目录
Class-Aware Transformer-类感知的Transformer模块
摘要
1.背景介绍:transformer在医学图像分析领域的建模长距离依赖方面取得了显著的进步。
2.现存问题:当前基于transforemr的模型具有以下几个缺点1)由于naive tokens方案导致现有的方法无法捕获重要特征 2)模型遭受信息丢失的影响,现存模型只考虑了单尺度特征表示 3)由于没有考虑丰富的语义环境和解剖学上下文,模型生成的分割图还不够准确
3.解决办法:本文作者提出了Castformer。这是一种新型的生成对抗Transformer,用于2D医学图像分割。首先利用金字塔结构来构建多尺度表示并处理多尺度变化。然后设计了一种新颖的多尺度transformer模块,以更好的学习具有语义结构的对象区域,最后采用了一种对抗性训练策略,这个策略提高了分割精度,并相应的允许基于transformer的判别器捕获高级语义特征和低级解剖学特征。
方法
本文提出的方法如下图所示:
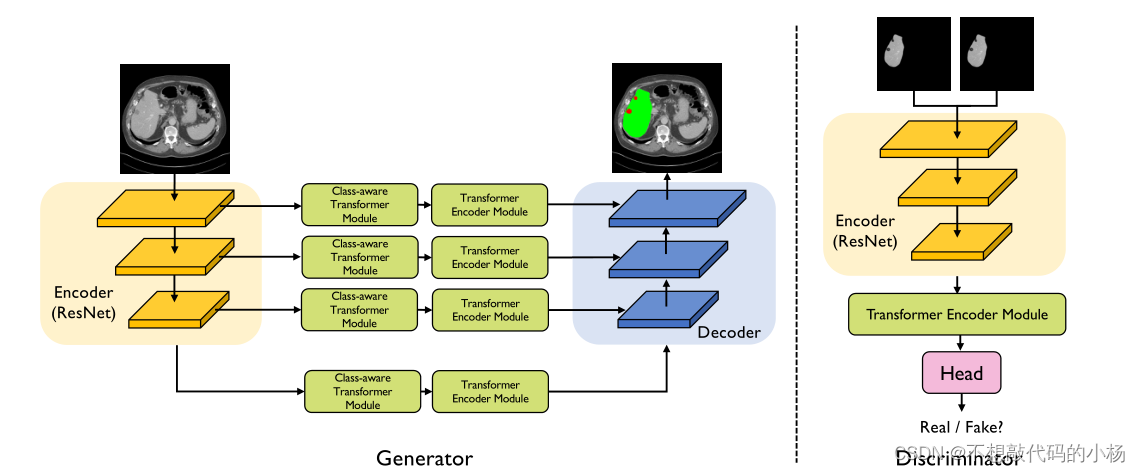
给定输入的图像,其类似于Transunet架构,生成器G(称为CATformer)由四个关键的组件组成分别是:编码器模块;类感知的transformer模块;transformer编码器模块;解码器模块。G具有4个阶段。所有阶段共享一个类似的体系结构,其中包含一个patch嵌入层,类感知层和
?Transformer编码器层。
编码器模块
采用CNN-Transformer的混合模型设计,具有两个优点:(1)使用卷积主干有助于Transformer在下游视觉任务中表现的更好 (2)它提供了具有多分辨率特征图,以帮助提升更好的表示。通过这种方式,可以为Transformer构造特征金字塔,并将多尺度特征用于下游医疗分割任务,能够对多分辨率的空间局部上下文进行建模
分层特征表示
?重点是提取CNN的多级特征,其中i=1,2,3,4.通过利用高分割精度和低分辨率来实现高分割精度。具体来说,在第一阶段,利用编码器模块获得密集的特征映射
,以类似的方式还可以制定以下特征图
,
和
。然后我们将
划分为HW/
个大小为16*16*3的Patch。并将扁平的patches送入到可学习的线性转换中,以获得HW/
*c1的patch嵌入
Class-Aware Transformer-类感知的Transformer模块
类感知Transformer的结构图如下所示:
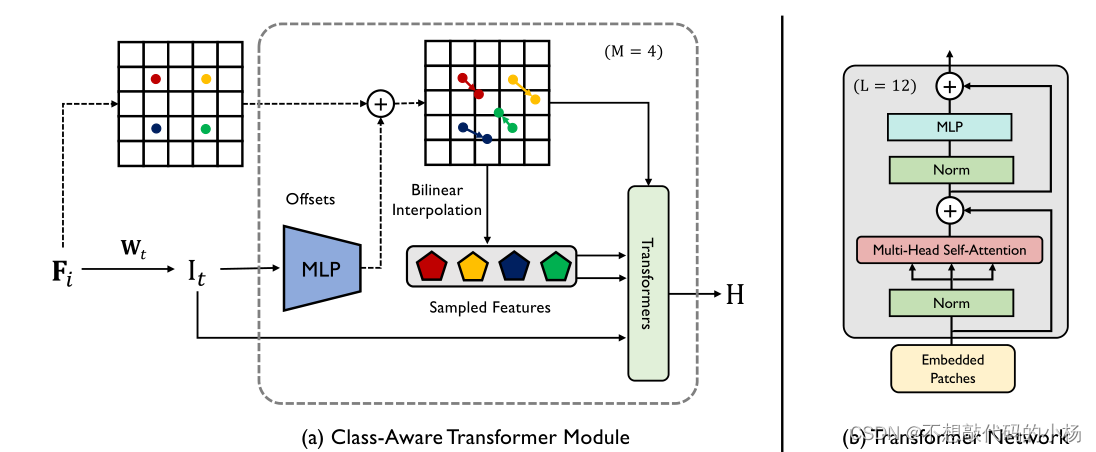
