МВВЁМьВтжаЕФгявєЩњЮяБъЪЖбаОП
МВВЁМьВтжаЕФгявєЩњЮяБъЪЖбаОП
ИХвЊ:ОЁЙмгявєЪЖБ№ММЪѕЫцзХвдЩюЖШбЇЯАЮЊДњБэЕФШЫЙЄжЧФмЕФЗЂеЙЕУЕНСЫОоДѓЕФЬсЩ§,ЕЋЪЧШчКЮНЋгявєаХЯЂзїЮЊМВВЁМьВтЕФвЛжжЪжЖЮ,етШдШЛЪЧвЛИіМЌЪжЕФЮЪЬтЁЃЫцзХЖрФЃЬЌММЪѕЕФЗЂеЙ,гявєЩњЮяЪЖБ№ж№НЅв§Ц№ШЫУЧЕФЙизЂЁЃзїЮЊвЛжжЗЧЧжШыЪНЕФгявєЩИВщЙЄОп,дкЪ§зжНЁПЕЁЂЩњУќМьВтЁЂМвЭЅЛЄРэЕШГЁОАЯТОпгаживЊЕФгІгУМлжЕЁЃБОбаОПНЋЙизЂгявєЩњЮяЪЖБ№ММЪѕдкМВВЁЩИВщ,НЁПЕМьВтЕШЗНУцЕФЗНЗЈЁЃ
ЙиМќДЪ:гявєЪЖБ№ЁЂгявєЩњЮяБъМЧЮяЁЂЖрФЃЬЌММЪѕЁЂМВВЁЩИВщ
вЛЁЂ баОПИХЪі
гявєЪЖБ№ЪЧвдгявєЮЊбаОПЖдЯѓ,ЭЈЙ§гявєаХКХДІРэКЭФЃЪНЪЖБ№ЕШММЪѕШУЛњЦїФмЙЛздЖЏЪЖБ№КЭРэНтШЫРрПкЪіЕФгябдЁЃгявєЪЖБ№ММЪѕАќКЌЛњЦїЖдгявєаХКХЕФДІРэ,ЛњЦїЖдШЫРргявхЕФРэНт,вдМАНЋгявєаХКХзЊЛЛЮЊЯргІЕФЮФБОЛђЖЏзїЕШЙ§ГЬЁЃгявєЪЖБ№ПЩвдАяжњМЦЫуЛњРэНтШЫРрЕФааЮЊ,ХаЖЯШЫРрЕБЧАЕФЧщаїКЭзДЬЌЁЃ
ФПЧА,вбОгаДѓСПЕФЛњЦїбЇЯАФЃаЭКЭЩюЖШбЇЯАФЃаЭБЛЙуЗКгІгУЕНгявєЪЖБ№баОПжа[1-5],ВЂШЁЕУСЫСМКУЕФаЇЙћЁЃР§ШчЪЙгУбЛЗЩёОЭјТчПЩвдгааЇЕиРћгУгявєжаЕФЩЯЯТЮФаХЯЂ,ЪЙгУОэЛ§ЩёОЭјТчПЩвдРћгУЙВЯэШЈжЕЕФЗНЗЈМѕЩйМЦЫуИДдгЖШ,в§ШыГЄЖЬЪБМЧвфЭјТчНтОіСЫЬнЖШЯћЪЇЕФЮЪЬт,ЪЙЕУгявєЪЖБ№дкНќГЁЬѕМўЯТДяЕНТњзуШЫУЧШеГЃЩњЛюЕФБъзМЁЃ
ЫцзХвдAttention[6]ЮЊДњБэЕФЖЫЕНЖЫгявєЪЖБ№ММЪѕЕФПьЫйЗЂеЙ,вЛжжЛљгкAttentionЕФSeq2Seq[7]ЕФгявєЪЖБ№ФЃаЭЕУЕНСЫбЇЪѕНчЕФМЋДѓЙизЂ,ВЂШЁЕУСЫЯджјЕФаЇЙћЁЃ2017ФъGoogleЬсГіЕФвЛжжГЦЮЊTransformer[8]ЕФМмЙЙдйвЛДЮШЁЕУСЫУїЯдЕФИФНјаЇЙћЁЃЭЌЪБ,ЩњГЩЪНЖдПЙЭјТч(GAN)ЪЧНќФъРДЮоМрЖНбЇЯАЗНУцзюОпгаЧАОАЕФвЛжжЩюЖШбЇЯАПђМмЁЃIan J. GoodfellowЕШЬсГіСЫвЛИіЖдПЙЙ§ГЬЙРМЦЩњГЩФЃаЭПђМмЕФШЋаТЗНЗЈ[9],ЬсЩ§СЫгявєЪЖБ№ЕФдыЩљТГАєадЁЃZhangЕШ[10]ЕквЛИіНЋGANв§ШыЕНSnSЗжРрШЮЮёжа,ЮЊНтОіДђї§ЮЛЕуЖЈЮЛЕФвНСЦШЮЮёжаЕФЪ§ОнЯЁЪшЮЪЬтЬсЙЉСЫвЛжжЫМТЗЁЃ
