模型结构
总体来看,LeNet(LeNet-5)由两个部分组成:
-
卷积编码器:由两个卷积层组成;
-
全连接层密集块:由三个全连接层组成。

每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用5×5卷积核和一个sigmoid激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个2×2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。?
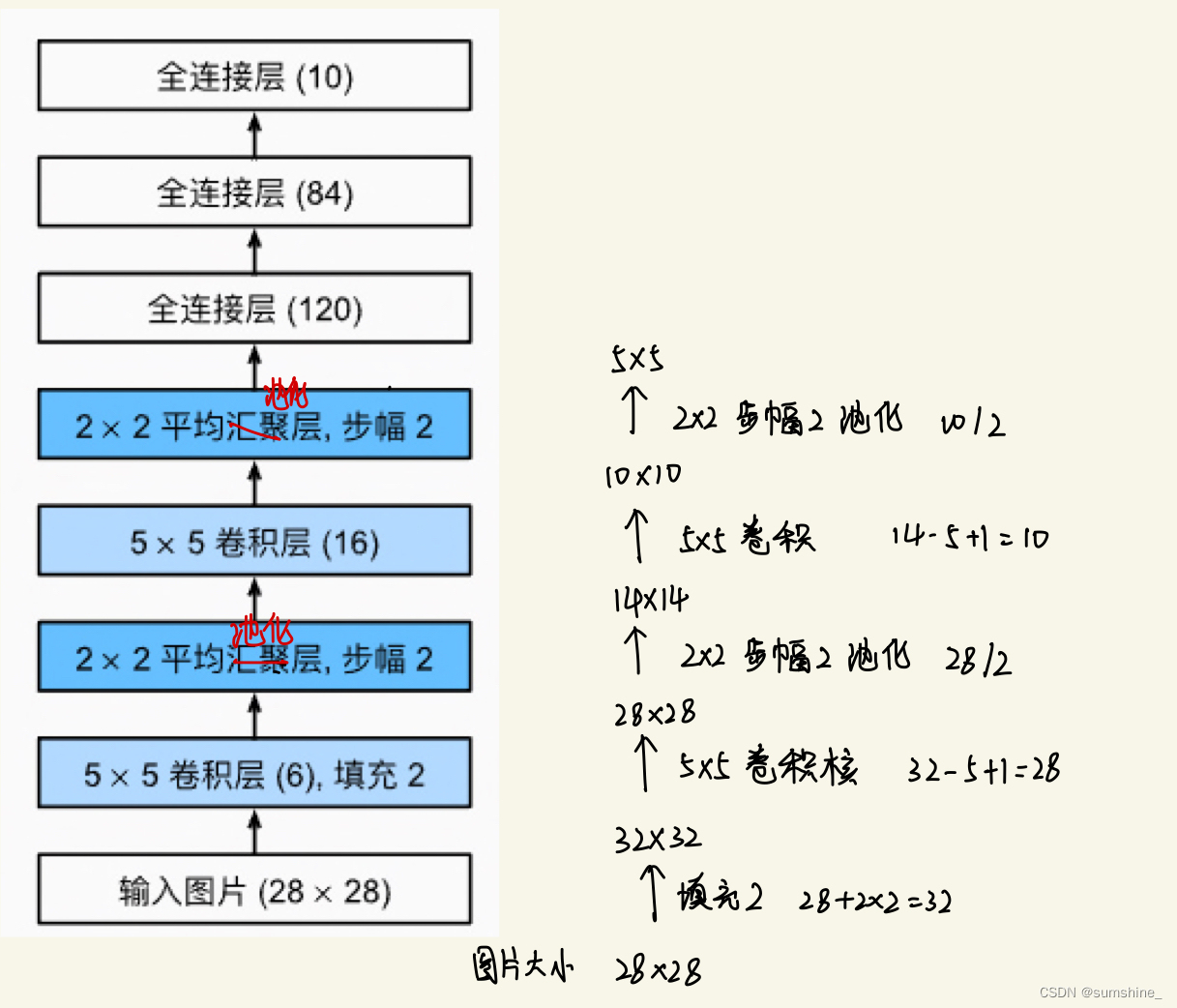
对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。
模型代码
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), #卷积层,第一层卷积有6个输出通道
nn.Sigmoid(),#sigmoid激活函数
nn.AvgPool2d(kernel_size=2, stride=2),#平均池化层,减小维数
nn.Conv2d(6, 16, kernel_size=5),#第二层卷积有16个输出通道
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),#变为二维输入
nn.Linear(16 * 5 * 5, 120),#全连接层:每一个输入都通过矩阵-向量乘法得到它的每个输出
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)注:输出通道的设计没啥依据,经验?
数据集
Fashion-MNIST数据集
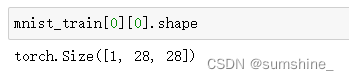
数据长下面这样:

图片shape:
 ??
??
?结果

几个没什么太大关系,但又比较重要的点
1、下面这两行代码与这个模块没有关系,是为了解决最后训练时内核挂了加的:
由于在每次打开jupyter notebook后没有实际上关掉,所以占据了大量的内存,根据anaconda-prompt的提示:需提前增加如下代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"2、查看每一层的输出
手写
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)函数――summary函数
参数:
model:网络模型
input_size:网络输入图片的shape,这里不用加batch_size进去
batch_size:batch_size参数,默认是-1
device:在GPU还是CPU上运行,默认是cuda在GPU上运行,如果想在CPU上执行将参数改为CPU即可
#安装
! pip install torchsummary
#运行
from torchsummary import summary
summary(net.cuda(0),(1,28,28))#模型在cpu上,输入数据在GPU上,要迁移一下3、CNN EXPLAINER(网络学习到什么的可视化,很有意思)
 https://poloclub.github.io/cnn-explainer/
https://poloclub.github.io/cnn-explainer/