一、论文简述
1. 第一作者:Xiaoyang Guo
2. 发表年份:2019
3. 发表期刊:CVPR
4. 关键词:端到端训练、组相关体、改进的堆叠沙漏网络、3D卷积、回归
5. 探索动机:完全相关是测量特征相似性的有效方法,但它只在每个视差水平产生一个单通道相关图,因此丢失了很多信息。连接体在聚合网络中需要更多的参数来从头开始学习相似性测量函数。还有一些网络仍然使用传统的匹配代价,无法进行端到端的优化。
6. 工作目标:如何结合先前各种代价体构建的优势,提出一种更高效的代价体?
7. 核心思想:相关体时间复杂度低,但搜索空间有限,连接体搜索空间大,但时间复杂度高。因此提出组相关提供更好的相似性测量,并与连接体结合构建最终的代价体。
8. 实现方法:
- 使用残差块组提取左右图像的一元特征
- 将需要做相关的特征图进行通道分类,在每个组计算相关图,获得组相关体
- 将只有12通道的连接体和组相关体连接构建4D代价体
- 使用改进后的预沙漏模块和三个堆叠的3D沙漏网络进行3D聚合
- 使用soft argmin回归视差
- 使用平滑L1损失函数计算几个输出的loss,并加权求和得到最终loss
9. 实验结果:在Scene Flow和KITTI数据集上GWC-Net达到SOTA,在计算成本有限的实时立体网络中组相关是可能实现的有价值的方法。
二、论文翻译
Group-wise Correlation Stereo Network
摘要
立体匹配估计一对矫正过的图像对之间的视差,这对深度感测、自动驾驶和其他相关任务非常重要。先前的工作通过互相关或在所有视差水平上连接左右特征的建立了代价体,然后利用2D或3D卷积神经网络来回归视差图。在本文中,我们提出通过组相关来构建代价体。左边特征和右边特征在通道维度被分成组,并且在每个组计算相关图以获得多个匹配代价提议,然后将其打包到代价体中。组相关为计算特征相似性提供了有效的表示,并且不会像完全相关一样不会丢失过多的信息。与以前的方法相比,它在减少参数的同时也能保持更好的性能。我们改进了先前工作中提出的3D堆叠沙漏网络以提高性能并降低推断计算成本。实验结果表明,在Scene Flow,KITTI 2012和KITTI 2015数据集上我们的方法优于以前的方法。该代码可从https://github.com/xy-guo/GwcNet获得。
1. 介绍
精确的深度感应是许多计算机视觉应用的核心,例如自动驾驶,机器人导航和浅层的景深图像合成。立体匹配属于被动深度感应技术,其通过匹配由两个相机拍摄的矫正过的图像对的像素来估计深度。可以通过Fl/d将像素的视差d转换为深度,其中F表示相机镜头的焦距,l是两个相机中心之间的距离。因此,深度的精确性随着视差预测的精确性提高而提高。
传统的立体管道机制通常由以下四个步骤的全部或部分组成,匹配代价计算,代价聚合,视差优化和后处理。匹配代价计算为左图像块和可能的对应右图像块提供初始的相似性度量,这是立体匹配的关键步骤。一些常见的匹配代价包括绝对差值(SAD),平方差和(SSD)和归一化互相关(NCC)。代价聚合和优化步骤结合了上下文匹配代价和正则化项,以获得更鲁棒的视差预测。