ОЁЙмгявєЪЖБ№дкећЬхЫЎЦНЩЯвбОгыШЫРрЫЎЦНЯрВюВЛДѓ,ЩѕжСвбОГЌдНСЫШЫРрЕФЦНОљЫЎЦН,ЕЋЪЧдкФГаЉЬиЖЈГЁОАжавРШЛДцдкВЛЩйгІгУЬєеН,ЦфжаАќРЈ:ШчКЮБЃжЄдкИДдгГЁОАЯТгявєЪЖБ№ЕФТГАєад;ШчКЮЪЪгІВЛЭЌЕиЧјЁЂВЛЭЌШЫШКЕФЫЕЛАЗНЪН;ШчКЮЪЙгУЩйСПЕФЪ§ОнТњзуИДдгзЈвЕЕФвЕЮёГЁОАЁЃ
ЖўЁЂ баОПФкШн
БОбаОПНЋЙизЂИДдгвНСЦБЃНЁГЁОАжагявєЩњЮяЪЖБ№[11-13]ЮЪЬт,НЈСЂЛљгкЖрФЃЬЌЗНЗЈЕФгявєЩњЮяБъжОЮяЗжЮіЗНЗЈ,ДйНјМВВЁЩИВщКЭеяЖЯаЇТЪЕФЬсЩ§,ДДаТвНСЦЗўЮёФЃЪНЁЃ
дквНСЦБЃНЁГЁОАжа,ГЃМћЕФгявєЪЖБ№гІгУЪЧЩњГЩвНСЦЕЕАИ(ШчВЁР§ЁЂвНжіЕШ)[14]ЁЃгЩгкгявєЪЖБ№ММЪѕЕФгІгУ,вНЩњПЩвдПьЫйМЧТМЫћУЧЕФЩљвє,ВЂЭЌЪБМЧТМеяЖЯЁЂжЮСЦМЧТМКЭЦфЫћживЊЕФБЪМЧ,ЖјВЛБиеМОнвЕгрЪБМфЁЃЖдгкЛЄРэШЫдБРДЫЕ,ЪЙгУгявєЪЖБ№ММЪѕПЩвдМѕЩйЫћУЧдкЮФЪщЙЄзїЩЯЕФЪБМф,ЪЙЕУФмЙЛЛЈЗбИќЖрЕФЪБМфдкВЁЛМЩэЩЯЁЃ
ЫцзХПЩДЉДїЩшБИКЭБуаЏЪНжЧФмвєЯфЕФЗЂеЙ,НјвЛВНРЉеЙСЫвНСЦБЃНЁЗўЮёЕФЮяРэЗЖЮЇЁЃгявєЩњЮяЪЖБ№ММЪѕПЩвдЭЈЙ§ИажЊКЭЗжЮіФПБъЖдЯѓЩљвєжаЕФЯИЮЂБфЛЏ,РДЪЖБ№Р§ШчПШЫдЁЂЯјДЁЂCOPD(Т§адзшШћадЗЮМВВЁ)ЕШКєЮќЯЕЭГМВВЁЕФжЂзДЁЃОЁЙмИУЗНЗЈВЛФмДњЬцвНЩњЕФХаЖЯ,ЕЋЪЧЭЈЙ§ПьЫйЙуЗКЕФЩИВщЬсЙЉПЩППЕФЗчЯеЦРЗжРДжИЕМПЩФмашвЊЖюЭтеяЖЯВтЪдЕФШЫ,ДгЖјЪЙЮРЩњЯЕЭГФмЙЛИќгааЇЕиЗжХфеяЖЯзЪдД,етЪЧгявєЩњЮяБъжОЮяМьВтЕФживЊМлжЕжЎвЛЁЃ
Г§СЫКєЮќЯЕЭГМВВЁЩИВщжЎЭт,гявєЩњЮяЪЖБ№ЖдгкЗжЮіаФРэНЁПЕЮЪЬт[15]вВОЭгабаОПМлжЕЁЃЕБШЫЬхГіЯжНЁПЕЮЪЬтЪБ,МВВЁЕФЬивьадИЩШХЛсЖдФГИіЯЕЭГЛђЖрИіЯЕЭГВњЩњЯИЮЂЕФЁЂФбвдВьОѕЕФ,ЕЋОпгаЬивьадЕФБфЛЏ,ЖјетжжБфЛЏЪЧПЩвдБЛгУРДНјааМЦЫуЗжЮіЕФЁЃвдвжгєжЂ[16]ЮЊР§,ЛМепЭљЭљЛсБэЯжГібдгяГйЛКЁЂвєСПВЛЮШЖЈЁЂЗЂЩљВќЖЖЁЂгябддЯТЩвьГЃЕШжЂзДЁЃгабаОПЗЂЯж,вжгєжЂЛМепжЮСЦЧАНЯжЮСЦКѓ,ЩљДјЗЂЩљЕФЪБПЬКЭЧПЖШдкУПДЮЩљДјеёЖЏЕФжмЦкжа,ВЈЖЏЖМБШНЯЯджј,ВЂЧвВЈЖЏГЬЖШгывжгєжЂЕФбЯжиГЬЖШГЪе§ЯрЙиЁЃ