类感知的Transformer模块(CAT)旨在适应物体的有用区域(例如基本的解剖特征和结构信息)。CAT模块具有以下特点(1)使用4个独立的Transformer编码器模块(TEM)(2)将M个CAT模块合并到多尺度表示上,以允许解剖特征的上下文信息传递到表示中。类感知Transformer模块是一个迭代优化的过程。特别是,应用了类感知transformer模块来获得token序列,其中(n*n)和M分别表示每个特征图上的采样数量和总迭代次数。如上图所示,给定特征映射F1,通过将其添加到最后一步的估计偏移量来迭代的更新采样位置,公式表示为
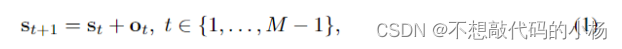
其中St和Ot是采样位置和预测的偏移矢量,具体而言,S1在间距采样网格上进行初始化,第i个采样位置定义如下

可以以以下形式定义输入特征映射上的初始Tokens:,将采样函数设置为双线性插值,然后我们可以在每个步骤中获得输出Token。
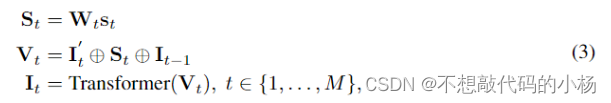
其中St是个位置嵌入,估计的采样位置偏置为
Transformer编码器模块
transformer编码器模块旨在通过嵌入的输入图像patch的完整序列中汇总全局上下文信息对远程上下文信息进行建模。Transformer编码器模块遵循VIT的体系结构,公式如下:
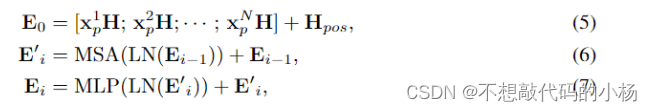
解码器模块
这个解码器旨在基于不同分辨率的四个输出特征图生成分割掩码,结合了轻量级的MLP解码器。解码器包括以下设置:1)多尺度特征的通道维度通过MLP层统一;3)利用MLP层融合串联特征,然后从融合特征中预测多类别分割掩码Y'。
判别网络
将在ImageNet上的预训练R50+VIT-B/16混合模型作为判别器设计的初始化,在这种情况下,使用预训练的策略来有效地学习有限的尺寸目标任务数据。然后,只需应用两层多层感知器(MLP)就可以预测类感知图像的真假。
首先利用输入图像X和预测的分割掩码Y'获得了类感知的图像也就是X和Y'的乘积。注意,这个构造重新使用预训练权重,并且不引入其他参数。D试图在真假输入之间进行判别。G和D通过试图达到Minmax的平衡点相互竞争。使用这种对抗结构能够使鉴别器对远程依赖性进行建模。
损失函数
分割损失包含了Dice损失和交叉熵损失。公式如下:
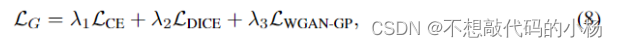
总结
本文引入了CA GANformer,这是一种简单而有效的生成对抗Transformer类型,关键在于整合多尺度金字塔结构,以获取丰富的全局上下文信息和本地尺度上下文信息。此外这个网络还受益于提出的类感知Transformer模块,可以逐步选择性的学习感兴趣的对象区域,最后生成鉴别器用于提高分割性能,并相应的使基于Transformer的鉴别器能捕获低级解剖特征和高级语义信息。