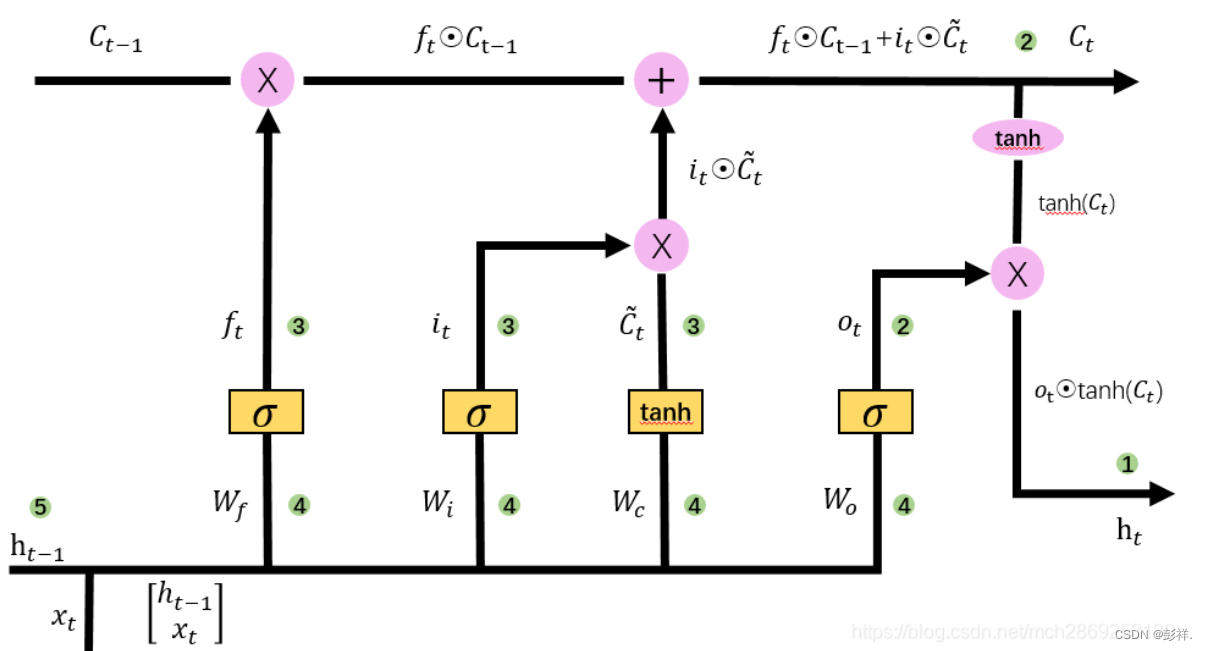
LSTM����ʵ��ʱ�����ݵ�Ԥ��,������һ�����������仯��ʱ��������������ʵ�ֺʹ������̡�
LSTMģ��
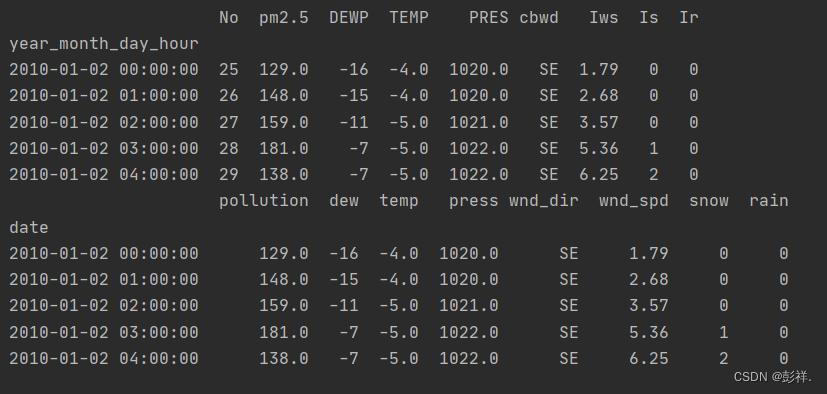
���ݼ�����
���������ݼ�:������9������ֵ,���а���ʱ�����������ָ�����
,�������ݴ�������Ч������:
�������ݼ��ṹ
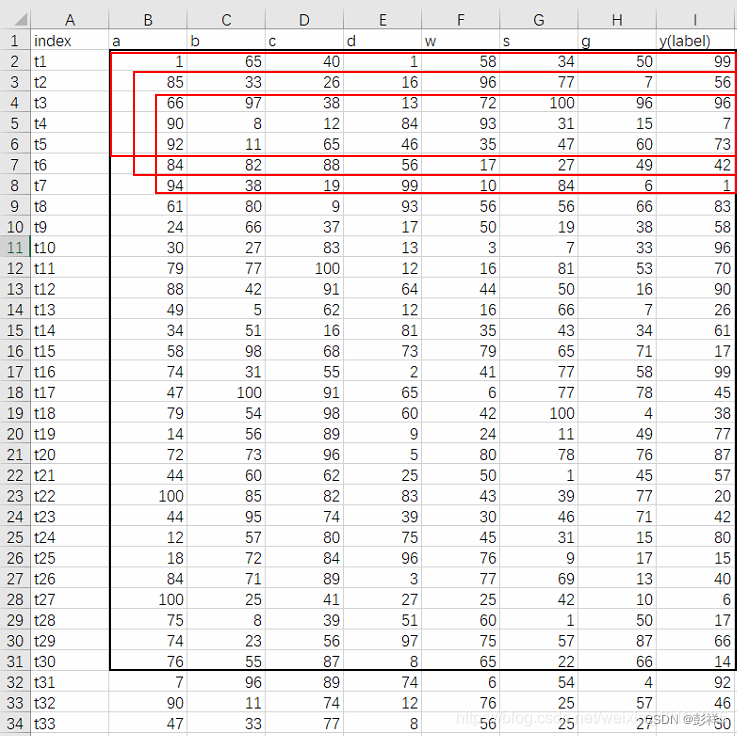
��� [batch_size, time_step, input_size]=[30,5,7]
��ô,��ͼ��,��ɫ������ľ���һ��batch_size�������е����ݵ�����
��ô,���ϵ��µ�3����ɫ���Ϊ time_stepΪ5��ʱ��,ÿ��ϸ�����������������������
��ô,��B~��H,һ��7��,��Ϊ input_size
- input_size �Ǹ������ѵ�������ȷ���ġ�
- time_step��LSTM�������е���Ҫ����,time_step��������ģ�ͽ��ú�һ��Ͳ���ı��ˡ�
- ��time_step��ͬ����,batch_size��ģ��ѵ��ʱ��ѵ������,��ģ��ѵ��ʱ�ɸ���ģ��ѵ���Ľ���Լ�loss��ʱ���е���,�ﵽ���š�
from pandas import read_csv
from datetime import datetime
# load data
def parse(x):
return datetime.strptime(x, '%Y %m %d %H')
dataset = read_csv('raw.csv', parse_dates = [['year', 'month', 'day', 'hour']], index_col=0, date_parser=parse)
print(dataset.head(5))
dataset.drop('No', axis=1, inplace=True)
# manually specify column names
dataset.columns = ['pollution', 'dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain']
dataset.index.name = 'date'
# mark all NA values with 0
dataset['pollution'].fillna(0, inplace=True)
# drop the first 24 hours
dataset = dataset[:]
# summarize first 5 rows
print(dataset.head(5))
# save to file
dataset.to_csv('pollution.csv')
��Ҫ�ǽ�ԭ���ݵ����ڸ�ʽ���й淶,ɾ��һЩȱʧֵ����������������Ҫ�����ݼ���
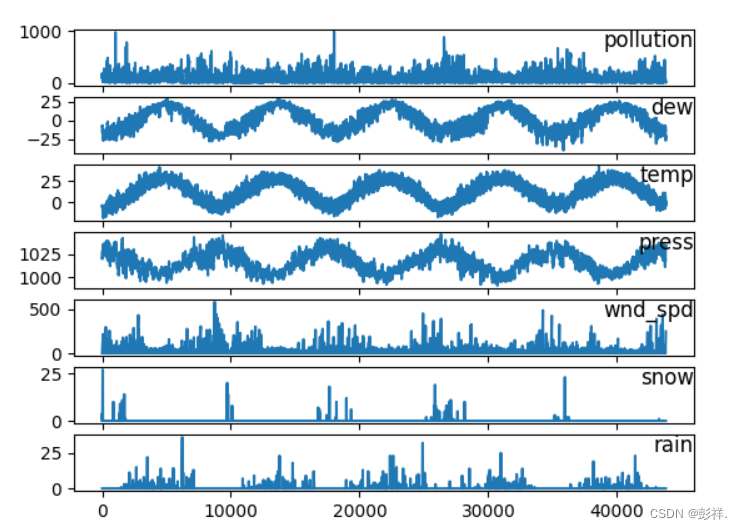
ͼ��չʾ
�����ݽ���ͼ�����:
from pandas import read_csv
from matplotlib import pyplot
# load dataset
dataset = read_csv('pollution.csv', header=0, index_col=0)
