Ŀ¼
һ��ǰ��
ICLR��Ϊ����ѧϰ����Ķ���,�������ICLR2023 Openreview������Ͷ�����,ͨ��2022��2023�����Ĺؼ��ʡ������Ƶ�ʵ���Ϣ�Ŀ��ӻ��Ƚϡ�����ǰʮ�Ĺؼ���Ƶ������Ƶ������,�����Ϻ�ȥ�걣��һ��,�����������ɴ�𡣵��ǿ������Կ���ǰ�����ؼ��ʵ�Ƶ�ʲ�����١� ����˼����representation learning��һ�ؼ����������ػ�ǰ��,�ٴ�Ϊ������ѧϰ�������项(ICLR)������graph neural network��һ�ؼ������ǵ���һ��,��representation learning������λ��,�������ȥ���Ƶ����Ȼ�𱬡�GCN��ΪGNN�ı���,��Ȼ��һ�������ĵ����š�
| Keyword | 2022 | 2023 |
|---|---|---|
| reinforcement learning | 1 | 1 |
| deep learning | 2 | 2 |
| representation learning | 4 | 3 |
| graph neural network | 3 | 4 |
| transformer | 5 | 5 |
| federate learning | 7 | 6 |
| self-supervised learning | 6 | 7 |
| contrastive learning | 10 | 8 |
| robustness | 9 | 9 |
| generative model | 8 | 10 |
�������仯������,����graph neural network�ڹؼ���Ƶ������������һ��,�����ڱ�����graphȴ����һ����
| Title | 2022 | 2023 |
|---|---|---|
| representation | 1 | 1 |
| graph | 3 | 2 |
| data | 6 | 3 |
| reinforcement | 2 | 4 |
| transformer | 7 | 5 |
| training | 5 | 6 |
| image | 10 | 7 |
| efficient | 9 | 8 |
| language | 15 | 9 |
| federate | 14 | 10 |
����ͼ�ĸ���
������GNN֮ǰ,���������˽�һ��ʲô��ͼ���ڼ������ѧ��,ͼ���ɽڵ�ͱ���������ɵ�һ�����ݽṹ��ͼG����ͨ���ڵ㼯��V���������ı�E����������������ͼ��ʾ:
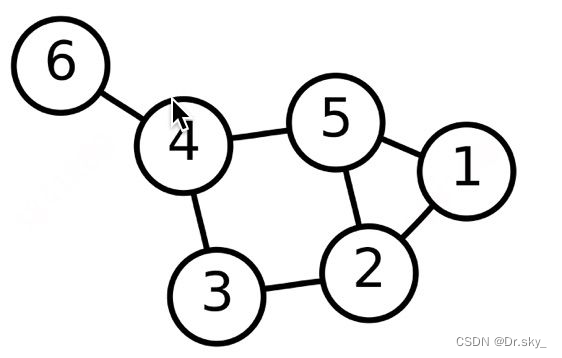
����GNNͼ������
GNNȫ��----ͼ������,����һ��ֱ��������ͼ�ṹ�ϵ������硣���ǿ���ͼ�е�ÿһ���ڵ� V �����������,��ÿһ���� E ���������������ij����ϵ,���нڵ���ɵĹ�ϵ����������ͼ U��
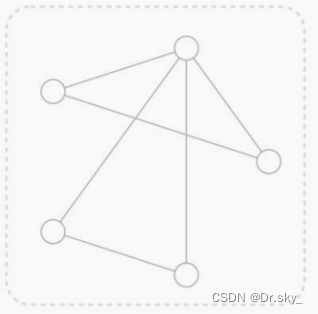

��Ԫ��Ķ���
ͼG��һ�������Ԫ��(V,E),����V��Ϊ����(Vertices Set),E��Ϊ��(Edges set),E��V���ཻ���������д��V(G)��E(G)��
E��Ԫ�ض��Ƕ�Ԫ��,��(x,y)��ʾ,����x,y��V��
��Ԫ��Ķ���
ͼG��ָһ����Ԫ��(V,E,I),����V��Ϊ����,E��Ϊ��,E��V���ཻ;I��Ϊ��������,I��E�е�ÿһ��Ԫ��ӳ�䵽 �����e��ӳ�䵽(u,v),��ô�Ʊ�e���Ӷ���u,v,��u,v�����e�Ķ˵�,u,v��ʱ����e���ڡ�ͬʱ,��������i,j��һ����������u,���i,j����u���ڡ�
��������ͼ�������Ŀ�ľ�����������
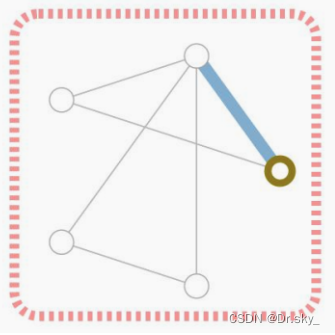
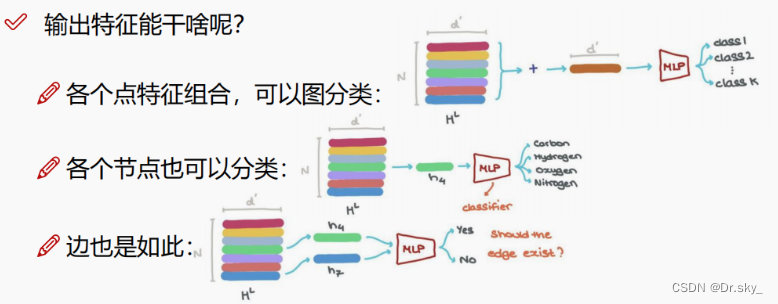 GNN����ҪĿ�ľ�����ͼ�ṹ��ȡ����,���������ڵ����ǹ���Ԥ���������Լ�������
GNN����ҪĿ�ľ�����ͼ�ṹ��ȡ����,���������ڵ����ǹ���Ԥ���������Լ�������
�ġ�GNN��CNN��RNN������
������ȡ������������,��ΪʲôҪ����ͼģ������ȡ��?CNN�ľ�����RNN�ĵݹ鷽ʽ������?
�𰸻��治��,����˵ʮ���鷳��?
��ΪGNN��������������ʵ���ǽṹ�������̶������ݽṹ,��CNN�����ͼ�����ݺ�RNN������ı����ݵĸ�ʽ���ǹ̶���,������Ȼ���ܻ�Ϊһ̸�����,��Ա����ṹ���˴˹�ϵ�����̶��Ľڵ�����,������Ҫ����ͼ�ṹ���������ǵ�������ϵ��
�塢GNNԭ��
5.1 �ڽӾ���
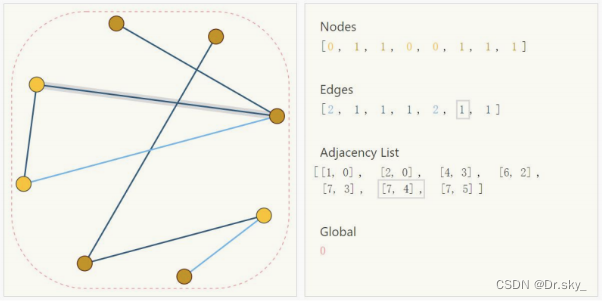
���������ڽӾ���(Adjacency Matrix)�ĸ���,������ʾ�ڵ���ڵ������ӹ�ϵ,��Edge�Ĺ�ϵ,����ľ�����ʽ����ͼ��ʾ:

5.2 �ۺϲ���
GNN������һ����ÿ���ڵ����ʼ���������ͱ�ʾ�ڵ���ϵ���ڽӾ���,����������������Ϣ,���������Ǿۺϲ����ˡ���ν�ľۺ�,��ʵ���ǽ��ܱ���ڵ� Vi �й����Ľڵ�{Va , Vb , . . .}��Ȩ��Vi��,����һ���������¡�ͬ��,��ͼ�е�ÿ���ڵ���оۺϲ���,��������ͼ�ڵ��������
�ۺϲ����ķ�ʽ���ֶ���,�ɸ�������IJ�ͬ����ѡ��,����ͼ��ʾ: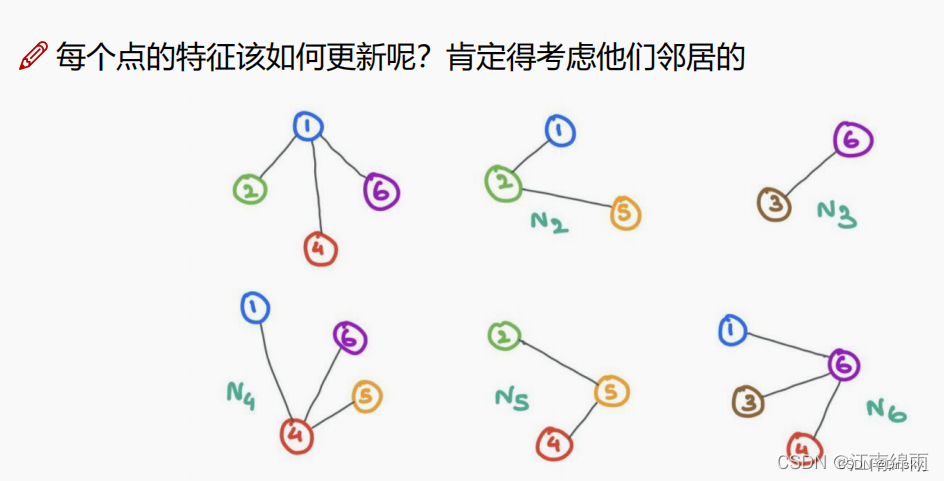

��Ȼ�����ͼ�ڵ��������һ�ξۺϲ�����,����Ҫ�ٽ���һ�� w �ļ�Ȩ,����� w ��Ҫ�����Լ�ѧϰ��
5.3 ������
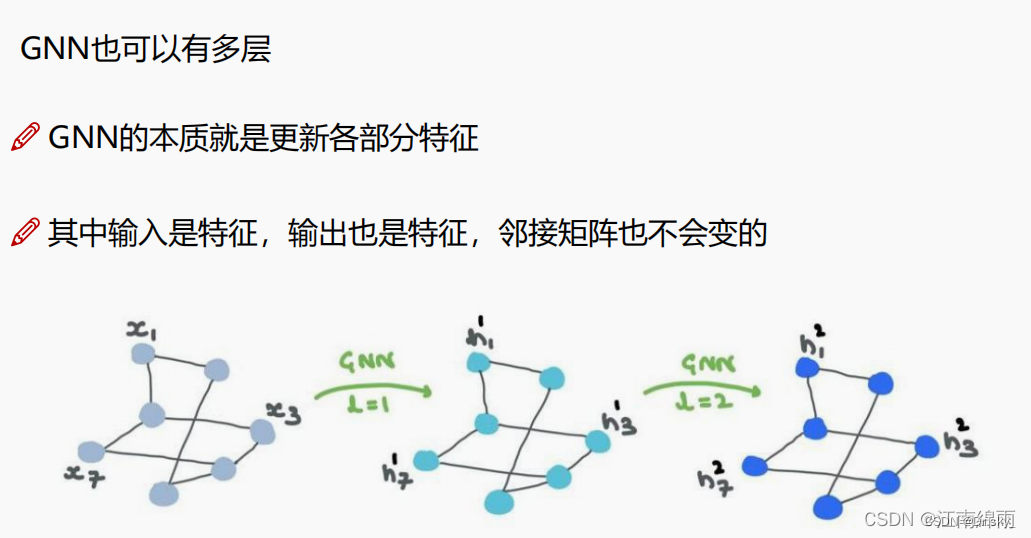
CNN,RNN�������ж����,��ôGNNҲ��Ȼ���ԡ�һ��ͼ�ڵ�ۺϲ����� w ww ��Ȩ,��������Ϊһ��,�������ظ����оۺϡ���Ȩ,���Ƕ������ˡ�һ��GNNֻҪ3~5�㼴��,����ѵ��GNN������Ҫ��ܵ͡�����ͼ��ʾ:
����GCNͼ��������·
����:Semi-Supervised Classification with Graph Convolutional Networks(ICLR2017)
(https://arxiv.org/abs/1609.02907)

GCN,ͼ����������,ʵ���ϸ�CNN������һ��,����һ��������ȡ��,ֻ�������Ķ�����ͼ���ݡ�GCN����������һ�ִ�ͼ��������ȡ�����ķ���,�Ӷ������ǿ���ʹ����Щ����ȥ��ͼ���ݽ��нڵ����(node classification)��ͼ����(graph classification)����Ԥ��(link prediction),������˳��õ�ͼ��Ƕ���ʾ(graph embedding),�ɼ���;�㷺��������������Զ���,��GCN�����������з��ⷢ�ȡ�
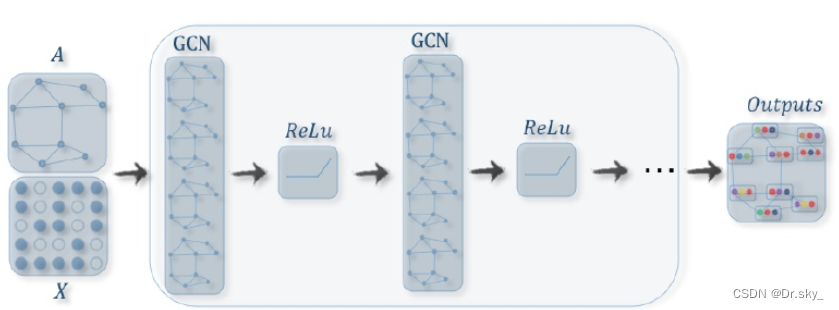
GCN�ĺ��IJ�����ʲô����:
����������ͷ��һ��ͼ����,������N���ڵ�(node),ÿ���ڵ㶼���Լ�������,��������Щ�ڵ���������һ��N��Dά�ľ���X,Ȼ������ڵ�֮��Ĺ�ϵҲ���γ�һ��N��Nά�ľ���A,Ҳ��Ϊ�ڽӾ���(adjacency matrix)��X��A��������ģ�͵����롣
