һ��MVSNetһЩ����
1��MVSNet ����������
�ο�ͼ���һ��pixel(����x)(r image),�������㷽����������(d_i)��Ӧ��һ����ά��(x_i)����������ֵ,��ͶӰ��matching image�����ij��pixel(x_i)(�������ϵ�C>��һ���õ���������)��λ�á�x��x_i��ƥ����ۻ���˵�����Ƴ̶�,����cost volume��¼�����������cost volumeͨ�����3D�����õ�һ����ʼ�����ͼ����������ʼ���ͼ(initial depth map)��reference image��ͬ����,ȥ���Ʊ߽緶Χ��ȷ�ʡ�
�Ӳο��ӽǵ�ȥ��Դ�ӽǵ����������Ӧ��ļ������,�����õ�Ӧ�Ծ�����������
���ӱ任�������Vi(d)�͵�i���ӽ�ͼ������Fi������ο�����ӽ������d��صķ���任��
����õ�����N+1��������,����������һ����,��������ҳ����ʾ32ͨ��,��ȿ����õڼ������ʾ��

2������������
��N+1��������ۺ�Ϊһ��ͳһ�Ĵ��ۿռ�,��N+1����ת��Ϊһ����
�����������ۺ������ں϶��ӽǵ���Ϣ,���DZȽ϶�Ӧ����������Ƴ̶�,���ƶ�Խ��,˵�����ƽ���Ӧ�����Խ�ӽ���ʵ��ȡ�
�����嶼���ص�������һ���,��ÿ�����һҳ(��32��channel)���Ͻǵĵ㶼ȡ����,Ȼ����㷽��,�õ������������ĵ�һҳ���Ͻǵĵ㡣��ÿ���ռ�㶼���������ļ���,�õ������һ����,�����յĴ��ۿռ�,ÿһ������һ�����
3������������
һ������һ����,��ά���������ͨ����Ϊ1,Ҳ���ǰ�ÿ���鶼���һҳֽ,һ��ֽ����һ�����,������ҳ((W,H)ƽ��)�ϵ�ÿһ����,�����ڵ���ҳ��ֵ���,��ô��������Ⱦ�Ϊ����ҳ��ȡֵ��ʹ��һ��3D U-Net�ṹ�������� cost ת��Ϊ����,������(W,H)ƽ���ϵ�ÿ����,��D����ĸ��ʺ�Ϊ1.,���õ����յĸ��ʿռ�P���ӽ�ͼ���е�ÿһ�������ڲο��������ϵ�µ���ȵĸ���
���ɵĸ�����ȿ������������ص���ȹ���,ͬʱ�����ڲ������Ƶ����Ŷ�
����ο���һЩ����
https://zhuanlan.zhihu.com/p/571631019
https://zhuanlan.zhihu.com/p/148569782
����1
����R-MVSNet
���������Ǻ�MVSNet��������,ƽ��ɨ��ת���ӽǹ���������,����ʱ��ʹ��ѭ��������RNN�������л�����,��2D�ľ�������GNU(�ſ�ѭ����Ԫ)������ÿһ������ͼ��
1��ѭ��������
��Щ������Ҫ���õĴ���������Ϣ,ǰ�������ͺ���������й�ϵ��ÿ�λ�õ���ǰ���ز������Լ����ݸ���һ�ڵ������״̬

����һ����ѭ��������,���ز��е�ֵS����ȡ���ڱ��ε�����X,��ȡ������һ�����ز��ֵS��,Ȩ�ؾ���W�������ز���һ�ε�ֵ��Ϊ��һ�ε�������ռ��Ȩ��,W�൱���Dz�������S������S�С�

GRU��RNN��һ��,,���Խ��RNN�в��ܳ��ڼ���ͷ����е��ݶȵ����⡣
����ѧϰ����ƪ����

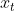 :��ʾ��ǰʱ����������
:��ʾ��ǰʱ����������
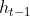 :��ʾ��һʱ�̵�����״̬,������ǰ��ļ��䡣
:��ʾ��һʱ�̵�����״̬,������ǰ��ļ��䡣
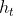 :���ݵ���һʱ�̵�����״̬
:���ݵ���һʱ�̵�����״̬
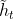 :��ѡ����״̬
:��ѡ����״̬
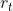 :������
:������
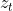 :������
:������
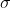 :sigmoid����,������ӳ�䵽[0,1]��Χ�ڡ�
:sigmoid����,������ӳ�䵽[0,1]��Χ�ڡ�
tanh : tanh����,������ӳ�䵽[-1,1]��Χ�ڡ�

��ʽ�Ƶ����Բο����ӵIJ���
��ѡ������Ϣ��ͨ����ǰ��Ϣ�������Լ������ų���һʱ�̵�����;���յ�����״̬����Ϊ�����Ż����һʱ�̵�ijЩ��Ϣ,�����뵱ǰ�ڵ�ĺ�ѡ����״̬��һЩ��Ϣ��

2������������
������ȷ���,˳������������,���ڴ�ռ�÷���Ҫ����ʹ��3D CNN,������ģ�͵ľ��Ⱥ�Ч��,ʹ�ø߷ֱ��ʵ����ͼ/�����ؽ���Ϊ���ܡ�
GRU+Softmax
��������Ϊ3��GRU��Ԫ��ջ�γ�һ���������,��ÿ��������(32 channel)ת��Ϊ16channel��Ϊ����,ÿһ��GRU�����Ϊ��һ�������,���channel��Ϊ16��4��1����ʧͼ,����Ӧ���Ƕ�Ӧ�����������ʧͼ��
��ͨ��softmax��õ������塣