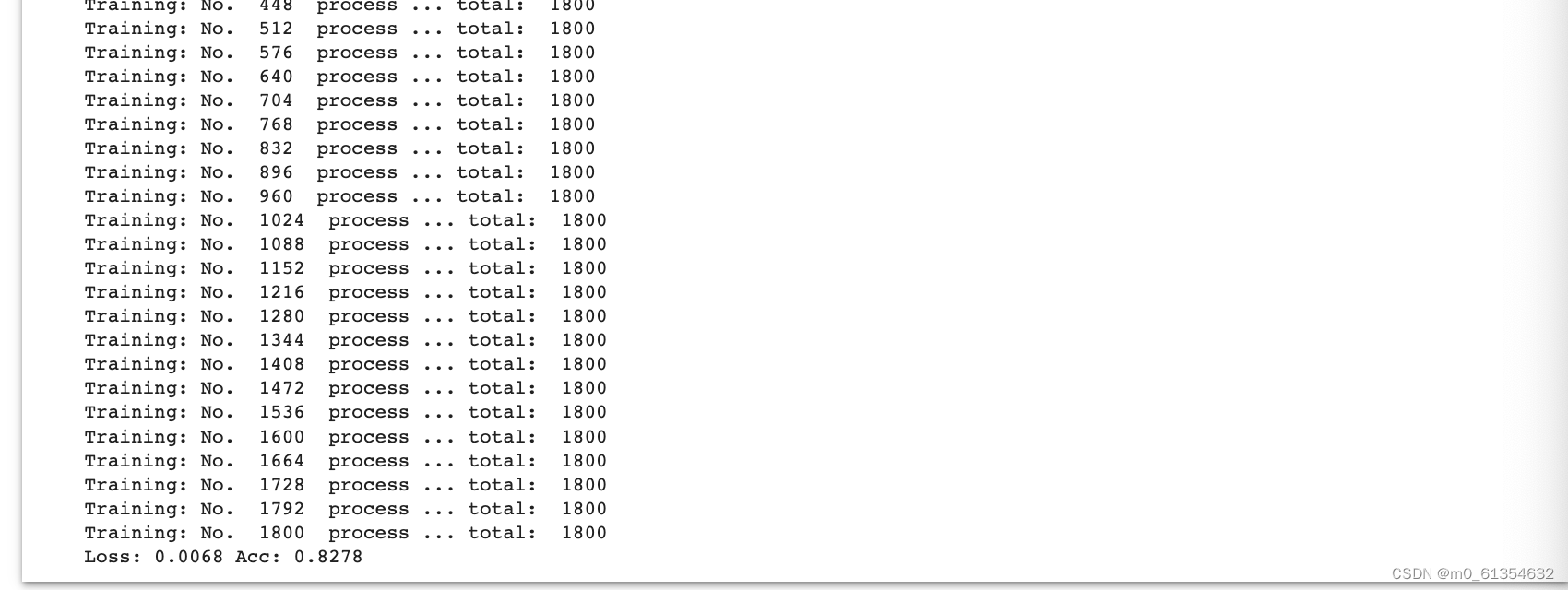
ЪЙгУVGGФЃаЭНјааУЈЙЗДѓеН(ЛљгкColab)
ЕМШывЊЪЙгУЕФЯрЙиАќ,ХаЖЯЪЧЗёДцдкGPUЩшБИ:
ЯТдиЯрЙиУЈКЭЙЗЕФЪ§Он,бЕСЗМЏАќКЌ1800еХЭМ(УЈЕФЭМЦЌ900еХ,ЙЗЕФЭМЦЌ900еХ),ВтЪдМЏАќКЌ2000еХЭМ:
ЪЙгУ torchvision ЖдЪ§ОнНјааИДдгЕФдЄДІРэКЭБфЛЛ,ећРэЭМЦЌГЩ 224ЁС224ЁС3 ЕФДѓаЁ,ВЂНјааЙщвЛЛЏДІРэЁЃЪЙгУЪ§ОнДІРэЕФАќdatasets,ЫќПЩвдвдЖрЯпГЬ(multi-thread)ЕФаЮЪНДггВХЬжаЖСШЁЪ§Он,ЪЙгУ mini-batch ЕФаЮЪН,дкЭјТчбЕСЗжаЯђ GPU ЪфЫЭЁЃ
