- ������Ŀ:Multimodal Learning with Transformers:
A Survey - ����ʱ��:2022
ժҪ
- Transformer ��һ�ֺ���ǰ;��������ѧϰ��,�ڸ��ֻ���ѧϰ������ȡ���˾�ijɹ������������ģ̬Ӧ�úʹ����ݵ�����,���� Transformer �Ķ�ģ̬ѧϰ�ѳ�Ϊ AI �о������Ż��⡣���Ķ������ģ̬���ݵ� Transformer ����������ȫ����顣���ε������Ҫ���ݰ���:(1)��ģ̬ѧϰ��Transformer ��̬ϵͳ�Ͷ�ģ̬������ʱ���ı���,(2)�Ӽ������˵ĽǶȶ� Vanilla Transformer��Vision Transformer �Ͷ�ģ̬ Transformer �����ۻع�, (3) ͨ��������Ҫ�ķ�ʽ�ع˶�ģ̬ Transformer Ӧ�ó���,����ģ̬Ԥѵ�����ض���ģ̬����,(4) �Զ�ģ̬ Transformer ģ�ͺ�Ӧ�ó����е���ս����Ƶ��ܽ�,�Լ� (5)���������Ŀ��������DZ�ڵ��о�����
����
- �˹����� (AI) ����������ģ������ĸ�֪,���翴�����������ᡣһ�����,ģ̬ͨ���봴������ͨ���������ض������������,�����Ӿ������ԡ���������,���Ǹй�֪����һ�������������ܹ���ͬ���ö��ָ�֪����ģ̬,�Ա��ڶ�̬����Լ�����������ȷ�������绥��,ÿ��ģ̬���䵱��ͬ����ϢԴ,���в�ͬ��ͳ���������ԡ�����,һ��ͼ��ͨ����ǧ�����س��֡�������ˮ����ˣ���������Ӿ����,����Ӧ���ı���һ��ʹ����ɢ���ʵľ���������һʱ�̡��Ӹ�����˵,��ģ̬�˹�����ϵͳ��Ҫ�Զ�ģ̬��ϢԴ������ȡ�����ͺ�����,��ʵ����������ˮƽ�ĸ�֪��������ģ̬ѧϰ (MML) ��һ�ֹ��� AI ģ�͵�ͨ�÷���,��ģ�Ϳ��ԴӶ�ģ̬��������ȡ������Ϣ [1]��
- �����������ʹ�� Transformers ���ж�ģ̬ѧϰ(��ͼ 1 ��ʾ),����������������ڽ�ģ��ͬģ̬(�������ԡ��Ӿ�������)������(�������Է��롢ͼ��ʶ������)������������ƺͿ���չ��ʶ��)���н��ٵ��ض���ģ̬�ļܹ�����(����,ƽ�Ʋ����Ժ��Ӿ��еľֲ�����ע��ƫ��)��������˵,Transformer �����������һ�������������,�Լ�ÿ�����е�����(����,ģ̬��ǩ��˳��),��Ȼ���� MML ����ܹ��ġ�����,ͨ������ self-attention ������ģʽ���Լ�ʵ��ѧϰÿ��ģ̬�������Ժ�ģ̬�������ԡ�������Ҫ����,����粻ͬѧ��̽�� Transformer �ܹ����о����Ժͻ����,���½����������˴����µ� MML ����,���ڸ�������ȡ�������źͶ������Ľ�չ [4], [5]��[6]��[7]��[8]������Ҫ��ʱ�ع˺��ܽ�����Է���,��ʹ�о���Ա�ܹ��˽�����ѧ�Ƶ� MML �����ȫ��ͼ��,����Ҫ���Dz���ǰ�ɾͺ���Ҫ��ս������ṹ��ͼ����
- ���෨ Ϊ���ڲ�ͬѧ��֮���ø��õĿɶ��ԺͿɴ���,���Ƿֱ���û���Ӧ�ú���սά�ȵ�����ṹ�����෨�����м����ô�:(1)�����ض�Ӧ��רҵ֪ʶ���о���Ա���������ӵ������������֮ǰ�ҵ��ʺ��Լ��о������Ӧ�á� (2) ��ͬ����������ģ����ƺͼܹ����Գ���ġ���ʽ�������ӽǽ����ܽ�,�Ӷ��ڲ�ͬӦ�����γɵĸ���ģ�͵���ѧ˼������ڹ�ͬ�Ļ����Ͻ��й����ͶԱ�,��Խ�ض��������ơ�������Ҫ����,���ǵķ��෨�ṩ��һ����Ȥ�ĸ�����Ʒ������ͼ,ͬʱ����Ӧ�������Ժ��䷽ͨ���Եļ��⡣ϣ���������ڴ����������,�ٽ�����Ч�Ŀ�ģʽ��˼�뽻���ͽ�����ͨ��ʹ�ü�ʱ��ģ���� [9] ��Ϊ����Ļ���,���ǻ����������������(����ͼ�����)����ͨ������Ϊ��ͳ MML �����еĵ�һģ̬ѧϰӦ�� [1]��[10] , [11] �C ��Ϊһ������� MML Ӧ�ó������п������ŷḻ MML,��Ϊ����������һ���˹���������,����������㷺���о�֮һ [12]��
- ��Χ�����齫���� Transformer �ܹ��Ķ�ģ̬�ض����,����������������ģ̬:RGB ͼ�� [5]�����ͼ�� [13]����Ƶ [7]����Ƶ/����/���� [13] ,[14],[15],����[16],����ͼ/����[17],[18],[19],���ƹǼ�[20],SQL [21],[22],�䷽[23], �������[24],����[25],[26],[27],����[28],����֪ʶ(ͼ)[29],[30],��ģ̬֪ʶͼ[31],����ͼ[32 ]��[33]��[34]��[35]��3D ����/���� [36]��[37]��[38]���ĵ� [39]��[40]��[41]��[42]����̴��� [ 43]�ͳ������(AST)����һ��ͼ[44]������[45]��ҽѧ֪ʶ(����,��ϴ��뱾��[46])�� ��ע��,���ε��鲻��������û�ж�ģʽ��Ƶ�����½��� Transformer ����������ȡ���Ķ�ģʽ���ġ�
- ��ص��� ���ǽ�������������ض�ά�� MML �� Transformers �����е�����ϵ����������һЩ MML ���� [1]��[10]��[11]���ر���,[1] ͨ�������ս�����һ���ṹ���ġ����ϵķ��෨,����Ҳ������Ϊ���ǽṹ��һ���֡���ع�ͨ�û���ѧϰģ�͵� [1]��[10] �� [11] ��ͬ,����ת����ע Transformer �ܹ�������ע�������ơ�����,�����������һЩר�����Transformer�ĵ���,�ص����ͨ��Transformer[47]����Ч���[48]�����ӻ�[49]��������Ӿ�����[50]��[51]��[52] ]��[53]��ҽѧ����[54]����Ƶ����[55]���Ӿ�����Ԥѵ��[56]����Ȼ [50]��[52]��[53]��[54] ������ MML,�����ǵ������ڷ�Χ��������Ƿ�Χ���������ơ���������֪,ֻ������������Ƶ����Ԥѵ�� (VLP) [56]��[57]��[58] �ĵ����� MML ��ء�Ȼ��,VLP ֻ�� MML ��һ�������ڱ��ε�����,����ֻ��ע��ģ̬ѧϰ�� Transformer �Ľ���㡣
