
{kind=link}
工具&框架
🚧 『mmyolo』OpenMMLab YOLO 系列工具箱
https://github.com/open-mmlab/mmyolo
https://mmyolo.readthedocs.io/en/latest/
MMYOLO 是一个基于 PyTorch 和 MMDetection 的 YOLO 系列算法开源工具箱。它是 OpenMMLab 项目的一部分。主分支代码目前支持 PyTorch 1.6 以上的版本。


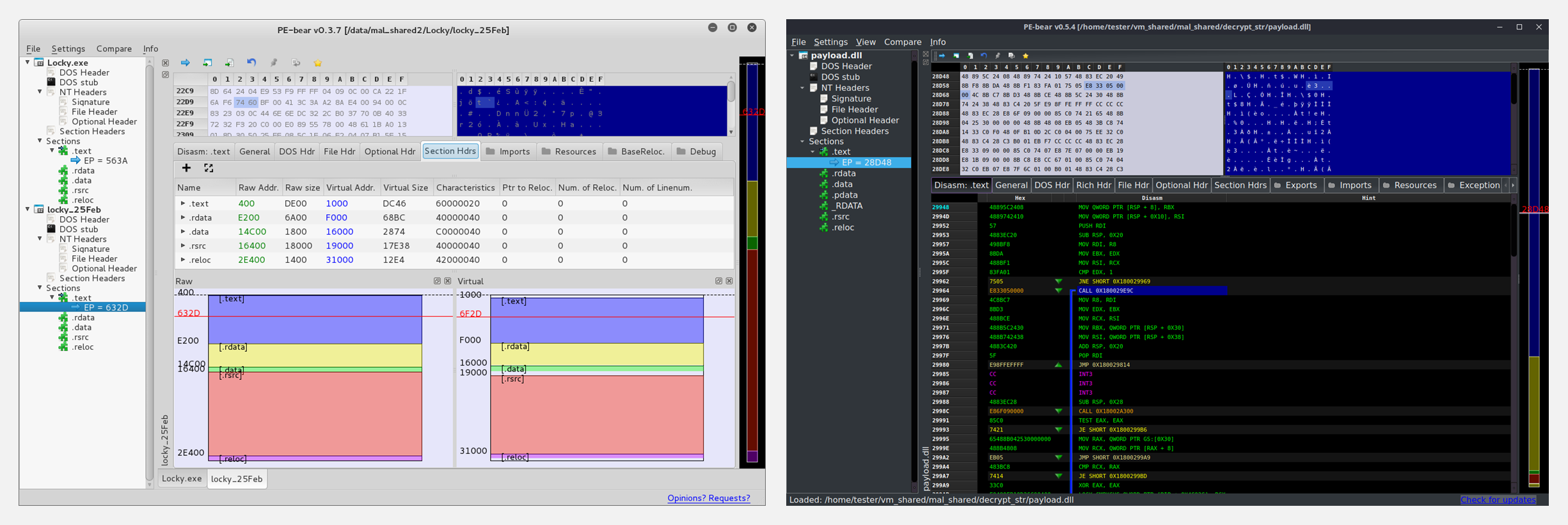
🚧 『pe-bear』界面友好的PE文件逆向工具
https://github.com/hasherezade/pe-bear
https://hshrzd.wordpress.com/pe-bear/
PE-bear 是一个跨平台的PE文件逆向工具。它的目标是为恶意软件分析人员提供快速和灵活的『第一视角』,稳定并能够处理异常的PE文件。
🚧 『LAVIS』一站式语言-视觉智能库
https://github.com/salesforce/LAVIS
LAVIS 是一个用于 LAnguage-and-VISion(语言-视觉)智能研究和应用的 Python 深度学习库。这个库的目的是为工程师和研究人员提供一个一站式的解决方案,为他们特定的多模态场景快速开发模型,并在标准和定制的数据集上进行基准测试。它有一个统一的界面设计,支持:
- 10多个任务(检索、字幕、视觉问题回答、多模态分类等)
- 20多个数据集(COCO、Flickr、Nocaps、Conceptual Commons、SBU等)
- 30多个经过预训练的最先进的基础语视模型的权重及其特定任务的适应性(包括ALBEF、BLIP、ALPRO、CLIP)

🚧 『Obsidian Tasks』Obsidian 知识库的任务管理器
https://github.com/obsidian-tasks-group/obsidian-tasks