values = dataset.values
# specify columns to plot
groups = [0, 1, 2, 3, 5, 6, 7]
i = 1
# plot each column
pyplot.figure()
for group in groups:
pyplot.subplot(len(groups), 1, i)
pyplot.plot(values[:, group])
pyplot.title(dataset.columns[group], y=0.5, loc='right')
i += 1
pyplot.show()
���±���ģ�Ͷ�ȡ����,ѵ��,�����Ĺ�����:
��ʵ�ֵ���һ���ಽ��,�������ʱ������Ԥ�����:
���ɼල����
���ȶ����ݼ����д���Ϊ�ල����,����ת��Ϊ3�C>1��Ԥ�����ݸ�ʽ��
# ת���ɼල����,��������,3->1,����Ԥ��һ��
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
# ��3�������������������ƶ�3,2,1��,�����ݼ���cols�б�(����:(n_in, 0, -1)�е�-1ָ����ѭ��,����Ϊ1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
# ��һ��������ݼ���cols�б�(����:����i=0)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# cols�б�(list)���������Ŀ龭�����ƺ������(��:df(-3),df(-2),df(-1),df),���Ŀ����ݰ��� ���źϲ�
agg = concat(cols, axis=1)
# ���ϲ����������������
agg.columns = names
print(agg)
# ɾ��NaNֵ��
if dropnan:
agg.dropna(inplace=True)
return agg
��ȡ����,�����з������:�����ʱ�Ϊ����,�����б�������
# load dataset
dataset = read_csv('pollution.csv', header=0, index_col=0)
values = dataset.values
# �ԡ������н�����������
encoder = LabelEncoder()
values[:,4] = encoder.fit_transform(values[:,4])#fit_transform���ǽ������������к��ٽ��б���
print(values[:,4])
values = values.astype('float32')
# ����/���� ����ֵ��(0,1)֮��
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
ת��Ϊ�ල����:
# ��3Сʱ����Ԥ��һСʱ����,8������ֵ
n_hours = 3
n_features = 8
# ����һ��3->1�ļලѧϰ������
reframed = series_to_supervised(scaled, n_hours, 1)
print(reframed.shape)
���õ����ݸ�ʽ:(43797, 32)����43797������,��ÿ��Сʱ����,32������ֵ

