1ЁЂBPЩёОЭјТчЕБжа ЫљЬсЕНЕФЗКЛЏФмСІЪЧжИЪВУД?
ОЭЪЧЭтЭЦЕФФмСІЁЃ
КмЖрЪБКђбЕСЗЕФЭјТчЖдгкбЕСЗЕФЪ§ОнФмКмКУЕФФтКЯ,ЕЋЪЧЖдгкВЛдкбЕСЗМЏФкЕФЪ§ОнФтКЯОЭКмВюЧПШЫвтСЫЁЃетжжЧщПіОЭНаЗКЛЏФмСІ----ВюЁЃвВОЭЪЧЫЕПЩФмФуЕФЭјТчДцдкЙ§ФтКЯЕФЯжЯѓЁЃ
ЙШИшШЫЙЄжЧФмаДзїЯюФП:аЁЗЂУЈ

2ЁЂbpЩёОЭјТчЬсИпЗКЛЏФмСІ?гаМИжжЗНЗЈ?
ГЃЙцЕФМИжждіЧПЗКЛЏФмСІЕФЗНЗЈ,ТоСаШчЯТ:1ЁЂНЯЖрЕФЪфШыбљБОПЩвдЬсИпЗКЛЏФмСІ;
ЕЋВЛЪЧЬЋЖр,Й§ЖрЕФбљБОЕМжТЙ§ЖШФтКЯ,ЗКЛЏФмСІВЛМб;бљБОАќРЈжСЩйвЛДЮЕФзЊелЕуЪ§ОнЩёОЭјТчЗКЛЏЕФФмСІЁЃ
2ЁЂвўКЌВуЩёОдЊЪ§СПЕФбЁдё,ВЛгАЯьадФмЕФЧАЬсЯТ,ОЁСПбЁдёаЁвЛЕуЕФЩёОдЊЪ§СПЁЃвўКЌВуНкЕуЬЋЖр,дьГЩЗКЛЏФмСІЯТНЕ,дьЛ№М§вВжЛвЊМИЪЎИіЕНМИАйИіЩёОдЊ,ФтКЯМИАйМИЧЇИіЪ§ОнКЮБивЊФЧУДЖрЩёОдЊ?
3ЁЂЮѓВюаЁ,дђЗКЛЏФмСІКУ;ЮѓВюЬЋаЁ,дђЛсЙ§ЖШФтКЯ,ЗКЛЏФмСІЗДЖјВЛМбЁЃ
4ЁЂбЇЯАТЪЕФбЁдё,ЬиБ№ЪЧШЈжЕбЇЯАТЪ,ЖдЭјТчадФмгаКмДѓгАЯь,ЬЋаЁдђЪеСВЫйЖШКмТ§,ЧвШнвзЯнШыОжВПМЋаЁЛЏ;ЬЋДѓдђ,ЪеСВЫйЖШПь,ЕЋвзГіЯжАкЖЏ,ЮѓВюФбвдЫѕаЁ;вЛАуШЈжЕбЇЯАТЪБШвЊЧѓЮѓВюЩдЮЂЩдДѓвЛЕуЕу;СэЭтПЩвдЪЙгУБфЖЏЕФбЇЯАТЪ,дкЮѓВюДѓЕФЪБКђдіДѓбЇЯАТЪ,ЕШЮѓВюаЁСЫдйМѕаЁбЇЯАТЪ,етбљПЩвдЪеСВИќПь,бЇЯАаЇЙћИќКУ,ВЛвзЯнШыОжВПМЋаЁЛЏЁЃ
5ЁЂбЕСЗЪБПЩвдВЩгУЫцЪБжежЙЗЈ,МДЪЧЮѓВюДяЕНвЊЧѓМДжежЙбЕСЗ,вдУтЙ§ЖШФтКЯ;ПЩвдЕїећОжВПШЈжЕ,ЪЙОжВПЮДЪеСВЕФМгПьЪеСВЁЃ
3ЁЂЩёОЭјТчбЇЯАбљБОдНЖр,ЗКЛЏФмСІдНЧП?
