简介
在前面介绍的线性回归还有逻辑回归它们都是知道x,y然后开始训练模型,这也就是有监督学习的情况,还有如果只是知道x不知道y的情况那么这种就是无监督学习。
描述
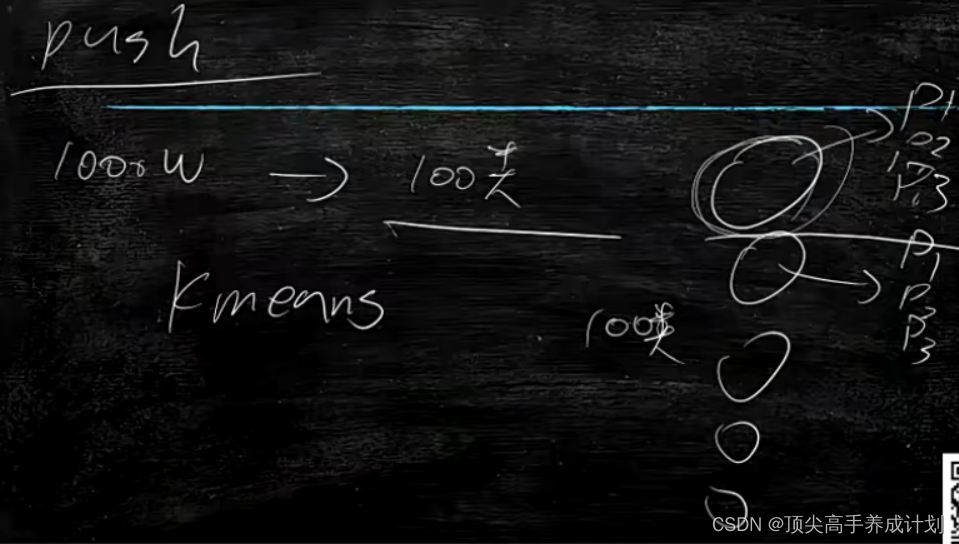
需求引入,如果有一千万用户,我们要对用户进行分类。这里由于没有标注y,也就是只知道x的情况然后进行分类,典型的无监督学习。

示例
下面打一个比方,对于不同的数据k=2表示要分2个类,那么我们可以随机的取两个中心点,然后不同的x对于到c1和c2中心点的距离,距离小那么就属于哪个区域,打个比方,如果x1到c1的距离小于到c2的距离,那么x1就属于c1。
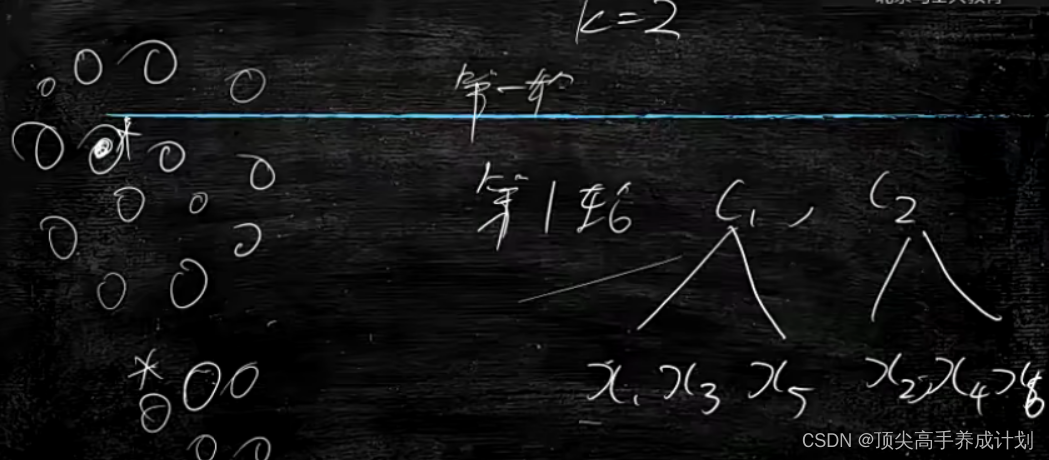
在得到第一轮随机的分类以后要想分类越准那么就需要根据分类出来的数据进行求出真实的中心点,然后在不断的迭代这一个过程。
 代码例子?
代码例子?
# -*- encoding:utf-8 -*-
# from sklearn.datasets.samples_generator import make_blobs
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import math
def cal_distance(v1,v2):
return sum([ math.pow(s1-s2,2) for [s1,s2] in zip(v1,v2)])
def cal_cluster_distance(label_X,centers):
center_distance_num=[[0,0] for _ in centers]
for label,x in label_X:
center=centers[label]
d=cal_distance(center,x)
center_distance_num[label][0]+=d
center_distance_num[label][1]+=1
d=sum([ sum_distance/num for [sum_distance,num] in center_distance_num])
return d
def find_clusters_num(X,max_num,min_num):
k_inner={}
#从k=2遍历到k=10
for k in range(min_num,max_num+1):
model=KMeans(n_clusters=k)
model.fit(X)
y_pred = model.predict(X)
label_X=zip(y_pred,X)
centers=model.cluster_centers_.tolist()
inner=cal_cluster_distance(label_X,centers)
k_inner[k]=inner
max_delta_distance=-1
max_delta_k=-1
for k in range(min_num,max_num):
d=k_inner[k]-k_inner[k+1]
if d>max_delta_distance:
max_delta_distance=d
max_delta_k=k+1
return max_delta_k
# X为样本特征,Y为样本簇类别,共1000个样本,每个样本2个特征,对应x和y轴,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2])
#X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1]],cluster_std=[0.4, 0.2, 0.2])
# k=find_clusters_num(X,10,2)
# print (k)
#分成多少类
model=KMeans(n_clusters=2)
model.fit(X)
y_pred = model.predict(X)
print (y_pred)
输出结果,可以看到,由于上面代码设置了k等于2,那么就被分出了2类。

