文章目录
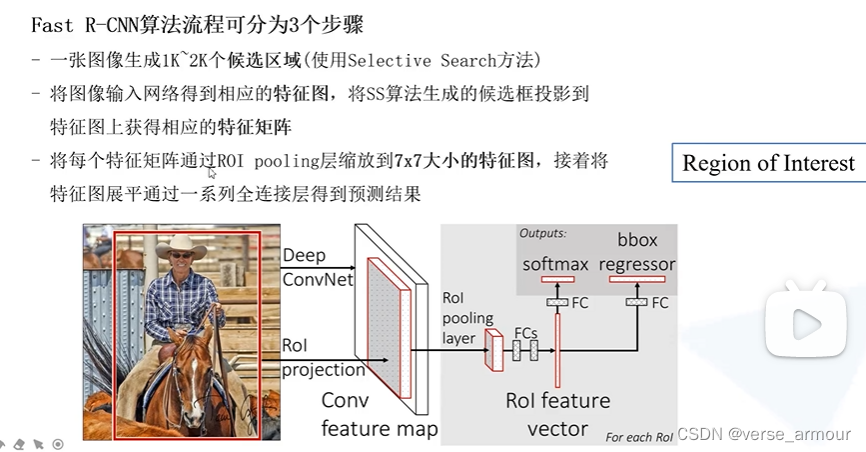
一、Fast R-CNN概述
| Fast R-CNN | R-CNN |
|---|---|
| 直接将整幅图像送入网络得到相应的特征图,将原图上生成的候选区域直接映射到特征图上即可得到我们的特征矩阵 | 将每一个候选区域分别送入网络得到特征向量 |
二、Fast R-CNN如何生成候选框
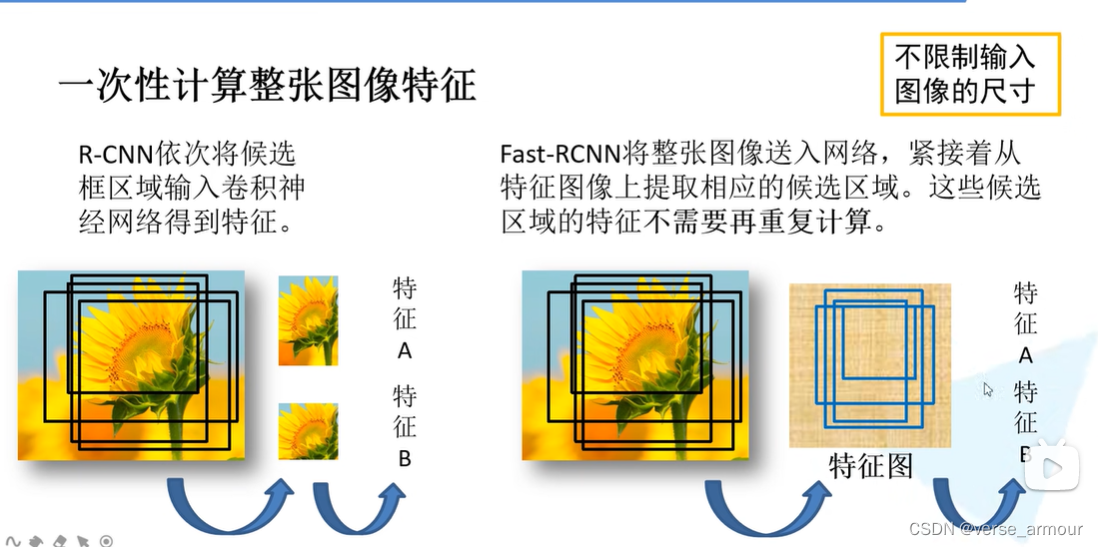
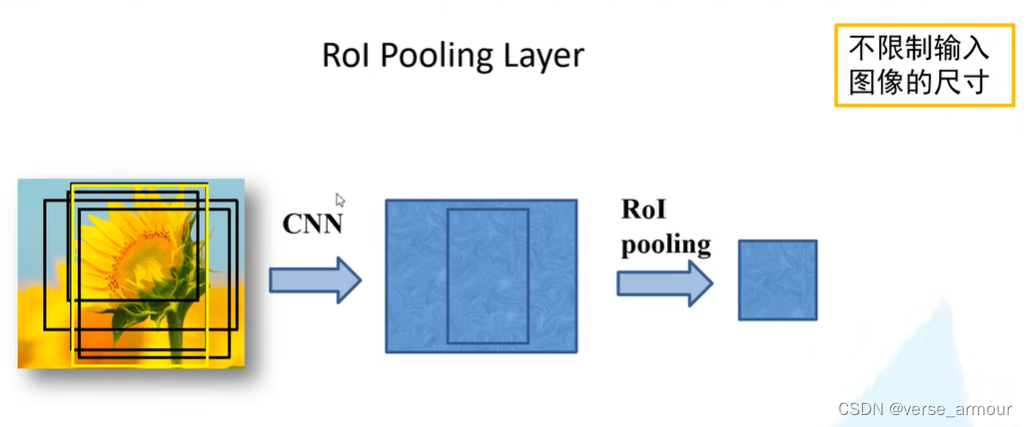
