RepVGG(一)论文解析
论文解读
前言
- 我们知道,不管是分类、目标检测,还是分割任务,Backbone部分都是极为关键的。
- 而VGG自2014年提出后,迎来了短暂的辉煌。但是随着研究的深入,ResNet、DenseNet等网络的出现,VGG似乎已经变成了一个冷门的模型。不再作为backbone进行下游的一些分支任务。
- 直到2020年,有人提出了RepVGG,这绝对算是当年的一个最有影响力的研究工作,VGG开始了新生。
一、REPVGG是什么?
- RepVGG主要做了两件事情。
- 第一件事情,是在训练时使用多分支网络,在block当中加入了**
identity分支和残差分支**。- 第二件事情,在推理阶段,通过**
op融合策略**,将所有的网络层都转化为3x3卷积,因为3x3卷积就有一定的加速操作,如计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,所有卷积累积起来就会有很大的一个加速提升。
二、论文解读
0.摘要
- 我们提出了一个简单但功能强大的卷积神经网络架构,该架构具有类似于VGG的推理时间体,该推理体仅由3×3卷积和ReLU的堆叠组成,而训练时间模型具有一个多分支拓扑。
- 训练时间和推理时间架构的这种解耦是通过结构的重新参数化技术实现的,因此模型叫做RepVGG。
- 在ImageNet数据集上,RepVGG是首个达到80%以上top-1精度的普通模型。在NVIDIA 1080Ti GPU上,RepVGG模型的运行速度比ResNet-50快83%,比ResNet-101快101%,且具有更高的精度。
- 与EfficientNet和RegNet等最先进的模型相比,很好的平衡了精度和速度。
- 代码和经过训练的模型可以在这个地址找到: https://github.com/megvii-model/RepVGG
1.引言
- 卷积神经网络已经成为许多任务的主流解决方案。 VGG通过由卷积,ReLU和池化组成的组成的简单架构在图像领域实现了巨大的成功。
- 有了Inception、ResNet和DenseNet ,许多研究兴趣转移到精心设计的架构,使模型变得越来越复杂。 最近一些强大的架构是通过自动或手动架构搜索,或在基础架构上通过复合缩放策略获得。
- 尽管许多复杂的ConvNet都比简单的ConvNet提供更高的准确性,但缺点也很明显。
1)复杂的多分支设计(例如,ResNet中的残差加法和Inception中的分支级联使模型难以实现和定制,降低了推断速度并降低内存利用率。
2)一些组件(例如,Xception和MobileNets中的深度可分离卷积以及ShuffleNets中的channal shuffer(分组卷积后的随机打乱)增加了内存访问成本,并且缺乏各种设备的支持。 有这么多影响推论速度的因素,每秒浮点运算次数(FLOP)不能准确反映实际速度。
尽管一些新颖的模型的FLOP低于VGG和ResNet-18/34/50 等老式模型,但它们可能并不运行得更快。 因此,VGG和ResNets的原始版本在学术界和工业界仍被大量用于实际应用。
在本文中,我们提出了RepVGG,这是一种VGG风格的架构,其性能优于许多复杂的模型。RepVGG具有以下优点。
- 模型具有类似VGG(也称为前馈)的拓扑结构,没有任何分支。 也就是说,每一层都只需要前一层的输出作为输入并且只输出到其下一层。
- 模型的主体仅使用
3×3 conv和ReLU。 - 具体架构(包括具体深度和宽度)
不是通过自动搜索,手动优化,复合缩放或其他繁琐的手段生成的。
普通模型要达到和多分支架构可比的性能级别是极有挑战性的。 一个解释是多分支的架构,例如ResNet,使模型成为
众多较浅模型的隐式集成,因此训练多分支模型可以避免梯度消失的问题。
由于多分支架构的全部好处
都在于训练,而缺点则不希望用于推理,因此我们建议通过结构重新参数化将训练时间的多分支和推理时间的普通架构解耦。
这意味着通过转换其参数将架构转换为另一种。具体而言,一个网络结构是与一组参数耦合的,例如,一个conv层可由一个4th-order kernel tensor。 如果某个结构的参数可以转换为与另一种结构耦合的另一组参数,我们可以用后者等效地替换前者,从而改变整个网络体系结构。
2.相关工作
2.1. 从单路径到多分支
- 在VGG将ImageNet分类的top-1准确率提高到70%之后。很多创新都是通过使
卷积网变得复杂来得到更高的性能。- 比如GoogLeNet及以后的版本Inception模型采用了精心设计的
多分支架构。- ResNet提出了简化的
双分支架构。- DenseNet通过将
低层和大量的高层连接起来,使得网络结构更加复杂。神经结构搜索和人工设计可以生成性能更高的卷积网络,但代价是大量的计算资源或人力。nas生成的模型的一些大型版本甚至不能在普通gpu上训练,因此限制了应用程序。除了实现上的不便之外,复杂的模型可能会降低的并行度,从而降低推理的速度。
2.2. 有效的单路径训练模型
- 已经有人尝试训练
没有分支的卷积网络。然而,前人的工作主要是寻求非常深的模型以合理的精度收敛,并没有达到比复杂模型更好的性能。因此,所建立的方法和模型既不简单也不实用。- 刚开始提出的方法是训练一个极深的简单卷积网络。通过使用基于
