
目录
2. 自定义隐藏层层数和每个隐藏层中的神经元个数,尝试找到最优超参数完成多分类。(选做)
4. 尝试基于MNIST手写数字识别数据集,设计合适的前馈神经网络进行实验,并取得95%以上的准确率。(选做)
深入研究鸢尾花数据集
画出数据集中150个数据的前两个特征的散点分布图:
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据集
df = pd.read_csv('Iris.csv', usecols=[1, 2, 3, 4, 5])
# pandas打印表格信息
# print(df.info())
# pandas查看数据集的头5条记录
# print(df.head())
"""绘制训练集基本散点图,便于人工分析,观察数据集的线性可分性"""
# 表示绘制图形的画板尺寸为8*5
plt.figure(figsize=(8, 5))
# 散点图的x坐标、y坐标、标签
plt.scatter(df[:50]['SepalLengthCm'], df[:50]['SepalWidthCm'], label='Iris-setosa')
plt.scatter(df[50:100]['SepalLengthCm'], df[50:100]['SepalWidthCm'], label='Iris-versicolor')
plt.scatter(df[100:150]['SepalLengthCm'], df[100:150]['SepalWidthCm'], label='Iris-virginica')
plt.xlabel('SepalLengthCm')
plt.ylabel('SepalWidthCm')
# 添加标题 '鸢尾花萼片的长度与宽度的散点分布'
plt.title('Scattered distribution of length and width of iris sepals.')
# 显示标签
plt.legend()
plt.show()

4.5 实践:基于前馈神经网络完成鸢尾花分类
继续使用第三章中的鸢尾花分类任务,将Softmax分类器替换为前馈神经网络。
损失函数:交叉熵损失;
优化器:随机梯度下降法;
评价指标:准确率。
4.5.1 小批量梯度下降法
在梯度下降法中,目标函数是整个训练集上的风险函数,这种方式称为批量梯度下降法(Batch Gradient Descent,BGD)。 批量梯度下降法在每次迭代时需要计算每个样本上损失函数的梯度并求和。当训练集中的样本数量NN很大时,空间复杂度比较高,每次迭代的计算开销也很大。
为了减少每次迭代的计算复杂度,我们可以在每次迭代时只采集一小部分样本,计算在这组样本上损失函数的梯度并更新参数,这种优化方式称为小批量梯度下降法(Mini-Batch Gradient Descent,Mini-Batch GD)。
 ?4.5.1.1 数据分组
?4.5.1.1 数据分组
为了小批量梯度下降法,我们需要对数据进行随机分组。目前,机器学习中通常做法是构建一个数据迭代器,每个迭代过程中从全部数据集中获取一批指定数量的数据。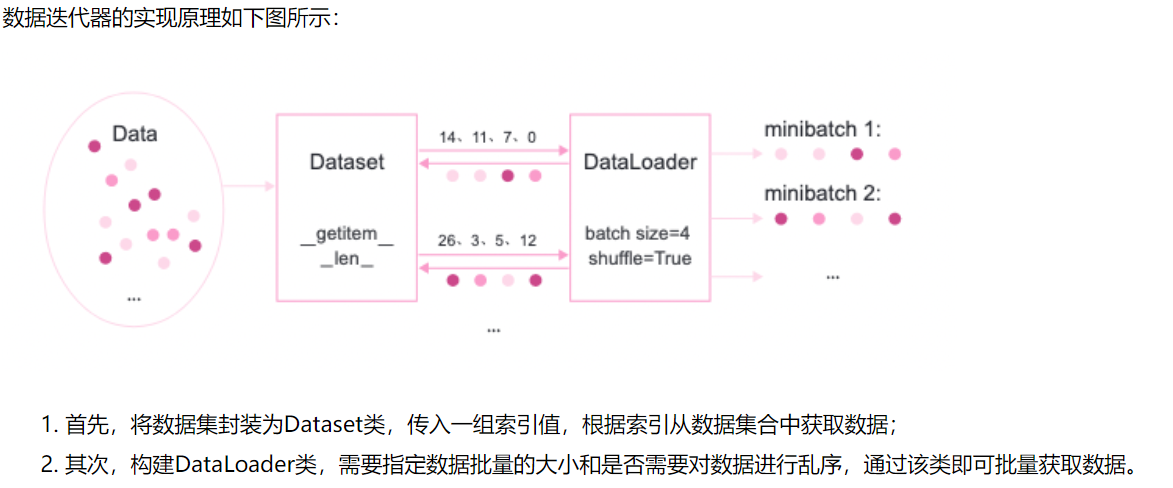
4.5.2 数据处理
import numpy as np
import torch
import torch.utils.data as data
from dataset import load_data
class IrisDataset(data.Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
# 调用第三章中的数据读取函数,其中不需要将标签转成one-hot类型
X, y = load_data(shuffle=True)
if mode == 'train':
self.X, self.y = X[:num_train], y[:num_train]
elif mode == 'dev':
self.X, self.y = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.X, self.y = X[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
def __len__(self):
return len(self.y)
torch.random.manual_seed(12)
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
# 打印训练集长度
print ("length of train set: ", len(train_dataset))
得到以下结果:
length of train set: 120?4.5.2.2 用DataLoader进行封装
# 批量大小
batch_size = 16
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=0)
dev_loader = torch.utils.data.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)4.5.3 模型构建
输入层神经元个数为4,输出层神经元个数为3,隐含层神经元个数为6。

from torch import nn
# 定义前馈神经网络
class Model_MLP_L2_V3(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Model_MLP_L2_V3, self).__init__()
# 构建第一个全连接层
self.fc1 = nn.Linear(input_size,hidden_size)
nn.init.normal_(tensor=self.fc1.weight,mean=0.0, std=0.01)
nn.init.constant_(tensor=self.fc1.bias,val=1.0)
# 构建第二全连接层
self.fc2 = nn.Linear(hidden_size,output_size)
