
?The DECIMER 2.0:https://github.com/Kohulan/DECIMER-Image_Transformer
��ѧ��ѧ�ṹʶ��(OCSR)����,����������õ�OCSR���ߴ���ǻ��ڹ���DECIMER�㷨�������Ҫ�������ɹȸ��DeepMind�����ijɹ���AlphaGo Zero�㷨��AlphaGo Zero�ijɹ�,�dz�������ս�Ե��������ͨ��ӵ���㹻����������ʹ���ʵ���������ܹ�����ֽ����
Ŀ���ǽ���һ��ȷ��ԼΪ90%��ϵͳ,����ͨ����5000 - 1�ڸ��������ݼ���ѵ��������ʵ��
Materials and methods
��ȫ���������Ļ�ѧͼ��ʶ��������,PubChem,ʹ��CDKȥ��������ʽ��,������SMILES,�̳��˹淶�������������廯ѧ��Ϣ��������SMILES֮��,��ʹ������һ���������ݼ����й���,�Ի��һ��ƽ������ݼ���
SMILESɸѡ:

�����ݼ�����3900���������ͬ���Ĺ����������ɵڶ������ݼ�,���Ǵ��д�����ŵķ��Ӱ�������������ʽ�����廯ѧ������������������,�������ݼ��к�����ǵķ��ӱ�ɾ��,�����һ��������Լ3700������ӵ����ݼ������Ӷ������Ϣ����SMILES�ַ��ij��ȱ䳤��
ÿ������Image�������ת,������Ϊ8λPNGͼ��,�ֱ���Ϊ299 �� 299
ʹ�����Եڶ������ݼ���ͼ��,������ͼ����ǿ,���ɵ��������ݼ���ͼ����ǿ��ʹ��imgaug python��Ӧ�õġ���ͼ�����Ӧ��������ǿ֮һ:

ѵ����,��Ԥ���о���������Чsmiles,�������徫���������͡�Ϊ�˽���������,ʹ��DeepSMILES��SELFIES�������SMILES���,DeepSMILES���ֳ����õĽ��,����Ч��DeepSMILES�ٴ����������Ƶ����⡣���,ʹ����SELFIES,��Ϊͨ����������(��]��)��������(��[��)�зָ�SELFIES,���Ժ����طָ��token������ҪӦ�ý�һ���Ĺ�����ָ��һ��token����
3�����ݼ��е�����smile�ַ�����ʹ��Pythonת��ΪSELFIES,
the datasets:
Dataset 1:?PNG images + SELFIES, without?stereochemical information and charged groups
Dataset 2: PNG images ?+ SELFIES, with stereochemical information and charged groups.
Dataset 3:?Augmented PNG images + SELFIES, with stereochemical information and charged groups
���ݼ���ÿ�����ݼ���10%��ѡȡ��Ϊ�˱�֤���Ժ�ѵ�����ݵĻ�ѧ����������,ʹ��RDKIT MaxMin�㷨ѡȡ10%��SMILES��Ϊ�������ݼ�

Image feature extraction:������InceptionV3��EfficientNet-B3,����ֵ��һ��Ϊ����?1��1,������InceptionV3(ImageNetԤѵ��)��EfficientNet-b3(Noisy-studentԤѵ��),��ȡ������InceptionV3 feature map(8 �� 8 �� 2048),EfficientNet-b3 feature map(10 �� 10 �� 1536)
Tokenization:�� [ _ ] ����ָ�,����������:

encoder-decoder�ṹ:������ΪCNN����������(InceptionV3/EfficientNet-B3),����������RNN(GRU)������ȫ���Ӳ㡣�ý�������1024����Ԫ���,embed_dimΪ512��Adam�Ż�������ѵ��,����ѧϰ�ε�learning_rateΪ0.0005,��ʧΪԤ��SELFIES��SELFIES ground truth��Cross_entropy
Transformer network: 4���8 heads��attention_embed_dimΪ512,forward_mlp_sizeΪ2048,dropout 0.1,adam

Training the models:
V100 Tesla with 32 ?GB, 384 ?GB of RAM and two Intel(R) Xeon(R) Gold 6230 CPUs,batch_size 512,һ��epoch 30min,������1d5h48m,
TPU v3- node 8,batch_size 1024,ÿepoch 8 min 41 s,������8 h 41 min 4 s
Testing the models:Ԥ���SELFIES�������SMILES,Ȼ��ʹ�ð�����CDK�е�PubChemָ�Ƽ���ԭʼ�ĺ�Ԥ���SMILES��Tanimoto���ƶȡ����˶���Tanimoto����ָ��Ϊ1.0��Ԥ��,��ʹ��CDK������inchi��ִ��ͬ�����,��ȷ��Tanimoto 1.0Ԥ���Ƿ�Ϊ�ṹ��ʶ������proxy��
Results and discussion:
��ͬ�豸����ʱ��(��������),100�����ݼ�:

90Wѵ��,10W����
Image feature extraction test(InceptionV3 vs EfficentNet-B3):

EfficentNet-B3Ч�����á�
Encoder�Cdecoder model vs. transformer model:

transformerЧ�����á�
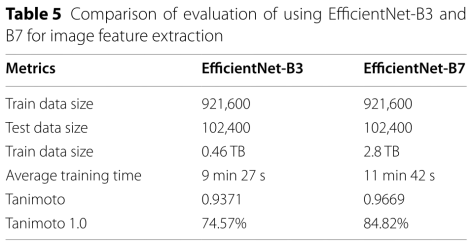
Image feature extraction comparison using EfficientNet?B3 ?and B7:
EfficientNet-B7��EfficientNet-B3 ���� 2.7%����B7,ͼ�����600 �� 600,��ѧ�ṹ��������Ŵ���������������B3 299*299�Ϳ����ˡ��������ѧ�ṹ�������Ժ�������Ӧ299 �� 299�ı���,���Ҫʹ��600 �� 600�ı���,ͼ��Ӧ�÷ŴŴ�ᵼ����Ϣ��ʧ
The performance measure with increasing dataset size:Ϊ����ѵ���Ͳ������ݵķָ�ٷֱ����Ӱ��ѵ��Ч��
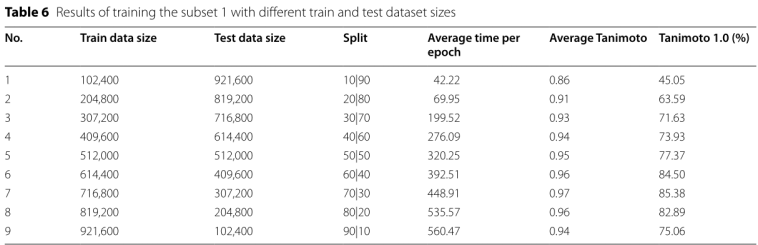
��������������ߵ�7:3,�����½�,�Դ�����������,
��ͬ���ݼ���С������:

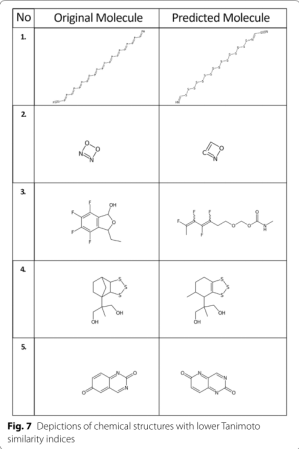
Analysis of the predictions with low Tanimoto similarity ?indices
�����ϵ�С����,�绷�պϵ�ȱʧ,�����»�ѧ�����п������ܴ�Ĵ���:

�˷���������ѵ������ʹ�ò�ͬ��ת��ͬһ��ѧ�ṹ�Ķ������,����ɿ���ͬһ���������ݵĸ������ӡ�����,���ò�ͬ/�����ͼ����ǿ����,����ʹ���������ؿ�����ѧ�ṹ��

Performance of the network with training data using stereochemistry information��Dataset 2(��ͬ�����ݼ�,�����������廯ѧ��������Ϣ)
ͨ�����������Ϣ,���Ƶ�Ψһ����������,�ڼ������Ʒֲ���,�����������ٵķ��ӱ�ɾ����ʹ��RDKit MaxMin�㷨�����˰���37��Mio���ӵ������ݼ�,��������Ϊѵ�����ݼ��Ͳ������ݼ���
�������廯ѧ��Ϣ������,Ψһ��SELFIES token_dim��27�����ӵ�61�������廯ѧ��Ϣ�ļ���������token������,Ҳ�ڻ�ѧ�ṹ����(image)���������µ���Ϣ,��Ш�μ���������

���ݼ�2�������Ӽ�,һ������1500���ѵ�����Ӽ���150������Է���,��һ������3300���ѵ�����Ӽ���370������Է��ӡ�

ƽ��Tanimoto�ϵ͡�Tanimoto 1.0�ļ���Ҳ���͡