平均场理论的方案,10000层网络在MNIST上训练的准确率超过99%,在CIFAR-10上训练的准确率达到82%。虽然模型不实用(甚至LeNet-5在MNIST上的准确率达到99.3%,VGG-16在CIFAR- 10上的准确率达到93%以上),但理论贡献是很有见地的。- 最近的工作结合了几种技术,包括
Leaky ReLU、max-norm和careful initialization。在ImageNet上,参数量为147M的简单卷积网络准确率可以达到74.6%的top-1精度,比之前的基线(ResNet-101, 76.6%,45M参数)低2%。- 值得注意的是,本文仅仅是演示一个简单模型可以很好地收敛的。而且并不打算训练像ResNets这样极其深度的卷积网络。相反,我们的目标是建立一个简单的模型,具有
合理的深度和良好的精度-速度平衡,可以简单地用最常见的组件(regular conv和BN)和简单的代数来实现。
2.3.模型重参数化
DiracNet是一种与我们相关的重参数化方法。它通过卷积层的卷积核来构建深平面模型,其中W是用于卷积的最终权值(一个被视为矩阵的四阶张量),a和b是学习向量,Wnorm是规范化的可学习卷积核。
W = diag(a)I + diag(b)Wnorm- 与同等参数量的ResNets相比,CIFAR- 100数据集上
DiracNet的top-1准确率降低了2.29%(78.46% vs. 80.75%), ImageNet数据集上降低了0.62%(DiracNet-34的72.21% vs. ResNet-34的72.83%)。- Dirac- Net与我们的方法的
不同之处是:
1)我们的结构重参数化是通过一个具体的结构来实现的,这个具体的结构后来可以转换成另一个。而DiracNet为了方便优化,仅仅使用了另一个卷积核的数学表达式。换句话来说,训练时候的RepVGG是一个多分支结构,但DiracNet不是。
2)DiracNet模型的性能高于一般参数化的简单模型,但低于可比的ResNet模型,而RepVGG模型的性能则大大优于ResNets模型。
Asym Conv Block(ACB)采用不对称卷积加强常规卷积的骨架,它可以被视为另一种形式的结构重参数化,它把训练块转换成卷积。和我们的方法相比,不同之处在于,ACB是专为组件级的改进和用作卷积层替代在任何结构中。而我们的结构性重参数化只用于训练简单的卷积网络,如4.2部分所示。
2.4.Winograd卷积
- RepVGG只使用了
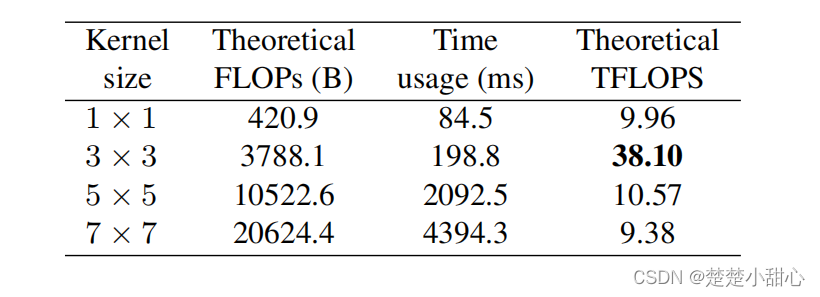
3X3卷积,因为它在GPU和CPU上被一些现代的计算库如NVIDIA cuDNN[和Intel MKL高度优化。- 表1显示了在1080Ti GPU上用cuDNN 7.5.0测试的理论
FLOPs、实际运行时间和计算密度(以每秒Tera浮点运算次数衡量,TFLOPS) 。- 结果表明,3X3卷积的理论计算密度和其他相比在
4倍左右,这表明在不同的体系结构中,TFLOPS并不能代表实际速度。加速3X3卷积的经典算法是winograd算法(仅当stride为1时),它已经被库如cuDNN和MKL很好的支持(并默认启用)。- 例如,用标准F(2X2,3X3)Winograd,一个3X3卷积的乘法(MULs)
减少到原来的4/9。由于乘法比加法更加耗时,我们计算乘法来衡量Winograd支持下的计算成本(用Wino MULs,表4、5)。注意,具体计算库和硬件决定为是否为每个运算使用Winograd,因为小规模的卷积可能由于内存开销不能加速。
3.架构
3.1. 简单快速,节省内存,灵活
- 使用简单的卷积网络至少有三个原因:
快速、节省内存、灵活。
- 快速 : 许多最近的多分支架构的FLOPs比VGG要低,但运行起来可能不会更快。例如,VGG-16相比于EfficientNet-B3的FLOPs是8:4,但在1080Ti上运行速度要快1.8倍(表4),这意味着
前者的计算密度是后者的15倍。
除了Winograd卷积带来的加速外,内存访问开销(MAC)和并行度是影响速度的两个重要因素,但内存访问开销并没有被计算在内。例如,虽然需要的分支加法或连接的计算是微不足道的,但内存访问开销是重要的。
此外,内存访问开销在分组卷积中占据了很大一部分时间。另一方面,在相同的FLOPs情况下,具有高并行度的模型可能比另一个具有低并行度的模型要快得多。由于多分支拓扑在初始化和自动生成架构中被广泛采用,很多大的运算被许多小运算所替代。
之前的工作显示,片段式的运算符的数量(即个别的卷积或池化操作的数量在一个构建块)在NASNET-A是13,这对具有强大的并行计算能力GPU的设备是不友好的,并且会引入了额外的开销比如:内核启动和同步等,。相比之下,这个数字在ResNets中是2或3,我们将其设为1:单个卷积。
- 节省内存 多分支结构的内存效率是低下的,因为每个分支的结果都需要
保留到添加或连接时,这大大提高了内存占用的峰值。
如图3所示,残差块的输入需要保持到加法为止。假设残差块保持特征图的大小,则内存占用的峰值为是输入的两倍。相比之下,普通结构允许特定层的输入所占用的内存在操作完成后立即释放。在设计专门的硬件时,普通的卷积网络可以进行深度内存优化并降低内存单元的成本,以便我们可以在芯片上集成更多的计算单元。
- 灵活 多分支拓扑对
体系结构规范施加了约束。例如,ResNet要求将卷积层组成残差块,这限制了灵活性,因为每个残差块的最后一个卷积层必须产生相同形状的张量,否则快捷连接将没有意义。