nn.init.normal_(tensor=self.fc2.weight,mean=0.0, std=0.01)
nn.init.constant_(tensor=self.fc2.bias,val=1.0)
# 定义网络使用的激活函数
self.act = nn.Sigmoid()
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
return outputs
fnn_model = Model_MLP_L2_V3(input_size=4, output_size=3, hidden_size=6)4.5.4 完善Runner类
基于RunnerV2类进行完善实现了RunnerV3类。其中训练过程使用自动梯度计算,使用DataLoader加载批量数据,使用随机梯度下降法进行参数优化;模型保存时,使用state_dict方法获取模型参数;模型加载时,使用set_state_dict方法加载模型参数.
由于这里使用随机梯度下降法对参数优化,所以数据以批次的形式输入到模型中进行训练,那么评价指标计算也是分别在每个批次进行的,要想获得每个epoch整体的评价结果,需要对历史评价结果进行累积。这里定义Accuracy类实现该功能。
import torch
class Accuracy():
def __init__(self, is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, dim=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"RunnerV3类的代码实现如下:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
model_state_dict = torch.load(model_path)
self.model.set_state_dict(model_state_dict)4.5.5 模型训练
实例化RunnerV3类,并传入训练配置,代码实现如下:
import torch.optim as opt
import torch.nn.functional as F
lr = 0.2
# 定义网络
model = fnn_model
# 定义优化器
optimizer = opt.SGD(lr=lr, params=model.parameters())
# 定义损失函数。softmax+交叉熵
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
runner = RunnerV3(model, optimizer, loss_fn, metric)使用训练集和验证集进行模型训练,共训练150个epoch。在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
# 启动训练
log_steps = 100
eval_steps = 50
runner.train(train_loader, dev_loader,
num_epochs=150, log_steps=log_steps, eval_steps = eval_steps,
save_path="best_model.pdparams") 得到以下结果:
[Train] epoch: 0/150, step: 0/1200, loss: 1.09898
[Evaluate] dev score: 0.33333, dev loss: 1.09582
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.33333
[Train] epoch: 12/150, step: 100/1200, loss: 1.13891
[Evaluate] dev score: 0.46667, dev loss: 1.10749
[Evaluate] best accuracy performence has been updated: 0.33333 --> 0.46667
[Evaluate] dev score: 0.20000, dev loss: 1.10089
[Train] epoch: 25/150, step: 200/1200, loss: 1.10158
[Evaluate] dev score: 0.20000, dev loss: 1.12477
[Evaluate] dev score: 0.46667, dev loss: 1.09090
[Train] epoch: 37/150, step: 300/1200, loss: 1.09982
[Evaluate] dev score: 0.46667, dev loss: 1.07537
[Evaluate] dev score: 0.53333, dev loss: 1.04453
[Evaluate] best accuracy performence has been updated: 0.46667 --> 0.53333
[Train] epoch: 50/150, step: 400/1200, loss: 1.01054
[Evaluate] dev score: 1.00000, dev loss: 1.00635
[Evaluate] best accuracy performence has been updated: 0.53333 --> 1.00000
[Evaluate] dev score: 0.86667, dev loss: 0.86850
[Train] epoch: 62/150, step: 500/1200, loss: 0.63702
[Evaluate] dev score: 0.80000, dev loss: 0.66986
[Evaluate] dev score: 0.86667, dev loss: 0.57089
[Train] epoch: 75/150, step: 600/1200, loss: 0.56490