����ͼ:
Labeled graph(��ǩͼ),ͼ��·���ͽڵ��ǩ
Degree matrix(�Ⱦ���) ,ÿ���ڵ�Ķ�,����ÿ���ڵ����ӵĽڵ�����
Adjacency matrix(�ڽӾ���),ÿ���ڵ����ӵĽڵ�λ��
Laplacian matrix(������˹����),�����ɢ������˹���Ӷ���ͼ��������˹����Ϊ�ڵ����ھӽڵ�������Ϣf����ĺ�
L = D - A

GCNҲ��һ����������,���IJ����֮��Ĵ�����ʽ��:
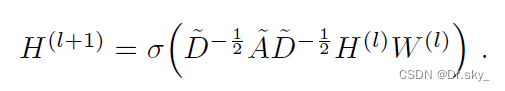
�����ʽ��:?
- A����=A+I,I�ǵ�λ����
- D������A���˵ĶȾ���(degree matrix),��ʽΪ
- H��ÿһ�������,���������Ļ�,H����X
- ���Ƿ����Լ����
�����Ȳ��ÿ���ΪʲôҪ����ȥ���һ����ʽ����������ֻ��֪��:
�������,�ǿ���������õ�,��ΪD������A�������,��A�����ǵ�����֮һ��
���Զ��ڲ���Ҫȥ�˽���ѧԭ����ֻ��Ӧ��GCN�����ʵ�����������˵,��ֻ��֪��:Ŷ,���GCN�����һ��ţ�ƵĹ�ʽ,�������ʽ�Ϳ��Ժܺõ���ȡͼ�������������,�Ͼ�����ʲô���鶼��Ҫ֪���ڲ�ԭ��,���Ǹ�����������ġ�
Ϊ��ֱ������,�����������е�һ��ͼ:
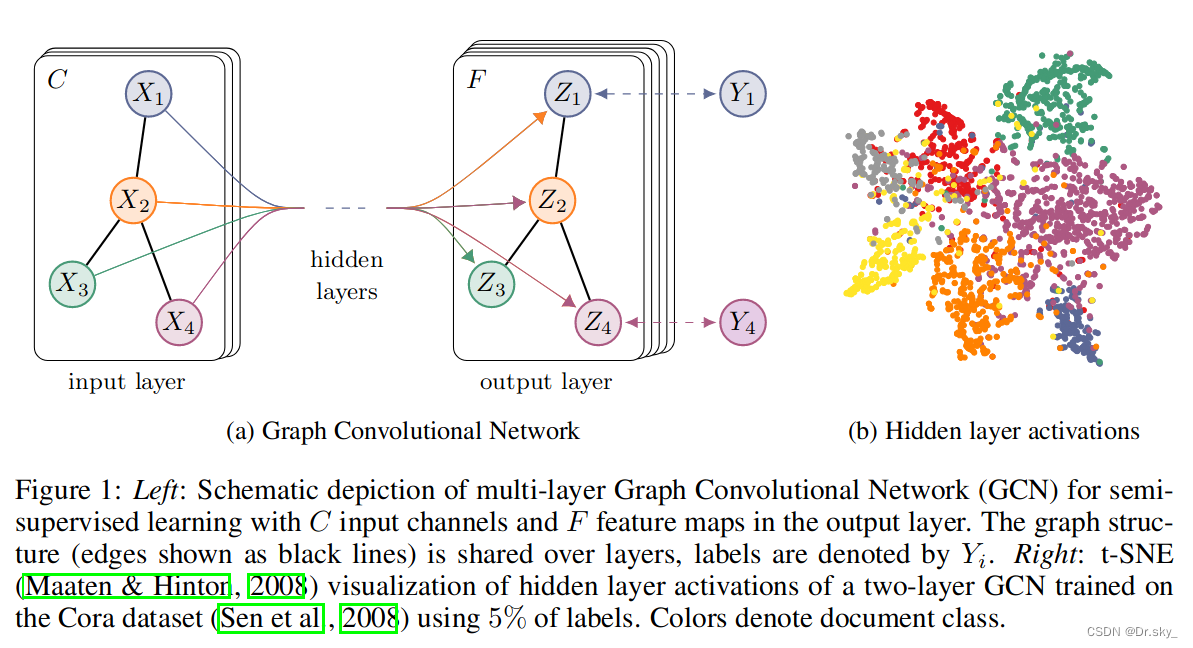 ��ͼ�е�GCN����һ��ͼ,ͨ�����ɲ�GCNÿ��node��������X�����Z,����,�����м��ж��ٲ�,node֮������ӹ�ϵ,��A,���ǹ����ġ�
��ͼ�е�GCN����һ��ͼ,ͨ�����ɲ�GCNÿ��node��������X�����Z,����,�����м��ж��ٲ�,node֮������ӹ�ϵ,��A,���ǹ����ġ�
�������ǹ���һ�������GCN,������ֱ����ReLU��Softmax,������������Ĺ�ʽΪ:
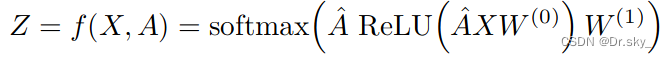
���,����������д���ǩ�Ľڵ����cross entropy��ʧ����:?
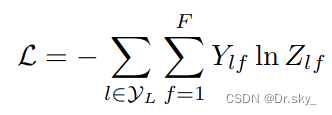
�Ϳ���ѵ��һ��node classification��ģ���ˡ����ڼ�ʹֻ�к��ٵ�node�б�ǩҲ��ѵ��,���߳����ǵķ���Ϊ��ල���ࡣ
��Ȼ,��Ҳ�������������ȥ��graph classification��link prediction,ֻ�ǰ���ʧ�������仯һ�¼��ɡ�
���յIJ�����������ʽ:
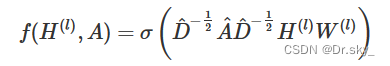
��Ϊ��ʹ��ѵ��,��ȫʹ�������ʼ���IJ���W,GCN��ȡ�������������Լ�ʮ��������!���CNN��ѵ������ȫ��һ����,���߲�ѵ���Ǹ����ò���ʲô��Ч�����ġ�
���ǿ�����ԭ��:

Ȼ����������һ��ʵ��,ʹ��һ�����ֲ���Ա�Ĺ�ϵ����,ʹ�������ʼ����GCN����������ȡ,�õ�����node��embedding,Ȼ����ӻ�:
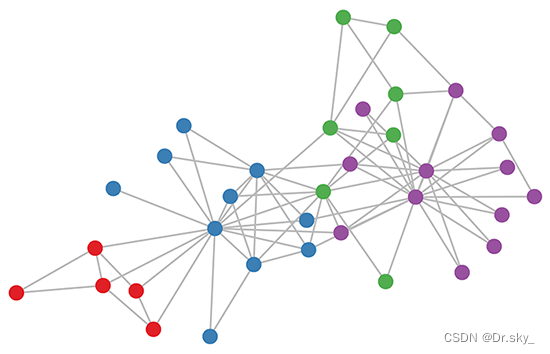
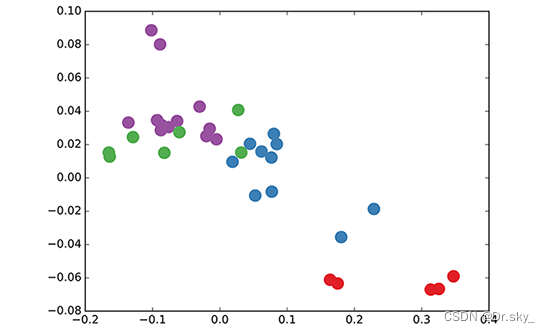
���Է���,��ԭ������ͬ����node,����GCN����ȡ����embedding,�Ѿ��ڿռ����Զ������ˡ������־�����,���Ժ�DeepWalk��node2vec���־�������ѵ���õ���node embedding��Ч�������ˡ�
˵�Ŀ���һ��,������û��ʼ,GCN���Ѿ����յ��ˡ���ûѵ�����Ѿ�Ч����ô��,�Ǹ������ı�ע��Ϣ,GCN��Ч���ͻ���ӳ�ɫ��
��������GCN�ĵ��:
���ںܶ�����,���ǿ���û�нڵ������,���ʱ�����ʹ��GCN��?���ǿ��Ե�,�����������߶��Ǹ����ֲ�����,���õķ�����������λ���� I �滻�������� X��
��û���κεĽڵ����ı�ע,����ʲô�����ı�ע��Ϣ,����ʹ��GCN��?��Ȼ,����ǰ�潲��,��ѵ����GCN,Ҳ����������ȡgraph embedding,����Ч����������
GCN����IJ������ٱȽϺ�?���ĵ���������GCN������ȵĶԱ��о�,�����ǵ�ʵ���з���,GCN�������˶�,2-3���Ч���ͺܺ��ˡ�
�ߡ�GCN��Pytorchʵ��
7.1 ���ݼ�����
1. ���ݼ��ṹ
��������ʹ�õ����ݼ�����Cora���ݼ����ص�ַhttps://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz
�ܹ��������ֹ���:cora.content cora.cites ��README��
README: �����ݼ����ݵ�����;
cora.content: ���������ÿһƪ���ĸ��Զ�������Ϣ;
���ļ��ܹ�����2078��,ÿһ�д���һƪ����,�����ı�š����Ĵ�����(1433ά)�����ĵ���������������
cora.cites: ��������и�����֮�������ü�¼
���ļ��ܹ�����5429��,ÿһ������ƪ���ĵı��,��ʾ�ұߵ�����������ߵ����ġ�
2. ���ݼ����ݷ���
�����ݼ��ܹ���2078������,����ÿ��������Ϊһƪ���ġ�����README��֪,���е����ı���Ϊ��7�����,�ֱ�Ϊ:
���ڰ��е�����???????????????? Case_Based
�����Ŵ��㷨������????????? Genetic_Algorithms
���������������????????? Neural_Networks
���ڸ��ʷ���������????????? Probabilistic_Methods
����ǿ��ѧϰ������????????? Reinforcement_Learning
���ڹ���ѧϰ������????????? Rule_Learning
���������������????????????? Theory
����,Ϊ���������ĵ����,ʹ��һ��1433ά�Ĵ�����,��ÿһƪ���Ľ�������,��������ÿ��Ԫ�ض�Ϊһ�������Ƿ��������г���,���������Ϊ��1��,����Ϊ��0����
7.2 �������
��������(������ϴ���github��)
1. utils.py
import numpy as np
import scipy.sparse as sp
import torch
#���������봦��
def encode_onehot(labels):
# �����еı�ǩ���ϳ�һ�����ظ����б�
classes = set(labels) # set() ��������һ�������ظ�Ԫ�ؼ�
'''enumerate()������������,��������i��ֵc��
��һ�佫string���͵�label��Ϊint���͵�label,����ӳ���ϵ
np.identity(len(classes)) Ϊ����һ��classes�ĵ�λ����
����һ���ֵ�,����Ϊ label, ֵΪ����������(����֮ǰ���ɵľ����е�ijһ��)'''