更糟糕的是,多分支拓扑限制了通道剪枝的应用。通道剪枝是一种去除一些不重要通道的实用技术,有些方法可以通过自动发现每一层的合适宽度来优化模型结构。然而,多分支模型使修剪变得棘手,并导致显著的性能退化或较低的加速比。相比之下,普通架构允许我们根据需求自由配置每个卷积层,并进行修剪,以获得更好的性能-效率平衡。
3.2.多分支结构训练时间
简单的卷积网络有很多优点,但有一个致命的缺点:
性能差。
例如,使用BN等现代组件,VGG-16可以在ImageNet上达到72%的top-1精度,这似乎过时了。我们的
结构重新参数化方法受到了ResNet的启发,该方法明确地构建了一个快捷分支,将信息流建模为y = x + f(x),并使用一个残差块学习f。当x和f(x)的维数不匹配时,就变成y = g(x) + f(x),其中g(x)是一个卷积捷径,通过一个1X1的卷积实现。Resnets成功的一个解释是,这样的多分支架构使模型成为众多较浅模型的隐含集成。具体来说,有n个块,模型可以解释为2的n次方个模型的集合,因为每个块将流分成两条路径。
由于多分支架构在推理方面存在缺陷,但多分支似乎有利于的训练,因此我们
仅在推理阶段对众多模型使用多分支架构。
为了使大多数成员更浅或更简单,我们使用类似resnet的identity(仅当维度匹配时)和1X1分支,来构建训练阶段的残差块。计算公式是:y = x + g(x) + f(x)。我们只是简单地堆叠几个这样的块来构建训练阶段模型。模型是由3的n次方个成员和n个这样的块组成的集合。
3.3. 重参数化推理阶段
- 在本小节中,我们将描述如何将一个经过训练的块转换为一个单独的3X3卷积层进行推理。注意,我们在加法之前的每个分支中都使用了BN。
- 形式上,我们用 W ( 3 ) ∈ R C 2 × C 1 × 3 × 3 W(3) ∈ R^{C2×C1×3×3} W(3)∈RC2×C1×3×3表示具有C1输入通道和C2输出通道的3X3卷积层的核,
- 用 W ( 1 ) ∈ R C 2 × C 1 W(1) ∈ R^{C2×C1} W(1)∈RC2×C1表示1X1分支的核。
- 我们使用
μ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) μ(3),σ(3), γ(3), β(3) μ(3),σ(3),γ(3),β(3)作为一个3X3卷积后的BN层的累积均值、标准差、学习缩放因子和偏差。
μ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) μ(1),σ(1), γ(1), β(1) μ(1),σ(1),γ(1),β(1)为1X1卷积后BN层的累积均值、标准差、学习缩放因子和偏差, μ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) μ(0),σ(0), γ(0), β(0) μ(0),σ(0),γ(0),β(0)为恒等分支后BN层的累积均值、标准差、学习缩放因子和偏差。
设
M ( 1 ) ∈ R N × C 1 × H 1 × W 1 M(1) ∈ R^{N×C1×H1×W1} M(1)∈RN×C1×H1×W1 , M ( 2 ) ∈ R N × C 2 × H 2 × W 2 M(2) ∈ ^{RN×C2×H2×W2} M(2)∈RN×C2×H2×W2
分别为输入和输出,*为卷积算子。
如果 C 1 = C 2 , H 1 = H 2 , W 1 = W 2 C1 = C2, H1 = H2, W1 = W2 C1=C2,H1=H2,W1=W2,我们有
M ( 2 ) = b n ( M ( 1 ) ? W ( 3 ) , μ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) ) + b n ( M ( 1 ) ? W ( 1 ) , μ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) ) + b n ( M ( 1 ) , μ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) ) M(2) = bn(M(1) ? W(3),μ(3),σ(3), γ(3), β(3))+ bn(M(1) ? W(1),μ(1),σ(1), γ(1), β(1))+ bn(M(1),μ(0),σ(0), γ(0), β(0)) M(2)=bn(M(1)?W(3),μ(3),σ(3),γ(3),β(3))+bn(M(1)?W(1),μ(1),σ(1),γ(1),β(1))+bn(M(1),μ(0),σ(0),γ(0),β(0))
如果我们不使用恒等分支,那么上述方程只有前两项。这里bn是推理时间bn函数, ? 1 ≤ i ≤ C 2 , ?1 ≤ i ≤ C2, ?1≤i≤C2,
b n ( M , μ , σ , γ , β ) : , i , : , : = ( M : , i , : , : ? μ i ) γ i σ i + β i . bn(M, μ,σ, γ, β):,i,:,: = (M:,i,:,: ? μi) {γi \over σi }+ βi . bn(M,μ,σ,γ,β):,i,:,:=(M:,i,:,:?μi)σiγi?+βi.
