https://arxiv.org/pdf/2105.15203.pdf
文章提出了SegFormer,encoder由金字塔Transformer组成,不使用位置编码,而是使用一个3x3的逐深度卷积。decoder使用了简单的MLP。
因为分类与语义分割有很强的联系,因此设计一个backbone用来分割是很重要的。
思考:Resnet刚开始也是作为分类使用的,然后语义分割也使用Resnet作为backbone,除此以外还有MobileNet。
VIT应用于语义分割有很多架构,而SETR则把VisionTransformer作为语义分割的backbone,PVT则是第一个在Transformer引入金字塔结构。金字塔结构可以产生高分辨率的精细特征图和低分辨率的粗略特征图。
思考:现在很多框架提出目标就是作为backbone来提取特征,传统的卷积作为encoder来提取特征,和transformer作为encoder来提取特征那个效果更好呢?
答案显而易见:如果纯粹为了MIOU,transformer可能更合适,decoder就可以设计的很简单,GPU资源有限的话,Resnet可能更合适,decoder就需要设计的很复杂。
我们看网络的架构:

?1:Segformer相比于VIT可以通过金字塔设计产生类似于卷积的多层特征,这些特征对语义分割来说大有裨益,多层特征图的大小如上图所示。
2:除此以外文章提出了overlapped patch merging。相比于不重叠的设计,重叠的设计可以保存局部连续性。
3:自注意力,为了减少Transformer的计算复杂度,原始的复杂度为N平方。我们通过设计新的方法来减少序列复杂度。

?原始维度为NXC,首先reshape为(N/R,CR),然后CR作为线性层输出,输出为C,这样新的维度就为(N/R,C)。R设置为[64,16,4,1]。
4:Mix-FNN,位置编码对于语义分割没那么重要,之前的文章提出卷积可以通过padding学习位置信息,而Mix-FNN是为了解决padding=0造成的信息缺失。Xin是自注意力的输出。
![]()
?5:轻量化MLP-decoder,该模块只包含MLP层,因此很大的减少了计算量。Decoder设计的如此简单得益于Transformer相比传统卷积有更的大感受野。即在Stage4有更多大的感受野。
注:下采样可以增大感受野,stage4比stage1感受野更大,因为他下采样了四次。

?
?实验设置:
8块特斯拉v100,encoder在imagenet1k上预训练,decoder随机初始化。使用AdamW优化器,学习率为0.00006,使用Ploy优化器策略,不使用tricks。验证阶段将图像的短边调整到训练时候的大小。
1:消融实验:
1.1:模型大小对结果影响,可以看到模型参数越多,效果越好。

?具体看一下每个模型的参数量和在各自数据集上表现:

?decoder参数量仅为encoder的百分之几,且decoder固定时,encoder越大,结果越好。
1.2:mlp的decoder通道对结果影响。

当通道为256时,参数量比较少,计算复杂度最小,且结果已经不错,虽然升高通道,结果会不断提高,但是?升高通道后,计算量会成倍增加,综合考量,C=256是性价比最高的。
1.3:位置编码对结果影响。
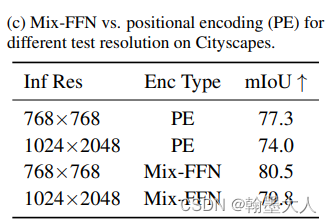
对于不同分辨率,本文的Mix-FFN结果比传统的position encoding高了不少。同时Mix-FFN对于 测试的分辨率变换更加具有鲁棒性。
1.4:感受野大小。
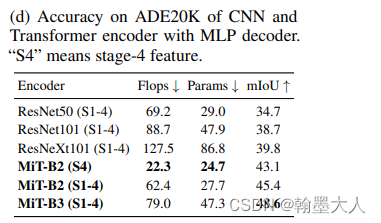
encoder分别采用CNN和MiT,decoder采用相同的MLPdecoder,结果如上,transformer作为encoder的效果高于CNN,原因是CNN不能提供更大的感受野,在全局推理时候就会力不从心。
2:实验对比:SOTA!!!!!!!!!!!!