[Evaluate] dev score: 0.93333, dev loss: 0.52392
[Evaluate] dev score: 0.86667, dev loss: 0.45410
[Train] epoch: 87/150, step: 700/1200, loss: 0.41929
[Evaluate] dev score: 0.86667, dev loss: 0.46156
[Evaluate] dev score: 0.93333, dev loss: 0.41593
[Train] epoch: 100/150, step: 800/1200, loss: 0.41047
[Evaluate] dev score: 0.93333, dev loss: 0.40600
[Evaluate] dev score: 0.93333, dev loss: 0.37672
[Train] epoch: 112/150, step: 900/1200, loss: 0.42777
[Evaluate] dev score: 0.93333, dev loss: 0.34534
[Evaluate] dev score: 0.93333, dev loss: 0.33552
[Train] epoch: 125/150, step: 1000/1200, loss: 0.30734
[Evaluate] dev score: 0.93333, dev loss: 0.31958
[Evaluate] dev score: 0.93333, dev loss: 0.32091
[Train] epoch: 137/150, step: 1100/1200, loss: 0.28321
[Evaluate] dev score: 0.93333, dev loss: 0.28383
[Evaluate] dev score: 0.93333, dev loss: 0.27171
[Evaluate] dev score: 0.93333, dev loss: 0.25447
[Train] Training done!
可视化观察训练集损失和训练集loss变化情况。
import matplotlib.pyplot as plt
# 绘制训练集和验证集的损失变化以及验证集上的准确率变化曲线
def plot_training_loss_acc(runner, fig_name,
fig_size=(16, 6),
sample_step=20,
loss_legend_loc="upper right",
acc_legend_loc="lower right",
train_color="#8E004D",
dev_color='#E20079',
fontsize='x-large',
train_linestyle="-",
dev_linestyle='--'):
plt.figure(figsize=fig_size)
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::sample_step]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color=train_color, linestyle=train_linestyle, label="Train loss")
if len(runner.dev_losses) > 0:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color=dev_color, linestyle=dev_linestyle, label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize=fontsize)
plt.xlabel("step", fontsize=fontsize)
plt.legend(loc=loss_legend_loc, fontsize=fontsize)
# 绘制评价准确率变化曲线
if len(runner.dev_scores) > 0:
plt.subplot(1, 2, 2)
plt.plot(dev_steps, runner.dev_scores,
color=dev_color, linestyle=dev_linestyle, label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize=fontsize)
plt.xlabel("step", fontsize=fontsize)
plt.legend(loc=acc_legend_loc, fontsize=fontsize)
plt.savefig(fig_name)
plt.show()
plot_training_loss_acc(runner, 'fw-loss.pdf')?
?从输出结果可以看出准确率随着迭代次数增加逐渐上升,损失函数下降。
4.5.6 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及Loss情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
得到以下结果:?
[Test] accuracy/loss: 1.0000/0.2396
4.5.7 模型预测
同样地,也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。代码实现如下:
test_loader = iter(test_loader)
# 获取测试集中第一条数据
(X, label) = next(test_loader)
logits = runner.predict(X)
pred_class = torch.argmax(logits[0]).numpy()
label = label.numpy()[0]
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))得到以下结果:?
