1 ժҪ
Transformer һֱ����Ȼ���Դ��� (NLP) �ͼ�����Ӿ� (CV) �ĺ��ġ�NLP �� CV �ľ�ɹ��������о��߶� Transformer �ڵ��ƴ����е�ʹ�õ�̽��������,Transformer���Ӧ�Ե��ƵIJ������Ժ�������?Transformer �Բ�ͬ�� 3D ��ʾ(������ƻ�����)�����������?Transformer �Ը��� 3D ����������������?��ĿǰΪֹ,��û�ж���Щ������о�����ϵͳ�ĵ��顣����ȫ����������� 3D ���Ʒ����� Transformer�㷨�����Ƚ��� Transformer �ṹ�����۲��ع����� 2D/3D �����Ӧ�á�Ȼ��,��������ֲ�ͬ�ķ��෨(������ʵ�֡����ݱ�ʾ������),���ԴӶ���ǶȶԵ�ǰ���� Transformer �ķ������з��ࡣ����,����չʾ�� 3D ��self-attention���Ƶı���Ľ�����ؽ����Ϊ��֤�� Transformer �ڵ��Ʒ����е���Խ��,���ĶԸ��ֻ��� Transformer �ķ��ࡢ�ָ��Ŀ���ⷽ��������ȫ��Ƚϡ����,���������DZ�ڵ��о�����,Ϊ3D Transformer �ķ�չ�ṩ����ο���
2 ����
��������������е� Transformer������ NLP �е���Ҫ������ṹ�����ڽ�ģԶ��������ǿ������,�����ѳɹ�Ӧ�����Զ���ʻ���Ӿ����㡢���ܼ�غ�ҵ���� CV [1]-[3] ����һ������ Transformer ������ͨ����������Ҫ������,����ͼ��ʾ:
-
����(word)Ƕ��;
-
λ�ñ���;
-
self-attention;
-
��һ��;
-
feed-forward;
-
��Ծ���ӡ�
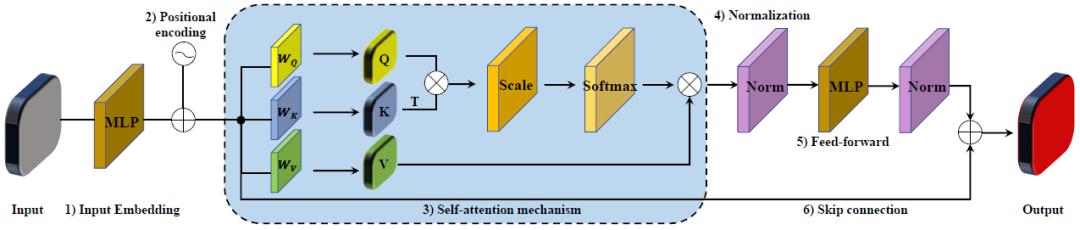
���� Transformer ������,ͨ�������Ϊ�������ľ���,���˶��⽫��������DZ��������Ϊ���롣Ȼ��,���� 3D ����Ӧ��,����������ר�����(�����Ǵ� Transformer)�����ܼ�Ԥ������,���� 3D ���Ʒ����еIJ����ָ������ָ3D �Ӿ��о���Աͨ������ PointNet++ [4] �����а��� Transformer ģ��ľ������ɡ�
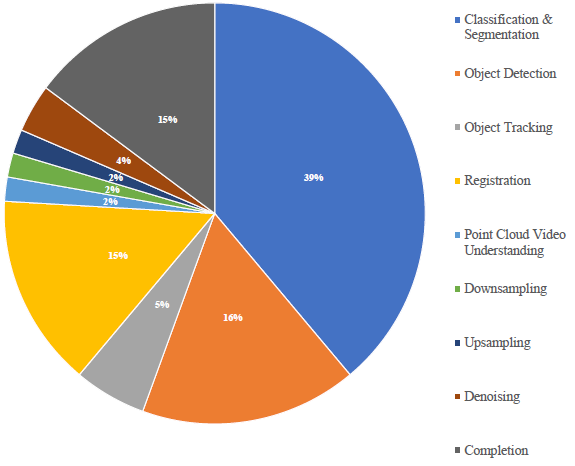
���������ȫ������ѧϰ�������û��ȱ����,Transformer �����������ڵ��ƴ����ͷ�����Ŀǰ�о���Ա������������ڵ��Ʒ���ͷָ�� 3D Transformer ����(����ͼ)[7]��[12]��[34]��[37]��[69]��[70]����� [35]��[ 54],����[56]-[58],��[59]-[63],[71],[72],��ȫ[50],[66]-[68],[73],[74],���ټ���������,3D Transformer ����Ҳ�����ڸ���ʵ��Ӧ��,����ṹ��� [75]��ҽѧͼ����� [37] ���Զ���ʻ [76]��[77]�����,�б�Ҫ��3D Transformer����ϵͳ�ĵ��顣
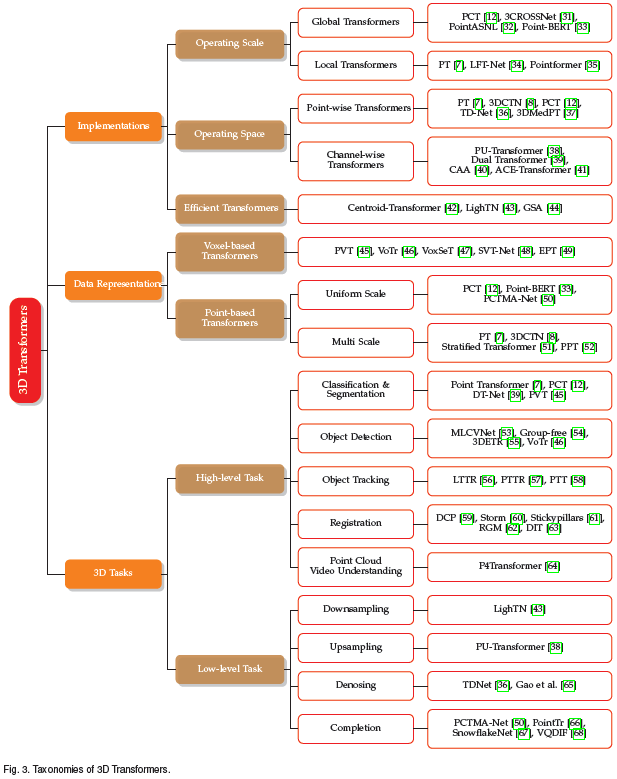
������������ֲ�ͬ�ķ��෨,����ͼ��ʾ:1)����ʵ�� 2) �������ݱ�ʾ�� 3)��������ͨ�����ַ�ʽ,�����ܹ��Ӷ���Ƕȶ� Transformer ������з���ͷ���������Щ���෨������ų⡣��Point Transformer(PT)[7]Ϊ��:1)��Transformerʵ�ַ���,���ھֲ�Transformer����,��Ŀ����Ƶľֲ�����������;2)�����ݱ�ʾ����,���ڶ�߶Ȼ��ڵ��Ƶ�Transformer����,�ֲ���ȡ���κ���������;3)��3D������,רΪ���Ʒ���ͷָ����ơ�����,���Ļ��� 3D ���ƴ����еIJ�ͬ��ע������������˵��顣
���ĵ���Ҫ��������:
-
��������ƪ�������ڵ�����ȫ����� Transformer ��ʵ�� 3D �Ӿ�����Ĺ���;
-
�����о��˵��Ʒ����е�һϵ����ע�������塣���������µ���ע��������,ּ����� 3D Transformer �����ܺ�Ч��;
-
�����ڼ��� 3D �Ӿ��������ṩ�˻��� Transformer �����ıȽϺͷ���,���� 3D ��״����� 3D ��״/����ָ�,�Լ������������ϵ� 3D Ŀ����;
-
��������߽����� SOTA �����Լ����� Transformer �ĵ��ƴ������������½�չ��
3 Transformerʵ��
�ڱ�����,���ĴӶ���Ƕȶ� 3D �����е� Transformer �����˹㷺�ķ��ࡣ����,�Ͳ����߶�(Operating Scale)����,3D Transformers ���Է�Ϊ:Global Transformers �� Local Transformers�������߶ȱ�ʾ�㷨����ڵ��Ƶķ�Χ,����ȫ�����ֲ������,�Ͳ����ռ����,3D Transformer ���Է�Ϊ Point-wise Transformers �� Channel-wise Transformers�������߶ȱ�ʾ�㷨�����ά��,��ռ�ά�Ȼ�ͨ��ά�ȡ����,���Ļع���Ϊ���ټ���������Ƶĸ�Ч Transformer ���硣
3.1 ������ģ
���ݲ���,3D Transformer ���Է�Ϊ��������:Global Transformer ��Local Transformer ��ǰ�߱�ʾ�� Transformer ģ��Ӧ�������������������ȡȫ������,�����߱�ʾ�� Transformer ģ��Ӧ���ھֲ� patch ����ȡ�ֲ�������
3.1.1 Global Transformers