?2.1对攻击的鲁棒性
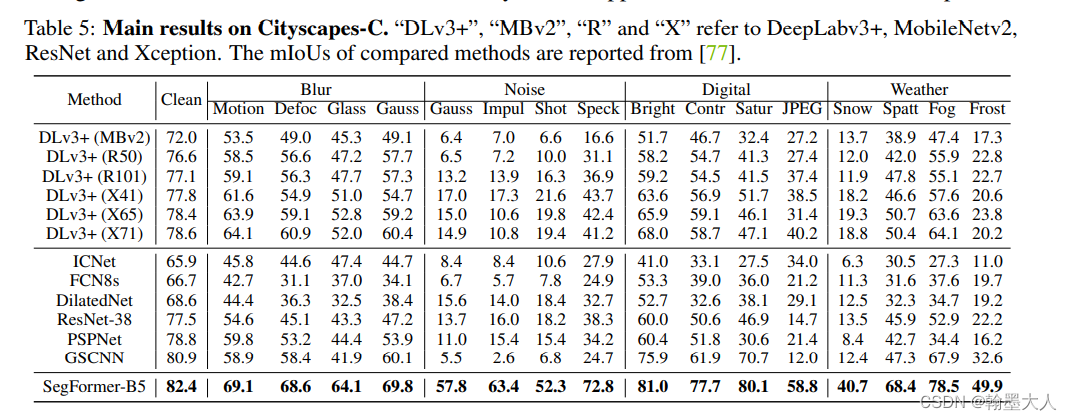
2.2整体的网络配置
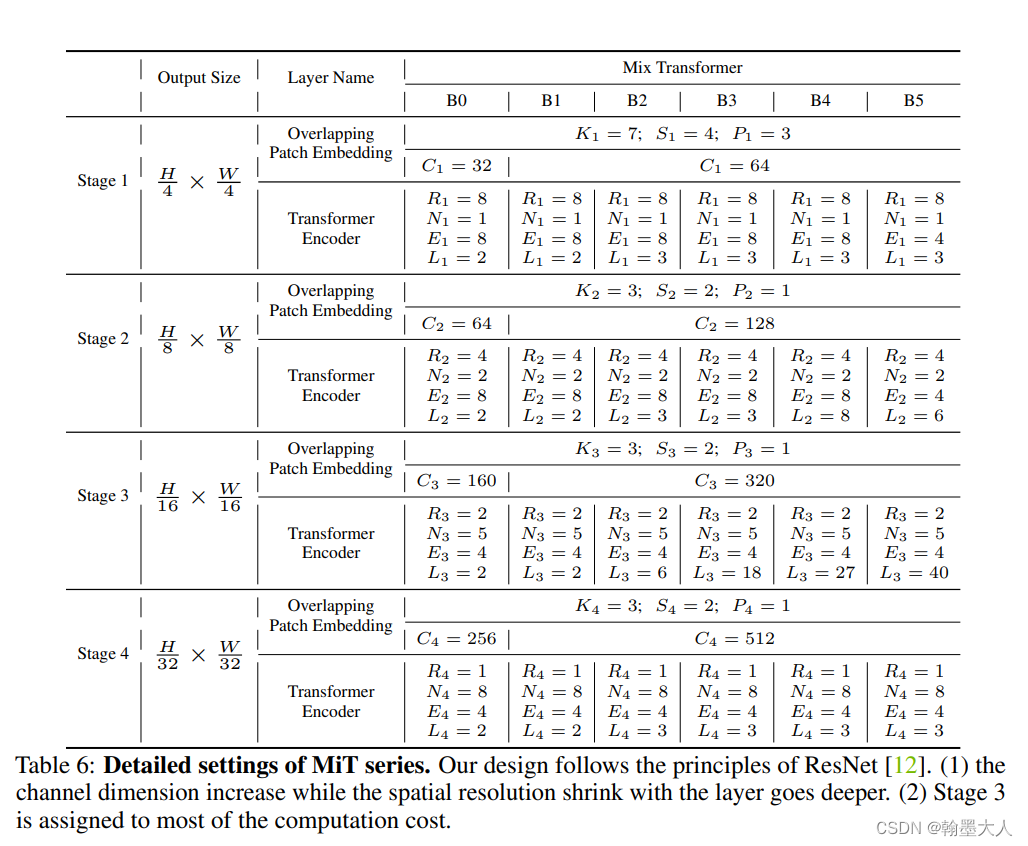 ?
?
?
?