2022年10月7日
图卷积神经网络(GCN)
参考:何时能懂你的心――图卷积神经网络(GCN) - 知乎 (zhihu.com)
? 一文让你看懂图卷积神经网络(GCN)!!! - 知乎 (zhihu.com)
? Graph Convolutional Networks | Thomas Kipf | University of Amsterdam (tkipf.github.io)
原始论文:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL 1609.02907.pdf (arxiv.org)
本篇内容是对本人不了解的知识进行总结
参考的别人的文章就很不错了。不再重复造轮子了。概述
? 图的结构一般来说是十分不规则的,可以认为是无限维的一种数据,所以它没有平移不变性。每一个节点的
周围结构可能都是独一无二的,这种结构的数据,就让传统的CNN、RNN瞬间失效。所以很多学者从上个世纪就
开始研究怎么处理这类数据了。这里涌现出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其
中一种,这里只讲GCN。
? GCN,图卷积神经网络,实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。
GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类
(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得
到图的嵌入表示(graph embedding),可见用途广泛。因此现在人们脑洞大开,让GCN到各个领域中发光发
热。
公式
? 假设我们手头有一批图数据,其中有N个节点(node),每个节点都有自己的特征,我们设这些节点的特征组成一个N×D维的矩阵X,然后各个节点之间的关系也会形成一个N×N维的矩阵A,也称为邻接矩阵(adjacency matrix)。X和A便是我们模型的输入。
GCN也是一个神经网络层,它的层与层之间的传播方式是:
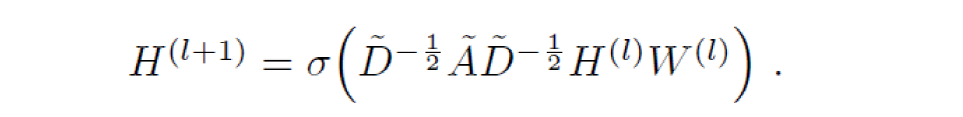
这个公式中:
- A波浪=A+I,I是单位矩阵
- D波浪是A波浪的度矩阵(degree matrix),公式为 Dii=∑jAij
- H是每一层的特征,对于输入层的话,H就是X
- σ是非线性激活函数
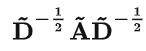 这个部分,是可以事先算好的,因为D波浪由A计算而来,而A是我们的输入之一。
这个部分,是可以事先算好的,因为D波浪由A计算而来,而A是我们的输入之一。
论文中的一幅图:

上图中的GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间
的连接关系,即A,都是共享的。
GCN作者给出的公式理解:Graph Convolutional Networks | Thomas Kipf | University of Amsterdam (tkipf.github.io)
作者给出了一个由简入繁的过程来解释:
我们的每一层GCN的输入都是邻接矩阵A和node的特征H,那么我们直接做一个内积,再乘一个参数矩阵W,然
后激活一下,就相当于一个简单的神经网络层嘛,是不是也可以呢?
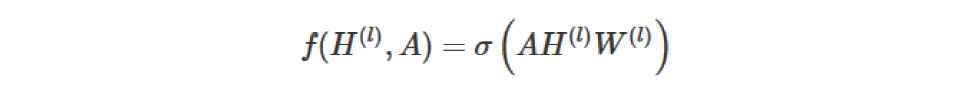
实验证明,即使就这么简单的神经网络层,就已经很强大了。这个简单模型应该大家都能理解吧,这就是正常的神
经网络操作。
但是这个简单模型有几个局限性:
-
只使用A的话,由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个node的所有邻居的
-
特征的加权和,该node自己的特征却被忽略了。因此,我们可以做一个小小的改动,给A加上一个单位矩阵
I,这样就让对角线元素变成1了。
-
A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我
们对A做一个标准化处理。首先让A的每一行加起来为1,我们可以乘以一个 D?1 ,D就是度矩阵。我们可以
进一步把 D?1 拆开与A相乘,得到一个对称且归一化的矩阵: D?1/2AD?1/2 。
通过对上面两个局限的改进,我们便得到了最终的层特征传播公式:
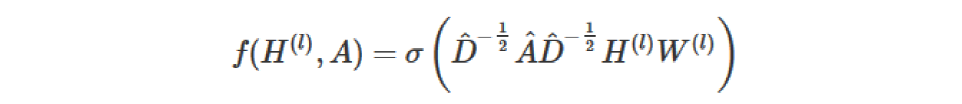
其中 A^=A+I , D^ 为 A^ 的degree matrix。
公式中的 D?1/2AD?1/2 与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉
斯矩阵,这也是GCN的卷积叫法的来历。原论文中给出了完整的从谱卷积到GCN的一步步推导,我是看不下去
的,大家有兴趣可以自行阅读。
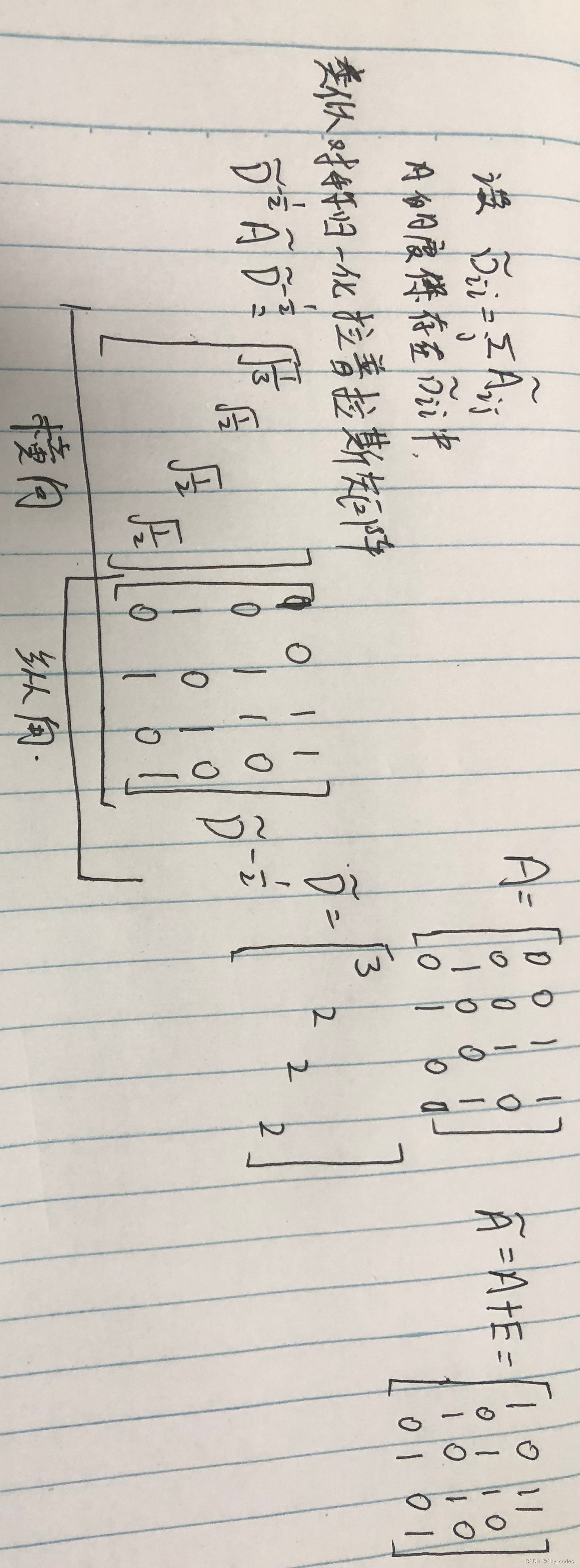
手推一下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q8wKaX8F-1665127512134)(C:\SelfFile\笔记\论文\gcn\gcn.assets\B8C65D6697698971BAC81FC82A2BCBF4.png)]](https://img-blog.csdnimg.cn/60ec7bfcac50439f8a3d12bb2acc2467.png)
对称归一化拉普拉斯矩阵
gcn中对邻接矩阵进行对称归一化拉普拉斯标准化一开始是因为图谱论中的一些知识点,理解上很费劲,不过我在
看源代码的时候发现其实可以从标准化层面,很容易的理解对称归一化拉普拉斯变换的实际意义。
A=G.to_adjacency_matrix().todense()
np.fill_diagonal(A,np.ones(A.shape[0])) ## 加入了自环的邻接矩阵
A=pd.DataFrame(A)
A

cora图数据集的邻接矩阵加入自环之后。
A1=A/np.sqrt(A.sum(axis=1))
A2=A1.T/np.sqrt(A.sum(axis=0))
A2=A2.T
A2
对称归一化拉普拉斯矩阵:

下面我们对对称归一化拉普拉斯矩阵的计算过程进行拆解,发现,这不就是做横向和纵向的标准化吗。。只不过多了一个根号
A1=A/A.sum(axis=1)
首先是横向标准化,这一步的意义从深度学习的角度来说是很容易理解的,因为graph中,不同节点之间的edge
的weight差异可能很大,比如节点0和其他节点的edge的weights范围在0~1之间,而节点1和其他节点的
weights范围在100~1000之间,对于金融中通过user之间的交易关系来构建的图尤其如此,交易的金额作为
weights则不同用户之间的交易金额(即edge)权重差异可能非常大。这对于nn的训练来说问题比较大,比如
GCN处理有权图问题,不对邻接矩阵进行横向标准化,则sum之后,不同节点的领域的sum结果量纲差异可能会
很大,比如节点A和领域的edge weights范围在0~1,sum的结果可能也就是10以内,节点B和领域的edge
weights范围在1000~10000,sum的结果就非常大了,这样gnn中做节点非线性变换的dense层会很头疼,难收
敛啊。
那么显然,我们做个横向标准化就可以解决这样的问题了,因为对于GNN来说,我们无非是想学习到所有节点和
领域的某种隐藏的关联模式,而对于不同用户来说,edge weights的绝对大小不重要,相对大小才重要。这和时
间序列预测中的多序列预测问题是一样的,不同商品的销量的绝对值差异很大,但是我们要学习到的是相对的模式
而不是绝对的模式,因此在多序列的时间序列预测问题中也常常会做横向标准化,即将所有商品的销量放缩到大致
相同的区间。
接下来是纵向标准化,纵向标准化相对来说就比较“graph独有”了,
A2=A1.T/A.sum(axis=0)
这里也非常有意思,我们做纵向标准化实际上是希望将节点的领节点对其的“贡献”进行标准化。比如说脉脉上的
用户之间的关注关系就是天然的同构图,假设我们要做节点分类判定某个用户A是不是算法工程师,并且假设A用
户仅仅和另一个算法工程师B以及10个猎头有关注的关系,直观上,猎头对用户A的节点类别的判定的贡献应该是
很小的,因为猎头往往会和算法,开发,测试,产品等不同类型的用户有关联关系,他们对于用户A的“忠诚关联
度”是很低的,而对于算法工程师B而言,假设他仅仅和A有关联, 那么明显,B对A的“忠诚关联度”是很高
的,B的node features以及B和A的关联关系在对A进行节点分类的时候应该是更重要的。
那么,纵向标准化就较好的考虑到了上面的问题,思想很简单,假设节点1和节点2有一个权重为1的edge相连,
节点2和其他1000个节点也有关联,那么节点2对于节点1的贡献度为1/1000,即用edge weights除以节点2的度
(有权图上用加权度)。
而对称归一化拉普拉斯矩阵,实际上是横纵向标准化之后又开了根号,开根号不影响计算结果的相对大小,不改变
实际的物理意义。
因此,对称归一化拉普拉斯矩阵可以看作是对原始的邻接矩阵的一种横纵向标准化。(注:上述的计算是包括了自
环的,不影响理解)
其实在sage,gat之类的gnn中,也是可以引入这样的标准化方法的,总的来说gnn的标准化的三种形式:
1 node features的标准化,这个不用说,和nn训练之前要做标准化一个道理;
2 横向标准化,消除不同节点的edge weights的差异性避免NN训练难收敛的问题;
3 纵向标准化,区别对待节点的领域节点对其的贡献度,“忠诚”的节点贡献度更大,不忠诚的节点贡献度更小。
厉害之处
**完全使用随机初始化的参数W,GCN提取出来的特征就以及十分优秀了!**这跟CNN不训练是完全不一样的,后者
不训练是根本得不到什么有效特征的。
我们看论文原文:

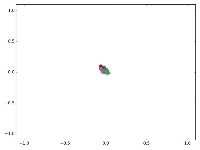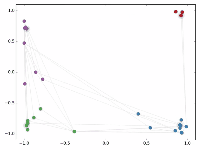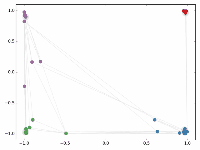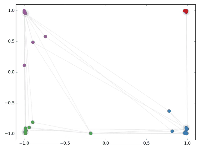
然后作者做了一个实验,使用一个俱乐部会员的关系网络,使用随机初始化的GCN进行特征提取,得到各个node
的embedding,然后可视化:
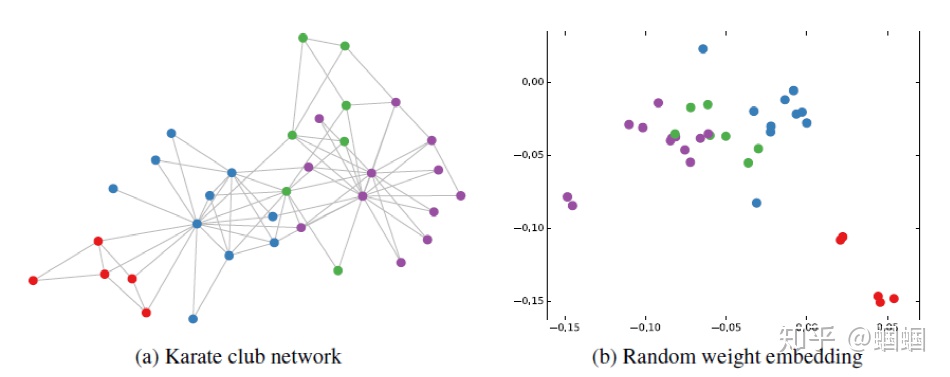
可以发现,在原数据中同类别的node,经过GCN的提取出的embedding,已经在空间上自动聚类了。
而这种聚类结果,可以和DeepWalk、node2vec这种经过复杂训练得到的node embedding的效果媲美了。
说的夸张一点,比赛还没开始,GCN就已经在终点了。看到这里我不禁猛拍大腿打呼:“NB!”
还没训练就已经效果这么好,那给少量的标注信息,GCN的效果就会更加出色。
作者接着给每一类的node,提供仅仅一个标注样本,然后去训练,得到的可视化效果如下:
杂谈
原论文中的推到证明,我是真不行

不得不说,这最后不给训练直接得到embedding,就完成了自动聚类,也是震惊到我了。
GCN强啊,难怪让看的论文一半GNN相关,一半transform。