论文名称:Densely Connected Convolutional Networks
论文下载地址:https://arxiv.org/pdf/1608.06993.pdf
论文代码地址:https://github.com/bamos/densenet.pytorch
论文参考翻译:https://blog.csdn.net/qq_41295976/article/details/88249740
论文标题

1.论文概述
- 最近的研究表明,如果在接近输入层与输出层之间的网络层包含短连接,就可以训练更深、更准确、更有效的卷积网络。
- 基于这一研究结论,作者提出了一种稠密卷积网络(DenseNet),该网络在前馈传播时,将每一层与其后的每一层连接起来。传统的 L L L层卷积网络有 L L L个连接,而DenseNet有 L ( L + 1 ) / 2 L(L+1) / 2 L(L+1)/2连接(根据后文的理解,这里的 L L L层应该不算上输入层)。每一层都将之前所有层的特征图作为输入,而它自己的特征图是之后所有层的输入。
- DenseNet有一些很不错的优点:有助于梯度消失问题,有利于特征传播,鼓励特征的重复利用,还可以减少参数量。
- DenseNets在CIFAR-10/100, SVHN,和ImageNet数据集上都取得了较好的性能。
2.论文提出的背景
-
随着卷积神经网络的发展,越来越深的网络被提出,这导致了一个新问题的出现:当输入和梯度信息在经过很多层的传递之后,在到达网络的最后(或开始)可能会消失或“被冲洗掉”,即梯度消失问题。网络层数的增加也让更多的人进行结构的改善、不同连接模式的探索工作。
-
针对上述问题,在以往的研究中提出了很多策略。例如,ResNets网络和Highway网络采用了一种旁路连接的方式。随机深度(Stochastic depth)在训练过程中随机丢掉一些层,进而缩短了ResNets网络,获得更好的信息和梯度流。FractalNets网络重复组合几个具有不同数量卷积块的并行层序列,获得更深的网络的同时还保留了网络中的短路径。
-
上述的这些方法都有一个关键点:它们都在前几层和后几层之间产生了短路径。
-
在这篇论文中,作者提出了一种结构,该结构提炼了上述的观点而形成了一种简单的连接模式:为了保证能够获得网络层之间的最大信息,作者将所有层都进行相互连接。为了能够保持前馈的特性,每一层都将之前所有层的输入进行拼接,之后将输出的特征图传递给之后的所有层。如下图所示。
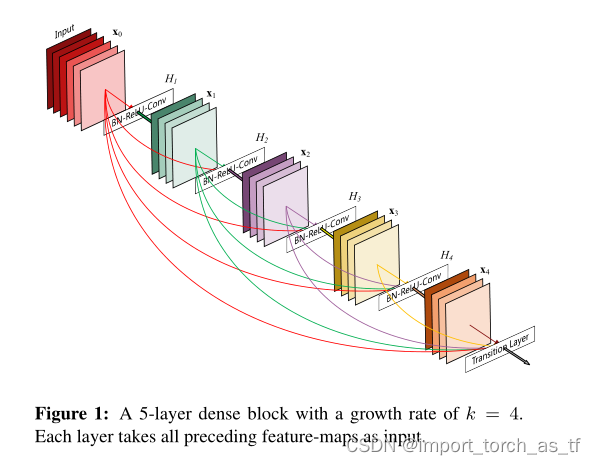
-
DenseNets不是通过很深或者很宽的网络来获得表征能力,而是通过特征的重复使用来利用网络的隐含信息,获得更容易训练、参数效率更高的稠密模型。将不同层学到的特征图进行组合连接,增加了之后层输入的多样性,提升了性能。
所以本质上来说,DenseNet网络的提出还是为了解决网络层不断加深而引发的一系列问题。
3.论文提出的方法
假设一张图片 x 0 x_0 x0?,在卷积网络中传播。网络共有 L L L层,每一层都有一个非线性变换 H l ( . ) H_l(.) Hl?(.),其中 l l l表示层的维度,即第几层。 H l ( . ) H_l(.) Hl?(.)是一个组合函数,有BN、ReLU、池化或卷积。用 x l x_l xl?表示 l t h l^{th} lth层的输出。
- ResNets:传统前馈网络是将 l t h l^{th} lth层的输出作为 ( l + 1 ) t h (l+1)^{th} (l+1)th层的输入。因此可将这一过程抽象为表达式: x l x_l xl? = H l ( x l ? 1 ) H_l(x_{l-1}) Hl?(xl?1?)。而ResNets增加了一个跨层连接,将本层特征与输入到下一层的非线性转换的结果相加: x l x_l xl? = H l ( x l ? 1 ) H_l(x_{l-1}) Hl?(xl?1?) + x l ? 1 x_{l-1} xl?1?。ResNets的一个优点是可以直接将梯度从后层传向前层。然而,本层特征与经过 H l H_l Hl?层得到的输出是通过求和的形式来连接的,这可能使网络中信息的传播受到影响。
- 稠密连接:为了更好的改善层与层之间的信息的传递,作者提出了一种不同的连接模式:将该层与之后的所有层进行连接。如上图,图一所示。因此,
l
t
h
l^{th}
lth层将之前所有层的特征图
x
0
x_0
x0?,…,
x
l
?