ЪЧЕФЁЃ
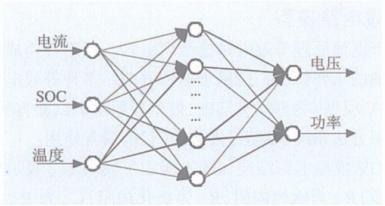
ЙЙИДдгадКЭбљБОИДдгад:ЩёОЭјТчЕФШнСПвдМАЙцФЃГЦжЎЮЊЩёОЭјТчЕФНсЙЙИДдгад,бљБОИДдгадЪЧбЕСЗФГвЛЙЬЖЈНсЙЙЩёОЭјТчЫљашЕФбљБОЪ§ФПЁЃ
бљБОжЪСПЪЧбЕСЗбљБОЗжВМЗДгГзмЬхЗжВМЕФГЬЖШ,ЛђепЫЕгЩећИібЕСЗбљБОМЏЬсЙЉЕФаХЯЂСПЁЃбљБОжЪСППЩвдЧПСвЕигАЯьЩёОЭјТчЕФЗКЛЏФмСІ,ИФНјбЕСЗбљБОжЪСП,вВЪЧИФЩЦЩёОЭјТчЗКЛЏФмСІЕФвЛжжживЊЗНЗЈЁЃ
РЉеЙзЪСЯ:
зЂвтЪТЯю:
гЩгкбЇЯАЫйТЪЪЧЙЬЖЈЕФ,вђДЫЭјТчЕФЪеСВЫйЖШТ§,ашвЊНЯГЄЕФбЕСЗЪБМфЁЃЖдгквЛаЉИДдгЮЪЬт,BPЫуЗЈашвЊЕФбЕСЗЪБМфПЩФмЗЧГЃГЄ,етжївЊЪЧгЩгкбЇЯАЫйТЪЬЋаЁдьГЩЕФ,ПЩВЩгУБфЛЏЕФбЇЯАЫйТЪЛђздЪЪгІЕФбЇЯАЫйТЪМгвдИФНјЁЃ
BPЫуЗЈПЩвдЪЙШЈжЕЪеСВЕНФГИіжЕ,ЕЋВЂВЛБЃжЄЦфЮЊЮѓВюЦНУцЕФШЋОжзюаЁжЕ,етЪЧвђЮЊВЩгУЬнЖШЯТНЕЗЈПЩФмВњЩњвЛИіОжВПзюаЁжЕЁЃЖдгкетИіЮЪЬт,ПЩвдВЩгУИНМгЖЏСПЗЈРДНтОіЁЃ
ВЮПМзЪСЯРДдД:
ВЮПМзЪСЯРДдД:
4ЁЂгаФФаЉЪжЖЮПЩвдЬсЩ§ЩюЖШЩёОЭјТчЕФЗКЛЏадФм
ШЫЙЄЩёОЭјТчвдЦфжЧФмадМћГЄ,ФЧУДЩёОЭјТчФмецЕФбЇЕНвЛИігГЩфЕФБОжЪТ№?вВОЭЪЧЫЕ,ЖдвЛИігГЩфИјГівЛЖЈЕФБивЊЕФбЕСЗбљБОбЕСЗКѓ,ЭјТчФмЗёЖдбљБОвдЭтЕФбљБОИјГіНЯЮЊзМШЗЕФдЄВтЁЃЗКЛЏФмСІвВОЭЪЧЩёОЭјТчгУгкЖдЮДжЊЪ§ОндЄВтЕФФмСІЁЃЩёОЭјТчЖдбЕСЗбљБОЧјМфЗЖЮЇФкЕФбљБОгаНЯКУЕФЗКЛЏФмСІ,ЖјЖдгкбЕСЗбљБОШЗЖЈЕФЗЖЮЇЭтЕФбљБОВЛФмШЯЮЊгаЗКЛЏФмСІЁЃГЃЙцЕФМИжждіЧПЗКЛЏФмСІЕФЗНЗЈ,ТоСаШчЯТ:
5ЁЂBPЩёОЭјТч ЗКЛЏФмСІжИЪВУД?ЭјТчЗТецОпЬхЪВУДвтЫМ?ЮЊЪВУДНјааЗТец?
