1、 网络结构
关于YOLOv5的网络结构其实网上相关的讲解已经有很多了。网络结构主要由以下几部分组成:
- Backbone:?
New CSP-Darknet53 - Neck:?
SPPF,?New CSP-PAN - Head:?
YOLOv3 Head

激活函数

????????通过和上篇博文讲的YOLOv4对比,其实YOLOv5在Backbone部分没太大变化。但是YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效。

?2、Neck部分
? ? ? ?在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF(Glenn Jocher自己设计的),这个改动我个人觉得还是很有意思的,两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
? ? ? ??而SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
? ? ? ??在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。在Head部分,YOLOv3, v4, v5都是一样的,这里就不讲了。

?3、损失计算
YOLOv5的损失主要由三个部分组成:
- Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
- Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
- Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
?
其中,为平衡系数。
? ? ? ?针对三个预测特征层(P3, P4, P5)上的obj损失采用不同的权重。在源码中,针对预测小目标的预测特征层(P3)采用的权重是4.0,针对预测中等目标的预测特征层(P4)采用的权重是1.0,针对预测大目标的预测特征层(P5)采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
4、消除Grid敏感度
? ? ??YOLOv4中有提到过,主要是调整预测目标中心点相对Grid网格的左上角偏移量。下图是YOLOv2,v3的计算公式。

?
其中:
是网络预测的目标中心x坐标偏移量(相对于网格的左上角)
是网络预测的目标中心y坐标偏移量(相对于网格的左上角)
是对应网格左上角的x坐标
是对应网格左上角的y坐标
- σ是Sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域
关于预测目标中心点相对Grid网格左上角偏移量为
,?
。YOLOv4的作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点
,?
应该趋近与0)或者右下角点?
,?
应该趋近与1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。为了解决这个问题,作者对偏移量进行了缩放从原来的( 0 , 1 ) 缩放到( ? 0.5 , 1.5 )这样网络预测的偏移量就能很方便达到0或1,故最终预测的目标中心点
,
的计算公式为:

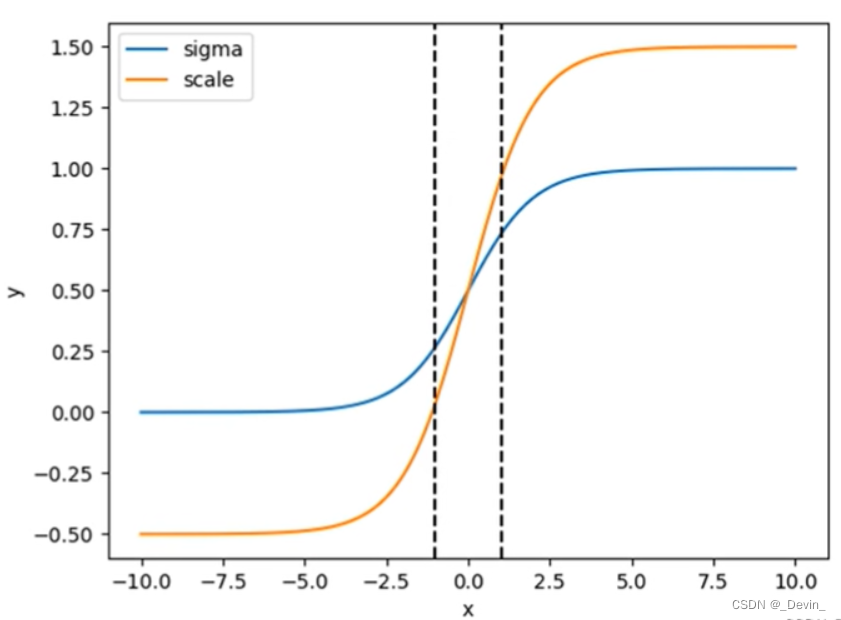
下图是我绘制的对应before曲线和
对应after曲线,很明显通过引入缩放系数scale以后,y对x更敏感了,且偏移的范围由原来的( 0 , 1 )调整到了( ? 0.5 , 1.5 ) 。
?在YOLOv5中除了调整预测Anchor相对Grid网格左上角偏移量以外,还调整了预测目标高宽的计算公式,之前是:
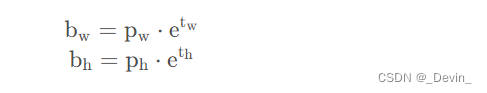
?在YOLOv5调整为:

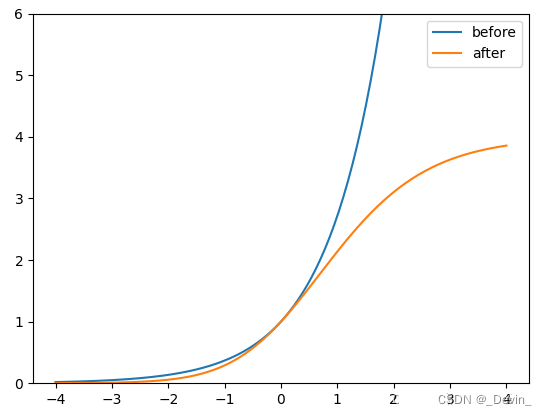
?原来的计算公式并没有对预测目标宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题。下图是修改前??和修改后?
(相对Anchor宽高的倍率因子)的变化曲线, 很明显调整后倍率因子被限制在( 0 , 4 )之间。
5、?匹配正样本(Build Targets)
? ? ? ?之前在YOLOv4介绍中有讲过该部分内容,其实YOLOv5也差不多。主要的区别在于GT Box与Anchor Templates模板的匹配方式。在YOLOv4中是直接将每个GT Box与对应的Anchor Templates模板计算IoU,只要IoU大于设定的阈值就算匹配成功。但在YOLOv5中,作者先去计算每个GT Box与对应的Anchor Templates模板的高宽比例,即:

?然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小):
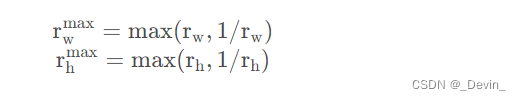
?接着统计 和
之间的最大值,即宽度和高度方向差异最大的值:

? ? ? 如果GT Box和对应的Anchor Template的小于阈值anchor_t(在源码中默认设置为4.0),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。为了方便大家理解,可以看下我画的图。假设对某个GT Box而言,其实只要GT Box满足在某个Anchor Template宽和高的×0.25倍和×4.0倍之间就算匹配成功。匹配方式如下图所示,其中黑色虚线框表示缩放过的anchor。

?剩下的步骤和YOLOv4中一致:
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了( ? 0.5 , 1.5 ) ,所以按理说只要Grid Cell左上角点距离GT中心点在( ? 0.5 , 1.5 )范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。
- 则这三个Cell对应的AT2和AT3都为正样本。
 ?
?
还需要注意的是,YOLOv5源码中扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据,?
?的位置扩展的一些Cell案例,其中%1表示取余并保留小数部分。