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in
enumerate(classes)}
# Ϊ���еı�ǩ������Ӧ�Ķ�����
# map() ������ṩ�ĺ�����ָ��������ӳ�䡣
# ��һ�佫string���͵�label�滻Ϊint���͵�label
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
return labels_onehot
#���ݼ��غʹ���
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
#���ݰ���id,features��labels
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
#�ڵ������,ά��Ϊ 2708 * 1433,����Ϊ np.ndarray
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
#�ڵ�ı�ǩ,�ܹ�����7�����,����Ϊ np.ndarray
labels = encode_onehot(idx_features_labels[:, -1])
# build graph
#�ڵ��id
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
#ÿ��id���б��
idx_map = {j: i for i, j in enumerate(idx)}
#
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape) #map������ṩ�ĺ�����ָ��������ӳ��,flatten()���ǽ���һά
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features)
adj = normalize(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
#������һ������
def normalize(mx):
"""Row-normalize sparse matrix""" #��ϡ��������������
rowsum = np.array(mx.sum(1)) #��õ�һ��(2708,1)�ľ���
r_inv = np.power(rowsum, -1).flatten() #����Ԫ����-1�η�
# �ڼ��㵹����ʱ�����һ������,���ԭ����ֵΪ0,���䵹��Ϊ�����,�����Ҫ��r_inv��������ֵ��������,����Ϊ0
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
#���ȼ��㺯��
def accuracy(output, labels):
# ʹ��type_as(tesnor)������ת��Ϊ�������͵�����
preds = output.max(1)[1].type_as(labels)
# ��¼����preds��label eq:equal
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
#��scipyϡ�����ת��ΪTorchϡ������
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
"""
numpy�е�ndarrayת����pytorch�е�tensor : torch.from_numpy()
pytorch�е�tensorת����numpy�е�ndarray : numpy()
"""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
2. models.py
import torch.nn as nn
import torch.nn.functional as F
from pygcn.layers import GraphConvolution
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid) #������1:���������Ϊnfeat,ά����2708,���������Ϊnhid,ά����16
self.gc2 = GraphConvolution(nhid, nclass) #������2:���������Ϊnhid,ά����16,���������Ϊnclass,ά����7(�����Ľ��)
self.dropout = dropout
def forward(self, x, adj): #forward����ǰ��������,���յõ�������ǰ�����ķ�ʽΪ:relu�C>fropout�C>gc2�C>softmax
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return F.log_softmax(x, dim=1)
3. layers.py
import math
import torch
from torch.nn.parameter import Parameter
from torch.nn.modules.module import Module
#layers����Ҫ������ͼ����ʵ�־��������IJ�,������CNN�еľ�����,ֻ��һ�������
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
#GraphConvolution��Ϊһ����,������Ҫ������������ԡ���Ҫ����������������in_feature���������out_feature��������,
# �Լ�Ȩ��weight��ƫ������bias��������,ͬʱ�������������ʼ���ķ���
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
#Ϊ����ÿ��ѵ�������ij�ʼ���������ܵ���ͬ,�Ӷ�����ʵ�����ĸ���,�������ù̶����������������
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1)) #��ƫ��
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
#�˴���Ҫ������DZ����ǰ��,ͨ�����õ��� A ? X ? W A * X * WA?X?W�ļ��㷽��������A��һ��sparse����,�������X���о����Ľ��Ҳ��ϡ�����
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
#__repr__()���������ʵ�������������������ҽ��ܡ��ķ���,Ĭ�������,���᷵�ص�ǰ����ġ�����+object at+�ڴ��ַ��,
# ������Ը÷���������д,����Ϊ�������Զ��������������Ϣ
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
4. train.py
from __future__ import division
from __future__ import print_function
import time
import argparse
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
from pygcn.utils import load_data, accuracy
from pygcn.models import GCN
import matplotlib.pyplot as plt
# Training settings
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False,
help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False,
help='Validate during training pass.')
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
parser.add_argument('--epochs', type=int, default=200,
help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.01,
help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4,
help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=16,
help='Number of hidden units.')
parser.add_argument('--dropout', type=float, default=0.5,
help='Dropout rate (1 - keep probability).')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data()
# Model and optimizer
model = GCN(nfeat=features.shape[1],
nhid=args.hidden,
nclass=labels.max().item() + 1,
dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),
lr=args.lr, weight_decay=args.weight_decay)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
def train():
loss_history = []
val_acc_history = []
t = time.time()
model.train()
if not args.fastmode:
# Evaluate validation set performance separately,
# deactivates dropout during validation run.
model.eval()
output = model(features, adj)
t_total = time.time()
for epoch in range(args.epochs):
optimizer.zero_grad()
output = model(features, adj)
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
loss_history.append(loss_val.item())
val_acc_history.append(acc_val.item())
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.item()),
'acc_train: {:.4f}'.format(acc_train.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}s'.format(time.time() - t))
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
return loss_history,val_acc_history
def test():
model.eval()
output = model(features, adj)
# test_mask_logits = output[mask]
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
#����loss��acc����
def plot_loss_with_acc(loss_history, val_acc_history):
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(range(len(loss_history)), loss_history,
c=np.array([255, 71, 90]) / 255.)
plt.ylabel('Loss')
ax2 = fig.add_subplot(111, sharex=ax1, frameon=False)
ax2.plot(range(len(val_acc_history)), val_acc_history,
c=np.array([79, 179, 255]) / 255.)
ax2.yaxis.tick_right()
ax2.yaxis.set_label_position("right")
plt.ylabel('ValAcc')
plt.xlabel('Epoch')
plt.title('Training Loss & Validation Accuracy')
plt.show()
# Train model
loss, val_acc = train()
plot_loss_with_acc(loss, val_acc)
#Testing
test()
# ���Ʋ������ݵ�TSNE��άͼ
output = model(features, adj)
output = output.cpu()
output = output[idx_test].detach().numpy()
print(output)
print(output.shape)
from sklearn.manifold import TSNE
tsne = TSNE()
out = tsne.fit_transform(output)
fig = plt.figure()
labels_test = labels[idx_test].detach().cpu().numpy()
for i in range(7):
indices = labels_test == i
# print(indices)
x, y = out[indices].T
plt.scatter(x, y, label=str(i))
plt.legend()
plt.show()
5. ��������
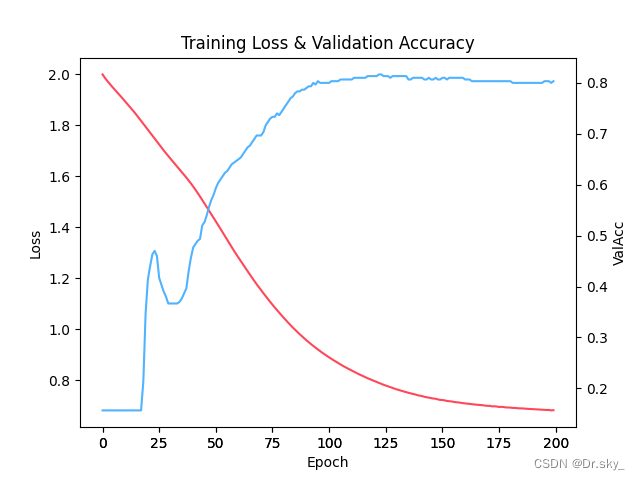
(1)loss��accѵ������
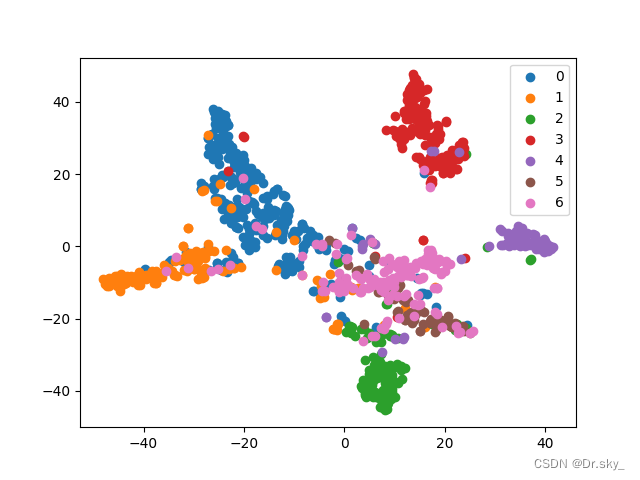
(2)�������ݵ�TSNE��άͼ
�����:
1. ICLR 2023 Open ReviewͶ������һ��,Ͷ��������46%,��Diffusion������Mask���ؼ��ʳ�Ϊ���ȵ� - ֪��2. GNN���������о�_���Ͼd��IJ���-CSDN����_gnnICLR 2023 Open ReviewͶ������һ��,Ͷ��������46%,��Diffusion������Mask���ؼ��ʳ�Ϊ���ȵ� - ֪��
3. ������ʽ,����ȫ��,ͼ������(GCN)ԭ�����_kisssfish�IJ���-CSDN����_gcnԭ��
4.?pytorch����¡�GCN������ϸ���_MelvinDong�IJ���-CSDN����_gcn������
5.?GNNѧϰ�ʼ�(��):Cora���ݼ���ȡ�����_�����IJ���-CSDN����_cora����