左图是一个候选区域在原图上的对应的一个特征矩阵,它所展示的是一个更抽象的信息,我们是看不懂的。
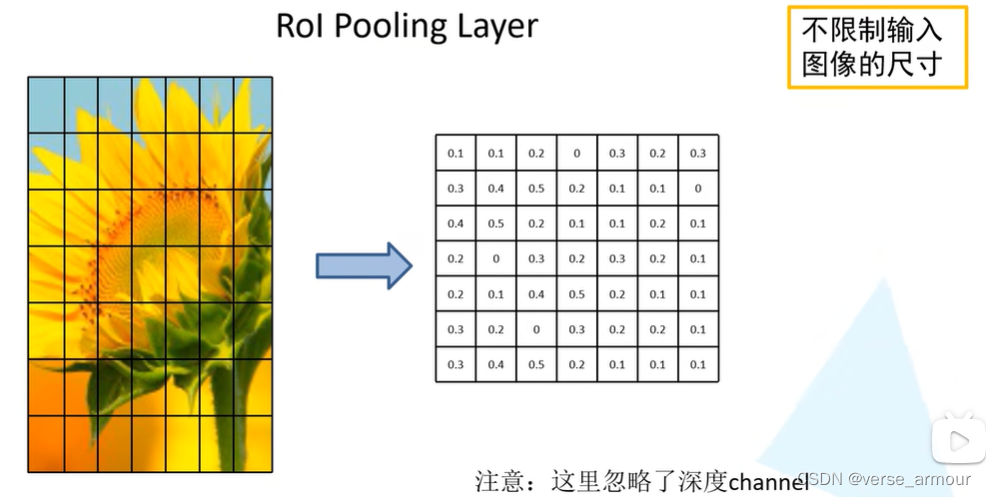
将我们所得到的特征矩阵划分成
7
?
7
=
49
7*7=49
7?7=49等份,对每一个区域执行最大池化下采样(max-pooling)
无论输入的特征矩阵是多大的尺寸,RoI Pooling Layer都会将它缩放到7*7大小
在R-CNN中我们要求输入图像的大小是
227
?
227
227*227
227?227的大小,而在Fast R-CNN中我们就不需要对输入图像的尺寸进行限制。
三、CNN
