NVRadar:一种实时的雷达障碍检测和占位栅格预测方法
文章目录
- 论文地址:https://arxiv.org/abs/2209.14499
- 源码:暂未公布
- 效果展示:https://youtu.be/WlwJJMltoJY
一、摘要

最近特斯拉提出的Occupancy Networks引起了一些讨论,本篇论文也提出了一个occupy grid预测的网络,不过相关性并不大。回到正题,作者基于毫米波的问题:识别静态目标的性能较差、稀疏的缺点,提出了第一个实时(1.5ms)BEV多任务(障碍检测、可驾驶区域网格预测)网络。Free space定义为可行驶的网格区域。通过引入Lidar的标记数据对毫米波进行监督,能够有效增强毫米波对静态目标的感知能力的同时解决了毫米波数据难以标注的问题。另一方面作者通过预测dense occupancy probability map以生成RDM(radial distance map)进一步生成Free Space Contour用于路径规划。除此之外,在阅读之前可以看一下我之前的一个回答:自动驾驶方向有哪些具体的研究课题,对路径规划比较感兴趣,想问下具体一点的研究课题? - Naca yu的回答 - 知乎
二、相关工作与主要贡献
-
相关工作
-
障碍检测上:分为dense RADAR data cubes和radar points,第一种,也就是Range-Dopper这类稠密的特征虽然特征保留度好,但是如今商业化的雷达大部分仅提供点云数据(经过CRAR处理后),并且为了获得更稠密的特征,需要增加许多天线等升级毫米波,这显然对于如今普遍好几个雷达的商用车辆是不符的,这类方法拥有自己独立的一套体系。第二种,借鉴的Lidar-based方法较多,包括借鉴于centerpoint, pointnet等等,与激光雷达的方法论大同小异。
-
占位栅格生成:
-
Probably Unknown: Deep Inverse Sensor Modelling In Radar
-
Road scene under- standing by occupancy grid learning from sparse radar clusters using semantic segmentation
这两个工作与其相关,感兴趣读者可以进一步阅读,这里不再赘述。
-
-
-
主要贡献:
- 作者提出的NVRadarNet,在仅使用雷达点云数据的情况下(CFAR处理后生成的点云图),在BEV空间能够实现端到端的静态与动态目标检测,并且完成占位栅格的预测任务;
- 提出了一种新的半监督预测行驶区域的方法,仅使用Radar peak detection也就是点云就能够完成稠密的占位栅格预测;
- 能够实现1.5ms的端到端预测,这个时间是在嵌入式GPUNVIDIA DRIVE AGX上,使用TensorRT加速推理得到;
三、模型结构
3.1 整体架构
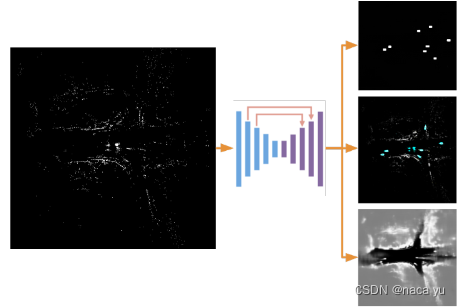
如上图所示,整体结构比较简单,输入是累加多帧的毫米波点云图(800x800, 100mx100m),送入类似于UNet结构的网络中,UNet常用于分割任务中,能够较好结合底层与高层信息,经过多次下采样后的低分辨率信息。能够提供分割目标在整个图像中上下文语义信息,可理解为反应目标和它的环境之间关系的特征。这个特征有助于物体的类别判断,然后经过concatenate操作从encoder直接传递到同高度decoder上的高分辨率信息。能够为分割提供更加精细的特征,生成多尺度语义特征后,将特征分别送入不同的三个检测头,任务分别是:分类、回归、占位栅格预测头。
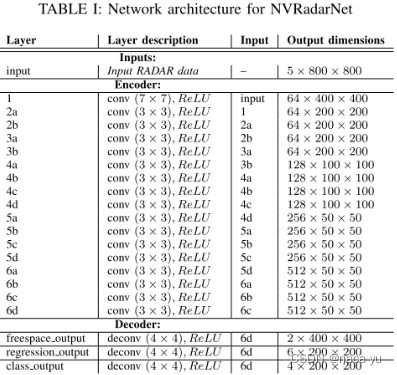
如上图所示,encoder结构及特征维度变化、decoder结构与特征尺度分别上、下部分所示,encoder提供给decoder融合了底层与高层特征的最终特征,decoder也就是head用于解码出所需要的Headmap。
