LeNet
1989年,Yann LeCun提出了LeNet模型,1994年,发布了LeNet-5模型。后来LeNet网络模型被广泛应用于银行的ATM取款机中,识别支票的数字。
1、LeNet(LeNet-5)简介
现在我们常说的LeNet一般指LeNet-5,结构简单,性能优异。
1.1 网络结构
LeNet作为一种卷积神经网络,主要由两部分组成:特征提取器和分类器。特征提取器由两个卷积块组成,每个卷积块都包含一个卷积层,一个sigmoid激活函数和一个平均汇聚层(池化层);分类器则由三个全连接层组成。
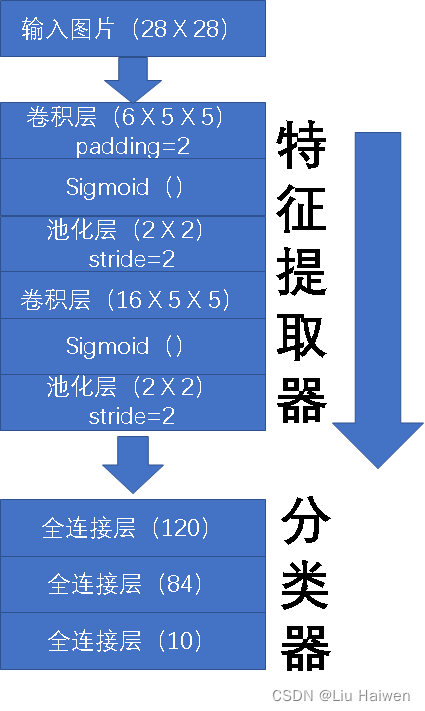
1.2网络实现
接下来用Python+Pytorch来搭建LeNet-5,实例化一个Sequential来连接所有的层:
net=nn.Sequential(
nn.Conv2d(1,6,kernel_size=(5,5),padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=(5,5)),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*5*5,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10)
为了检查搭建的网络是否正确,可以给net输入一个28 x 28的矩阵来检查每层的输出:
X=torch.rand((1,1,28,28),dtype=torch.float32)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'out shape:\t',X.shape)
运行结果如下:
Conv2d out shape: torch.Size([1, 6, 28, 28])
Sigmoid out shape: torch.Size([1, 6, 28, 28])
AvgPool2d out shape: torch.Size([1, 6, 14, 14])
Conv2d out shape: torch.Size([1, 16, 10, 10])
Sigmoid out shape: torch.Size([1, 16, 10, 10])
AvgPool2d out shape: torch.Size([1, 16, 5, 5])
Flatten out shape: torch.Size([1, 400])
Linear out shape: torch.Size([1, 120])
Sigmoid out shape: torch.Size([1, 120])
Linear out shape: torch.Size([1, 84])
Sigmoid out shape: torch.Size([1, 84])
Linear out shape: torch.Size([1, 10])
说明:
Conv2d out shape:卷积层输出图像的高/宽可以用下面公式计算:
h
′
=
(
h
+
2
?
p
a
d
d
i
n
g
?
h
1
)
/
s
t
r
i
d
e
+
1
h' = (h+2*padding-h1)/stride+1
h′=(h+2?padding?h1)/stride+1
w
′
=
(
w
+
2
?
p
a
d
d
i
n
g
?
