ТлЮФЕижЗ:TL-BERT: A Novel Biomedical Relation Extraction Approach
1. Introduction
дкОфзгМЖБ№ЬсШЁЩњЮявНбЇЙиЯЕЪБ,ФЧаЉЭЌдДЕЋВЛЭЌРр(SODC)ЕФЪЕР§КмШнвзБЛДэЮѓЕиЛЎЗжЮЊЭЌвЛРрЁЃ

ЪОР§ОфзгАќКЌШ§ИіЕААзжЪЪЕЬх TPOЁЂGrb2 КЭ JAK2,ЫќУЧПЩвдаЮГЩШ§жжКђбЁЙиЯЕЁЃЦфжа,ЪЕР§ <TPO,False,Grbs> КЭЪЕР§<Grb2,True,JAK2> ЪЧ SODC ЪЕР§ЁЃгЩгк SODC ЪЕР§ЪЧДгЭЌвЛИіОфзгЩњГЩЕФ,ЫќУЧОпгаМИКѕЯрЭЌЕФДЪЛуаХЯЂКЭОфЗЈаХЯЂ,етЛсЮѓЕМЗжРрЦїНЋЫќУЧЛЎЗжЮЊЭЌвЛРрЁЃ
Ъм FaceNet жаШ§жиЫ№ЪЇВпТдЕФЦєЗЂ,ЮвУЧЬсГіСЫЛљгкШ§жиЫ№ЪЇЕФ BERT(TL-BERT)ФЃаЭРДДгЮФБОжаЬсШЁ DDI КЭ PPIЁЃЮвУЧЪдЭМзюДѓЛЏетаЉгЩЯрЭЌОфзгЩњГЩЕЋЪєгкВЛЭЌРрЕФЪЕР§жЎМфЕФОрРы,вддіМг SODC ЪЕР§жЎМфЕФЧјБ№ЁЃЪзЯШ,ЪЙгУжИЖЈЕФШ§жиЩњГЩЙцдђЩњГЩШ§жиЪ§ОнЁЃЦфДЮ,НЋЩњГЩЕФШ§жиЪ§ОнЪфШыЕНЛљгк BERT ЕФЬиеїГщШЁЦїжавдЛёШЁОфзгМЖЬиеїКЭЪЕЬхМЖЬиеїЁЃзюКѓ,ЛљгкОфзгМЖКЭЪЕЬхМЖЬиеї,ЗжБ№МЦЫуШ§жиЫ№ЪЇКЭЖўдЊНЛВцьиЫ№ЪЇРДбЕСЗФЃаЭЁЃTL-BERT ЗжБ№дк PPI Ъ§ОнМЏКЭ DDI Ъ§ОнМЏЩЯНјааСЫЦРЙР,ВЂШЁЕУСЫЯджјЕФНсЙћЁЃДЫЭт,в§ШыШ§жиЫ№ЪЇбЕСЗВпТдПЩвдЬсИп PPI ЬсШЁШЮЮёКЭ DDI МьВтШЮЮёЕФадФм,етжЄУїСЫШ§жиЫ№ЪЇбЕСЗВпТддкЙиЯЕЬсШЁСьгђЕФгааЇадЁЃ
2. Method
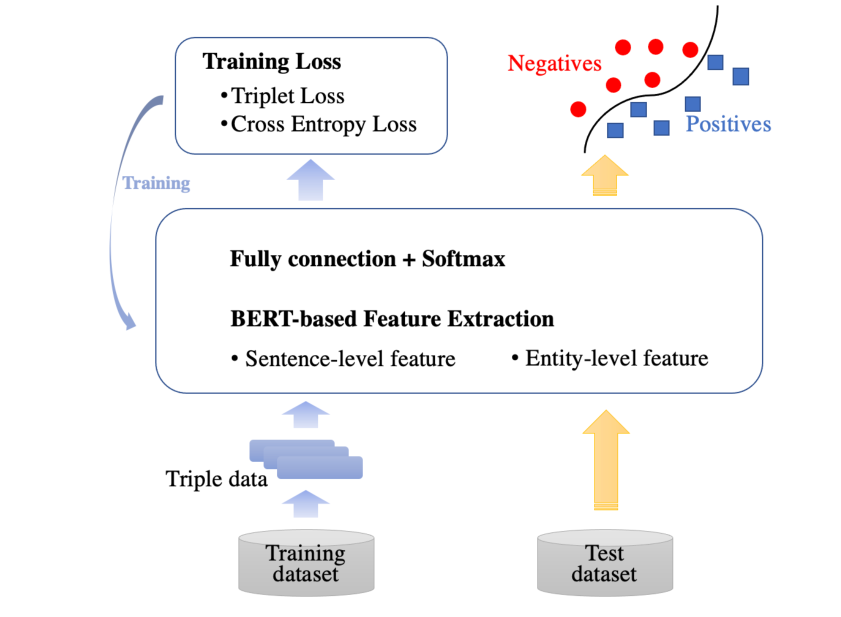
дкБОбаОПжа,ЮвУЧзХжигкЧЩУюЕиЪЙгУШ§жиЫ№ЪЇбЕСЗВпТдРДбЕСЗЛљгк BERT ЕФЩњЮявНбЇЙиЯЕЬсШЁФЃаЭЁЃЮвУЧЕФЗНЗЈПђМмШчЭМЫљЪО:
2.1 Triple Data Generation
ЮЊСЫХфКЯ Triplet Loss ЕФбЕСЗВпТд,НЋЪЙгУвдЯТШ§ЬѕЙцдђЩњГЩКЯЗЈЕФШ§жиЪ§Он:
(1)ЖдгкУПИіе§ЪЕР§,ДгЭЌвЛИіОфзгжаЛёШЁвЛИіИКЪЕР§,ДгЫцЛњбЁдёЕФОфзгжаЛёШЁвЛИіе§ЪЕР§,вдаЮГЩШ§жиЪ§ОнЁЃ
(2)ЖдгкУПИіИКЪЕР§,ДгЭЌвЛИіОфзгжаЛёШЁвЛИіе§ЪЕР§,ДгЫцЛњбЁдёЕФОфзгжаЛёШЁвЛИіИКЪЕР§,вдаЮГЩШ§жиЪ§ОнЁЃ
(3)ЖдгкУПИіЮоЗЈДгЭЌвЛИіОфзгжаевЕНвЛИіИК/е§ЪЕР§ЕФе§/ИКЪЕР§,ШєИУОфзгжажЛгаСНИіЪЕЬх,ФЧУДЫќНЋДгЦфЫќОфзгжаЫцЛњбЁдёвЛИіе§ЪЕР§КЭвЛИіИКЪЕР§,вдаЮГЩШ§жиЪ§ОнЁЃ
ЖдгкЪЙгУЙцдђ(1)КЭЙцдђ(2)ЩњГЩЕФШ§жиЪ§Он,Ш§жиЪ§ОнжаЕФСНИіЪЕР§ЙВЯэЯрЭЌЕФЩЯЯТЮФаХЯЂ,етНЋЮѓЕМЗжРрЦїНЋЫќУЧЗжЕНЭЌвЛРржа,в§Шы Triplet Loss ВпТдЕФжївЊФПЕФЪЧЬсИпЧјЗжетаЉ SODC ЪЕР§ЕФФмСІЁЃ
2.2 Bert based feature extraction
R-BERT НЋЪЕЬхМЖаХЯЂКЯВЂЕНдЄбЕСЗЕФBERTФЃаЭжагУгкЙиЯЕЗжРр,ВЂДяЕНСЫзюЯШНјЕФЫЎЦНЁЃвђДЫ,ЮвУЧЪЙгУR-BERTзїЮЊЬиеїГщШЁЦї,ДгЪфШыЪЕР§жаЬсШЁОфзгМЖЬиеїКЭЪЕЬхМЖЬиеїЁЃдкЪфШыЕНЬиеїЬсШЁЦїжЎЧАашвЊДІРэУПИіЪЕР§ЁЃИјЖЈОпгаСНИіЪЕЬх
e
1
e1
e1 КЭ
e
2
e2
e2 ЕФОфзг,ЮвУЧашвЊдкЪЕЬх
e
1
e1
e1 ЕФПЊЭЗКЭНсЮВВхШы $,дкЪЕЬх
e
2
e2
e2 ЕФПЊЭЗКЭНсЮВВхШы #ЁЃ
ОЙ§дЄДІРэКѓ,ЪЕР§БЛЫЭШыЛљгк BERT ЕФЬиеїЬсШЁЦїЁЃЪзЯШ,BERT ФЃаЭНЋДІРэКѓЕФЪЕР§(БъМЧађСа)гГЩфЕНвўВизДЬЌађСа
H
=
{
H
0
,
H
1
,
?
?