- �������� ��������֪,�����ǶԻ��� Transformer �Ķ�ģ̬����ѧϰ״̬�ĵ�һ��ȫ��عˡ� ���ε������Ҫ�ص����
- (1) ����ǿ�� Transformer �������������ǿ�������ģ̬�صķ�ʽ������ ���,���������ģʽ(��ģʽ�����)���ݡ� Ϊ��֧����һ�۵�,�����״δӼ������˵ĽǶ��ṩ�˶Զ�ģ̬��������Transformer���������������⡣ ���ǽ��齫 self-attention ��Ϊһ��ͼ��ʽ��ģ,������������(��ģ̬�Ͷ�ģ̬)��ģΪȫ����ͼ�� ������˵,self-attention ����������ģ̬����������Ƕ�뽨ģΪͼ�ڵ㡣
- (2)���Ǿ���������ѧ�����۶�ģ̬��������Transformer�Ĺؼ������
- (3)����Transformers,��ģ̬����(�����ںϡ�����)����������self-attention������崦���ġ� �ڱ�����,���Ǵ���ע������ƵĽǶ���ȡ�˻��� Transformer �� MML ʵ������ѧ���ʺ�ʽ��
- �ڻع��˶�ģ̬ѧϰ��Transformer ��̬ϵͳ�Ͷ�ģ̬������ʱ����ǰ��֮��,���ǽ����ǵ���Ҫ�����ܽ����¡�
- (1) ���ǴӼ������˵ĽǶȶ� Vanilla Transformer��Vision Transformer �Ͷ�ģ̬ Transformer ���������ۻعˡ�
- (2) ���Ǵ����������ĽǶ�Ϊ���� Transformer �� MML �ṩ����,������Ӧ�ó���ͻ�����ս�� �ڵ� 4 ����,����ͨ��������Ҫ�ķ���,����ģ̬Ԥѵ�����ض��Ķ�ģ̬����,�Զ�ģ̬ Transformer Ӧ�ó�������˻عˡ� �ڵ� 5 ����,�����ܽ��˸��ֶ�ģ̬ Transformer ģ�ͺ�Ӧ�ó��������еĹ�ͬ��ս����ơ�
- (3) ���������˻��� Transformer �� MML ��ǰ��ƿ�������ڵ������DZ�ڵ��о�����
- ���ε������֯ ���ε�������ಿ����֯����:�� 2 �ڽ�����ʹ�� Transformer ���ж�ģ̬����ѧϰ�ı���,������ʷ�۵�ؼ���̱��� �� 3 �������� Transformer��Vision Transformer �������ģ̬�� Transformer �Ĺؼ�������ԡ� �ڵ� 4 ����,���Ǵ�Ӧ�úʹ�����ģ�͵ĽǶ�Ϊ��ģ̬ Transformer ģ���ṩ��һЩ���ࡣ �ڵ� 5 ����,�����ܽ��˸��������Ҫ��ս����ơ� �� 6 ��������һЩ���ڵ������DZ�ڵ��о����� �� 7 �ڸ����˽��ۡ�
- ���������������,��������˵��,������ѧ���ź���д�ʾ���ѭ�� 1 �е�Լ����
����
��ģ̬ѧϰ(MML)