ВщПД dsets ЕФвЛаЉЪєад,0ДњБэУЈ,1ДњБэЙЗ,бЕСЗМЏКЭВтЪдМЏЕФЭМЦЌЪ§СПвВПЩЕУЕН:

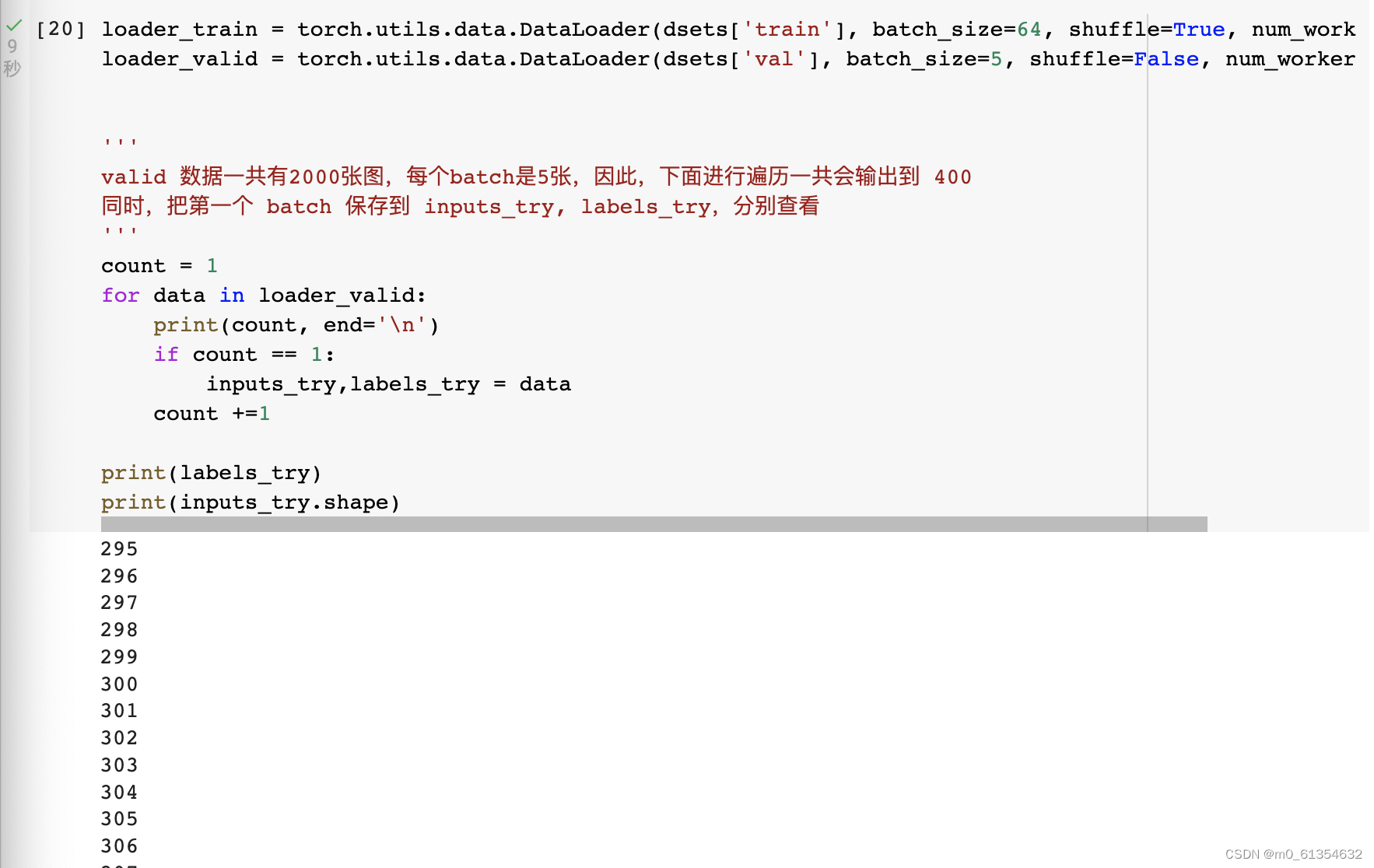
ЪЙгУtorch.utils.data.DataLoader ЖдЪ§ОнНјаа batch ЕФЛЎЗжЁЃЪ§ОнМгдиЦїНсКЯСЫЪ§ОнМЏКЭШЁбљЦї,ВЂЧвПЩвдЬсЙЉЖрИіЯпГЬДІРэЪ§ОнМЏЁЃдкбЕСЗФЃаЭЪБЪЙгУЕНДЫКЏЪ§,гУРДАббЕСЗЪ§ОнЗжГЩЖрИіаЁзщ ,ДЫКЏЪ§УПДЮХзГівЛзщЪ§Он ЁЃжБжСАбЫљгаЕФЪ§ОнЖМХзГіЁЃОЭЪЧзівЛИіЪ§ОнЕФГѕЪМЛЏЁЃ