https://obsidian-tasks-group.github.io/obsidian-tasks/
Obsidian Tasks 是 Obsidian 知识库的任务管理器,跟踪与查询任务,并在你想做的地方将它们标记为已完成。支持截止时间、重复性任务、完成日期、检查表项目的子集和过滤。

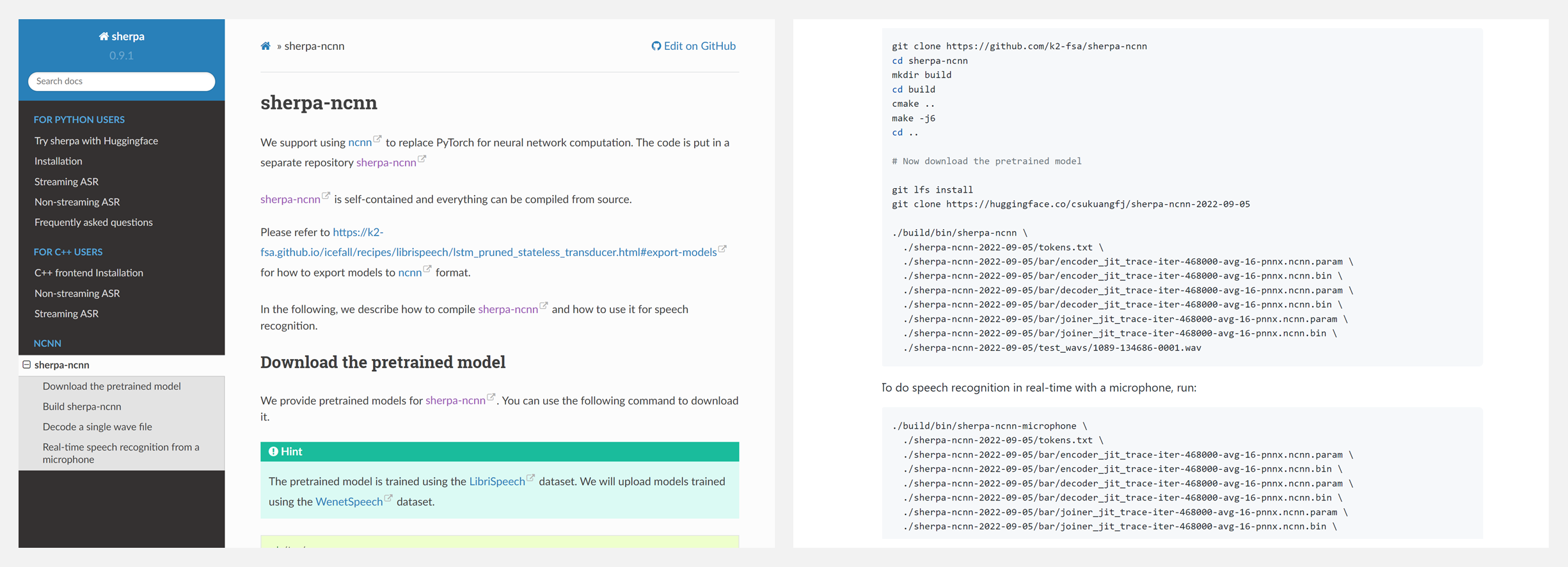
🚧 『sherpa-ncnn』使用下一代Kaldi与ncnn的实时语音识别工具
https://github.com/k2-fsa/sherpa-ncnn
https://k2-fsa.github.io/sherpa/ncnn/index.html
sherpa-ncnn是使用下一代Kaldi与ncnn的实时语音识别工具,有训练好的预训练模型,对英文可以做很好的识别支撑,中文的支持也正在更新开发中。
博文&分享
👍 『(ADL4CV) Advanced Deep Learning for Computer Vision』 慕尼黑工业大学 ・ 计算机视觉深度学习进阶课
https://www.showmeai.tech/article-detail/343
https://www.bilibili.com/video/BV1Tf4y1L7wg/
ADL4CV,全称是 Advanced Deep Learning for Computer vision (ADL4CV),是慕尼黑工大讲授的计算机视觉方向进阶课程,覆盖深度学习计算机视觉基础之上的进阶深度内容,包括:神经网络可解释性、相似度与度量学习、自注意力与transformer、图神经网络、生成模型与GAN、无监督学习、视频处理、迁移学习等。

课程主要面向深度学习计算机视觉进阶内容,有深度学习和计算机视觉基础的同学可以通过本课程进阶,学习到更深入的CV研究方向和内容。课程包含以下主题:
- Introduction to the course and projects(课程与项目介绍)
- Neural network visualization and interpretability(神经网络可视化与可解释性)
- Similarity Learning(相似度与度量学习)
- Attention and transformers(注意力与transformer)
- Graph neural networks(图神经网络)
- Autoencoders & VAE(自编码器与VAE)
- Generative models I(生成模型与GANI)
- Generative models II(生成模型与GANII)
- Videos, autoregressive models, multi-dimensionality(视频处理、自回归模型、高维)
- Domain Adaptation and Transfer Learning(自适应与迁移学习)
课程对应的资料和视频公开放出,ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
课程公开资料为第1章~第10章的 📚『课件/Slides』,制作得非常专业和用心,如下图所示。

👍 『(CS294) Deep Unsupervised Learning』Berkeley 伯克利 ・ 深度无监督学习课程
https://www.showmeai.tech/article-detail/344
https://www.bilibili.com/video/BV1uq4y1p7fG
深度学习的研究方向包括一个非常重要的主题:对无标签数据的应用。CS294 是顶级名校 UC 伯克利的课程,针对无监督学习的场景展开,包括深度生成模型和自监督学习两大主题。其中,生成模型使得对自然图像、音频波形和文本语料库等高维原始数据进行真实建模成为可能;而自监督学习算法在逐步缩小监督表示学习和非监督表示学习之间的差距。

