_plm=False)
if use_cuda:
prompt_model= prompt_model.cuda()
��ģ���Ƶ�GPU�ϡ���GPU�Ͻ���ѵ��:
# Now the training is standard
from transformers import AdamW, get_linear_schedule_with_warmup
loss_func = torch.nn.CrossEntropyLoss()
no_decay = ['bias', 'LayerNorm.weight']
# it's always good practice to set no decay to biase and LayerNorm parameters
optimizer_grouped_parameters = [
{'params': [p for n, p in prompt_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in prompt_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-4)
for epoch in range(5):
tot_loss = 0
for step, inputs in enumerate(train_dataloader):
if use_cuda:
inputs = inputs.cuda()
logits = prompt_model(inputs)
labels = inputs['label']
loss = loss_func(logits, labels)
loss.backward()
tot_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
if step %100 ==1:
print("Epoch {}, average loss: {}".format(epoch, tot_loss/(step+1)), flush=True)
Epoch 0, average loss: 0.6918223202228546
Epoch 1, average loss: 0.21019931323826313
Epoch 2, average loss: 0.0998007245361805
Epoch 3, average loss: 0.0021352323819883168
Epoch 4, average loss: 0.00015113733388716355
�����������һ��ģ��Ч��:
validation_dataloader = PromptDataLoader(dataset=dataset["validation"], template=mytemplate, tokenizer=tokenizer,
tokenizer_wrapper_class=WrapperClass, max_seq_length=256, decoder_max_length=3,
batch_size=4,shuffle=False, teacher_forcing=False, predict_eos_token=False,
truncate_method="head")
allpreds = []
alllabels = []
for step, inputs in enumerate(validation_dataloader):
if use_cuda:
inputs = inputs.cuda()
logits = prompt_model(inputs)
labels = inputs['label']
alllabels.extend(labels.cpu().tolist())
allpreds.extend(torch.argmax(logits, dim=-1).cpu().tolist())
acc = sum([int(i==j) for i,j in zip(allpreds, alllabels)])/len(allpreds)
print(acc)
0.9107142857142857
OpenDelta����
�������OpenDelta����,����delta tuning,�����ص���:
- �ɾ�
- ��
- �ɳ���
- ����չ
- ���
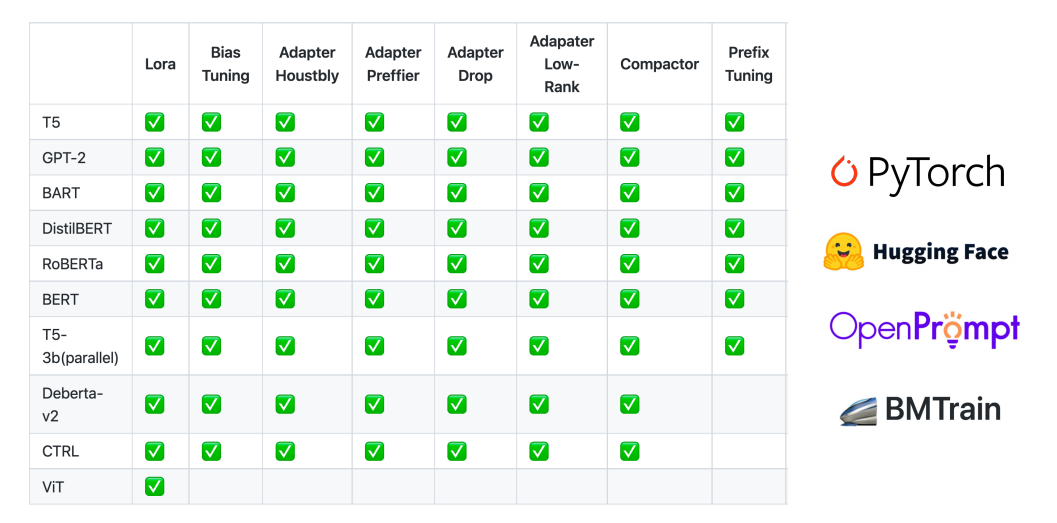
֧�ַdz����ģ�͡�
��������һ��ʵ���ɡ�
���Ȱ�װ��Ҫ�İ���
!pip install transformers --quiet
!pip install datasets==2.0 --quiet
!pip install opendelta==0.2.2 --quiet
�ڿ�ͷ������Ҫ�õ��İ�:
from dataclasses import dataclass, field
from typing import Optional, List
from transformers import Seq2SeqTrainingArguments, TrainerCallback
from datasets import load_dataset, load_metric, concatenate_datasets
import transformers
from transformers import (
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer,
HfArgumentParser,
MBartTokenizer,
default_data_collator,
set_seed,
)
from datasets import load_dataset
import torch
import numpy as np
import random
����ģ�͵IJ���:
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
"with private models)."