我们首先将每一个BN及其前面的卷积层转换成一个带有偏置向量的卷积。让 W 0 , b 0 {W0 , b0 } W0,b0
是从 W , μ , σ , γ , β {W, μ,σ, γ, β} W,μ,σ,γ,β转换而来的内核和偏置,我们有
W 0 i , : , : , : = γ i σ i W i , : , : , : , b 0 i = ? μ i γ i σ i + β i W0i,:,:,: = {γi \over σi }Wi,:,:,: , b0i = ?{μiγi \over σi }+ βi W0i,:,:,:=σiγi?Wi,:,:,:,b0i=?σiμiγi?+βi
很容易可以验证 ? 1 ≤ i ≤ C 2 ?1 ≤ i ≤ C2 ?1≤i≤C2
b n ( M ? W , μ , σ , γ , β ) : , i , : , : = ( M ? W 0 ) : , i , : , : + b 0 i . bn(M ? W, μ,σ, γ, β):,i,:,: = (M ? W0 ):,i,:,: + b0i . bn(M?W,μ,σ,γ,β):,i,:,:=(M?W0):,i,:,:+b0i.
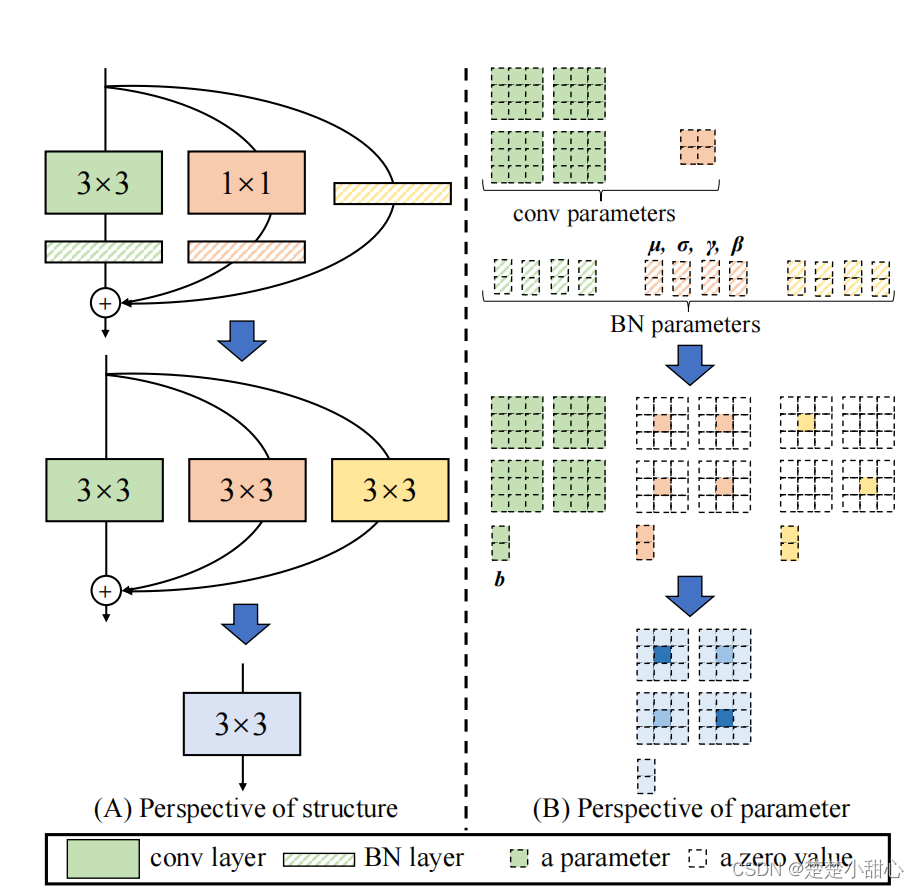
- 上述变换也适用于恒等分支,因为恒等分支可以看作是一个带有单位矩阵的1X1卷积的核。经过这样的变换,我们将得到一个3X3核,两个1X1核,和三个偏置向量。
- 然后我们获得最终的偏置通过添加了三个偏置向量,最后3X3内核通过在3X3内核的中心点上添加1X1内核。可以很容易地实现:先补零的两个1X1内核成为3X3内核,然后三个内核相加,如图4所示。
- 需要注意的是,此类转换的等效性要求3X3层和1X1层具有相同的步长,而1X1层的填充配置应比3x3层少一个像素。例如,对于一个3*3层填充一个像素的输入,这是最常见的情况,1x1层应该有填充(padding)= 0。
3.4. 结构规范
- 表2显示了RepVGG的规格,包括深度和宽度。RepVGG是VGG-style的,它采用简单的拓扑结构,大量使用3X3卷积,但它不像VGG那样使用最大池化,因为我们希望主体只有一种类型的操作。
- 我们将3x3卷积层排列为5个阶段,一个阶段的第一层以stride = 2的方式下采样。对于图像分类,我们使用全局平均池化,然后使用全连接层作为head。对于其他任务,特定于任务的head可以用于任何层产生的特征。
- 我们根据
三个简单的原则来决定每个阶段的层数。
1)第一阶段的操作分辨率较大,耗时较长,因此我们只使用一层以降低延迟。
2)最后一个阶段应该有更多的通道,所以我们只使用一层来保存参数。
3)我们将大部分图层放入最后的第二阶段(ImageNet输出分辨率为14X14),紧接着是ResNet及其最新版本(例如,ResNet-101在其14*14分辨率阶段使用了69层)。