,
H
N
}
H=\{H_0,H_1,\cdots,H_N\}
H={H0?,H1?,?,HN?}ЁЃ
H
0
H_0
H0? ЪЧЕквЛИі token [CLS](БЛЪгЮЊОфзгМЖБ№ЕФЧЖШы)ЕФЧЖШы,
H
i
ЁЋ
H
j
H_i\sim H_j
Hi?ЁЋHj? ЪЧЪЕЬх
e
1
e1
e1 ЕФЧЖШы,
H
m
ЁЋ
H
n
H_m\sim H_n
Hm?ЁЋHn? ЪЧЪЕЬх
e
2
e2
e2 ЕФЧЖШыЁЃгЩгкУПИіЪЕЬхЕФГЄЖШВЛвЛжТ,вђДЫЮвУЧгУЦНОљВйзїРДЛёЕУОпгажИЖЈГЄЖШЕФЪЕЬхМЖЧЖШыЁЃДЫЭт,ЮЊСЫЬсШЁИќЖрЕФГщЯѓЬиеї,дкОфзгМЖЧЖШыКЭЪЕЬхМЖЧЖШыжаЖМЬэМгСЫвЛИіШЋСЌНгВу,вдЛёЕУзюжеЕФОфзгМЖЬиеїЯђСП
H
S
H_S
HS? КЭЪЕЬхМЖЬиеїЯђСП
H
e
1
H_{e1}
He1? КЭ
H
e
2
H_{e2}
He2?,ЗжБ№БэЪОЮЊ:
H
S
=
W
0
[
tanh
(
H
0
)
]
+
b
0
(1)
H_S=W_0[\text{tanh}(H_0)]+b_0\tag{1}
HS?=W0?[tanh(H0?)]+b0?(1)
H
e
1
=
W
[
tanh
(
1
j
?
i
+
1
ЁЦ
t
=
i
j
H
t
)
]
+
b
(2)
H_{e1}=W[\text{tanh}(\frac{1}{j-i+1}\sum_{t=i}^jH_t)]+b\tag{2}
He1?=W[tanh(j?i+11?t=iЁЦj?Ht?)]+b(2)
H
e
2
=
W
[
tanh
(
1
m
?
n
+
1
ЁЦ
t
=
m
n
H
t
)
]
+
b
(3)
H_{e2}=W[\text{tanh}(\frac{1}{m-n+1}\sum_{t=m}^nH_t)]+b\tag{3}
He2?=W[tanh(m?n+11?t=mЁЦn?Ht?)]+b(3)
2.3 Training process
Triplet LossХрбЕВпТдЕФЩшМЦЖЏЛњШчЭМЫљЪОЁЃдкЬиеїПеМфжа,ЮвУЧЯЃЭћзюДѓЛЏ SODC ЪЕР§(Instance1 КЭ Instance3)жЎМфЕФОрРы,ВЂзюаЁЛЏетаЉЯрЭЌРрЪЕР§(Instance1 КЭ Instance2)жЎМфЕФМфОрЁЃЭЈЙ§ЖдУПИіЪЕР§ЧЖШыаТЕФЬиеї,ЗжРрЦїПЩвдИќзМШЗЕиЧјЗж SODC ЪЕР§ЁЃ

TL-BERT ЕФзмЬхбЕСЗЙ§ГЬШчЭМЫљЪО:
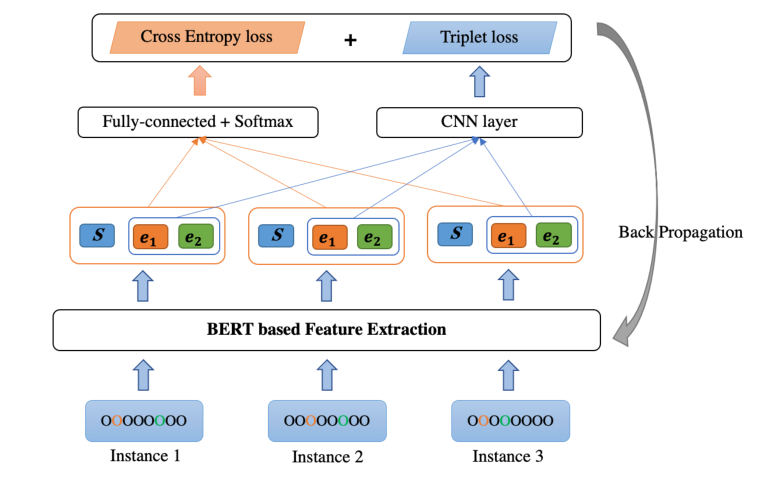
(1)НЛВцьиЫ№ЪЇ
ЖдгкШ§жиЪ§ОнжаЕФУПИіЪЕР§,НЋОфзгМЖЬиеїЯђСП
H
0
ЁЏ
H_0^ЁЏ
H0ЁЏ? КЭСНИіЪЕЬхМЖЬиеїЯђСП
H
e
1
,
H
e
2
H_{e1},H_{e2}
He1?,He2? ЦДНгЦ№РД,ШЛКѓЬэМгвЛИіШЋСЌНгВуКЭвЛИі