基于学习的方法探索用于匹配代价的不同特征表示和聚合算法。DispNetC从左右图像特征计算相关体,并利用CNN直接回归视差图。GC-Net和PSMNet构建基于连接的特征体,并结合3D CNN来聚合上下文特征。还有一些方法尝试聚合来自多个人工制定的匹配代价提议的证据。然而,上述方法有几个缺点。完全相关提供了一种度量特征相似性的有效方法,但它丢失了很多信息,因为它只在每个视差水平产生一个单通道相关图。连接体在接下来的聚合网络中需要更多参数来从头开始学习相似性度量函数。[1,19]仍然利用传统的匹配代价,无法进行端到端的优化。
在本文中,我们提出了一种简单但更高效的操作,称为组相关,解决了上述缺点。提取并连接多层一元特征以形成左右图像对的高维特征表示fl,fr。然后,在通道维度将特征分成多个组,并且在所有视差水平上将第i个左特征组与对应的第i个右特征组计算互相关,以获得组相关图。最后,打包所有相关图形成最终的4D代价体。一元特征可以被视为结构化向量组,因此特定组的相关图可以被视为匹配代价提议。这样,与[6,2]相比,我们可以利用传统互相关匹配代价的优势,为接下来的3D聚合网络提供更好的相似性度量。多重匹配代价提议也避免了完全相关中的信息丢失。
我们改进了PSMNet中提出的3D堆叠沙漏聚合网络,进一步提高性能并降低推断计算成本。在每个沙漏模块内的直连边中采用1×1×1的3D卷积,而不会增加太多的计算成本。
我们的主要贡献可归纳如下:1)我们提出了组相关来构建代价体以提供更好的相似性度量。2)修改堆叠的3D沙漏细化网络,在不增加推断时间的情况下提高了性能。3)我们的方法在Scene Flow,KITTI 2012和KITTI 2015数据集上实现了比以前方法更好的性能。4)实验结果表明,在限制3D聚合网络的计算成本时,我们提出的网络的性能降低比PSMNet小很多,说明组相关在实时立体网络中很有应用价值。
2. 相关工作
2.1. 传统方法
通常,传统的立体匹配由以下四个步骤的全部或部分组成:匹配代价计算,代价聚合,视差优化和一些后处理步骤。在第一步中,针对所有可能的视差计算所有像素的匹配代价。常见匹配代价包括绝对差之和(SAD),平方差之和(SSD),归一化互相关(NCC)等。局部方法探索了不同策略来聚合相邻像素的匹配代价,并且通常利用赢者通吃(WTA)策略来选择具有最小匹配代价的视差。相比之下,全局方法则最小化目标函数,得到最优的视差图,其通常考虑匹配代价和平滑先验,例如置信传播和图切割。半全局匹配(SGM)通过动态规划近似全局优化。局部和全局方法可以结合起来用,以获得更好的性能和鲁棒性。
2.2.?基于学习的方法
除了人工制定的方法,研究人员还提出了许多学习的匹配代价和代价聚合算法。Zbontar和Lecun首先提出使用神经网络计算匹配代价。然后使用传统的基于交叉的代价聚合和半全局匹配来处理预测的匹配代价以预测视差图。通过关联一元特征,在[13]中加速了匹配代价的计算。Batsos等人提出的CBMV结合来自多个基础匹配代价的证据。Schonberger等人提出用随机森林分类器对扫描线算法的匹配代价候选进行分类。Seki等人提出的SGM-Nets为SGM提供了可学习的惩罚项。Knobelreiter等人提出了结合CNN预测的相关匹配代价和CRF来整合远程交互。