3.ЭјТчФЃаЭЩшМЦгаЮЪЬт,ашвЊTry
Error
and
Try
4.ПЩвдЪЙгУTrainbr(БДвЖЫЙе§дђЛЏбЕСЗКЏЪ§),етИіКЏЪ§ЖдЭјТчЕФЗКЛЏФмСІБШНЯКУ
6ЁЂЩёОЭјТч,бЕСЗбљБО500Ьѕ,ЮЊЪВУДБШбЕСЗбљБО6000Ьѕ,бЕСЗЭъ,500ЬѕдЄВтБШ6000ЬѕбљБОКУ!
ВЂЗЧбЕСЗбљБОдНЖрдНКУ,вђПЮЬтЖјвьЁЃ 1ЁЂбљБОзюЙиМќдкгке§ШЗадКЭзМШЗадЁЃФуЫљбЁдёЕФбљБОЪзЯШвЊФме§ШЗЗДгГИУЯЕЭГЙ§ГЬЕФФкдкЙцТЩЁЃЮвУЧДгЩњВњЯжГЁВЩЕУЕФбљБОЪ§ОнжагаВЛЩйПЩФмЪЧЛЕбљБО,етбљЕФбљБОЛсИЩШХФуЕФЩёОЭјТчбЕСЗЁЃЭЈГЃЮвУЧШЯЮЊЛЕбљБОжЛЪЧИіБ№ЯжЯѓ,ЫљвдЮвУЧЯЃЭћЭЈЙ§ОЁПЩФмДѓЕФбљБОЙцФЃРДЕжПЙЛЕбљБОдьГЩЕФИКУцгАЯьЁЃ 2ЁЂЦфДЮЪЧбљБОЪ§ОнЗжВМЕФОљКтадЁЃФуЫљбЁдёЕФбљБОзюКУФмЩцМАЕНИУЯЕЭГЙ§ГЬПЩФмЗЂЩњЕФИїжжЧщПі,етбљПЩвдМЋДѓПЩФмЕФееЙЫЕНЯЕЭГдкИїИіЧщПіЯТЕФЙцТЩЬиеїЁЃЭЈГЃЮвУЧЖдЯЕЭГЕФФкдкЙцТЩВЛЪЧКмСЫНт,ЫљвдЮвУЧЯЃЭћЭЈЙ§ОЁПЩФмДѓЕФбљБОЙцФЃРДЁАЕиЬКЪНЁБИВИЧЖдЯѓЯЕЭГЕФЗНЗНУцУцЁЃ 3ЁЂдйДЮОЭЪЧбљБОЪ§ОнЕФЙцФЃ,вВОЭЪЧФувЊЮЪЕФЮЪЬтЁЃдкШЗБЃбљБОЪ§ОнжЪСПКЭЗжВМОљКтЕФЧщПіЯТ,бљБОЪ§ОнЕФЙцФЃОіЖЈФуЩёОЭјТчбЕСЗНсЙћЕФОЋЖШЁЃбљБОЪ§ОнСПдНДѓ,ОЋЖШдНИпЁЃгЩгкбљБОЙцФЃжБНггАЯьМЦЫуЛњЕФдЫЫуЪБМф,ЫљвддкОЋЖШЗћКЯвЊЧѓЕФЧщПіЯТ,ЮвУЧВЛашвЊЙ§ЖрЕФбљБОЪ§Он,ЗёдђЮвУЧвЊЕШД§КмОУЕФбЕСЗЪБМфЁЃ ВЙГфЫЕУївЛЯТ,ВЛТлЪЧОЖЯђЛљ(rbf)ЩёОЭјТчЛЙЪЧОЕфЕФbpЩёОЭјТч,ЖМжЛЪЧОпЬхЕФбЕСЗЗНЗЈ,ЖдгкзуЙЛЖрДЮЕФЕќДњ,бЕСЗНсЙћЕФзМШЗЖШЪЧЧїгквЛжТЕФ,ЗНЗЈжЛгАЯьМЦЫуЕФЪеСВЫйЖШ(дЫЫуЪБМф),КЭбљБОЙцФЃУЛгажБНгЙиЯЕЁЃ
ШчКЮШЗЖЈКЮЪБбЕСЗМЏЕФДѓаЁЪЧЁАзуЙЛДѓЁБЕФ?
ЩёОЭјТчЕФЗКЛЏФмСІжївЊШЁОігк3ИівђЫи:
1.бЕСЗМЏЕФДѓаЁ
2.ЭјТчЕФМмЙЙ
3.ЮЪЬтЕФИДдгГЬЖШ
вЛЕЉЭјТчЕФМмЙЙШЗЖЈСЫвдКѓ,ЗКЛЏФмСІШЁОігкЪЧЗёгаГфзуЕФбЕСЗМЏЁЃКЯЪЪЕФбЕСЗбљБОЪ§СППЩвдЪЙгУWidrowЕФФДжИЙцдђРДЙРМЦЁЃ ФДжИЙцдђжИГі,ЮЊСЫЕУЕНвЛИіНЯКУЕФЗКЛЏФмСІ,ЮвУЧашвЊТњзувдЯТЬѕМў(Widrow and Stearns,1985;Haykin,2008): N = nw / e Цфжа,NЮЊбЕСЗбљБОЪ§СП,nwЪЧЭјТчжаЭЛДЅШЈжиЕФЪ§СП,eЪЧВтЪддЪаэЕФЭјТчЮѓВюЁЃ вђДЫ,МйШчЮвУЧдЪаэ10%ЕФЮѓВю,ЮвУЧашвЊЕФбЕСЗбљБОЕФЪ§СПДѓдМЪЧЭјТчжаШЈжиЪ§СПЕФ10БЖЁЃ
7ЁЂBPЩёОЭјТчЕФЗКЛЏФмСІШчКЮЬсИп?
вРЪщЩЯЫљЫЕ:
1.ЬсЧАЭЃжЙЗЈЁЃ
2.ЙщвЛЛЏЁЃ
ОпЬхФуОЭgoogleвЛЯТЁЃ
8ЁЂЭЈГЃЫЕВтЪдBPЩёОЭјТчЕФФтКЯФмСІКЭВтЪдЗКЛЏФмСІгаУЛгавЛбљ?ЛЙЪЧСНепвЛбљ,жЛЪЧЫЕЗЈВЛЭЌ 20
ВтЪдBPЩёОЭјТчЕФФтКЯФмСІКЭЗКЛЏФмСІ,АДетжжЫЕЗЈЪЧЭЌвЛИХФю,ЕЋЪЧФтКЯКЭЗКЛЏдкЦфЫќСьгђЪЧЭъШЋВЛЭЌЕФ,етИівЊЧјЗжЧхГўЁЃВтЪдвЛИіЩёОЭјТчЕФФтКЯФмСІ,етжжЫЕЗЈКмЩйгУ,ДѓМвОГЃгУЕФЪЧВтЪдЩёОЭјТчЕФЗКЛЏФмСІЁЃ
9ЁЂЩёОЭјТчбЕСЗбљБОдНЖрЪЧВЛЪЧЗКЛЏФмСІдНКУ?
етИіУЛгаУїШЗвЊЧѓ,бљБОвВВЛЪЧдНЖрдНКУЁЃЭЈГЃЧщПіЯТ,ФуЕФбљБОПЩвдвЛВПЗжгУРДзібщжЄЁЃМгЫйФуга100ИібљБО,90%гУРДзібЕСЗ,10%гУРДзібщжЄЕШ,ЕБШЛ,гаЪБКђЛЙЕУСєЯТ10%зіВтЪдгУЁЃЮвИіШЫЕФОбщЪЧ,бљБОЪ§ОЁСПдк10вдЩЯАЩЁЃ