ЯдЪОЭМЦЌЕФаЁГЬађ:

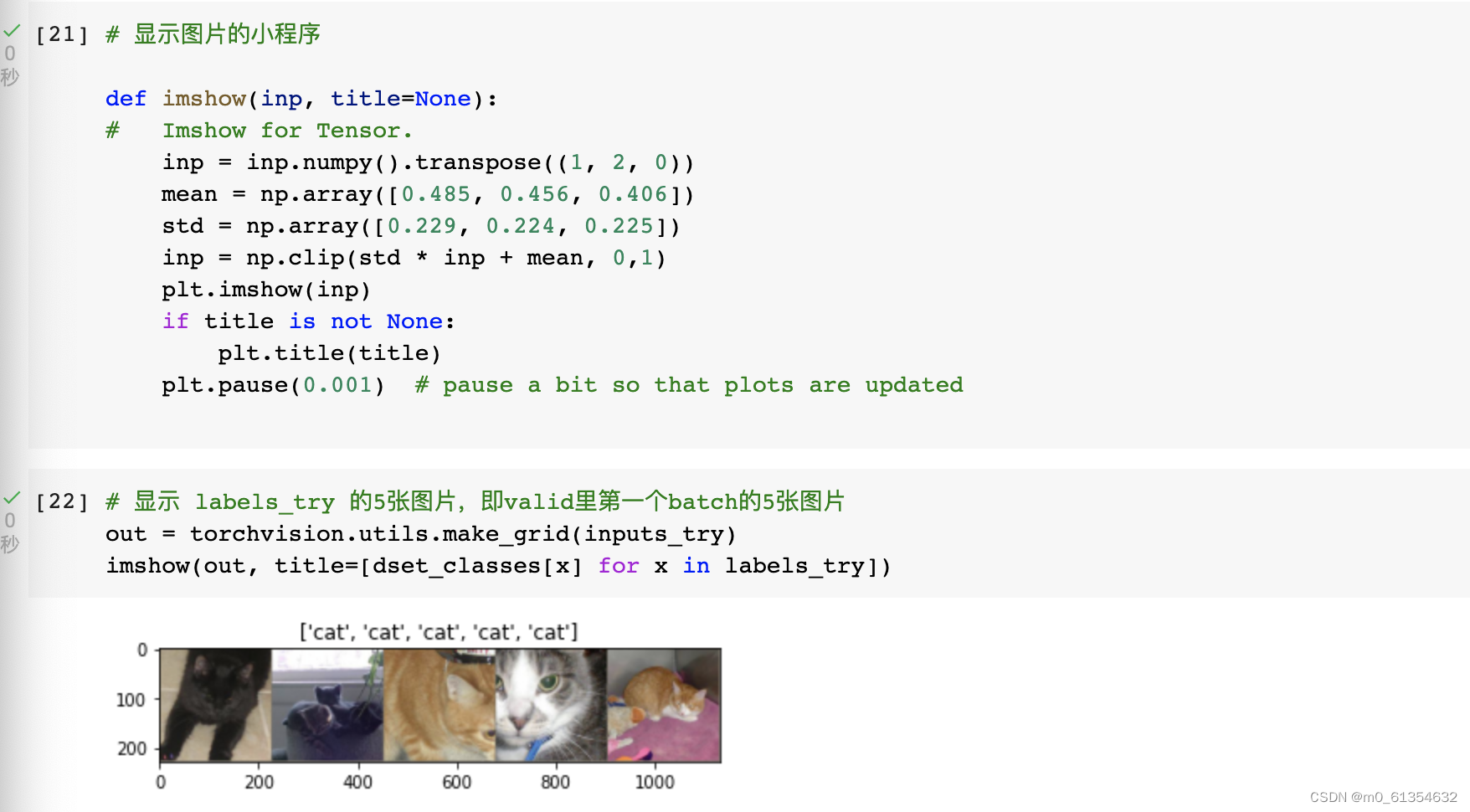
ЯдЪО labels_try ЕФ5еХЭМЦЌ,МДvalidРяЕквЛИіbatchЕФ5еХЭМЦЌ:

ДДНЈVGG Model
torchvision жаМЏГЩСЫКмЖрдк ImageNet ЩЯдЄбЕСЗКУЕФЭЈгУЕФCNNФЃаЭ,ПЩвджБНгЪЙгУдЄбЕСЗКУЕФVGGФЃаЭ,дйЯТдиImageNet 1000 ИіРрЕФ JSON ЮФМў,ФПЕФЪЧеЙЪО VGG ФЃаЭЖдБОЪ§ОнЕФдЄВтНсЙћ: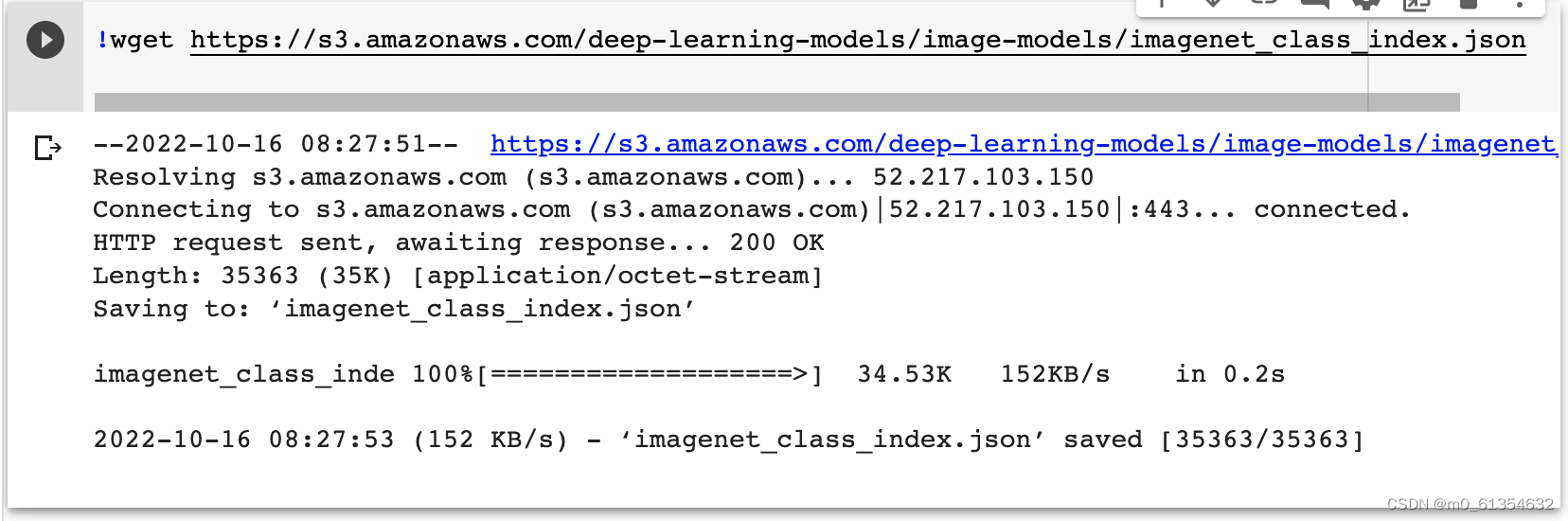
ЖдЪфШыЕФ5ИіЭМЦЌРћгУVGGФЃаЭНјаадЄВт,ЭЌЪБ,ЪЙгУsoftmaxЖдНсЙћНјааДІРэ,ЗЂЯжЪЖБ№НсЙћЪЧБШНЯзМШЗЕФЁЃ