聚类问题
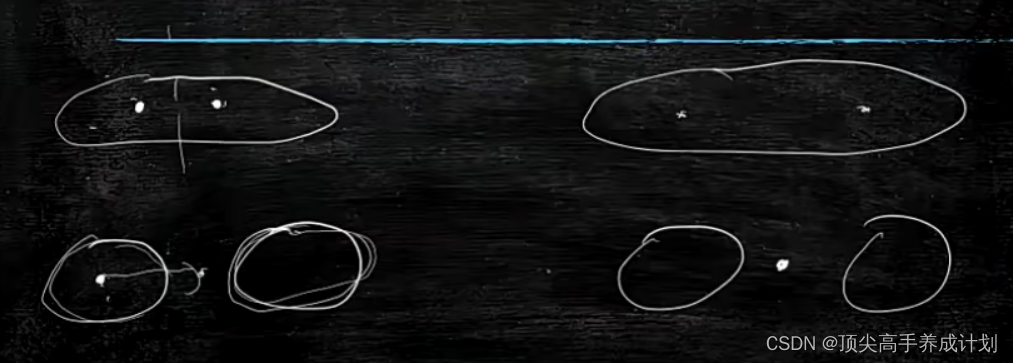
如果中心点选择正确,那么结果也会正确的被分类。

问题一
如果中心点选择错误,如下,误差就挺大。
解决办法
如果想解决这个问题,那么就要不断的求中心点的最小距离和。但是计算量又太大。

问题二?
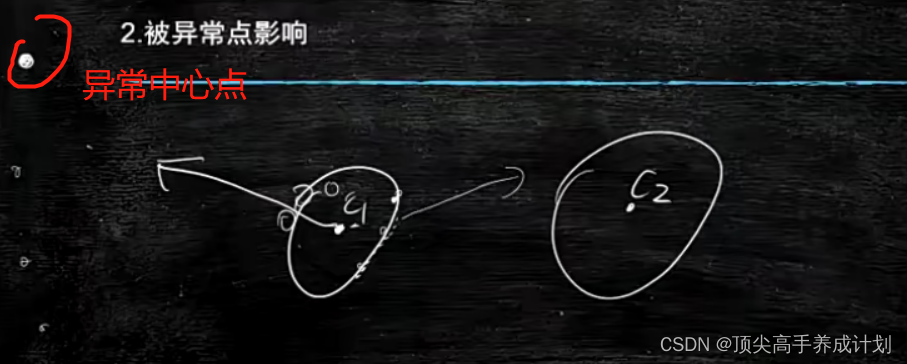
异常点的影响 ,也就是如果第一次随机的中心点取到一个异常的点,那么最后的结果就会被影响?,那么这种情况就是计算的时候,还要不断的去除异常点。
问题三
k不好选择,Inner表示内聚程度,?下图是k和Inner的关系图。

Kmeas的缺点?
缺点就是有极端的情况的时候,多个类别他们是在同一个中心点。
 ????????
????????
实际应用
推荐打标签
推荐用户打标签,下面就是如果有1000万用户,用kmeans算法分为100个类,然后每一个类取离中心点最近的点,然后人为的为用户打标签。