softmax
\text{softmax}
softmax ВувдЛёЕУзюжеЗжРрНсЙћ
p
p
pЁЃзюжеЪЙгУЙЋЪН(6)МЦЫуНЛВцьиЫ№ЪЇ,Цфжа
i
=
1
,
2
,
3
i=1,2,3
i=1,2,3 ЗжБ№ДњБэШ§жиЪ§ОнЪЕЬх1ЁЂЪЕЬх2КЭЪЕЬх3ЕФЫїв§ЁЃ
e
=
W
3
[
c
o
n
c
a
t
(
H
S
;
H
e
1
;
H
e
2
)
]
+
b
3
(4)
e=W_3[concat(H_S;H_{e1};H_{e2})]+b_3\tag{4}
e=W3?[concat(HS?;He1?;He2?)]+b3?(4)
p
=
softmax
(
e
)
(5)
p=\text{softmax}(e)\tag{5}
p=softmax(e)(5)
l
o
s
s
C
E
=
ЁЦ
i
=
1
3
?
[
y
i
?
log
?
(
p
i
)
+
(
1
?
y
i
)
?
log
?
(
1
?
p
i
)
]
(6)
loss_{CE}=\sum_{i=1}^3-[y^iЁЄ\log(p^i)+(1-y^i)ЁЄ\log(1-p^i)]\tag{6}
lossCE?=i=1ЁЦ3??[yi?log(pi)+(1?yi)?log(1?pi)](6)
(2)Ш§жиЫ№ЪЇ
Ждгк SODC ЪЕР§,ЫќУЧЙВЯэЯрЭЌЕФЩЯЯТЮФаХЯЂ,ЮЈвЛЕФЧјБ№ЪЧЪЕЬхМЖБ№ЕФаХЯЂЁЃвђДЫ,ЮвУЧЭЦЖЯЪЕЬхМЖБ№ЕФаХЯЂЖдНЋетаЉ SODC ЪЕР§е§ШЗЗжРрЦ№зХЙиМќзїгУЁЃвђДЫ,ЮвУЧЛљгкЪЕЬхМЖЬиеїЯђСПМЦЫуШ§жиЫ№ЪЇЁЃ
ЪзЯШ,ЖдгкУПИіЪЕР§,НЋСНИіЪЕЬхМЖЬиеїЯђСП
H
e
1
ЁЪ
R
d
,
H
e
2
ЁЪ
R
d
H_{e1}\in R^d,H_{e2}\in R^d
He1?ЁЪRd,He2?ЁЪRd ЖбЕўЛёЕУЯђСП
H
e
ЁЪ
R
2
ЁС
d
H_{e}\in R^{2\times d}
He?ЁЪR2ЁСdЁЃШЛКѓ,ЮЊВЖЛёЪЕЬхЖдЕФЯрЙиаХЯЂ,дк
H
e
H_e
He? ЩЯжДаавЛЮЌОэЛ§,ЪЙгУЙЋЪН(8)ЛёЕУЪЕЬхЖдОэЛ§ЬиеїЯђСП
H
e
p
ЁЪ
R
d
H_{ep}\in R^d
Hep?ЁЪRdЁЃзюКѓ,ЪЙгУШ§ИіЪЕЬхМЖОэЛ§ЬиеїЯђСПРДМЦЫуШ§жиЫ№ЪЇЁЃ
H
e
=
s
t
a
c
k
[
H
e
1
,
H
e
2
]
(7)
H_e=stack[H_{e1},H_{e2}]\tag{7}
He?=stack[He1?,He2?](7)
H
e
p
=
f
c
o
n
v
(
H
e
)
(8)
H_{ep}=f_{conv}(H_{e})\tag{8}
Hep?=fconv?(He?)(8)
l
o
s
s
T
L
=
[
ЈO
ЈO
H
e
p
1
?
H
e
p
2
ЈO
ЈO
2
2
?
ЈO
ЈO
H
e
p
1
?