跨预测分支匹配正样本:yolov5一共有三个预测分支,假设一个ground truth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该ground truth框,即一个ground truth框可以由多个预测分支来预测。
为了扩充正样本个数一共采用了以下方案:
-
跨预测分支预测:假设一个ground truth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该ground truth框,即一个ground truth框可以由多个预测分支来预测。
-
跨网格预测:假设一个ground truth框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据ground truth框的中心位置,将偏移范围在( ? 0.5 , 1.5 )之间的网格也作为预测网格,也即一个ground truth框最多可以由3个网格来预测;
-
跨anchor预测:假设一个ground truth框落在了某个预测分支的某个网格内,该网格具有3种不同大小anchor,若ground truth可以和这3种anchor中的多种anchor匹配,则这些匹配的anchor都可以来预测该ground truth框,即一个ground truth框可以使用多种anchor来预测。
?6、数据增强
在YOLOv5代码里,关于数据增强策略还是挺多的,这里简单罗列部分方法:
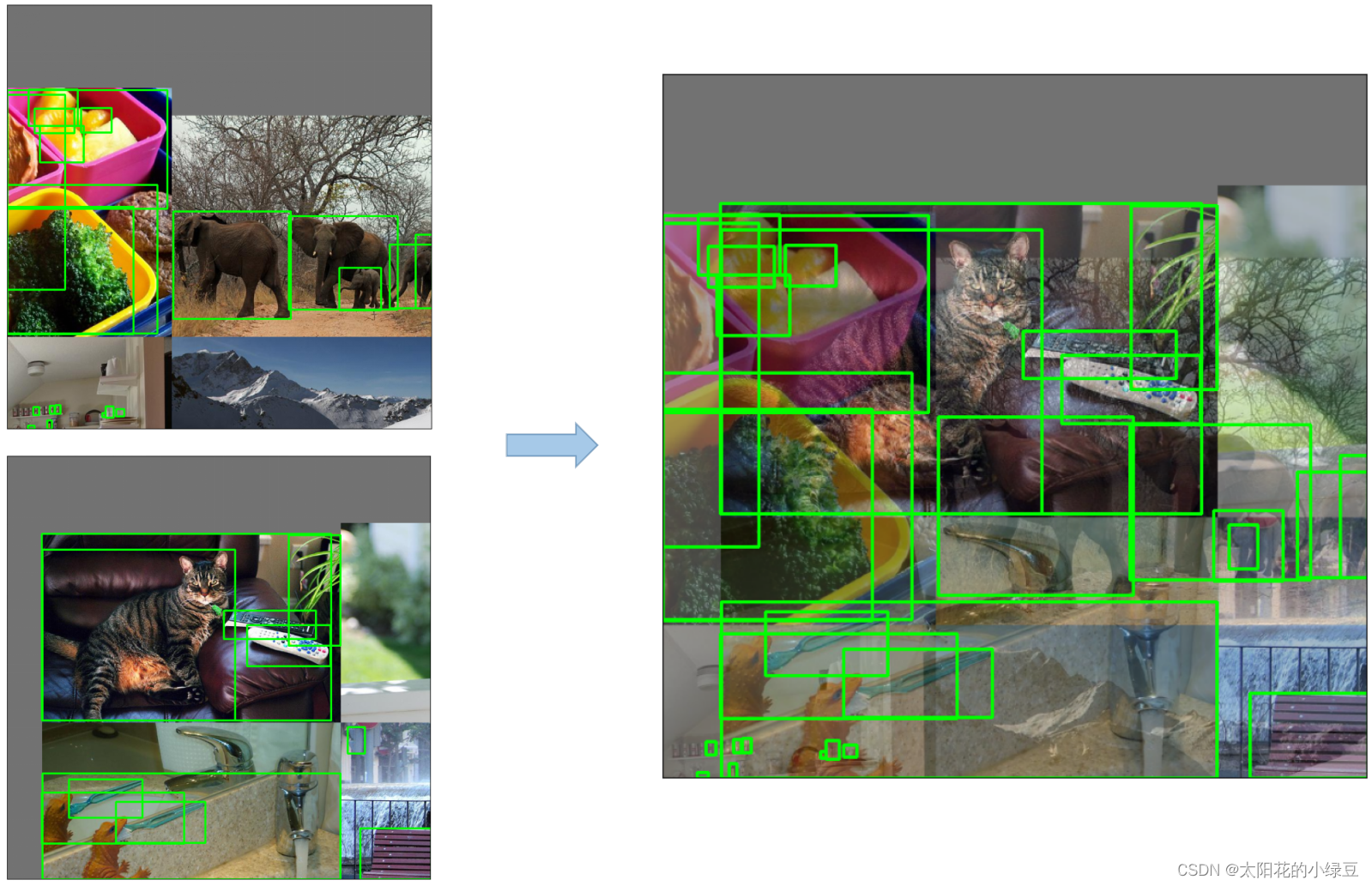
- Mosaic,将四张图片拼成一张图片