ЭЌЪБ,гявєЩњЮяЪЖБ№ЕФбаОПвВУцСйетвЛаЉЮЪЬтЁЃЪзЯШЪЧЪЙгУГЁОАЕФИДдгЛЏ,етОЭЕМжТСЫШнвзГіЯждыЩљИЩШХЕШЮЪЬт;ЦфДЮЪЧгяСЯЕФВЛзуЛђШБЪЇ,вЛЗНУцЪЧЬиЖЈРраЭгяСЯПтЕФШБЩй,СэвЛЗНУцЪЧгявхРэНтЙцдђашвЊЯШбщЕФзЈМвжЊЪЖЁЃЕкШ§ЪЧИіадЛЏгябдЯАЙпЮЪЬт,БШШчЗНбдгыЦеЭЈЛАЁЂжаЮФгыгЂЮФЕШ,етПЩФмвЊЧѓгявєЩњЮяЪЖБ№ЯЕЭГОпгаИіадЛЏгХЛЏЕФФмСІЁЃ
Ш§ЁЂ баОПЗНЗЈ
3.1 ЩюЖШбЇЯАФЃаЭ
ЕБЧА,ЩюЖШбЇЯАФЃаЭдкгявєЪЖБ№еЙЯжСЫЗЧГЃКУЕФаЇЙћ,вРОнФЃаЭЕФВЛЭЌ,ГЃгУЕФЗНЗЈга:
- CTC[17],МДConnectionist Temporal Classification,ДгзжУцЩЯПД,ЫќЪЧвЛжжгУРДНтОіЪБађРрЪ§ОнЕФЗжРрЮЪЬтЁЃЭЈЙ§CTC,ПЩвджБНгНЋгявєдкЪБМфЩЯЕФжЁађСаКЭЯргІЕФзЊТМЮФзжађСадкФЃаЭбЕСЗЙ§ГЬжаздЖЏЖдЦы,ЮоашЖдУПИізжЗћЛђвєЫиГіЯжЕФЦ№жЙЪБМфЖЮзіБъзЂ,вдЪЕЯжжБНгдкЪБМфађСаЩЯНјааЗжРрЁЃ
- LAS[18],МДListen, Attend and Spell,ЪЧвЛжжФмЙЛНЋгявєжБНгзЊЛЛЮЊзжЗћЕФЖЫЕНЖЫЩёОЭјТчгявєЪЖБ№Цї,ЫќВЛашвЊЗЂвєФЃаЭЁЂHMMsЛђЦфЫћДЋЭГгявєЪЖБ№жаЕФзщМўЁЃ
- RNN-T[19],МДRNN-Transducer,ЪЧвЛжжФмЙЛИќКУЕиЖдЪфГіНсЙћЧАКѓДЪжЎМфЕФвРРЕЙиЯЕНјааНЈФЃЕФЗНЗЈЁЃЫќАќКЌШ§ИіВПЗж:EncoderЁЂPrediction NetworkЁЂJoint NetworkЁЃЖдЩљбЇФЃаЭКЭгябдФЃаЭЗжБ№НЈФЃ,ЭЌЪБгжЭЈЙ§Joint NetworkРДСЊКЯгХЛЏ,НЋЫЕЛАШЫЗжРыШЮЮёКЭгявєЪЖБ№ШЮЮёШкКЯдквЛЦ№,ЬсЙЉСЫвЛжжгааЇНЕЕЭЗжРыДэЮѓТЪЕФШЋаТЫМТЗЁЃ