H
e
p
3
ЈO
ЈO
2
2
+
ІС
]
+
(9)
loss_{TL}=[||H_{ep}^1-H_{ep}^2||_2^2-||H_{ep}^1-H_{ep}^3||_2^2+\alpha]_+\tag{9}
lossTL?=[ЈOЈOHep1??Hep2?ЈOЈO22??ЈOЈOHep1??Hep3?ЈOЈO22?+ІС]+?(9)Цфжа,
H
e
p
1
,
H
e
p
2
,
H
e
p
3
H_{ep}^1,H_{ep}^2,H_{ep}^3
Hep1?,Hep2?,Hep3?ЗжБ№ДњБэЪЕЬх1ЁЂЪЕЬх2ЁЂЪЕЬх3ЕФЪЕЬхЖдОэЛ§ЬиеїЯђСПЁЃЪЕЬх1КЭЪЕЬх2ЪєгкЭЌвЛИіРр,ЖјЪЕЬх1гыЪЕЬх3ЪєгкВЛЭЌЕФРрЁЃ
ІС
\alpha
ІСВЛЭЌРржЎМфЧПМгЕФБпОрЁЃ
злЩЯ,TL-BERT ЕФЫ№ЪЇКЏЪ§ЖЈвхШчЯТ, ІТ \beta ІТ ЪЧГЌВЮЪ§: l o s s = l o s s C E + ІТ l o s s T L (10) loss = loss_{CE}+\beta loss_{TL}\tag{10} loss=lossCE?+ІТlossTL?(10)
3. Experiments
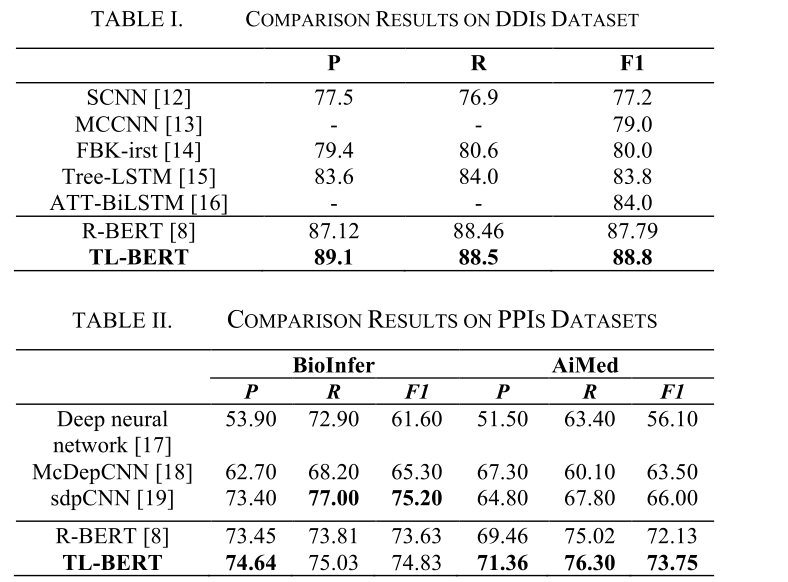
дкБОеТжа,ЮвУЧНЋбщжЄ TL-BERT дк PPI ЬсШЁШЮЮёКЭ DDI МьВтШЮЮёжаЕФгааЇадЁЃ
3.1 Datasets
ЮвУЧЕФЗНЗЈЪЧИљОнСНИіСїааЕФ PPI ЛљзМ(AIMedЁЂBioInfer)КЭвЛИіжјУћЕФ DDI ЛљзМ(DDI Extraction-2013гяСЯПт)НјааЦРЙРЕФЁЃЛљгк DDI Extraction-2013 гаСНИізгШЮЮё:DDI МьВт(ЖўНјжЦЗжРр)КЭ DDI ЗжРр(ЖрЗжРр)ЁЃгЩгкШ§жиЫ№ЪЇВЛЪЪгУгкЖрРрЗжРрШЮЮё,вђДЫЮвУЧжЛНјаа DDI МьВтШЮЮёРДбщжЄЮвУЧЕФбЕСЗВпТдЕФгааЇадЁЃ
3.2 Experimental Results and Analysis
ЮЊСЫбщжЄ TL-BERT ЕФгааЇад,НјааСЫвдЯТЪЕбщЁЃгЩгк AIMed КЭ BioInfer жаУЛгаВтЪдЪ§ОнМЏ,вђДЫЖдетСНИігяСЯПтНјааСЫЪЎДЮНЛВцбщжЄЪЕбщЁЃPPIs гяСЯПтКЭ DDIs гяСЯЕФБШНЯНсЙћЗжБ№ШчБэIКЭБэIIЫљЪОЁЃ