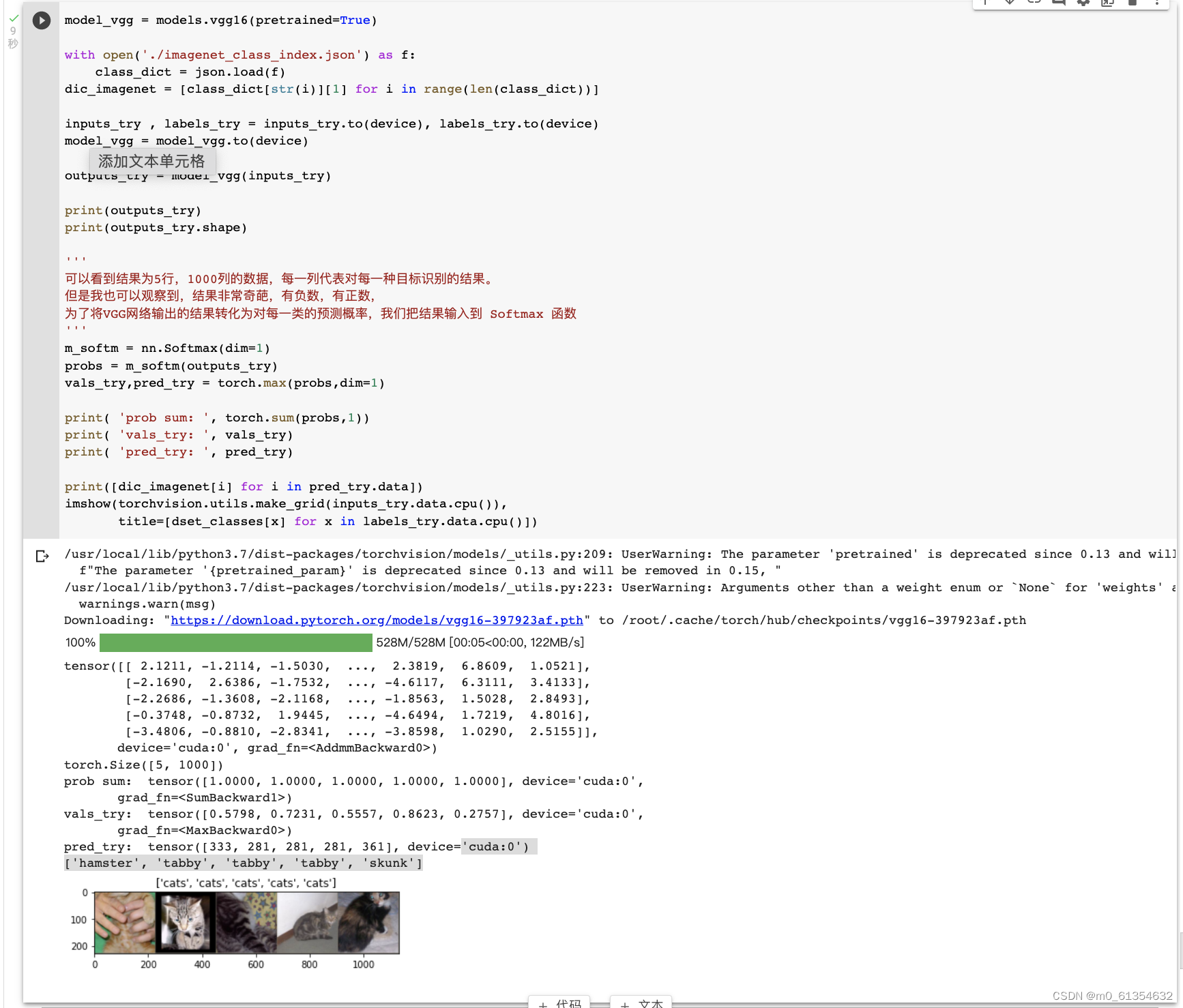
аоИФзюКѓвЛВу,ЖГНсЧАУцВуЕФВЮЪ§,АбзюКѓЕФ nn.Linear ВугЩ1000Рр,ЬцЛЛЮЊ2РрЁЃЮЊСЫдкбЕСЗжаЖГНсЧАУцВуЕФВЮЪ§,ашвЊЩшжУ required_grad=FalseЁЃетбљ,ЗДЯђДЋВЅбЕСЗЬнЖШЪБ,ЧАУцВуЕФШЈжиОЭВЛЛсздЖЏИќаТСЫЁЃбЕСЗжа,жЛЛсИќаТзюКѓвЛВуЕФВЮЪ§ЁЃ
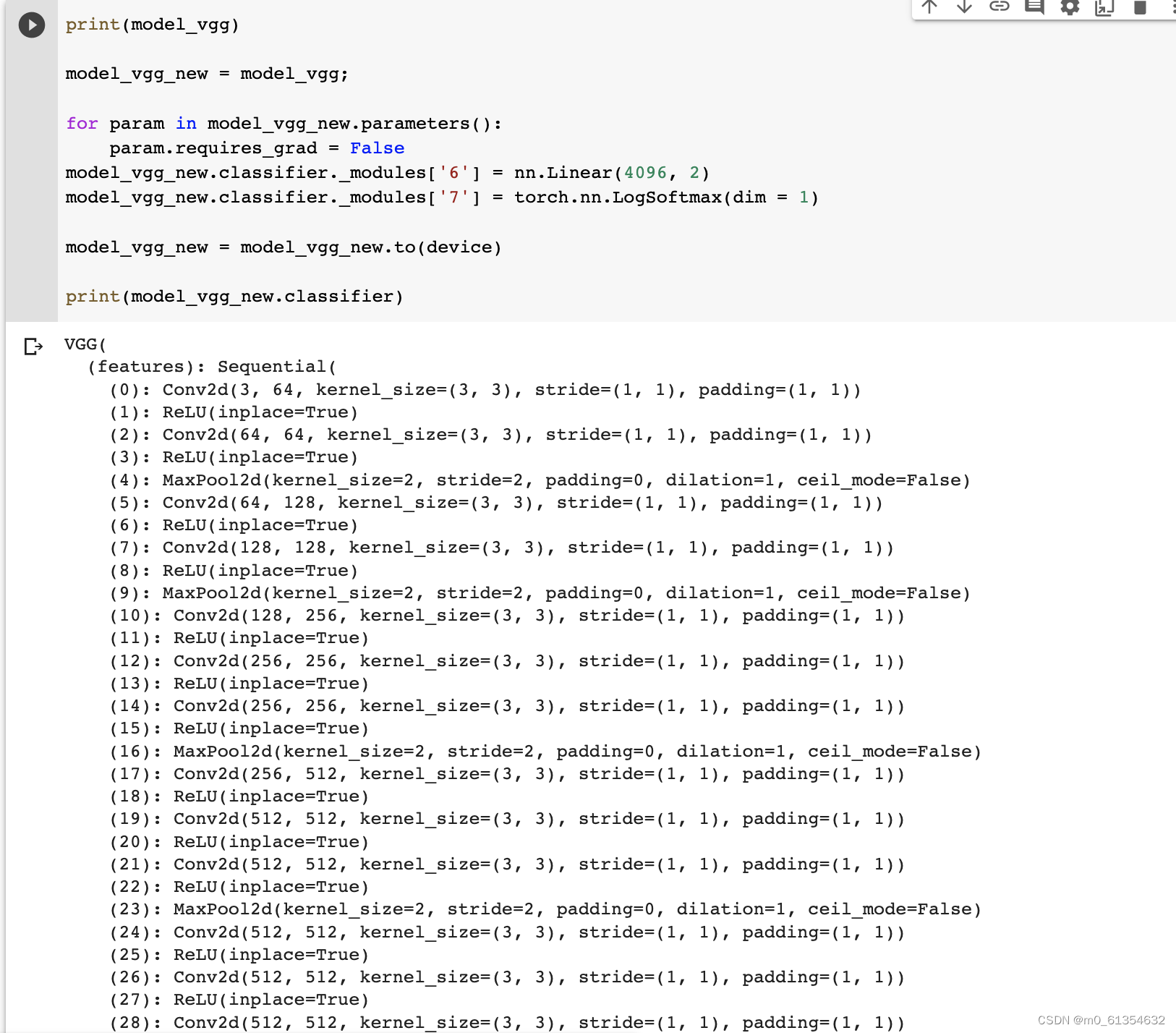

бЕСЗВЂВтЪдШЋСЌНгВу
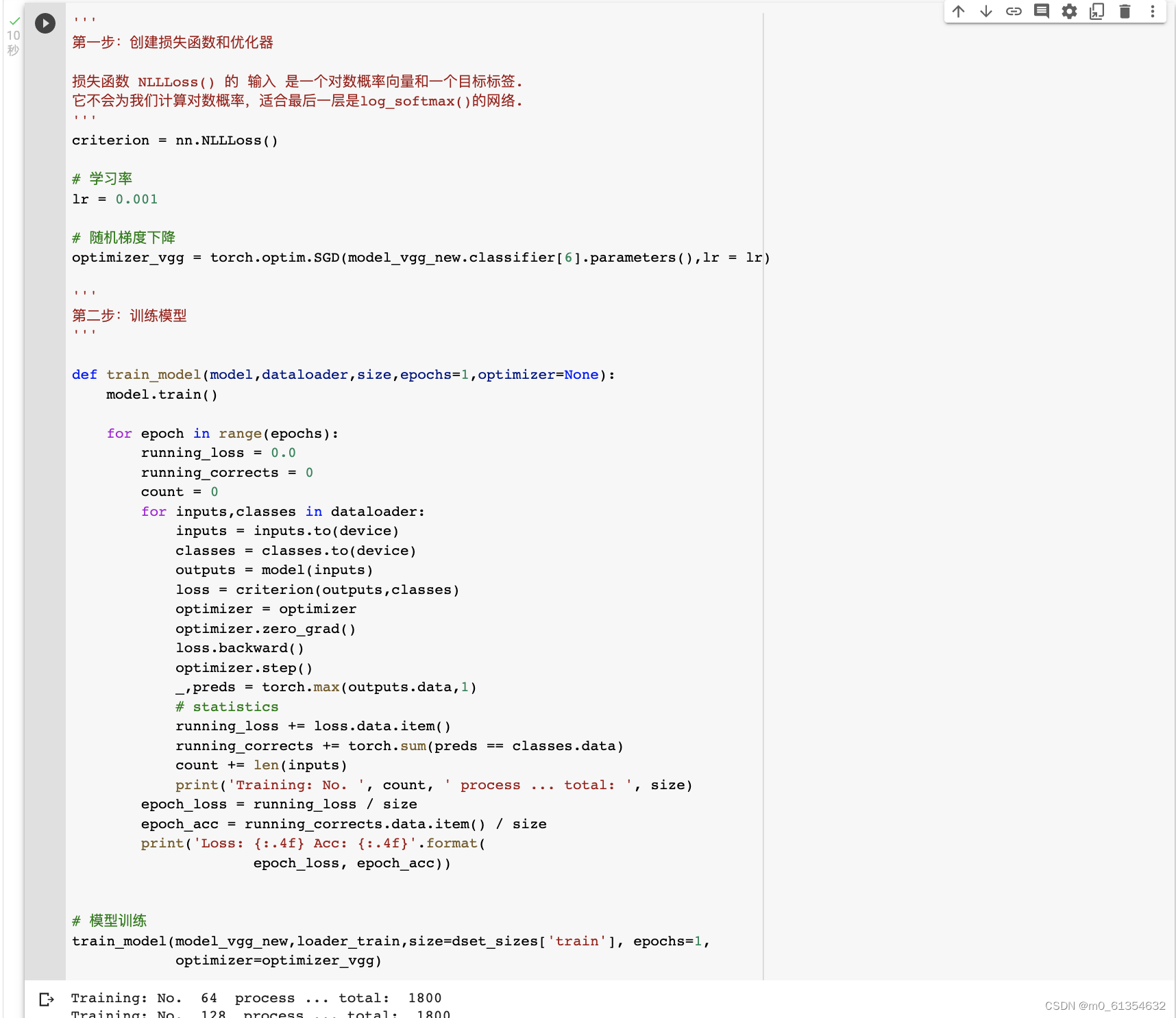