The true category is 2 and the predicted category is 2
思考题
1. 对比Softmax分类和前馈神经网络分类。(必做)
? Softmax分类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
iris = datasets.load_iris() # 加载数据
list(iris.keys()) # ['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module']
X = iris["data"][:, 0:]
y = (iris["target"] == 2).astype(np.int32) # 标签,是维吉尼亚鸢尾花y就是1,否则为0
log_reg = LogisticRegression(solver="lbfgs", random_state=42)
log_reg.fit(X, y) # 训练模型
X = iris["data"][:, (0, 1)]
y = iris["target"]
# 设置超参数multi_class为"multinomial",指定一个支持Softmax回归的求解器,默认使用l2正则化,可以通过超参数C进行控制
softmax_reg = LogisticRegression(multi_class="multinomial", solver="lbfgs", C=10, random_state=42)
softmax_reg.fit(X, y)
softmax_reg.predict([[5, 2]]) # 输出:array([2])
softmax_reg.predict_proba([[5, 2]])
# 输出:array([[6.38014896e-07, 5.74929995e-02, 9.42506362e-01]])
# 分别对应:山鸢尾、变色鸢尾和维吉尼亚鸢尾
x0, x1 = np.meshgrid(
np.linspace(4, 8, 500).reshape(-1, 1),
np.linspace(1.5, 4.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = softmax_reg.predict_proba(X_new)
y_predict = softmax_reg.predict(X_new)
zz1 = y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10,4))
plt.axis([4, 8, 1.5, 4.5])
plt.plot(X[y == 2, 0], X[y == 2, 1], "g^", label="Iris virginica")
plt.plot(X[y == 1, 0], X[y == 1, 1], "bs", label="Iris versicolor")
plt.plot(X[y == 0, 0], X[y == 0, 1], "yo", label="Iris setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#FF0000', '#9898ff', '#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
plt.xlabel("SepalLengthCm", fontsize=14)
plt.ylabel("SepalWidthCm", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.show() 前面的实验也写过softmax分类鸢尾花,这里直接拿图:
前面的实验也写过softmax分类鸢尾花,这里直接拿图:
?
?前馈神经网络的上面已经做过了,这里也直接把图拿过来: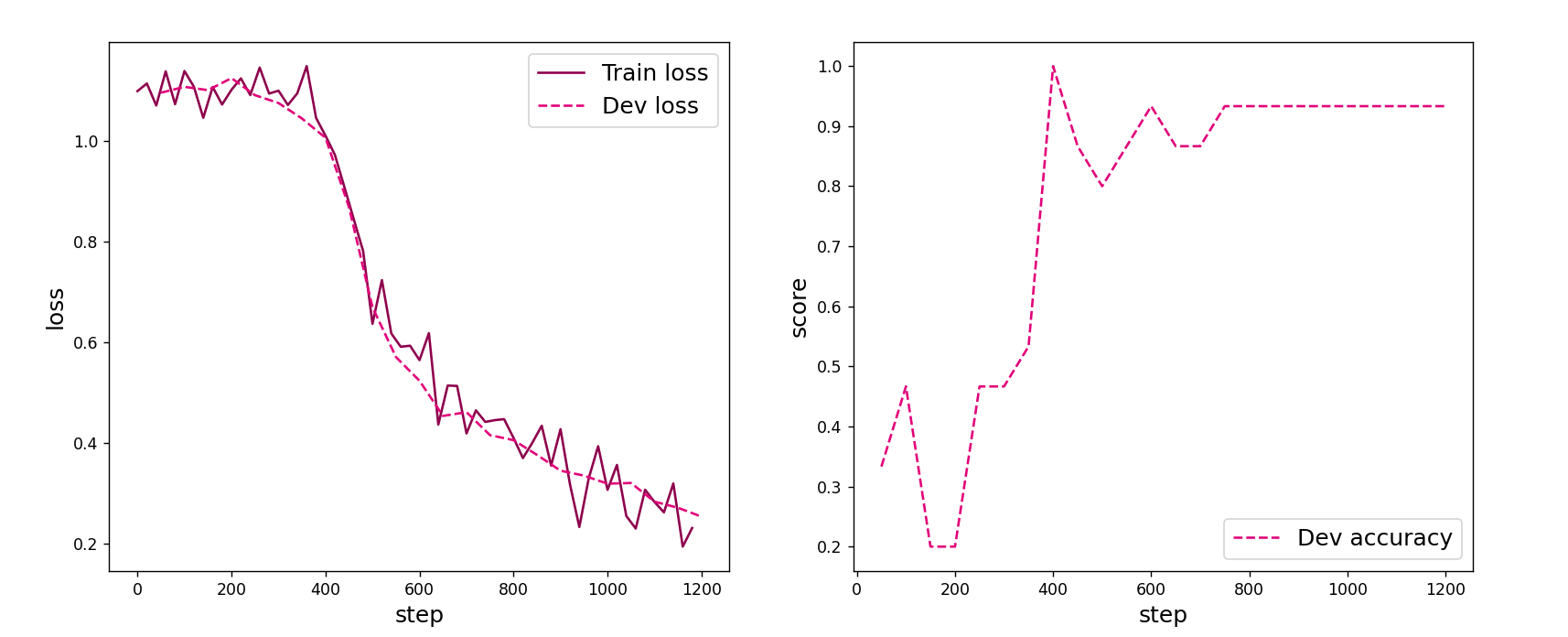
?