���е������㷨 [8]��[10]-[12]��[31]��[33]��[37]��[38]��[52]��[81] רע��Global Transformer������Global Transformerģ��,ÿ������������������������������������ӡ�������������з����ǵȱ��,�����ܹ�ѧϰȫ������������ [12]��
�� PointNet [5] ֮��,PCT [12]��Ϊһ����ȫ�� Transformer ���类�����PCT �� 3D ������Ϊ����,���������һ������Ƕ��ṹ,������ӳ�䵽��ά�����ռ䡣�˲��������Խ��ֲ���Ϣ�ϲ���Ƕ�������С�Ȼ����Щ�������뵽�ĸ��ѵ���ȫ�� Transformer ģ������ѧϰ������Ϣ������ͨ��ȫglobal Max��Average�ػ���ȡȫ������,���ڷ���ͷָ����,PCT �Ľ��� self-attention ģ��,��Ϊ Offset-Attention��
�� PCT �ĵ�һ�߶����,�� [31] �������һ�� Cross-Level��Cross-Scale��Cross-Attention��Transformer ����,��Ϊ 3CROSSNet�����ȶ�ԭʼ�������ִ��Farthest Point Sampling(FPS)�㷨[4],�Ի�þ��в�ͬ�ֱ��ʵ����������Ӽ������,���öѵ��Ķ����������֪(MLP)ģ������ȡÿ���������Ƶľֲ�����������,�� Transformer ģ��Ӧ����ÿ�������Ӽ��Խ���ȫ��������ȡ�����,�����Cross-Level Cross-Attention (CLCA) ģ���Cross-Scale Cross-Attention (CSCA) ģ����������ͬ�ֱ��ʵ����Ӽ��Ͳ�ͬ�㼶����֮�������,��ʵ��Զ�̲��Ͳ��ڵ�������ģ��
������ع���[33]��[5]��ο����ġ�
3.1.2 Local Transformers
��ȫ�� Transformer ���,�ֲ� Transformer [7]��[34]��[35]��[42]��[85]��[86] ּ��ʵ�־ֲ�patch���������������е������ۺϡ�
PT [7] ���� PointNet++ [4] �ֲ�ܹ����е��Ʒ���ͷָ��רע��local patch����,���� PointNet++ �еĹ��� MLP ģ���滻Ϊlocal Transformer ģ�顣PT �����local Transformer ,�����²����ĵ��Ƽ������С�ÿ��ģ�鶼Ӧ���ڲ������Ƶ� K-����� (KNN) ��������˵,PT ʹ�õ���ע��������������ע���� [87] �����DZ���ע������ǰ���ѱ�֤���Ե��ƴ�������Ч,��Ϊ��֧��ͨ��ע����,�����ǽ�����Ȩ�ط������������������
Pointformer �� [35] �����,�� Transformer ��ȡ�ľֲ���ȫ����������������� 3D Ŀ���⡣Pointformer ��Ҫ��������ģ��:Local Transformer (LT) block��Global Transformer (GT) block��Local-Global Transformer (LGT) block������,LT �� FPS [4] ���ɵ�ÿ��centroid point����ʹ���ܼ�����ע�������������,����������Ϊ����,GTģ��ּ��ͨ����ע��������ѧϰȫ�������ĸ�֪���������,LGT ����ö�߶Ƚ���ע��ģ��,�� LT �ľֲ������� GT ��ȫ������֮�佨�����ӡ�
�� Swin Transformer [21] ������,[51] ����� Stratified Transformer ���� 3D ���Ʒָ��ͨ�� 3D ���ػ������Ʒָ��һ�鲻�ص�����������,����ÿ��������ִ�оֲ� Transformer ������������ع���[88]��ο����ġ�
3.2 �����ռ�
���ݲ����ռ�,3D Transformer ���Է�Ϊ����:Point-wise �� Channel-wise Transformers��ǰ�߲����������֮���������,��������ͨ������ע����Ȩ��[40]��һ����˵,������Transformer��ע����ͼ���Ա�ʾΪ:
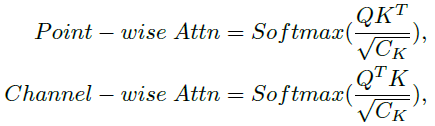
3.2.1 Point-wise Transformers
Point-wise Transformers ּ���о�����֮��Ŀռ������,�����������ͼ��ʾΪ�������������ļ�Ȩ�͡�
ȫ�� Transformer �;ֲ� Transformer �������ڿռ�����߶�,���������ƻ�ֲ�patch,���������������[7],[8],[10]-[12],[31],[33]-[35] , [37], [38], [42], [51], [52], [81] ���Ա���Ϊ��Point-wise Transformer��
Point-wise Transformers Ҳ�㷺Ӧ������������[36] �����һ�����ڵ���ȥ��ı�����-������ Transformer ����(TD-Net)����������һ���������������Ƕ��ģ�顢����Ӧ����ģ����ĸ��ѵ���point-wise��ע����ģ����ɡ��ĸ���ע����ģ������������һ����Ϊ�����������롣����,TD-Net ʹ��������Ӧ��������,�����Զ�ѧϰ FPS [4] ���ɵ�ÿ���������Ƶ�ƫ���������������ڸ�����ȡ�ĸ���������underlying manifold�����,����ͨ��manifold sampling�ؽ�ȥ���ĵ��ơ���������㷨[37]��[10]��[52]���Բο����ġ�
3.2.2 Channel-wise Transformers
��point-wise Transformers���,channel-wise Transformers[38]-[41]��[69]רע�ڲ�����ͬ����ͨ����������ԡ���ͨ��ǿ����ͨ���������������Ľ���������Ϣ��ģ[39]��
[40] ���þ��������ṹ(error-correcting feedback structure)��˼�������һ�����ھֲ���������ķ�ͶӰģ�顣���������һ�� Channel-wise Affinity Attention (CAA) ģ���Ի�ø��õ�������ʾ��������˵,CAA ģ��������ģ�����:Compact Channel-wise Comparator (CCC) ģ���Channel Affinity Estimator (CAE) ģ�顣CCC ������ͨ���ռ����������ƶȾ���CAE��һ��������һ��affinity����,����attentionֵԽ�ߵ�Ԫ�ش�����Ӧ������ͨ�������ƶ�Խ�͡��˲����������ע����Ȩ�ز�����ۺ����ƻ�������Ϣ�����,���������ÿ��ͨ����������ͬ��ͨ�����㹻�Ľ���,��������ģ��ѧϰ��
3.3 Efficient Transformers
�����ڵ��ƴ�����ȡ���˾�ɹ�,���� Transformer ��������Ϊ������������������¸��������ڴ����ġ����� N ���������,����ע����ģ��ļ�����ڴ渴�Ӷ��� N �Ķ��η�,�� �������ڴ��ģ�������ݼ���Ӧ�� Transformer ����Ҫȱ�㡣
���,�м��� 3D Transformer ���о��Ľ���ע����ģ���������Ч�ʡ�����,Centroid Transformer [42] �� N ������������Ϊ����,��� M ����������(M<N)�����,��������еĹؼ���Ϣ����ͨ���������������(��Ϊ����)��������������˵,������ͨ���Ż�һ��ġ�soft K-means��Ŀ�꺯���� N ������㹹�� M �����ġ�Ȼ��ʹ�� M �����ĺ� N ��������Ʒֱ����� Query �� Key ����ע��ͼ�Ĵ�С�� N��N ���ٵ� M��N,��� self-attention �ļ���ɱ��� ���ٵ� ��Ϊ�˽�һ����ʡ����ɱ�,����ʹ����KNN���ơ��ò���ʵ�����ǽ�ȫ�� Transformer ת���ֲ� Transformer�������������,���ƶȾ�����ͨ������ÿ��query������������ K ������key����֮��Ĺ�ϵ������ N �����������ɵġ����Լ���ɱ����Խ�һ�����͵������Ƶ�,PatchFormer [89] Ҳ���Լ���ע��ͼ�Ĵ�С��
Light-weight Transformer Network(LightTN)[43]���ò�ͬ�ķ�ʽ���ͼ���ɱ���LightTN ּ�ڼ�Transformer�е���Ҫ���,�����Ч�ʵ�ͬʱ����Transformer�����ܡ�����,ȥ����λ�ñ���,��Ϊ����� 3D �����Ѿ�����λ����Ϣ,��ʡ�˸ò��ֵļ����������,����һ��С�ߴ�Ĺ������Բ���Ϊ����Ƕ��㡣�� [12] �н�ʡ�����neighbor embedding���,Ƕ��������ά�ȼ�����һ��,��˽�һ�������˼�����������,�����һ����ͷ����ز���Ϊ��ע��ģ�顣����ע����ͼ�������������ز�������,�����ע����ģ��Ҳ������Ϊ�����ģ��,���Ա���Ϊ:
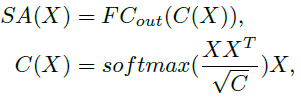
4 ���ݱ�ʾ
3D ���ݱ�ʾ�ж�����ʽ,������ƺ����ض�������Ϊ 3D Transformer �����롣���ڵ��ƿ��������ر�ʾ��ת��Ϊ����,���Ҳ�����ڵ����Ͻ��м��ֻ������صķ���,���� 3D Transformer�����������ʽ�IJ�ͬ,���Ľ� 3D Transformer ��Ϊ Voxel-based Transformers �� Point-based Transformers��
4.1 �������ص�Transformers
��ͼ��ͬ����,3D ����ͨ���Ƿǽṹ����,����ֱ��ʹ�ô�ͳ�ľ������Ӵ���������,3D ���ƿ��Ժ�����ת��Ϊ 3D ����,��ṹ������ͼ�����,һЩ���� Transformer �Ĺ��� [45]-[47]��[51] ̽���˽� 3D ����ת��Ϊ�������صı�ʾ����ͨ�õ����ػ�����������������[91]:����ͨ��դ�����Ƶı߽�����ػ���Ϊ 3D �����塣�����������Ƶ�����,���ɵ��Ƶ����ر�ʾ��
��ϡ����������� [92]��[93],Mao ��[46] �״���������� 3D Ŀ���������Transformer (VoTr) ���ɡ����������Submanifold Voxelģ���Sparse Voxelģ��,�ֱ�ӷǿ����غͿ���������ȡ��������������ģ����,�ڶ�ͷ��ע��������(MSA)�Ļ�����,ʵ���˾ֲ�ע����������ע��������,�Ա��ִ������صĵͼ������ġ�������� VoTr ���Լ��ɵ�������������ص� 3D ������С�Ϊ�˽���������ص����� 3D ������� Transformer �ļ�������,�����Voxel Set Transformer (VoxSeT) [47] ��һ��set-to-set�ķ�ʽ����������塣������ע��������ĵ�������,�����һ��Voxel-based Self-Attention (VSA)ģ��,ͨ��Ϊÿ�����ط���һ���ѵ���ġ�latent codes��,�����������Set Transformer [94]����������㷨[48]��[49]��ο����ġ�
4.2 ���ڵ��Ƶ�Transformers
���������dz����ʽ�����Ʋ���,���ת��Ϊ���ػ���һ���̶�����ʧ������Ϣ[4],[5]����һ����,���ڵ�����ԭʼ��ʾ,�����������ݵ�����������Ϣ�����,��������� Transformer �ĵ��ƴ�����ܶ����ڻ��ڵ��Ƶ� Transformer ���롣�ṹͨ����Ϊ������:ͳһ�߶�(uniform-scale)�ṹ[12]��[33]��[50]��[63]��[81]�Ͷ�߶�(multi-scale)�ṹ[7]��[8]��[37]��[39] ],[51],[52]��
4.2.1 ͳһ�߶�
ͳһ�߶Ƚṹͨ�������ݴ��������б��ֵ��������ij߶Ȳ��䡣ÿ��ģ������������������������һ�¡���ߴ����ԵĹ����� PCT [12],������Ƕ���֮��,PCT ���ĸ�ȫ�� Transformer ģ��ֱ�Ӷѵ���һ����ϸ������������û�зֲ������ľۺϲ���,�������ڵ��Ʒָ���ܼ�Ԥ���������е������� Transformer������ȫ������ѧϰ��Ȼ��,����ȱ���ֲ�������Ϣ,ͳһ�߶ȵ� Transformer ����ȡ�ֲ�����������������������,ֱ�Ӵ����������ƻᵼ�¸��������ڴ����ġ�
4.2.2 ��߶�
��߶�Transformer��ָ��������ȡ�����в��ý���ʽ���Ʋ������Ե�Transformer,Ҳ��Ϊ�ֲ�Transformers��PT [7] �ǽ���߶Ƚṹ���봿 Transformer ����Ŀ�������ơ�PT �е� Transformer ��Ӧ���ڽ���ʽ(��)�������Ƽ���һ����,������������ͨ������ Transformer �IJ�����������������ļ��㡣��һ����,��Щ�ֲ�ṹͨ�����л��� KNN �ľֲ������ۺϲ��������־ֲ������ۺ���������Ҫ��ϸ�����֪������,����ָ�Ͳ�ȫ�����������һ��߶Ⱦۺϵľֲ�����������Ϊȫ������,���ڵ��Ʒ��ࡣ����,�����������߶� Transformer ���� [8]��[37]��[51]��[52],�������� EdgeConv [13] �� KPconv [88] ���оֲ�������ȡ,������ Transformer ��ȡȫ����������������ܹ���Ͼ���ǿ��ľֲ���ģ������ Transformer Խ��ȫ������ѧϰ����,�Ի�ø��õ�����������ʾ��
5 3D ����
��ͼ���� [29] ����,�� 3D ������ص�����Ҳ���Է�Ϊ������:������͵ͼ����������漰�������,���ص��ǽ� 3D ����ת��Ϊ���ǿ����������Ϣ��ȥ��Ͳ�ȫ�ȵͼ����������̽������������Ϣ��������������������û��ֱ�ӹ�ϵ,�����Լ�Ӵٽ�������
5.1 ������
�� 3D ���ƴ�������,������ͨ������:����ͷָ� [7]��[11]��[12]��[32]-[34]��[37]��[39]��[40] , [42], [44], [45], [51], [85], [86], [89], [95]�C[99], Ŀ���� [35], [46], [47] , [53]�C[55], [69], [77], [100]�C[102], ���� [56]�C[58], �� [59]�C[63], [71], [72] , [103] �ȵȡ�
5.1.1 ����ͷָ�
��ͼ�����[104]-[107]����,3D���Ʒ����ּ�ڽ�������3D��״����Ϊ�ض����,�������ڳ��������ӡ�����ɳ��,�Լ����ⳡ�������ˡ������г����˺��������� 3D ���ƴ�������,���ڷָ�����ı�����ͨ���Ǵӷ������緢չ������,������Ľ���Щ����һ����ܡ�
Xie��[11]�״ν�self-attention�����������ʶ����������״������[108]����״ƥ���Ŀ��ʶ����ɹ�������,�������Ƚ��������ת��Ϊ��״�����ı�ʾ����ʽ���ñ�ʾ��һ��concentric shell bins��ɡ������������ӱ��ʾ,������������� ShapeContextNet (SCN) ��ȡ����������Ϊ���Զ�����ḻ�ľֲ���ȫ����Ϣ,��һ��ʹ�õ����ע����ģ��,�Ӷ������� Attentional ShapeContextNet (A-SCN)��
��ͼ����� [87]��[109] �� NLP [83] �е���ע�������������,Zhao �� [7] �����һ����������ע�����ĵ���Transformer�㡣Point Transformer block���� Point Transformer layer�Ļ������Բвʽ�����ġ�PT �ı�������ʹ��Point Transformer blocks�����任�����ڵ��Ʒ���ijػ���������������,PT ��ʹ�� U-Net �ṹʵ�ֵ��Ʒָ�,���н�������������Գơ��������һ�� Transition Up ģ��,���ڴ��²������Ƽ��лָ���������������ԭʼ���ơ�����,��������Ծ�����Դٽ�������ƾ����Щ������Ƶ�ģ��,PT ��Ϊ��һ���� S3DIS ���ݼ� [110] ��Area 5�ϴﵽ���� 70% mIoU (70.4%) ������ָ�ģ�͡������� ModelNet40 ���ݼ��ϵ���״��������,Point Transformer Ҳȡ���� 93.7% ������ȷ�ʡ�
5.1.2 Ŀ����
������ 3D ����ɨ���ǵ��ռ�,3D Ŀ��������ΪԽ��Խ���ŵ��о����⡣�� 2D Ŀ������������,3D Ŀ������ּ�����3D�߽�����,[15] ����˵�һ������ Transformer �� 2D Ŀ������ DETR���佫 Transformer �� CNN �������,�������˷Ǽ���ֵ���� (NMS)������ʱ��,Transformer ��ص���Ʒ�ڻ��ڵ��Ƶ� 3D Ŀ��������Ҳ���ֳ����չ��̬�ơ�
�� VoteNet [113] �Ļ�����,[53]��[114] �״ν� Transformer ����ע�����������뵽���ڳ����е� 3D Ŀ���������С����������Multi-Level Context VoteNet(MLCVNet),ͨ��������������Ϣ���������ܡ���������,ÿ������patch��vote cluster������Ϊ Transformers �е�token��Ȼ��������ע��������ͨ���������patch��vote cluster�Ĺ�ϵ����ǿ��Ӧ��������ʾ�����ڼ�������ע����ģ��,MLCVNet �� ScanNet [80] �� SUN RGB-D ���ݼ� [79] �϶�ȡ���˱Ȼ���ģ���ߵ����ܡ�PQ-Transformer [100] ����ͬʱ��� 3DĿ�� ��Ԥ�ⷿ�䲼�֡����� Transformer �������ķ��䲼�ֹ��ƺ�ϸ������,PQ-Transformer �� ScanNet �ϻ���� 67.2% �� mAP@0.25��
�������������ֹ����鷽��,ͨ������Ӧ�ֲ������ڵĵ���ѧϰ�����Ŀ���ѡ��������Ȼ��,[54] ��Ϊ���������ڵĵ���grouping����������3DĿ��������ܡ����,���ǽ��� Transformers �е�ע�������������һ��group-free�Ŀ�ܡ�����˼���Ǻ�ѡĿ�������Ӧ�����Ը��������е����е���,�����ǵ��Ƶ��Ӽ����ڻ�ú�ѡĿ���,[54]����������ע����ģ���������ѡĿ��֮�����������Ϣ��Ȼ�������һ������ע����ģ��,�������е��Ƶ���Ϣ��ϸ��Ŀ��������ͨ���Ľ���ע�����ѵ�����,[54]�� ScanNet ���ݼ���ʵ���� 69.1% �� mAP@0.25����������㷨[55]��[69]��[115]���Բο����ġ�
5.1.3 Ŀ�����
3D Ŀ����ٽ���������(��ģ����ƺ���������)��Ϊ���롣�����������������Ŀ��(ģ��)�� 3D �߽���漰���Ƶ�������ȡ�Լ�ģ�����������֮��������ںϡ�
[56]��Ϊ��������еĸ��ٷ�����û�п��Ǹ��ٹ�����Ŀ�������ע�����仯�������������еIJ�ͬ����Ӧ�ö������ںϹ��̹��ײ�ͬ����Ҫ�ԡ�������һ�۲�,���������һ�ֻ��� LiDAR �� 3D Ŀ��������� TRansformer network (LTTR)���÷����ܹ�ͨ���������ʱ���ע�����仯���Ľ�ģ����������Ƶ������ںϡ�������˵,���ȹ�����һ�� Transformer ������,�ֱ�Ľ�ģ����������Ƶ�������ʾ��Ȼ��ʹ�ý���ע��������Transformer������,�����ͨ��������������֮��Ĺ�ϵ�ں�����ģ����������Ƶ������������ڻ��� Transformer �������ں�,LTTR �� KITTI �������ݼ��ϴﵽ�� 65.8% ��ƽ�����ȡ�[57] �������һ��Point Relation Transformer (PRT) ģ��,�ԸĽ�coarse-to-fine��Point Tracking TRansformer (PTTR) ����е������ںϡ��� LTTR ����,PRT ʹ����ע�����ͽ���ע�����ֱ�Ե����ڲ��͵���֮��Ĺ�ϵ���б��롣��֮ͬ������ PRT ���� Offset-Attention [12] �������������ݵ�Ӱ�졣����,PTTR ��ƽ���ɹ��ʺ;��ȷ���ֱ� LTTR 8.4% �� 10.4%,��Ϊ KITTI ���ٻ��ϵ��� SOTA��
����������רע�������ںϲ���ķ�����ͬ��[58]������һ��Point-Track-Transformer(PTT)ģ������ǿ�����ںϲ�����������ʾ��PTTNet �� KITTI �� Car�Ͼ�������� P2B ����� 9.0%��
5.1.4 ������
��������������Ϊ����,��������Ŀ�����ҵ�һ���任������ж��롣
[59] �������Deep Closest Point (DCP) ģ�ͽ� Transformer ���������뵽�����������С�δ����ĵ���������������Ƕ��ģ��,���� PointNet [5] �� DGCNN [13],�Խ� 3D ����ת���������ռ䡣Ȼ��ʹ�ñ��� Transformer ��������ִ������������������ľۺϡ����,DCP ���ÿ�������ֵ�ֽ� (SVD) ����������Ա任����DCP �ǵ�һ��ʹ�� Transformer ���Ľ����е���������ȡ�Ĺ��������Ƶ�,STORM [60] Ҳʹ�� Transformer ��ϸ�� EdgeConv [13] ��ȡ��point-wise����,�Բ������֮��ij��ڹ�ϵ�������� ModelNet40 ���ݼ���ȡ���˱� DCP ���õ����ܡ�ͬ��,[61]���ö�ͷ��ע�����ͽ���ע����������ѧϰĿ���Դ����֮�����������Ϣ�����ǵķ���רע�ڴ������ⳡ��,���� KITTI ���ݼ� [117]��
���,[72] ��Ϊ�ڵ������п���ʹ��ע���������滻ͨ�� RANSAC ���е���ʽ����ƥ����쳣ֵ���ˡ����������һ����Ϊ REGTR �Ķ˵��� Transformer ���,��ֱ�Ӳ��ҵ��ƶ�Ӧ��ϵ���� REGTR ��,���� KPconv [88] ���ɵĵ������������뵽������ͷ��ע�����ͽ���ע��������,���ڱȽ�Դ���ƺ�Ŀ����ơ�ͨ�����������,REGTR ��Ϊ ModelNet40 [112] �� 3DMatch [118] ���ݼ���SOTA�ĵ��������������Ƶ�,GeoTransformer [71] Ҳ������ע�����ͽ���ע�������ҵ�³����superpoint correspondences������ Recall��,REGTR �� GeoTransformer �� 3DMatch ���ݼ��϶��ﵽ�� 92.0%��Ȼ��,GeoTransformer �� 3DLoMatch [119] ���ݼ��ϳ��� REGTR 10.2%����������㷨[62]��ο����ġ�
5.1.5 ������Ƶ����
������Χ�� 3D �����Ƕ�̬�ġ�ʱ��������,���Ǵ�ͳ��֡�̶���������ȫ��ʾ�ġ����֮��,������Ƶ(�Թ̶�֡���ʲ����һ�����)��������ʵ�����ж�̬�������õı�ʾ���˽̬�����Ͷ�̬Ŀ����ڽ�����ģ��Ӧ������ʵ����dz���Ҫ��������Ƶ�����漰���� 3D ���Ƶ�ʱ������,����Transformer �����Ǵ���������Ƶ������ѡ��,�����ó�����ȫ��Զ�̽�����
������������, [64] ����� P4Transformer ������������Ƶ��ʵ�ֶ���ʶ��Ϊ����ȡ������Ƶ�ľֲ�ʱ������,��������������һ��ʱ�վֲ������ʾ��Ȼ��ʹ�õ��� 4D ��������ÿ���ֲ������������֮������Transformer ������,ͨ������������Ƶ��Զ�̹�ϵ�����պ����Ͼֲ������������P4Transformer �ѳɹ�Ӧ���ڵ��Ƶ� 3D ����ʶ��� 4D ����ָ������������������(����,3D����ʶ�����ݼ� MSR-Action3D [120] �� NTU RGB+D 60 [121] �� 4D ����ָ����ݼ� Synthia 4D [93]),ȡ���˱Ȼ��� PointNet++ �ķ������ߵĽ��,չʾ�� Transformers �ڵ�����Ƶ�����ϵ���Ч�ԡ�
5.2 �ͼ�����
�ͼ��������������ͨ���Ǿ����ڵ��������Ͳ������ܶȵ�ԭʼɨ����ơ����,�ͼ����������Ŀ���ǻ�ø������ĵ���,����������ڸ�����һЩ���͵ĵͼ�������������²���[43]���ϲ���[38]��ȥ��[36]��[65]����ȫ[50]��[66]-[68]��[73]��[74] ,[123],[124]��
5.2.1 �²���
����һ������ N ����ĵ���,�²�������ּ��������� M ����ĸ�С�ߴ�ĵ���,ͬʱ����������Ƶļ�����Ϣ������ Transformers ǿ���ѧϰ����,LightTN [43] ����ȥ����λ�ñ���,Ȼ��ʹ����һ��С�ߴ�Ĺ������Բ���ΪǶ��㡣����,MSA ģ�鱻��ͷ����ز�ȡ����ʵ��������,�����������Ž����˼���ɱ����ڽ����� 32 ����������,��Ȼ���Դﵽ 86.18% �ķ���ȷ�ʡ�����,�������� Transformer ���类��Ƴ�һ���ɲ�ж��ģ��,���Ժ����ز��뵽�����������С�
5.2.2 �ϲ���
���²����෴,�ϲ�������ּ�ڻָ���ʧ�ľ�ϸ������Ϣ[125]�����������ϲ�����ĵ��ƿ��Է�ӳ��ʵ�ļ�����״,��λ�ڸ���ϡ����Ʊ�ʾ��Ŀ������ϡ�PU-Transformer [38] �ǵ�һ���� Transformer Ӧ���ڵ����ϲ����Ĺ�����[38] �����������ӱ��ģ�顣��һ��ģ����Positional Fusion(PosFus)ģ��,ּ�ڲ�����ֲ�λ����ص���Ϣ���ڶ����� Shifted Channel Multi-head Self-Attention (SC-MSA) ģ��,ּ�ڽ����ͳ MSA �в�ͬhead���֮��ȱ�����ӵ����⡣ʵ��������,PU-Transformer չʾ�˻��� Transformer ��ģ���ڵ����ϲ����еľ�DZ����
5.2.3 ����
ȥ���Ա������ƻ��ĵ�����Ϊ����,���þֲ�������Ϣ����ɾ��ĵ��ơ���ƪ��ع���TDNet [36],��ÿ��������Ϊword token,֤���� NLP Transformer [6] �����ڵ���������ȡ������ Transformer �ı��������������ӳ�䵽��ά�����ռ䲢ѧϰ����֮��������ϵ��ͨ���ӱ���������ȡ������,���Ի������������Ƶ� latent manifold�����,����ͨ����ÿ��patch manifold���в��������ɸɾ��ĵ��ơ�
��һ�����ȥ�뷽����ֱ�Ӵ�����������˳������㡣����,һЩ�����״���ƿ��ܰ�����������(����)����,��Щ�������ɲ���������������ϵľ��淴������ġ�Ϊ�˼����Щ������������,[65] ���Ƚ������ 3D LiDAR ����ͶӰ�� 2D range image�С�Ȼ��ʹ�û��� Transformer ���Զ�������������Ԥ����������,������ȡ�����������ơ�
5.2.4 ��ȫ
�ڴ���� 3D ʵ��Ӧ����,������������Ŀ����ڵ������ڵ�,ͨ�����ѻ��Ŀ������������ơ��������ʹ�õ��Ʋ�ȫ��Ϊ 3D �Ӿ�������һ����Ҫ�ĵͼ�����
[66] �״����PoinTr,�����Ʋ�ȫת��Ϊ���ϵ����ϵķ�����������˵,��������������ƿ�����һ��ֲ����Ʊ�ʾ,��Ϊ�����ƴ�����������һϵ�е��ƴ�����Ϊ����,���������һ�����θ�֪�� Transformer block������ȱʧ���ֵĵ��ƴ�������һ�ִӴֵ�ϸ�ķ�ʽ,����ʹ�� FoldingNet [126] ����Ԥ��ĵ��ƴ�����ȫ���ơ���������㷨[67]��[68]���Բο����ġ�
6 3D��ע��������
���ڱ��� self-attention ģ��,���������ּ����� Transformers �� 3D ���ƴ����е����ܡ�
6.1 Point-wise����
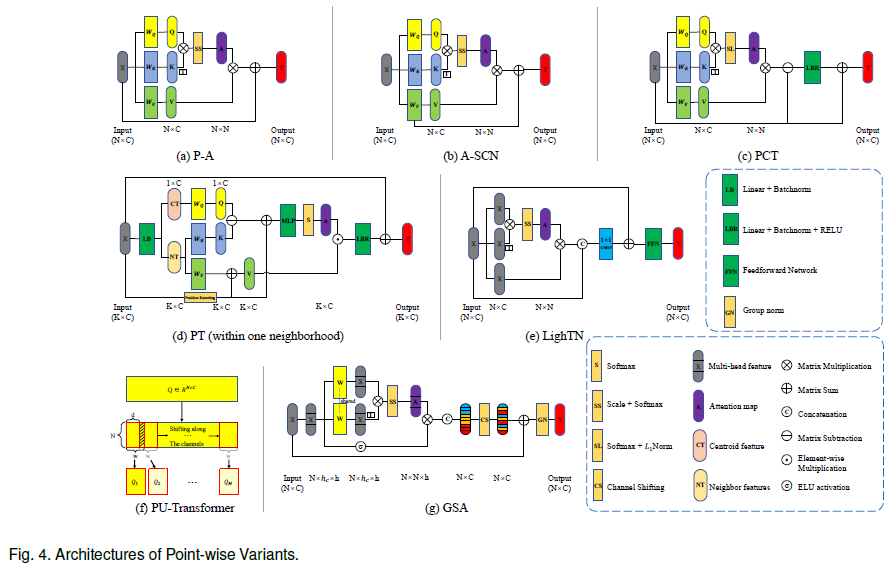
P-A [10](��ͼa)�� A-SCN [11](��ͼb)���� Transformer ��������ʹ�ò�ͬ�IJв�ṹ��ǰ��ǿ��ģ������������֮�����ϵ,������������ģ��������Value ����Ĺ�ϵ�����ʵ�����,�в����Ӵٽ���ģ������[11]��
��ͼ�������� [82] �е�������˹���������,PCT [12] ��һ������� Offset-Attention ģ��(��ͼc)����ģ��ͨ���������������ע����(SA)��������������X֮���ƫ��(����),��������ɢ������˹���㡣