- AttentionФЃаЭЁЃРрЫЦгкRNN-T,ЛљгкAttentionЕФEncoder-DecoderФЃаЭвВВЛашвЊЖдЪфГіађСазіЯрЛЅЖРСЂЕФМйЩш,ЕЋЪЧгыCTCКЭRNN-TВЛЭЌ,AttentionВЛвЊЧѓЪфГіађСаКЭЪфШыађСаАДЪБМфЫГађЖдЦыЁЃеыЖдгявєЪЖБ№,ИјЖЈЪфШыЬиеїађСаXКЭЪфГіађСаYЕФБрНтТыЙ§ГЬАќРЈШ§ИіВПЗж:Encoder,Decoder,вдМАAttentionЁЃЦфжаEncoderЯрЕБгкЩљбЇФЃаЭ,DecoderЯрЕБгкгябдФЃаЭ,AttentionФЃПщДгEncoderЪфГіЫљгаЯђСПађСа,МЦЫузЂвтСІШЈжи,ВЂЛљгкИУШЈжиЙЙНЈDecoderЭјТчЕФЩЯЯТЮФЯђСП,НјЖјНЈСЂЪфГіађСагыЪфШыађСажЎМфЕФЖдЦыЙиЯЕЁЃ
- TransformerЁЃетжжМмЙЙдкУПИіEncoderКЭDecoderжаОљВЩгУAttentionЛњжЦ,НЈСЂЪфШыгявєЬиеїКЭЪЖБ№НсЙћжЎМфЕФађСаЖдгІЙиЯЕ,БОжЪЩЯЛЙЪЧseq2seqЕФНсЙЙЁЃTransformerФЃаЭМмЙЙШчЭМ1ЫљЪО:
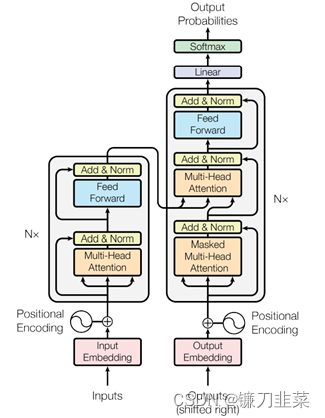
ЭМ1 TransformerФЃаЭПђМм[20]
3.2 ЖрФЃЬЌгявєЪЖБ№
жкЫљжмжЊ,Г§СЫгявєЭт,ШЫРрЛЙПЩвдЭЈЙ§ЮФзжЁЂБэЧщЁЂЪгЦЕЁЂЖЏзїЕШЗНЪНДЋЕнаХЯЂЁЃДЋЭГЕФгявєЪЖБ№ДѓЖМЛљгкЕЅвЛЕФгявєаХКХ,ЧвШнвзЪмЕНЛЗОГжадыЩљЕШвђЫиЕФИЩШХЁЃвђДЫ,вбОгаДѓСПЕФбаОПЙЄзїБэУїЖрФЃЬЌЗНЗЈгХгкЕЅвЛФЃЬЌЕФЗНЗЈЁЃЖрФЃЬЌгявєЪЖБ№ММЪѕзлКЯРћгУвєЦЕЁЂЪгЦЕЩѕжСИќЖрФЃЬЌаХЯЂ,вдЛёЕУИќИпОЋЖШЧвЖдЬиЖЈГЁОАОпгаНЯЧПЪЪгІадЕФЪЖБ№ЯЕЭГЁЃдчЦкЕФбаОПЗНЗЈЪЧЛљгкHMMЕФЖрдДЪ§ОнНЈФЃЗНЗЈ(CHMM),НЋЖрФЃЬЌЪ§ОнзїЮЊЭГвЛHMMФЃаЭЕФЙлВтБфСП[21]ЁЃ
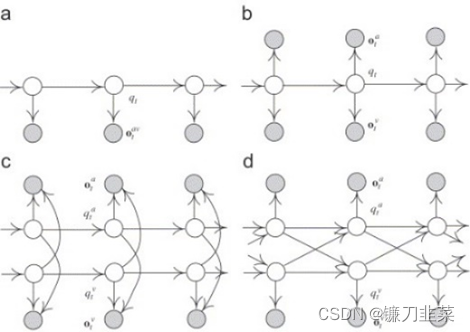
ЭМ2 ДЋЭГЛљгкHMMЕФЖрдДЪ§ОнНЈФЃЗНЗЈ[21]
ЫцзХНќФъРДЕФЛљгкЩюЖШЩёОЭјТчЕФЖрФЃЬЌгявєЪЖБ№ММЪѕЕФЗЂеЙ,ЬиБ№ЪЧЖЫЕНЖЫбЇЯАЗНЗЈКЭДѓЙцФЃвєЪгЦЕЪ§ОнПтЕФГіЯж,НјвЛВНЬсИпСЫЖрФЃЬЌгявєЪЖБ№ЕФадФмЁЃAfourasЕШ[22]ПЊЗЂСЫУцЯђДНЖСОфзгЕФЩёОзЊЛЛЬхЯЕМмЙЙ,ВЂНЈСЂСЫСНжжЛљгкTransformer Self-AttentionЕФМмЙЙ,ЛЙбаОПСЫдкдыЩљЬѕМўЯТДНЖСЖдгявєЪЖБ№ЕФИЈжњзїгУЁЃ
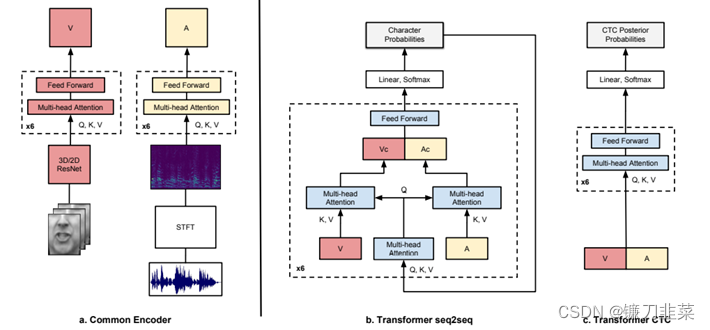