我们让这五个阶段分别有1、2、4、14、1层来构建一个名为RepVGG-A的实例。我们还构建了一个更深层的RepVGG-B,在阶段2、3和4中有更多的层。我们使用RepVGG-A与其他轻量级和中量级模型(包括ResNet-18/34/50)竞争,使用RepVGG-B与高性能模型竞争。
- 我们通过统一缩放宽度设置来确定层宽度(例如VGG和ResNets)。我们使用
乘数a来衡量前四个阶段,最后一个阶段使用乘数b,通常设置b>a因为我们希望最后一层为分类或其他下游任务具有更丰富的特性。由于RepVGG在最后阶段只有一层,所以较大的b并不会显著增加延迟和参数的数量。具体来说,阶段2、3、4、5的宽度分别为[64a;128a;256a;512b]。为了避免在大的特征地图上进行大的卷积,我们对第一阶段进行了缩小,如果a<1,不要扩大它,使阶段1的宽度是最小的(64;64a)。- 为了进一步减少参数和计算,我们可以选择使用
密集的3X3卷积层来交换精度和效率。具体来说,我们将第3、5、7、…,第21层RepVGG-A和另外23、25、27层RepVGG-B设为组g。为了简单起见,我们对这类层全局设置g为1、2或4,而不进行分层调优。我们不使用相邻的逐群卷积层,因为这将禁用通道间信息交换,并带来一个副作用:特定通道的输出将仅来自一小部分输入通道。注意,1x1分支应具有与3x3 conv相同的g值。

4.实验
在本节中,我们比较了RepVGG与ImageNet上的基线的性能,通过一系列的消融研究和比较,论证了结构重参数化的意义,并验证了RepVGG在语义分割上的泛化性能。
4.1. RepVGG 用于 ImageNet 分类
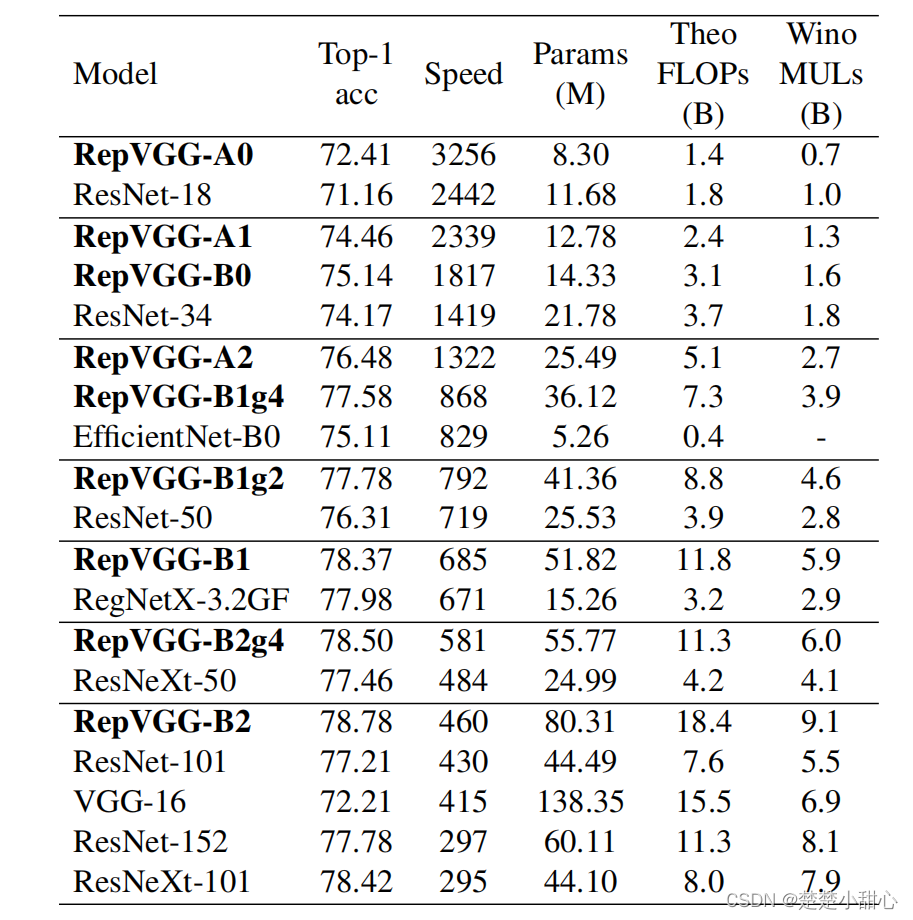
我们比较了RepVGG与经典和最先进的模型,包括VGG-16、ResNet、ResNeXt、EfficientNet和RegNet在ImageNet- 1K。
我们分别以EfficientNet-B0/B3和RegNet-3.2GF/12GF作为中量级模型和重量级模型的代表。
我们改变乘数a和b,生成一系列RepVGG模型,以与基线进行比较。如表3所示。
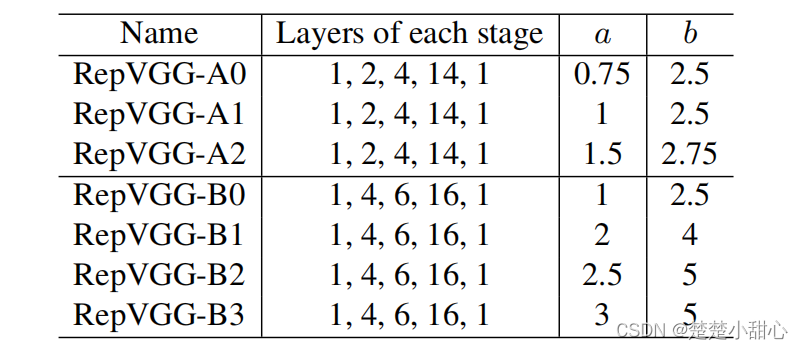
- 我们首先比较RepVGG和ResNets,这是最常用的基准。
- 与ResNet-18比较,对于RepVGG-A0,设a = 0.75, b = 2.5。
- 对于ResNet-34,我们使用更宽的RepVGG-A1。
- 为了使RepVGG的参数略少于ResNet-50,我们构建了a = 1.5,b = 2.75的RepVGG- a2。
- 为了与更大的模型进行比较,我们构造了深度更大的RepVGGB0/B1/B2/B3,并增加了宽度。
- 对于那些具有交叉分组层的RepVGG模型,我们在模型名后面加上g2/g4作为后缀。
- 为了训练轻量级和中量级模型,我们只使用简单的数据增强,包括随机裁剪和左右反转,遵循正式的PyTorch示例。
- 在8个gpu上
- 256batchsize
- 初始学习率为0.1
