���˼�ʻ���
�Զ���ʻ�����ȼ�
| �Զ���ʻ�ȼ� | ���� |
|---|---|
| L0 �C No automation | ������Ϊ��ȫ���˿���,ϵͳ�����ṩԤ����ʾ��� ADAS ����,��������ƫ��Ԥ��,ǰײԤ����,����������Ԥ���� |
| L1 �C Driver assistance | ��ʻ����,�˲ٿس���,����ϵͳ���Ե��������ٶȺͷ���������ӦѲ��,��������,����ɲ���ȹ��� |
| L2 �C Partial automation | �����Զ���ʻ,�߱��Զ�����,�Զ�ɲ��,�Զ�ת������,ϵͳ�߱�������ʻ����,���Ǽ��������Ȼ��Ҫ��������,�����������Ҫ�˹����� |
| L3 �C Conditional automation | ���������Զ���ʻ,ָ�����������������,����ʵ�ֳ�����ȫ��֪����,�������������߿��ơ������ڽ��������,ϵͳ��������Ѱ���˹����� |
| L4 �C Full automation | ȫ�Զ���ʻ,����Ҫ�˹���ʻԱ,����Ҫ�˹�����,�������������л��� |
���˼�ʻ - �ܹ�
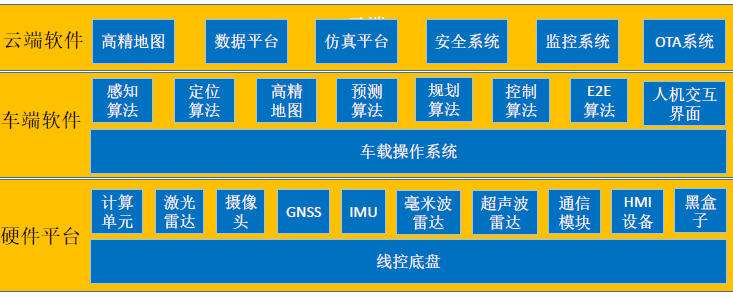
GNSS + IMU:��ϵ���
���˼�ʻ - ��������
- ȷ�����/�յ�,�滮·��
- Where Am I (HD map & Localization):������ȷ�ϵ�ǰλ��,��·����ʻ

- What��s Around Me (Perception):�۲��Գ���Χ������Ϣ
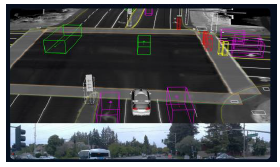
- Where Will Happen (Prediction):Ԥ��������ͨ��������Ϊ(����/����/���˺ᴩ��)
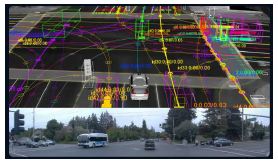
- What Should I Do (Planning & Control):���߱�����Ϊ(�Ӽ���/���е�)��ʵʩ
�߾���ͼ�붨λ
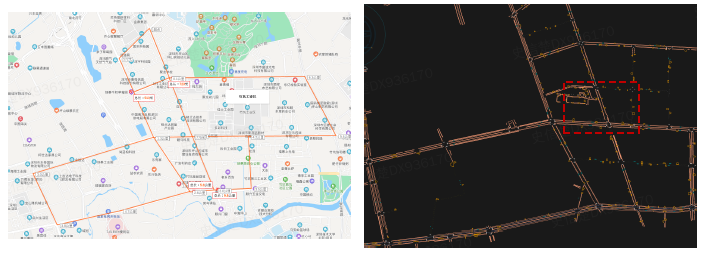

��֪���
- ��:ͨ������/����ʽ������,����ԭʼ�Ļ�����Ϣ
- ֪:�Խ��յ���Ϣ��������,�õ����Ժ�ϵ���ɵ�����

�����״�
- Velodyne - 32 �����״�:32 �����������״���ϵ���ͬ������ 32 ������,���� TOF (time of flight) ԭ�����в��;�Ƿֱ��� 0.2 �� ��ʾ�����״�ÿת 0.2 �Ⱦͷ���һ�μ���
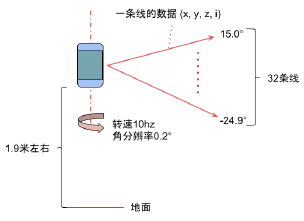
- Velodyne - 32 ���������ݿ��ӻ�ʾ��

����������
- �������� (Point Cloud):3D ��Ϣ��ȷ��֪,���ɱ���,����������,ϡ��СĿ������©,ʶ�������� (����ѩ���ȼ������������ܽϲ�,����ȫ����)
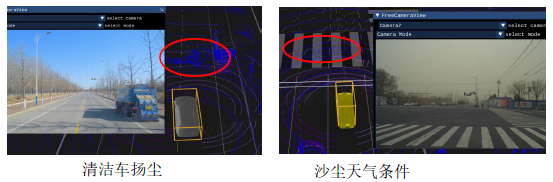
- ͼ������ (Pixel):����������,�ܹ���Ӱ���,3D ������

- ���ײ��״�����:���ײ�����������ǿ,����ȫ�������,�����,��������ǿ,���߶���Ϣȱʧ (��ȼ����״�,��Χ��Զ����ྫ�ȸ���)
ҵ����״
Top-down ȫ�Զ���ʻ (L4)

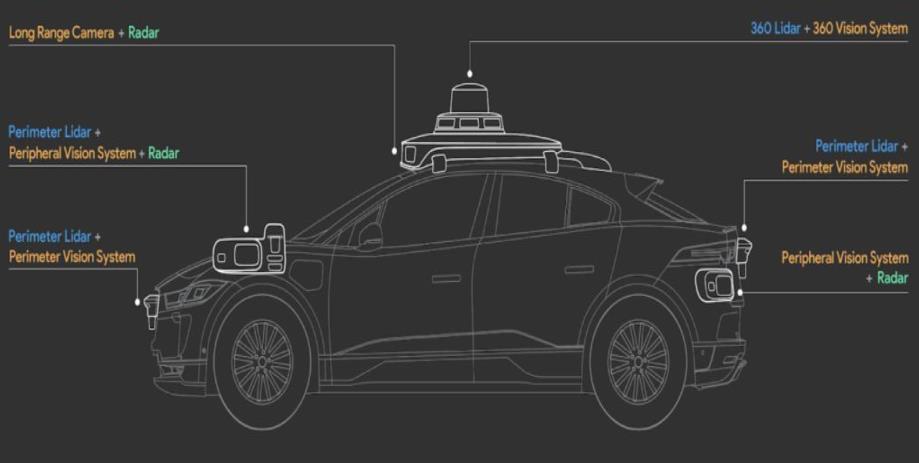
- �ص�:�ؼ����״�,�ഫ�����ں�
- �ŵ�:��֪����ǿ,������Դ��
- ����:�������ɱ���,������չ��
Bottom-up ����ʽ�Զ���ʻ (L2 ~ L3)