3.2 Head与Loss设计
- Head
作者在BEV二维平面检测和生成Free Space,分别生成的是2D检测框和稠密的占位栅格地图(dense occupancy probability map)。
将Encoder输出的特征图,分别输入三个Head,用于检测、分类、生成Free Space预测,其中regression和classification的HW相同,而freespace的网格更为细密。freespace对100x100m的分割单元为25cm,regression和classification的分割单元大小为50cm,后者和BEVformer等网络设置的grid大小一致,而占位栅格需要的细粒度更高,需要设置两倍的细分精度。
-
对于Regression Head:
- channel=6,包括中心位置,size(w,l),偏航角(sinθ和cosθ),注意这里没有回归高度信息;
-
对于Classification Head:

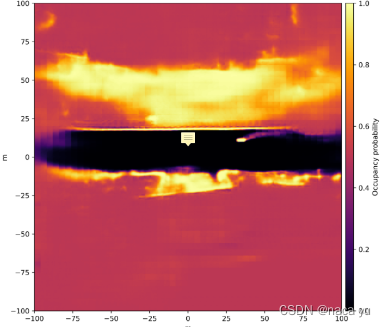
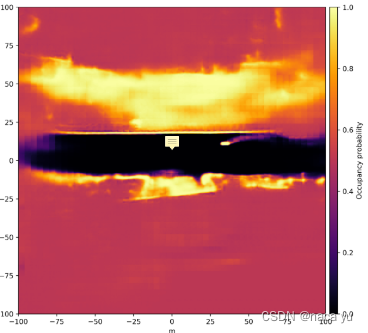
- 对于Inverse sensor model head (ISM,逆向传感器模型):用来将传感器观测值转换为占位栅格概率的网格图,关于如何预测和生成占位栅格图,细节没有多提,具体可以看Probably Unknown: Deep Inverse Sensor Modelling In Radar这篇文章。预测生成的占位栅格图如下图所示,中间黑色的为道路部分,占位的概率大小从黑色到黄色逐渐升高,颜色越亮代表所在栅格存在目标的可能性越大。
- Loss
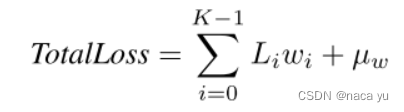
? 总体损失如上图所示,其中,作者采用贝叶斯权重损失计算,K是损失的种类数,这里是3,Li是某个loss的值,wi为需要预测的损失项权值,μw为wi的均值,将整体最小化,最后一项也能够作为正则项避免权值过大。
- 检测头损失计算:分别为交叉熵损失、L1损失
- Inverse sensor model head (ISM,逆向传感器模型) 损失计算:
? inverse sensor model loss用于占位栅格网络的损失,最后一项损失为Probably Unknown: Deep Inverse Sensor Modelling In Radar, ICRA2019中提出,如下图所示,由左侧的Range-Doppler-Matrix(由极坐标系下经过插值转换到笛卡尔坐标系下)生成的右侧的Label作为GT,监督Inverse sensor model head预测占位栅格图,生成的占位栅格图在沿中心的射线上高于某个threshhold的栅格作为occupied grid(将网格的值赋值为1),遍历360°的射线后生成的栅格图与GT计算loss。
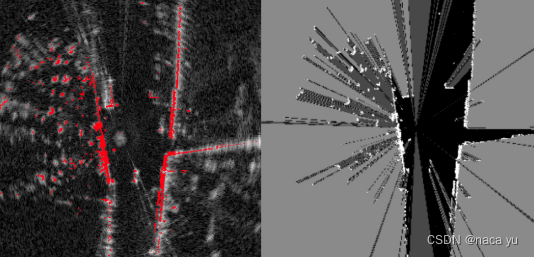
浅提一下“Probably Unknown: Deep Inverse Sensor Modelling In Radar(ICRA2019)”这篇论文,论文使用深度神经网络将原始雷达扫描转换为占用概率栅格地图,使用激光雷达生成的部分占用标签进行自我监督,优于标准的CFAR滤波方法,能够成功地将世界划分为占用的和空闲的空间,泡泡机器人有一篇简单的解读:https://www.sohu.com/a/351948334_715754
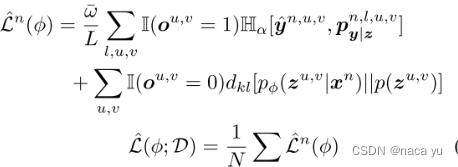
上图是loss计算的细节,可以看到loss综合考虑了y=1和y=0也就是占据和非占据(free space)两种损失。
四、一些论文细节
4.1 数据处理与Label生成
-
雷达数据预处理
-