- 余弦退火120个轮次
- 标准SGD
- 动量系数为0.9
- 卷积层和全连接层的核上重量衰减为10-4
对于RegNetX-12GF、EfficientNet-B3和RepVGG-B3重量级模型,我们采用了:
5轮预热、200轮余弦学习率退火、标签平滑和混合算法,以及自动增强的数据增强pipline、随机剪切和反转。
RepVGG-B2及其g2/g4变种都在这两种设置下进行了训练。我们在1080Ti GPU 4上测试了128批的每个模型的速度,首先输入50batches对硬件进行预热,然后记录50batches的时间使用情况。
为了公平比较,我们在同一个GPU上测试所有模型,所有基线的conv-BN序列也转换为带有偏置的卷积。
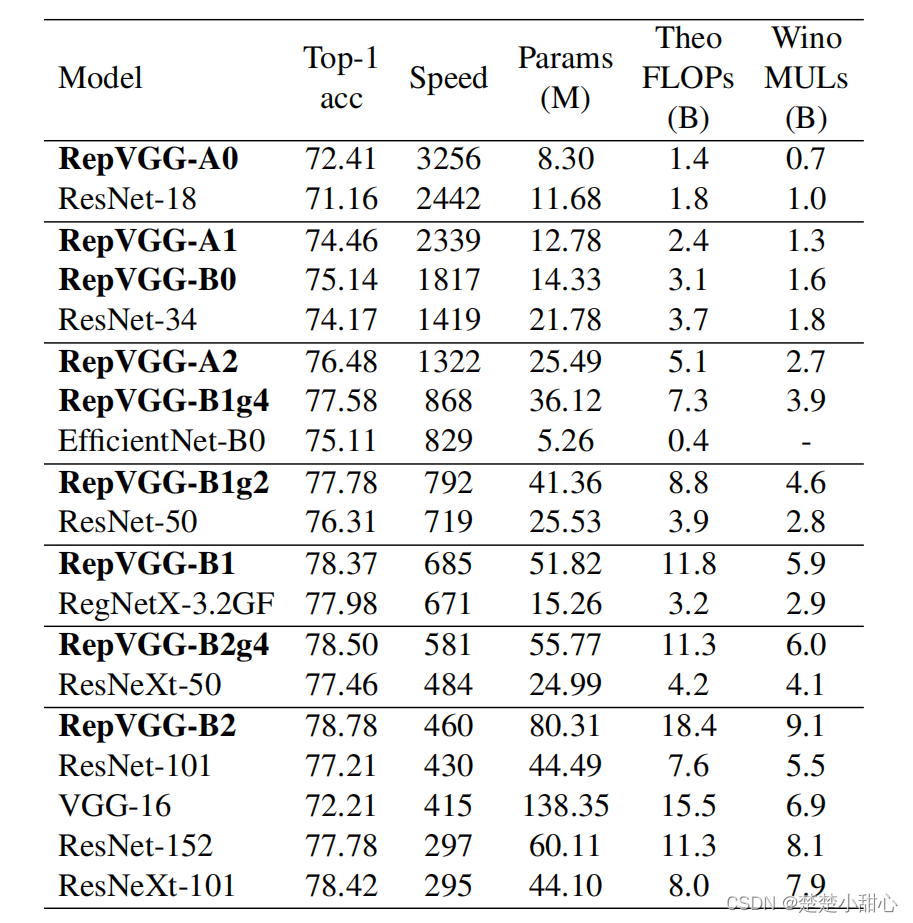
如表4和图1所示,RepVGG显示了良好的精度-速度平衡。例如,RepVGG-A0的精度和速度分别比ResNet-18高1.25%和33%,RepVGG-A1比ResNet-34高0.29%/64%,RepVGG-A2比ResNet-50高0.17%/83%。
采用分组分层(g2/g4),进一步加速了RepVGG模型的建立,并合理降低了模型的精度。例如,RepVGG-B1g4比ResNet-101好0.37%/101%,RepVGG-B1g2在相同精度下比ResNet-152快2.66。尽管参数的数量不是我们主要关心的问题,但是上面所有的RepVGG模型都比ResNets更有效地使用参数。
与经典的VGG-16相比,RepVGGB2只有58%的参数,运行速度快10%,精度高6.57%。与我们所知的精度最高(74.5%)的基于修剪的良好设计的训练方法RePr[25]训练的VGG模型相比,RepVGG-B2的准确率也高出4.28%。
与最先进的基线相比,RepVGG也表现出良好的性能,从简单性上看,RepVGG-a2比EfficientNet-B0高出1.37%/59%,RepVGG-b1比RegNetX-3.2GF高出0.39%,运行速度略快。
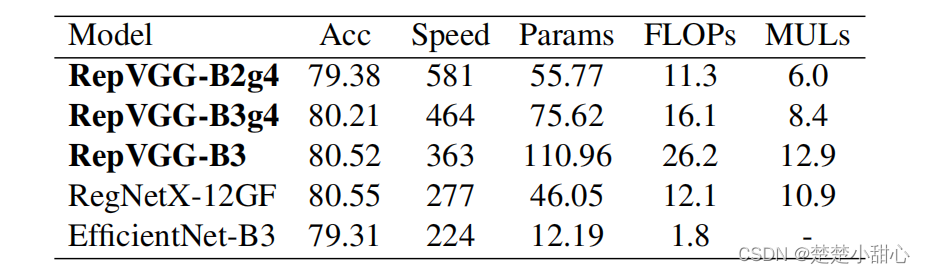
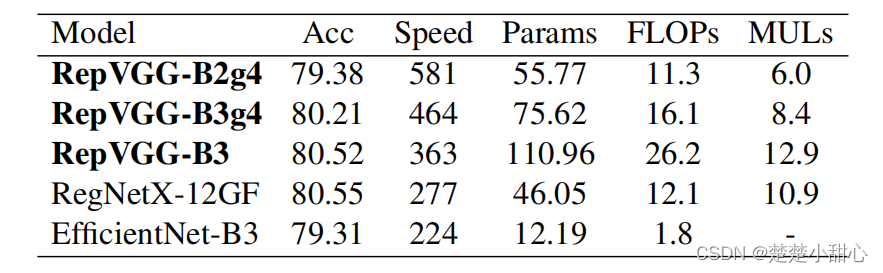
值得注意的是,RepVGG模型在200个epochs时达到了80%以上的精度(表5),这是我们所知的普通模型第一次赶上最先进的水平。与RegNetX-12GF相比,RepVGGB3的运行速度快了31%,考虑到RepVGG不需要像RegNet[27]那样大量的人力来完善设计空间,而且架构超参数的设置也很随意,这一点令人印象深刻。
作为计算复杂度的两个指标,我们计算2.4节中描述的理论失败和Wino MULs。例如,我们发现,在EfficientNet-B0/B3中,Winograd算法没有加速任何conv。表4显示Wino MULs在GPU上是一个更好的代理,例如,ResNet-152运行速度比VGG-16慢,理论上的失败次数更低,但Wino MULs更高。当然,实际速度应该永远是黄金标准。
