数据集
使用的是hnSentiCorp_htl_all
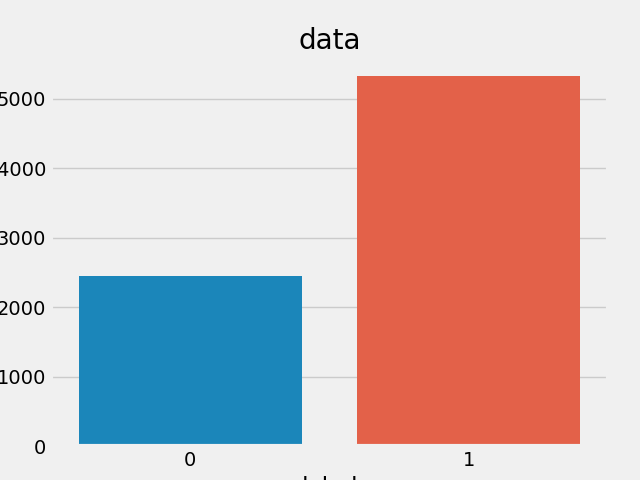
数据概览: 7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
字段说明
| 字段 | 说明 |
|---|---|
| label | 1 表示正向评论,0 表示负向评论 |
| review | 评论内容 |
导包
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
查看部分数据
data = pd.read_csv("ChnSentiCorp_htl_all.csv")
print(data.sample(20))

获得数据集的标签数量分布
plt.style.use('fivethirtyeight')
sns.countplot(x="label", data=data)
plt.title("data")
plt.show()
获取数据集的句子长度分布
#第一步:将int类型转化为str;
#data['Air_quality']=data['Air_quality'].astype('str')
#第二步:利用len()函数,判断Air_quality列每个字符串的长度,并生成新列
data["sentence_length"] = data["review"].str.len()
# 绘制句子长度列的数量分布图
sns.countplot(x="sentence_length", data=data)
# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看
plt.xticks([])
plt.show()
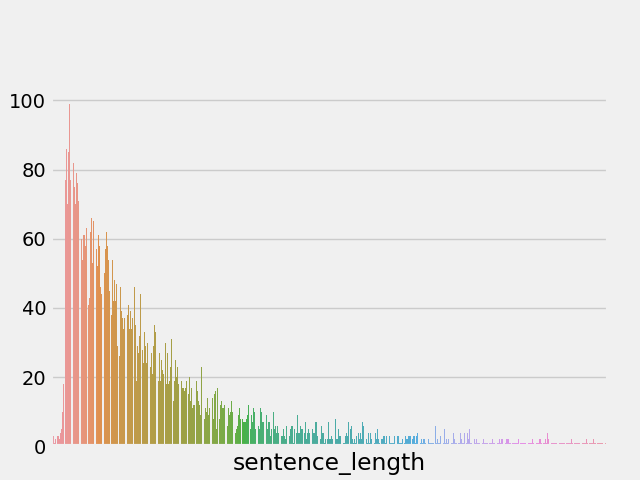
# 绘制dist长度分布图
sns.distplot(data["sentence_length"])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show()

通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用。
获取数据集的正负样本长度散点分布
# 绘制训练集长度分布的散点图
sns.stripplot(y='sentence_length', x='label', data=data)
plt.show()

通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查。
获得数据集不同词汇总数统计
# 导入jieba用于分词
# 导入chain方法用于扁平化列表
import jieba
from itertools import chain
# 进行训练集的句子进行分词, 并统计出不同词汇的总数
train_vocab = set(chain(*map(lambda x: jieba.lcut(str(x)), data["review"])))
print("数据集共包含不同词汇总数为:", len(train_vocab))
获得数据集上正负的样本的高频形容词词云
# 使用jieba中的词性标注功能
import jieba.posseg as pseg
# 导入绘制词云的工具包
from wordcloud import WordCloud
def get_a_list(text):
"""用于获取形容词列表"""
# 使用jieba的词性标注方法切分文本,获得具有词性属性flag和词汇属性word的对象,
# 从而判断flag是否为形容词,来返回对应的词汇
r = []
for g in pseg.lcut(text):
if g.flag == "a":
r.append(g.word)
return r
def get_word_cloud(keywords_list,name):
# 实例化绘制词云的类, 其中参数font_path是字体路径, 为了能够显示中文,
# max_words指词云图像最多显示多少个词, background_color为背景颜色
wordcloud = WordCloud(font_path="C:\Windows\Fonts\simhei.ttf", max_words=100, background_color="white")
# 将传入的列表转化成词云生成器需要的字符串形式
keywords_string = " ".join(keywords_list)
# 生成词云
wordcloud.generate(keywords_string)
wordcloud.to_file(name)
# 绘制图像并显示
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# 获得数据集上正样本
p_data = data[data["label"] == 1]["review"]
# 对正样本的每个句子的形容词
p_a_vocab = chain(*map(lambda x: get_a_list(str(x)), p_data))
# 获得训练集上负样本
n_data = data[data["label"] == 0]["review"]
# 获取负样本的每个句子的形容词
n_a_vocab = chain(*map(lambda x: get_a_list(str(x)), n_data))
# # 调用绘制词云函数
get_word_cloud(p_a_vocab, "good.png")
get_word_cloud(n_a_vocab, "bad,png")


根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准. 上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在"便利"这样的褒义词, 因此可以人工进行审查.