- ?Copy paste,将部分目标随机的粘贴到图片中,前提是数据要有
segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图
 ?
?
- Random affine(Rotation, Scale, Translation and Shear),随机进行仿射变换,但根据配置文件里的超参数发现只使用了
Scale和Translation即缩放和平移。
 ?
?
- MixUp,就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了
MixUp,而且每次只有10%的概率会使用到。?
 ?
?
-
Albumentations,主要是做些滤波、直方图均衡化以及改变图片质量等等,我看代码里写的只有安装了
albumentations包才会启用,但在项目的requirements.txt文件中albumentations包是被注释掉了的,所以默认不启用。 - ?Augment HSV(Hue, Saturation, Value),随机调整色度,饱和度以及明度。
 ?
?
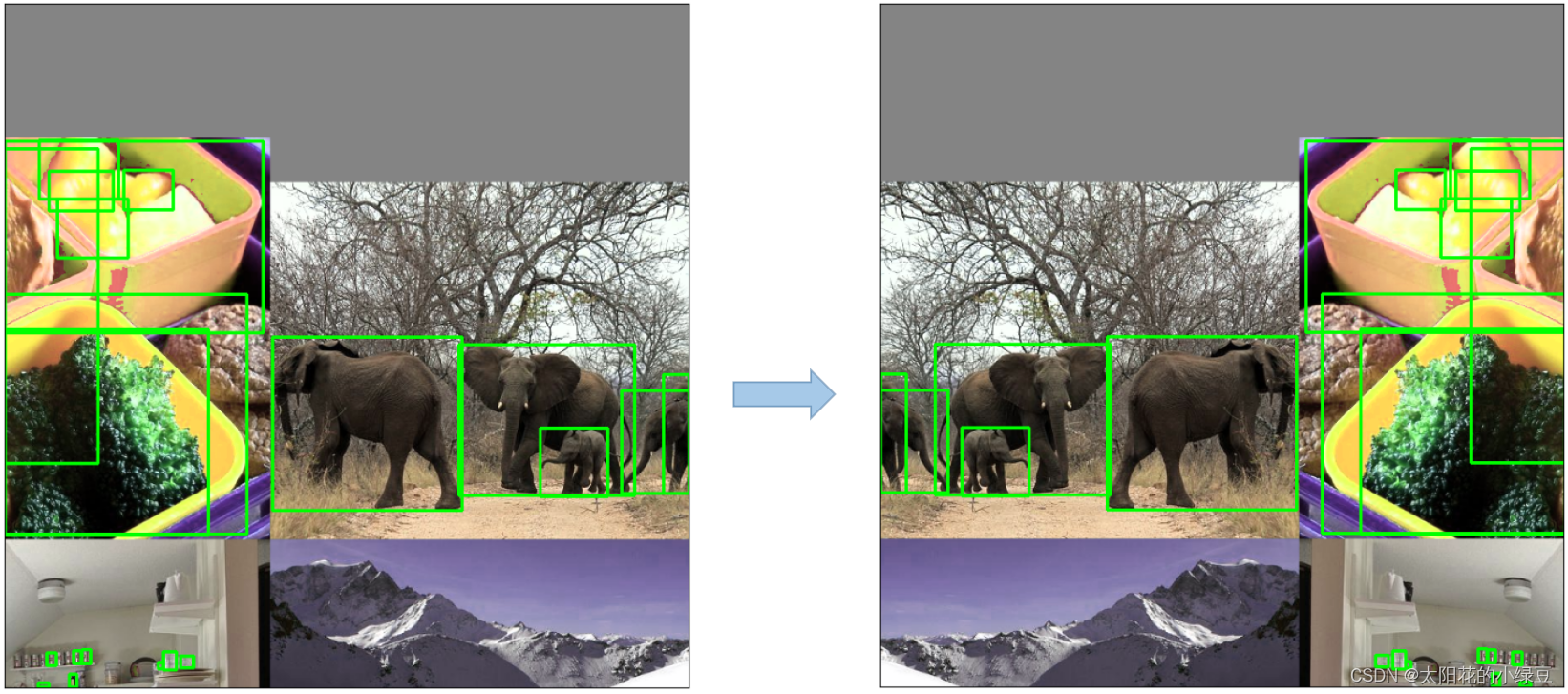
- Random horizontal flip,随机水平翻转?
 ?
?
?