Vision Transformer��MLP-Mixer�����ѧϰ�������µ�������ϵ�ṹ�������ڸ����Ӿ������ж��dz��ɹ����Ӿ�Vision Transformer�������Ժ���MLP-Mixers,�������ӡ�����������ģ�ͷdz�����,ֻ��С�����𡣱����н�������ģ���е����������ϵ�ͶԱ�,˵�������ǵ���Ҫ����,���Ƚ������ǵ����ܡ�
���
Transformer��2016����������,һֱ����Ȼ���Դ���(NLP)������ش�ͻ�ơ��ȸ��BERT��Open AI��GPT��ϵ�ṹ�Ѿ���Ϊ���Է��롢�ı����ɡ��ı�ժҪ������ش����������Ƚ����������
Transformer���Ӿ������Ӧ���Ѿ�����������ӡ����̵Ľ����һ������ΪViT��ģ���ܹ����Ӿ�������ʤ������Ļ��ھ�����ģ�͡������ڱ���ΪSwin Transformer��ViT�����Ѿ��ڸ��ּ�����Ӿ�������ʵ�������Ƚ�������,�������ࡢ���ͷָ
��������һ����ΪMLP-Mixer�ļܹ��ܵ��˹㷺��ע������ģ�͵ļ��Էdz������ˡ���VITһ��,MLP-Mixer�ı���Ҳ��Ӧ���ڲ�ͬ�ļ�����Ӿ�����,�������ͷָ��ijЩ�����,��Щģ�͵����������Transformer��ģ���൱��
ViT��MLP-Mixer�ļܹ�������ʾ����Щ��ϵ�ṹ�dz�����,ͨ������������Ҫ����,a)����Ƕ��,b)ͨ���ѵ���Transformer��������ȡ����,c)����ͷ��

��ͼΪVIT
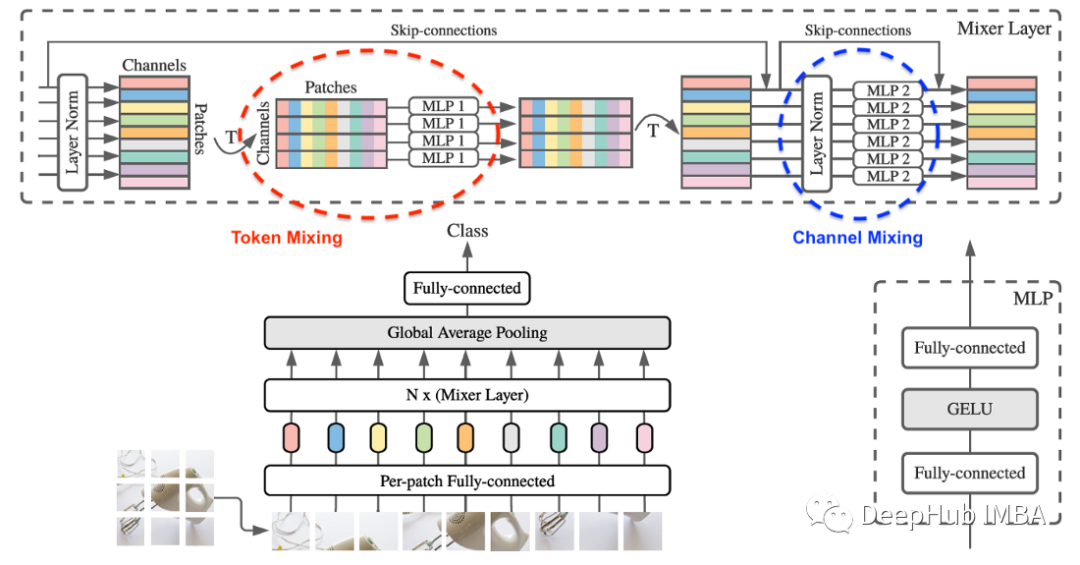
MLP-Mixer
���ĵ���ҪĿ����˵��MLP-Mixer��ViTʵ������һ��ģ����,���������ڱ����Ͽ�������ͬ��
MLP-Mixer��VIT�Ĺ�ϵ
MLP-Mixer�����VIT��һЩ���˼�롣�����Եķ����ǽ�����ͼ��ָ�ΪС��,��ʹ�����Բ㽫ÿ��С��ӳ�䵽Ƕ��������ViT��MLP-Mixer����ʹ�þ���,�����������Ʋ�ʹ�á���ʵ����Ƕ��ʵ�����Ǿ����벽�����ڲ�����С�Ͳ��������IJ�����
�Ա������ּܹ�,���������ǵ�����֮����������Ƕ���:
- ����ģ���е�Ƕ�������ͬ��,������ʹ�þ��е����MLPʵ�ֵġ�
- ͨ�����������ģ����ͨ��˫��MLP����ȫ��ͬ�ķ�ʽ��ɡ�
- ������ģ����ͨ�������ƻ�ϲ�������ͬ�ķ�ʽʹ�òв����ӡ�
- ����ģ�Ͷ�ʹ��LayerNorm���й淶����
- ��Щģ��֮�����Ҫ����������ʵ�����ƻ�ϵķ�ʽ�����ƻ����ViT�з����ڶ�ͷ��ע��(MHSA)��,����ViT����ͨ������MLP��ɵġ�MHSA�����ж��ͷ�����ڼ��������,��������һ����СΪd(Ƕ��ά��)��ͷ,������d����СΪ1��ͷ������ע������Ϣ����ͨ��MLP���ݵġ�ʵ����,MSHA��ͬʱ�������ƻ�Ϻ�ͨ����ϡ�����ͼ��ʾ
- �ڶ�����ƺ�ͨ�����֮��,ģ�ͽ���Ϣӳ�䵽���ǩ����ViT��,ʹ������MLP��һ������ı�dz�Ϊ[cls]���(ά��Ϊd)ӳ�䵽���ǩ����MLP- mixer��,����ʹ��MLP�ķ�ʽ��ͬ,��������Ϣ�粻ͬ�IJ���(ƽ���ػ���)���гػ���
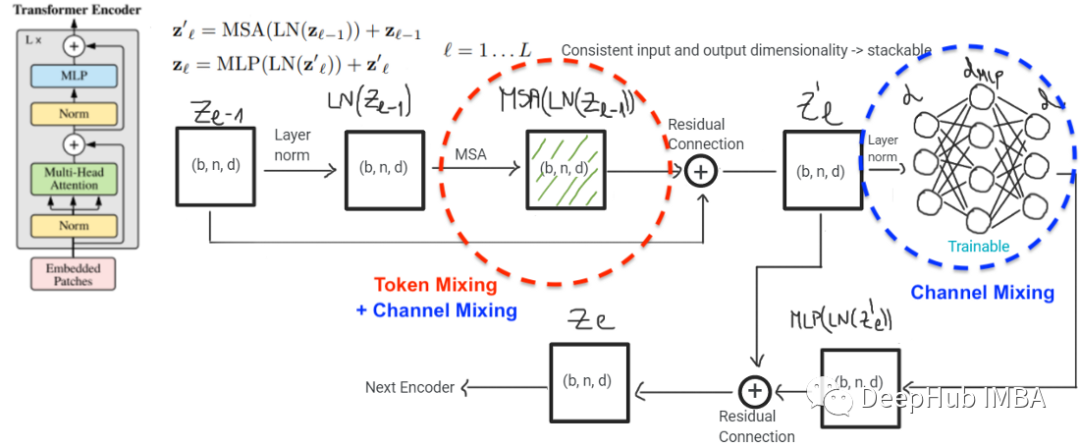
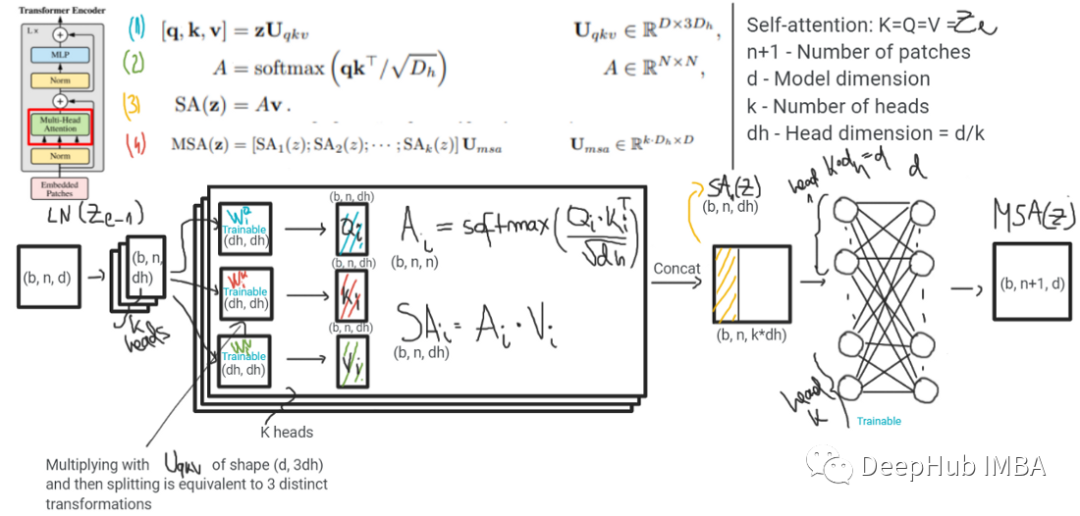
ģ�͵���Ҫ�������ڱ�ǻ������ν��еġ�ViTʹ����ע��,��MLP- mixerʹ��MLP��������һ�㡣�������������ƺ���̫��Ҫ:
ViT�е�[CLS]�����Ѿ�������������������ժҪ��Ϣ������MLP-Mixer(ƽ���ػ���)�������粹���ػ���Ϣ�ƺ�����̫��Ҫ,�������������Ҫ����ϸ�о���һ�㡣
MLP-Mixer��ʹ��λ�ñ��롣��ͬ��NLP��˳��ʿ��Ըı���ӵ���˼,��������ͼ���ƺ��������һ�����еij���Ҳ������Ȼ��������������Ӿ������п��ܲ�����Ҫ!
