������ѧϰ��,�������������Ŀ����: �ڸ����۲������� (����,��ʱ�����е��������л�������ģ�͵���������), ����һ��������н�ģ�� ��Ȼ����һ�������龰,������Ψһ�ġ� �����ܷ���ʲô�����������? ���ǿ��������������ı���������յ�����:
-
��
___�� -
��
___���ˡ� -
��
___����,�ҿ��Գ�ͷ����
���ݿɻ�õ���Ϣ��,���ǿ����ò�ͬ�Ĵ����, �硰�ܸ��ˡ�(��happy��)��������(��not��)�͡��dz���(��very��)�� ������,ÿ������ġ����ġ���������Ҫ��Ϣ(����еĻ�), ����Щ��Ϣ�غ���ѡ���ĸ��������, ������������һ�������ģ�ͽ�����������ϱ��ֲ��ѡ� ����,���Ҫ��������ʵ��ʶ�� (����,ʶ��Green��ָ���ǡ�����������������ɫ), ��ͬ���ȵ������ķ�Χ��Ҫ������ͬ�ġ� Ϊ�˻��һЩ�����������,���������ػص�����ͼģ�͡�
�������ɷ�ģ���еĶ�̬�滮
��һС��������˵����̬�滮�����, ����ļ���ϸ�ڶ����������ѧϰģ�Ͳ�����Ҫ, ��������������˼��ΪʲôҪʹ�����ѧϰ, �Լ�ΪʲôҪѡ���ض��ļܹ���
����������ø���ͼģ��������������, �������һ��������ģ��: ������ʱ�䲽t,�������ij��������ht, ͨ������P(xt�Oht)�������ǹ۲��xt�� ����,�κ�ht��ht+1ת�� ������һЩ״̬ת�Ƹ���P(ht+1�Oht)������ �������ͼģ�;���һ���������ɷ�ģ��(hidden Markov model,HMM)��
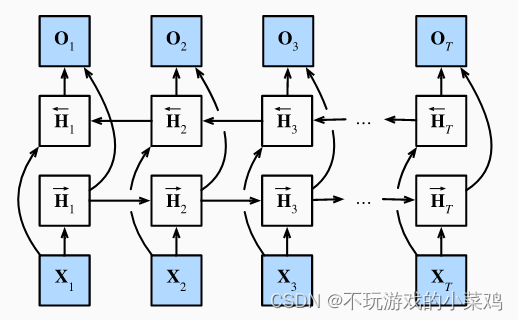
�������ɷ�ģ��

�ܽ�:
-
��˫��ѭ����������,ÿ��ʱ�䲽����״̬�ɵ�ǰʱ�䲽��ǰ������ͬʱ������
-
˫��ѭ�������������ͼģ���еġ�ǰ��-�����㷨���������ԡ�
-
˫��ѭ����������Ҫ�������б������˫�������ĵĹ۲���ơ�
-
�����ݶ�������,���˫��ѭ���������ѵ�����۷dz��ߡ�
����:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True) # bidirectional��˫�����
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device) # ˫��ѭ����������Ԥ��δ����Ϣ
?
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.GRU(num_inputs, num_hiddens, num_layers, bidirectional=True) # bidirectional��˫�����
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device) # ˫��ѭ����������Ԥ��δ����Ϣ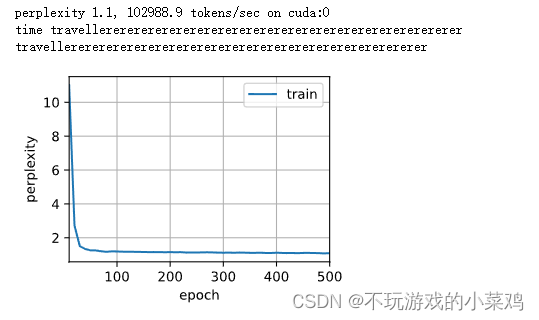
LSTM ��GUR�ڴ�������������ʱ,Ч�������һЩ��?