},
)
model_args = ModelArguments(model_name_or_path="t5-large", )
ʹ�ô�ͳ�ķ�ʽ����ģ��:
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
config.dropout_rate = 0.0
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
model.resize_token_embeddings(len(tokenizer))
������ʾһ��opendelta�ṩ�Ŀ��ӻ�����:
from opendelta import Visualization
Visualization(model).structure_graph();

root
������ shared(Embedding),lm_head(Linear) weight:[32100, 1024]
������ encoder (T5Stack)
�� ������ embed_tokens (Embedding) weight:[32100, 1024]
�� ������ block (ModuleList)
�� �� ������ 0 (T5Block)
�� �� �� ������ layer (ModuleList)
�� �� �� ������ 0 (T5LayerSelfAttention)
�� �� �� �� ������ SelfAttention (T5Attention)
�� �� �� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� �� �� �� ������ relative_attention_bias (Embedding) weight:[32, 16]
�� �� �� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� �� �� ������ 1 (T5LayerFF)
�� �� �� ������ DenseReluDense (T5DenseActDense)
�� �� �� �� ������ wi (Linear) weight:[4096, 1024]
�� �� �� �� ������ wo (Linear) weight:[1024, 4096]
�� �� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� �� ������ 1-23(T5Block)
�� �� ������ layer (ModuleList)
�� �� ������ 0 (T5LayerSelfAttention)
�� �� �� ������ SelfAttention (T5Attention)
�� �� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� �� ������ 1 (T5LayerFF)
�� �� ������ DenseReluDense (T5DenseActDense)
�� �� �� ������ wi (Linear) weight:[4096, 1024]
�� �� �� ������ wo (Linear) weight:[1024, 4096]
�� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� ������ final_layer_norm (T5LayerNorm) weight:[1024]
������ decoder (T5Stack)
������ embed_tokens (Embedding) weight:[32100, 1024]
������ block (ModuleList)
�� ������ 0 (T5Block)
�� �� ������ layer (ModuleList)
�� �� ������ 0 (T5LayerSelfAttention)
�� �� �� ������ SelfAttention (T5Attention)
�� �� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� �� �� ������ relative_attention_bias (Embedding) weight:[32, 16]
�� �� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� �� ������ 1 (T5LayerCrossAttention)
�� �� �� ������ EncDecAttention (T5Attention)
�� �� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� �� ������ 2 (T5LayerFF)
�� �� ������ DenseReluDense (T5DenseActDense)
�� �� �� ������ wi (Linear) weight:[4096, 1024]
�� �� �� ������ wo (Linear) weight:[1024, 4096]
�� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� ������ 1-23(T5Block)
�� ������ layer (ModuleList)
�� ������ 0 (T5LayerSelfAttention)
�� �� ������ SelfAttention (T5Attention)
�� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� ������ 1 (T5LayerCrossAttention)
�� �� ������ EncDecAttention (T5Attention)
�� �� �� ������ q,k,v,o(Linear) weight:[1024, 1024]
�� �� ������ layer_norm (T5LayerNorm) weight:[1024]
�� ������ 2 (T5LayerFF)
�� ������ DenseReluDense (T5DenseActDense)
�� �� ������ wi (Linear) weight:[4096, 1024]
�� �� ������ wo (Linear) weight:[1024, 4096]
�� ������ layer_norm (T5LayerNorm) weight:[1024]
������ final_layer_norm (T5LayerNorm) weight:[1024]
������ʾͬһ��backbone(T5)���ϲ�ͬdelta:
from opendelta import AutoDeltaConfig, AutoDeltaModel
delta_model_spelling = AutoDeltaModel.from_finetuned("thunlp/Spelling_Correction_T5_LRAdapter_demo", backbone_model=model)
delta_model_spelling.detach()
delta_model_topic = AutoDeltaModel.from_finetuned("thunlp/Question_Topic_T5-large_Compacter", backbone_model=model)
delta_model_topic.detach()
delta_model_fact = AutoDeltaModel.from_finetuned("thunlp/FactQA_T5-large_Adapter", backbone_model=model)
delta_model_fact.detach()
���涨������������:
def multitask_serving(input_text):
# ���Ƚ���ƴд�Ĵ�
input_ids = tokenizer(input_text, return_tensors="pt").input_ids#.cuda()
delta_model_spelling.attach()
answers_ids =model.generate(input_ids=input_ids, max_length=20, num_beams=4)
input_text = tokenizer.decode(answers_ids[0], skip_special_tokens=True)
print("Correct Spelling: {}".format(input_text))
delta_model_spelling.detach()
# Ȼ�����������ģ��
delta_model_topic.attach()
input_ids = tokenizer(input_text, return_tensors="pt").input_ids#.cuda()
answers_ids =model.generate(input_ids=input_ids, max_length=20, num_beams=4)
topic = tokenizer.decode(answers_ids[0], skip_special_tokens=True)
delta_model_topic.detach()
print("Question Topic: {}".format(topic))
# ������ʴ�
delta_model_fact.attach()
input_ids = tokenizer(input_text, return_tensors="pt").input_ids#.cuda()
answers_ids =model.generate(input_ids=input_ids, max_length=20, num_beams=4)
input_text = tokenizer.decode(answers_ids[0], skip_special_tokens=True)
delta_model_fact.detach()
print("Question Answer: {}".format(input_text))
���������л�ͨ����attach��detach��
����չʾ��������:
multitask_serving("When was Beiiing olymp#ic heldd ?")
multitask_serving("What the commmon career of Newton ad eintesin?")
Correct Spelling: When was Beijing Olympic held?
Question Topic: The question's topic is sports.
Question Answer: 2008
Correct Spelling: What was the common career of Newton and Einstein?
Question Topic: The question's topic is science.
Question Answer: Physicists
���Կ���ƴдģ�Ͱ�������������������ģ�ͺ��ʴ�ģ�͡�
�������������Ԥѵ��ģ�ͻ��˵�û�м�deltaģ�͵�ģ��,ֻҪִ��detach����:
delta_model_spelling.detach()
delta_model_topic.detach()
delta_model_fact.detach()