ЭМ3 ЛљгкTransformerЕФЪгЬ§гявєЪЖБ№ФЃаЭ[22]
ФПЧА,ЫфШЛЖрФЃЬЌгявєЪЖБ№вбОШЁЕУСЫВЛДэЕФаЇЙћ,ЕЋЪЧЛЙгавЛаЉЮЪЬташвЊНтОі,ЬиБ№ЪЧШчКЮЖдвьжЪЕФЖрФЃЬЌЪ§ОнНјааКЯРэШкКЯЁЃЕБЧАЕФЭЈГЃзіЗЈЪЧЖдЖрФЃЬЌЬиеїНјааЦДНгЛђбЁдё,ЕЋЪЧетбљУЛгаПМТЧЕНИїИіФЃЬЌдкаХЯЂСНЁЂТГАєадЁЂЪБгђНтЮіЖШЕШЬиадЩЯЕФВювь,вВУЛгаПМТЧВЛЭЌФЃЬЌжЎМфЕФЯрЙиадЁЂЛЅВЙадЁЂвьВНадЁЃгШЦфЪЧдкНсКЯЩюЖШЩёОЭјТчЪБ,МђЕЅЕФЬиеїВуУцШкКЯЛсДјРДПЩНтЪЭадКЭПЩРЉеЙадЕФНЕЕЭЁЃ
ИљОнHanЕШ[23]ЕФзмНс,ЖрФЃЬЌаХЯЂЕФШкКЯВпТдПЩвдЗжЮЊШ§Рр,МДЬиеїВуУцЕФШкКЯЁЂОіВпВуУцЕФШкКЯвдМАФЃаЭВуУцЕФШкКЯЁЃЦфжаЙигкЬиеїВуУцЕФШкКЯдкЩЯЮФвбОЬсЕН,ЖдгкОіВпВуУцЕФШкКЯ,ЭЈГЃЕФзіЗЈЪЧЛљгкЖрЪ§ЭЖЦБжЦ(majority voting)КЭБпМЪГщбљЭЖЦБжЦ(margin sampling voting)[24]ЁЃЖдгкФЃаЭВуУцжМдкећКЯВЛЭЌФЃЪН(Р§ШчЩљвєЁЂЪгЦЕЕШ)ЕФжаМфБэЪОаЮЪН,ПЩвдРћгУИУВпТддкЩюЖШЩёОЭјТчЕФбЕСЗЙ§ГЬжав§ШыИХТЪФЃаЭећКЯЖрдДЪ§ОнБэЪОНјЖјЬсИпЪ§ОнШкКЯЕФАВШЋадЁЂКЯРэадКЭПЩНтЪЭадЁЃ
3.3гявєЩњЮяБъМЧМьВт
ЖдгкгявєЩњЮяЪЖБ№ЮЪЬт,ТщЪЁРэЙЄбЇдКЕФбаОПШЫдБЬсГіСЫвЛжжаТЕФЖрФЃЬЌДІРэПђМм,МДOpen Voice Brain Model(OVBM)[13],ИУПђМмЪзЯШЭЈЙ§дкДѓЕФгявєЪ§ОнМЏЩЯбЕСЗФЃаЭ,ШЛКѓНјааЧЈвЦбЇЯА,ЪЙЕУбЇЯАЕНЕФЬиеїМДЪЙЪЧдкаЁЙцФЃЕФЛМепЪ§ОнМЏЩЯвВФмЙЛКмКУЕиИФЩЦАЂЖћзШКЃФЌжЂ(AD)ЕФМьВтзМШЗЖШЁЃЭЌЪБ,зїепЛЙБэЪОИУПђМмПЩвдгУгкЖржжМВВЁЕФвєЦЕМьВт,ВЂбаОПВЛЭЌМВВЁжЎМфЪЧЗёДцдкЙВЭЌЕФгявєЩњЮяБъМЧЁЃ
OVBM ПђМмЙЙНЈСЫвЛИігЩЫФИіЕЅдЊЙЙНЈЕФЯЕЭГРДМьВтЩњЮяБъМЧзщКЯ,ВЂЮЊФПБъШЮЮё(Шч AD МјБ№)ЬсЙЉСЫвЛИіПЩНтЪЭЕФеяЖЯПђМмЁЃетЫФИіЕЅдЊЗжБ№ЪЧ
- Sensory Stream,ИКд№дкНЯДѓЕФгявєЪ§ОнМЏЩЯжДаадЄбЕСЗЙ§ГЬ,жМдкЬсШЁИіЬхЮяРэВуУцЕФБъМЧЬиеї;