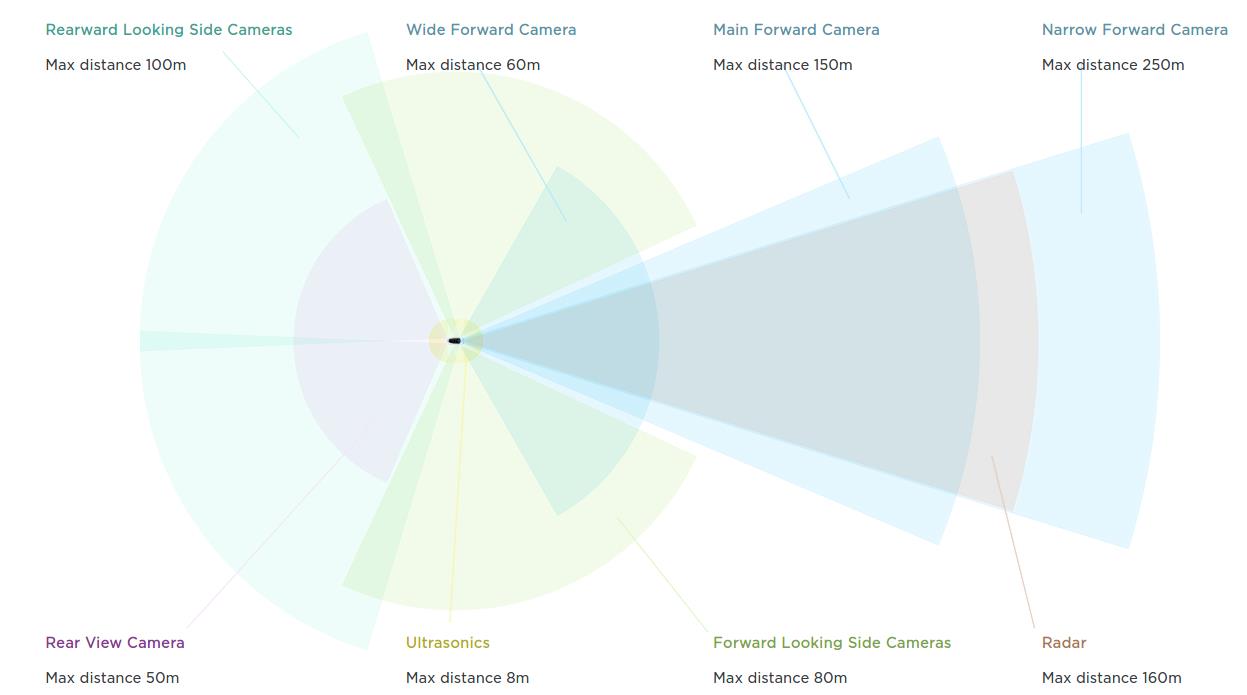
- �ص�:����������,������ʻ,�˻����
- �ŵ�:�ɱ��ܿ�,��ģ��Ӧ��,������չ��
- ����:��֪���������
��֪����
- �ϰ����֪:�ϰ��� 3D �ռ���Ϣ(λ��,�ߴ�)+ ������Ϣ(�ٶ�,����,״̬)
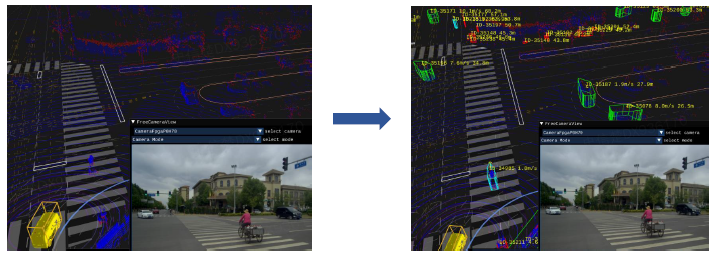
- ��������:����������Ϣ

- �źŵ�ʶ�� / ��ͨ��ʶ��֪:���̵Ƶ�״̬��Ϣ(��/��/��/��/����/���ֵ�)

�ϰ����֪
- ����Ŀ��:������Χ�����е�Ŀ����Ϣ,�����ռ�λ��/�ߴ�/����/�ٶ�/�����Լ��������õ�����
һ���ϰ����֪���ͼ
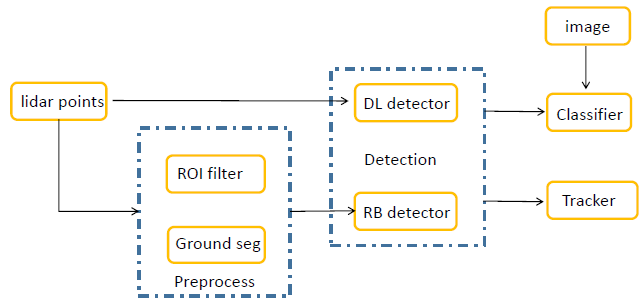
�����ϰ����֪ - Ԥ����
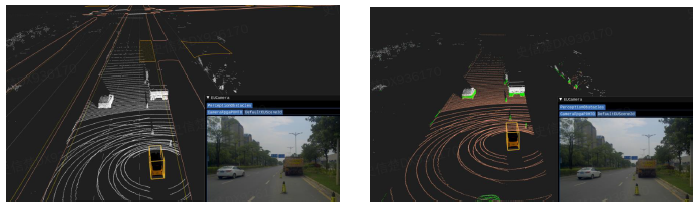
ROI (Region of Interest ) filter: ����Ȥ�����˲�
- ͨ������ / ����֪ʶȥ���������Ϣ,��������Ч�� / �Ľ���֪Ч�� (����ͼ��ʾ,�˳���·���صĵ�����Ϣ)

����ָ�
- ���ֵ����ͷǵ���� (����ԭ��: (�ֲ�)ƽ�����;�߶�����)
- ƽ��դ��:1) �� X-Y ƽ�滮��Ϊ���դ��(grid),����ͶӰ����Ӧդ����;2) ����ÿ��դ���� 3D �㼯��
z
z
z ����ͳ��ֵ,��ƽ��ֵ,����,ƫ��(�߶Ȳ�);3) ����ͳ��ֵ��Ԥ�����õ� threshold ���ж�ʵ��դ��ĵ���/�ǵ��������
- ����:���õ��Ƹ߶ȵ�ͳ������,��/ֱ��
- ����:��б�������Դ���,Զ����դ������ͳ�����Բ����ȶ�
- ģ����Ϸ�:ƽ����� - RANSAC ��:���ѡ�� 3 �������,���ƽ�淽��
A
x
+
B
Y
+
C
Z
+
D
=
0
Ax+BY+CZ+D=0
Ax+BY+CZ+D=0,�����е����δ����ƽ�淽����,�����ƽ����ڵ���� (�趨һ����ֵ,�㵽ƽ��ľ���С����ֵ����Ϊ�õ�Ϊ�ڵ�);�������ڵ�����ƽ����Ϊ����ƽ��,��ƽ����ڵ㼴Ϊ�����,��㼴Ϊ�ǵ���� (Fast segmentation of 3D point clouds: A paradigm on LiDAR data for autonomous vehicle applications)
- ����:�����ҵ���б����
- ����:ƽ�治���ڵ���,δ���ó�������,���㸴��
- ��Ԫ����:1) ѡ�����ӵ�(�߶�/����/������);2)��������,�������ӵ�������ľֲ��ṹ(�߶Ȳ�/ˮƽƫ��/������ƫ��)��,�����������������չ���������ѡ;3)�ظ������õ��ֲ����漯��,�Ծֲ����漯����ƽ����Ϻͽ���,�õ���ϸ����㼯
- ����:���þֲ����νṹ,���Եõ�����ֲ���ƽ��
- ����:���㸴��
�����ϰ����� - ���� (Rule-based method)
- Rule based detector:��ǰ������ĵ���ڵ��Ƶ��ܶ�/�ռ���������� (k-means, mean-shift, dbscan),�õ��ϰ��� candidate

�����ϰ����� - ���ѧϰ�㷨
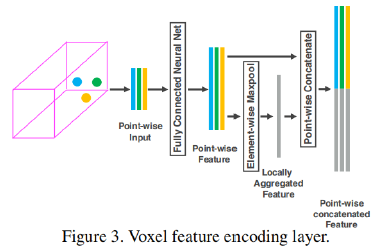
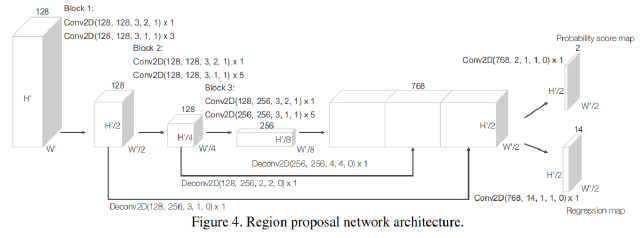
Voxelnet: End-to-end learning for point cloud based 3d object detection
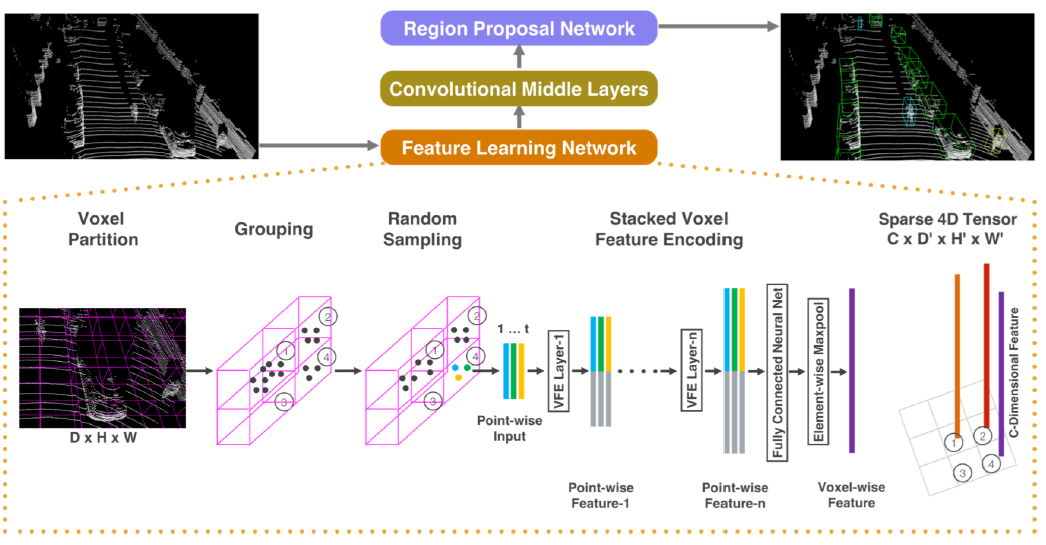
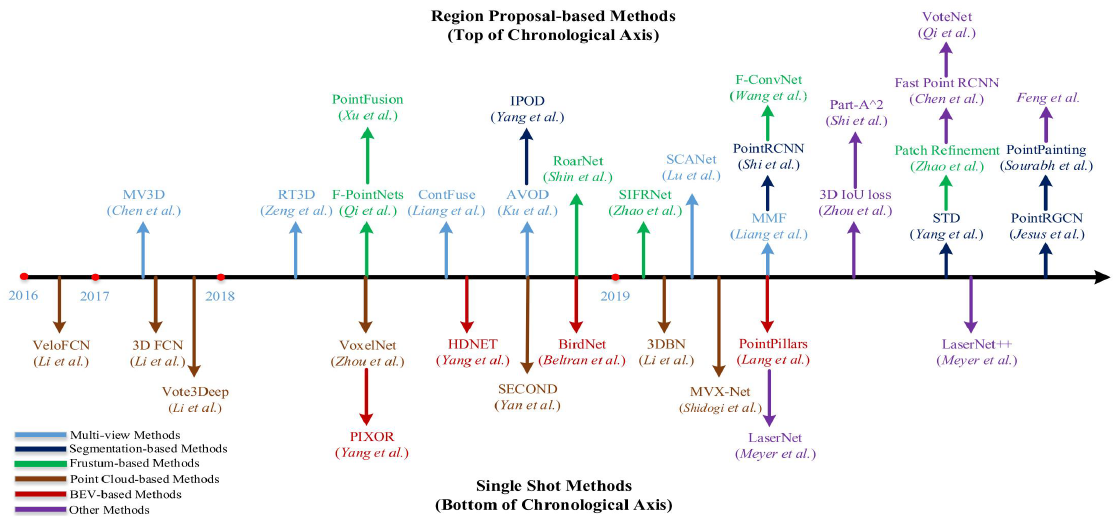
Deep Learning for 3D Point Clouds: A Survey
�����ϰ������
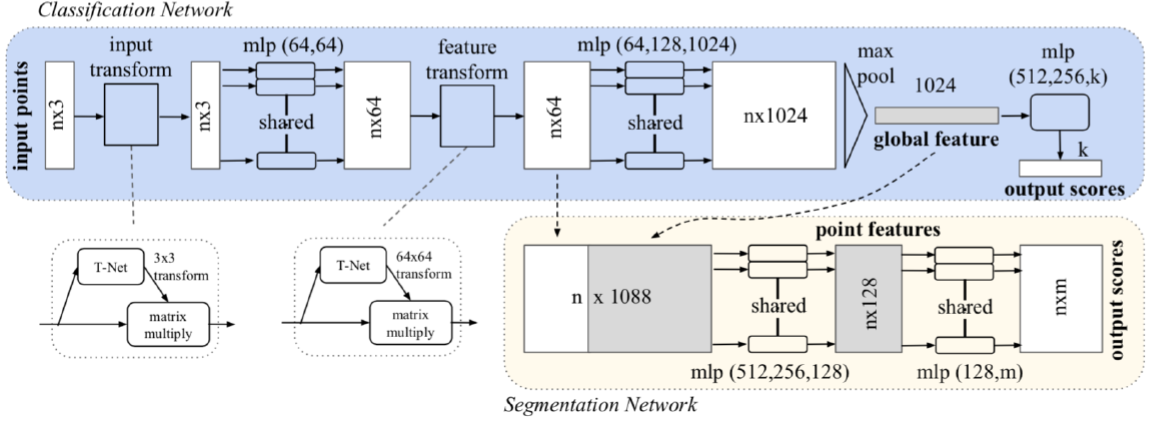
Pointnet: Deep learning on point sets for 3d classification and segmentation
�����ϰ������
- ��Ŀ�����:ͬʱ���ֶԶ��Ŀ�����,ʵ��Ŀ��ʱ���˶�״̬��Ϣ�Ŀ̻�

- ��Ŀ�����:��֡:Hungarian algorithom;��֡:Multiple-hypothesis tracking (An algorithm for tracking multiple targets. Tracking and data association.)

- ״̬���������:Kalman filter:A new approach to linear filtering and prediction problems


�Ӿ��ϰ����֪
- Object detection:Object Detection in 20 Years: A Survey
- �Ӿ� 3D ��֪:2D detection
��
\rightarrow
�� 3D box
- ��Ŀ����Լ������:Vision-based ACC with a Single Camera: Bounds on Range and Range Rate Accuracy
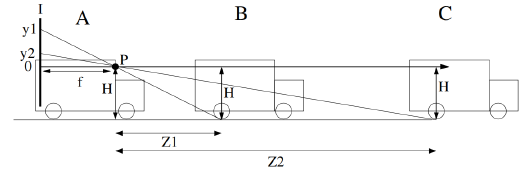
 �ӵص㷨:
Z
=
f
H
y
Z=\frac{fH}{y}
Z=yfH?
�ӵص㷨:
Z
=
f
H
y
Z=\frac{fH}{y}
Z=yfH?
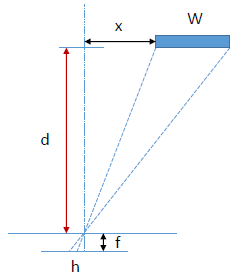
ģ����Ʒ�: d / f = x / h 1 d/f=x/h_1 d/f=x/h1?, d / f = ( x + w ) / h 2 d/f=(x+w)/h_2 d/f=(x+w)/h2? ( w w w:Ŀ�����ʵ����,����Ԥ����)
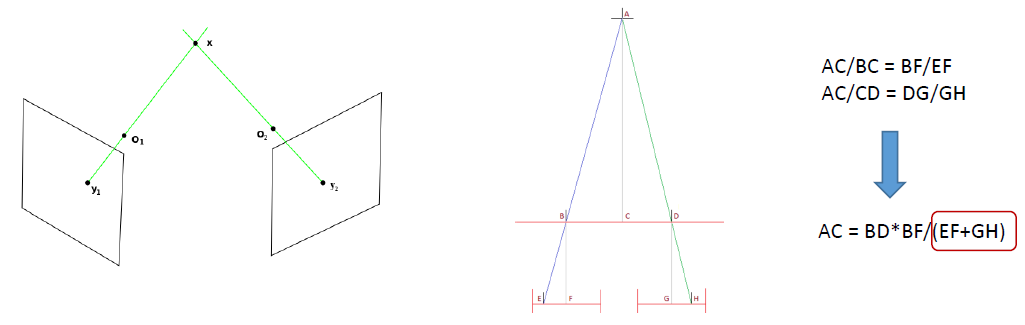
- ˫Ŀ 3D ���� (Multiple View Geometry in computer vision):triangulation refers to the process of determining a point in 3D space given its projections onto two, or more, images. In order to solve this problem it is necessary to know the parameters of the camera projection function from 3D to 2D for the cameras involved, in the simplest case represented by the camera matrices
- �������ѧϰ�ķ���:
��Ŀ��ȹ���
Deeper Depth Prediction with Fully Convolutional Residual Networks,3DV 2016
Deep Ordinal Regression Network for Monocular Depth Estimation. CVPR 2018
From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation Group-wise Correlation Stereo Network,CVPR 2019
˫Ŀ��ȹ���
Learning for Disparity Estimation through Feature Constancy,CVPR 2018
SegStereo: Exploiting Semantic Information for Disparity,ECCV 2018
Group-wise Correlation Stereo Network,CVPR 2019
��Ŀ 3D ���
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. CVPR 2019
Monocular 3D Object Detection via Geometric Reasoning on Keypoints. arXiv:1905.05618
Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction. CVPR 2019
- ��Ŀ����Լ������:Vision-based ACC with a Single Camera: Bounds on Range and Range Rate Accuracy
�ϰ����ںϸ�֪
- �ںϸ�֪:���ö��ִ���������Ϣ��ʵ��ͬһ��֪����
�����ںϵĴ�����ʽ
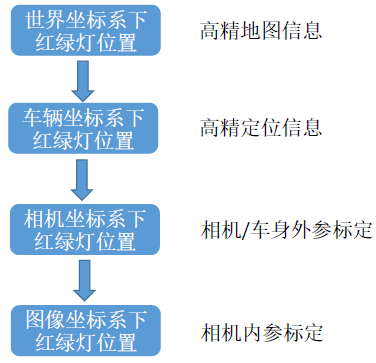
- ���ݲ��ں�:�Ӿ� + ����ԭʼ���ݵ��ںϡ��������궨:������ͬ����������ϵ��ת����ϵ,�ڴ�ת����ϵ�¿��ҵ�ͬһĿ���ڲ�ͬ����������ϵ�µĿռ�λ��

- �м���ں�:�Ӿ� + ���� + ���ײ��м䴦��������ں� (lidar / camera �м���ں�: Frustum pointnets for 3d object detection from rgb-d data)

- ���߲��ں�:�Ӿ� + ���� + ���ײ�������֪������ںϡ��� 2D box & attribute �� 3D lidar detection ��������ں�


������֪
Why we need scene understanding ?

������֪ - ʩ������
Special object detection & bottom-up clustering
������֪ - ˮ��ʶ��
Image segmentation + 3D polygon fitting
������֪ - ����ʶ��
Image classification

������֪ - �������
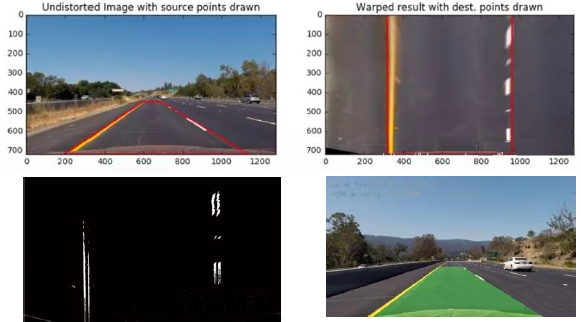
��ͳ����
- (1) ͼ��ӳ�䵽 BEV �ӽ�(��ѡ)
- (2) ��ֵ��/��Ե���
- (3) ����:��Ե����ȡ + ֱ��/�������,�����任 + �������
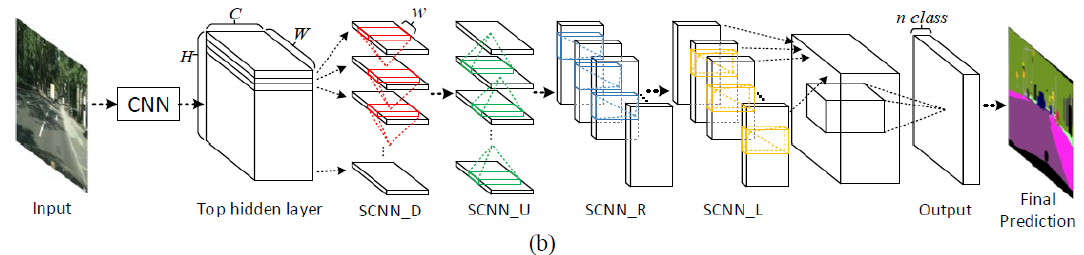
���ѧϰ���� - Spatial As Deep: Spatial CNN for Traffic Scene Understanding. AAAI 2018
�źŵƸ�֪
- ���̵�:�̶����̵�/�ƶ����̵�;����������/�ǻ���������/���к���źŵ�;��ͷ��/Բ�ε�/���ε�/�����;������/���ϵ�
- ���̵Ƹ�֪: Ѱ����Ч���Ƶ�,ʶ����Ч�Ƶ���ɫ
һ�̶ֹ��źŵ�ʶ�������
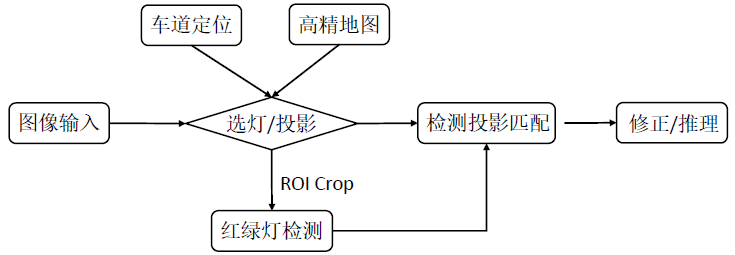
- ѡ��:���߾���λ&��ͼ��ȡ������Ϣ,Ȼ�����߾���ͼ��ȡ���Ƶ���Ϣ (��ǰ������Ӧ·�ڵ��ĸ������źŵ�)
- ���̵�����ת������:
- ���̵� ROI Crop:�̿�:���ڸ߾���ͼ/��λ�����̵�ͶӰ��;�ƿ�:����ͶӰ������Χ�õ��� ROI Crop ����;���:�Իƿ����������̵Ƽ���Ľ��

- ͶӰ���ƥ��:�Ѽ��������̵Ƽ���ͻ��ڸ߾���ͼ/��λ�ĺ��̵�ͶӰ�����ƥ��;���ڼ���ͶӰ����������,��������������ƥ���㷨
 ������ƥ�������:��©��/��쵼�µ�ƥ�����
������ƥ�������:��©��/��쵼�µ�ƥ�����
 �������:����ƥ��
?
\Rightarrow
? �ṹƥ��
�������:����ƥ��
?
\Rightarrow
? �ṹƥ��
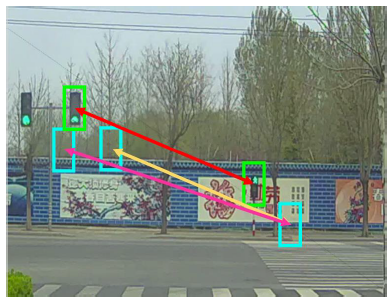
- ������:
��������ĺ��̵�ʶ��
 ���ڹ���ĺ��̵�У��:����״̬������
���ڹ���ĺ��̵�У��:����״̬������
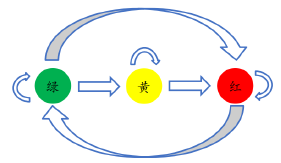
�ƶ����̵�ʶ��

- ��������:(1) �̶����̵�·��;(2) �̶����̵ƻ�����ʱ��
- ����ԭ��:(1) ȫͼʶ���ʼ��;(2) ͨ���߾���ͼ/lidar���У��
Corner case

- �����������̵ƽ��������:�����źŵƱ��ڵ�ʱ,������������δ���ڵ����źŵƽ�������
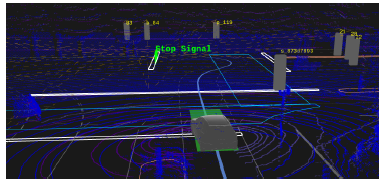
- ���ڽ�ͨ��������

���˼�ʻ��֪ - �ο�����
Open course
- CSC2541 - Visual Perception for Autonomous Driving
- MIT 6.S094: Deep Learning for Self-Driving Cars
- ���˼�ʻ�ɻ���
Survey
- Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art Self-Driving Cars: A Survey
- Towards Fully Autonomous Driving: Systems and Algorithms
- A Survey of Autonomous Driving: Common Practices and Emerging Technologies
- Self-Driving Cars: A Survey
Open source
- Apollo - https://github.com/ApolloAuto
- Autoware.ai - https://www.autoware.ai/
Labs & guys
- CASIL-MIT,Robotics-CMU,SAIL-Stanford
- Raquel Urtasun (University of Toronto),Andreas Geiger (University of T��bingen)