提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
我的前面博客有吴恩达深度学习进行情感二分类分析的案例,建议看一下,讲的比较基础。这篇博客数据预处理时用到的一些函数在那篇博客讲过,这里就不再赘述。
一、LSTM是什么?
LSTM它是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
LSTM 已经在科技领域有了多种应用。基于 LSTM 的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。今天我们用它来实现一下文本多分类,相信会取得较好的效果。
二、数据处理
1数据集
2.加载数据集
import pandas as pd
df = pd.read_csv('E:/数据集/online_shopping_10_cats/online_shopping_10_cats.csv')
df=df[['cat','review']]
print("数据总量: %d ." % len(df))
df.sample(10)

3.数据预处理
1.查看、去除缺失值
print("在 cat 列中总共有 %d 个空值." % df['cat'].isnull().sum())
print("在 review 列中总共有 %d 个空值." % df['review'].isnull().sum())
df = df.dropna()# 去除空值
2. 将汉字标签转换为数字
factorize函数
# pandas 的factorize函数,将Series中的标称型数据映射称为一组数字,相同的标称型映射为相同的数字。例上
df['cat_id'] = df['cat'].factorize()[0] #将种类标签映射为数字
# 去除重复行。drop = True 表示去除原来index,然后重置index。否则则是保留index,添加新的index
# 下面是构建cat与id的对应关系
cat_id_df = df[['cat', 'cat_id']].drop_duplicates().sort_values('cat_id').reset_index(drop=True)
cat_to_id = dict(cat_id_df.values)
id_to_cat = dict(cat_id_df[['cat_id', 'cat']].values)
df.sample(10)
3.去除标点符号,再进行分词,再去除停用词
import re
#定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):
line = str(line)
if line.strip()=='':
return ''
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")# 括号中是需要被替换的
line = rule.sub('',line)
#sub(replacement, string, count=0)
#replacement是被替换成的文本
#string是需要被替换的文本
#count是一个可选参数,指最大被替换的数量
return line
def stopwordslist(filepath):
# strip 是去除空格,这里是去除每一行的停用词。
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
#加载停用词
stopwords = stopwordslist("E:/数据集/停用词/中文停用词.txt")
# 删除多余字符
df['clean_review'] = df['review'].apply(remove_punctuation)
import jieba as jb
#分词,并过滤停用词
# jb.cut 分词,
df['cut_review'] = df['clean_review'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df.sample(10)
4.文本数据转换为向量
这里用到的tokenizer之前吴恩达自然语言处理博客,已经讲过,这里就不再讲了。主要就是用于讲文本转化为数字向量,然后再进行截断和填充到设定的长度。就将一条条评论转化为一个个格式相同向量。
# LSTM 建模
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 设置最频繁使用的50000个词
MAX_NB_WORDS = 50000
# 每条cut_review最大的长度
MAX_SEQUENCE_LENGTH = 250
# 设置Embeddingceng层的维度
EMBEDDING_DIM = 100
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~', lower=True)
tokenizer.fit_on_texts(df['cut_review'].values)
word_index = tokenizer.word_index
print('共有 %s 个不相同的词语.' % len(word_index))
X = tokenizer.texts_to_sequences(df['cut_review'].values)
#填充X,让X的各个列的长度统一
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
#多类标签的onehot展开
Y = pd.get_dummies(df['cat_id']).values
print(X.shape)
print(Y.shape)
三、 LSTM建模
1 划分数据集
from sklearn.model_selection import train_test_split
#拆分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.10, random_state = 42)
print(X_train.shape,Y_train.shape)
print(X_test.shape,Y_test.shape)
2 LSTM模型
SpatialDropout1D
SpatialDropout1D与Dropout的作用类似,但它断开的是整个1D特征图,而不是单个神经元。如果一张特征图的相邻像素之间有很强的相关性(通常发生在低层的卷积层中),那么普通的dropout无法正则化其输出,否则就会导致明显的学习率下降。这种情况下,SpatialDropout1D能够帮助提高特征图之间的独立性,应该用其取代普通的Dropout。
#定义模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(MAX_NB_WORDS, EMBEDDING_DIM, input_length=X.shape[1]),
tf.keras.layers.SpatialDropout1D(0.2),
tf.keras.layers.LSTM(40, dropout=0.2, recurrent_dropout=0.2),
tf.keras.layers.Dense(10, activation='sigmoid')
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()

3 模型训练
epochs = 5
batch_size = 64
from keras.callbacks import EarlyStopping# 防止过拟合
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size,validation_split=0.1,
callbacks=[EarlyStopping(monitor='val_loss', patience=3, min_delta=0.001)])
4 预测结构查看
import seaborn as sns
from sklearn.metrics import accuracy_score, confusion_matrix
y_pred = model.predict(X_test)
y_pred = y_pred.argmax(axis = 1)
Y_test = Y_test.argmax(axis = 1)
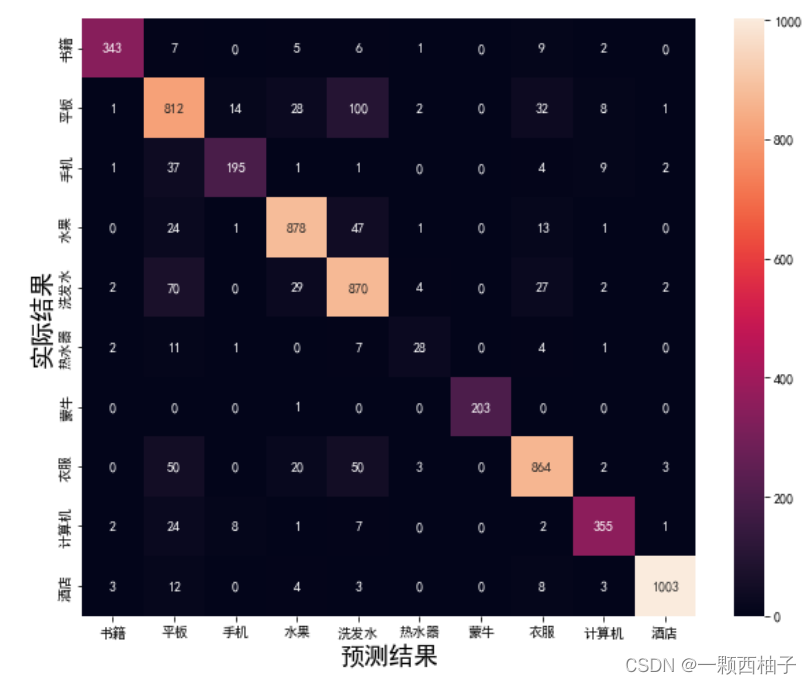
#生成混淆矩阵
conf_mat = confusion_matrix(Y_test, y_pred)
fig, ax = plt.subplots(figsize=(10,8))
sns.heatmap(conf_mat, annot=True, fmt='d',
xticklabels=cat_id_df.cat.values, yticklabels=cat_id_df.cat.values)
plt.ylabel('实际结果',fontsize=18)
plt.xlabel('预测结果',fontsize=18)
发现有很多平板,被预测成了洗发水。比较奇怪
总结
在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。LSTM就是具备了这一特性。