����ѵ��������Լ�,����������ֵ�����ֵ,����ǰһ������ݽ���ѵ��,ȡÿ�����ݵ�ǰ38��Ϊ����ֵ,��18Ϊ���ֵ,ȡʣ�µ�����,����������Ϊ���Լ���
values = reframed.values
# ��һ���������ѵ��
n_train_hours = 365 * 24
train = values[:n_train_hours, :]
test = values[n_train_hours:, :]
# split into input and outputs
n_obs = n_hours * n_features
# ��32=(4*8)������,ȡǰ24=(3*8) ����ΪX,������8��=(��25��)��ΪY
train_X, train_y = train[:, :n_obs], train[:, -n_features]
test_X, test_y = test[:, :n_obs], test[:, -n_features]
print(train_X.shape, len(train_X), train_y.shape)
(8760, 24) 8760 (8760,)
(8760, 3, 8) (8760,) (35037, 3, 8) (35037,)
�������ģ��
# �������
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
�������
history = model.fit(train_X, train_y, epochs=50, batch_size=8, validation_data=(test_X, test_y), verbose=2, shuffle=False)
ͼ��չʾ�������ֵ
# plot history
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
pyplot.show()
����Ԥ��
# ִ��Ԥ��
yhat = model.predict(test_X)
# �����ݸ�ʽ���� n�� * 24��
test_X = test_X.reshape((test_X.shape[0], n_hours*n_features))
# ��Ԥ���оݺͺ�7������ƴ��,�����������ʱ,������״Ҫ���� n��*8�� ��Ҫ��
inv_yhat = concatenate((yhat, test_X[:, -7:]), axis=1)
# ��ƴ�Ӻõ����ݽ���������
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:,0]
test_y = test_y.reshape((len(test_y), 1))
# ����ʵ�оݺͺ�7������ƴ��,�����������ʱ,������״Ҫ���� n��*8�� ��Ҫ��
inv_y = concatenate((test_y, test_X[:, -7:]), axis=1)
# ��ƴ�Ӻõ����ݽ���������
inv_y = scaler.inverse_transform(inv_y)
inv_y = inv_y[:,0]
# ����RMSE���ֵ
rmse = sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
ϵͳ�Ľ�
֮ǰ�����ڿ����ϵͳʱ,�����˼�������,�������յ���������pollution�ȼ�,�������ʵ�ֵ���?