CS294 课程涵盖了许多当前的最新研究和模型,是研究生级课程。对无监督学习和深度学习感兴趣的小伙伴可以重点关注这门课程。课程包含以下主题:
- Autoregressive Models(自回归模型)
- Flow Models(流模型)
- Latent Variable Models(变分自动编码器)
- Generative Adversarial Networks(生成对抗网络)
- Self-Supervised Learning(自监督学习)
- Semi-Supervised Learning(半监督学习)
- Unsupervised Distribution Alignment(无监督分布对齐)
- Compression(压缩)
- Learning from Text (OpenAI)(文本学习)
- Representation Learning in Reinforcement Learning(表征学习)

ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
📚 课件(PDF)。Lecture 1~23所有章节。
📚 课程示例代码(.ipynb文件)。可colab运行。
📚 课程作业与解答(.ipynb文件)。Homework 1~4。可colab运行。
📚 deepul(.py文件)。示例代码与作业辅助函数

数据&资源
🔥 『How DALL・E 2 Works』 DALL・E 2工作原理通俗解析
http://adityaramesh.com/posts/dalle2/dalle2.html

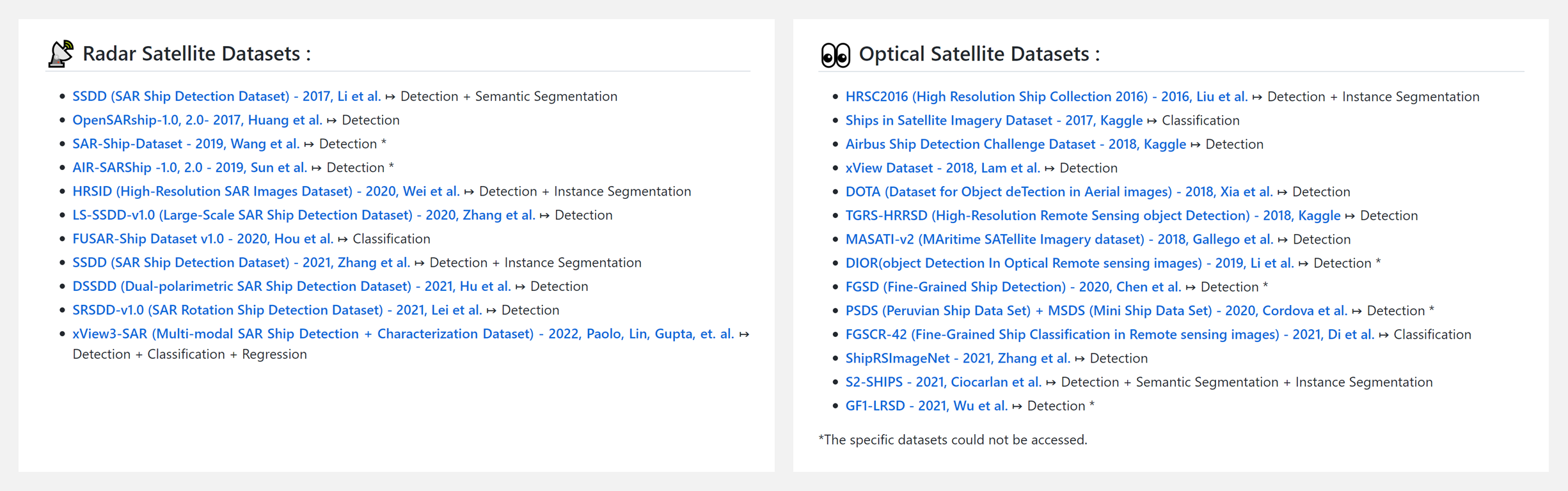
🔥 『Satellite imagery datasets containing ships』包含船只的卫星图像数据集列表
https://github.com/JasonManesis/Satellite-Imagery-Datasets-Containing-Ships