4.2. 结构重参数化是关键
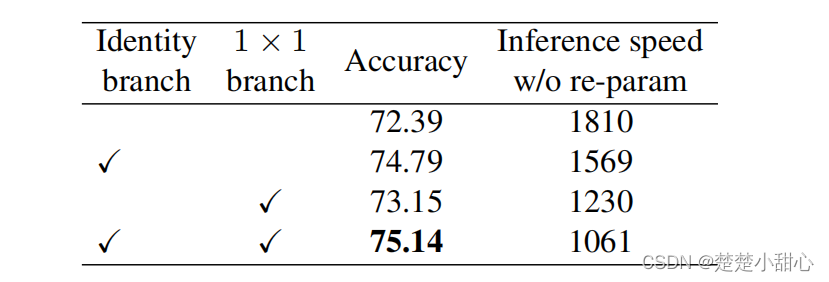
在本小节中,我们验证了我们的结构重参数化技术的重要性(表6)。所有的模型都是用上面描述的相同的简单训练设置从零开始训练120个epochs。首先,我们通过移除RepVGG-B0每个区块的恒等和11分支进行消融研究。
剔除两个分支后,训练时间模型退化为原始普通模型,准确率仅为72.39%。在只有1X1分支的情况下,准确率提高到73.15%,在只有恒等连接的情况下,准确率提高到74.79%。完整的RepVGG-B0模型的精度为75.14%,比原始普通模型的精度高2.75%。
然后我们构建了一系列的变量和基线用于比较RepVGG-B0(表7)。所有的模型都是在120个epochs从零开始训练的。
统一w/o BN层 删除标识分支中的BN。
Post-addition BN 删除三个分支中的BN层,并在添加后附加BN层。即BN的位置由加前变为加后。
+ReLU in branches 将ReLU插入到每个分支中(BN之后,add之前)。由于这样的块不能转换成一个单独的卷积层,因此没有实际用途,我们只是想看看更多的非线性是否会带来更高的性能。
DiracNet [38]采用了在2.2节中介绍的精心设计的卷积核的重参数化。我们使用它的官方PyTorch代码来构建层,以取代原来的33卷积。
Trivial Re-param 是对卷积核的一种更简单的重参数化,直接在33核中添加一个单位核,可以看作DiracNet的退化版本(^W = I +W[38])。
Asymmetric Conv Block (ACB) [9]可以看作是结构重参数化的另一种形式。我们与ACB进行比较,看看我们的结构重新参数化的改进是否是由于组件级的过度参数化(即,额外的参数使每个33卷积变得更强)。
Residual Reorg 构建每个阶段,通过重新组织它在一个类似resnet的方式(2层每个块)。具体来说,合成模型在第一阶段和最后阶段有一个3*3层,在第二阶段、第三阶段、第四阶段有2、3、8个剩余块,并使用像ResNet-18/34这样的捷径。
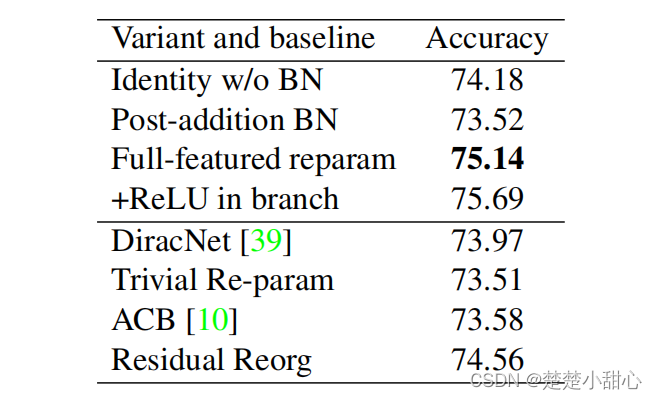
我们认为结构重参数相对于DiractNet和普通重参数的优势在于前者依赖于通过具有非线性行为(BN)的具体结构的实际数据流,而后者仅使用另一种卷积核的数学表达式。例如,前者的re-param是指使用一个结构的参数来参数化另一个结构,而后者是指先用另一组参数计算参数,然后再使用它们进行其他计算。对于训练时间BN这样的非线性分量,前者不能用后者近似。作为证据,通过去除BN降低了精度,通过添加ReLU提高了精度。换句话说,虽然一个RepVGG块可以等效地转换成一个单独的卷积来进行推理,但推理时间等价并不意味着训练时间等价,因为我们不能构造一个卷积层来具有与RepVGG块相同的训练时间行为。