����,���з����ݼ���,��ȡǰ24����Ϊ��֪����,ʹ�õ�����8��ΪԤ������,����ǩ:
# ��32=(4*8)������,ȡǰ24=(3*8) ����ΪX,������8��=(��25��)��ΪY
train_X, train_y = train[:, :n_obs], train[:, -n_features]#ע�������-n_features�ǵ�����8�ж��ǵ������8��
test_X, test_y = test[:, :n_obs], test[:, -n_features]
ȷ�������ǵ�������Ϊ1��,��ô��������ȫ���Ӳ���Ϊ1����:
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
Ȼ�����ǵ����ݸ�ʽ��ι淶��,�����ǵ�fit�����������:
history = model.fit(train_X, train_y, epochs=2, batch_size=8, validation_data=(test_X, test_y), verbose=2, shuffle=False)#ָ����ѵ�������Լ�,��Ҳ�������˸�ʽ
��ô����������ͺ�������,����������ҵĽ��Ϊ�˸�����ֵ��,����ֻ��Ҫ������:����ǩȡ��8��:
# ��32=(4*8)������,ȡǰ24=(3*8) ����ΪX,������8��=(��25��)��ΪY
train_X, train_y = train[:, :n_obs], train[:, -n_features:]
test_X, test_y = test[:, :n_obs], test[:, -n_features:]
print(train_X.shape, len(train_X), train_y.shape,train_y)
# ������ת��Ϊ3D����,timesteps=3,3������Ԥ��1�� [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], n_hours, n_features))
test_X = test_X.reshape((test_X.shape[0], n_hours, n_features))