?我们可以发现对于鸢尾花数据集的分类,前馈神经网络和softmax的拟合效果都达到了顶端。
而且在原来的实验中还用了SVM对鸢尾花进行了分类,这里我们一块比较一下
精确度: 0.9333333333333333发现无论是哪种方法,对鸢尾花的分类都是比较好用的。
Softmax是一种激活函数,它可以将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出。Softmax层常常和交叉熵损失函数一起结合使用。
对于多分类问题,一种常用的方法是Softmax函数,它可以预测每个类别的概率。对于阿拉伯数字预测问题,选择预测值最高的类别作为结果即可。Softmax的公式如下,其中z是一个向量,zi和zj是其中的一个元素。![]()
?下图中,我们看到,Softmax将一个[2.0,1.0,0.1]的向量转化为了[0.7,0.2,0.1],而且各项之和为1。
Softmax函数可以将上一层的原始数据进行归一化,转化为一个(0,1)之间的数值,这些数值可以被当做概率分布,用来作为多分类的目标预测值。Softmax函数一般作为神经网络的最后一层,接受来自上一层网络的输入值,然后将其转化为概率。?
?总结来说:Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
但Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠。
所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
神经网络的优点是分类的准确度高;并行分布处理能力强,分布存储及学习能力强,对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系;具备联想记忆的功能。
而它的缺点是神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;学习时间过长,甚至可能达不到学习的目的。
2. 自定义隐藏层层数和每个隐藏层中的神经元个数,尝试找到最优超参数完成多分类。(选做)
把学习率调成0.1而神经元还是6个得到以下结果:
[Evaluate] best accuracy performence has been updated: 0.86667 --> 0.93333