与ACB的比较表明,RepVGG的成功不应该简单地归因于每个组件的过度参数化的影响,因为ACB使用了更多的参数,但不能像RepVGG那样提高性能。为了进一步确认,我们将ResNet-50的每个33卷积的替换为RepVGG块,并从头开始训练120个epochs。精度为76.34%,仅比ResNet- 50基线高0.03%,表明RepVGG-style结构重参数化不是一种通用的过度参数化技术,而是一种训练强大的普通卷积神经网络的关键方法论。
与Residual Reorg(具有相同33卷积数量以及用于训练和推理的其他快捷方式的真实残差网络)相比,RepVGG的表现高出0.58%,这并不奇怪,因为RepVGG有更多的分支。例如,分支使得RepVGG的stage4是2315 = 2.8107模型的集合,而剩余Reorg的数量是28 = 256。
4.3. 语义分割
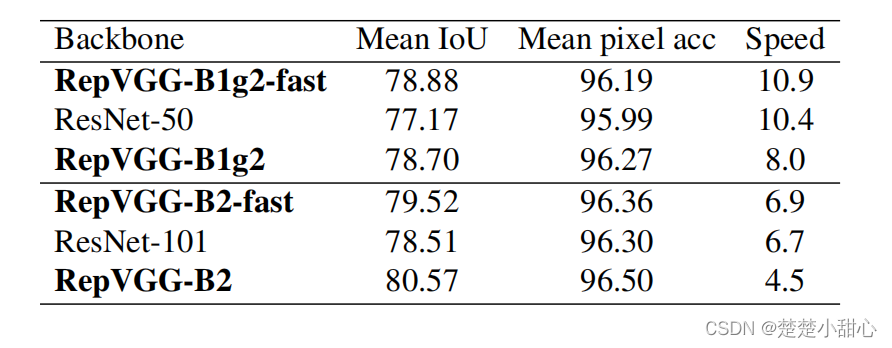
我们验证了imagenet预训练的RepVGG在城市景观上的泛化性能,该图像包含5K个精细标注的图像和19个类别。我们使用PSPNet框架,一个基为0.01,幂为0.9,权重衰减为10-4,全局批处理规模为16的多聚学习速率策略,在8个gpu上运行40个epochs。为了公平比较,我们只将ResNet-50/101骨干更改为RepVGG-B1g2/B2,其他设置保持一致。
在PSPNet-50/101正式实施后,在ResNet-50/101的最后两个阶段使用了扩张的卷积,我们也对RepVGG-B1g2/B2的最后两个阶段的所有33卷积层进行了扩张。由于目前33扩张卷积的低效实现(尽管FLOPs与3*3常规卷积相同),这样的修改减缓了推理。为便于比较,我们建立两个PSPNets(在表8中用fast表示)膨胀只有在最后5层(例如,最后4层stage4和唯一的stage5层),所以PSPNets运行略高于ResNet-50/101骨干。结果表明,RepVGG骨干的平均IoU比ResNet-50和ResNet-101分别高出1.71%和1.01%。令人印象深刻的是,RepVGG-B1g2-fast在mIoU中的性能比ResNet- 101骨干高出0.37,运行速度快62%。有趣的是,与RepVGG-B1g2-fast模型相比,扩大的卷积层似乎对更大的模型更有效,但扩大后的RepVGG-B2的mIoU提高了1.05%,并有合理的放缓。
4.4.局限性
RepVGG模型是快速、简单和实用的卷积网络,为GPU和专用硬件上的最大速度而设计,较少考虑参数数量。尽管RepVGG模型比ResNets更具参数效率,但在低功耗设备上,它们可能不如MobileNets和ShuffleNets等移动设备模型受欢迎。
5.总结
我们提出了RepVGG,一个由3X3卷积和ReLU组成的简单架构,特别适合于GPU和专业推理芯片。通过我们的结构重参数化方法,这种简单的卷积网络在ImageNet上达到了80%以上的top-1精度,与最先进的复杂模型相比,在速度-精度方面表现出了良好的权衡。