- Brain OS,НЋвєЦЕЗжИюГЩжиЕўЕФПщ,ВЂРћгУЧЈвЦбЇЯАВпТд,НЋЩњЮяБъМЧФЃаЭЕїећЕНИќаЁЕФФПБъЪ§ОнМЏЩЯ;
- Cognitive Core,ећКЯЬиЖЈФПБъШЮЮёЕФвНбЇжЊЪЖРДбЕСЗШЯжЊЩњЮяБъМЧЬиеїЬсШЁЦї;
- Symbolic Compositional Models НЋЮЂЕїЕФЩњЮяБъМЧФЃаЭећКЯЕНвЛИіЭМЩёОЭјТчжа,ЫќдкЕЅЖРЕФвєЦЕПщЩЯЕФдЄВтЪфГіБЛЪфШыЕНвЛИіОлКЯв§Чцжа,зюжеЕУЕНеяЖЯНсЙћКЭвЛИіЛМепЕФЯджјадЭМЁЃ
LaguartaЕШ[25]НЋИУПђМмгІгУдкСЫCOVID-19ЕФМьВтжа,ЪзЯШМЧТМЛМепЕФПШЫдвєЦЕЪ§Он,ШЛКѓЖдЪ§ОнжДааСНИідЄДІРэВНжш,ВЂНЋЦфЪфШыЕНвЛИіЛљгкCNNЕФФЃаЭжа,ЕУЕНвЛИідЄЩИбЁЕФеяЖЯНсЙћКЭвЛИіЩњЮяБъжОЮяЯджјадЭМЁЃ
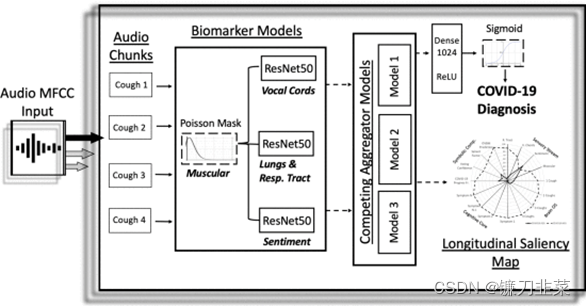
ЭМ4 вдПШЫдТМвєЮЊЪфШыЪ§ОнЕФCOVID-19еяЖЯПђМм[25]
ChenЕШ[26]ЬсГіСЫвЛжжЪЙгУКєЮќЩљЁЂЫЕЛАЩљКЭПШЫдЩљЕФЛљгкЫЋЯђГЄЖЬЪБМЧвф(BiLSTM)ЭјТчЕФCOVID-19МьВтЗНЗЈЁЃЗжБ№ЭЈЙ§ВЛЭЌЕФЩљбЇаХКХШЅбЕСЗЭјТч,ЮЊШ§ИіШЮЮёНЈСЂЕЅЖРЕФФЃаЭ,НЋЦфВЮЪ§НјааЦНОљвдЕУЕНвЛИіЦНОљФЃаЭ,ШЛКѓНЋЦфгУгкУПИіШЮЮёЕФBiLSTMФЃаЭЕФГѕЪМЛЏЁЃ
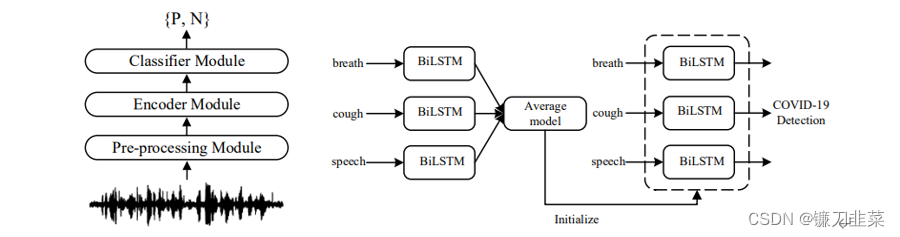
ЭМ5 DiCOVAеяЖЯФЃаЭЪОвтЭМ(зѓ)МАгаМрЖНЕФдЄбЕСЗСїГЬ(гв)[26]
Г§ДЫжЎЭт,ShengЕШЬсГіСЫвЛжжШкКЯгявєКЭблЖЏаХЯЂНјааГеДєМьВтЕФЗНЗЈЁЃЪзЯШ,ВЩгУгявєЪЖБ№КЭЧјгђЭМЯёЪЖБ№ФЃаЭЬсШЁЪмЪдепдкЭМЦЌУшЪіШЮЮёжаЕФгявєКЭблЖЏЬиеїЁЃШЛКѓ,ВЩгУЩюЖШбЇЯАШкКЯСНжжФЃЬЌЕФЬиеїРДХаБ№ГеДєЛМепКЭНЁПЕШЫШК,АќРЈгУгкЬиеїШкКЯЕФПчФЃЬЌTransformerКЭзюжеЗжРрЕФздзЂвтСІTransformerЁЃ
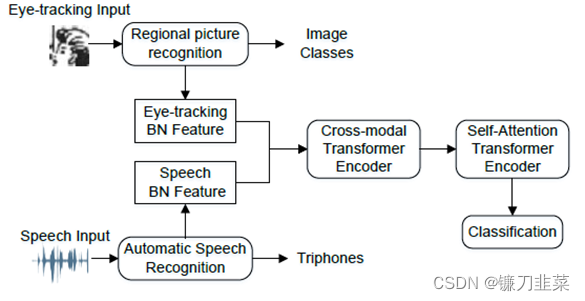
ЭМ6 вЛжжШкКЯгявєКЭблЖЏаХЯЂЕФГеДєМьВтЗНЗЈ
ЫФЁЂ змНс