train_Y = train_y.reshape((train_y.shape[0], 1, n_features))
test_Y = test_y.reshape((test_y.shape[0], 1, n_features))
#�����и�ʽת��
�������������������,ȫ���Ӳ��Ϊ8
model = Sequential()
model.add(LSTM(50,input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(8))
����øı�,����������������Ϊ��8��������
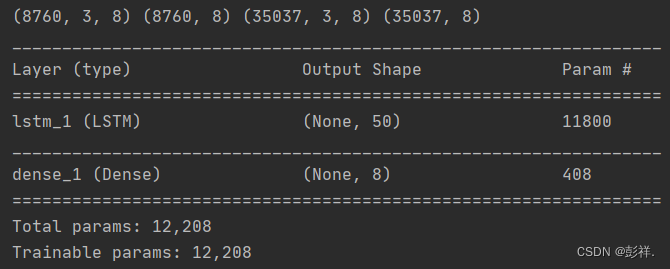
Ȼ�����Ƕ����õİ˸��������������Ϊԭ��������:
# ִ��Ԥ��
yhat = model.predict(test_X)#���ý��Ϊ8������
print(yhat.shape)
# ��ƴ�Ӻõ����ݽ���������
inv_yhat = scaler.inverse_transform(yhat)
test_y = test_y.reshape((len(test_y), n_features))
# ��ƴ�Ӻõ����ݽ���������
inv_y = scaler.inverse_transform(test_y)#Ԥ��������ʵ���ֻȡ��һ��
��ʵ��Ԥ������ʵ�ʽ�����жԱ�:
groups = [0, 1, 2, 3,4, 5, 6, 7]
i = 1
# plot each column
pyplot.figure()
for group in groups:
pyplot.subplot(len(groups), 1, i)
pyplot.plot(inv_yhat[:, group],label='predict',c='blue')
pyplot.plot(inv_y[:,group],label='true',c='red')
i += 1
pyplot.show()
# ����RMSE���ֵ
rmse = sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
���������
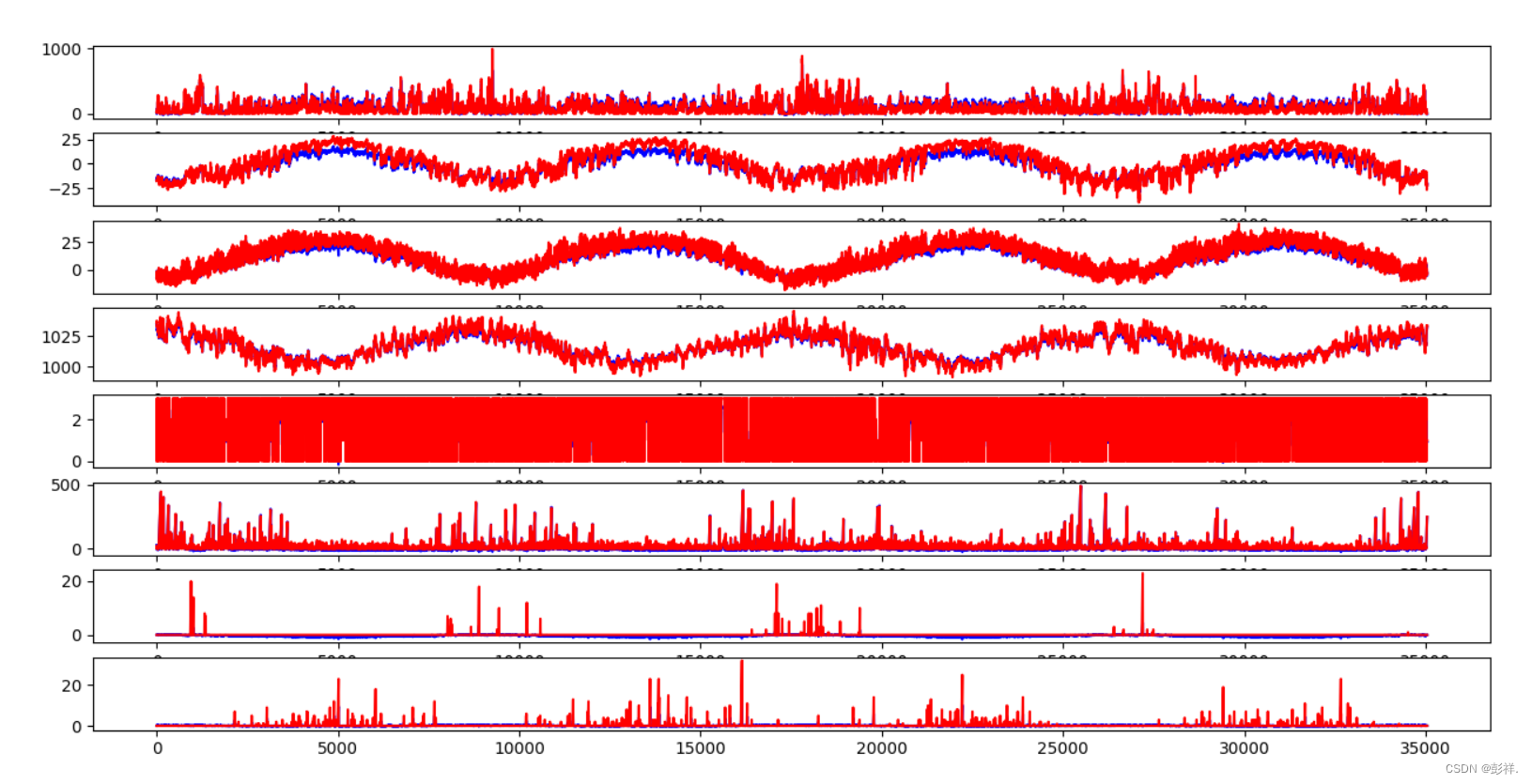
Test RMSE: 16.705