ДДНЈЫ№ЪЇКЏЪ§КЭгХЛЏЦїЁЂбЕСЗФЃаЭЁЂВтЪдФЃаЭЁЃ
ВтЪдФЃаЭ:
ВщПДПЩЪгЛЏФЃаЭдЄВтНсЙћ:
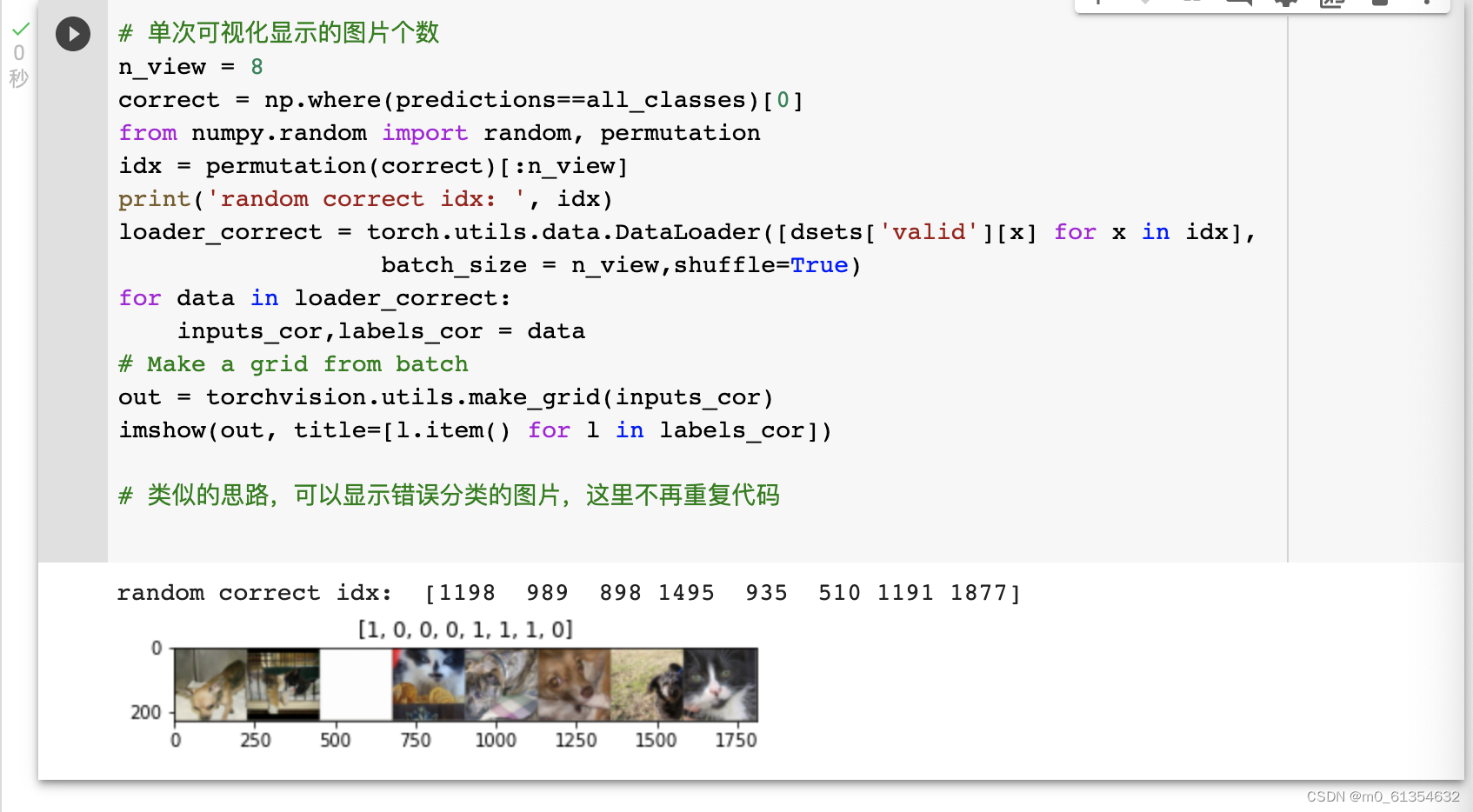
ЗНЪНПЩЗжЮЊвдЯТМИжж:ЫцЛњВщПДвЛаЉдЄВте§ШЗЕФЭМЦЌ;ЫцЛњВщПДвЛаЉдЄВтДэЮѓЕФЭМЦЌ;дЄВте§ШЗ,ЭЌЪБОпгаНЯДѓЕФprobabilityЕФЭМЦЌ;дЄВтДэЮѓ,ЭЌЪБОпгаНЯДѓЕФprobabilityЕФЭМЦЌ;зюВЛШЗЖЈЕФЭМЦЌ,БШШчЫЕдЄВтИХТЪНгНќ0.5ЕФЭМЦЌЕШ,ЯТУцЫцЛњЪфГівЛаЉдЄВте§ШЗЕФМИР§:
дкAIбаЯАЩчЭјеОЯТдиЪ§ОнНјааУЈЙЗДѓеН:
ЕМШыЯрЙиАќ,ЯТдиВЂНтбЙУЈЙЗЮФМў:
зЂвтетРяЯТдиЕФЮФМўЪЧrarЮФМў,ВЛЭЌгкЩЯУцЪЕбщЕФzipЮФМў,ЪЙгУunrarУќСюНјааНтбЙЁЃ
ЯТдиГЩКѓЮвУЧЗЂЯжЭМЦЌЮФМўЪЧдгТвЕФ,ЮвУЧашвЊНЋбЕСЗМЏКЭВтЪдМЏНјааУЈЙЗЗжРр:
ЗжРрКѓЕФЮФМўФПТМШчЯТ:


НјааЪ§ОндЄДІРэ:

ВЂДДНЈVGGФЃаЭ

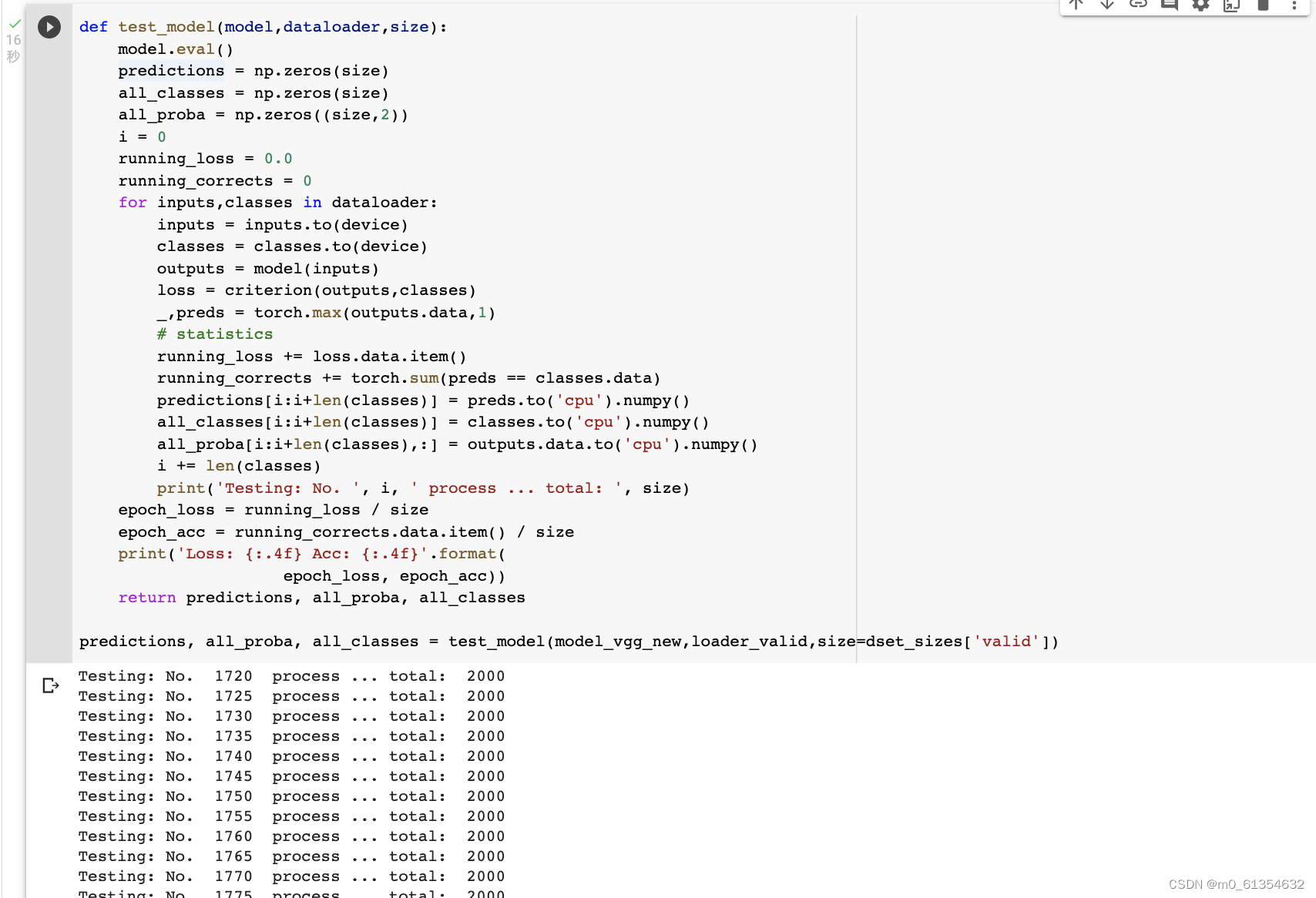
жЎКѓНјаабЕСЗВЂВтЪдШЋСЌНгВуЕШВНжшЭЌЩЯ:
ЮвУЧЗЂЯжзМШЗТЪДяЕНСЫ94.79%ЁЃ
testВПЗжРрЫЦ,ЮЊБугкКѓајImageFolderЖСШЁ,ПЩвдЩњГЩвЛИіrawЮФМўМаДцЗХдЭМЦЌМЏ;ЮФМўЯТдйЩњГЩвЛИіаТЕФЮФМўМа:
import os
import random
import shutil
# source_file:дДТЗОЖ, target_ir:ФПБъТЗОЖ
def cover_files(source_dir, target_ir):
for file in os.listdir(source_dir):
source_file = os.path.join(source_dir, file)
if os.path.isfile(source_file):
shutil.copy(source_file, target_ir)
def ensure_dir_exists(dir_name):
"""Makes sure the folder exists on disk.