对毫米波点云进行量化采样,生成voxel网格数据,对重复投影到同一位置的点云采用均值池化的方式
-
累计8个雷达的0.5s内的扫描点云稠密性,通过运动补偿完成多帧雷达累计
-
输入维度为:Doppler, elevation angle, RADAR cross section (RCS), azimuth angle and the relative detection timestamp
-
将RCS小于?40 dBm的雷达点云过滤
-
小于4个毫米波点云投射的目标进行滤除
-
-
生成Detection Head的GT数据:Label Propagation(由Lidar生成用于目标检测的GT)
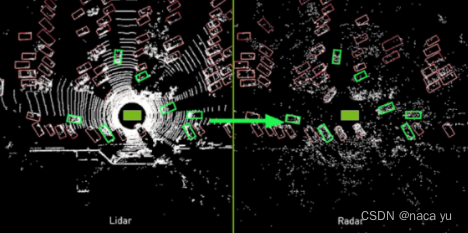
- 如下图所示,作者将Lidar标注好的2D GT,进行筛选,条件如下:1. 少于4个point在内的bbox去除;2. 反射强度<?40 dBm的点云移除;左右两侧为筛选前后的对比图,这里我认为是为了解决:一是radar数据难以标注的问题,二是能够通过Lidar模态的数据监督将检测静态目标性能提升。
-
生成Inverse sensor model head的Label:Free Space Label Generation
-
将occupy grid分为:Observed and free,Observed and occupied,Unobserved,Partially observed四类网格
-
激光雷达数据辅助生成Free Space Label,将多线(这里是128线)的点云投射到地面,去除道路的点云以生成free space label,因为路面由于多线雷达的多面扫描会使可行驶的路面被认作为障碍物,因此要去除道面点云,以生成准确的Free Space监督信号
-
总结来说,就是分为几个区间[ego,first return), (first return, last_return), (last_return, border],分别标记为:黑色,深灰色,灰色,颜色由深变浅,白色就是返回的有目标的点,如下图所示:
-

4.2 正负样本分配
- 作者使用OneNet的匹配方法,同时考虑尺寸和类别信息用于正样本分配,同样是一种Anchor-free的检测方法。
4.3 数据集

- 作者使用Nvidia的自动驾驶数据集,数据集未公开,只说明了基本的信息,对比而言,nuScenes作为目前较大的自动驾驶数据集,只有15小时的采集,作者的内部数据集有几百个小时的采集;
- 激光雷达128线,8个毫米波雷达Continental ARS430,相比NuScenes的408更加稠密,综合性能有提升;
4.4 题外话:ISM输出转化为RDM图(Converting ISM Head Output to a Radial Distance Map)
自动驾驶中并不是直接利用生成的占位栅格概率图,一些方法通常将Free Space经过一系列转化,生成一种“可行驶区域的边界轮廓”用于自动驾驶的路径规划,这是作者额外介绍的应用。ISM生成的占位栅格概率图用于Loss的计算而不是这一节所介绍的边界轮廓。转换过程如下:
- 生成占位栅格地图:Inverse sensor model head (ISM,逆向传感器模型)生成概率栅格地图,亮度由暗到亮,存在物体的概率逐渐上升
-
转化到极坐标系下:通过近邻采样方法,将笛卡尔坐标系的栅格转化到当前的极坐标系中,如下图所示,y由上到下,分别是-180度到180度,代表笛卡尔坐标系中心向外的一条射线(至边界),x从左到右代表0-100m的距离

-
根据上图的极坐标系,沿着每个角度,将其作为一条射线,将遇到的第一个概率大于阈值的栅格作为最远的点,并以此遍历360°,生成下图的RDM(radial distance map)
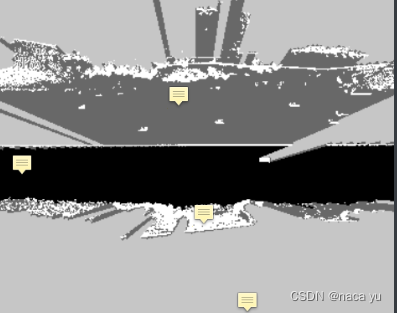
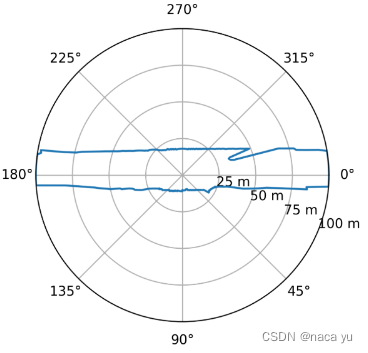
- 在生成了上述RDM图后,可以进一步得到如下在极坐标系下的简化后的可行区域图,这就是最后所求的车辆可行驶区域的边界图,这是在极坐标系下的表示,这个图可以与RDM图相转换。
四、总结评价
4.1 实验

可以看出,还没有与作者较为合适的网络用于对比,作者在2D检测领域并没有进行对比实验,只在Free Space生成上与OccupancyNet做了对比试验。
Occupancy probability po < 0.4作为占位栅格的阈值,大于等于此值的认为其是被占据的栅格。实验总共分为两部分(2D检测和Free Space prediction),每一部分都在内部数据集和NuScenes数据集上做了实验,由于两个数据集的设置大部分是一致的,所以这里仅介绍在内部数据集上的实验。
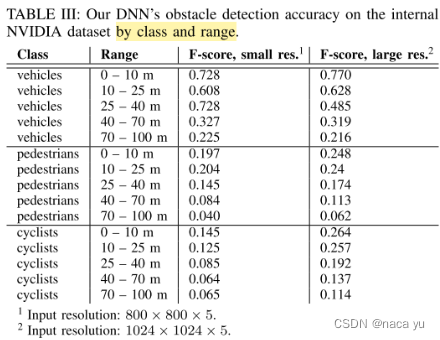
- 在检测距离增加时,明显的可以看到精度的损失,同时增加分辨率可以有效增加对于行人等小目标的检测精度,减小量化损失
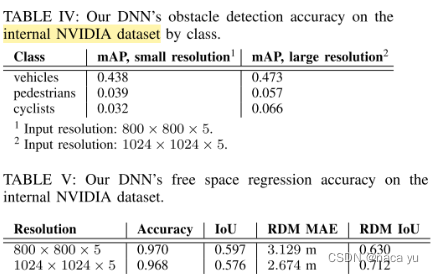
- 这里只介绍在作者内部数据集的实验:增加输入分辨率可以有效提高精度,这降低了量化采样的损失,但是在Free Space生成上效果不大
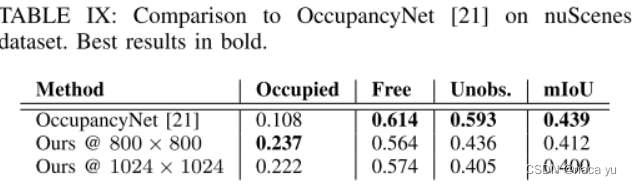
- 在NuScenes数据集上与OccupancyNet的对比,虽然Ocuupied有两倍的提升,但是其他性能都有下降
4.2 评价(均为个人推测,看看就行)
- 本文的一个亮点,就是实时、多任务,作者在英伟达的嵌入式自动驾驶设备上进行了一系列优化并达到了1.5ms远大于实时的速度要求,可以满足实时性
- 作者并没有在实验中验证前文中提到的对于静态目标、遮挡目标等的效果提升,大部分实验只是在摆出自己的实验效果,没有做检测任务上的对比实验,感觉实验还是缺不少的
- 作者使用Lidar数据标注GT用于Radar的任务标签,会存在很多问题:一个是Lidar visible的目标Radar有些事invisible的,这样会导致radar检测假阳性会多一些,二是毫米波的透视能力强,加上多路干扰会检测到一些遮挡的目标,所以使用Lidar的标签会导致毫米波的透视性能下降,顺便提一句,在之前的一个工作有说过并解决了这个问题,可以看我之前写过的:毫米波雷达在检测、分割、深度估计等多个方向的近期工作及简要介绍 - Naca yu的文章 - 知乎,在里面的一个工作 “Radar Occupancy Prediction With Lidar Supervision While Preserving Long-Range Sensing and Penetrating Capabilities” 解决了这个问题。
参考文献
Radar Occupancy Prediction With Lidar Supervision While Preserving Long-Range Sensing and Penetrating Capabilities
Road scene under- standing by occupancy grid learning from sparse radar clusters using semantic segmentation
Probably unknown: Deep inverse sensor modelling radar
OneNet:https://zhuanlan.zhihu.com/p/339441508
by occupancy grid learning from sparse radar clusters using semantic segmentationProbably unknown: Deep inverse sensor modelling radar
OneNet:https://zhuanlan.zhihu.com/p/339441508