机器学习主要包括两种问题,监督学习和无监督学习。在这篇文章中将介绍什么是监督学习和无监督学习(基本思想)。
监督学习
我们用一个例子介绍什么是监督学习,把正式的定义放在后面介绍。
假如说你想预测房价。目前已经收集了一些房价的数据,把这些数据画出来,看起来是这个样子:横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。基于这组数据,假如你有一个朋友,他有一套 750 平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱。
那么关于这个问题,机器学习算法将会怎么帮助你呢?
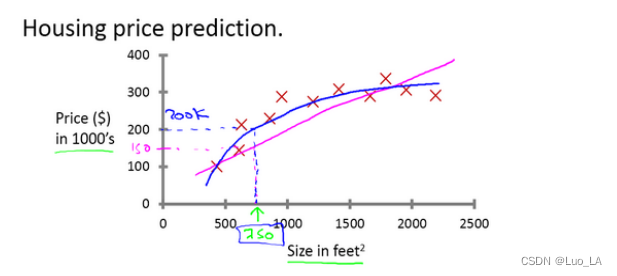
我们应用学习算法,可以在这组数据中画一条直线,或者换句话说,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖$150,000;或者用二次方程拟合一条曲线,可能效果会更好,我们可以从这个点推测出,这套房子能卖接近$200,000。两个方案中有一个能让你朋友的房子出售得更合理。以上就是监督学习的例子。
可以看出,监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。比如你朋友那个新房子的价格。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格。回归这个词的意思是,我们在试着推测出这一系列连续值属性。
再举另外一个监督学习的例子。
假设说你想通过查看病历来推测乳腺癌良性与否。让我们来看一组数据:这个数据中,横轴表示肿瘤的大小,纵轴上,我标出 1 和 0 表示是或者不是恶性肿瘤。我们之前见过的肿瘤,如果是恶性则记为 1,不是恶性,或者说良性记为 0。
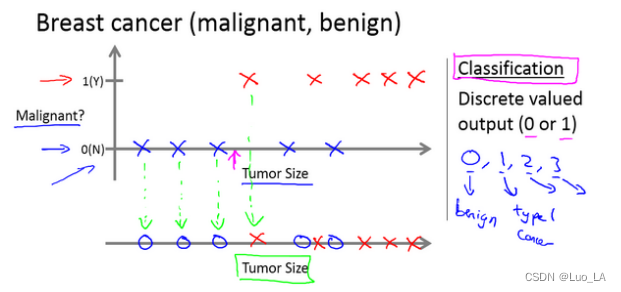
假如有 5 个良性肿瘤样本,在 1 的位置有 5 个恶性肿瘤样本。现在我们有一个朋友很不幸检查出乳腺肿瘤。假设说已知她的肿瘤的大小,那么机器学习的问题就在于,你能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。
分类指的是,我们试着推测出离散的输出值:0 或 1 良性或恶性,而事实上在分类问题中,输出可能不止两个值。比如说可能有三种乳腺癌,所以你希望预测离散输出 0、1、2、3。0 代表良性,1 表示第 1 类乳腺癌,2 表示第 2 类癌症,3 表示第 3 类,但这也是分类问题。
在其它一些机器学习问题中,可能会遇到不止一种特征。举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄。
总结:
监督学习:我们数据集中的每个样本都有相应的“正确答案”,再根据这些样本作出预测,就像房子和肿瘤的例子中做的那样。
回归问题,即通过回归来推出一个连续的输出。
分类问题,其目标是推出一组离散的结果。
无监督学习
对于监督学习数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤,因此我们已经清楚地指导训练集对应的正确答案。
无监督学习中没有任何的标签、或者是有相同的标签、或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。那么对于这种数据集,你能从数据中找到某种结构吗?无监督学习算法可能会把这些数据分成两个不同的聚集簇。所以叫做聚类算法。
聚类应用的一个例子就是在谷歌新闻中。谷歌新闻每天都在,收集非常多的网络的新闻内容。它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
再举一个一DNA 微观数据的例子。基本思想是输入一组不同个体,对其中的每个个体,你要分析出它们是否有一个特定的基因。技术上,你要分析多少特定基因已经表达。所有这些颜色,红,绿,灰等等颜色,这些颜色展示了相应的程度,即不同的个体是否有着一个特定的基因。你能做的就是运行一个聚类算法,把个体聚类到不同的类或不同类型的组(人)。
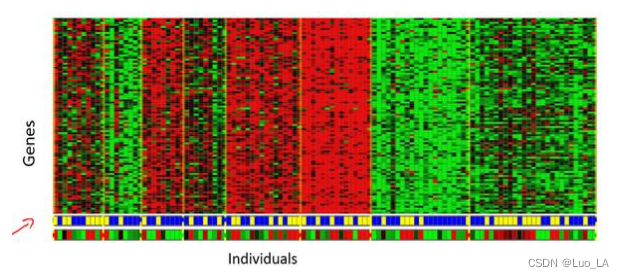
所以这个就是无监督学习,因为我们没有提前告知算法一些信息,比如,这是第一类的人,哪些是第二类的人,还有第三类,等等。只有一堆数据,我们不知道数据里面有什么,不知道谁是什么类型,不知道人们有哪些不同的类型,这些类型又是什么。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类。我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习。