дкЮДРДЕФбаОПжа,вЛЗНУцЩюШыРэНтЖрФЃЬЌгявєЪЖБ№ЕФЯрЙиЗНЗЈ,ВЂИљОнЪЕМЪЮЪЬтЗжЮіЪ§ОнЬиЕуЁЃЕБДцдкЪ§ОнВЛзуЛђепБъЧЉаХЯЂШБЪЇЪБ,ПМТЧв§ШыАыМрЖНЕФЩњГЩЪНЖдПЙЭјТчФЃаЭ,ЭЈЙ§НЋЫцЛњдыЩљгГЩфЕНдЪМЪ§ОнЗжВМжа,здЖЏЩњГЩЪ§ОнЁЃСэвЛЗНУцЬНЫїЛљгкOVBMЕФМВВЁМьВтЗНЗЈдкВЛЭЌРраЭМВВЁжаЕФгІгУФЃЪН,ВЂНЋЦфгыЦфЫћЩюЖШЩёОЭјТчФЃаЭНјааШкКЯ,НјвЛВНЗЂеЙЗЧЧжШыЕФМВВЁЩИВщЗНЗЈЁЃЭЈЙ§ЖрФЃЬЌгявєЩњЮяБъМЧЮяЪЖБ№,ЬсИпвНСЦЗўЮёЕФаХЯЂЛЏЫЎЦНЁЃ
ЮхЁЂ ВЮПМЮФЯз
[1] G. Mark and Y. Steve, Application of Hidden Markov Models in Speech Recognition. now, 2008, p. 1.
[2] G. E. Dahl, D. Yu, L. Deng, and A. Acero, ЁАContext-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition,ЁБ IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 30-42, 2012, doi: 10.1109/TASL.2011.2134090.
[3] M. Mohri, F. Pereira, and M. Riley, ЁАSpeech Recognition with Weighted Finite-State Transducers,ЁБ Handbook of Speech Processing, 01/01 2008, doi: 10.1007/978-3-540-49127-9_28.
[4] A. Graves, A. Mohamed, and G. Hinton, ЁАSpeech recognition with deep recurrent neural networks,ЁБ in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 26-31 May 2013 2013, pp. 6645-6649, doi: 10.1109/ICASSP.2013.6638947.
[5] H. Sak, A. Senior, and F. Beaufays, ЁАLong short-term memory recurrent neural network architectures for large scale acoustic modeling,ЁБ Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, pp. 338-342, 01/01 2014.
[6] K. Cho, B. Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y. Bengio, ЁАLearning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,ЁБ 06/03 2014, doi: 10.3115/v1/D14-1179.