1
x_{l-1}
xl?1?作为输入,则可以将这一过程抽象为数学表达式:
x l = H l ( [ x 0 , x 1 , . . . , x l ? 1 ] ) x_l = H_l([x_0, x_1,...,x_{l-1}]) xl?=Hl?([x0?,x1?,...,xl?1?])
其中 [ x 0 , x 1 , . . . , x l ? 1 ] [x_0, x_1,...,x_{l-1}] [x0?,x1?,...,xl?1?]表示将第 0 , . . . , l ? 1 0,...,l-1 0,...,l?1层输出的特征图进行拼接。由于DenseNet的稠密连接模式,所以称该网络为稠密卷积网络。为了方便表达,将上式中 H l ( . ) H_l(.) Hl?(.)的多个输入表示为一个向量。
上述是ResNets和DenseNets的数学表达式,值得注意的一点是:与ResNets不同,DenseNets从不在特征到达一个层之前通过求和的方式来组合特征,而是将之前层的特征进行拼接。在DenseNets中,对于一个L层的网络,第 l l l层有 l l l个输入,这些输入是 l l l层之前所有层的特征图 ,而 l l l层自己的特征图则传递给之后的所有 L ? l L-l L?l层。因此,一个一个L层的DenseNets网络,有 L ( L + 1 ) / 2 L(L+1) / 2 L(L+1)/2连接(这其实就是等差数列求和: 1 + 2 + . . . . . + L 1+2+ ..... + L 1+2+.....+L),而传统的结构只有 L L L个连接。
- 增长速率:增长速率是作者引入的一个超参数
k
k
k,用来表示每层网络产生的特征图的数量(看原文中的解释
k
k
k其实就是网络的宽度)。如果每个
H
l
H_l
Hl?都产生
k
k
k个特征图,则
l
t
h
l^{th}
lth层就有
k
0
+
k
?
(
l
?
1
)
k_0 + k*(l-1)
k0?+k?(l?1)个特征图作为输入,其中
k
0
k_0
k0?表示输入层的通道数。作者将这里的
k
k
k作为一种超参数引入,并且DenseNet和现存结构的一个很重要的不同是,DenseNet很窄。当使用一个较小的增长速率时,DenseNet就已经在测试数据集上表现出了很好的性能。作者给出了性能好的解释:在DenseNet中,每一层都可以和它之前的所有层的特征图进行拼接,使得网络具有了“集体知识”。可以将特征图看作是网络的全局状态。每一层相当于对当前状态添加
k
k
k个特征图。增长速率控制着每一层有多少信息对全局状态有效。全局状态一旦被写定,就可以在网络中的任何地方被调用,而不用像传统的网络结构那样在层与层之间不断的重复。
如下所示,为DenseNet的结构示意图:

特别值得注意的是,在以前学习的很多网络层结构中,各种操作的顺序往往是先卷积,再BN层,最后是ReLU层,而DenseNet中网络层的操作顺序为先BN层,再ReLU层,最后是卷积层。
如下图为网络层的forward函数:
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat((x, out), dim=1)
return out
- 过渡层:当特征图的尺寸改变时,稠密连接就会出现问题。但是可以通过卷积网络中的下采样层来改变特征图的尺寸。为了便于下采样的实现,作者将网络划分为多个稠密连接的Dense Block,如下图所示:
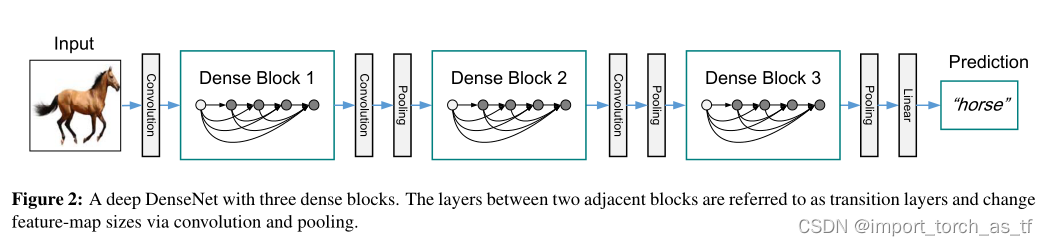
作者将每个Dense Block之间的层称为过渡层,完成卷积、池化操作。每个过渡层由BN层、1x1卷积层和2x2平均池化层组成。 - Bottleneck层:在我给的代码链接中,Bottleneck结构:在3x3的卷积之前加入1x1的卷积。而如果没有Bottleneck结构,则单个网络层只有3x3的卷积操作。然后多个单个网络层的重复堆叠形成Dense Block结构。
根据网络结构图,对DenseNet的几种衍生结构进行说明。
- DenseNet-B:添加Bottleneck结构:在3x3的卷积之前加入1x1的卷积实现降维,可以减少计算量。而这一结构给了DenseNet启发,作者在3x3的卷积之前加入1x1的卷积实现升维,并令1x1的卷积产生 4 k 4k 4k个特征图。
- DenseNet-C:为了简化模型,作者在过度层中减少了特征图的数量。如一个Dense Block有m个特征图,让其经过过渡层生成 Θ m Θm Θm个输出特征图。其中 0 < Θ < = 1 0<Θ<=1 0<Θ<=1,表示压缩系数。定义当 Θ < 1 Θ<1 Θ<1时的 DenseNet为 DenseNet-C。当Bottleneck和过渡层都有 Θ < 1 Θ<1 Θ<1时,定义为DenseNet-BC。
4.实验
- 训练集:CIFAR-10、CIFAR-100、SVHN和ImageNet ILSVARC2012分类数据集
4.1 CIFAR和SVHN数据集
作者使用不同深度
L
L
L和不同增长速率
k
k
k来分别训练DenseNets。在CIFAR和SVHN数据集上的分类结果如下表所示:
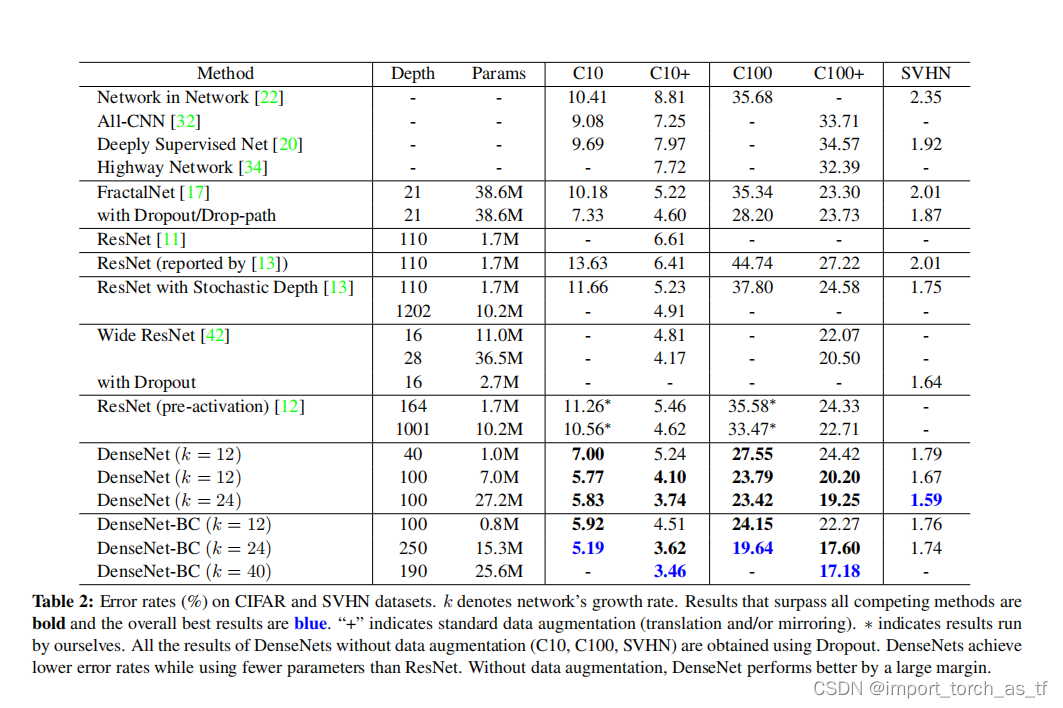
注释:在上表中,加粗的字号表示性能优于现存的模型,蓝色标注表示在该数据集上的最好结果。通过上表可以观察到:DenseNets在准确率、模型容量、参数效率上都取得了优秀的性能。
4.2 ImageNet数据集
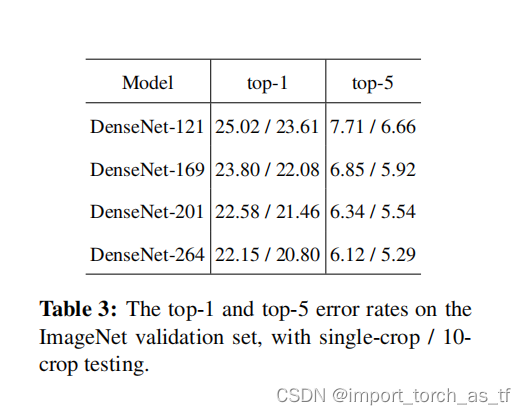
- 作者在ImageNet分类任务上测试了不同深度和增长速率的DenseNet-BC的误差,并且和ResNet结构的性能进行了比较。如下表中记录了DenseNets在ImageNet上的single-crop和10-crop的验证误差:
- DenseNets和ResNets single-crop的top-1验证误差如下图所示。其中,左图以参数量为变量,右图以flops为变量。
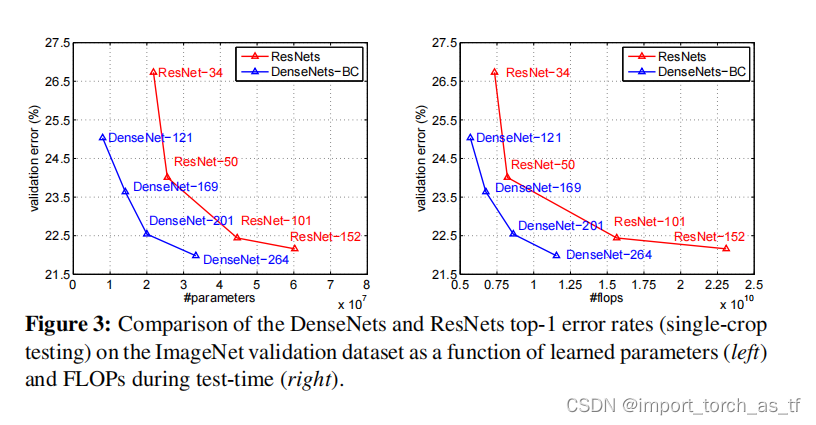
注释:从上图中可以看出:与ResNets相比,在相同性能的前提下,DenseNets的参数量和计算量更小。并且作者只是修改了和ResNets对应的超参数,而不是DenseNets的所有超参数,作者认为修改更多的超参数可以进一步优化DenseNets的性能。