���ر�Ҷ˹�㷨
1 ���ر�Ҷ˹����
���ر�Ҷ˹��һ�ַ����㷨,�����������ı�����,������������ij����������ij�����ĸ��ʡ�
2 ��Ҷ˹��ʽ
���ʻ�����ϰ
- ���ϸ���:�����������,����������ͬʱ�����ĸ���
- ����:
P(A,B)- ��������:�����¼�A������һ���¼�B�Ѿ����������µķ�������
- ����:
P(A|B)- �����:���
P(A, B) = P(A)P(B),����¼�A���¼�B�����

����ͨ��һ������ �� �ж�Ů������ϲ����� �� �����������ʽ
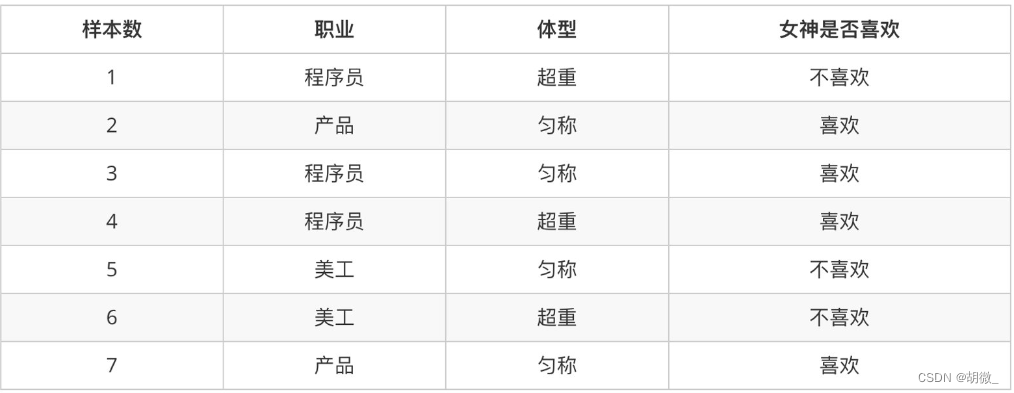
��������:
Ů��ϲ���ĸ���?
ְҵ�dz���Ա���������ȳƵĸ���?
��Ů��ϲ����������,ְҵ�dz���Ա�ĸ���?
��Ů��ϲ����������,ְҵ�dz���Ա�����س��صĸ���?
������Ϊ:
P(ϲ��) = 4/7
P(����Ա, �ȳ�) = 1/7(���ϸ���)
P(����Ա|ϲ��) = 2/4 = 1/2(��������)
P(����Ա, ����|ϲ��) = 1/4
˼����:
- ��С���Dz�Ʒ�����������س��ص������,��μ���С����Ů��ϲ���ĸ���?
��P(ϲ��|��Ʒ, ����) = ?
��ʱ������Ҫ�õ����ر�Ҷ˹������⡣
��ô˼����Ϳ������ñ�Ҷ˹��ʽ���������:
P(ϲ��|��Ʒ, ����) = P(��Ʒ, ����|ϲ��)P(ϲ��)/P(��Ʒ, ����)
������ʽ���Է���:
P(��Ʒ, ����|ϲ��)��P(��Ʒ, ����)�Ľ����Ϊ0,��������������������Ϊ���ǵ�������̫����,�����д����ԡ�- ������ʵ������,�϶��Ǵ���ְҵ�Dz�Ʒ�����������س��ص��˵�,P(��Ʒ, ����)������Ϊ0;
- �����¼�
ְҵ�Dz�Ʒ�������¼����س���ͨ������Ϊ����������¼�,����,������������7����������P(��Ʒ, ����) = P(��Ʒ)P(����)��������
�����ر�Ҷ˹���������ǽ���������:
- ���ر�Ҷ˹,������,���Ǽٶ�������������֮��������ı�Ҷ˹��ʽ��
- Ҳ����˵,���ر�Ҷ˹,֮��������,�����ڼٶ��������������������
����,˼��������������ر�Ҷ˹��˼·�����,�Ϳ�����
P(��Ʒ, ����) = P(��Ʒ) * P(����) = 2/7 * 3/7 = 6/49
p(��Ʒ, ����|ϲ��) = P(��Ʒ|ϲ��) * P(����|ϲ��) = 1/2 * 1/4 = 1/8
P(ϲ��|��Ʒ, ����) = P(��Ʒ, ����|ϲ��)P(ϲ��)/P(��Ʒ, ����) = 1/8 * 4/7 / 6/49 = 7/12
3 ������˹ƽ��ϵ��
��Ҷ˹��ʽ���Ӧ�������·����ij�������,���ǿ���������:
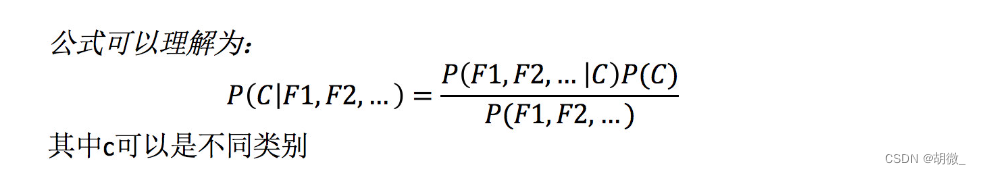

����ͨ��һ��������������
����:ͨ��ǰ�ĸ�ѵ������(����),�жϵ���ƪ����,�Ƿ�����China��
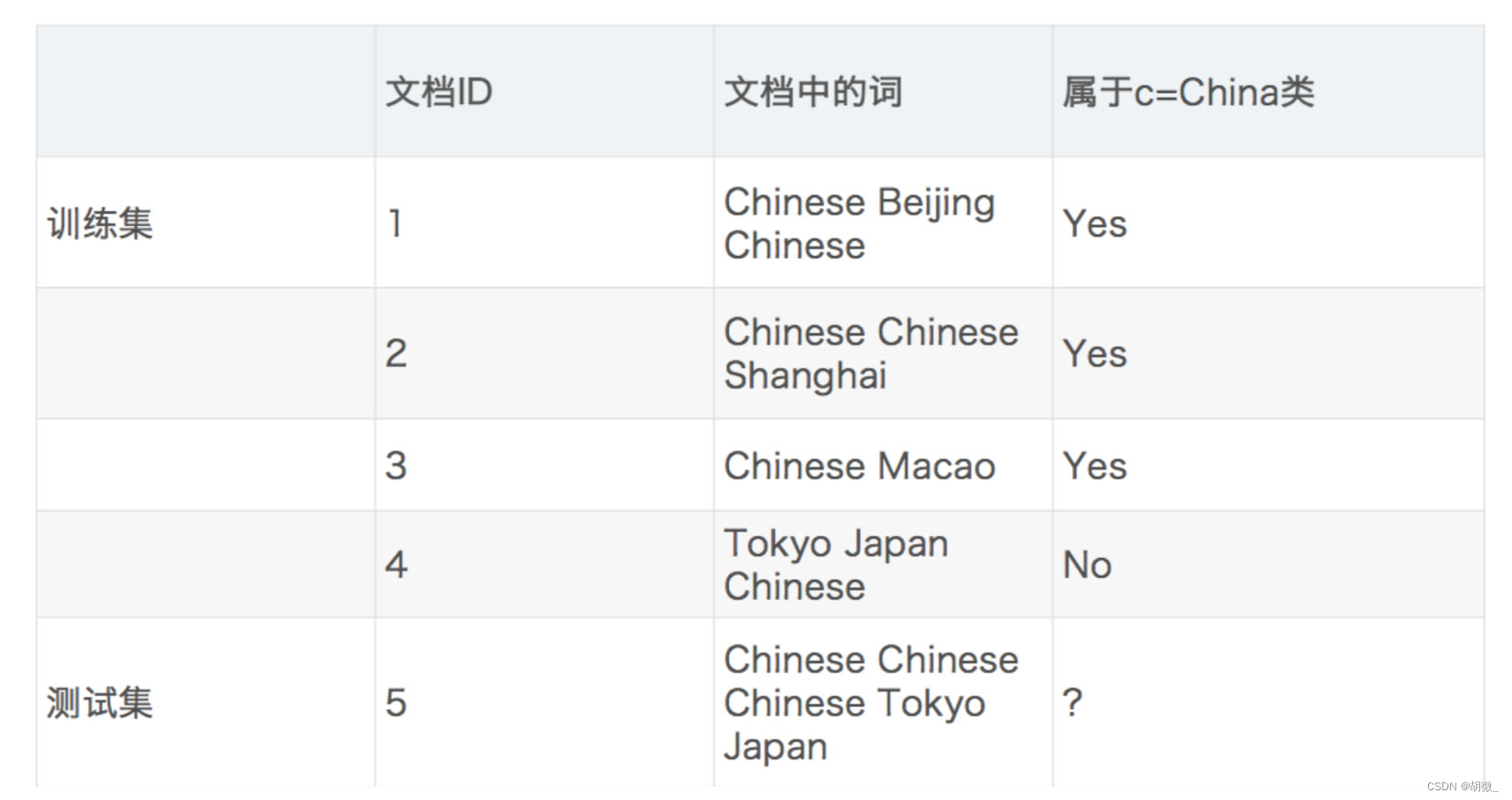
P(C|Chinese, Chinese, Chinese, Tokyo, Japan)
= P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P(C) / P(Chinese, Chinese, Chinese, Tokyo, Japan)
= P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C) * P(C) / [P(Chinese)^3 * P(Tokyo) * P(Japan)]
# �����������Ҫ�����Dz���China��,�ǻ��߲������ķ�ĸֵ����ͬ:
# ���ȼ�����China��ĸ���:
P(Chinese|C) = 5/8
P(Tokyo|C) = 0/8
P(Japan|C) = 0/8
# ���ż��㲻��China��ĸ���:
P(Chinese|C) = 1/3
P(Tokyo|C) = 1/3
P(Japan|C) = 1/3
����:��������������ǿ��Եõ� P(Tokyo|C) �� P(Japan|C)��Ϊ0,���Dz�������,�����Ƶ�б������кܶ������Ϊ0,�ܿ��ܼ�������Ϊ0��
����취:������˹ƽ��ϵ��

# �����������Ҫ�����Dz���China��:
# ������,m=6(ѵ�����������ʵĸ���,�ظ�����)
���ȼ�����China��ĸ���:
P(Chinese|C) = 5/8 --> 6/14
P(Tokyo|C) = 0/8 --> 1/14
P(Japan|C) = 0/8 --> 1/14
���ż��㲻��China��ĸ���:
P(Chinese|C) = 1/3 --> 2/9
P(Tokyo|C) = 1/3 --> 2/9
P(Japan|C) = 1/3 --> 2/9
4 ���ر�Ҷ˹apiʹ��
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- ���ر�Ҷ˹����
alpha:������˹ƽ��ϵ��
���ر�Ҷ˹Ӧ�ð��� ���� ��Ʒ������з���
5 ���ر�Ҷ˹�㷨�ܽ�
5.1 ���ر�Ҷ˹��ȱ��
(1)�ŵ�
- ���ر�Ҷ˹ģ�ͷ�Դ�ڹŵ���ѧ����,���ȶ��ķ���Ч��
- ��ȱʧ���ݲ�̫����,�㷨Ҳ�Ƚϼ�,�������ı�����
- ����ȷ�ȸ�,�ٶȿ�
(2)ȱ��
- ����ʹ�����������Զ����Եļ���,����������������й���ʱ��Ч������
- ��Ҫ�����������,��������ʺܶ�ʱ��ȡ���ڼ���,�����ģ�Ϳ����кܶ���,�����ijЩʱ������ڼ��������ģ�͵�ԭ����Ԥ��Ч������;
- �������:ֱ������,��ν���ȡ�,����������֮ǰ,�������鷢��֮ǰ���鷢���ĸ��ʡ��Ǹ�����������ͷ����õ��ĸ���,�������������
- �������:�����Ѿ�������,���鷢�������кܶ�ԭ��,�ж����鷢��ʱ���ĸ�ԭ������ĸ���,���ɹ�����
- ������ʾ���ͨ��˵�ĸ���,���������һ����������,���������ʲ�һ���������ʡ���Ҷ˹��ʽ������������������ʵĹ�ʽ
5.2 ���ر�Ҷ˹���ѵ�
(1)���ر�Ҷ˹ԭ��
���ر�Ҷ˹���ǻ��ڱ�Ҷ˹����������������������ķ������
- ���ڸ����Ĵ�������x,ͨ��ѧϰ����ģ�ͼ��������ʷֲ�,
- ��:�ڴ�����ֵ������¸���Ŀ�������ֵĸ���,�����������������Ϊx���������
(2)���ر�Ҷ˹����������?
�ڼ����������ʷֲ� P(X=x�OY=c_k) ʱ,NB������һ����ǿ��������������,��,��Yȷ��ʱ,X�ĸ�����������ȡֵ֮���������
(3)Ϊʲô�������������Լ���?
Ϊ�˱��ⱴҶ˹�������ʱ���ٵ���ϱ�ը������ϡ�����⡣
�����������ʷ�Ϊ:

(4)�ڹ�����������P(X�OY)ʱ���ָ���Ϊ0�������ô��?
�����һ����ķ����Dz��ñ�Ҷ˹���ơ�
����˵,�����,
- ����=0ʱ,������ͨ�ļ�����Ȼ����;
- ����=1ʱ��Ϊ������˹ƽ����
(5)Ϊʲô���Զ����Լ�����ʵ������к��ѳ���,�����ر�Ҷ˹����ȡ�ýϺõ�Ч��?
- ������ʹ�÷�����֮ǰ,�������ĵ�һ��(Ҳ������Ҫ��һ��)����������ѡ��,������̵�Ŀ�ľ���Ϊ���ų�����֮��Ĺ����ԡ�ѡ����Խ�Ϊ����������;
- ���ڷ���������˵,ֻҪ��������������������ȷ,���辫����ֵ�Ϳ��Եó���ȷ����;
- ������Լ��������������Ӱ����ͬ,��������ϵ��Ӱ���������,���������������Լ����ڽ��ͼ��㸴�Ӷȵ�ͬʱ��������ܲ�������Ӱ�졣
5.3 �����ع������
(1)����һ:
���ر�Ҷ˹������ģ��
- ���������������б�Ҷ˹����ѧϰ���������P(Y)����������P(X|Y),
- ����������Ϸֲ�����P(XY),
- ������ñ�Ҷ˹�������P(Y|X),
��LR���б�ģ��
- ���ݼ�������Ȼ����ֱ�������������P(Y|X);
(2)�����:
- ���ر�Ҷ˹�ǻ��ں�ǿ��������������(����֪����Y��������,������������ȡֵ���������),
- ��LR��Դ�û��Ҫ��
(3)������:
- ���ر�Ҷ˹���������ݼ��ٵ��龰,
- ��LR�����ڴ��ģ���ݼ���
�б�ʽģ��������ģ��
