��������:
Seq2seq model,��Transformerģ��Ϊ��(Encoder-Decoder�ܹ�)
Ӧ��: ������ʶ���������롢�����ϳɡ�?��������ˡ�NLP���ķ�������multi-label classification��object detection��ժҪ
2021 - Transformer (��)_��������_bilibili
(��ҵ��)
���ν�յ�Ӣ�ľ���Transformer,��TransformerҲ������֮���,�ᵽ��BERT�зdz�ǿ�ҵĹS,

?
Sequence-to-sequence (Seq2seq)
Transformer����һ��,Sequence-to-sequence��model,(��д:Seq2seq),��Sequence-to-sequence��model,����ʲ�N��
����֮ǰ�ڽ�input��һ��sequence��,case��ʱ��,����˵input��һ��sequence,��output�м��ֿ���
- һ����input��output�ij���һ��,���������ҵ����ʱ������
- ��һ��case��outputֻ,outputһ������,���������ҵ�ĵ�ʱ������
- �ǽ�����ҵ���case��,���Dz�֪��Ӧ��Ҫoutput�,�ɻ����Լ�����output�ij���,��Seq2seq

-
������˵,Seq2seqһ���ܺõ�Ӧ�þ��� ������ʶ
����������ʶ��ʱ��,����������Ѷ��,����Ѷ����ʵ����һ����vector,�����������ʶ�Ľ��,Ҳ������������ ����Ѷ��,����Ӧ������
���������ij���,��Ȼ����һЩ�S,����ȴû�о��ԵĹS,���������Ѷ��,���ij�����T,���Dz�û�а취֪��˵,���ݴ�T������������Nһ���Ƕ��١�
����ij����ɻ����Լ�����,�ɻ����Լ�ȥ���������Ѷ�ŵ�����,�Լ�������Ӧ��Ҫ�����������,�������������ʶ���,����ľ����e��Ӧ�ð���������,�ɻ����Լ�������,�����������ʶ
-
���кܶ�����������,����˵��ҵ�塢���ǻ�����������
�û�����һ�����Եľ���,�������һ�����Եľ���,���������������ʱ��,��������ֵij�����N,����ľ��ӵij�����N',��N��N'֮��ĹS,ҲҪ�ɻ����Լ�������
�������ѧϰ�������,�����machine learning,���������ĸ���,���������Ӣ�ĵĴʻ�,���Dz������������ĸ�Ӣ�ĵĹS,���������������Ķ���֮һ,��������һ�ξ���,���Ӣ�ĵľ���Ҫ�,�ɻ����Լ�����
-
���������������ӵ�����,����˵����������
�����������,��Ի���˵һ�仰,����˵machine learning,������IJ���Ӣ��,��ֱ������������Ӣ�ĵ�����Ѷ�ŷ������������
�����˵machine learning,��������ǻ���ѧϰ
��ʲ�N����Ҫ��,Speech Translation����������,��ʲ�N���Dz�ֱ������һ��������ʶ,����һ����������,��������ʶϵͳ����������ϵͳ,������ ��ֱ������������?
����������кܶ�����,�����������ֶ�û��,�������г�����ǧ������,�г���������ʵ��û�����ֵ�,����Щû�����ֵ����Զ���,��Ҫ��������ʶ,���ܸ�����û�а취,�����û������,�����������û�а취��������ʶ,��������û�п��ܶ���Щ����,����������,ֱ�Ӱ��������,�����а취�Ķ�������
������ʶ(̨������Ѷ��--->������������)
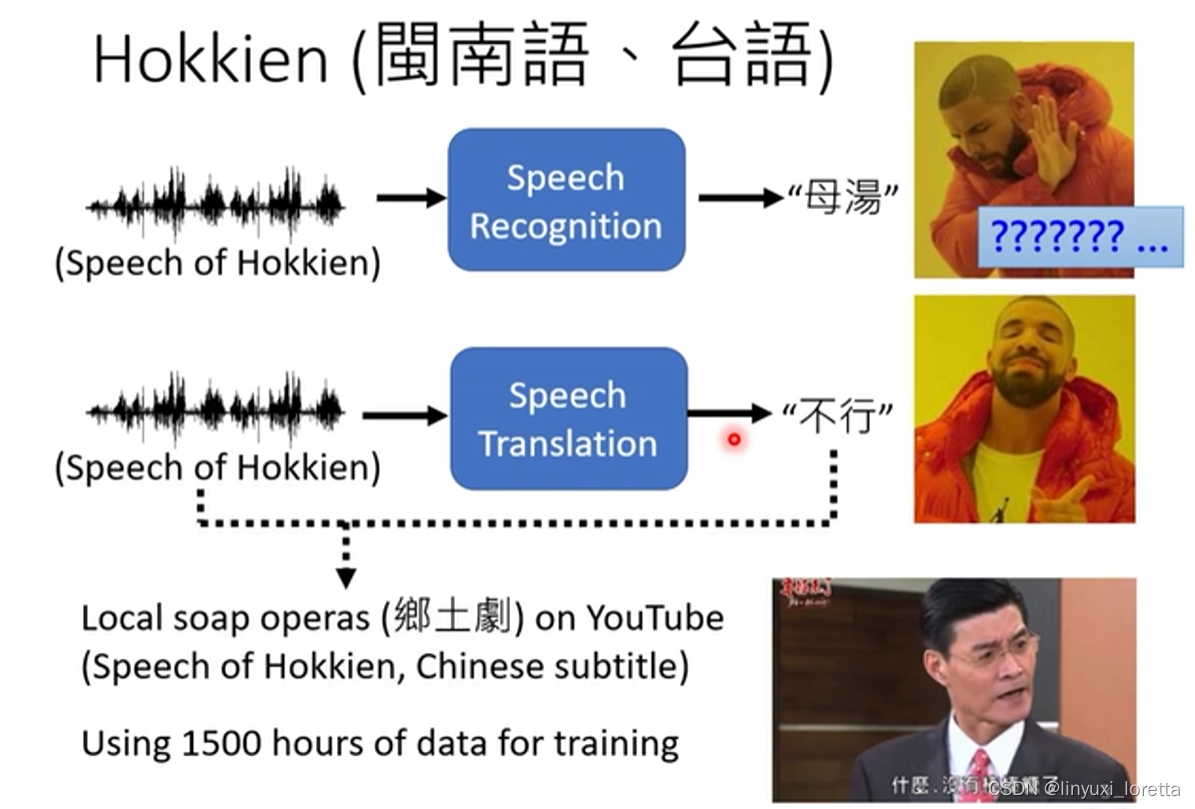
?һ���ܺõ�����Ҳ������,̨���������ʶ,? ?̨���������ֵ�,��û�����N�ռ�,������˵Сѧ���н�̨���������,��̨�������,������һ�����ܹ����ö���
(������è�����,����.....è����Ҫ��ѵ��������)
���ǿ���ѵ��һ��������·,���������·��ijһ������ ������Ѷ��,���������һ�����Ե����֡�
������Ҫѵ��һ��neural network,�����Ҫ��input��output�����,����Ҫ��̨�������Ѷ��,���������ֵĶ�Ӧ�S,�������������DZȽ������ռ��ġ�����˵YouTube����,�кܶ��������
���������,̨������ ������Ļ,������ֻҪ����̨������������,������Ļ������,�����̨������Ѷ��,������֮��Ķ�Ӧ�S,��Ϳ���Ӳtrainһ��ģ��,��Ϳ���trainһ��transformer,Ȼ��л���ֱ����̨���������ʶ,����̨�� �������
������ܻ��������뷨�ܿ�,���Һ����������кܶ�ܶ������,������ʵ���Ҿ�����,һǧ��ٸ�Сʱ�������������,Ȼ�� ���������ѵ��һ��,������ʶϵͳ

����ܻ����˵,���������кܶ������
- �������кܶ���Ѷ,�кܶ������,---->��Ҫ����
- ���������Ļ,��һ���������ж�����,---->��Ҫ����
- ̨�ﻹ��һЩ,����˵̨��ƴ��,̨��Ҳ���������������ֶ���,Ҳ�����ǿ����ȱ�ʶ������,����һ���н�,Ȼ���ڴ�����ת������,---> Ҳû��������
ֱ��ѵ��һ��ģ��,����������Ѷ��,���ֱ�Ӿ������ĵ�����,����û����̫�� ֱ�����ϵ���ȥ,��ѵ��һ��ģ�͵��О�,�ͽ���Ӳtrainһ��
������ܻ���˵,������Ӳtrainһ�������ܲ��ܹ�,��һ��̨��������ʶϵͳ��,��ʵ ��������п��ܵ�,������һЩ�����Ľ��
����������һǧ��ٸ�Сʱ��,�������Ժ�,����Զ�������һ��̨��,Ȼ���������һ�����ĵ�����,����������������
���������������������ӵ�

- ǰ����ok
- ���� �����ĸ�����? û��û�I(̨��),����֪��˵ Ҳ��Ӧ����� û��,
- ��������ʵҲ������������,
- (��ʱ���̨��,ת�����ľ�����Ҫ��װ)���̨������ĵĹS��Ҫ��װ�Ļ�,������ѧϰ����������һ������
���������Ҫ������˵,ֱ��̨������Ѷ��ת��������,����û�п���,���п��ܿ������õ���,����ʵ̨���кܶ��˶�����,̨���������ʶ,�������Ҫ֪�������й�,̨��������ʶ������Ļ�,���Կ�һ�����������վ
Text-to-Speech (TTS) Synthesis �����ϳ�
̨��������ʶ������,����̨��������ϳ�,���������һ��ģ��,����̨������ ������ĵ�����,�Ǿ���������ʶ,������ �������� �������Ѷ��,���������ϳ�
��߾���demoһ��̨��������ϳ�,? ֻҪgoogle ̨��s��,�Ϳ����ҵ�������ϼ�,? ?�e�����̨�������Ѷ��,
�����������Ҫ�����˵��һ��,���ڻ�û�������End to End��ģ��,���ģ�ͻ��Ƿֳ�����,�����Ȱ����ĵ�����,ת��̨���̨��ƴ��,������̨���KK����,�ڰ�̨���KK����ת������Ѷ��,
������̨���KK����,ת������Ѷ����һ��,����һ������Transformer��network,��ʵ��һ������echotron��model,�������Ͼ���һ��Seq2Seq model,��ų������������? (���Ͻ�ͼ)

?����������ǿ���,�ϳ�̨�������Ѷ�ŵ�,������������һ�ſ��e��ѧ����,Transformer������Seq2Seq��model
Seq2seq for Chatbot ���������
�ղŽ����Ǹ������Ƚ��йص�,����������,Ҳ�ܹ㷺��ʹ����Seq2Seq model
������˵�������Seq2Seq model,��ѵ��һ�����������

?��������˾��������˵һ�仰,��Ҫ����һ����Ӧ,���������������,���־���һ��vector Sequence,��������ȫ������Seq2Seq ��model,����һ�����������
���Ҫ�ռ������˵ĶԻ�,�����ֶԻ�������ռ�,���Ӿ� ��Ӱ��̨�� �ȵ�,
�����ڶԻ��e���г���,ijһ����˵Hi,������һ����˵,Hello How are you today,����Ϳ��Խ̻���˵,����������Hi,����������Ҫ��,Hello how are you today,Խ�ӽ�Խ��
�ǾͿ���ѵ��һ��Seq2Seq model,�Ǹ���˵һ�仰,���ͻ����һ����Ӧ
Question Answering (QA)? ? ?NLP
����ʵ��Seq2Seq model,��NLP������,��natural language processing�������ʹ��,�DZ�������ĸ���㷺,��ʵ�ܶ�NLP������,�����������question answering,QA������
��νQuestion Answering,���Ǹ�������һ������,Ȼ�����ʻ���һ������,ϣ�������Ը���һ����ȷ�Ĵ𰸡����ܶ�����ø�QAûʲô��ϵ������,�����ܿ����������QA��������˵:
- ����������������Ƿ���,�ǻ����������¾���һ��Ӣ�ľ���,��������������ӵĵ��ķ�����ʲ�N,Ȼ������������ǵ���
- �Զ�ժҪ,ժҪ���Ǹ�������һƪ��������,�����ѳ������µ��ص��¼����,������Ǹ�����һ������,������������ֵ�ժҪ��ʲ�N,Ȼ���ڴ������������һ��ժҪ
- ����������Ҫ�л�����Sentiment analysis, ���ǻ���Ҫ�Զ��ж�һ������,������Ļ��Ǹ����;������������һ���aƷ,Ȼ�������Ժ�,����Ҫ֪�����ѵ�����,�������ֲ�����һֱ���˼�ptt����,��ÿһƪ���¶�����,���Ծ���һ��Sentiment analysis model,������һƪ�����e��,���ᵽ��ĮaƷ,Ȼ��Ͱ���ƪ���¶���,���model�e��,ȥ�ж���ƪ����,�����滹�Ǹ��档�������Ҫ�ж����滹���������,���������������,�����滹�Ǹ����,Ȼ��ϣ���������Ը�������
���Ը�ʽ������NLP������,���������Կ�����QA������,��QA������,�Ϳ�����Seq2Seq model����

?������˵������һ��Seq2Seq model����,��������°�������һ��,�����������Ĵ�,�ͽ�����;�����������º�����,��һ�κܳ�������,����һ������
Seq2Seq modelֻҪ������һ������,���һ������,ֻҪ������һ��Sequence,���һ��Sequence�Ϳ��Խ�,���������QA������,Ӳ����Seq2Seq model��,������һƪ���¶�һ������,Ȼ���ֱ�������,���Ը�ʽ����NLP������,��ʵ���л���ʹ��Seq2Seq model

?����Ҫǿ��һ��,�Զ���NLP������,��Զ�����������ص��������,��������Щ�������u��ģ��,���õ����õĽ��
���Ǹ���������u����ģ��,�Ͳ���������һ�ſε��ص���,�������������Դ���,�������� ������Ȼ���Դ���,��Щ��ص���������Ȥ�Ļ���,���Բο�һ�� �γ���ҳ������(��ͼ),����ȥ���ϵ����ѧϰ���������Դ���,���ſε������e��ͻ����,��ʽ������������õ�ģ��,Ӧ����ʲ�N
������˵����������ʶ,���ǸղŽ�����һ��Seq2Seq model,����һ������Ѷ��,ֱ���������,���찡 Google�� pixel4,Google�ٷ�������˵,Google pixel4Ҳ����,N to N��Neural network,pixel4�e�����,��һ��Neural network,��������Ѷ��,�����ֱ��������
������ʵ�õIJ���Seq2Seq model,���õ���һ������,RNN transducer�� model,����Щģ�������Ǟ���,������ijЩ���������,������ʵ���Ա��ֵø��á�
Seq2seq for Syntactic Parsing??�ķ�����
�ղ����ǽ��˺ܶ�Seq2Seq model,������������Ȼ���Դ����ϵ�Ӧ��,? ��ʵ�кܶ�Ӧ��,������������һ��Seq2Seq model������,���㶼����Ӳ��Seq2Seq model������Ӳ����
������˵�ķ�����,������һ������,����Ҫ���������Ǯa��,һ���ķ���������?

?�ǽ����ķ�����Ҫ��������,���Ǯa�������ӵ�һ��Syntactic tree,�������ķ������������e��,��������Ҫ��deep learning��Ļ�,������һ������,����һ��Sequence,�����������������һ��Sequence,�����һ����״�Ľṹ,����ʵ��һ����״�Ľṹ,����Ӳ�ǰ���������һ��Sequence
�����״�ṹ���Զ�Ӧ��һ��,�����ӵ�Sequence,

?���Sequence�ʹ�������һ��tree ��structure,���Ȱ�tree ��structure,ת��һ��Sequence�Ժ�,��Ϳ�����Seq2Seq modelӲ����
��������������dz��Ŀ�,��������Ŀ������õ���,
����Զ�һƪ���½���,grammar as a Foreign Language

?��ƪ������ʵ����̫�µ�����,��ᷢ��������arxiv�����ʱ��,��14������,������ʵҲ��һ��,�Ϲ����ȼ�������,��ƪ����������ʱ��,�Ǹ�ʱ��Seq2Seq model��������,��ʱ��Seq2Seq model,��Ҫֻ�б����ڷ�����,������ƪ���µ�title�Ż�ȡ˵,grammar as a Foreign Language
�����ķ������������,������һ�����������,���ķ�����������һ������,ֱ�����õ�ʱ�����Ϟ�,ֻ�����ڷ����ϵ�ģ��Ӳ��,������õ�state of the art�Ľ��
��(�������ʦ)��ʵ�ڹ��ʻ����ʱ��,�����������һ����Oriol Vlnyals,�Ǹ�ʱ��Seq2Seq model,���Ǹ��dz����Ķ���,�Ǹ�ʱ�����ҵ���֪�e��,�Ҿ������ģ��,Ӧ����ͦ��train��,������˵,train Seq2Seq model��û��ʲ�Ntips,û�뵽�������ķ�����,��Seq2Seq model,��Ȼ����Ӳ����state of the art,��Ӧ����ʲ�N��������tips��
��˵û��ʲ�Ntips,��˵����Adam��û����,��ֱ��gradient descent,��train������,�ҵ�һ��train�ͳɹ���,ֻ����Ҫ�嵽state of the art,����������һ�²�������,��Ҳ��֪������Ļ��ٵ���,��������Seq2Seq model,������Ѿ����ܹ㷺��,Ӧ���ڸ�ʽ������Ӧ������
Multi-label Classification
����һЩ���������seq2seq's model,������˵ multi-label��classification��
�Ƚ�multi-class��classification,��multi-label��classification,���������ֺ���,��������ʵ�Dz�һ��������,multi-class��classification��˼��˵,�����в�ֻһ��class,����Ҫ��������,�Ǵ�����class�e��,ѡ��ijһ��class����
����multi-label��classification,��˼��˵ͬһ������,��������춶��class,������˵ ���������·����ʱ��

??,����ܻ�˵,����multi-label classification������? ? Ҫ��ô����,,�ܲ���ֱ�Ӱ�������һ��multi-class classification����������
������˵,�Ұ���Щ���¶���һ��classifier�e��
- ����classifierֻ�����һ����,���������ߵ��Ǹ���
- �����ھ����������ߵ�ǰ����,�����ܲ��ܽ�,multi-label��classification������
�����ַ����������в�ͨ��,���ÿһƪ���¶�Ӧ��class����Ŀ,������һ��
���� �����˵ ��ֱ��ȡһ��threshold,��ֱ��ȡ������ߵ�ǰ����,? classifier output������ߵ�ǰ����,�������ҵ���� ��Ȼ,��һ���ܹ��õ��õĽ�� �����N����
��߿�����seq2seqӲ��,����һƪ���� �������class �ͽ�����,�����Լ����� ��Ҫ�������class
?����˵seq2seq model,�����ɻ����Լ����������������,�����output sequence�ij����Ƕ���,��Ȼ ��û�а취����class����Ŀ,�Ǿ��û����������, ���Լ���? ?ÿƪ���� Ҫ��춶��ٸ�class
Seq2seq for Object Detection
������object detection,�����������seq2seq model,Ӧ�ð˸��Ӵ���������,��Ҳ������seq2seq's modelӲ��
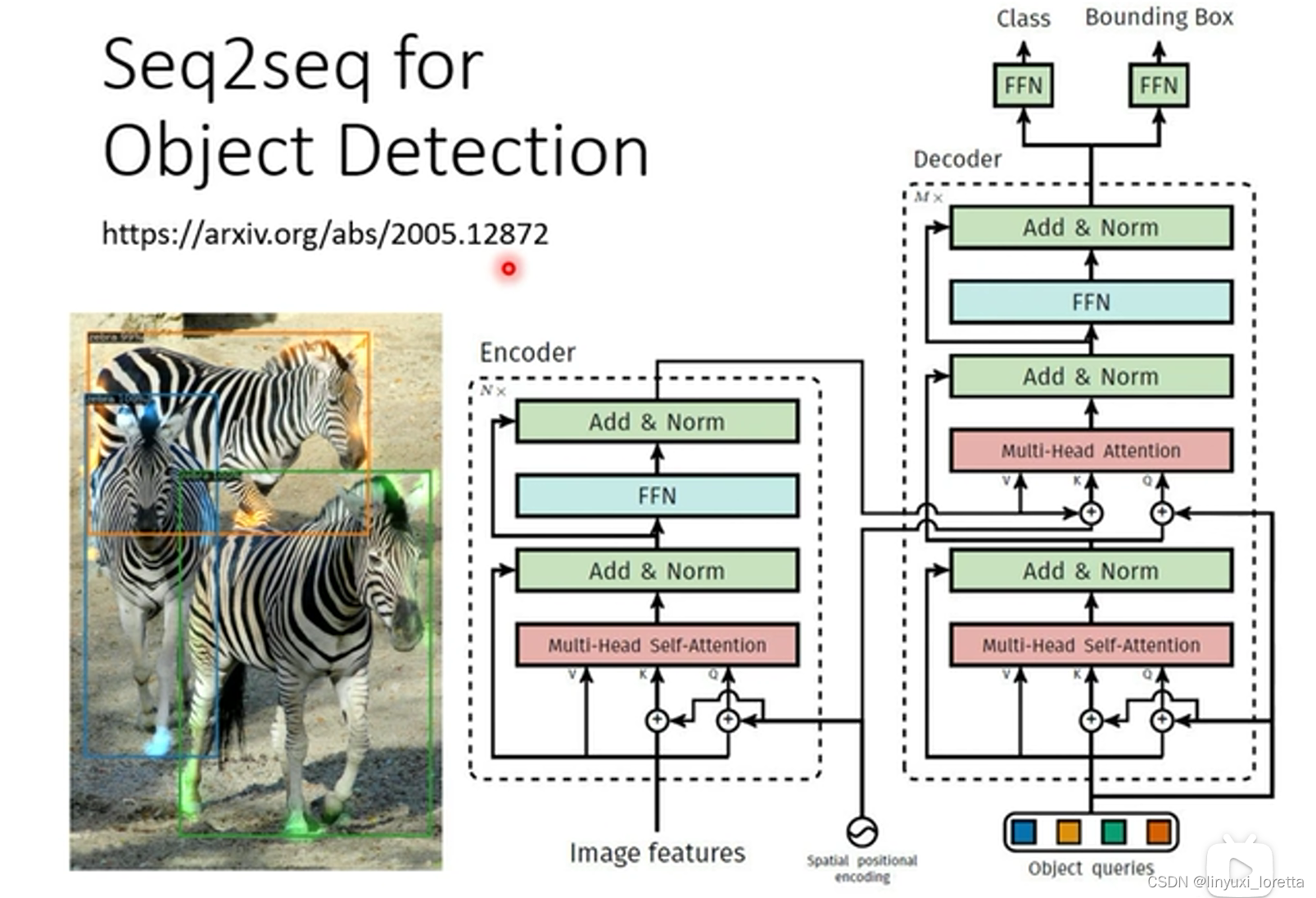
object detection���Ǹ�����һ��ͼƬ,Ȼ������ͼƬ�e�����������,? �����˵ ����ǰ��� ���Ҳ�ǰ���,���������� ������seq2seq'sӲ��,������N�� ������߾Ͳ�ϸ��, ������߷�һ�������������Ҳο�,�����N�����Ҫ������˵,seq2seq's model ����һ��,��powerful��model,����һ�������õ�model
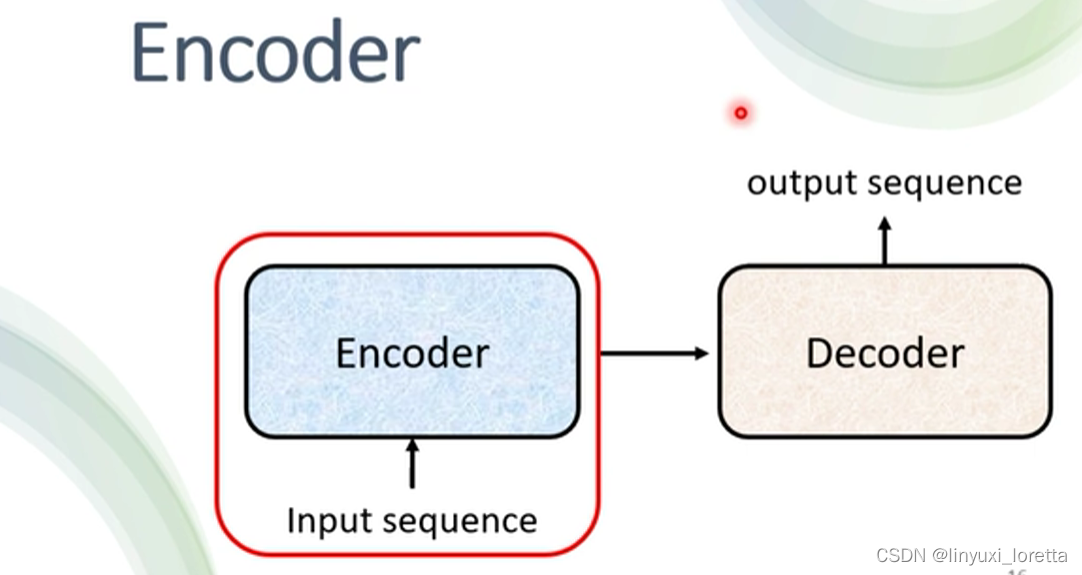
Encoder-Decoder
�������ھ���Ҫ��ѧ,���N��seq2seq�����,һ���seq2seq's model,���e���ֳ����� һ����Encoder,����һ����Decoder
��inputһ��sequence��Encoder,���������sequence,�ٰѴ����õĽ������Decoder,��Decoder����,��Ҫ���ʲ�N����sequence,��һ�� ���Ƕ�������ϸ��,Encoder�� Decoder�ڲ��ļܹ�
seq2seq model����Դ,��ʵ�dz����� ��14���9��,����һƪseq2seq's model,���ڷ�������� ���ŵ�Arxiv��,��������ʱ��seq2seq's model,���������DZȽ�����(��)��,

?���콲��seq2seq's model��ʱ��,��ҵ�һ���ḡ�������е�,���ܶ������ǽ��������,Ҳ����transformer
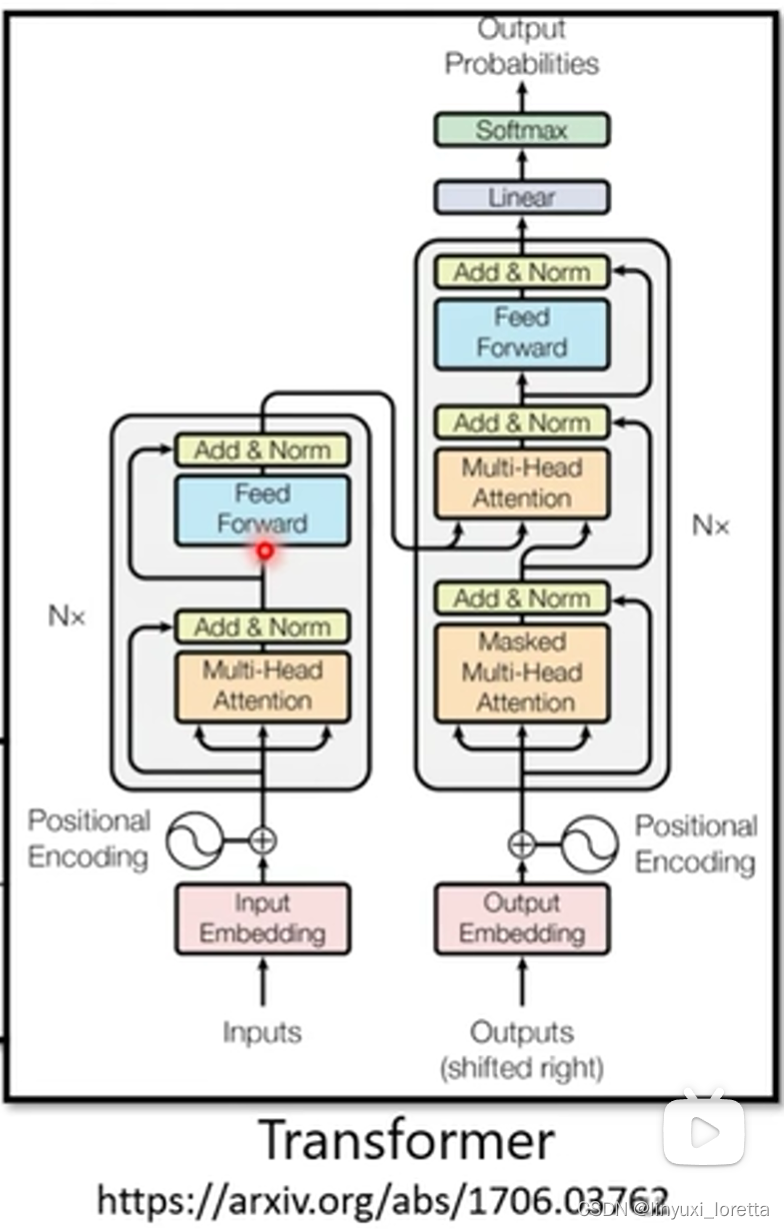
����һ��Encoder�ܹ�,��һ��Decoder�ܹ�,���e���кܶ�����̵�block,��һ�¾ͻὲһ��,���e��ÿһ���������̵�block,�ֱ�������������ʲ�N
Encoder
?seq2seq model? ? ?EncoderҪ��������,������һ������,�������һ������

?��һ�����������һ�������������,�ܶ�ģ�Ͷ���������,���ܵ�һ���뵽����,���Ǹոս����self-attention,��ʵ��ֻself-attention,RNN CNN ��ʵҲ���ܹ�����,inputһ������,output����һ��ͬ�����ȵ�����
��transformer�e��,transformer��Encoder,�õľ���self-attention,��߿������е㸴��,����������һ��ͼ,����ϸ�ؽ���һ��,���Encoder�ļܹ�,��һ��������ԭʼ��transformer��,�����e���ͼ���бȶ�,
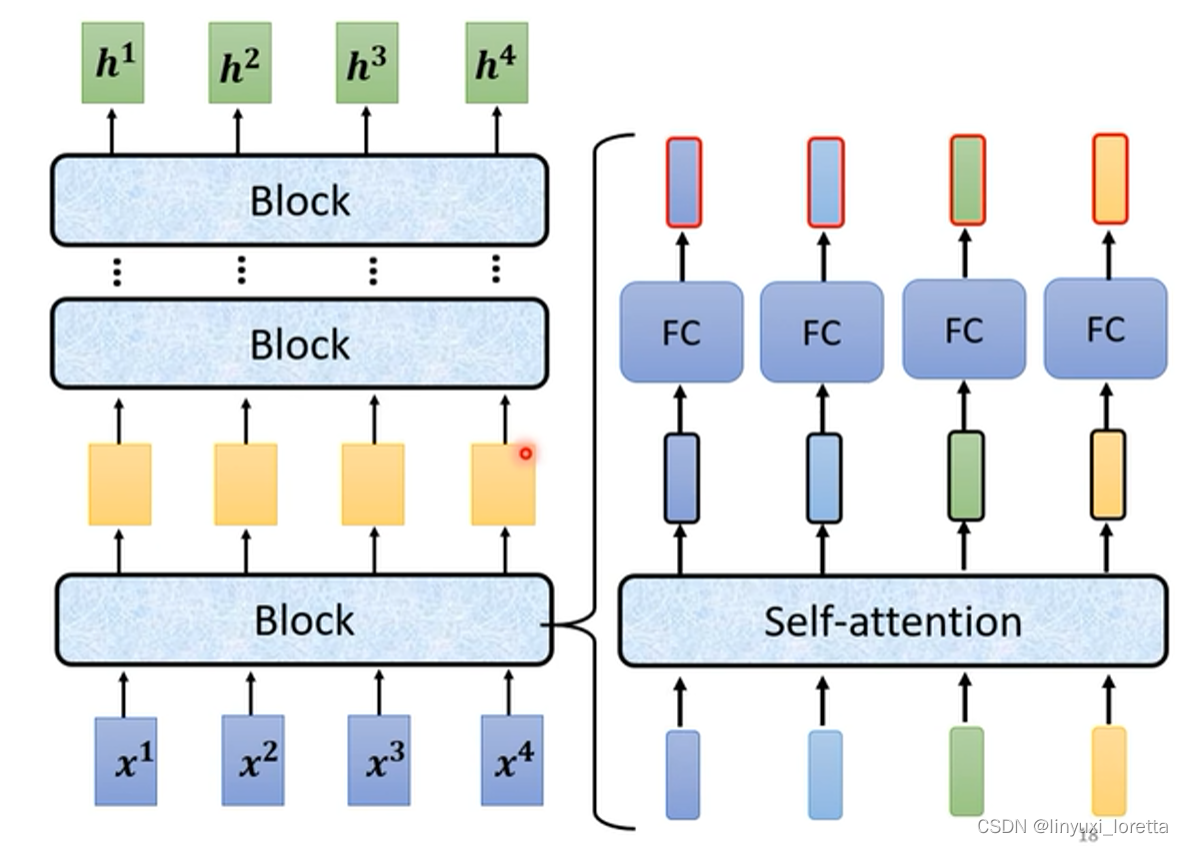
���ڵ�Encoder�e��,���ֳɺܶ�ܶ��block
ÿһ��block��������һ������,���һ������,������һ������ ��һ��block,��һ��block�������һ������,���������һ��block,�����һ��block,��������յ�vector sequence,
ÿһ��block ��ʵ,������neural network��һ��
ÿһ��block�e����������,�Ǻü���layer����������,��transformer��Encoder�e��,ÿһ��block��������,����������ӵ�
- ����һ��self-attention,inputһ��vector�Ժ�,��self-attention,��������sequence����Ѷ,Output����һ��vector.
- ��������һ��vector,���ٶ���fully connected��feed forward network�e��,��output����һ��vector,��һ��vector����block�����
?
��ʵ����ԭ����transformer�e��,�����������Ǹ����ӵ�
��֮ǰself-attention��ʱ��,����˵ ����һ��vector,�����һ��vector,��ߵ�ÿһ��vector,���ǿ����� ���е�input�Ժ�,���õ��Ľ��
��transformer�e��,��������һ�����,������ֻ��������vector,���ǻ�Ҫ�����vector��������input,,�����µ�output
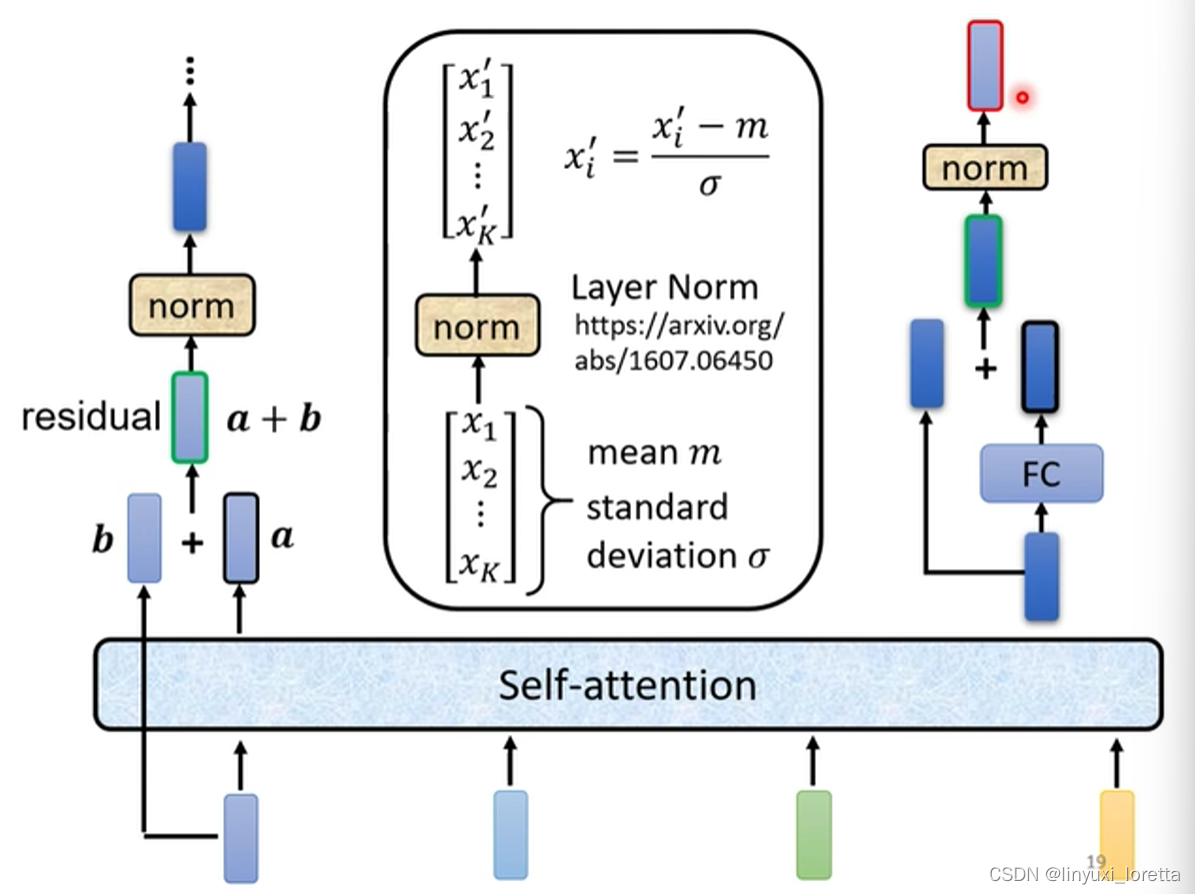
?�����ӵ�network�ܹ�,����residual connection,����ʵ����residual connection,��deep learning�������õ��Ƿdz��Ĺ㷺,֮�����������ʱ��Ļ�,������ϸ����,��ʲ�NҪ��residual connection
�������ھ���֪��˵,��һ��network��Ƶļܹ�,����residual connection,�����inputֱ�Ӹ�output������,�õ��µ�vector
�õ�residual�Ľ���Ժ�,�ٰ�����һ���������normalization,����õIJ���batch normalization,����õĽ���layer normalization
layer normalization��������,��bacth normalization����һ��:
����һ������ �������һ������,����Ҫ����batch,������������������,��������mean��standard deviation
����Ҫע��һ��,batch normalization�ǶԲ�ͬexample,��ͬfeature��ͬһ��dimension,ȥ����mean��standard deviation
��layer normalization,���Ƕ�ͬһ��feature,ͬһ��example�e��,��ͬ��dimension,ȥ����mean��standard deviation
(batch norm�����,layer norm�����)
�����mean,��standard deviation�Ժ�,�Ϳ�����һ��normalize,���ǰ�input ���vector�e��ÿһ��,dimension����mean,�ٳ���standard deviation�Ժ�õ�x',����layer normalization�����
�õ�layer normalization������Ժ�,���������� ����FC network������
��FC network���,Ҳ��residual�ļܹ�,? ֮���residual�Ľ��,����һ��layer normalization,�õ������,����encoder�e��,һ��block�����,���������ͦ���ӵ�
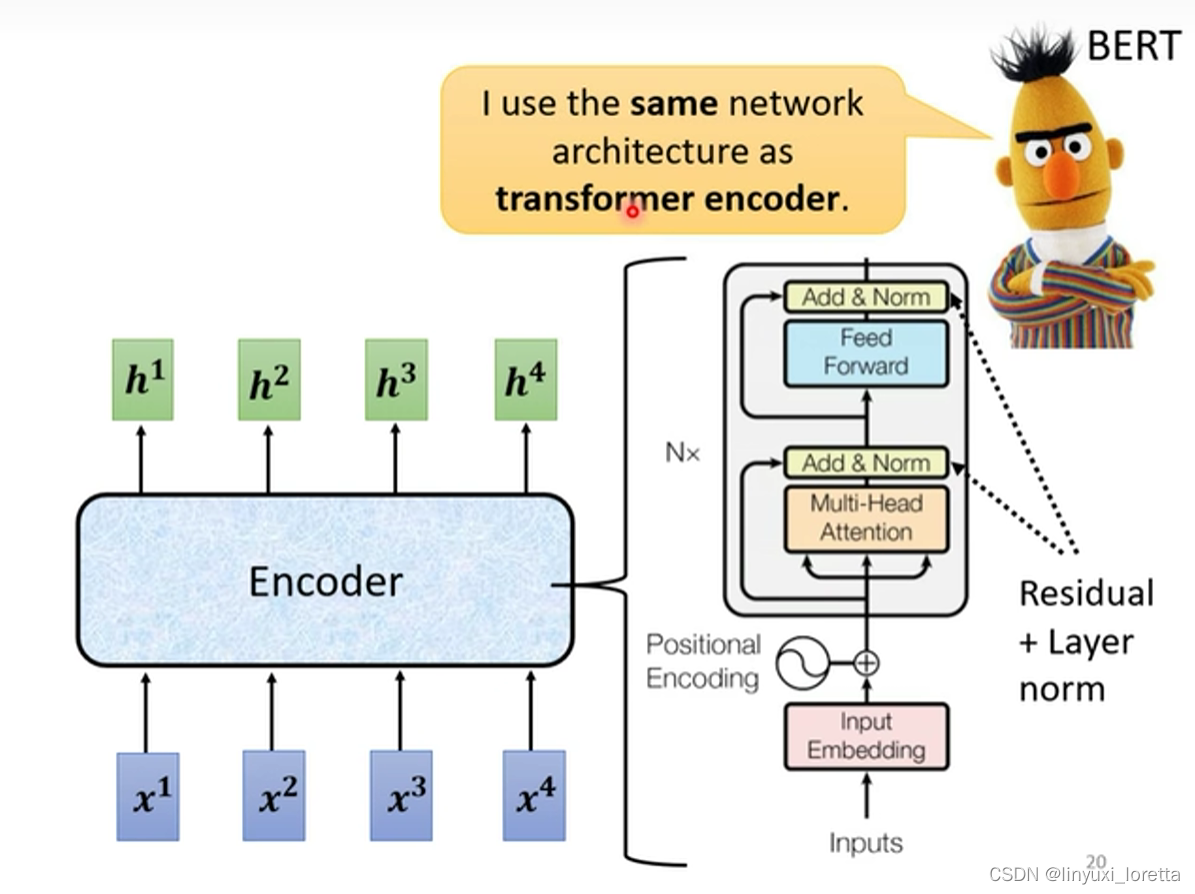
?����������߽��� ��һ��ͼ,��ʵ�������ǸղŽ����Ǽ�����
- ��input�ĵط�,���м���positional encoding,����֮ǰ�Ѿ��н���,�����ֻ����self-attention,��û��λ�õ���Ѷ,
- Multi-Head Attention,�������self-attention��block,������ر�ǿ��˵,����Multi-Head��self-attention
- Add&norm,����residual + layer normalization,���Ǹղ���˵self-attention,�м���residual��connection,��������Ҫ��layer normalization,
- ������,Ҫ��FC��feed forward network,�Ժ�����һ��Add&norm,����һ��residual��layer norm,����һ��block�����,
- Ȼ�����block���ظ�n��,������ӵ�block,��ʵ��֮��ὲ����,һ���dz���Ҫ��ģ��BERT�e��,�����õ� ,BERT,����ʵ����transformer��encoder
To Learn more
������� �����eһ���������ʺ�,���Ǟ�ʲ�N transformer��encoder,Ҫ������� ����������в���?
�� ��һ��Ҫ�������,���encoder��network�ܹ�,������Ƶķ�ʽ,�����ǰ���ԭʼ�����Ľ���������,��ԭʼ���ĵ���� ������������õ�,��optimal�����
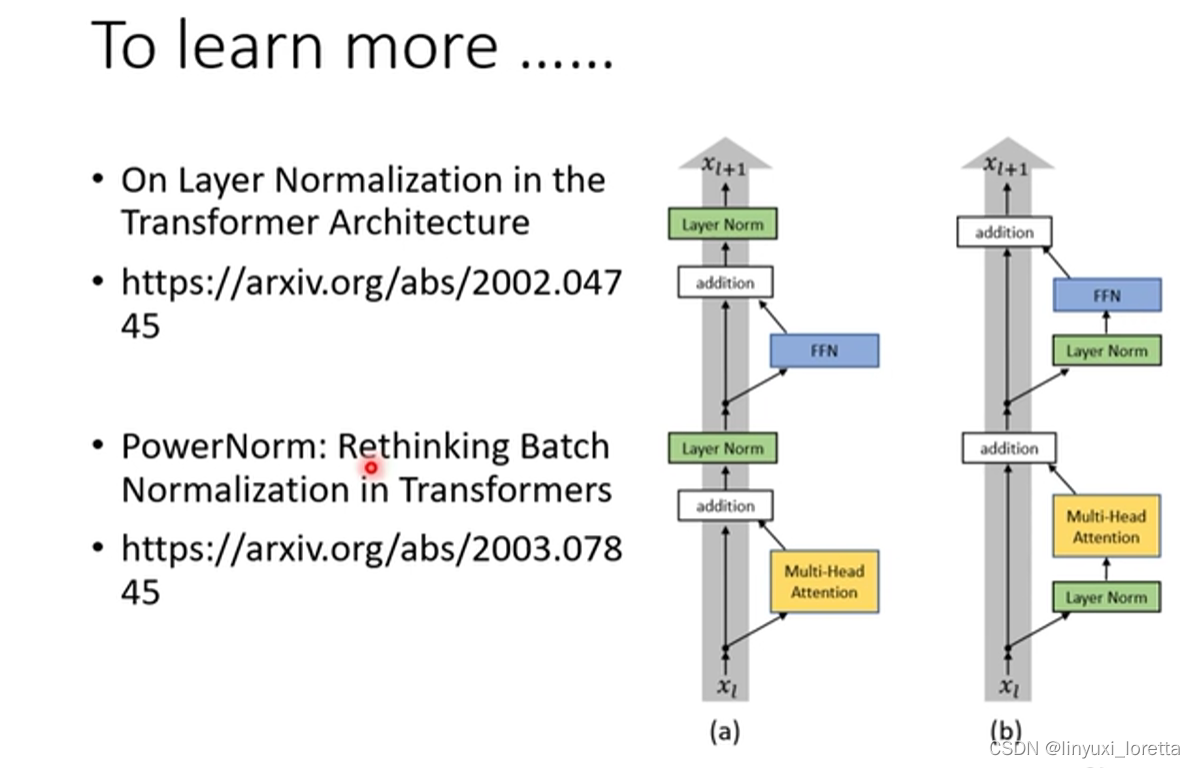
?
- ��һƪ���½�,on layer normalization in the transformer architecture,���ʵ�������� ��ʲ�N,layer normalization�Ƿ����Ǹ��ط���,��ʲ�N����������,residual����layer normalization,�ܲ��ܹ���layer normalization,�ŵ�ÿһ��block��input,? ����Կ���˵������ͼ,��ԭʼ��transformer,�ұ����ͼ������block,����һ��˳���Ժ��transformer,����һ��˳���Ժ� ����ǻ�ȽϺõ�,��ʹ���˵,ԭʼ��transformer �ļܹ�,������һ����optimal�����,����Զ����˼������,��û�и��õ���Ʒ�ʽ
- ��������һ���������,��ʲ�N��layer norm ��ʲ�N���DZ��,��ʲ�N����batch normalization,Ҳ����ƪpaper���Իش��������,��ƪpaper��Power Norm:,Rethinking Batch Normalization In Transformers,�����ȸ�����˵ ��ʲ�N��Transformers�e��,batch normalization����,layer normalization,��������˵,�������һ��power normalization,һ�����Ǻ�power����˼,�����Ա�layer normalization,��Ҫperformance����������һ��
Decoder
Decoder �C Autoregressive (AT)

?Decoder��ʵ������,�������Ứ�Ƚ϶�ʱ�����,�Ƚϳ����� Autoregressive Decoder,��� Autoregressive �� Decoder,�����N������
��������ʶ,������������˵��,��������ҵ�e�����������,��ʵ��һģһ����,��ֻ�ǰ��������,�ijɲ�ͬ�Ķ�������
������ʶ��������һ������,���һ������,����һ����������� Encoder,����˵��Ի���˵,����ѧϰ,�����յ�һ������Ѷ��,����Ѷ�� ���� Encoder�Ժ�,�������ʲ�N,�������һ�� Vector
Encoder ��������,�ܽ���˵����??����һ�� Vector Sequence,�������һ�� Vector Sequence
������,���ֵ� Decoder ������,Decoder Ҫ����������Ǯa�����,Ҳ�����a��������ʶ�Ľ��, Decoder ���N�a�����������ʶ�Ľ��
Decoder ��������,������ Encoder ������ȶ���ȥ,? ������N����ȥ,������ǵ�һ���ٽ� ������,���ȼ��� Somehow ������ij�ַ���,�� Encoder ��������� Decoder �e��,�ⲽ���ǵ�һ���ٴ���
Decoder ���N�a��һ������?
����,��Ҫ�ȸ���һ������ķ���,�������ķ���,����"��ʼ",�����̵�ͶӰƬ�e��,��д Begin Of Sentence,��д�� BOS������ Begin ����˼,�����һ�� Special �� Token,���������ĸ� Lexicon �e��,������㱾�� Decoder ���ܮa���������e��,���һ���������,����־ʹ����� BEGIN,�����˿�ʼ�������
����Decoder�ͳԵ��������ķ���,�ڻ���ѧϰ�e��,������Ҫ���� NLP ������,ÿһ�� Token,�㶼��������һ�� One-Hot �� Vector ����ʾ,One-Hot Vector ������һά�� 1,�������� 0,���� BEGIN Ҳ���� One-Hot Vector ����ʾ,
������Decoder ���³�һ������,��� Vector �ij��Ⱥܳ�,����� Vocabulary �� Size ��һ����
Vocabulary Size ָʲ�N?��������˵,��� Decoder ����ĵ�λ��ʲ�N,�������ǽ������������ĵ�������ʶ,���� Decoder �����������,����ߵ� Vocabulary �� Size ,���ܾ������ĵķ����ֵ���Ŀ
��ͬ���ֵ�,��������ֿ����Dz�һ����,���õ����ĵķ�����,����� ��ǧ��,һ����,�����ϵõ��� ��ǧ��,�ٸ���Ķ��Ǻ����� ��Ƨ����,������Ϳ���˵,��Ҫ����� Decoder,�����Щ���ܵ����ĵķ�����,��Ͱ����������
������˵,�������� Decoder,�ܹ���������� 3000 �������־ͺ���,�Ͱ�����������ط�,��ͬ������,������ĵ�λ �һ��,���ȡ�������Ǹ����Ե�����
����˵Ӣ��,�����ѡ�������ĸ�� A �� Z,���Ӣ�ĵ���ĸ,������ܻ������ĸ�����λ̫С��,���˿��ܻ�ѡ�����Ӣ�ĵĴʻ�,Ӣ�ĵĴʻ����ÿհ���������,��������ôʻ㵱�����,��̫���ˡ�������ᷢ��,�ղ������̵�ͶӰƬ�e��,���� Subword ����Ӣ�ĵĵ�λ,����һЩ����,����Ӣ�ĵ������ָ��г���,�������ָ�������λ,
������ĵĻ�,�Ҿ��þͱȽϵ���,ͨ����������ܾ������ĵ����������,��������λ
ÿһ�����ĵ���,�����Ӧ��һ����ֵ,������a���������֮ǰ,��ͨ��������һ�� Softmax,��������һ��,������һ�������e��ķ���,����һ�� Distribution,Ҳ����,����������e���ֵ,��ȫ��������,�ܺ� ���� 1
������ߵ�һ��������,���������յ����
����������e��,���ķ������,���Ի�,�͵�������� Decoder ��һ�����
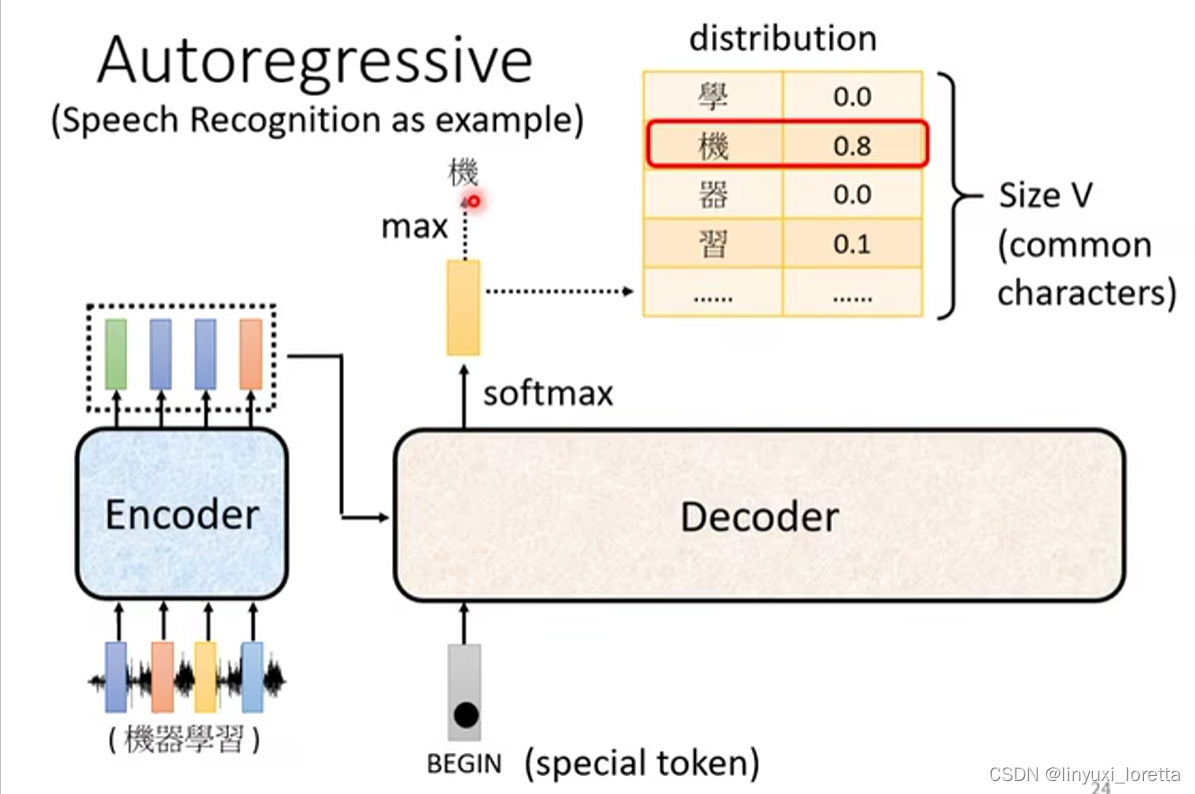
Ȼ�������,���ѡ����������� Decoder �µ� Input,? ? ԭ�� Decoder �� Input,ֻ�� BEGIN ����ر�ķ���,?Decoder ����������������:һ����BEGIN �������,һ����������
��������������,�����һ����ɫ������,���������ɫ�������e��,��ÿһ�����ĵ��ֵķ���,���ǻ�����ڶ������ʲô
?
Encoder �����ʵҲ������,��һ���ٽ� Encoder ������,Decoder �����N������,
���� Decoder ���� Encoder ��ߵ�����,����"��" ������"��"�� ����"ѧ",�������������һ������,��������e��,"ϰ"��������ֵķ�����ߵ�,�����������"ϰ"

Ȼ����� Process ,�ͷ���������ȥ,�����һ���ؼ��ĵط�,�����ر��ú�ɫ�����߰��������
Ҳ����˵ Decoder ����������,��ʵ������ǰһ��ʱ���,�Լ������,Decoder ����Լ������,����������������
���Ե�Decoder�ڲ���һ�����ӵ�ʱ��,����ʵ�п��ܿ�������Ķ���,������Ҫ��취���ݴ���ı�ʶ���������ȷ�������
����ܾ���,,�� Decoder �����Լ��a�������Ĵ��������,�ٱ� Decoder �Լ��Խ�ȥ,������ Error Propagation ������
Error Propagation ���������,һ���� ������
�п���,�����һ��,������������һ��,�������Ҫ���N����,��������,�������������,��������ȥ
��������һ����� Decoder�ڲ��Ľṹ��ʲ�N����

?���������,�� Encoder �IJ�������ʱʡ�Ե�,? ?�� Transformer �e��,Decoder �Ľṹ,������������ӵ�,�������е㸴��,�� Encoder ��������һ��,
�����������Ȱ� Encoder �� Decoder ����һ��,���Ƚ�һ������֮��IJ���,

?����ᷢ��˵,������ǰ� Decoder �м���һ��,�м���һ�����������,��ʵ Encoder �� Decoder,��û�����N��IJ��
��ֻ�����,���ǿ��ܻ�����һ�� Softmax,ʹ������������һ������,�������һ������һ���ĵط���,�� Decoder ���,Multi-Head Attention ��һ�� Block ����,������һ�� Masked,
��� Masked ����˼�������ӵ�,

?��������ԭ���� Self-Attention,Input һ�� Vector,Output ����һ�� Vector,��һ�� Vector ÿһ�����,��Ҫ���������� Input �Ժ�,��������,������� ��ʱ��,��ʵ�Ǹ��� �� ���е���Ѷ,ȥ���
�����ǰ� Self-Attention,ת�� Masked Attention ��ʱ��,���IJ�ͬ����,�������Dz����ٿ��ұߵIJ���,

?���ø�����һ��,������������,������Ҫ�a�� b2��ʱ��,����ֻ�õڶ���λ�õ� Query ,ȥ����һ��λ�õ� Key,�͵ڶ���λ�õ� Key,ȥ���� Attention,������λ�ø����ĸ�λ��,�Ͳ�����,��ȥ���� Attention
�Ǟ�ʲ�N������,��ʲ�N��Ҫ�� Masked?
���������ʵ�dz���ֱ��: ��������һ��ʼ Decoder ��������ʽ,���������һ��һ�������ġ�
���ԭ���� Self-Attention ��һ��,ԭ���� Self-Attention, a1��a4 ��һ���������ȥ��� Model �e���,�����ǽ� Encoder ��ʱ��,Encoder ��һ�ΰ�a1 ��a4 ,������������ȥ
���Ƕ� Decoder ����,���� a1, ����a2 ,����a3 ����a4,
��������Ǟ�ʲ�N,���Ǹ� Decoder ���Ǹ�ͼ����,Transformer ԭʼ�� Paper �ر����ǿ��˵,�Dz���һ��һ��� Attention,����һ�� Masked �� Self-Attention,��˼ֻ����Ҫ������˵,Decoder ���� Tokent,������Ķ�����һ��һ���a����,������ֻ�ܿ�������ߵĶ���,��û�а취�������ұߵĶ���
���� ���� Decoder ��������ʽ,�������,����һ���dz��ؼ�������,Decoder �����Լ�����,����� Sequence �ij���
���ǵ�������� Sequence �ij���Ӧ���Ƕ���,���Dz�֪��
��û�а취���Ĵ������ Sequence �ij���,��֪������� Sequence �ij����Ƕ���,������˵,������ 4 ������,���һ������ 4 ������,ʵ��������������Ӧ���e��,�����������ȵĹS,�Ƿdz����ӵ�,������ʵ���ڴ����������Լ�ѧ��,�������һ�� Input Sequence ��ʱ��,Output �� Sequence Ӧ��Ҫ�
��������Ŀǰ�������� Decoder����������Ļ����e��,������֪����ʲ�Nʱ��Ӧ��ͣ����,���a���ꡱϰ���Ժ�,�������Լ����ظ�һģһ���� Process,�Ͱ�ϰ,��������,Ȼ��Ҳ�� Decoder ,�ͻ��һ�����ߡ�,Ȼ�������,��һֱ������ȥ,��Զ������ͣ����

?��������뵽���Ľ���

,����һ��������ϵ����״�ͳ,������ PTT ����,
,��� Process ,���Գ����ü�����,����ͣ����,��Ҳ��֪����ʲ�N, ,��Ҫ���N����ͣ����
Ҫ����ð��ȥ��һ����,�Ƹ���,����ͣ������

��������Ҫ�� Decoder ��������,Ҳ��һ��,Ҫ�����������һ����,������Ҫ�ر�ʱ�һ���ر�ķ���,�������,�� END ����ʾ�������ķ���
���Գ����������ĵķ�����,���� BEGIN ����,�㻹Ҫ�ʱ�һ������ķ���,����"��",����ʵ�����̵ij�ʽ�e��,���ǰ� ��ʼ�������,��ͬһ����������ʾ
�������,��� BEGIN ֻ���������ʱ�����,��ֻ���������ʱ�����,���������̵ij�ʽ�e��,�������ϸ�о�һ�µĻ�,�ᷢ��˵ END �� BEGIN,�õ���ʵ��ͬһ������,�����ò�ͬ�ķ���,Ҳ����ȫ���Ե�,Ҳ��ȫû������
������������,��Decoder����������ϡ��������,
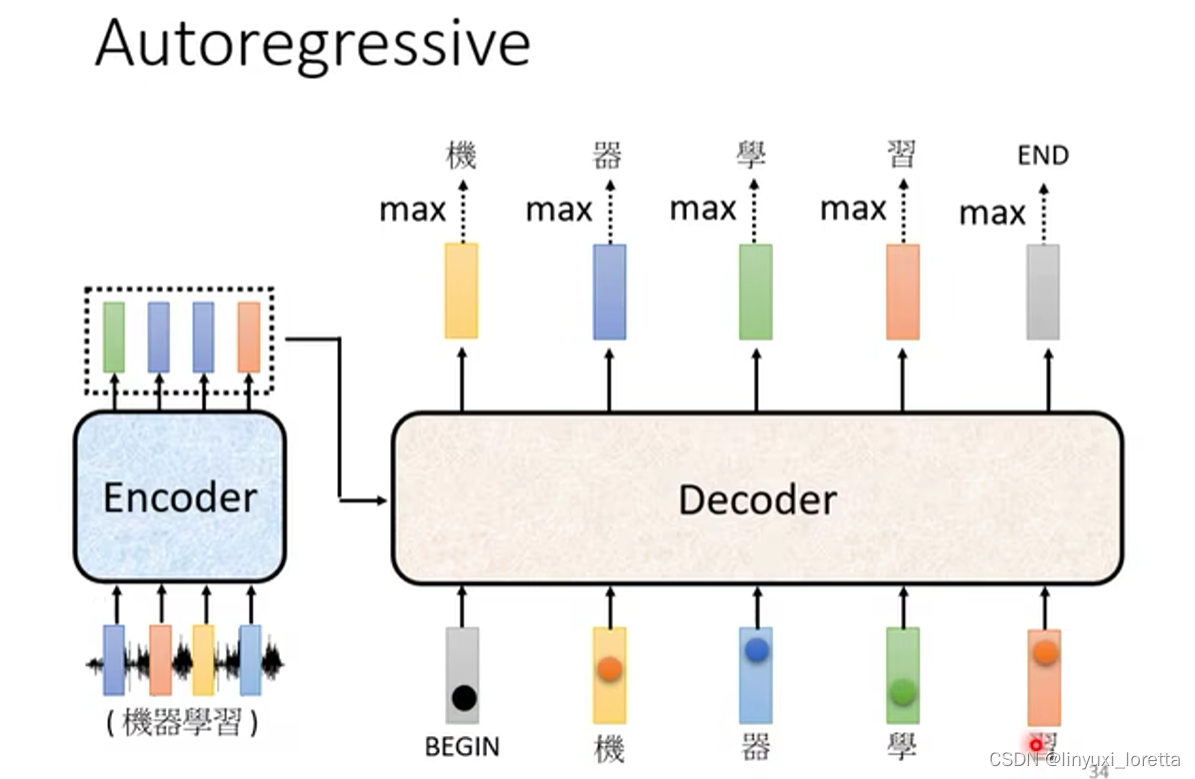
�����ڴ�˵,����"ϰ"���������Ժ�,Decoder��Ҫ��������ϡ���Ҳ����˵,����"ϰ"���������Ժ�,?Decoder ���� Encoder �������� Embedding,������ "BEGIN","��" "��" "ѧ" "ϰ"�Ժ�,������Щ��Ѷ�Ժ� ��Ҫ֪��˵,���������ʶ�Ľ���Ѿ�������,����Ҫ�ٮa������Ĵʻ���
���a������������END,���Ƕϵ��Ǹ�����,���Ļ��ʱ���Ҫ������,Ȼ�����������������,�����������Ĺ���,���� Decoder �a�� Sequence �Ĺ���,�ͽ�����
������� Autoregressive Decoder,�������ķ�ʽ
Decoder �C Non-autoregressive (NAT)
������? �dz���̵ؽ�һ��,Non-Autoregressive �� Model
Non-Autoregressive ,ͨ����д�� NAT,������ʱ�� Autoregressive �� Model,Ҳ��д�� AT,
Non-Autoregressive �� Model �����N������
AT v.s. NAT

?��� Autoregressive �� Model ��:������ BEGIN,Ȼ������ w1,Ȼ������ w1 ��������,����� w2,ֱ����� END ��ֹ
�� NAT ��:�ͼ����������ڮa�������ĵľ���,���������ήa��һ����,����һ�ΰ��������Ӷ��a������
NAT �� Decoder���ܳԵ���һ���ŵ� BEGIN �� Token,��Ͱ�һ�� BEGIN �� Token ��������,����һ�ήa��һ�� Token �ͽ�����
������˵,����㶪���� 4 �� BEGIN �� Token,���ͮa�� 4 �����ĵ���,���һ������,�ͽ�����,������ֻҪһ������,�Ϳ�����ɾ��ӵ�����
�������ܻ���һ������:�ղŲ���˵��֪������ij���Ӧ���Ƕ�����,������������N֪�� BEGIN Ҫ�Ŷ��ٸ�,���� NAT Decoder ������?
û�� �����û�а취����Ȼ��֪��,û�а취��ֱ�ӵ�֪��,�����м�������
- һ��������,������learnһ�� Classifier,��� Classifier ,���� Encoder �� Input,Ȼ�������һ������,������ִ��� Decoder Ӧ��Ҫ����ij���,����һ�ֿ��ܵ�����
- ��һ�ֿ�����������,��Ͳ������߶�ʮһ,����һ�� BEGIN �� Token,��ͼ���˵,����������ľ��ӵij���,���Բ��ᳬ�� 300 ����,��ͼ���һ�����ӳ��ȵ�����,Ȼ�� BEGIN ,����� 300 �� BEGIN,Ȼ��ͻ���� 300 ������,Ȼ��,���ٿ���ʲ�N�ط���� END,��� END �ұߵ�,�͵�����û�����,�ͽ�����,��������һ�ִ��� NAT ����� Decoder,��Ӧ������ij��ȵķ���
�� NAT �� Decoder,����ʲ�N�����ô�,
-
����һ���ô���,���л�,��� AT �� Decoder,����������ľ��ӵ�ʱ��,��һ��һ���֮a����,�����������,����Ҫ�������һ�ٸ��ֵľ���,�������Ҫ��һ�ٴε� Decode
���� NAT �� Decoder ��������,���ܾ��ӵij������,����һ������ͮa���������ľ���,�������ٶ���,NAT �� Decoder �����ܵñ�,AT �� Decoder Ҫ��,�����������˵,��� NAT Decoder ���뷨��Ȼ����,����� Transformer �Ժ�,������ Self-Attention �� Decoder �Ժ���е�
�����ǰ����������Ǹ� LSTM,�� RNN �Ļ�,����������һ�� BEGIN,��Ҳû�а취ͬʱ�a��ȫ�������,�����������һ��һ���a����,������û����� Self-Attention ֮ǰ,ֻ�� RNN,ֻ�� LSTM ��ʱ��,�����Ͳ���������Ҫ��ʲ�N NAT �� Decoder,�����Դ����� Self-Attention �Ժ�,�� NAT �� Decoder,���ھ�����һ�����ŵ��о���������
-
�� NAT �� Decoder ��������һ���ô�����,��Ƚ��ܹ�����������ij���,�������ϳɞ���,��ʵ�������ϳ��e��,NAT �� Decoder ���Ƿdz����õ�,��������һ��ʲ�Nϡ�� ����������
�����ϳɽ����㶼������,Seq2Seq ��ģ������,����֪����,��һ������ Tacotron ��ģ��,������ AT �� Decoder
��������һ��ģ�ͽ� FastSpeech,������ NAT �� Decoder,�� NAT �� Decoder ��һ���ô�,��������Կ���������ij���,�����Ǹղ�˵���N����,NAT �� Decoder ����
�������һ�� Classifier,���� NAT �� Decoder Ӧ������ij���,��������������ϳɵ�ʱ��,����������ͻȻ��Ҫ�����ϵͳ����һ��,����,����Ͱ��Ǹ� Classifier �� Output ���Զ�,�������ٶȾͱ�������,
������������������ NAT �� Decoder,������ Explicit ȥ Model,Output ����Ӧ���Ƕ��ٵĻ�,��ͱȽ��л���ȥ����,��� Decoder ����ij���Ӧ���Ƕ���,��Ϳ��������ֵı仯
why? NAT �� Decoder,�����һ�������о�����,��������Ȼ�����Ͽ����������ֵ�����֮��,������ƽ�л�������������,���� NAT �� Decoder ,���� Performance,���������� AT �� Decoder
���Է����кܶ�ܶ���о���ͼ��,NAT �� Decoder �� Performance Խ��Խ��,��ͼȥ�ƽ� AT �� Decoder,����������Ҫ�� NAT �� Decoder,�� AT �� Decoder Performance һ����,������Ҫ�÷dz���� Trick ���ܹ��쵽,�� AT �� Decoder ��� Train һ��,NAT �� Decoder ��Ҫ���ܶ�����,���п��ܸ� AT �� Performance ���
��ʲ�N NAT �� Decoder Performance ����,��һ���������ǽ���Ͳ�ϸ����,���� Multi-Modality ������,���������Ҫ��������˽� NAT,�ǾͰ�֮ǰ�Ͽ�,��������Ͽβ��������,����https://youtu.be/jvyKmU4OM3c������߸���Ҳο���? ?NATҲ�Ǹ����,
Encoder-Decoder
��������Ҫ��Encoder �� Decoder�����м������N������Ѷ����? ?,Ҳ���Ǹղ����ǿ����������������һ��
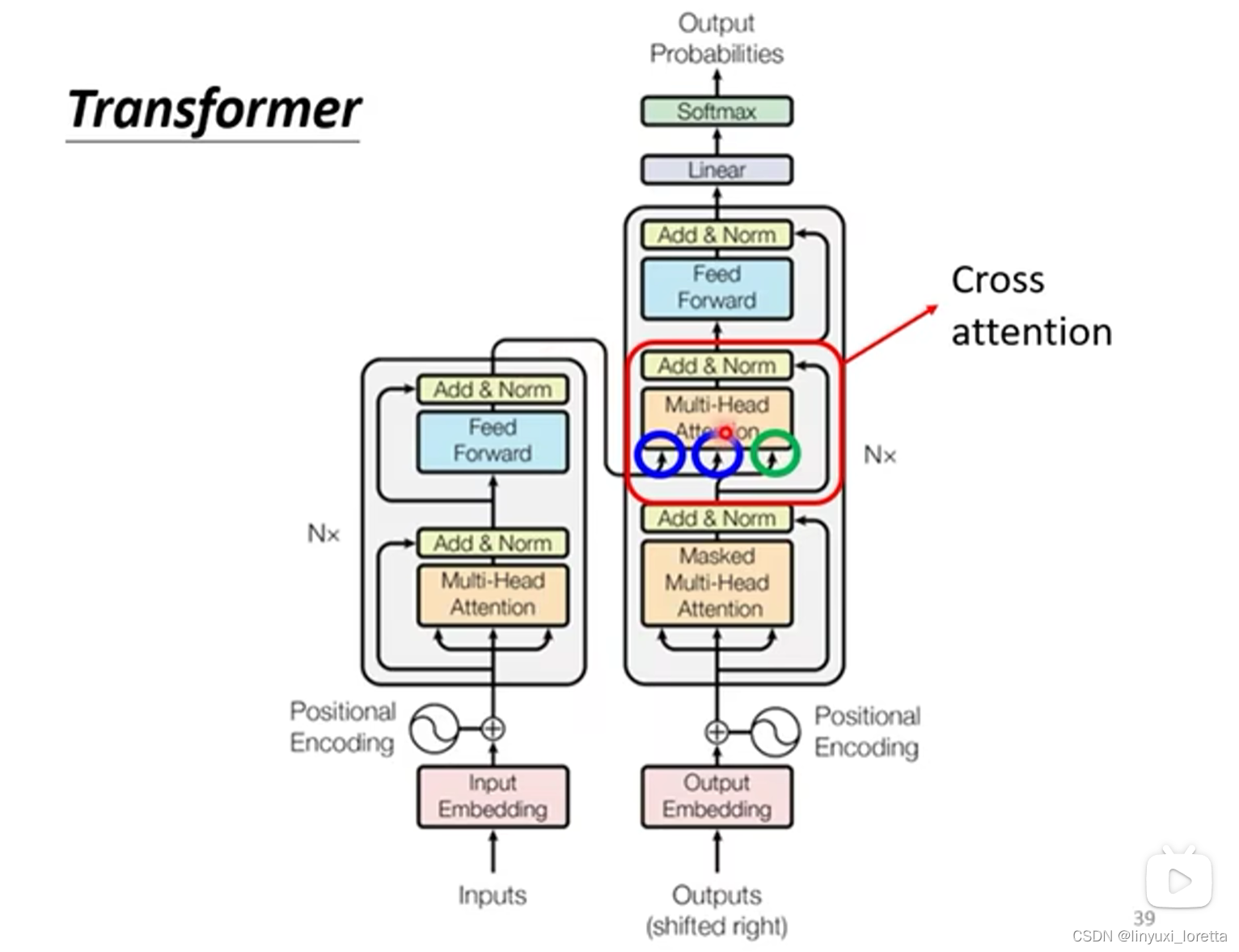
?������ Cross Attention,�������� Encoder �� Decoder ֮����Ř�,����һ���e�氡,�ᷢ����������������� Encoder,Encoder �ṩ������ͷ,Ȼ�� Decoder �ṩ��һ����ͷ,���Դ������������ͷ,Decoder ���Զ��� Encoder �����
�����ģ��ʵ���������N��������,�����Ǿ�ʵ�ʰ��������Ĺ��̸����չʾһ��

?������������ q ����� Decoder,k �� v ����� Encoder,�������ͽ��� Cross Attention
?���� Decoder ����ƾ�����a��һ�� q,ȥ Encoder ��߳�ȡ��Ѷ����,������������ Decoder ����� FC �� Network �� Input
(mask������ʵ��������̵IJ��л�,��ʦ��˳��,ʵ���Dz��е�)

?
�����һ��ʵ�ʵ������ϵ� Cross Attention�����������Ч��չʾ,����һƪ�Ƚ������seq2seq model �ɹ������Ա�ʶ��һƪ����,������ICASS 2016,�� state of the art(��ʱ��õ�������ʶϵͳ)ֻ��һ������,�ô�Ҿ���seq2seq����������ʶ���ƺ�����DZ����,��ʱ��Encoder ��,Decoder������LSTM,�����Ѿ���Cross Attention�����Ļ�����,ֻ��û��self-attention����,
��ߵ�ֵ����attention�ķ���,��ɫԽ�����attention�ķ��� ,���Ǧ���ֵԽ��,
ÿ����רע���ǵ�����Ѷ��,Ӧ�þ�����������
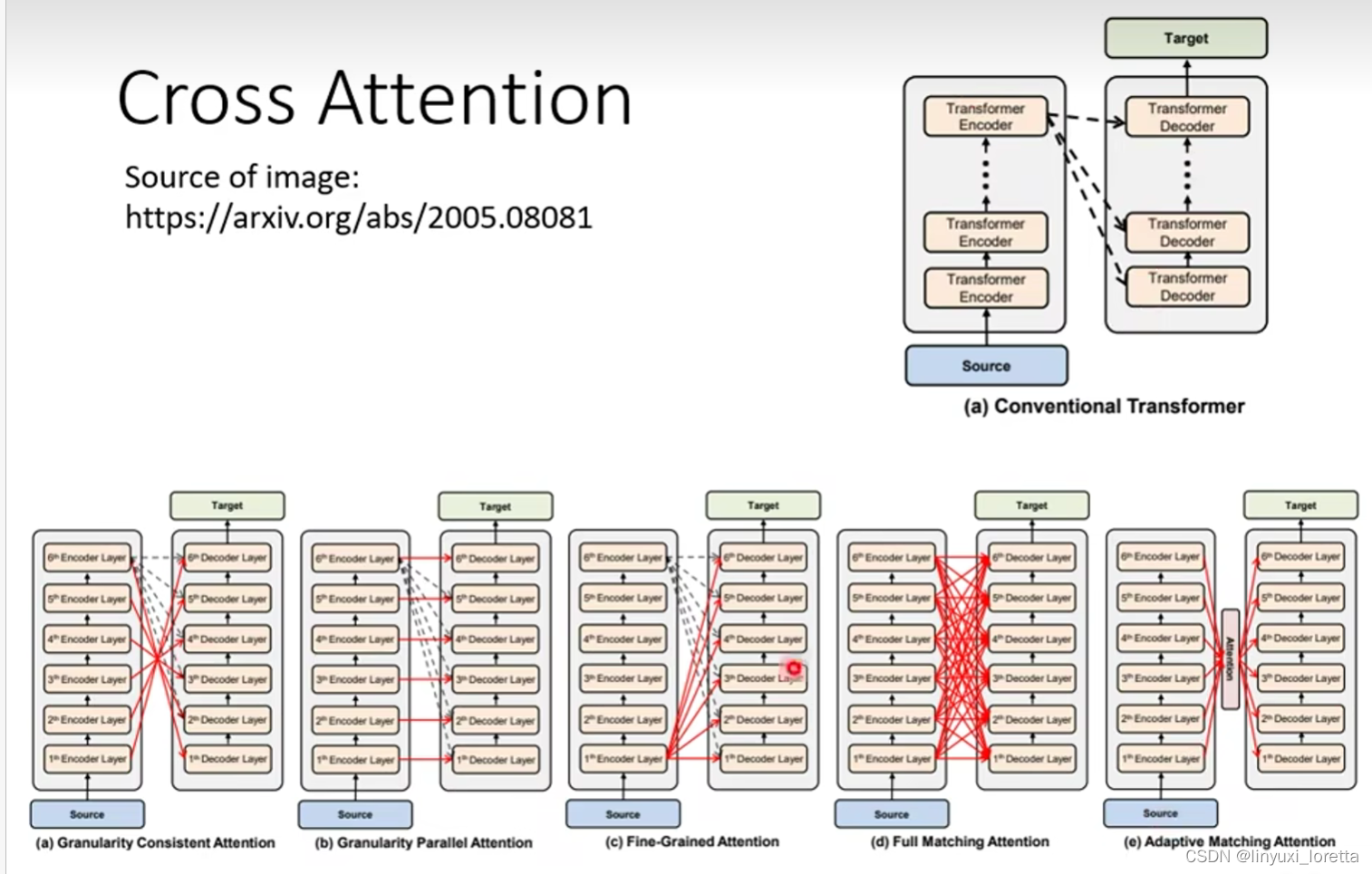
?Ҳ�����˻�������:����� Encoder �кܶ�㰡,Decoder Ҳ�кܶ�㰡,�ӸղŵĽ����e�����������,��� Decoder ������һ��,������ Encoder �����һ��������������?
��,��ԭʼ Paper �e���ʵ����������,��һ��Ҫ������
��һ��Ҫ����,����Զ�����Լ���һЩ�µ��뷨,��������߾�������һƪ���ĸ�����˵,Ҳ���˳��Բ�ͬ�� Cross Attension �ķ�ʽ
Encoder ����кܶ��,Decoder ����кܶ��,��ʲ�N Decoder ���ÿһ�㶼һ��Ҫ��,Encoder �����һ�������,�ܲ��ܹ��и�ʽ������ͬ�����ӷ�ʽ,����ȫ���Ե���һ���о��������� Study
Training
�ղ��Ѿ�˵���������ģ��ѵ�����Ժ��������N������,?Input һ�� Sequence,�����N�õ����յ����,�ǽ����������N��ѵ����?(,Inference ���� Testing ,)
?��������Ҫ�����N��ѵ��,���������������ʶ,����Ҫ��ѵ������,��Ҫ�ռ�һ��ѵ�����Ѷ��,ÿһ������Ѷ�Ŷ�Ҫ�й�����������һ��,���˵���������Ӧ�Ĵʻ���ʲ�N

����������ֻᱻ��ʾ��һ�� One-Hot �� Vector,������ȷ��,�����ǵ� Decoder,���������һ�� Distribution,��һ�����ʵķֲ�,���ǻ�ϣ����һ�����ʵķֲ�,����� One-Hot �� Vector Խ�ӽ�Խ��,����Cross Entropy
�������������, �������� ÿһ�� Decoder �ڮa��һ�������ֵ�ʱ��,��ʵ��������һ�η��������,�����ּ�������ǧ��,�Ǿ���������ǧ�����ķ��������
������������Ĵη��������,,���� END ������� ,?����ϣ����Щ���������,���ܺ������� Cross Entropy ԽСԽ��
(���ǽ�����,�������������ļнǵ�����ֵ(��άʱ),�����ڻ�����ģ��)

ע��:�� Decoder ѵ����ʱ��, ���ǻ����ȷ�Ĵ�ground truth ����Decoder ������,���?Teacher Forcing
�����ʱ�������Ͼͻ���һ��������
- ѵ����ʱ��,Decoder ��͵������ȷ����
- ���Dz��Ե�ʱ��,��Ȼû����ȷ�𰸿��Ը� Decoder ��
�ղ�Ҳ��ǿ��˵������ʹ�����ģ��,�� Inference ��ʱ��,Decoder ���������Լ�������,���м���Ȼ��һ�� Mismatch,�ǵ�һ�����ǻ���һҳͶӰƬ��˵��,��ʲ�N�����ܵĽ����ʽ
Tips
ѵ������ Sequence To Sequence Model ��Tips
Copy Mechanism
�����Ǹղŵ������e��,���Ƕ�Ҫ�� Decoder �Լ��a�����,���ǶԺܶ��������,Ҳ�� Decoder û�б�Ҫ�Լ������������,����Ҫ��������,Ҳ����������Ķ����e�渴�uһЩ��������
�����ָ��u���О�����Щ������õ�����,һ�������������������

?�Ի�����˵,����ʵû�б�Ҫ��������������ʻ�,��Ի�����˵һ������һ���dz�����Ĵʻ�,���������ܺ���,��ѵ�������e�����һ��Ҳû�г��ֹ�,��������̫������ȷ�خa����δʻ����
���Ǽ�������������ѧ��ʱ��,��ѧ�����ǿ��������ʱ��˵����ijijij,��ֱ�Ӱ�ijijij,���������ʲ�N���u����˵ijijij���
�������ӻ�����ѵ����Ȼ��Ƚ�����,����Ȼ�Ƚ��п��ܵõ���ȷ�Ľ��,���Ը��u��춶Ի���˵,������һ����Ҫ�ļ��� ��Ҫ������
����������ժҪ��ʱ��,����ܸ���Ҫ Copy �����ļ���
https://arxiv.org/abs/1704.04368
ժҪ����,��Ҫѵ��һ��ģ��,Ȼ�����ģ��ȥ��һƪ����,Ȼ��a����ƪ���µ�ժҪ
�����������ȫ���а취����,������ռ�����������,��ÿһƪ���¶�����д��ժҪ,Ȼ�����ѵ��һ��,Sequence-To-Sequence �� Model,�ͽ�����
��Ҫ������������,ֻ��һ��������������������,�е�ͬѧ�ռ�������ƪ����,Ȼ��ѵ��һ��������,Sequence-To-Sequence Model,���ֽ���е��
��Ҫѵ������,��Ҫ�л���˵�����ľ���,ͨ���������ƪ��������Ҫ��,����������а���ƪ����,��Щ���¶����˱��ժҪ,????????����ʱ�����ֱ�Ӱ����±����ժҪ,�������Ͳ���Ҫ��̫����������,���ǿ���ѵ��һ��,ֱ�ӿ������һƪ����,����ժҪ��ģ��
����֪��,��ժҪ��ʱ��,�ܶ�Ĵʻ���ʵ����ֱ�Ӵ�ԭ���������︴�Ƴ�����,
��ժҪ����������,��ʵ�������e��ֱ�Ӹ��uһЩ��Ѷ����,������һ���ܹؼ�������,�� Seq2Seq Model,�а취��������� ,�����ǾͲ���ϸ��
�����д����븴�u������������ģ��,���� Pointer Network,? �������ȥ�Ͽ����н�����,�Ұ�¼Ӱ������߸���Ҳο�,
�� �Ǻ�������һ������,���� Copy Network,������Կ�һ����һƪ,

,�㿴 Sequence-To-Sequence Model,�����N���������븴�u�������������
Guided Attention
��������һ���ں���,��ʱ�����e��ѧ��ʲ�N����,��ʵ���Ǹ㲻���,����ʱ�����᷸�dz��ͼ��Ĵ���
��߾ٵ������������ϳ�,? ���������ϳ�? ����ȫ���Ծ���ѵ��һ��,Sequence-To-Sequence �� Model,Transformer ����һ������
- �ռ��ܶ������,���ָ�����Ѷ�ŵĶ�Ӧ�S
- Ȼ��������������,Sequence-To-Sequence Model ,����������ĵľ���,�������������
- Ȼ���û��Ȼ��,��Ӳ Train һ���ͽ�����,Ȼ������Ϳ���ѧ���������ϳ���
�������ķ������������,��ʵ������,
������˵�ҽл�����˵ 4 �η���,�����������N��,��������Ľ����:���� ���� ���� ����
�ͷ��ֺ�����,������ķ�����������ͬ���Ĵʻ�,ֻ���ظ� 4 ��,������Ȼ�Լ���һЩ����ٴ�,�����Nѧ�������,��֪��,���Լ�ѵ�����������������
����,������ 1 ���,���������
��֪����ʲ�N������,��������� Sequence-To-Sequence Model,��ʱ�� Train ��������,��a��Ī������Ľ��,Ҳ����ѵ�������e��,���ַdz��̵ľ��Ӻ���,���Ի�����֪��Ҫ���N�������ַdz��̵ľ���? ? ,������� 4 �εķ���,�ظ� 4 ��û����,����ֻ��һ��,,���ѷ�ʡ�Ե�ֻ���, ��Ȼ��������,�������N�����
��Ȼ��ʵ������Ӳ�û�����N������,�� Sequence-To-Sequence,Learn ���� TTS,Ҳû������������N��,���Ҫ�����ֲ������Ҳ��ͦ��ʱ���,Ҫ���ܶ�ʱ����ҵõ����ֲ������,�������ӵ������Ǵ��ڵ�

?�������N����
���Ǹղŷ���˵������Ȼ©����,������һЩ��������Ȼû�п���,�����ܲ�����ǿ����,һ��Ҫ�������ÿһ������ͨͨ������
������п��ܵ�,���оͽ��� Guided Attention
��������ʶ�������ϳ� ��������,����ʵ���ѽ���˵,�㽲һ�仰,�����ʶ����,��Ȼ��һ�λ���û����,�������ϳ�������һ������,�����ϳ�����Ȼ��һ��û���,����˺��ѽ���
�����������Ӧ��,����˵ Chat Bot,������ Summary,���ܾ�û�����N�ϸ�,����һ�� Chat Bot ��˵,�����һ�仰,���ͻ�һ�仰,��������û�а����仰����,��ʵ�� Somehow Ҳ���ں�,����ʵҲ�㲻���
������������ʶ �����ϳ�,Guiding Attention,���ܾ���һ���Ƚ���Ҫ�ļ���
Guiding Attention Ҫ�����������,Ҫ����������� Attention ��ʱ��,���й̶��ķ�ʽ��(guide)
,������˵,�������ϳɻ�����������ʶ��˵,���������е� Attention,Ӧ�þ�����������
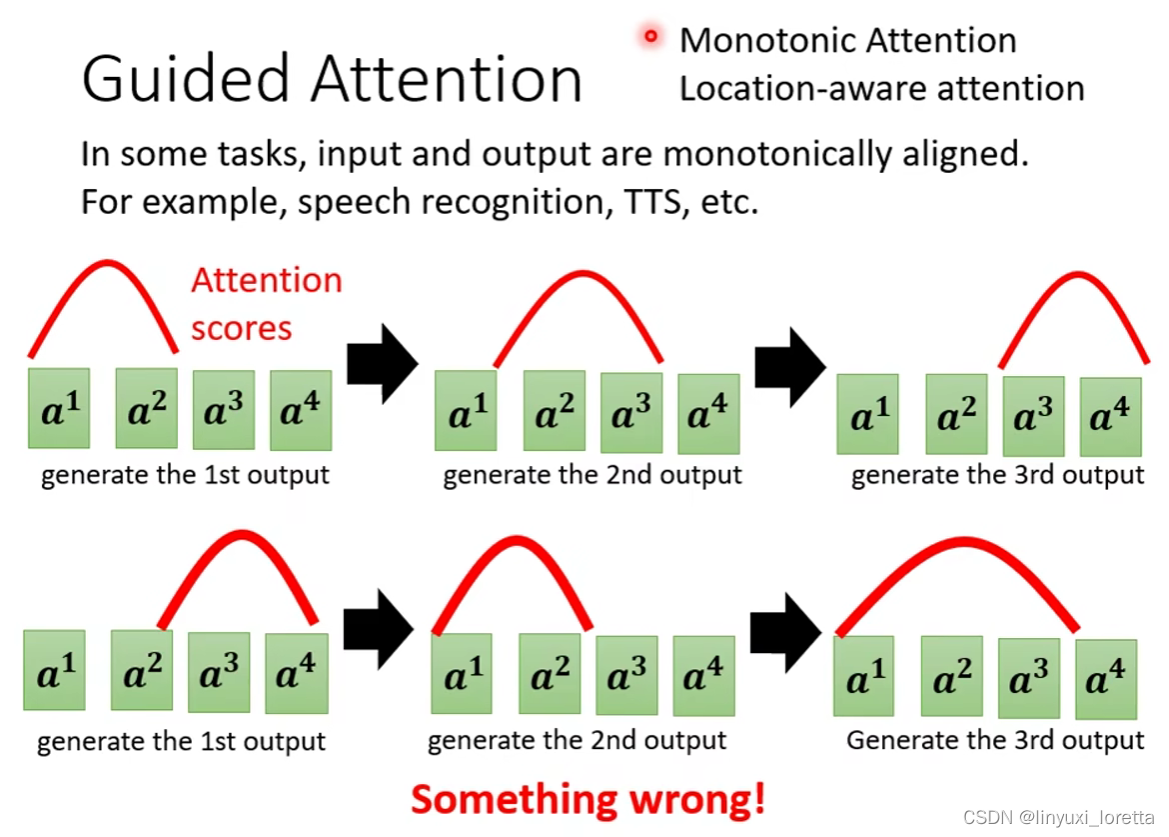
����������e��,�����ú�ɫ������,������ Attention �ķ���,? Խ�߾ʹ��� Attention ��ֵԽ��
�����������ϳɞ���,������������һ������,�����ںϳ�������ʱ��,��Ȼ���������,���Ի���Ӧ����,�ȿ����������Ĵʻ�a������,�ٿ��м�Ĵʻ�a������,�ٿ��ұߵĴʻ�a������
�����������������ϳɵ�ʱ��,�㷢�ֻ����� Attention,���������ĵ�,���ȿ������,�������ٿ�ǰ��,���ٺ��ҿ���������,����Ȼ,Something is wrong,��Щ��������,����Ȼ������Attention���������,���������������ϳɵ�ʱ��,��Ȼû���ϳ��õĽ��,
���� Guiding Attention Ҫ�����������,ǿ�� Attention ��һ���̶�����ò,���������������,�������Ѿ�������֪��˵,�����ϳ� TTS ����������,��� Attention �ķ���,Attention ��λ�ö�Ӧ����������,�Dz����ֱ�Ӱ��������,�Ž���� Training �e��,Ҫ�����ѧ�� Attention,��Ӧ��Ҫ��������
����������N����,��һЩ�ؼ��ʻ��Ҿͷ������,�ô���Լ� Google ��,����˵ijij Mnotonic Attention,�� Location-Aware Attention,���������Ҳ�Ǵ��,Ҳ��ϸ��,�Ǿ���������Լ��о�
Beam Search
Beam Search ,������߾�һ������,����������e�����Ǽ���˵,�������ڵ���� Decoder��ֻ�ܮa��������,һ������ A һ������ B������ ������ֻ���������ܵ����,
�Ƕ� Decoder ����,�������������,ÿһ���ڵ�һ�� Time Step,���� A B �e�����һ��,Ȼ������� A �Ժ�,�ٰ� A ��������,Ȼ���پ��� A B Ҫѡ��һ��

?������Ǹ������˲����������һ��, �ȶ����Լ�һ��,�������������Ӯ��
��������,�������Ҫ���N�ҵ�,�����õ���ɫ��һ��·��,Ҳ��һ��������,�������п��ܵ�·��,������������ʵ����,��û�а취�������п��ܵ�·��,���ʵ����ÿһ��ת�����Ե�ѡ��̫����,������ڶ����Ķ���,���������� 4000 ����,���������ÿһ���ط��ֲ�,���� 4000 �����ܵ�·��,�����������Ժ�,��������
�������N����,��һ�����㷨���� Beam Search,���ñȽ���Ч�ķ���,��һ�� Approximate,��һ������� Solution,��һ�����Ǻܾ��ʵ�,������ȫ���ʵ� Solution,����������� Beam Search,�����Ҳ��������Լ� Google,
����� Beam Search �������,������û������,��Ȥ���¾���,����ʱ������,��ʱ��û����,��ῴ����Щ��������˵,Beam Search ��һ�����õĶ���

������˵��ƪ Paper ����,The Curious Case Of Neural Text Degeneration,���������Ҫ����������,Sentence Completion,Ҳ���ǻ����ȶ�һ�ξ���,��������Ҫ��������ӵĺ���,�������,�����һ������,������һ�����µ�ǰ�벿,�� ���Լ�����������������,���������,�ѹ��µĺ�벿����д��
����ᷢ��˵,Beam Search ����ƪ�����e��,һ��ͷ������˵,Beam Search ������:������� Beam Search ,�ᷢ��˵�������Ͻ��ظ��Ļ�,�����Ͽ�ʼ�������ǽ ����ޒȦ,����˵�ظ��Ļ�
�������첻���� Beam Search,�м�һЩ�����,��Ȼ�����һ����ȫ��,���ǿ����������DZȽ������ľ���,������Ȥ��������,��ʱ��� Decorder ��˵,û���ҳ�������ߵ�·,��������DZȽϺõ�
���ʱ�����־������ҵ� �Բ���,���Ǹղ�ǰһҳͶӰƬ��˵,Ҫ�ҳ�������ߵ�·,������Ҫ��˵�ҳ�������ߵ�·�����ñȽϺ�,���������N������
����ʵ�������Ҫ,���������ı���������
-
�ͼ���һ������,�����𰸷dz�����ȷ
e.g. ,����˵������ʶ,˵һ�仰��ʶ�Ľ����ֻ��һ������,����һ�����־�����Ψһ���ܵ���ȷ��,��û��ʲ�Nģ���ĵش�
�������������,ͨ�� Beam Search �ͻ�Ƚ��а���,
-
����Ҫ��������һ�㴴������ʱ��,��ʱ�� Beam Search �ͱȽ�û�а���,
������˵����ߵ� Sentence Completion,����һ������,������µ�ǰ�벿,��벿���������ܵķ�չ��ʽ,��������Ҫ��һЩ��������,����ֻ��һ���𰸵�����,������Ƚ���Ҫ�� Decoder �e��,���������? ? ? ?,��������һ�� Decoder,Ҳ�dz���Ҫ����Ե�����,���������ϳ�,(��д:TTS )
machine learning��ʱ����ѵ����ʱ����noise,����˵ѵ��ʱ���dropout,ѵ��ʱ��һЩ��Ѷ,�û����������������,ѵ��ʱ��Ƚ�ǿ��.....TTS�������,?����ʱҪ��һЩ��Ѷ,(����ʶ)��������decode����, �ϳ����������������ǹ,Ҫ�����ȽϺõ�������Ȼ����ҪһЩ����Ե�,
��Ҳ���ͺ�Ӧ��һ��Ӣ�ĵ�����,����Ҫ����û��������������,����������Ҳ�����ڲ�����֮��,��� TTS �� Sentence Completion ��˵,Decoder �ҳ���õĽ��,�����������������õĽ��,��������ֵĽ��,�������һЩ�����,����������DZȽϺõ�
(Ҳ������Ϊ��˵��ͬ�����仰Ҳ�Dz����˲�ͬ������, ��Ϊ��"����")
Optimizing Evaluation Metrics?
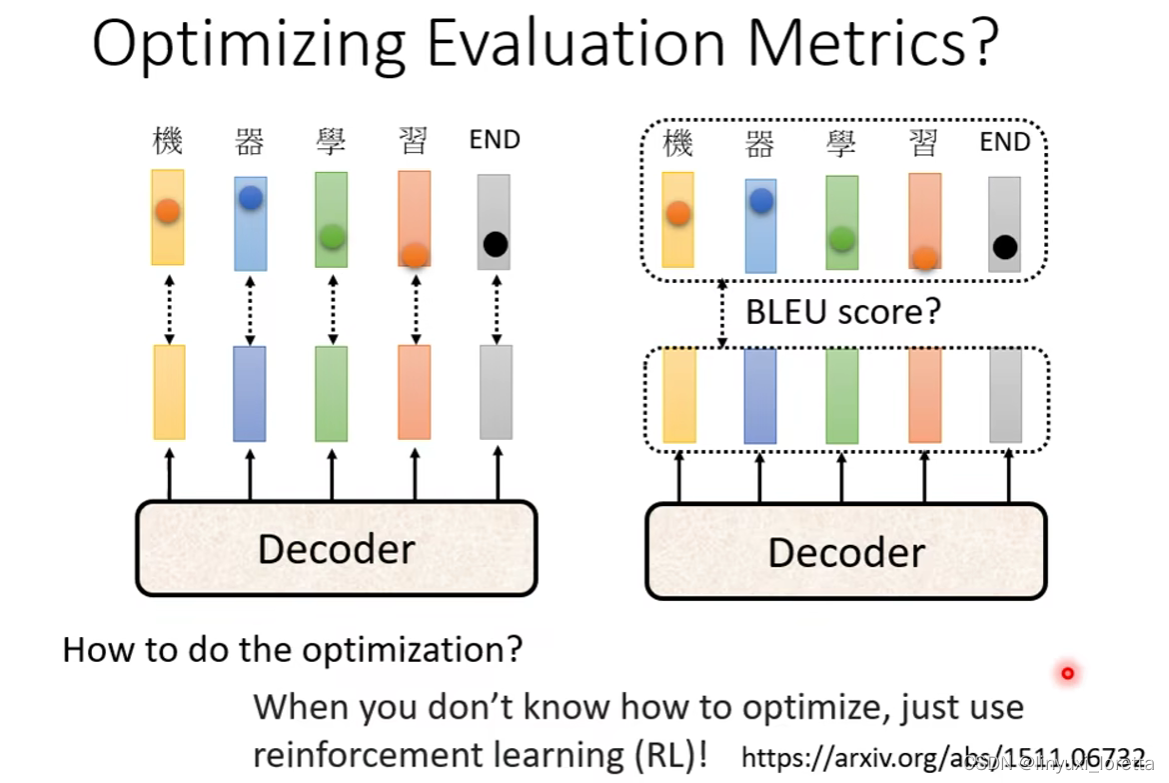
����ҵ�e��,���������ı���õ���,BLEU Score,:��� Decoder,�Ȯa��һ�������ľ����Ժ�,��ȥ����ȷ�Ĵ�һ�������Ƚ�,����������������֮�����Ƚ�,����� BLEU Score
��������ѵ����ʱ����Ȼ��������,ѵ����ʱ��,ÿһ���ʻ��Ƿֿ����ǵ�,ѵ����ʱ��,���� Minimize ���� Cross Entropy,Minimize Cross Entropy,��Ŀ��� Maximize BLEU Score ��
��һ��,�����������������,���ǿ�����һ���Ĺ���,��������û�����Nֱ�����,���Ǹ�������������ͬ����ֵ,
�����㷢��˵�����̵ij�ʽ�e��,�������� Validation ��ʱ��,�������� Cross Entropy ������õ� Model,������ BLEU Score ��ߵ���һ�� Model,��������ѵ����ʱ��,�ǿ� Cross Entropy,��������ʵ��������ҵ����������ʱ��,������ BLEU Score,������ Validation Set,��ʵӦ�ÿ����� BLEU Score
�ǽ��������˾ͻ���˵,�������ܲ����� Training ��ʱ��,�Ϳ��� BLEU Score ��,�����ܲ��ܹ�ѵ����ʱ���˵,�ҵ� Loss ����,BLEU Score ��һ������,
���������ʵ����û�����N����,�㵱Ȼ���� BLEU Score,������ѵ����ʱ��,��Ҫ���һ��Ŀ��,���� BLEU Score �����ܸ���,���Dz����ֵ�,
���֮���Ԓ��� Cross Entropy,������ÿһ�����ĵ��ַֿ�����,��������������Dz��а취����,�������Ҫ����,��������֮��� BLEU Score,��һ�� Loss,������û�а취����,�����N����
��߾ͽ̴��һ���ھ�,�������� Optimization �����������,�� RL Ӳ Train һ���Ͷ�������,�������� Optimize �� Loss Function,���������� RL �� Reward,����� Decoder ������ Agent,�������� RL,Reinforcement Learning ������Ӳ��,��ʵҲ���п��ܿ�������,
������������Թ�,�Ұ� Reference ������߸���Ҳο�,��Ȼ����һ���Ƚ��ѵ�����,�Dz�û���ر��Ƽ�������ҵ�e������һ��
Scheduled Sampling
������Ҫ����,���Ǹղŷ����ᵽ��������,����ѵ�������Ծ�Ȼ�Dz�һ����
���Ե�ʱ��,Decoder ���������Լ������,���Բ��Ե�ʱ��,Decoder �ῴ��һЩ����Ķ���,������ѵ����ʱ��,Decoder ����������ȫ��ȷ��,�������һ�µ��������,Exposure Bias
���� Decoder ��ѵ����ʱ��,��Զֻ������ȷ�Ķ���,���ڲ��Ե�ʱ��,��ֻҪ��һ����,�Ǿͻ�һ���� ������,���� Decoder ��˵,������û�п������Ķ���,���������Ķ�����dz��ľ���,Ȼ����������a���Ľ�����ܶ������
����Ҫ���N������������
��һ�����Ե�˼���ķ�����,�� Decoder �������һЩ����Ķ���,�����Nֱ��,�㲻Ҫ�� Decoder ������ȷ�Ĵ�,ż������һЩ���Ķ���,��������ѧ�ø���,��һ�н���,Scheduled Sampling,�������Ǹ� Schedule Learning Rate,�ղ������н� Schedule Learning Rate,���Dz���ɵ�����,����� Scheduled Sampling
Scheduled Sampling ��ʵ���������,����� 15 ��� Paper,? �ڻ�û�� Transformer,ֻ�� LSTM ��ʱ��,���Ѿ��� Scheduled Sampling,���� Scheduled Sampling ��һ��,����ʵ���˺���,Transformer ��ƽ�л�������,��ϸ�ڿ������Լ�ȥ�˽�һ��,���Զ� Transformer ��˵,���� Scheduled Sampling,������������ͳ������,��ԭ����������,��� LSTM�ϱ������������,Ҳ��̫һ��,���Ұ�һЩ Reference ��,������߸���Ҳο�
 �� ���������Ǿͽ�����,Transformer �����ֵ�ѵ������,��������Ѿ������� Encoder,������ Decoder,Ҳ�����������м�ĹS,Ҳ�������Nѵ��,Ҳ�������ֵ� Tip
�� ���������Ǿͽ�����,Transformer �����ֵ�ѵ������,��������Ѿ������� Encoder,������ Decoder,Ҳ�����������м�ĹS,Ҳ�������Nѵ��,Ҳ�������ֵ� Tip