通过RoI Pooling Layer得到RoI feature,然后进行展平处理,通过两个全连接层得到RoI feature vector。
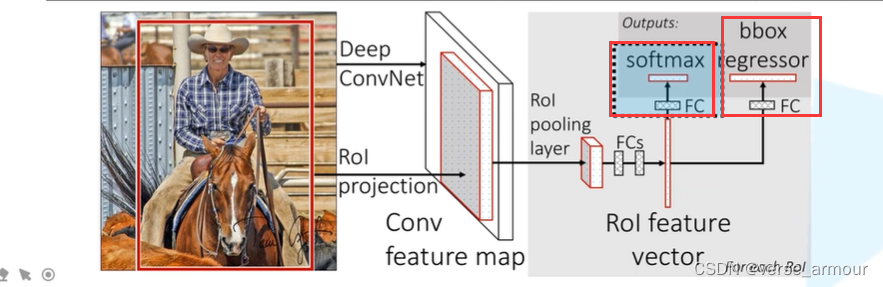
(1)关于目标概率的分类器
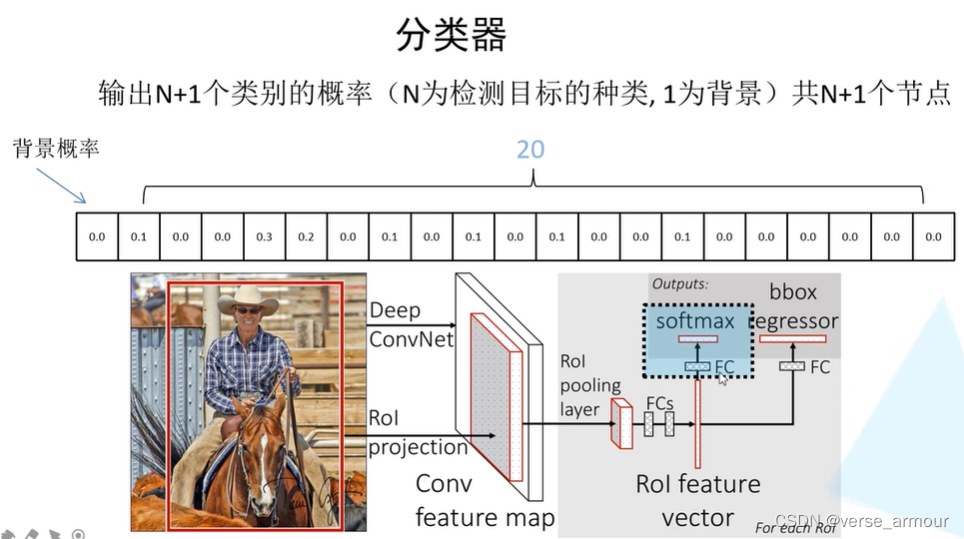
这里的目标概率满足概率分布,和为1
(2)边界框回归器
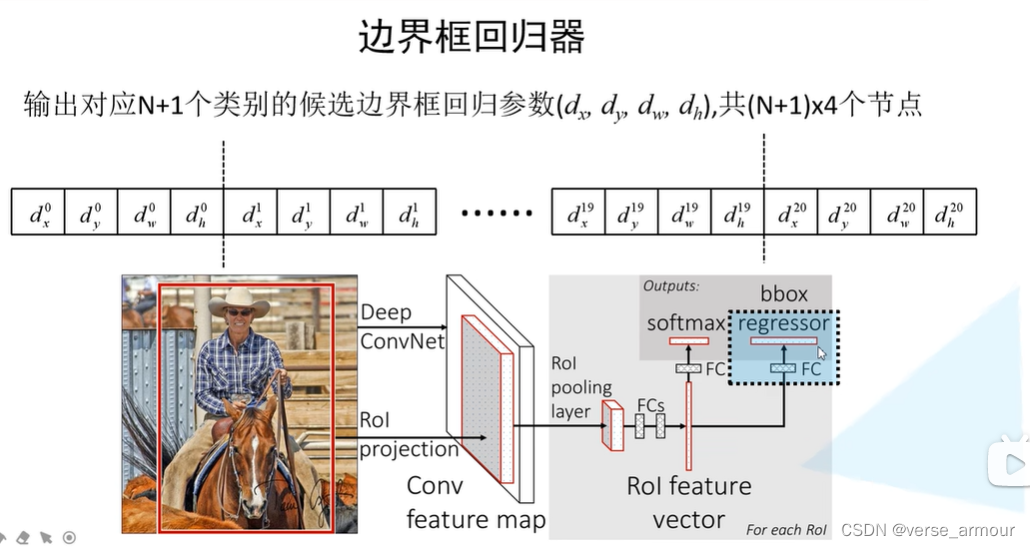
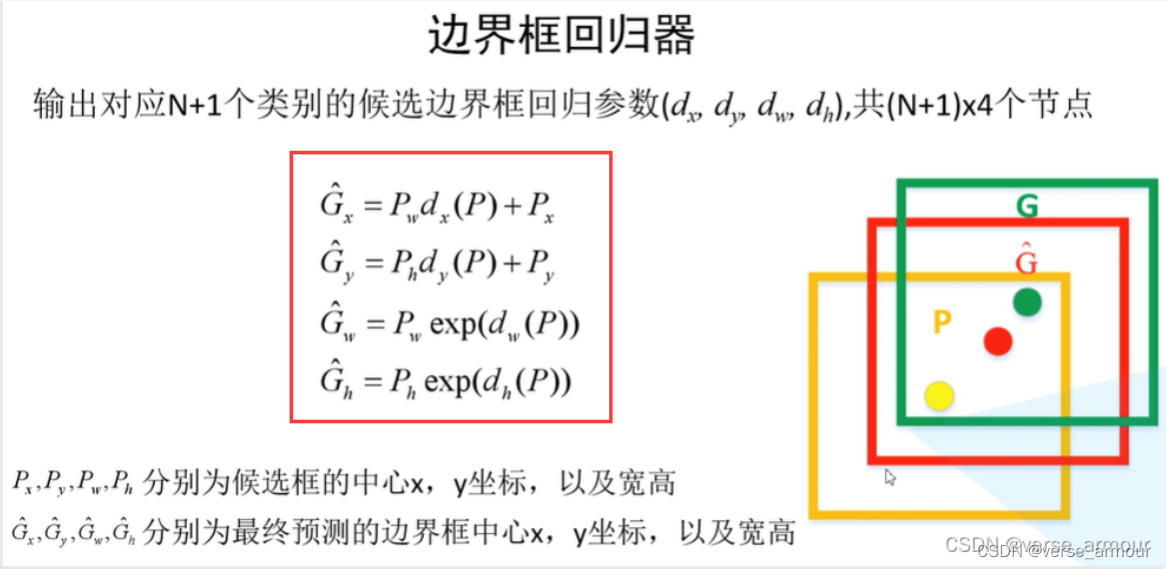
我们是如何通过我们得到的回归参数确定我们最终的边界框?