紧随DispNetC,有很多工作直接从相关代价体中回归视差图。给定左和右特征图fl和fr,计算每个视差水平d上的相关代价体,

其中<・,・>表示两个特征向体的内积,Nc表示通道数。CRL和iResNet遵循DispNetC的思想,使用堆叠改进子网络来进一步提高性能。还有一些工作结合了边缘特征和语义特征等附加信息。
最近的一些工作采用了基于连接的特征体和3D聚合网络,以实现更好的上下文聚合。Kendall等人提出了GC-Net并且是第一个使用3D卷积网络来聚合上下文信息得到代价体。它不是直接给出代价体,而是连接左右特征fl、fr,形成4D特征体,
![]()
用3D卷积网络从相邻的像素和视差聚合上下文特征,预测一个视差概率体。延续GC-Net,Chang等人提出了金字塔立体匹配网络(PSMNet),它有一个金字塔池化模块和堆叠的3D沙漏网络,以改进代价体。Yu等人提出了产生和选择多重代价聚合提议。Zhong等人提出了一个自适应的递归立体模型,处理开放世界的视频数据。
?LRCR利用左右一致性检查和递归模型,聚合从[21]预测的代价体,改进那些原先不可靠的视差预测。还有其他工作专注于实时立体匹配和应用友好的立体视觉的研究。
3. 组相关网络
我们提出了组相关立体网络(GwcNet),它扩展了PSMNet,具有组相关代价体和改进的3D堆叠沙漏网络。在PSMNet中,必须通过3D聚合网络从头开始学习连接特征的匹配代价,这通常需要更多的参数和计算成本。相比之下,完全相关提供了一种通过点积测体特征相似性的有效方法,但它丢失了很多信息。我们提出的组相关克服了这两个缺点,并为相似性度体提供了良好的特征。
3.1.?网络架构
我们提出的组相关网络的结构如图1所示。该网络由四部分组成,一元特征提取,代价体构建、3D聚合、视差预测。表1列出了代价体、堆叠沙漏、输出模块的详细结构。
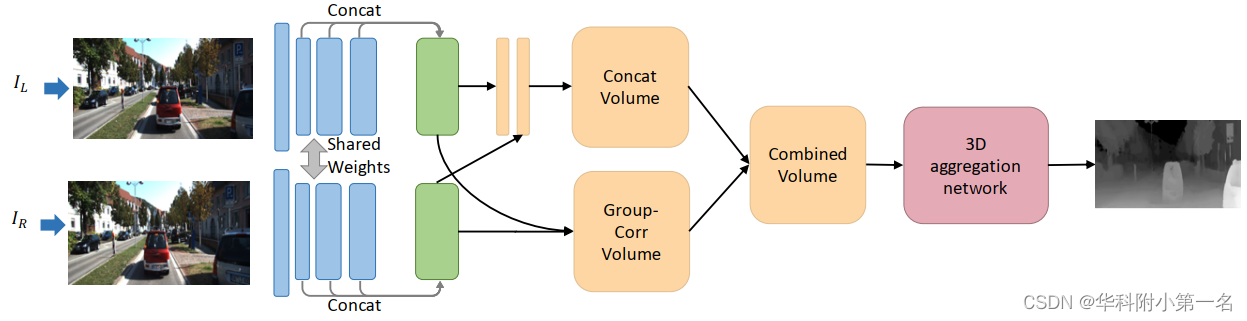
图1:我们提出的组相关网络的管道机制。整个网络由四部分组成,一元特征提取,代价体构建,3D卷积聚合和视差预测。代价体分为两部分,连接体(Cat)和组相关体(Gwc)。连接体是通过连接压缩的左右特征构建的。组相关体在3.2节中描述。
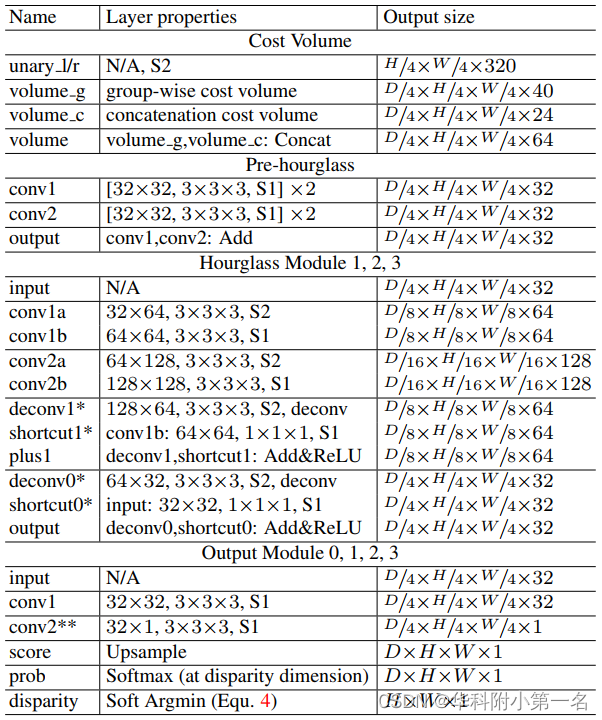
表1:模块的结构细节。H,W表示输入图像的高度和宽度。S1/2表示卷积步幅。如果未指定,则每个3D卷积都具有批归一化和ReLU。*表示不包括ReLU。**表示仅有卷积。
对于特征提取,我们采用PSMNet中类似于ResNet的网络,具有半膨胀设置,没有空间金字塔池模块。我们将conv2,conv3,conv4的最后特征图连接起来,形成了320通道的一元特征图。
代价体由两部分构成,一个连接体和一个组相关体。连接体和PSMNet中的一样,但是通道数要少些,在这之前我们用两个卷积将一元特征压缩为12个通道。组相关体在3.2节中将有详细描述。然后将这两个体连接起来,作为3D聚合网络的输入。