[Train] epoch: 137/150, step: 1100/1200, loss: 0.64805
[Evaluate] dev score: 0.86667, dev loss: 0.59557
[Evaluate] dev score: 0.86667, dev loss: 0.55623
[Evaluate] dev score: 0.86667, dev loss: 0.51105
[Test] accuracy/loss: 0.9333/0.5997这个明显比学习率是0.2的时候差太多了,不可取。
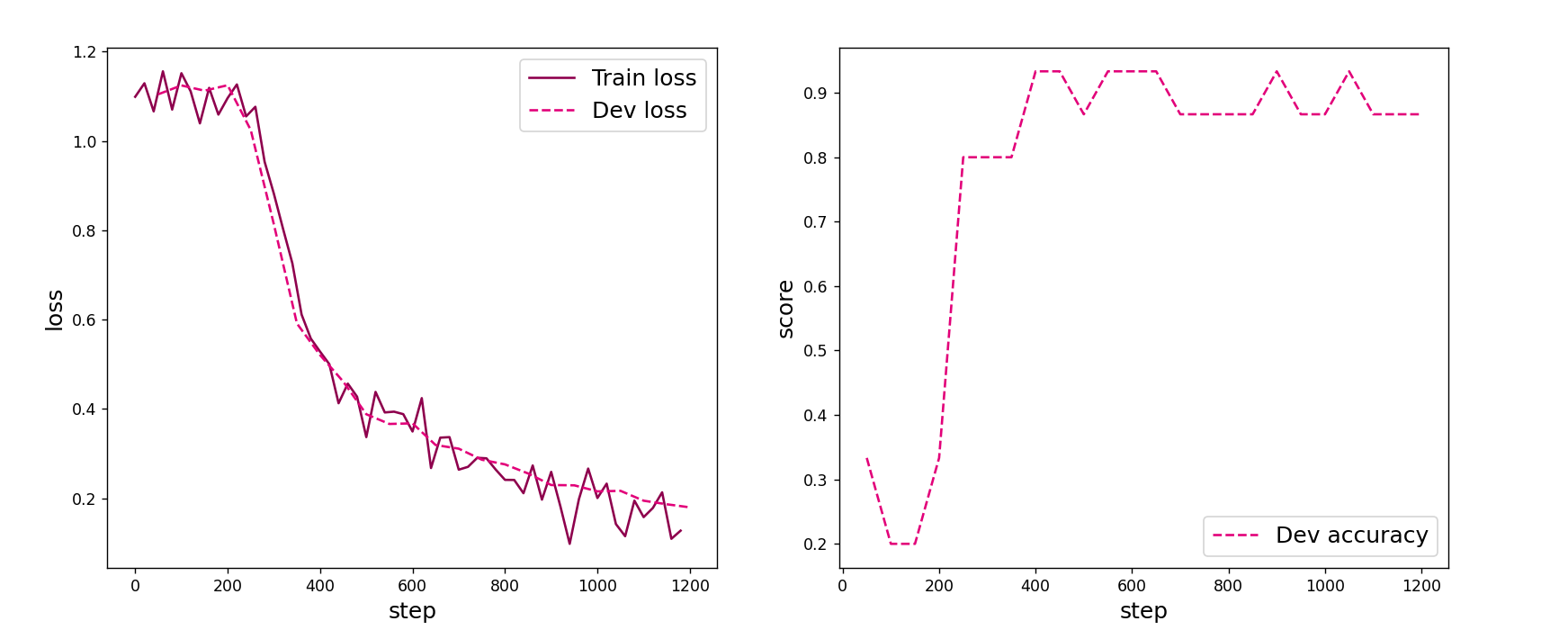
再把学习率lr=0.3得到以下结果:
 ?
?
[Train] epoch: 137/150, step: 1100/1200, loss: 0.15786
[Evaluate] dev score: 0.86667, dev loss: 0.19461
[Evaluate] dev score: 0.86667, dev loss: 0.18664
[Evaluate] dev score: 0.86667, dev loss: 0.17990
[Test] accuracy/loss: 1.0000/0.1292?这个效果要比0.2的时候好一些,那这样再把lr=0.5:
[Train] epoch: 137/150, step: 1100/1200, loss: 0.08099
[Evaluate] dev score: 0.86667, dev loss: 0.14090
[Evaluate] dev score: 0.93333, dev loss: 0.14572
[Evaluate] dev score: 0.93333, dev loss: 0.13878
[Test] accuracy/loss: 1.0000/0.0702?发现效果更好了,但是也差不多到了极限,我们再把神经元改成4个lr=0.5:
[Test] accuracy/loss: 1.0000/0.1161?发现效果不如神经元6个的时候,再把lr=0.2:
[Test] accuracy/loss: 0.9333/0.3155结果更差了,这说明4个神经元不如6个神经元,那我们再把神经元改成8个lr=0.2: ?
?