(3)如何计算Fast R-CNN的损失

关于v对应真实目标的边界框回归参数
(
v
x
,
v
y
,
v
w
,
v
h
)
(v_x,v_y,v_w,v_h)
(vx?,vy?,vw?,vh?):
是通过以下预测函数求函数得到的
Bounding Box Regression超详解(全站最全汇总版)综合各个途径文档 看这一篇就够了 解决你所有疑惑
1.分类损失


推导:


举例:假设真实标签的one-hot编码是:[0,0,…,1,…,0]
预测的softmax概率是[0.1,0.3,…,0.4,…,0.1]
Loss = -log(0.4)
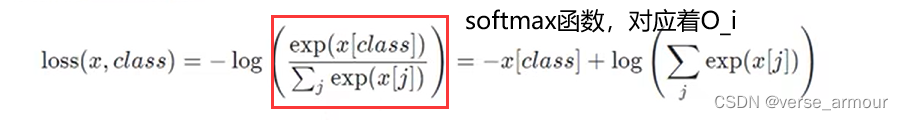
2.回归损失

- 关于
L
l
o
c
(
t
u
,
v
)
L_{loc}(t^u,v)
Lloc?(tu,v)及
s
m
o
o
t
h
L
1
(
t
i
u
?
v
i
)
smooth_{L_{1}}(t_i^{u}-v_i)
smoothL1??(tiu??vi?):
参考:回归损失函数1:L1 loss, L2 loss以及Smooth L1 Loss的对比

- λ \lambda λ:平衡系数,用来平衡分类损失和边界框回归损失
- [
u
≥
1
u\geq 1
u≥1]:艾弗森括号,当
u
≥
1
u\geq 1
u≥1时,这一项等于1,当不满足时,这一项等于0
即一个示性函数:

u u u是真实类别的概率,不是 0 0 0就是 1 1 1
当 u ≥ 1 u\geq 1 u≥1时,代表对应的是正样本,[ u ≥ 1 u\geq 1 u≥1]=1,计算边界框损失;
当 u ≤ 1 u\leq 1 u≤1时,代表对应的时负样本,[ u ≥ 1 u\geq 1 u≥1]=0,不计算边界框损失。
总的来说,就是当边界框框出来的不是背景(正样本),就计算边界框回归损失。
得到总损失,并对其进行反向传播,就可以来训练我们的Fast R-CNN网络了。
四、和R-CNN的对比


相比于R-CNN,Fast R-CNN将分类和回归融入到CNN网络中,快了200多倍;
接下来的Faster R-CNN将会把Region proposal也融进CNN网络中,完成一个端对端的训练过程。
但是SS算法在cpu上需要2s左右,而一系列CNN操作只有零点几秒,所以Fast R-CNN的瓶颈就在于SS算法。
Faster R-CNN会通过Region proposal Network来解决这个问题。