w
1
)
/
s
t
r
i
d
e
+
1
w' = (w+2*padding-w1)/stride+1
w′=(w+2?padding?w1)/stride+1
h/w是输入图像的高/宽,padding是填充,stride是步幅,在卷积层中一般为1,h1/w1是卷积核的高/宽。第一个卷积层输入28 x 28,所以输出=28+2x2-5+1=28;卷积层输出图像的通道数跟卷积核的数目相同,由于第一个卷积层有6个卷积核,因此输出图像有6个通道;最后输出图像(6 X 28 X 28)。池化层输出图像的图像通道数不变,高/宽计算方式跟卷积层输出图像的高/宽一样。
2.模型训练
第一节中已经成功搭建了LeNet网络,本节将利用MNIST数据集训练LeNet模型。
2.1MNIST数据集
MNIST数据集是NIST(National Institute of Standards and Technology,美国国家标准与技术研究所)数据集的一个子集,训练集train一共包含了 60000 张图像和标签,而测试集一共包含了 10000 张图像和标签,每张图片是一个28*28像素点的0 ~ 9的灰质手写数字图片。
2.2数据迭代器
先构建一个数据迭代器来加载训练数据和测试数据:
def load_data_mnist(batch_size):
transform=transforms.ToTensor()
mnist_train=torchvision.datasets.MNIST(root='data',train=True,transform=transform,download=True)
mnist_test=torchvision.datasets.MNIST(root='data',train=False,transform=transform,download=True)
return (data.DataLoader(mnist_train,batch_size,shuffle=True),
data.DataLoader(mnist_test,batch_size,shuffle=True))
可以看一下数据的形状,验证一下数据加载是否正确:
train_iter,test_iter=load_data_fashion_mnist(100)
for X,y in train_iter:
print(X.shape,y.shape)
break
本节指定了batch_size=100,同时输出了第一个batch:
torch.Size([100, 1, 28, 28]) torch.Size([100])
可以看到第一个batch中有100张1 X 28 X 28的图像,同时对应100个标签。
2.3训练器
2.3.1初始化权重
利用正态分布初始化权重:
def init(n):
if type(n)==nn.Conv2d or type(n)==nn.Linear:
nn.init.normal(n.weight.data)
net.apply(init)
2.3.2统计网络预测正确数字的个数
在训练网络过程中,一般通过监测损失函数是否下降来判断学习是否正常,也可以计算训练集每个batch的正确率,监测网络是否正常学习,损失函数的计算在Pytorch已经提供,因此还需要一个计算正确率的函数,下面函数用来统计每个batch中预测正确的个数,进而计算正确率。
def accuracy(Y,y):
Y=Y.argmax(axis=1)
acc_counts=Y.type(y.dtype)==y
return float(acc_counts.type(y.dtype).sum())
2.3.3训练器
def train(net,train_iter,test_iter,num_epochs,lr):
def init(n):
if type(n)==nn.Conv2d or type(n)==nn.Linear:
nn.init.normal(n.weight.data)
net.apply(init)
optimizer =torch.optim.SGD(net.parameters(),lr=lr)
loss=nn.CrossEntropyLoss()
train_loss_list=[]
train_acc_list=[]
for i in range(num_epochs):
for j,(X,y) in enumerate(train_iter):
optimizer.zero_grad()
Y=net(X)
l=loss(Y,y)
l.backward()
optimizer.step()
train_loss_list.append(l.data*X.shape[0]/X.shape[0])
train_acc_list.append(accuracy(Y,y)/X.shape[0])
3.训练模型
有了数据迭代器和训练器,就可以进行简单的训练了,指定epochs=1,lr=0.01
train_iter,test_iter=load_data_fashion_mnist(100)#加载数据
train(net,train_iter,test_iter,1,0.01)#开始训练
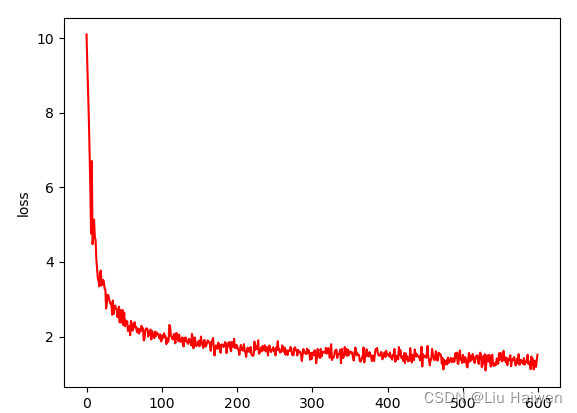
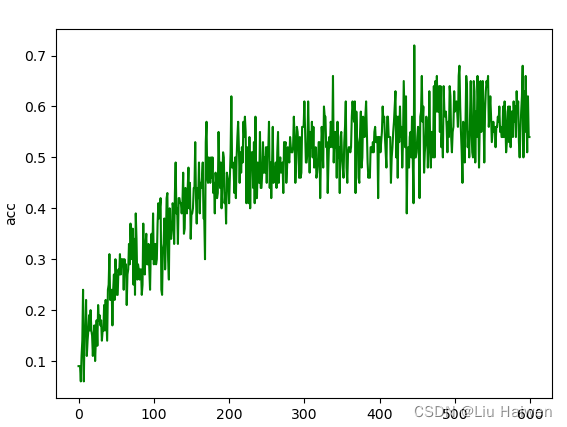
画出损失函数和正确率随训练次数的变化图:
plt.plot(train_loss_list,label='loss',color='r')
plt.show()
plt.plot(train_acc_list,label='acc',color='g')
plt.show()
结果如下:
损失函数变化情况:
正确率变化情况:
4.总结
本文首先对LeNet-5网络结构做了简单分析,然后用pytorch搭建了该网络,同时实现了数据迭代器和一个简单的训练器并对MNIST数据集做了简单训练,观察了训练过程中损失函数以及正确率的的变化情况达到了预期效果。但训练器比较简陋,后面将会着重对训练器进行改进。