用3D聚合网络将相邻视差和像素点的特征聚合,预测改进的代价体。它由一个预沙漏模块和三个堆叠的3D沙漏网络构成,对特征体正则化。如图2所示,预沙漏模块由4个具有批归一化和ReLU的3D卷积组成。然后是三个堆叠的3D沙漏网络,通过编码-解码结构来改进低纹理的模糊部分和遮挡部分。与[2]的3D聚合网络相比,我们提出了一些改进的地方,提升了性能,增加了推断速度,详见第3.3节。

图2:我们提出的3D聚合网络的结构。该网络包括一个沙漏预模块(开始时为四个卷积)和三个堆叠的3D沙漏网络。与PSMNet相比,我们删除了不同沙漏模块和输出模块之间的直连边,因此在推断过程中可以删除输出模块0,1,2以节省时间。1×1×1 3D卷积添加到沙漏模块内的直连边中。
预沙漏模块和三个堆叠的3D沙漏网络连接到输出模块。每个输出模块预测视差图。输出模块的结构和损失函数在3.4节中描述。
3.2. 组相关体
左边的一元特征和右边的一元特征用fl,fr表示,有Nc个通道,是原始输入图像大小的1/4。在之前的工作中,左、右特征在不同的视差水平上要么是相关的,要么是连接的,以构建代价体。但是,相关体和连接体都有缺点。完全相关提供了一个度量特征相似性的有效方法,但是它丢失了太多的信息,因为它在每个视差水平上仅输出单通道的相关图。连接体不包含特征相似性的信息,所以在接下来的聚合网络中就需要更多的参数,从头开始学习相似性度量。为了解决上述问题,我们提出了组相关,结合了连接体和相关体的优势。
组相关体的基本思想就是将特征分割为若干个组,然后按组来计算相关图。我们将一元特征的通道表示为Nc。所有的通道在通道维度被平均分为Ng个组,所以每个特征组就有Nc/Ng个通道。第g个特征组fl,fr由原始特征fl, fr的第![]() 个通道构成。组相关计算过程如下:
个通道构成。组相关计算过程如下:

??,?? 是两个特征向量的内积。注意,针对所有特征组g和所有视差水平d计算相关。然后,将所有相关图打包成形状![]() 的代价体,其中Dmax表示最大视差,Dmax/4对应于特征的最大视差。当Ng=1时,组相关变为完全相关。
的代价体,其中Dmax表示最大视差,Dmax/4对应于特征的最大视差。当Ng=1时,组相关变为完全相关。
可以将组相关体Cgwc视为Ng个代价体的提议,并且从相应的特征组计算每个提议。紧跟着3D聚合网络聚合多个候选以回归视差图。组相关成功地利用了传统相关匹配代价的功能,并为3D聚合网络提供了丰富的相似性度量特征,从而减少了参数需求。我们将在4.5节中展示我们探索了减少3D聚合网络的通道数,我们所提出的网络在性能上的下降要比其它方法小得多。我们提出的组相关体需要较少的3D聚合参数,就可以获得不错的结果。
?为了进一步提高性能,可以将组相关代价体与连接体进行组合。实验结果表明,组相关体和连接体相互补充。
3.3. 改进的3D聚合模块
在PSMNet中,提出了一种堆叠沙漏结构,来学习更好的上下文特征。基于此网络,我们作了几个重要的修改,使其适合我们提出的组相关并提升了推断速度。所提出的3D聚合的结构如图2和表1所示。
首先,我们为预沙漏模块的功能增加了一个辅助输出模块(输出模块0,参见图2)。 额外的辅助损失让网络在较低层学到更好的特征,这也有利于最终预测。
