Keras深度学习实战――使用循环神经网络构建情感分析模型
0. 前言
在《循环神经详解与实现》一节中,我们已经了解循环神经网络 (Recurrent neural networks, RNN) 的基本原理,并且在 Keras 中实现了 RNN 模型,在本节中,我们构建 RNN 模型进行航空推文情感分类。
1. 使用循环神经网络构建情感分析模型
1.1 数据集分析
接下来,我们将实现 RNN 构建情感分析模型,所用的数据集与在《从零开始构建单词向量》一节中使用的数据集相同,即航空公司 Twitter 数据集,模型的目标是预测用户对于航空公司的评价属于正面、负面或者中立。
1.2 构建 RNN 模型进行情感分析
本节中,我们将实现在 RNN 情感分析模型。
(1) 导入相关的库和数据集:
from keras.layers import Dense
from keras.layers.recurrent import SimpleRNN
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from sklearn.model_selection import train_test_split
import numpy as np
import nltk
from nltk.corpus import stopwords
import re
import pandas as pd
data=pd.read_csv('archive/Tweets.csv')
print(data.head())
(2) 预处理文本,删除标点符号、将所有单词转换为小写并删除停用词:
import nltk
stop = nltk.corpus.stopwords.words('english')
def preprocess(text):
text=text.lower()
text=re.sub('[^0-9a-zA-Z]+',' ',text)
words = text.split()
words2=[w for w in words if (w not in stop)]
#words3=[ps.stem(w) for w in words]
words4=' '.join(words2)
return(words4)
data['text'] = data['text'].apply(preprocess)
(3) 提取数据集中的所有单词,并为每个单词分配一个索引:
from collections import Counter
counts = Counter()
for i,review in enumerate(data['text']):
counts.update(review.split())
words = sorted(counts, key=counts.get, reverse=True)
nb_chars = len(words)
print(nb_chars)
word_to_int = {word: i for i, word in enumerate(words, 1)}
int_to_word = {i: word for i, word in enumerate(words, 1)}
提取到的单词示例如下:
{'whitterbug', 'funnycaptain', 'referencing', 'pnbajfkmhg', 'vacatinn', 'devalue', ...}
整数到单词的映射字典的示例如下:
{..., 9966: 'intrusive', 9967: 'pockets', 9968: 'goingtovegas', 9969: 'getconnected', 9970: 'achieving', ...}
(4) 将给定句子中的每个单词映射到与其关联的单词 ID 上,将文本评论转换为单词列表,其中每个列表均包含构成句子的单词 ID。
mapped_reviews = []
for review in data['text']:
mapped_reviews.append([word_to_int[word] for word in review.split()])
# 打印示例
print('Original text:',data.loc[0]['text'])
print('Mapped text:',mapped_reviews[0])
原始评论文本和映射为单词 ID 的评论示例如下:
Original text: virginamerica dhepburn said
Mapped text: [31, 6369, 137]
(5) 提取句子的最大长度,并通过填充所有句子将其标准化为相同的长度。接下来,遍历所有评论文本,并存储每个评论的长度。此外,我们还需要计算评论的最大长度,用于将所有句子标准化为最大长度:
length_sent = []
for i in range(len(mapped_reviews)):
length_sent.append(len(mapped_reviews[i]))
sequence_length = max(length_sent)
我们可以看到,不同的推文具有不同的长度。但是,RNN 接收的每个输入应具有相同长度。如果评论的长度小于数据集中最大的评论长度,则使用 0 值填充的评论,使所有输入具有相同的长度。
from keras.preprocessing.sequence import pad_sequences
x = pad_sequences(maxlen=sequence_length, sequences=mapped_reviews, padding="post", value=0)
(6) 构造训练和测试数据集,将目标输出转换为独热编码,并将原始数据拆分为训练数据集和测试数据集:
y = data['airline_sentiment'].values
y = np.array(pd.get_dummies(y))
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
(7) 构建 RNN 架构并编译模型:
embedding_vecor_length=32
max_review_length=26
model = Sequential()
model.add(Embedding(input_dim=nb_chars+1, output_dim=32, input_length = 26))
model.add(SimpleRNN(50, return_sequences=False))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
model.summary()
Embedding 层的 input_dim 参数为数据集中不重复单词的总数加 1,其会为每个单词创建一个单词向量,其中 output_dim 表示要表示创建单词维数,input_length 表示每个句子中的单词数。在 RNN 层中,如果要提取每个时间步的输出,则 return_sequences 参数为 True,在本例中,我们仅需要在处理所有输入后才会提取输出,因此 return_sequences = False。
模型简要信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 26, 32) 477920
_________________________________________________________________
simple_rnn (SimpleRNN) (None, 50) 4150
_________________________________________________________________
dense (Dense) (None, 3) 153
=================================================================
Total params: 482,223
Trainable params: 482,223
Non-trainable params: 0
_________________________________________________________________
在 Embedding 层中,由于共计有 14934 个不重复单词,且我们使用索引 0 作为填充词,因此共有 14934 个可能的单词,每个单词都以 32 维表示,因此共有 14934 x 32 = 48223个 参数。
在 simpleRNN 层中,有一组权重将输入连接到具有 50 个输出的 RNN 层,由于每个时刻有 32 个输入,每个时时刻具有相同的权重
W
x
h
W_{xh}
Wxh?,则总共使用 32 x 50=1600 个权重将输入连接到 RNN 中,每个输入对应的输出尺寸为 1 x 50。
此外,计算每个时刻的网络中间状态,需要计算
X
?