Args:
dir_name: Path string to the folder we want to create.
"""
if not os.path.exists(dir_name):
os.makedirs(dir_name)
def moveFile(file_dir, save_dir):
ensure_dir_exists(save_dir)
path_dir = os.listdir(file_dir) # ШЁЭМЦЌЕФдЪМТЗОЖ
filenumber = len(path_dir)
rate = 1 # здЖЈвхГщШЁЭМЦЌЕФБШР§,БШЗНЫЕ100еХГщ10еХ,ФЧОЭЪЧ0.1, 1--БэЪОall
picknumber = int(filenumber * rate) # АДееrateБШР§ДгЮФМўМажаШЁвЛЖЈЪ§СПЭМЦЌ
sample = random.sample(path_dir, picknumber) # ЫцЛњбЁШЁpicknumberЪ§СПЕФбљБОЭМЦЌ
# print (sample)
for name in sample:
shutil.move(file_dir+'/'+name, save_dir+'/'+name)
if __name__ == '__main__':
file_dir = '/content/drive/MyDrive/cat_dog/test' # дДЭМЦЌЮФМўМаТЗОЖ
save_dir = '/content/drive/MyDrive/cat_dog/raw' # вЦЖЏЕНаТЕФЮФМўМаТЗОЖ
moveFile(file_dir,save_dir)
зюКѓНјааНсЙћдЄВтВЂЪфГіCSVЮФМў:
#НЋНсЙћаДШыЮФМў
def result_model(model,dataloader,size):
model.eval()
predictions=np.zeros((size,2),dtype='int')
i = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
#_БэЪОЕФОЭЪЧОпЬхЕФvalue,predsБэЪОЯТБъ,1БэЪОдкааЩЯВйзїШЁзюДѓжЕ,ЗЕЛиРрБ№
_,preds = torch.max(outputs.data,1)
predictions[i:i+len(classes),1] = preds.to('cpu').numpy();
predictions[i:i+len(classes),0] = np.linspace(i,i+len(classes)-1,len(classes))
#ПЩдкЙ§ГЬжаПДЕНВПЗжНсЙћ
print(predictions[i:i+len(classes),:])
i += len(classes)
print('creating: No. ', i, ' process ... total: ', size)
return predictions
result = result_model(model_vgg_new,loader_valid,size=dset_sizes['test'])
np.savetxt("./cat_dog/result.csv",result,fmt="%d",delimiter=",")
НЋCSVЮФМўЕМШыAIбаЯАЩчНјааЬсНЛВщПДНсЙћ:

ЪЕбщИаЯы:
БОДЮЪЕбщЮвСЗЯАСЫVGGФЃаЭЙЙНЈМАбЕСЗЗНЗЈ,ЭЈЙ§УЈЙЗДѓеНЪЕМљСЫVGGФЃаЭЕФЙЙНЈЁЂбЕСЗЁЂВтЪдЕШ;ЕквЛВПЗжЕФСЗЯАПЩвдЫЕЪЧГѕДЮГЂЪд,ИљОнНЬГЬЫМПМДњТыЕФвтвх,ЮЊКѓајЕФAIбаЯАЩчЕФСЗЯАДђЯТСЫЛљДЁ,етВПЗжУЛгагіЕНЪВУДЮЪЬтЁЃдкНјШыбаЯАЩчЕФСЗЯАКѓ,жївЊгіЕНСЫСНИіЮЪЬт,ЕквЛИіЪЧУЈЙЗЮФМўжаЕФЭМЦЌЪЧЮДОЙ§ЗжРрЕФЭМЦЌ,ашвЊЯШНЋЮДЗжзщЕФЭМЦЌЗжЕНСНИіЮФМўМажа,СэвЛИіЮЪЬтОЭЪЧзюКѓЕМГіcsvЮФМўЪБ,дкtestЮФМўЯТашвЊЯШдкФПТМЯТаТНЈвЛИіЮФМўМа,НЋЭМЦЌЕМШы,ВХФмНЋВтЪдМЏЪфГіcsvЮФМўЁЃПЩвдЫЕБОДЮЪЕбщЕФЭъГЩОРњСЫКмЖрВЈел,зюжеФмЙЛЕУЕННсЙћЪЧСюШЫаРЮПЕФ,дквдКѓЕФбЇЯАжаЮвЛЙгІМЬајбЇЯАЯрЙижЊЪЖ,ЕБгіЕНЮЪЬтЪБПЩвдИќПьЕиНтОіЮЪЬт,ЬсИпздМКЕФЩюЖШбЇЯАФмСІ!