其次,去除了不同输出模块之间的残差连接,因此在推断期间可以移除辅助输出模块(输出模块0,1,2),以节省计算成本。
第三,将1×1×1 3D卷积添加到每个沙漏模块内的直连边中(参见图2中的虚线),在不增加计算成本的情况下提高了性能。由于1×1×1 3D卷积仅具有3×3×3卷积的1/27乘法运算量,因此运行速度非常快,时间可以忽略不计。
3.4.?输出模块和损失函数
对于每个输出模块,采用两个3D卷积来输出1通道4D代价体,然后对代价体进行上采样并将其在视差维度使用softmax函数转换为概率体。详细结构如表1所示。对于每个像素,我们有一个Dmax长度向量,其中包含所有视差水平的概率p。然后,由soft argmin函数给出的视差估计d~,

其中k和pk表示可能的视差和相应的概率。从四个输出模块中得到的预测视差图分别表示为:d0,d1,d2,d3。损失函数如下:

其中λi表示第i个视差预测的系数,d*表示真实的视差图。平滑的L1损失计算如下,
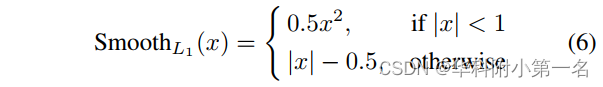
4.?实验
在本节中,我们将在Scene Flow数据集和KITTI数据集上评估我们提出的立体模型。我们进行消融研究来比较不同的模型和不同的参数设置。数据集和实现细节在4.1节和4.2节中描述。4.3节探讨了分组相关的有效性和最佳设置。4.4节讨论了新的堆叠沙漏模块性能的提高。在4.5节我们还探讨了当计算成本有限时分组相关的性能。
4.1.?数据集和评估指标
Scene Flow数据集是合成立体数据集的数据集集合,由Flyingthings3D,Driving和Monkaa组成。数据集提供了大小为960*540的35454张训练图像和4370张测试图像,并具有准确真实的视差图。我们使用Scene Flow的Finalpass数据集,因为它包含更多的运动模糊和散焦的,比Cleanpass更像真实世界的图像。KITTI 2012和KITTI 2015是驾驶场景数据集。KITTI 2012提供194个训练图像对和195个测试图像对,KITTI 2015提供200个训练图像对和200个测试图像对。两个数据集都为训练图像提供稀疏的LIDAR 真实的视差。
对于Scene Flow数据集,评价指标通常是终点误差(EPE),即像素的平均视差误差。对于KITTI 2012,报告了非遮挡(Noc)和所有(All)像素的错误像素和平均EPE的百分比。对于KITTI 2015,针对背景、前景和所有像素评估视差异常值D1的百分比。异常值被定义为其视差误差大于max(3px,0.05d*)的像素,其中d*表示真实的视差。
4.2.?实现细节
我们的网络用PyTorch实现。我们使用Adam优化器,β1= 0.9,β2= 0.999。批量大小固定为16,我们使用8个Nvidia TITAN Xp GPU训练所有网络,每个GPU上有2个训练样本。四个输出的系数设定为λ0= 0.5,λ1= 0.5,λ2= 0.7,λ3= 1.0。
对于Scene Flow数据集,我们总共训练立体网络16epoch。初始学习率设定为0.001。它在epoch10、12、14后各缩小2倍,最后结束于0.000125。为了测试Scene Flow数据集,将大小为960*540的完整图像输入到网络以进行视差预测。延续PSMNet,在Scene Flow数据集上我们将最大视差值设置为Dmax=192。为了评估我们的网络,我们删除了测试集中所有有效像素小于10%(0≤d<Dmax)的图像。对于每个有效图像,仅使用有效像素计算评价指标。
对于KITTI 2015和KITTI 2012,我们对在Scene Flow数据集上已经预训练的网络,微调了另外300个epoch。初始学习率为0.001,并且在200个epoch之后缩小10倍。为了在KITTI数据集上进行测试,我们首先在图像的顶部和右侧填充零,使输入大小为1248×384。
4.3.?组相关的有效性
在本节中,我们将探讨组相关的有效性和最佳设置。为了证明所提出的组相关体的有效性,我们在Base模型上进行了几次实验,该模型去除了堆叠的沙漏网络,仅保留了预沙漏模块和输出模块0。Cat-Base基本模型仅有连接体,Gwc- Base仅有组相关体,Gwc-Cat-Base两个体都有。
表2中的实验结果表明,Gwc-Base网络的性能随着组数的增加而增加。当组数大于40时,性能提升得很小,EPE保持在1.2px左右。考虑到内存使用和计算成本,我们选择40个组,每个组有8个通道作为我们的网络结构,这对应于表2中的Gwc40-Base模型。

表2:在Scene Flow的Finalpass数据集上我们提出的网络的消融研究的结果。Cat仅表示连接体,Gwc仅表示组相关体,Gwc-Cat两者都有。Base表示没有堆叠沙漏网络的网络变体。时间是在单个Nvidia TITAN Xp GPU上输入480×640大小图像的推断时间。结果是在开源的PSMNet使用我们的批量大小和评估设置训练得到的,以进行公平比较。
除Gwc1-Base外所有Gwc-Base模型都比使用连接体的Cat-Base模型性能好,这说明了组相关的有效性。Gwc40模型的EPE减少了0.1px, 3-pixel误差率减下降了0.75%,时间消耗几乎相同。通过将组相关体与连接体相结合,可以进一步提高性能(参见表2中的Gwc40-Cat24 Base模型)。组相关可以提供准确的匹配特征,连接体提供互补的语义信息。
4.4.?改进的堆叠沙漏
在本文中,我们对[2]中提出的堆叠沙漏网络进行了许多修改,以提高代价体聚合的性能。从表2和表3中,我们可以看出与Cat64-original-hg模型(具有[2]中的沙漏模块)相比,在Scene Flow数据集上具有我们提出的沙漏网络(Cat64)的模型EPE增加了7.8%,在KITTI 2015上增加了5.8%。在单个Nvidia TITAN Xp GPU上640×480大小的输入图像的推断时间也减少了42.7ms,因为在推断期间移除辅助输出模块可以节省时间。
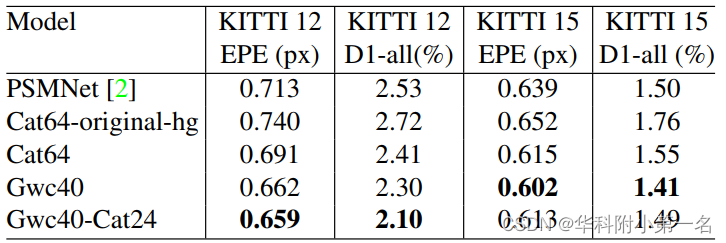
表3:我们的网络在KITTI 2012和KITTI 2015验证集上的消融研究结果。
4.5.?限制3D网络的计算成本
我们探索通过减少3D聚合网络中的通道来限制计算成本,以证实所提出的组相关的有效性。结果在图3中展示。通道的基本数量从原来的32修改为2,并且代价体和所有3D卷积的通道以相同的系数减少。随着通道数量的减少,我们具有组相关体(Gwc-Cat)的模型比仅具有连接体(Cat)的模型表现更好。随着更多通道的减少,性能提高的更多。其原因在于,组相关为3D聚合网络提供了良好的匹配代价表示,而仅具有连接体作为输入的聚合网络需要从头开始学习匹配相似度函数,这通常需要更多的参数和计算成本。因此,在计算成本有限的实时立体网络中我们提出的组相关是可能实现的有价值的方法。

图3:当通道数量减少时,我们的模型Gwc-Cat的性能比Cat好得多。具有32个基础通道的模型对应于Cat64模型(连接体)和Gwc40-Cat24模型(组相关体和连接体)。代价体和所有3D卷积的通道减少的系数与基础通道相同。
4.6.?KITTI2012和KITTI2015
对于KITTI stereo 2015,我们将训练集划分为180个训练图像对和20个验证图像对。由于在验证集上的结果不稳定,我们对预训练模型进行了3次微调,并选择具有最佳验证性能的模型。从表3中,Gwc40-Cat24和Gwc40的性能优于没有组相关的模型(Cat64,Cat64-original-hg)。我们将有最低验证误差的Gwc40模型(没有连接体)提交给评估服务器,测试集上的结果如表4所示。我们的模型在D-all超过PSMNet0.21%,超过SegStereo0.14%。
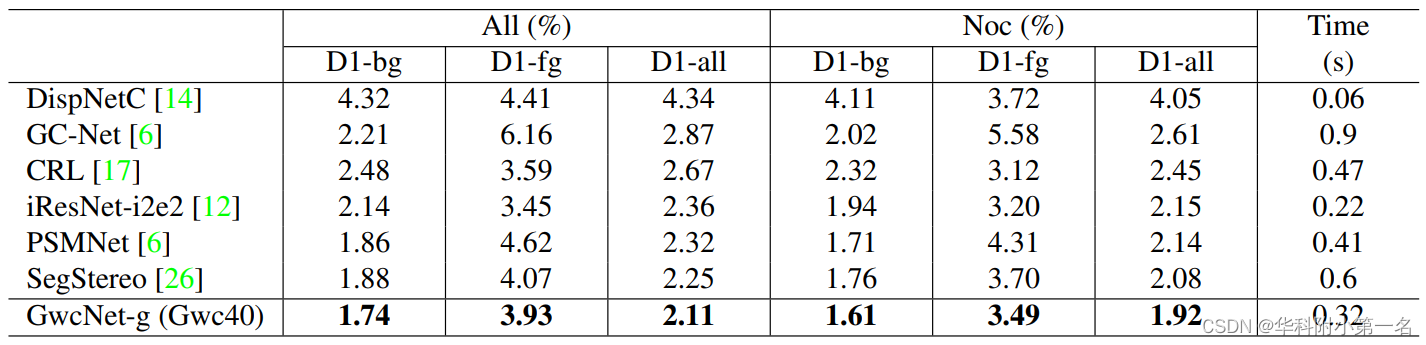
表4:KITTI 2015测试集结果。该数据集包含200个用于训练的图像和200个用于测试的图像。
对于KITTI 2012,我们将训练集分为180个训练图像对和14个验证图像对。验证集上的结果如表3所示。我们将验证集上的最佳模型Gwc40-Cat24提交给评估服务器。测试集的评估结果如表5所示。我们的方法超过PSMNet,3-pixel-error为0.19%,平均视差误差为0.1px。
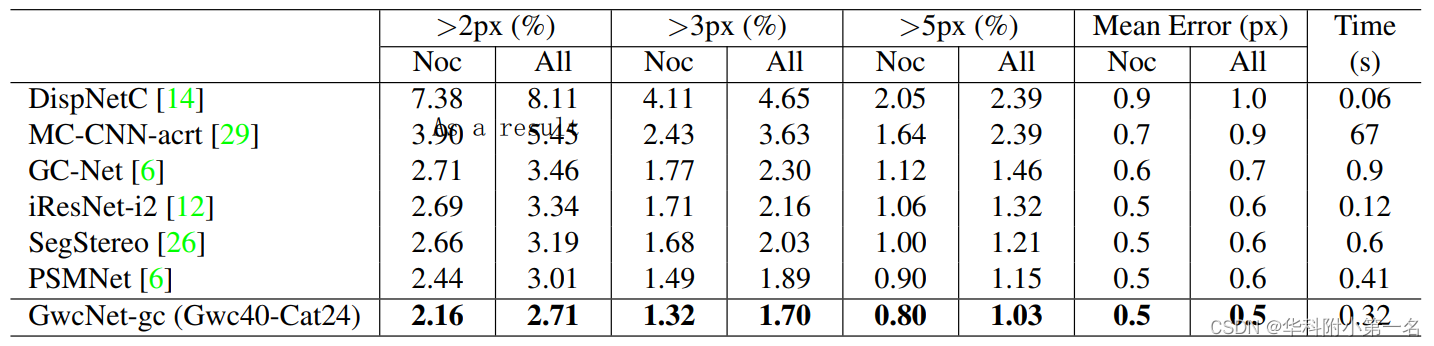
表5:KITTI 2012测试集结果。该数据集包含194个用于训练的图像和195个用于测试的图像。
5.?结论
在本文中,我们提出了GwcNet来估计立体匹配的视差图,该网络包含组相关来构建代价体。组相关体为3D聚合网络提供了良好的匹配特征,提高了性能,降低了聚合网络的参数需求。我们发现,当计算成本有限时,我们的模型比以前基于连接体的立体网络获得更大的增益。我们还改进了堆叠沙漏网络,以进一步提高性能并减少推断时间。实验证明了我们提出的方法在Scene Flow数据集和KITTI数据集的有效性。

- Scene Flow数据集的可视化结果。

- KITTI2012 数据集的可视化结果。

- KITTI2015数据集的可视化结果。
图4:Scene Flow,KITTI 2012和KITTI 2015数据集的测试集上的深度可视化结果。从左到右,输入左图像,预测视差图和误差图。