ViT���߱���,����λ����Ϣȷʵ�����ȷ��(�μ���¼�еı�8)��λ�ñ���������ά��λ����Ϣ,��Ϊ����������ļ������ƺ�ͨ�����֮��,λ����Ϣ����ʧ����Ȥ����,��û����ȷ���ǿռ���Ϣ�������,MLP-Mixer��Ȼ���ֵ÷dz���,������ViT�������¡���MLP-Mixer�����ӿռ���Ϣ�Ƿ��������侫��,��Ҳ��һ������Ȥ���о���
�±���ʾ������ģ�����ĸ����ϵıȽϡ�ViTģ�͵������Ժ���MLP-Mixer,�����и���IJ�����
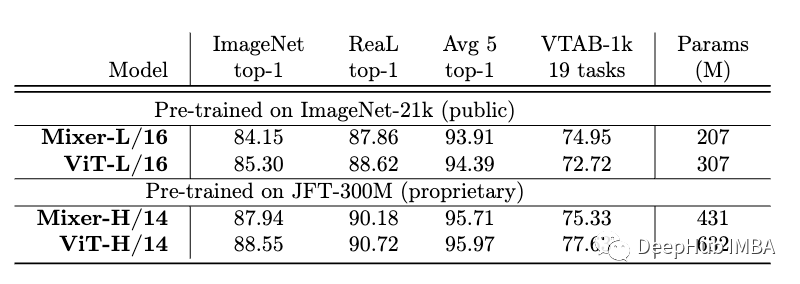
2ģ�͵�Ӱ���δ��
���������ܽ�����ģ�͵���ͬ�Ͳ�ͬ,������ȫ�ֿ���һ��ͳһ���ӽ�:
������ģ�͵IJ�ͬ��Ҫ�������ǿ��ǻ����Ϣ�ķ�ʽ(��,�ռ�λ��)��Ŀǰ���������ע���ڻ�����Ʒ����MLP�ж������ơ�������ע����������û��ʲô�ر��,������������ij�̶ֳ��ϴ��Һͻ�Ͽռ�λ���ϵ���Ϣ���о���������һ�ַ�������cnn��ʹ��MLP������Ͽ�ռ�λ�õ���Ϣ�����ƻ�Ϻ�ͨ����ϵĸ����ڸ��ߵIJ���ϱ��ģ��,��Ϊ��Ϣ������ĺ��ڷ�ɢ�ںܶ�ط���
���ֻ������һ������ӳ�䵽�����,������ViT������������,MLP-Mixer�Ƿ���Ȼִ��������,���Ҳ�ǿ��Խ���ʵ�顣������MLP-Mixer�����ӿռ�����Ƿ�����߾��Ȼ���һ������δ�������⡣
�������еļܹ�(��cnn��VIT��MLP-Mixer)�ƺ����Ż����ܺܺõ�ִ���Ӿ������ⲻ�����˺���,����һ����Ч���Ӿ�ϵͳ����Ļ���������ʲô?����Щģ�ͱ�����ģ�ͺ�,��Ҫ����Ϊ���������˸��á������ܵļܹ����,������Ϊ�о���Ա���˸����ʱ���Ż�����?���ֵ�ǰ�ܹ�����ѷ�����ʲô?���е�ģ������ι�����,������λ������?����ģ�͵���Ҫȱ����ŵ���ʲô?��Щ��ϵ�ṹ�жཡ׳?��ĿǰΪֹ,���ǵ�ֱ���ͽ��۴�����ʵ֤���,���Ǹ�����ȱ��ǿ���������۶���������ܳ�һ��ʱ������,������Ϊ�����ͳػ������������Ӿ�ϵͳ�Ļ�������ģ��,��VIT��MLP-Mixers��ս���������
����
[1] Vaswani, Ashish, et al. ��Attention is all you need.�� Advances in neural information processing systems 30 (2017).
[2] Dosovitskiy, Alexey, et al. ��An image is worth 16x16 words: Transformers for image recognition at scale.�� arXiv preprint arXiv:2010.11929 (2020).
[3] Liu, Ze, et al. ��Swin transformer: Hierarchical vision transformer using shifted windows.�� Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Tolstikhin, Ilya O., et al. ��Mlp-mixer: An all-mlp architecture for vision.�� Advances in Neural Information Processing Systems 34 (2021): 24261�C24272
https://avoid.overfit.cn/post/2416fcc61e2a48f4a0c288dfb30c81bf