- MML [1]��[63] �ǽ���ʮ������һ����Ҫ�о�����; ���ڵĶ�ģ̬Ӧ�á�����������ʶ���� 1980 ������о� [64]�� MML ���������Ĺؼ��� �������������������һ����ģ̬����,������ǵĹ۲����Ϊ���Ƕ�ģ̬��[65]�� ����,�˹����ܵ�����������Ҫ��ģʽ����������֪��ʵ���绷�� [66]��[67]��[68],��������������״�״��������GNSS�������ͼ����̱��� ����,������Ϊ���������¼�����������Ĭ�Ƕ�ģ̬��,��˸�������Ϊ���ĵ� MML ���㷺�о�,������ģ̬���ʶ�� [69]����ģ̬�¼���ʾ [70]�������ģ̬��Ĭ [ 71],�����沿-����-��������Ƶ�������[72]�ȡ�
- ������,���Ż������ķ�չ���������豸�ķ�չ,Խ��Խ��Ķ�ģ̬����ͨ������������,Խ��Խ��Ķ�ģ̬Ӧ�ó�������ӿ�֡� ���ִ�������,���ǿ��Կ������ֶ�ģʽӦ��,������ҵ����(�����������/��Ʒ����[73]���Ӿ������Ե���(VLN)[68]��[74]��[75]�� [76]��[77]��[78]��[79]��[80]��[81]��[82]��[83])������(���紽��[84]�������[25]�� [26]��[85])���˻�����[86]��ҽ�Ʊ���AI[87]��[88]�����AI[89]�ȡ�
- ����,�����ѧϰʱ��,��������缫����ƶ��� MML �ķ�չ�� �ر���,Transformers [2] ��һ���������ҵļܹ�����,Ϊ MML �������µ���ս�ͻ�����
Transformer:��ʷ����̱�
-
Transformer���ڳ�Ϊ��ǰ;��ѧϰ�ߡ� ������������ע��,Vanilla Transformer [2] ����������ע�����,�����Ϊ NLP ����������ض���ʾѧϰ��ͻ����ģ��,�� ���� NLP ���� ���� Vanilla Transformer �ľ�ɹ�,��������ģ�ͱ����,���� BERT [4]��BART [90]��GPT [91]��GPT-2 [92]��GPT-3 [93]��Longformer [ 40]��Transformer-XL [94]��XLNet [95]��
-
Transformers Ŀǰ�� NLP ������������λ,���ʹ�о���Ա���Խ� Transformers Ӧ��������ģʽ,�����Ӿ����� ���Ӿ���������ڳ�����,����̽����һ�������ǡ�CNN ���� + �� Transformer ��������,�о���Աͨ������ԭʼͼ���С���ͷֱ��ʲ���������Ϊһά������ʵ�� BERT ʽԤѵ�� [96 ]��
-
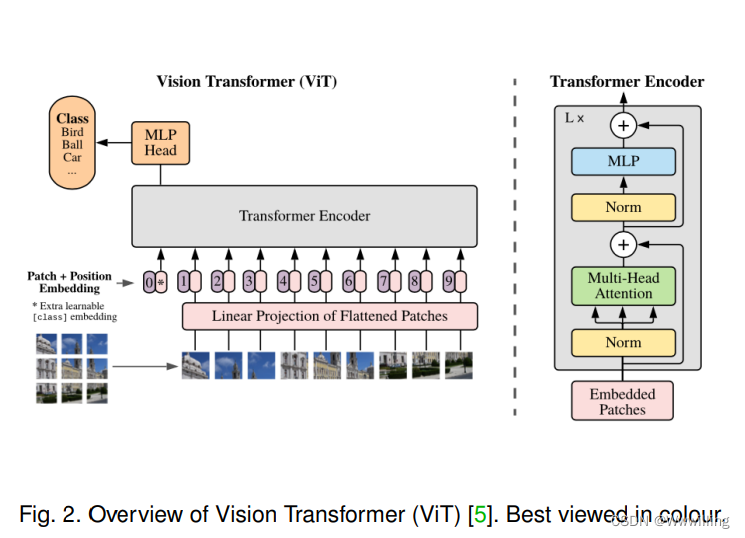
Vision Transformer (ViT) [5] ��һ����ԵĹ���,��ͨ���� Transformer �ı�����Ӧ����ͼ�����ṩ�˵��˵Ľ�������� (�μ�ͼ 2��)ViT ������嶼�ѹ㷺Ӧ���ڸ��ּ�����Ӿ�����,�����ͼ����� [97]��ʶ�� [98]����� [99]���ָ� [100] �� ,���Ҷ����мල��[98]�����Ҽල��[101]��[102]��[103]�Ӿ�ѧϰҲ����Ч�� ����,һЩ�����������ƷΪ ViT �ṩ�˽�һ������������,����,�����ڲ���ʾ³���� [104]����DZ�ڱ�ʾ������������Ϊ [105]��[106]��
-
�� Transformer �� ViT �ľ�ɹ����ƶ���,VideoBERT [7] ��һ��ͻ���ԵĹ���,�ǵ�һ���� Transformer ��չ����ģ̬����Ĺ����� VideoBERT չʾ�� Transformer �ڶ�ģ̬�����еľ�DZ���� �� VideoBERT ֮��,������� Transformer �Ķ�ģ̬Ԥѵ��ģ��(����,ViLBERT [107]��LXMERT [108]��LXMERT [108]��VisualBERT [109]��VL-BERT [110]��UNITER [111]��CBT [112] , Unicoder-VL [113], B2T2 [114], VLP [115], 12-in-1 [116], Oscar [117], Pixel-BERT [118], ActBERT [119], ImageBERT [120], HERO [121],UniVL [122])�ѳ�Ϊ����ѧϰ����Խ��Խ����Ȥ���о����⡣
-
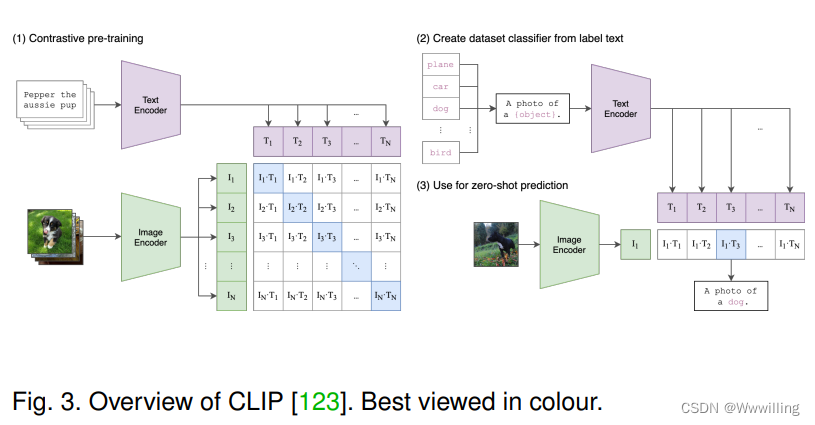
2021 ��,����� CLIP [123](��ͼ 3 ��ʾ)�� ����һ���µ���̱�,��ʹ�ö�ģ̬Ԥѵ��������ת��Ϊ��������,ʹԤѵ��ģ���ܹ�����������ʶ�� ���,CLIP ��һ���ɹ���ʵ��,����������˴��ģ��ģ̬Ԥѵ����ʵ��������ѧϰ�� ���,��һ���о��� CLIP ��˼��,������� CLIP Ԥѵ��ģ�͵�����������ָ� [124]��ALIGN [125]��CLIP-TD [126]��
��ģʽ������
- �ڹ�ȥ��ʮ����,�����罻ý����������۵Ȼ�����Ӧ�õĿ��ٷ�չ,�����Ķ�ģ̬���ݼ������,���������Ļ[127]��COCO[128]��VQA[129]���Ӿ�������[130] , SBU Captions [131], Cooking312K [7], LAIT [120], e SNLI-VE [132], ARCH [133], Adversarial VQA [134], OTT QA [16], MULTIMODALQA (MMQA) [135] ]��VALUE [136]��Fashion IQ [137]��LRS2-BBC [138]��ActivityNet [139]��CN ERTA [140]��DVD [141]��VisDial [142]��PhotoChat [143]��
- ��������Ķ�ģ̬���ݼ��г��ֵ�һЩ��������:
- (1)���ݹ�ģ����
- ��������ĸ������ݼ����ǰ���,���� Product1M [144]��Conceptual 12M [145]��RUC-CAS-WenLan [146] (30M)��HowToVQA69M [147]��HowTo100M [148]��ALT200M [149]��LAION -400M [150]��
- (2) ģ̬����
- �����Ӿ����ı�����Ƶ��һ��ģʽ֮��,�������˸��ͬ��ģʽ,���� Pano AVQA [151]������һ�� 360�� ��Ƶ�Ĵ��ģ�ռ�������ʴ����ݼ�,YouTube-360 (YT-360) [152] (360�� ��Ƶ), AIST++ [153] (һ���µ� 3D �赸���������ֵĶ�ģ̬���ݼ�), Artemis [154] (�Ӿ��������������)�� �ر���,Multi Bench [155] �ṩ��һ������ 10 ��ģʽ�����ݼ���
- (3)���ೡ��
- ���˳�������Ļ�� QA ���ݼ���,���о��˸����Ӧ�úͳ���,���� CIRR [156](��ʵ�����е�ͼ��)��Product1M [144]��Bed and Breakfast (BnB) [157](�Ӿ������� ����),M3A [158](�������ݼ�),X-World [159](�Զ���ʻ)��
- (4)����������ѡ�
- ���˼�����֮��,������˸�����Ķ�ģ̬����,���� MultiMET [160](������������Ķ�ģ̬���ݼ�)��Hateful Memes [161](��ģ̬ģ���еij������)��
- (5) ��ѧ��ƵԽ��Խ�ܻ�ӭ,���������Ƶ YouCookII [162]�� ��һϵ��ָ����ij��ִ���������Ƶ������һ��ǿ���Ԥѵ����������ʾ�� [7]��[163]��
- ���������������ܹ�����,Transformer Ҳ��Ҫ�������ݡ� ���,���ǵĸ�����ģ�ͺͶ�ģ̬�����ݻ�����ͬ�����˻��� Transformer �Ķ�ģ̬����ѧϰ�ķ��١� ����,�����ݴ���������ѧϰ��
Transformer: ��������ѧ�ӽ�
- �ڱ�����,����ʹ����ѧ��ʽ���ع� Vanilla Transformer [2]��Vision Transformer [5] �Ͷ�ģ̬ Transformer �Ĺؼ�����,������ǻ����롢self-attention��multi-head attention������ Transformer ��/��ȵȡ�����ǿ�����ԴӼ������˵ĽǶ����� Vanilla Transformer [164],��Ϊ������ע�����,���������κ�ģ̬��ÿ����ǻ�����,Vanilla ��ע��(Transformer)���Խ�ģ�������˼��οռ��е�ȫ����ͼ[165]���������������(����,CNN �����ڶ��������ռ�/����)���,Transformers �����Ͼ��и�ͨ�ú����Ľ�ģ�ռ䡣���� Transformer ���ڶ�ģʽ�����һ���������ơ��� 3.1 �ں͵� 3.2 �ڽ��ֱ�ع� Vanilla Transformer �� Vision Transformer �Ĺؼ���ơ����ǽ�����߲ο��������õ�ԭʼ�����Ի�ȡ������ϸ��Ϣ��
- �ڱ��ε�����,��multimodal Transformer����ָ����ģ̬ѧϰ�����е� Transformer��
- Vanilla Transformer
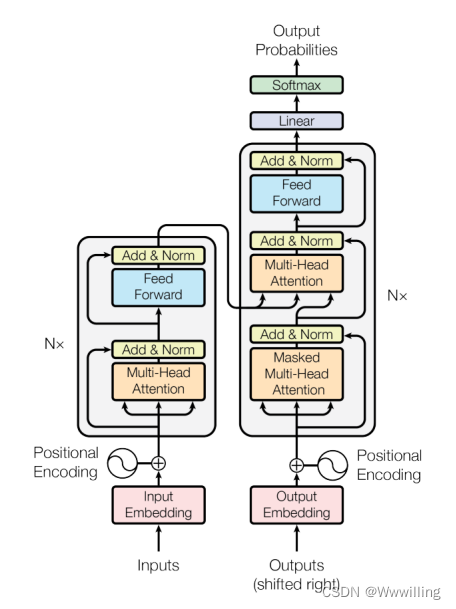
- Vanilla Transformer ���б�����-�������ṹ,�ǻ��� Transformer ���о��������Դ�� �����ñ�ǻ�����(�μ��� 3.1.1 ��)�� ���ı������ͽ��������� Transformer ��/��ѵ�,��ͼ 1 ��ʾ��ÿ���鶼�������Ӳ�,��һ����ͷ��ע���� (MHSA) ��(�μ��� 3.1.2 ��)��һ����λ�õ�ȫ����ǰ������(FFN)(���� 3.1.3 ��)�� Ϊ�˰����ݶȵķ���,MHSA �� FFN ��ʹ�òв����� [166](�������� x,�κ�ӳ�� f(��) �IJв����Ӷ���Ϊ x �� f(x) + x),����ǹ�һ���㡣 ���,������������Ϊ Z,MHSA �� FFN �Ӳ��������Ա�ʾΪ:
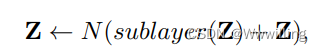
- ���� sublayer(��) ���Ӳ�����ʵ�ֵ�ӳ��,N(��) ��ʾ��һ��,���� BN(��)��LN(��)��
- ���� ��һ����Ҫ��δ��������Ǻ��һ����Ԥ��һ���� ԭʼ�� Vanilla Transformer ��ÿ�� MHSA �� FFN �Ӳ�ʹ�ú��һ���� ����,������Ǵ���ѧ�Ƕȿ�����һ��,Ԥ��һ���������塣 �������ھ������۵Ļ���ԭ��,����ͶӰ֮ǰ���й�һ��,����Gram-Schmidt���̡� �������Ӧ��ͨ�������о���ʵ����֤����һ���о���
- Vanilla Transformer �������Ϊ���е�����ģ�ͱ�������ڻ��������,��˿���ֱ�ӽ��ʻ�������Ϊ���롣 ��ǰ����,ԭʼ����ע�������Խ��������뽨ģΪ��ȫ���ӵ�ͼ,����ģ̬�ء� ������˵,Vanilla �ͱ��� Transformers �����ñ�ǻ�����,����ÿ����Ƕ�������Ϊͼ��һ���ڵ㡣
Self-Attention Variants in Multimodal Context
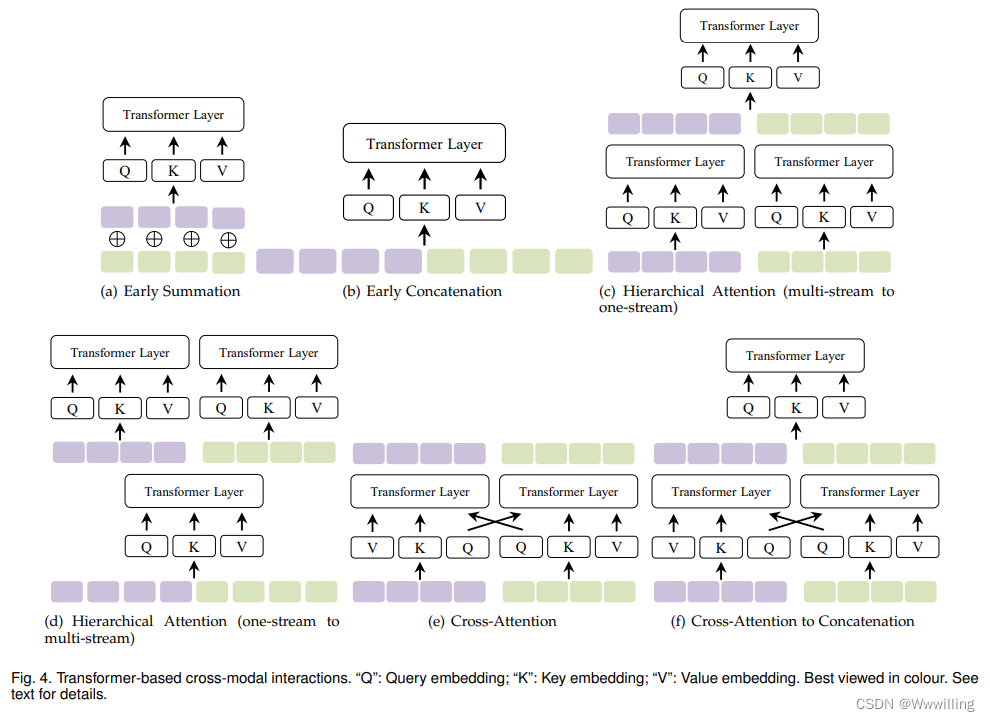
- (1)���������ʵ����,������� [45]��[89] ��һ�ּ���Ч�Ķ�ģ̬����,�������Զ��ģ̬�ı��Ƕ�������ÿ�����λ�ý��м�Ȩ���,Ȼ���� Transformer �㴦��:
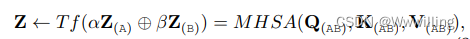
- ���Ш���Ԫ���ܺ�,���ͦ���Ȩ�ء� �������,
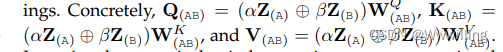
- ������Ҫ�ŵ��Dz������Ӽ��㸴�Ӷȡ� Ȼ��,������Ҫȱ���������ֶ�����Ȩ�ء� ��� 3.1.1 �ں�3.3.1�����λ��Ƕ�뱾������������͵������
- (2) Early Concatenation ��һ��ֱ�ӵĽ��������early concatenation [7]��[43]��[180]��[182],�����Զ��ģ̬������Ƕ�������������������뵽 Transformer ����:
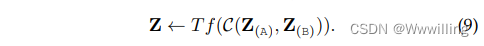
- ���,���еĶ�ģ̬���λ�ö�������Ϊһ������������������,����ÿ��ģ̬��λ�ÿ���ͨ����������ģ̬�����������ܺõر��롣 VideoBERT [7] �ǵ�һ����ģ̬ Transformer ��Ʒ,������Ƶ���ı�ͨ�����������ں�,���Ժܺõر���ȫ�ֶ�ģ̬������ [190]�� Ȼ��,���Ӻ�Ľϳ����л����Ӽ��㸴�Ӷȡ� ��������Ҳ����Ϊ��ȫע��������Co Transformer��[144]��
- (3)�ֲ�ע��(����������) Transformer ����Էֲ�����Դ�����ģ̬������ һ�ֳ����������Ƕ�ģʽ�����ɶ����� Transformer ������,���ǵ��������һ�� Transformer [153] ���Ӻ��ں�:
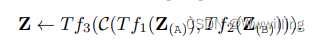
- ���ֲַ�ע�����Ǻ��ڽ���/�ںϵ�һ��ʵ��,���Ա���Ϊ�������ӵ�һ�����������
- (4)�ֲ�ע��(����������)InterBERT [190] �Ƿֲ�ע�����һ������ʵ��,�������ӵĶ�ģ̬�����ɹ����ĵ��� Transformer ����,Ȼ�������������� Transformer ���� �����̿��Ա���Ϊ
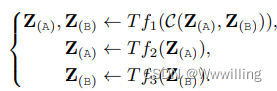
- �÷�����֪��ģ̬����,ͬʱ���ֵ�ģ̬��ʾ�Ķ����ԡ�
- (5)Cross-Attention ����˫�� Transformer,��� Q (Query) embeddings �Կ�����ʽ����/����,Ҳ���Ը�֪��ģ̬������ ���ַ�������Ϊ����ע���ͬע��[193],�������� VilBERT [107] �����:
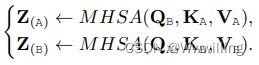
- Cross-attention ��עÿ������һ��Ϊ������ģ̬,���Ҳ��ᵼ�¸��ߵļ��㸴�Ӷ�,�����������ÿ��ģ̬,�÷�����ȫ��ִ�п�ģ̬��ע,��˻ᶪʧ���������ġ� ���� [190] �������۵�,˫������ע��������ѧϰ��ģ̬����,����ÿ��ģ̬�ڲ�������������û������ע�⡣
- (6) Cross-Attention to Concatenation ��������ע������ [107] ���Խ�һ�����Ӳ�����һ�� Transformer �����Զ�ȫ�������Ľ��н�ģ�� ���ֲַ�Ŀ�ģ̬����Ҳ���㷺�о�[144],[192],�������˽���ע������ȱ�㡣
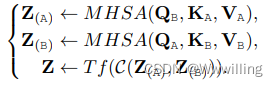
- ����������Щ�������ڶ�ģ̬��������ע�������嶼��ģ̬ͨ�õ�,���ҿ���Ӧ�������IJ��ԺͶ��������� ������˵,��Щ�������������Ϻ�Ƕ�ס� ����,�������ע�������ڷֲ�ע��(����������),��˫������ģ�� [194] ��,��ʽ 11 �� T f 2 Tf_2 Tf2? �� T f 3 Tf_3 Tf3? �ɵ�ʽ�ж���Ľ���ע��ʵ�� 12. ����,���ǿ�����չ������(�� 3 ��)ģʽ�� TriBERT [185] ��һ������Ӿ������ƺ���Ƶ����ģ̬����ע��(co attention),�ڸ�����ѯǶ��������,�����ֵǶ������������ģ̬�����ӡ� �� [192] ��,�����ӵĽ����עӦ��������ģʽ(�����ԡ���Ƶ����Ƶ)��