W
x
h
X * W_{xh}
X?Wxh? 与
h
(
t
?
1
)
?
W
h
h
h^{(t-1)}* W_{hh}
h(t?1)?Whh?,并求和,其中
X
X
X 是输入值,
W
x
h
W_{xh}
Wxh? 是将输入层连接到 RNN 层的权重,
W
h
h
W_{hh}
Whh? 是将上一个时刻网络状态连接到当前时刻网络状态的权重,
h
(
t
?
1
)
h^{(t-1)}
h(t?1) 是上一个时刻的网络状态,由于
X
?
W
x
h
X*W_{xh}
X?Wxh? 的输出为 1 x 50,则
h
(
t
?
1
)
?
W
h
h
h^{(t-1)}* W_{hh}
h(t?1)?Whh? 也为 1 x 50。由于
h
(
t
?
1
)
h^{(t-1)}
h(t?1) 的尺寸为 1 x 40,因此
W
h
h
W_{hh}
Whh? 矩阵的尺寸为 50 x 50。除权重外,我们还需要 50 个偏置项与 50 个输出相关联,因此共有 (32 x 50 + 50 x 50 + 50 = 4150) 个权重参数。
最后一层总共有 153 个权重参数,因为 RNN 最后时刻的 50 个输出连接到全连接层的 3 个节点上,因此具有 50 x 3 个权重和 3 个偏置,因此总共有 153 个权重参数。
(8) 拟合模型:
history = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=10,
batch_size=32)
训练过程中,训练、测试数据集中的准确率和损失值变化情况如下:
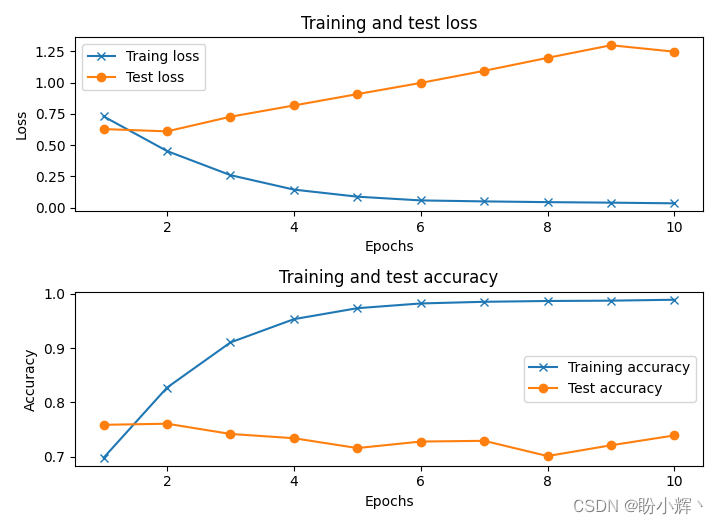
此模型的测试准确率约为 76%,与我们使用词向量构建情感分析中构建的基于词向量的网络相比,没有任何明显的改进。但是,通过使用更多数据样本数量的增加,该模型将具有更高的准确率。
相关链接
Keras深度学习实战(1)――神经网络基础与模型训练过程详解
Keras深度学习实战(2)――使用Keras构建神经网络
Keras深度学习实战(7)――卷积神经网络详解与实现
Keras深度学习实战(24)――从零开始构建单词向量
Keras深度学习实战(25)――使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)――文档向量详解
Keras深度学习实战(27)――循环神经详解与实现
Keras深度学习实战(28)――利用单词向量构建情感分析模型