[7] C.-C. Chiu et al., State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. 2018, pp. 4774-4778.
[8] L. Dong, S. Xu, and B. Xu, ЁАSpeech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition,ЁБ in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 15-20 April 2018 2018, pp. 5884-5888, doi: 10.1109/ICASSP.2018.8462506.
[9] I. Goodfellow et al., ЁАGenerative Adversarial Networks,ЁБ Advances in Neural Information Processing Systems, vol. 3, 06/10 2014, doi: 10.1145/3422622.
[10] Z. Zhang, J. Han, K. Qian, C. Janott, Y. Guo, and B. Schuller, ЁАSnore-GANs: Improving Automatic Snore Sound Classification With Synthesized Data,ЁБ IEEE Journal of Biomedical and Health Informatics, vol. 24, no. 1, pp. 300-310, 2020, doi: 10.1109/JBHI.2019.2907286.
[11] V. Ramanarayanan, A. Lammert, H. Rowe, T. Quatieri, and J. Green, ЁАSpeech as a Biomarker: Opportunities, Interpretability, and Challenges,ЁБ Perspectives of the ASHA Special Interest Groups, vol. 7, pp. 1-8, 01/11 2022, doi: 10.1044/2021_PERSP-21-00174.
[12] J. Robin, J. Harrison, L. Kaufman, F. Rudzicz, W. Simpson, and M. Yancheva, ЁАEvaluation of Speech-Based Digital Biomarkers: Review and Recommendations,ЁБ Digital Biomarkers, vol. 4, pp. 99-108, 10/01 2020, doi: 10.1159/000510820.
[13] J. Laguarta, F. Hueto, P. Rajasekaran, S. Sarma, and B. Subirana, Longitudinal Speech Biomarkers for Automated AlzheimerЁЏs Detection. 2020.
[14] C.-C. Chiu et al., Speech Recognition for Medical Conversations. 2018, pp. 2972-2976.
[15] L. Palaniyappan, ЁАMore than a biomarker: could language be a biosocial marker of psychosis?,ЁБ npj Schizophrenia, vol. 7, no. 1, p. 42, 2021/08/31 2021, doi: 10.1038/s41537-021-00172-1.
[16] A. C. Trevino, T. F. Quatieri, and N. Malyska, ЁАPhonologically-based biomarkers for major depressive disorder,ЁБ EURASIP Journal on Advances in Signal Processing, vol. 2011, no. 1, p. 42, 2011/08/16 2011, doi: 10.1186/1687-6180-2011-42.
[17] A. Graves, S. FernЈЂndez, F. Gomez, and J. Schmidhuber, Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural 'networks. 2006, pp. 369-376.
[18] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, ЁАListen, attend and spell: A neural network for large vocabulary conversational speech recognition,ЁБ in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 20-25 March 2016 2016, pp. 4960-4964, doi: 10.1109/ICASSP.2016.7472621.
[19] A. Graves, Supervised Sequence Labelling with Recurrent Neural Networks. 2012.
[20] A. Vaswani et al., ЁАAttention Is All You Need,ЁБ 06/12 2017.
[21] L. Xie and Z.-Q. Liu, ЁАA coupled HMM approach to video-realistic speech animation,ЁБ Pattern Recognition, vol. 40, no. 8, pp. 2325-2340, 2007/08/01/ 2007, doi: https://doi.org/10.1016/j.patcog.2006.12.001.
[22] T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, ЁАDeep Audio-visual Speech Recognition,ЁБ IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1-1, 2018, doi: 10.1109/TPAMI.2018.2889052.
[23] J. Han, Z. Zhang, Z. Ren, and B. Schuller, ЁАImplicit Fusion by Joint Audiovisual Training for Emotion Recognition in Mono Modality,ЁБ in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12-17 May 2019 2019, pp. 5861-5865, doi: 10.1109/ICASSP.2019.8682773.
[24] K. Qian et al., ЁАCan Machine Learning Assist Locating the Excitation of Snore Sound? A Review,ЁБ IEEE Journal of Biomedical and Health Informatics, vol. 25, no. 4, pp. 1233-1246, 2021, doi: 10.1109/JBHI.2020.3012666.
[25] J. Laguarta, F. Hueto, and B. Subirana, ЁАCOVID-19 Artificial Intelligence Diagnosis Using Only Cough Recordings,ЁБ IEEE Open Journal of Engineering in Medicine and Biology, vol. 1, pp. 275-281, 2020, doi: 10.1109/OJEMB.2020.3026928.
[26] X.-Y. Chen, Q.-S. Zhu, J. Zhang, and L.-R. Dai, Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals. 2022.