[Test] accuracy/loss: 1.0000/0.2402?这个效果也不好,再改成lr=0.5
[Test] accuracy/loss: 1.0000/0.0644发现这个效果要好一点,那就把lr=0.6:
[Test] accuracy/loss: 1.0000/0.0550
?lr=0.7:
[Test] accuracy/loss: 1.0000/0.0513
lr=0.8:
[Test] accuracy/loss: 1.0000/0.0523
?发现效果不如lr=0.7了,经过多次测试后,找到了结果,在8个神经元lr=0.7的时候达到了最好的结果
3. 对比SVM与FNN分类效果,谈谈自己看法。(选做)
SVM的分类效果图:
训练集上的正确率为: 94.0 %
测试集上的正确率为: 92.0 %?FNN的分类效果: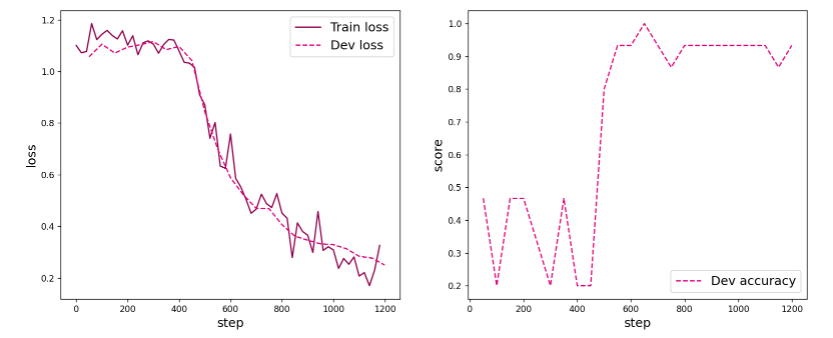
前面也说过了,两者对鸢尾花的分类效果是差不多的,二者在形式上有几分相似,但实际上有很大不同。
简而言之,神经网络是个“黑匣子”,优化目标是基于经验风险最小化,易陷入局部最优,训练结果不太稳定,一般需要大样本;
而支持向量机有严格的理论和数学基础,基于结构风险最小化原则, 泛化能力优于前者,算法具有全局最优性, 是针对小样本统计的理论。
目前来看,虽然二者均为机器学习领域非常流行的方法,但后者在很多方面的应用一般都优于前者。
SVM要求闭球和闭球之间有明显的空白带,同时由于不存在三维以上的基函数,所以支撑向量机最多一次只能处理两个属性(有不同意见的可以回帖,毕竟我也不能保证我的观点就是正确的),这是它的缺点。它的优点是它的分界面比神经元的要更光滑,从而比神经元的精确度要更高。
4. 尝试基于MNIST手写数字识别数据集,设计合适的前馈神经网络进行实验,并取得95%以上的准确率。(选做)
import numpy as np
import torch
import matplotlib.pyplot as plt
from torchvision.datasets import mnist
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
train_batch_size = 64#超参数
test_batch_size = 128#超参数
learning_rate = 0.01#学习率
nums_epoches = 20#训练次数
lr = 0.1#优化器参数
momentum = 0.5#优化器参数
train_dataset = mnist.MNIST('./data', train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transforms.ToTensor(), target_transform=None, download=False)
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
class model(nn.Module):
def __init__(self, in_dim, hidden_1, hidden_2, out_dim):
super(model, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, hidden_1, bias=True), nn.BatchNorm1d(hidden_1))
self.layer2 = nn.Sequential(nn.Linear(hidden_1, hidden_2, bias=True), nn.BatchNorm1d(hidden_2))
self.layer3 = nn.Sequential(nn.Linear(hidden_2, out_dim))
def forward(self, x):
# 注意 F 与 nn 下的激活函数使用起来不一样的
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
#实例化网络
model = model(28*28,300,100,10)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
#momentum:动量因子
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
def train():
# 开始训练 先定义存储损失函数和准确率的数组
losses = []
acces = []
# 测试用
eval_losses = []
eval_acces = []
for epoch in range(nums_epoches):
# 每次训练先清零
train_loss = 0
train_acc = 0
# 将模型设置为训练模式
model.train()
# 动态学习率
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.1
for img, label in train_loader:
# 例如 img=[64,1,28,28] 做完view()后变为[64,1*28*28]=[64,784]
# 把图片数据格式转换成与网络匹配的格式
img = img.view(img.size(0), -1)
# 前向传播,将图片数据传入模型中
# out输出10维,分别是各数字的概率,即每个类别的得分
out = model(img)
# 这里注意参数out是64*10,label是一维的64
loss = criterion(out, label)
# 反向传播
# optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0
optimizer.zero_grad()
loss.backward()
# 这个方法会更新所有的参数,一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率,找到概率最大的下标
_, pred = out.max(1)
num_correct = (pred == label).sum().item() # 记录标签正确的个数
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
eval_loss = 0
eval_acc = 0
model.eval()
for img, label in test_loader:
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
eval_loss += loss.item()