用于船舶检测、分类、语义分割、实例分割任务的雷达和光学卫星数据集列表。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.22 『少样本学习』 Efficient Few-Shot Learning Without Prompts
- 2022.08.29 『自监督学习』 CounTR: Transformer-based Generalised Visual Counting
- 2022.07.17 『物体重建』 An Algorithm for the SE(3)-Transformation on Neural Implicit Maps for Remapping Functions
? 论文:Efficient Few-Shot Learning Without Prompts
论文时间:22 Sep 2022
领域任务:Few-Shot Learning,少样本学习
论文地址:https://arxiv.org/abs/2209.11055
代码实现:https://github.com/huggingface/setfit
论文作者:Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg
论文简介:This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques./这个简单的框架不需要提示或口述者,并以比现有技术少几个数量级的参数实现了高精确度。
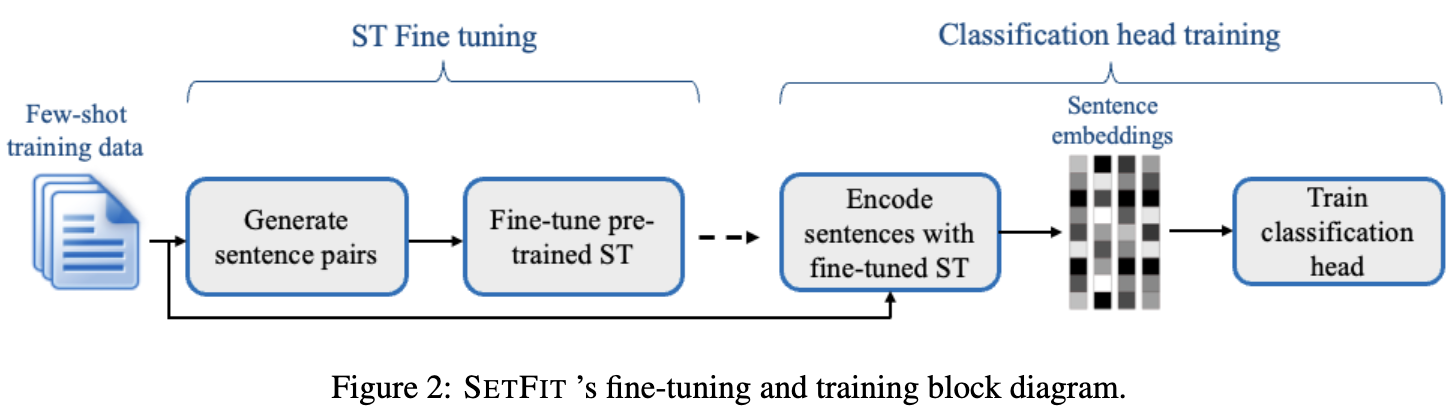
论文摘要:最近的一些方法,如参数有效微调(PEFT)和模式利用训练(PET),在标签稀缺的情况下取得了令人印象深刻的结果。然而,它们很难被采用,因为它们受制于手工制作的提示语的高变异性,并且通常需要十亿个参数的语言模型来实现高精确度。为了解决这些缺点,我们提出了SetFit(句子变换器微调),这是一个高效且无提示的框架,用于对句子变换器(ST)进行少量微调。SetFit的工作原理是,首先以对比连带的方式,在少量的文本对上对预训练的ST进行微调。然后,产生的模型被用来生成丰富的文本嵌入,这些嵌入被用来训练一个分类头。这个简单的框架不需要任何提示或口头语,并且以比现有技术少几个数量级的参数实现了高精确度。我们的实验表明,SetFit获得了与PEFT和PET技术相当的结果,同时其训练速度快了一个数量级。我们还表明,SetFit可以在多语言环境中应用,只需切换ST主体即可。我们的代码可在 https://github.com/huggingface/setfit 获取,我们的数据集可在 https://huggingface.co/setfit 获取。

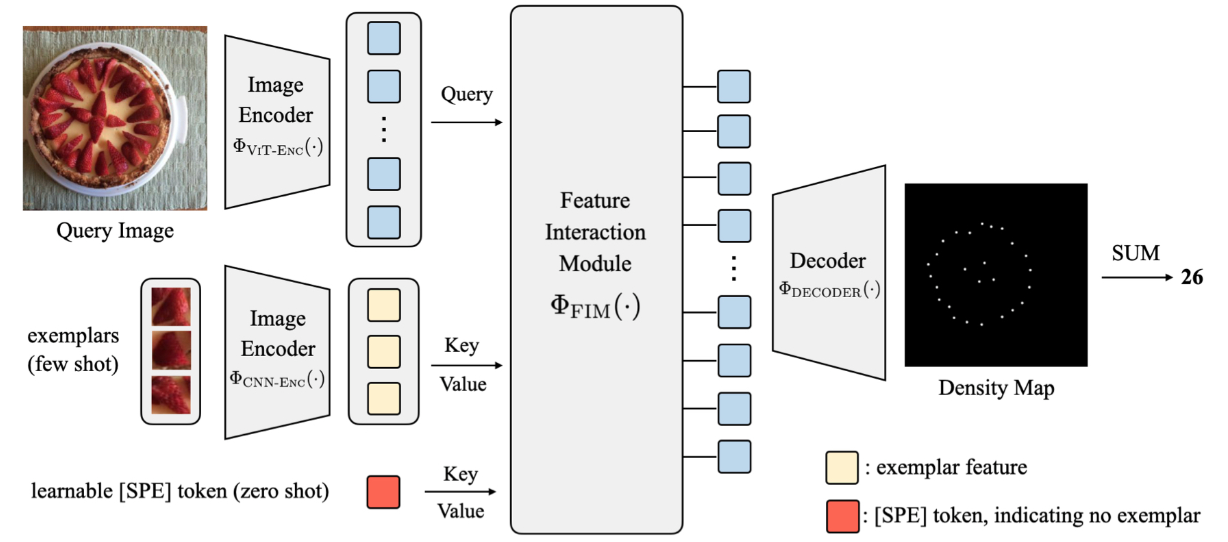
? 论文:CounTR: Transformer-based Generalised Visual Counting
论文时间:29 Aug 2022
领域任务:Object Counting, Self-Supervised Learning,物体计数,自监督学习
论文地址:https://arxiv.org/abs/2208.13721
代码实现:https://github.com/Verg-Avesta/CounTR
论文作者:Chang Liu, Yujie Zhong, Andrew Zisserman, Weidi Xie
论文简介:In this paper, we consider the problem of generalised visual object counting, with the goal of developing a computational model for counting the number of objects from arbitrary semantic categories, using arbitrary number of “exemplars”, i. e. zero-shot or few-shot counting./在本文中,我们考虑了广义的视觉对象计数问题,目的是开发一个计算模型,用于计数任意语义类别的对象数量,使用任意数量的 “典范”,即0-sot或少数几个sot计数。
论文摘要:在本文中,我们考虑了广义视觉物体计数的问题,目的是开发一个计算模型,用于计数任意语义类别的物体数量,使用任意数量的 “典范”,即零次或少数次计数。为此,我们做出了以下四个贡献。(1)我们为通用的视觉物体计数引入了一种新的基于变换器的结构,称为计数变换器(CounTR),它明确地捕捉了图像斑块之间的相似性或与给定的 "典范 "的相似性,并采用了一种两阶段的训练机制,首先通过自我监督学习对模型进行预训练,然后在监督下进行微调。 (3) 我们提出了一个简单的、可扩展的管道,用于合成具有大量实例或来自不同语义类别的训练图像,明确地迫使模型利用给定的 “典范”;(4) 我们对大规模计数基准进行了彻底的消融研究,例如 (4) 我们对大规模计数基准,如FSC-147,进行了彻底的消融研究,并在零和少量的设置中展示了最先进的性能。
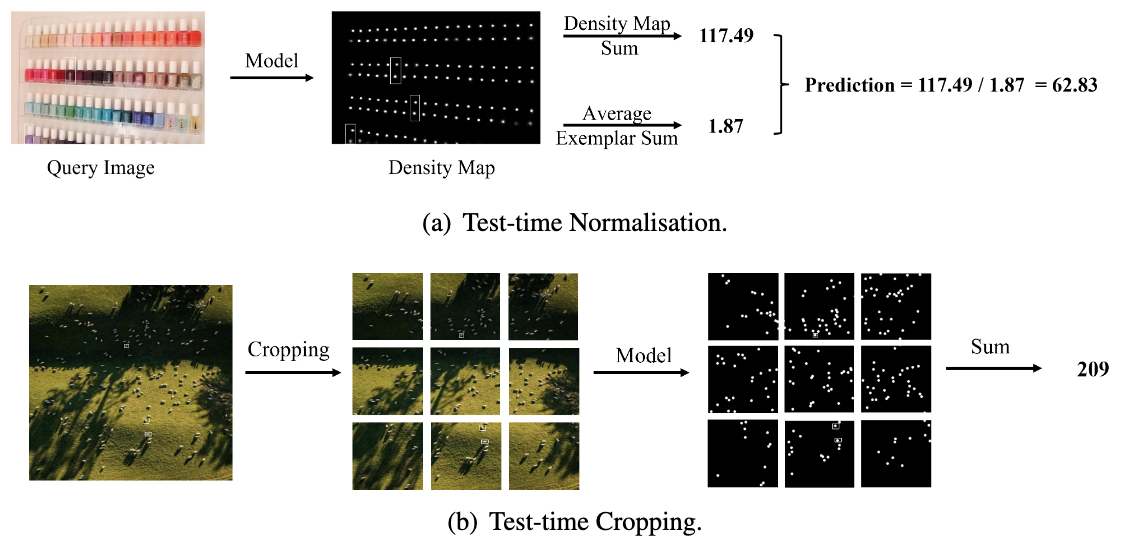
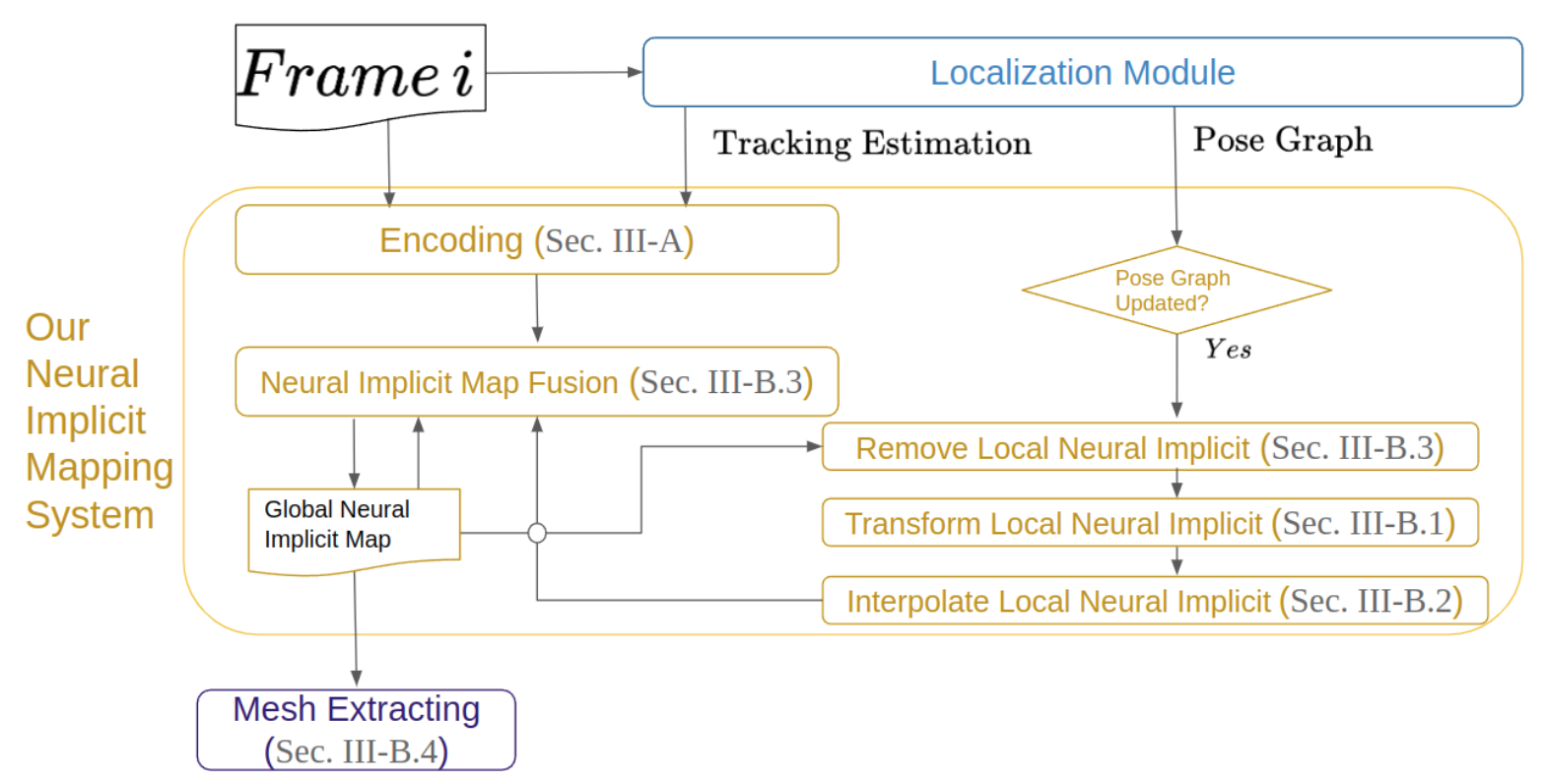
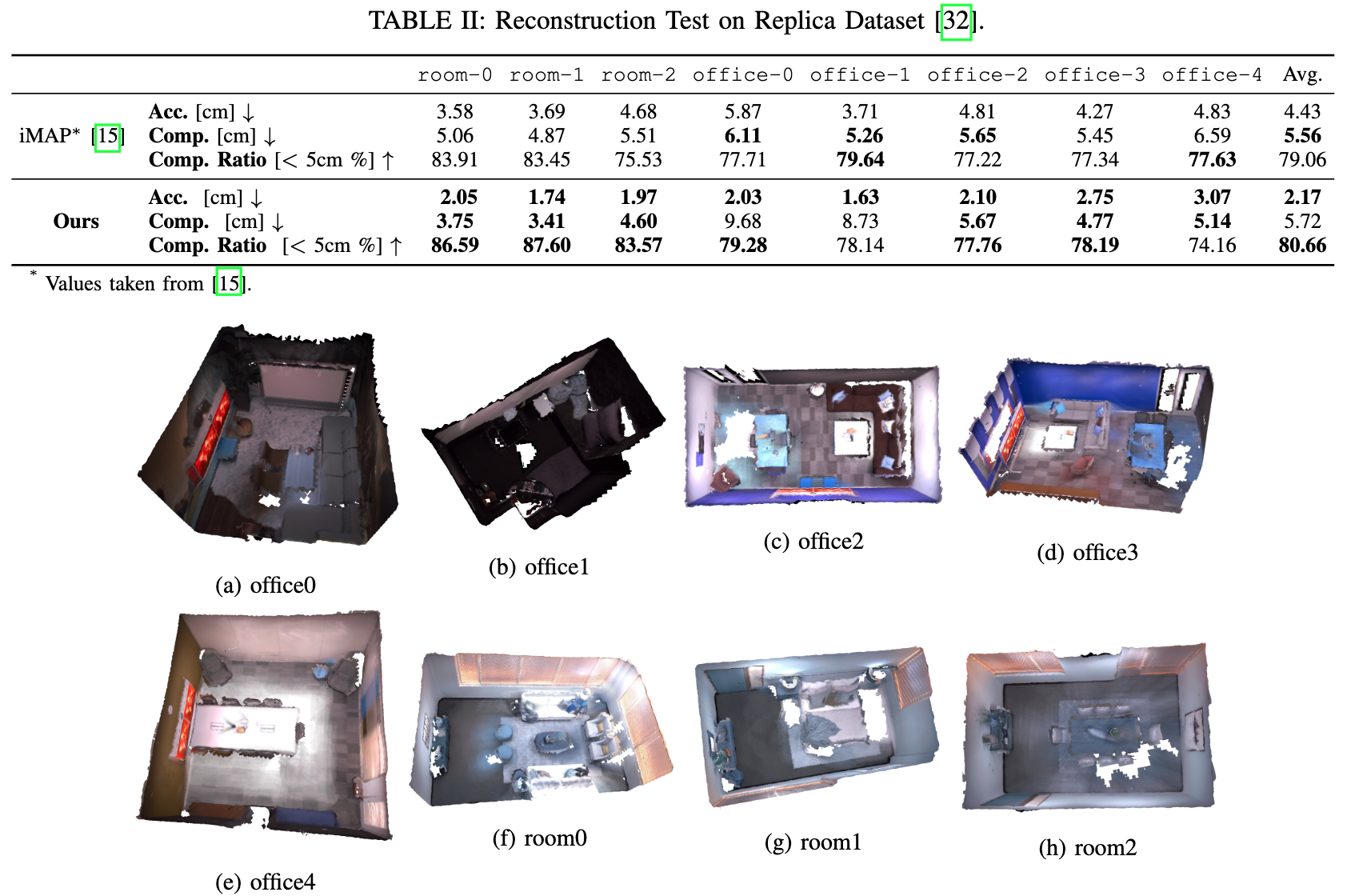
? 论文:An Algorithm for the SE(3)-Transformation on Neural Implicit Maps for Remapping Functions
论文时间:17 Jun 2022
领域任务:Object Reconstruction, Surface Reconstruction,物体重建,表面重建
论文地址:https://arxiv.org/abs/2206.08712
代码实现:https://github.com/jarrome/imt_mapping
论文作者:Yijun Yuan, Andreas Nuechter
论文简介:As our neural implicit map is transformable, our model supports remapping for this special map of latent features./由于我们的神经隐性图是可转换的,我们的模型支持对这种特殊的潜在特征图进行重映射。
论文摘要:隐性表征由于其效率和灵活性而被广泛用于物体重建。2021年,一种名为神经隐性图的新结构被发明用于增量重建。神经隐式图缓解了以往在线三维密集重建的低效内存成本问题,同时产生了更好的质量。然而,神经隐含图的局限性在于它不支持重映射,因为在生成神经隐含图后,扫描的帧被编码为深度先验。这意味着,这个生成过程是不可反转的,深度先验也是可转换的。不可逆的特性使得它不可能应用循环封闭技术。% 我们提出了一种基于神经隐含图的转换算法来填补这一空白。由于我们的神经隐性图是可转换的,我们的模型支持对这种特殊的潜在特征图进行重映射。实验表明,我们的重映射模块能够很好地将神经隐含图转化为新的姿势。嵌入到SLAM框架中,我们的映射模型能够解决循环闭合的重映射问题,并展示了高质量的表面重建。我们的实现可以在 https://github.com/Jarrome/IMT_Mapping 获取,供研究界使用。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
? 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
? 点击 电子月刊,快速浏览月度合辑。
? 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