PT [7](ͼ 4(d))���� Transformer ��������������������ע��������,ȡ���˳��õı������ע�����������ע�����,����ע�������߱�����,��Ϊ��֧�ֵ�������ͨ��������Ӧ����,�����������������������ֱ��﷽ʽ�� 3D ���ݴ������ƺ��dz����� [7]��������ؿ����㷨[8]��[43]��[38]��[44]���Բο����ġ�
6.2 Channel-wise����
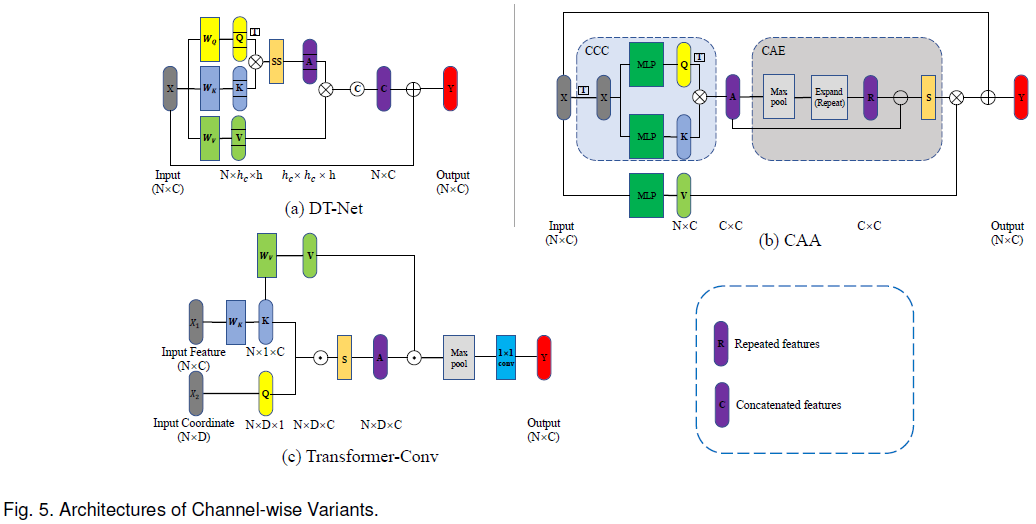
Dual Transformer Network (DT-Net) [39] ����˻���ͨ���� MSA,����ע��������Ӧ����ͨ���ռ䡣����ͼa��ʾ,�������ע�������Ʋ�ͬ,channel-wise MSA ��ת�õ� Query ����� Key ������ˡ����,��������ע����ͼ��������ͬͨ��֮��������ԡ�
����ͼb��ʾ,CAA ģ�� [40] �������Ƶķ��������ɲ�ͬͨ��֮������ƶȾ�����,�������һ�� CAE ģ���������;���,��ǿ��ͬͨ��֮�����ϵ������ۺ����ƻ��������Ϣ��[41] ������� Transformer-Conv ģ��ѧϰ������ͨ��������ͨ��֮���DZ�ڹ�ϵ������ͼc��ʾ,Query ����� Key ����ֱ��ɵ��Ƶ�������������ɡ�
7 �ԱȺͷ���
���ڶ� 3D Transformer �ڷ��ࡢ�����ָ����ָ��Ŀ����ȼ������������Ͻ���������ȽϺͷ�����
7.1 ����ͷָ�
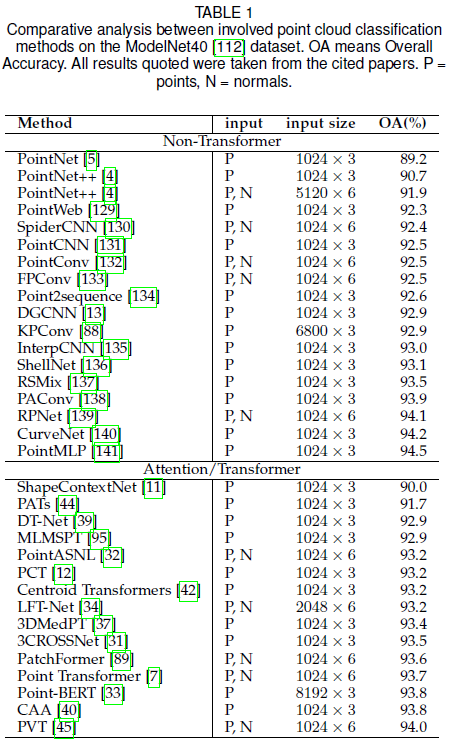
3D ���Ʒ���ͷָ������������������ս�Ե�����,Transformers �����з����˹ؼ����á��������ܷ�ӳ��������ȡ�����������������±�չʾ�˲�ͬ������ ModelNet40 [112] ���ݼ��ϵķ��ྫ�ȡ�Ϊ�˹�ƽ�Ƚ�,����ʾ���������ݺ������С��
�ӱ����п��Կ���������� Transformer �ĵ��ƴ��������� 2020 �꿪ʼ����,��ʱ�� ViT ���� [17] ���״ν� Transformer �ṹ����ͼ����ࡣ����ǿ���ȫ����Ϣ�ۺ�����,Transformers ������������Ѹ��ȡ�����ȵ�λ������� 3D Transformer �ķ���ȷ��ԼΪ 93.0%�����µ� PVT [45] �������Ƶ��� 94.0%,������ͬ�ڴ������ Transformer �㷨����Ϊһ�����˼���,Transformer �ڵ��Ʒ����ijɹ�չʾ������ 3D ���ƴ�������ľ�DZ�������Ļ�չʾ�˼������Ƚ��Ļ��ڷ� Transformer �ķ�����Ϊ�ο������Կ���,������ڷ�Transformer�ķ����ķ���ȷ���Ѿ�����94.0%,��ߵ���94.5%,��PointMLP[141]ʵ�֡�Transformer ������ʹ�õĸ���ע����������ͨ�õ�,δ�����кܴ��ͻ��DZ�����������Ž�ͨ�õ��ƴ��������Ĵ���Ӧ���� Transformer ��������ʵ�����Ƚ��Ľ��������,PointMLP �еļ��η���ģ����Ժ����ؼ��ɵ����� Transformer �������С�
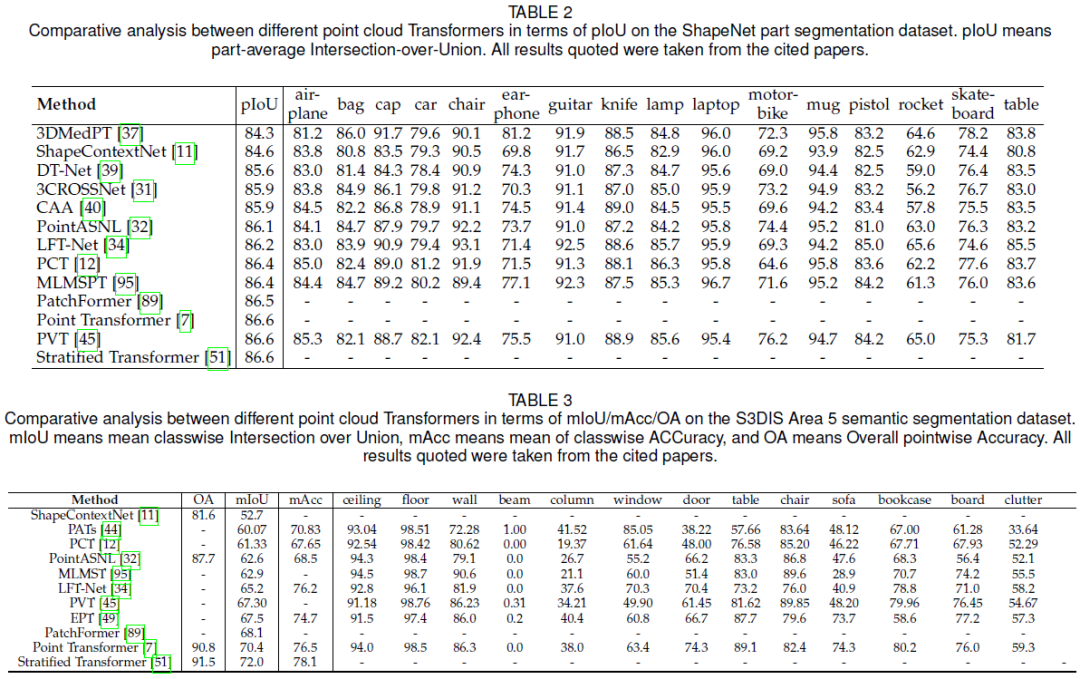
���ڲ����ָ�,ʹ�� ShapeNet �����ָ����ݼ� [142] ������бȽϡ������õ�part-average Intersection-over-Union ��Ϊ����ָ�ꡣ���2��ʾ,���л��� Transformer �ķ�����ʵ���˴�Լ 86% �� pIOU,���� ShapeContextNet [11],���� 2019 ��֮ǰ����������ģ�͡���ע��,Stratified Transformer [51] ʵ������ߵ� 86.6% pIOU����Ҳ�� S3DIS ����ָ����ݼ� [110](�� 3)������ָ������е����ģ�͡�
7.2 Ŀ����
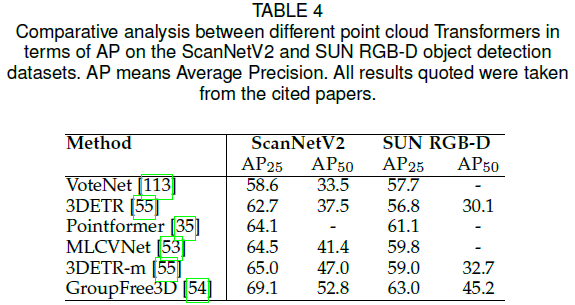
Transformers �ڵ��� 3D Ŀ�����е�Ӧ����Ȼ���١����ֻ���������� Transformer �� Attention �ķ�����һ��ԭ�������Ŀ����ȷ�������ӡ���4 �ܽ�������㷨���������ݼ��ϵ�����:SUN RGB-D [79] �� ScanNetV2 [80]��VoteNet [113] Ҳ��Ϊ�ο�,���� 3D Ŀ����Ŀ����Թ������� ScanNetV2 ���ݼ��е� AP@25 ����,���л��� Transformer �ķ������� VoteNet ���ֵø��á�Pointformer [35] �� MLCVNet [53] ���� VoteNet,��ȡ�������Ƶ����ܡ����Ƕ������� Transformers �е���ע������������ǿ������ʾ��GroupFree3D [54] û�������������ַ����еľֲ�ͶƱ����,����ֱ�Ӵӳ����е����е��ƾۺ�������Ϣ����ȡĿ����������� 69.1% �����ܱ���,ͨ����ע�������ƾۺ������Ⱦֲ�ͶƱ���Ը���Ч��3DETR [55] ��Ϊ��һ���˵��˵Ļ��� Transformer �� 3D Ŀ������,�� ScanNetV2 ���ݼ���ȡ�õڶ���,Ϊ 65.0%��
8 ���ۺ��ܽ�
8.1 ����
�� 2D ������Ӿ�һ��,Transformers �� 3D ���ƴ�������Ҳչʾ����DZ������ 3D ����ĽǶ�����,���� Transformer �ķ�����Ҫ�����ڸ�����,�������ͷָ������Ϊԭ���� Transformer ���ó�ͨ������������ϵ����ȡȫ����������Ϣ,���Ӧ�ڸ������е�������Ϣ����һ����,����Ͳ����ȵͼ����������̽���ֲ����������������ܵĽǶȿ�,3D Transformers ��������������ȷ��,����Խ�˴�������з��������Ƕ���ijЩ����,���������Ƚ��Ļ��ڷ�Transformer�ķ���֮�����в�ࡣ�������ʹ�� Transformer ��Ϊ�����Dz����ġ���������������µĵ��ƴ������������,����3D Transformer ��չѸ��,����Ϊһ�����˼���,�����һ��̽�������ơ�
���� Transformer �����Լ����� 2D ����ijɹ�Ӧ��,����ָ���� 3D Transformers �ļ���DZ��δ������
8.1.1 Patch-wise Transformers
3D Transformer ���Է�Ϊ����:Point-wise �� Channel-wise Transformers������,�ο� Transformers �� 2D ͼ�����е�̽�� [87],���Ը��ݲ�����ʽ�� Point-wise Transformers ��һ����Ϊ Pair-wise �� Patch-wise Transformers��ǰ��ͨ����Ӧ�ĵ���pair��������������ע����Ȩ��,�����߽���˸���patch�����е��Ƶ���Ϣ��
Ŀǰ,�� 3D ���ƴ�����������patch-wise Transformer �о������ǵ� patch-wise �����Ƽ�����ͼ�����еij�ɫ����,������Ϊ�� patch-wise Transformers ������ƴ�������������������
8.1.2 Adaptive Set Abstraction
PointNet++ [4] �����һ�����ϳ���(Set Abstraction,SA)ģ�����ֲ���ȡ���Ƶ���������������Ҫ����FPS��query ball grouping�㷨�ֱ�ʵ�ֲ������������;ֲ�patch������Ȼ��,FPS ���ɵIJ������������ھ��ȷֲ���ԭʼ������,�������˲�ͬ����֮��ļ��κ�������졣����,�ɻ�β���ļ�����״�Ȼ��������ӡ������ԡ����,ǰ����Ҫ����IJ�������������������,query ball grouping�����ڻ���ŷ����¾��������������,�����˵���֮���������������,��ʹ�þ��в�ͬ������Ϣ�ĵ��ƺ������鵽ͬһ���ֲ�patch�С����,��������Ӧ���ϳ������������ 3D Transformer �����ܡ����,�� 3D �����м��ֻ��� Transformer �ķ���̽������Ӧ���� [43]�����������˳��������ע�������Ʋ����ķḻ�Ķ��ںͳ���������ϵ����ͼ��������,[143]�������Deformable Attention Transformer(DAT)ͨ������ƫ������������deformed sampling points�����Եͼ������ڻ�������ȡ��������ӡ����̵Ľ�������һ�ֻ�����ע�������Ƶķֲ�Transformer����Ӧ������������������ġ�����,�� 2D ������ [144] ������,������Ϊ���� 3D Transformers �е�ע����ͼ��������ڵ���oversegmentatio �ġ�superpoint��[145],�����Ƽ� 3D ����ת��Ϊ���������ǿ��С����,��������Ӧ���༼��������������query ball grouping������
8.1.3 Self-supervised Transformer Pre-training
Transformers �� NLP �� 2D ͼ�������ϵijɹ��ܴ�̶��ϲ������������dz�ɫ�Ŀ���չ��,�������ڴ��ģ���ԼලԤѵ��[83]��Vision Transformer [17] ������һϵ���Լලʵ��,չʾ���Լල Transformer ��DZ�����ڵ��ƴ�������,�����мල�ĵ��Ʒ���ȡ�����ش��չ,�����Ʊ�ע��Ȼ��һ���Ͷ��ܼ����������ı�����ݼ��谭�˼ල�����ķ�չ,�ر����ڵ��Ʒָ������档���,�Ѿ������һϵ���Լල������������Щ����,���� 2D ��������ɶԿ����� (GAN) [146]���Զ������� (AE) [147]��[148] ��˹���ģ��(GMM)[149]����Щ����ʹ���Զ�������������ʽģ����ʵ���Լල���Ʊ�ʾѧϰ[96],��֤�����Լල���Ʒ�������Ч�ԡ�Ȼ��,Ŀǰ�������Լල Transformer Ӧ���� 3D ���ƴ��������Ŵ��ģ 3D ���ƵĿ�����Խ��Խ��,ֵ��̽�����ڵ��Ʊ�ʾѧϰ���Լල 3D Transformer��
8.2 �ܽ�
Transformer ģ���� 3D ���ƴ������������˹㷺��ע,���ڸ��� 3D ������ȡ����������Ŀ�ijɹ�������ȫ��ع������Ӧ���ڵ����������Ļ��� Transformer ������,������Ʒ��ࡢ�ָĿ���⡢����������ȥ�롢��ȫ��ʵ��Ӧ�á��������Ƚ����� Transformer ������,�������� 2D �� 3D Transformer �Ŀ�����Ӧ�á�Ȼ��,�����������ֲ�ͬ�ķ��෨�����������еķ�����Ϊ����,���Ӷ���Ƕȶ�����з���������,���Ļ�������һϵ��ּ��������ܺͽ��ͼ���ɱ�����ע�������塣�ڵ��Ʒ��ࡢ�ָ��Ŀ���ⷽ��,���Ķ������ķ��������˼�Ҫ�Ƚϡ����,����Ϊ 3D Transformer�ķ�չ���������DZ�ڵ�δ���о�����ϣ�����ε����ܹ����о���Աȫ���˽� 3D ���ν��,���������ǽ�һ�����¸������о�����Ȥ��
9 �ο�
[1] Transformers in 3D Point Clouds: A Survey
ת���ڹ��ں�:�Զ���ʻ֮��