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f},Test Loss:{:.4f},Test Acc:{:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
plt.title('trainloss')
plt.plot(np.arange(len(losses)), losses)
plt.legend(['Train Loss'], loc='upper right')
#测试
def test():
correct = 0
total = 0
y_predict=[]
y_true=[]
with torch.no_grad():
for data in test_loader:
input, target = data
input = input.view(input.size(0), -1)
output = model(input)#输出十个最大值
_, predict = torch.max(output.data, dim=1)#元组取最大值的下表
#
#print('predict:',predict)
total += target.size(0)
correct += (predict == target).sum().item()
y_predict.extend(predict.tolist())
y_true.extend(target.tolist())
print('正确率:', correct / total)
print('correct=', correct)
train()
test()
得到以下结果:
epoch:0,Train Loss:0.3498,Train Acc:0.9175,Test Loss:0.1283,Test Acc:0.9615
epoch:1,Train Loss:0.1283,Train Acc:0.9650,Test Loss:0.0824,Test Acc:0.9764
epoch:2,Train Loss:0.0881,Train Acc:0.9752,Test Loss:0.0628,Test Acc:0.9827
epoch:3,Train Loss:0.0665,Train Acc:0.9818,Test Loss:0.0503,Test Acc:0.9858
epoch:4,Train Loss:0.0535,Train Acc:0.9854,Test Loss:0.0416,Test Acc:0.9890
epoch:5,Train Loss:0.0368,Train Acc:0.9914,Test Loss:0.0259,Test Acc:0.9948
epoch:6,Train Loss:0.0338,Train Acc:0.9921,Test Loss:0.0255,Test Acc:0.9953
epoch:7,Train Loss:0.0321,Train Acc:0.9934,Test Loss:0.0250,Test Acc:0.9948
epoch:8,Train Loss:0.0307,Train Acc:0.9931,Test Loss:0.0245,Test Acc:0.9955
epoch:9,Train Loss:0.0299,Train Acc:0.9937,Test Loss:0.0240,Test Acc:0.9955
epoch:10,Train Loss:0.0280,Train Acc:0.9943,Test Loss:0.0239,Test Acc:0.9955
epoch:11,Train Loss:0.0289,Train Acc:0.9940,Test Loss:0.0241,Test Acc:0.9955
epoch:12,Train Loss:0.0282,Train Acc:0.9943,Test Loss:0.0235,Test Acc:0.9963
epoch:13,Train Loss:0.0278,Train Acc:0.9947,Test Loss:0.0237,Test Acc:0.9963
epoch:14,Train Loss:0.0279,Train Acc:0.9944,Test Loss:0.0235,Test Acc:0.9960
epoch:15,Train Loss:0.0276,Train Acc:0.9945,Test Loss:0.0233,Test Acc:0.9957
epoch:16,Train Loss:0.0268,Train Acc:0.9948,Test Loss:0.0238,Test Acc:0.9962
epoch:17,Train Loss:0.0270,Train Acc:0.9950,Test Loss:0.0240,Test Acc:0.9960
epoch:18,Train Loss:0.0277,Train Acc:0.9947,Test Loss:0.0233,Test Acc:0.9960
epoch:19,Train Loss:0.0271,Train Acc:0.9946,Test Loss:0.0238,Test Acc:0.9959
正确率: 0.9959
correct= 9959
[[ 979 0 0 0 0 0 0 1 0 0]
[ 0 1132 0 0 0 0 2 0 1 0]
[ 0 0 1030 0 0 0 0 2 0 0]
[ 0 0 0 1008 0 1 0 1 0 0]
[ 0 0 1 0 979 0 1 0 0 1]
[ 2 0 0 0 0 888 1 0 0 1]
[ 3 2 0 0 1 2 950 0 0 0]
[ 0 3 1 1 0 0 0 1021 0 2]
[ 0 0 0 2 0 0 0 0 972 0]
[ 2 1 0 1 2 1 0 2 0 1000]]
进程已结束,退出代码为 0
正确率达到0.9959,已经超过了老师要求的95%
总结
这次的实验是用前馈神经网络对iris进行分类,而在做这次实验之前,已经做过了SVM和softmax对iris的分类,所以正好可以很方便的对这三种方法对iris分类进行对比。在这次的实验中,我也搜查过很多资料,虽然softmax对鸢尾花进行分类看上去和前馈神经网络的效果差不多,但是因为他是一个线性分类,所以对于螺旋形状的数据集是不能很好的分类的。而后面对FNN进行参数的调试也发现其实在结果趋近于顶峰的时候,再对超参数进行微调得到的效果也很一般了。最后进行mnist数据集的分类也达到了99.59%的超高正确率,上学期用tensorflow对mnist分类得到的效果也没有这么好。
 参考文献:
参考文献: