目录
一、主题
在模型的设计上,是尽可能的按照最原始的Transformer来做的,这样的一个好处是我们可以直接把NLP那边已经成功地Transformer架构,直接拿过来用,就不需要魔改模型了,而且因为Transformer已经在NLP领域火了这么多年,他有一些写的非常高效的实现,同样Vision Transformer可以把它拿过来使用,
3.1模型总览图
模型总览图对于论文是非常重要的,画的好的总览图能够使读者在不读论文的情况下,光看图就能大概知道整篇论文再讲什么。
Vision Transformer的图好的就很好
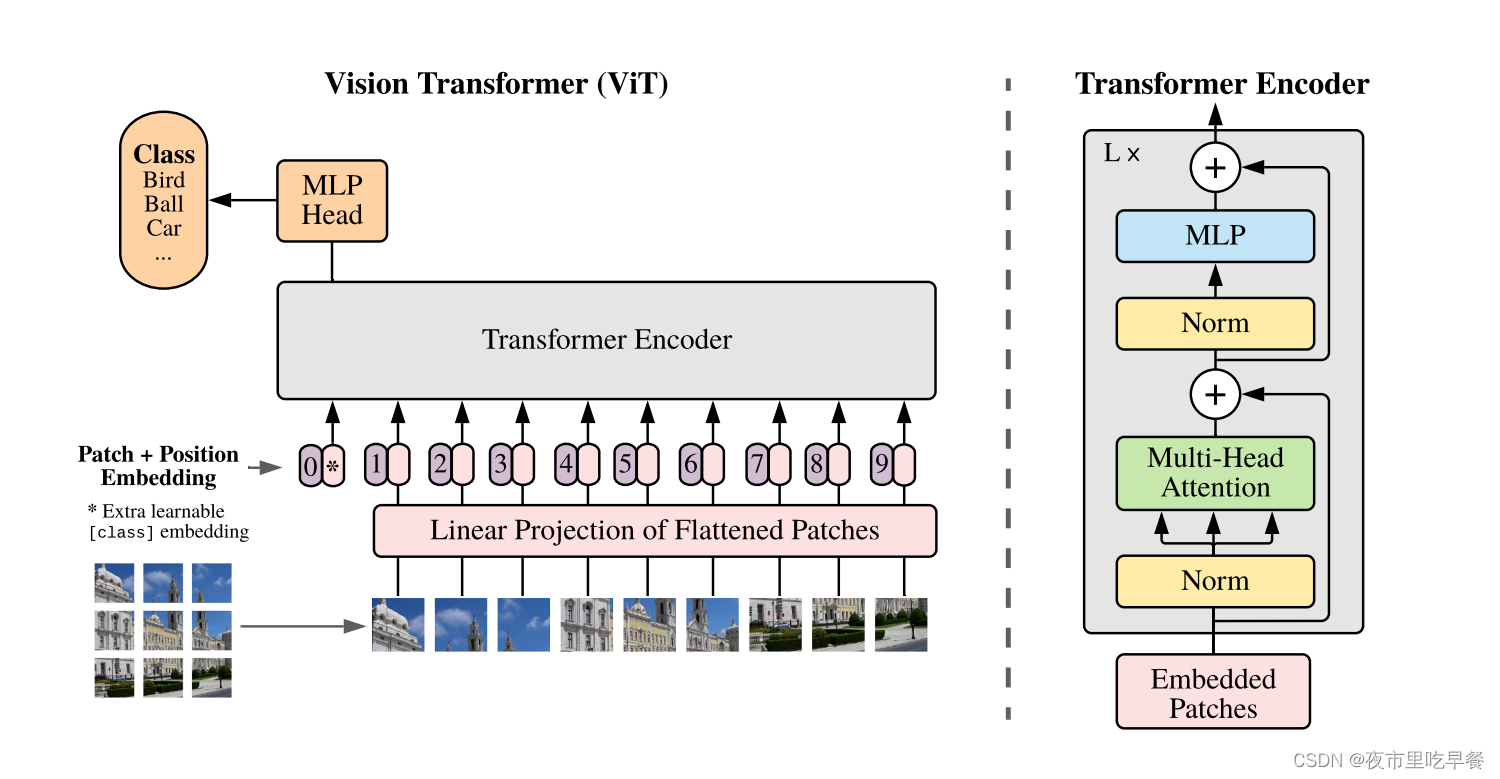
首先我们给定一张图,但是先把一张图打散成很多patch,在这里我们打散成了九宫格,然后把这些patch,变成了一个序列,每个patch会通过一个线性的投射层操作,得到一个特征,便是论文里说的patch embedding
自注意力是所有的元素之间两两去做这个交互,所以说本身并不存在一个顺序问题,但是对于图片来说,他是一个整体,九宫格是有自己的顺序的,如果顺序颠倒,其实就不是原来这张图片了,同样类似NLP,给Patch embedding加上了一个position embedding【位置编码】,加上了位置编码信息以后,这个整体的tokenization就既包含了图片块原来有的图像信息,又包含了这个图像块的所在位置信息,我们一旦得到这些一个个的token
接下来跟NLP那边就完全一样了,直接把它给Transformer encoder,Transformer encoder就会同样反馈给我们很多输出,但这里问题又来了,这么多输出,我们该拿哪些输出去做最后的分类呢?这一次我们再次借鉴Bert,Bert有这个叫做extra learnable embedding,有一个特殊字符叫做CLS,分类字符,同样的,我们在这边用*来代替,他也是position embedding,它有位置信息,他永远是0,因为所有的token都在跟所有的token做交互信息,所以他们的信息class embedding能够从别的这写embedding里头去学到有用的信息,从而我们只需要根据他们的输出,做一个最后的判断就ok了
MLP head其实就是一个通用的分类头,最后用交叉熵函数去进行模型的训练,Transformer encoder也是一个标准Transformer,如下图,当我们有这些patch的时候

先进来做一次layer norm,然后再做multi-head self-attention,layer norm,然后MLP,这就是一个Transformer block,我们可以叠加L次,就可以得到我们的Transformer encoder
Norm表示标准归一化,为了更快速的收敛
整体上来看,Vision Transformer的整体架构还是非常简洁的,他的特殊之处就在于如何把一个图片变成这一系列的token
接下来,我们具体按照论文中的文字,再把整个模型的前向过程走一遍
假如我们有个图片X,维度是224*224*3
如果我们这里使用16*16patch size大小,我们会得到多少token呢?
224*224/16*16=196,14的平方,我们会得到196个图像块,每个图像块的维度如何呢?其实是16*16*3=768,3是RGB channel,所以我们把原来的图片224*224*3,变成了一个有196个patch,每个patch的维度是768
接下来线性投射层,其实也就是全连接层,文章使用E符号代表全连接层,这个全连接层维度是768*768,768是文章中一直说的D,但是这个D是可以改变的,如果我们的Transformer变得更大了,那D也是相应变大,前面的768是从图像patch算出来的,16*16*3算出来的,所以是不变的,经过线性投射层我们得到这个patch embedding
具体来说就是如果X*E,那在维度上就可以理解成196*768,意思是我们现在有196个token,每个token的向量维度是768,现在我们已经成功的把一个vision问题变成了NLP问题,我的输入就是一系列的token,而不是一张2d的图片了
除了图像本身带来的token以外,我们还需要加上一些CLS特殊的字符,我们把cls的输出当做是整个Transformer模型的输出,也就是当做整个图片的特征,这个特殊字符只有一个token,维度也是768,这样方便我们可以和后面图像的信息直接拼接起来,所以最后序列的长度就整体进入Transformer的这个序列长度是196+1,197*768,最后加上位置编码信息,位置编码我们说1.2.3---9,一直到9,但这个只是位置序号,而不是我们真正使用的位置编码,我们不可能把1.2.3.4等数字传给一个Transformer去学习,具体的做法是我们有一个表,这个表的每一行代表了这里面的1.2.3的这个序号,每一行就是一个向量,这个向量的维度跟这边的维度d是一样的也是768,这个向量也是可以学习的,然后我们把这些位置信息加到这些所有的token里面,注意我们是加,而不时拼接,不是concatnation,而是sum,加完位置编码信息之后,这个序列还是197*768
到底我们做完对图片的预处理,包括加上特殊字符CLS和这个位置编码信息,对于Transformer的输入这块embedded patches,就是197*768的一个tensor,这个tensor先过一个layer norm出来,还是197*768,然后我们做多头自注意力,多头自注意力这里就变成了K、Q、V,每一个都是197*768,因为我们使用的是多头自注意力,所以这个维度并不是768,假设说我们现在用的是Vision Transformer的base版本,即多头是用了12个头,那么这个维度就变成了768/12=64维,这里的QKV变成了197*64,但是有12个头,12个对应的QKV去做这个自注意力操作,最后把这些12个头的QKV输出直接拼接起来,这样64拼接出来以后,又变成了768,所以多头自注意力的结果经过拼接,到这块还是197*768,再过一层layer norm还是197*768,再过一层MLP,MLP这里会把维度相对的放大,一般是放大四倍,所以是197*3072,然后再把它缩小投射回去,在变成197*768,就输出,这边是Transformer block的前向传播过程,进去是197*768,出来还是197*768,序列长度和每个token对应维度大小都是一样的,所以我们可以在一个Transformer block上不停的往上边叠传,相加多少加多少,最后有L层的Transformer block的模型就是整个Transformer encoder,到这里面我们就把Vision Transformer的模型讲解完毕了

One More Time【转圈圈】
我们再来过一遍
标准Transformer是需要一系列1d的token作为输入,但是作为2d的图片怎么办呢?
那我们就把整个图片打成小patch,具体有多少个patch呢?
就是n=H*W/P平方,其实就是我们之前算过224*224/16*16=196,这个是对应patch size=16而言,如果patch size变成8或者变成14,对于这个的序列长度也会相应改变
Transformer从头到尾都是用D当做向量长度的,也就是我们刚才说的768,从头到尾的向量长度都是768,这个维度是不变的,为了和Transformer的这个维度匹配上,所以我们图像的这个patch维度也得是768
具体怎么做,我们用可以训练的linear projection,一个全连接层,从全连接层出来的叫做patch embedding,为了最后的分类,我们借鉴了Bert里面的class token一个特殊的CLS token,这个token是一个可以学习的特征,他呢?跟图像的特征有同样的维度,都是768,它只有一个token,经过很多层的这个Transformer block,以后,我们把cls的输出当做是整个Transformer模型的输出,也就是当做整个图片的特征,一旦有了图像特征,后面就好做了,卷积神经网络这一块也是有一个图像的整体特征,我们就在后面加一个MLP的分类图就可以了
对于位置编码信息,这篇文章就是用的标准的可以学习的1D position embedding,就是Bert里面用的位置编码,当然作者也尝试使用了别的编码形式,比如因为我们是做图片的,所以我们对空间上的位置可能更加敏感,我们可能需要2d-aware,就是我们能处理2d信息的一个位置编码,最后发现结果差不多,没什么区别,其实对于特殊的Class token,含有这个位置编码,如果我们用不加任何位置编码,效果很差,只有61%,Transformer根本没有能力感知图片位置的能力,在没有位置编码的情况下,还能得到61的效果,其实相当不错了。这个现象其实还比较奇怪,作者在后边,也给出他们认为比较合理的解释,他们说这个vision Transformer是直接在图像块上去做的,而不是在原来得这个像素块做的,因为图像块很小,比如14*14,而不是全局的224*224,所以我们去排列组合这种小块,或者我们想知道这些小块之间的相对位置信息还是比较容易的,所以我们用什么位置编码都无所谓。
作者还做了详细的消融实验,因为对于Vision Transformer来说,怎么对图片进行预处理,还有怎么对图片进行最后的输出,进行后处理是很关键,因为中间的模型就是一个标准的Transformer
我们来看一下消融实验――Class Token
因为在Original Transformer这篇论文里,我们想跟原始的Transformer尽可能的保持一致,所以我们也使用了class token,因为class token在NLP领域的分类任务里也使用了,在NLP也是被当做一个全局的对句子理解的特征,在这里我们就把它当做是一个图像的整体特征,拿到图像的输出以后,我们就在后面接一个MLP,MLP是用一个tanh当做一个非线性的激活函数,来去做分类的预测,但是这个class token的设计完全借鉴与NLP,之前在视觉领域,我们不是这么做,假设我们现在有一个残差网络res50
![]()
我们前边有几个block,我们有res2res3res4res5,最后这个stage出来呢,是一个feature map,其是14*14这么大,然后在feature map之上,我们做了一步这个Gap操作,也就是global average pulling,就是一个全局的平均池化,池化以后的特征是拉直了,变成一个向量了,我们可以把这个向量理解成是一个全局的对于这个图片的特征,我们就可以拿这个特征去做分类
现在对于Transformer来说,如果你有一个transformer的model,如果进入有n个元素出来也有n个元素,我们为什么不能直接在n个输出上,去做一个global average pulling呢,然后得到一个最后的特征呢?我们为什么非得在这个前面加一个Class token,最后用class token去做输出呢?去做分类呢?
其实通过实验,作者得出结论,其实这两种方式都可以,你可以去做global average pulling ,得到一个全局的特征然后去做分类,或者用一个class token
Vision Transformer这篇论文所有的实验室用class token去做的,主要目的就是跟原始的Transformer保持尽可能的一致。不想让读者觉得,效果好是因为某些trick带来的,或者某些针对cv的改动而带来的,想告诉读者一个标准的Transformer照样能做视觉

绿线代表全局平均池化,原来vision领域里是如何做的,class token代表NLP是如何做的-蓝线,我们可以看到其实最后绿线和蓝线效果是一样的,但是作者指出,绿线和蓝线用的学习率是不一样的,我们需要好好来调参数,如果不好好调参,直接把class token用的学习率直接拿过来去做全局平均池化的话,效果是非常差的,所以有时候不是我们的idea不行,可能主要还是参没调好,炼丹技术还是要过硬。
位置编码这里也做了很多消融实验,主要是三种:
(1)-1D
(2)-2D
(3)-relative positional embedding,
1D就是NLP常用的位置编码,也是vision Transformer这篇文章从头到尾都在使用的位置编码,
2D这个位置编码:原来1D的,把图片打成九宫格,之前有的是123一直到9,现在与其用这种方式去表示那些图像块,我们不如用11,12,13,21,22,23,31,32,33去表示这样一个九宫格的图片,这样就跟视觉问题比较接近了,因为它有了整体的这个structure信息,具体如何做的?
原来1D这种位置编码维度是D,那现在因为横坐标和纵坐标都需要去表示,对于横坐标,我们有个D/2的维度,对于纵坐标来说一样,我们也有D/2的维度,我们分别用一个D/2的向量去表述这个横坐标,然后还有一个D/2的向量去表述纵坐标,最后我们把D/2的向量拼接在一个,concat就有得到一个长度为d的向量,我们把这个向量叫做2d的位置编码。
Relative positional embedding:相对位置编码是什么意思呢?假如我们讲还是1d的这个情况,2patch和9patch的举例既可以用绝对距离来表示,又可以用两个之间的相对距离来表示,就比如2和9之间,差了7个单位距离,也就是论文里说的offset,这样也可以认为是一种方式去表示各个图像块之间的这个位置信息,
这个消融实验最后的结果也是无所谓

如果我们用不加任何位置编码,效果很差,只有61%,Transformer根本没有能力感知图片位置的能力,在没有位置编码的情况下,还能得到61的效果,其实相当不错了
如果我们来对比三种位置编码的,我们会发现所有的Performance都是64%,没有任何区别,这个现象其实还比较奇怪,作者在后边,也给出他们认为比较合理的解释,他们说这个vision Transformer是直接在图像块上去做的,而不是在原来得这个像素块做的,因为图像块很小,比如14*14,而不是全局的224*224,所以我们去排列组合这种小块,或者我们想知道这些小块之间的相对位置信息还是比较容易的,所以我们用什么位置编码都无所谓。
在看了那些消融实验以后,我们可以看出这个class token,也可以用global average pulling去替换,包括最后的这个1dpositional embedding,也可以用2d的或者相对位置编码去替换,但是为了尽可能对标准Transformer不做改动,所以本文还是用了class token,还是用了1d位置编码
Transformer 现在来看已经是非常标准的一个操作,这里对Transformer或者多头自注意力解释都没有放在正文里,都放在附录里面,跟我们现在看卷积神经网络的论文不会有人把卷积写在正文里,作者用公式把整体过程总结了一下
刚开始,x1p、x2p、、、xnp,其实就是这些图像块patch,一共有n个patch,
每个patch先去跟全连接层去做转换从而得到patch embedding,得到这些之后,我们在他前面拼接一个class embedding,因为我们需要它去做最后的输出,一旦得到所有的tokens,我们需要对所有的token做位置编码,所以我们需要把位置编码加进去,这个是对Transformer的输入了,接下来就是循环,对每一个Transformer block来说,里面都有两个操作,一个多头自注意力一个是MLP,在做这两个操作之前,我们都要先过Layer norm,每一层出来的结果,都要再去有一个残差连接,zl’就是每一个多头自注意力出来的结果,zl是每一个Transformer block整体做完以后出来的结果
多头自注意力Multi-head Self-Attention(MSA)、多层感知机Multilayer Perceptron(MLP)

L层循环完之后,我们把ZL,最后一层的输出第一个位置上zL0,class token的输出当做整体图像的一个特征,从而做最后的这个分类任务,
到此,Vision Transformer的文字描述也就结束了,
3.2 微调
最后补了一些分析,比如归纳偏置,并且也提出了一个模型的变体,叫做这个混合模型
在3.2里讲的,当我们遇到更大尺寸图片的时候,你该怎么去做微调?
我们先来看归纳偏置,文章说Vision Transformer比CNN而言,要少很多这种图像特有的归纳偏置,比如说在CNN里这个locality,还有这个translation equivariance就是局部性还有平移等变性,是在模型的每一层都会有体现的,这个先验知识相当于贯穿整个模型始终,但是对于ViT来说,这个MLP这个层是局部而且平移等变性的,但是自注意力层,绝对是全局的,这种图片2d的信息呢,基本ViT没怎么用,其实就是刚开始把图片切成patch的时候,加这个位置编码的时候用了,而除此之外,再也没有用什么针对视觉问题,针对图像的这个归纳偏置了,位置编码其实刚开始随机初始化,并没有携带任何关于2d的信息,所有的关于这个图像块之间的距离信息这个场景信息都需要重头学习,vision translation没有用太多的归纳偏置,所以在中小型数据集上进行一系列的训练的时候,效果不如卷积神经网络是可以理解的
Translation全局建模能力比较强,卷积神经网络又比较data efficient,就不用那么多的训练数据,那么我们是否可以搞一个混合的网络,前边是卷积神经网络,后边是Transformer,这里也做了对应实验
原来我们有个图片,我们把它打成patch,例如我们打成了16*16的patch,我们得到了196个元素,196个元素去和全连接层做一次操作,得到patch embedding,现在我们不把图片打成块,我们就按照卷积神经网络那样去处理图片,一整张图片进来,然后我们给他一个CNN,比如说残差网络res50,最后的那个特征图出来,是一个14*14的特征图,这个特征图刚好把它拉直以后,它也是196个元素,我们把新得到的196个元素去跟这个全连接层做操作,得到新的patch embedding,这里就是两种不同对图片做预处理的方式,一种是直接把它打成patch,很简单直接过全连接层,另外一个就是还要过一个cnn,得到这样一个196的序列长度,但是得到的序列长度都是196,所以后续操作都是一样的,扔给一个Transformer,最后做分类
为什么要把微调放在这个3*3呢?
因为之前有工作说,如果我们在微调的时候,能用比较大的图像尺寸,不是用224*224的,而是用256*256,甚至更大,320*320,那么就会得到更好地结果,vision transformer也想在更大的尺寸上去做微调,但是由于预训练一个好的vision Transformer,其实是不太好去调整这个输入尺寸的,当你用更大尺寸图片的时候,如果我们把patch size保持一样,但是图片扩大,很显然我们的序列长度就增长了,原来是224*224/16*16,假如现在换成了320*320,那就是320*320/16*16,序列长度很定是增加的,虽然Transformer从理论上来说,可以处理任意长度的,只要硬件允许,任意长度都可以,但是我们之前提前预训练好的这些位置编码有可能就没用了,因为我们原来的位置编码,九宫格的话1-9,他是有明确的位置信息的意义在里面的,现在图片变大,如果保持patch size不变的话,我们可能得到16宫格,二十五宫格,patch增多,那么我们现在的位置信息从1到25,而不是从1到9,那这个时候的位置编码该如何使用呢,论文发现
其实简单地做一个2d的插值就可以了
这里的操作就是使用torch官方自带的这个interpolate的函数就能够完成,但是这个插值也不是想插多少就插多少的,当你从一个很短的序列,想要变成一个很长的序列的时候,比如从256到512,甚至768更长的时候,直接这样一个简单地插值操作,是会让最后的效果掉点的,所以这里的插值只能说是一种临时的解决方法,他算是vision transformer在微调的时候的一个局限性。因为我们用了这个图片的位置信息去做插值,所以这块的尺寸改变,还有这个抽图像块,是vision transformer里唯一的地方,用了2d信息的归纳偏置。
二、实验部分
在这个章节,主要是对比了残差网络,ViT他们这个混合模型的这个表征学习能力,了解到底训练好每个模型需要多少数据,他们在不同的数据集上去做预训练,然后在很多数据集上去做测试,当考虑到预训练的这个计算代价,预训练的这个时间长短的时候,vision transformer的表现得非常好,能在大多数数据之上取得最好的结果,同时需要更少的时间去训练
最后作者做了一个小实验做了个自监督的实验,实验结果还可以,虽然没有最好,但是这还是比较有潜力,事实上确实如此,最近大火的MAE就证明了用自监督的方式去训练VIT确实效果很好,数据集的使用方面,主要使用了ImageNet的数据集,把这个有1000个类,就是大家普遍使用的这个1000类的ImageNet数据集,叫做ImageNet或者很多论文叫做ImageNet-1k,更大的那个数据集,叫做ImageNet-21K,具有21k类和1400万图像有21000个类别的数据集叫做ImageNet-21K,JFT数据集就是谷歌自己的数据集,拥有18k类和3.03亿高分辨率图像,他的下游任务全部做的是分类,也用的是比较popular的数据集,比如ICIFar、oxford pet、Oxford flower这些数据集,
接下来我们来看一下模型的变体。
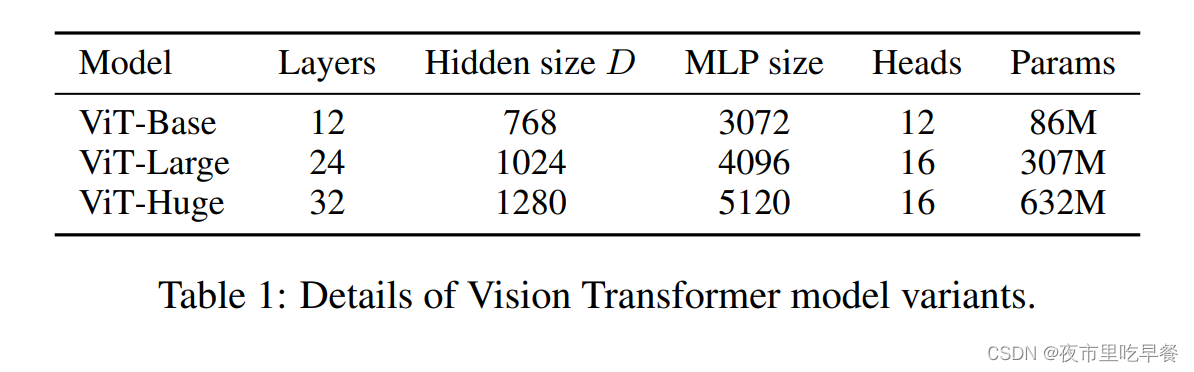
一共有三种模型,其实跟Transformer那边是对应的,有base、large、huge,对应的参数全都逐渐的变大,比如说用了更多地Transformer block,或者用了更长的向量维度,或者MLP的size变大,或者多头自注意力用了更多地头
接着在正文里补充了一些内容,因为它的模型不光跟Transformer本身有关系,还跟这个输入有关系,当然Patch size大小变化的时候,比如从16*16变成32*32,或者变小变成8*8的时候,这个模型的位置编码就不一样,所以patch size也要考虑到模型命名里面,所以他们模型命名的方式就是Vit-l 16,意思就是说用了一个vit large的模型,然后他的输入patch size是16*16,这个Transformer的序列长度其实是跟patch size成反比的,patch size越小,切成的块就越大,patch size越大,切成的块就小,所以当模型用了更小的patch size的时候,计算起来就会更贵,Vit-l 16换成Vit-l 8的话,vit-L 8的模型就比16贵很多,因为他的序列长度增加了。
结果
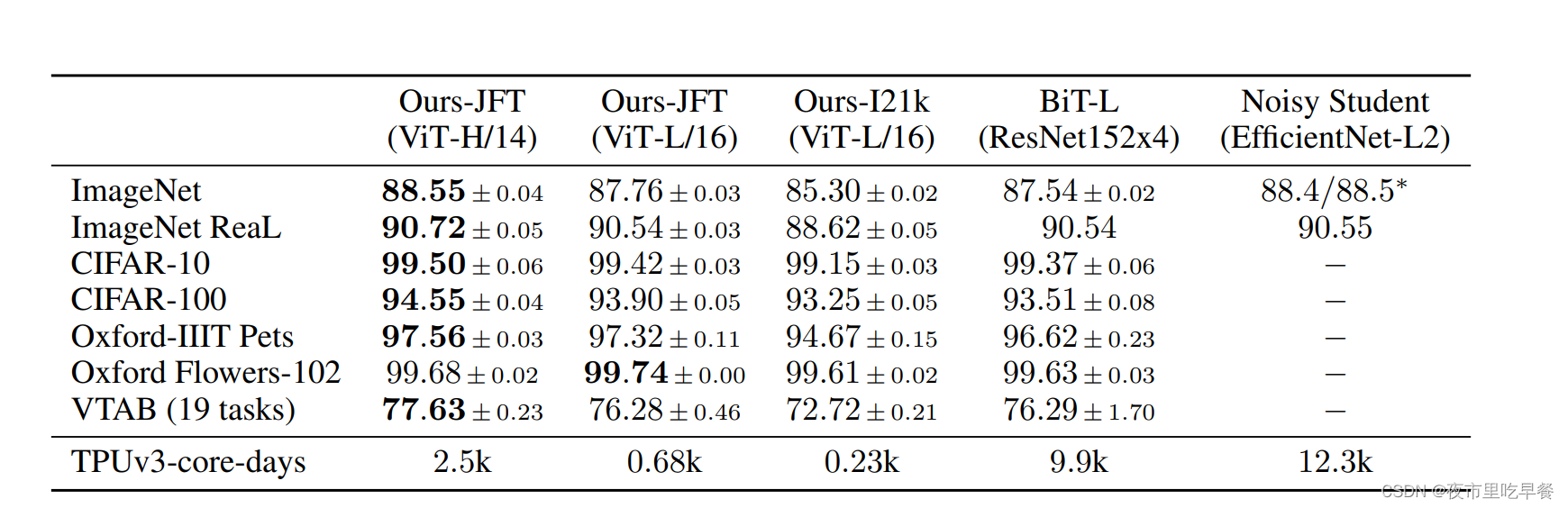
已经在大规模的数据集上进行预训练了,然后在这么多数据上去做fine-tune(微调)时候得到的表现,这里先对比了几个Vit的变体,比如vit的huge model就是最大的那个模型,全部取得了最好的结果,跟卷积神经网络Bit和noisy student来进行对比,跟bit做对比的原因,因为bit确实是卷积神经网络里做的比较大的,而且也因为这个作者团队自己本身的工作,所以真好可以那俩进行比较,所以之前做的数据集,bit也都做过,至于noisy student是因为他是ImageNet之前表现最好的方法,他用的方式是用pseudo-label为伪标签去进行self-training,就是用伪标签也取得掉了很好的效果。
我们从这个表里看出来vit-huge这模型,他是用比较patch size14,相对更贵一点的模型,它能取得所有数据集上最好得效果,虽然说这个99.74%被黑体了,但是跟99.68也没差多少。但是因为这些数值都太接近了,都是差零点几个点,一点多,没有特别大的差距,作者就觉得没有展现出来vision transformer的威力,作者就从另外一个角度来凸显vit 的优点,因为我们训练起来更便宜,他说的便宜是说他们最大vit huge,也只是需要训练2500天,tpuv 3天数,正好bit和noisy student也都是Google 的工作,也都是tpuv 3训练,刚好可以拿来比,bit用了9900天,noisy student用了一万多天,所以从这角度来说,vit不仅比之前bit和noisy student训练的快,而且效果还比他们好,这下双重卖点,大家就会觉Vision Transformer真的比卷积神经网络要好
接下来我们来做分析
Vision Transformer到底需要多少数据,才能训练的比较好?
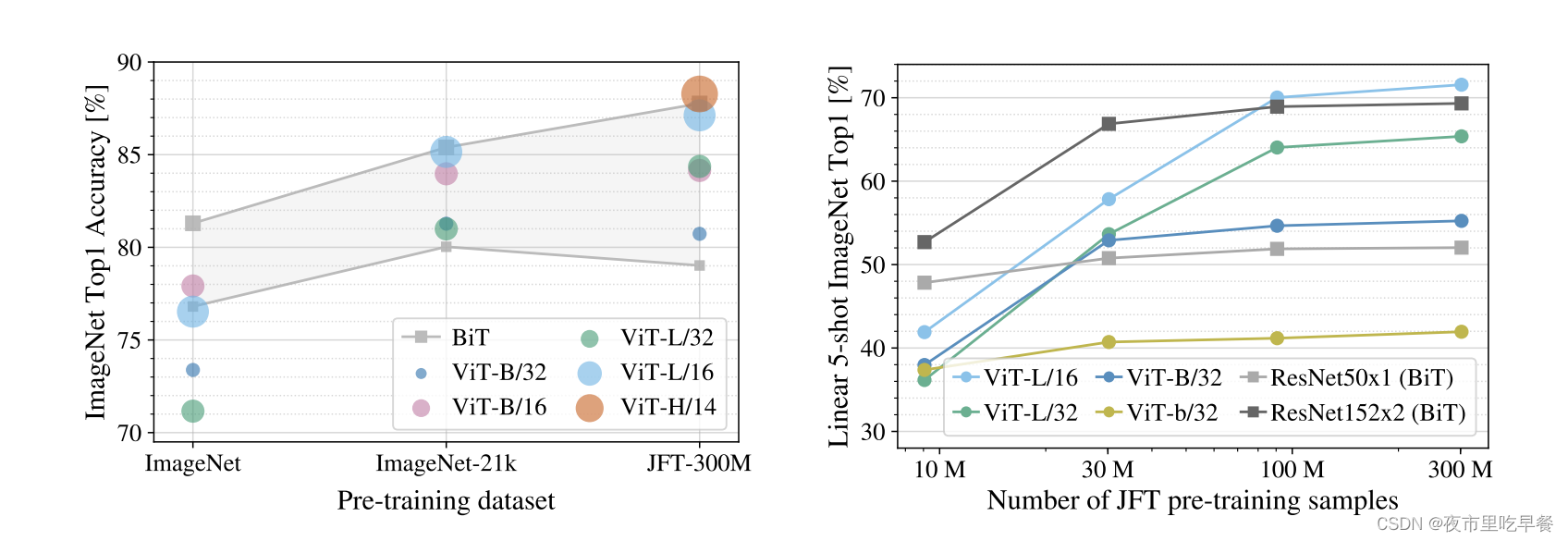
这个图应该是整个Vision Transformer论文最重要的take home message,最想要我们知道的,这张图的意思是当我们使用大小不同的数据集的时候,比如说ImageNet是1.2 million,ImageNet-21k是14million,JFT是300million,当数据集不断增大的时候,resnet和vit到底在ImageNet的fine-tune的时候效果如何,灰色代表bit
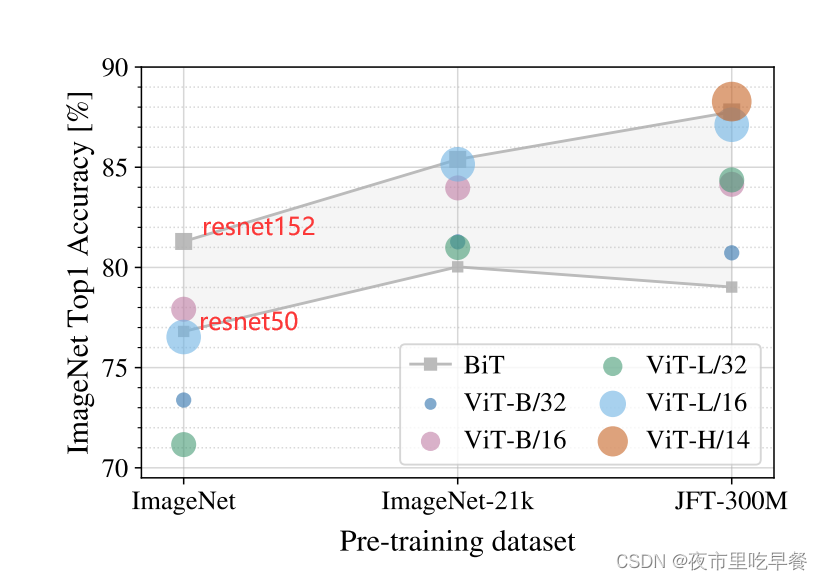
各种大小的resnet,最小的然后到最大的,这么一个范围,在中间这个灰色区域,resnet能达到的效果范围,剩下的圆圈和点就是大小不一的vision Transformer,在最小的ImageNet做预训练,Resnet和Vision Transformer的比较如何,Vision Transformer是全面不如resnet,我们看到vision Transformer基本都在resnet的灰色区域下方,vision Transformer在中小型数据集上做预训练的时候,效果是远不如残差网络,因为是Vision Transformer没有用先验知识,没有用归纳偏置,所以需要用更多的数据去让网络学习的更好,
换到ImageNet-21k,我们发现Vision Transformer和resnet效果差不都,基本大家都在灰色区域里,只有当用特别大的数据集用3个亿的图片数据集去做预训练的时候,我们可以发现vision transformer基本全面超过resnet,即使是最小的vit-b 32也比resnet50要高,其次我们用最大的模型vit h 14 的时候,他是比bit对应的res152还要高,总之,这张图表现两个信息:如果想用Vision Transformer,我们至少得准备差不多ImageNet-21k大小的数据集,如果只有很小的数据集呢?还是用卷积神经网络比较好。当我们有比ImageNet-21k数据集更大的时候,我们用vision transformer会带给我们更好地效果,它的扩展性会更好,
整篇论文就是这个scaling,接下来,作者做了图四
在图三【上图】的时候,需要用vision transformer去跟resnet相比,所以在训练的时候用了一些强约束。比如说用了dropout,用了weight decay,用了label smoothing,就不太好分析Vit模型本身的一些特性
在图四里面做的是linear fewshot evaluation,就是我们一旦拿到这个预训练的模型,直接把对它当成一个特征提取器,不去微调,而是拿这些特征直接来做一个just take a regression就行,同时他选择了few-shot
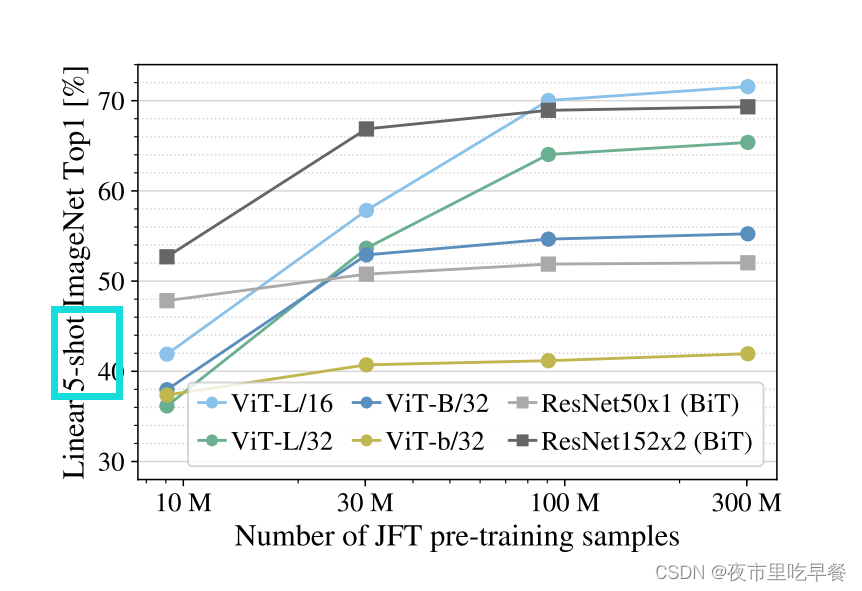
在图里也看到是5―shot就是在ImageNet上你去做linear evaluation的时候,每一类随机选择5个sample,所以这个evaluation做起来是很快的,作者也是用了这种方式去做了大量的消融实验,【控制变量法】
横轴表示预训练数据集的大小,这里没有用别的数据集,用的就是JFT,但是取了JFT的一些子集,这样所有的数据都是从一个数据集里来的,他就没有大的distribution gap【分配差距】,这样比较起来,模型的效果就更加体现模型本身的特质,至于结果跟图三相比也是差不多的,浅灰色的线是resnet50,深灰色是resnet152,当用很小的预训练数据集时候,vision transformer完全比不过resnet,文章给出的解释因为缺少归纳偏置和约束的方法,比如weight decay,label smoothing这些,所以导致这里的vision Transformer容易过拟合,导致最后学到的特征不是和做其他任务,但是随着预训练数据集的增大, Vision Transformer的稳健性就上来了。
但是因为这里的提升也不是很明显所以作者也写了如何用vision transformer去做小样本的学习是一个非常有前途的方向。

这篇论文之前说了预训练比用卷积神经网络要便宜,那这里需要做更多地实验去支持这个论断,因为大家对Transformer的印象都是又大又贵,很难训练,图五里画了两个表,一个average-5,他是在5个数据集上去做了evaluation然后把数字平均了,那这个五个数据集分别是ImageNet-real、pets、flowers、CIFar10 和CIFAR100,因为ImageNet太重要了,所以把ImageNet单独摘出来,又画出来了一张,其实两张表结果差不多,
蓝色是Vit,灰色是Resnet,橙色是混合模型,前面是卷积神经网络,后边是Transformer,图里大大小小的点,其实是各种配置下大小不一样的Vision Transformer的各种变体,或者说是Resnet的变体,这两张图里所有的模型都是在JFT 300million的这个数据集上去训练的,作者不想让魔性的能力受限于数据集的大小,所以说,所有的模型都在最大的数据集上去做预训练,我们可以看到几个比较有意思的现象,如果我们拿蓝色的圈圈去跟灰色Resnet相比,我们会发现在同等的计算复杂度的情况下,一般Transformer要比resnet要好的,这个证明他们所说的训练一个vision Transformer是要比一个训练一个卷积神经网络要便宜的
第二个是我们可以发现在比较小的模型上,混合模型的精读是非常高的,他比vision Transformer和对应的resnet都要高,这个也没有什么需要惊讶的,按道理来说,混合模型就应该吸收了双方的优点,即不需要很多数据进行预训练,同时又能达到跟Vision Transformer一样的效果,但是好玩的是说,当随着模型越来越大的时候,混合模型慢慢就跟Vision Transformer差不多了,甚至可能还不如在同等计算条件下的vision transformer,为什么卷积神经网络抽取出来的特征没有帮助vision transformer去更好地学习呢?这里作者没有进行过多的解释,其实怎么去预处理一个图像,怎么去做tokenization是非常重要的一个点,之后有很多论文都去研究了这个问题,最后,我们看整体趋势就是,随着这个模型不断地增加,vision transformer的效果也在不断增加,并没有饱和的现象,当然只从图里来看,我们会发现除了混合模型有点饱和之外,其实卷积神经网络效果也没有饱和,分析完这些训练成本之后,作者就继续做了一些可视化,作者希望通过可视化,可以分析一下vit内部的表征,如果类似卷积神经网络的话,就是第一层到底学到了什么特征

Vision transformer的第一层就是linear projection layer就是我们说的大E,我们来看图7

展示了大E是如何embed rgb value的,这里只是展示了头28个,其实vision transformer学到的跟卷积神经网络的很像,都是这种像gabor filter的这种,有一些颜色还有一些纹理,所以作者说这些成分是可以当做这个基函数的,也就是说可以去描述每一个图像块的这种底层的结构,看完patch embedding。我们来看一下positional embedding,位置编码如何工作
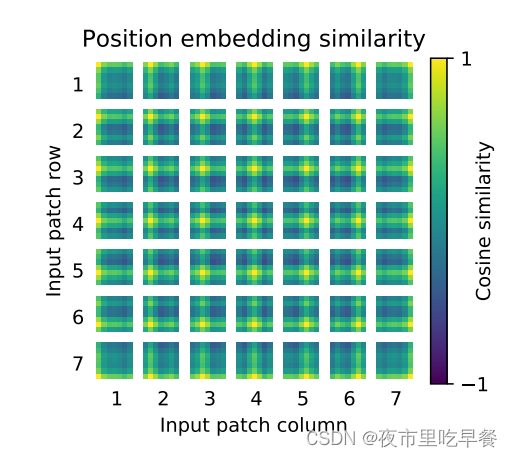
这个画的是位置编码的相似性,相似性越高是1,相似性越低是-1,因为它做的是cosine similarity,他的横纵坐标分别是对应的patch,首先我们来看,同一个patch,自己跟自己比,那这个相似性很定是最高的,接下来我们观察到,这个学到的位置编码真的可以表示一些这个距离的信息的,假如我们看这个
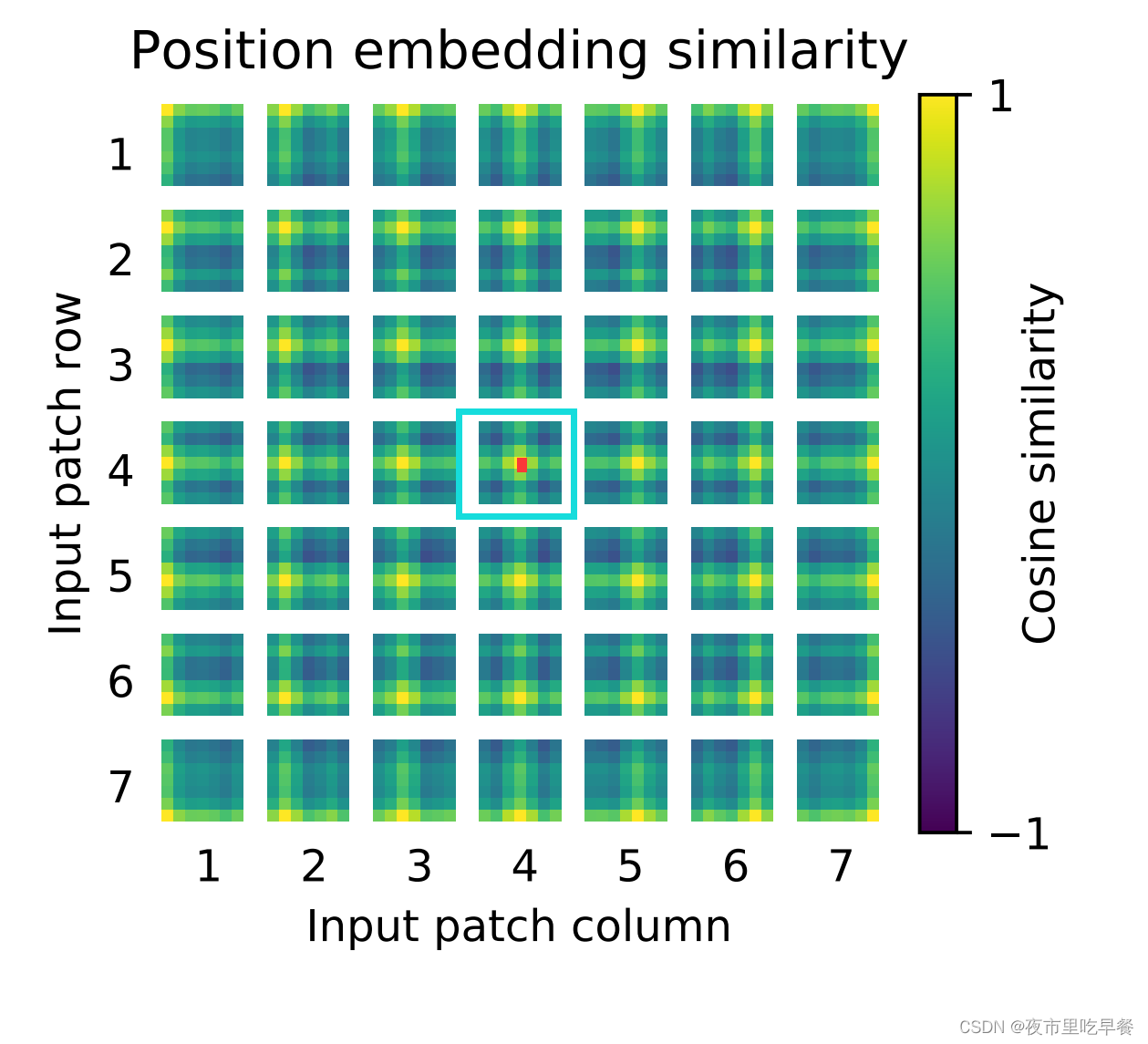
离中心点越近的地方,他就会越黄,离中心点越远的,就会越蓝,也就意味着相似度越低,所以它学到了这个距离的概念,同时我们还看到了他还学到了行和列之间的一个规则
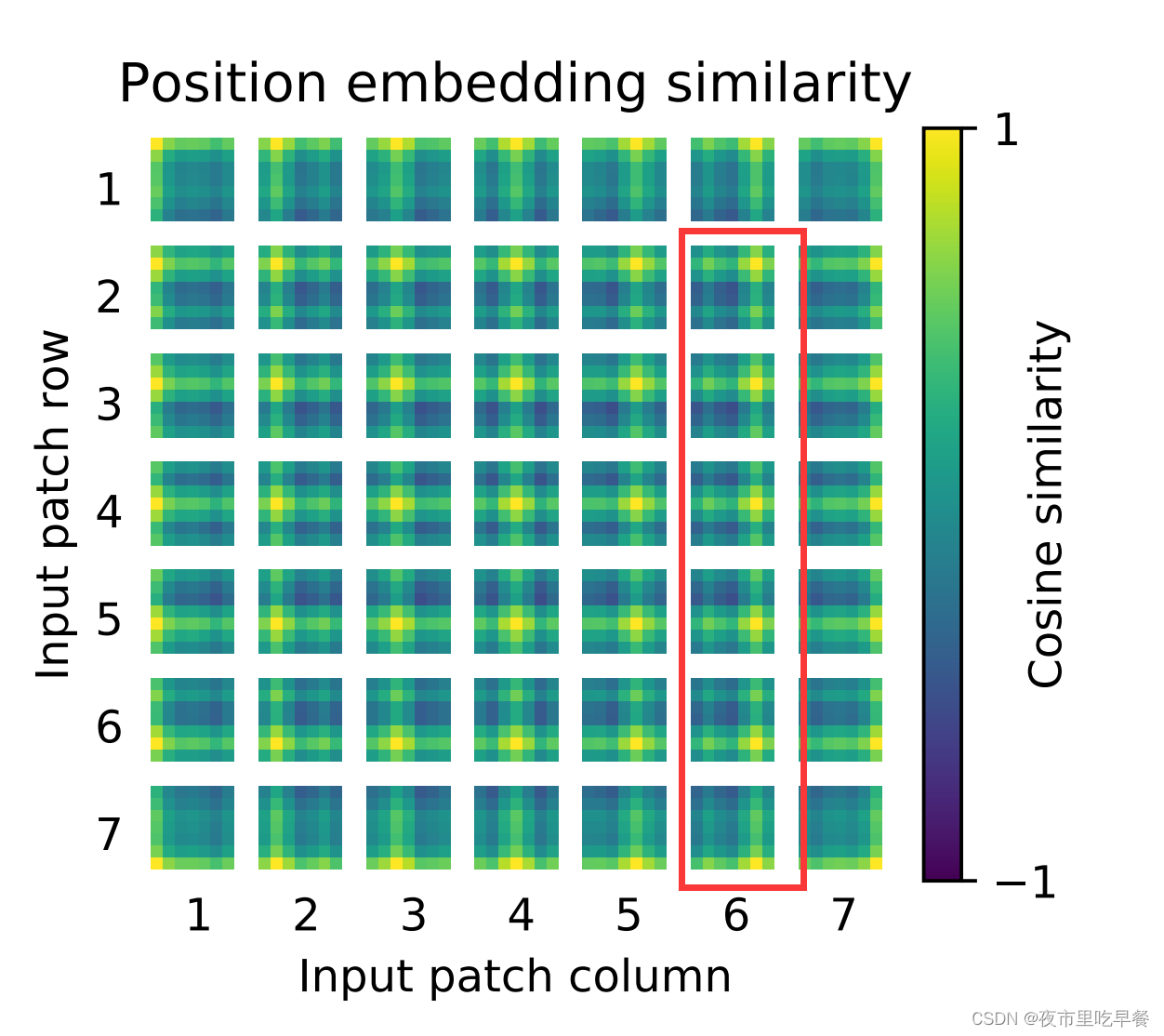
每一个都是同行同列的这个相似度更高,意味着虽然他是1d的位置编码,但是它已经学到了2d图像的这种距离的概念,所以作者在文中也说了,这也可以解释,为什么换成2d的位置编码以后,并没有得到效果的提升,是因为1d的已经够用了
最后,作者想看一下自注意力呢,到底有没有起作用,因为大家想用Transformer,就是因为自注意力操作,能够模拟长距离的关系,在NLP就是说一个很长的句子,开头的词和结尾的词也能互相有关联,在图像里面,就是很远的两个像素点,之间也能做自注意力,作者在这里就想看一下,自注意力到底是不是像期待的一样,去工作的。
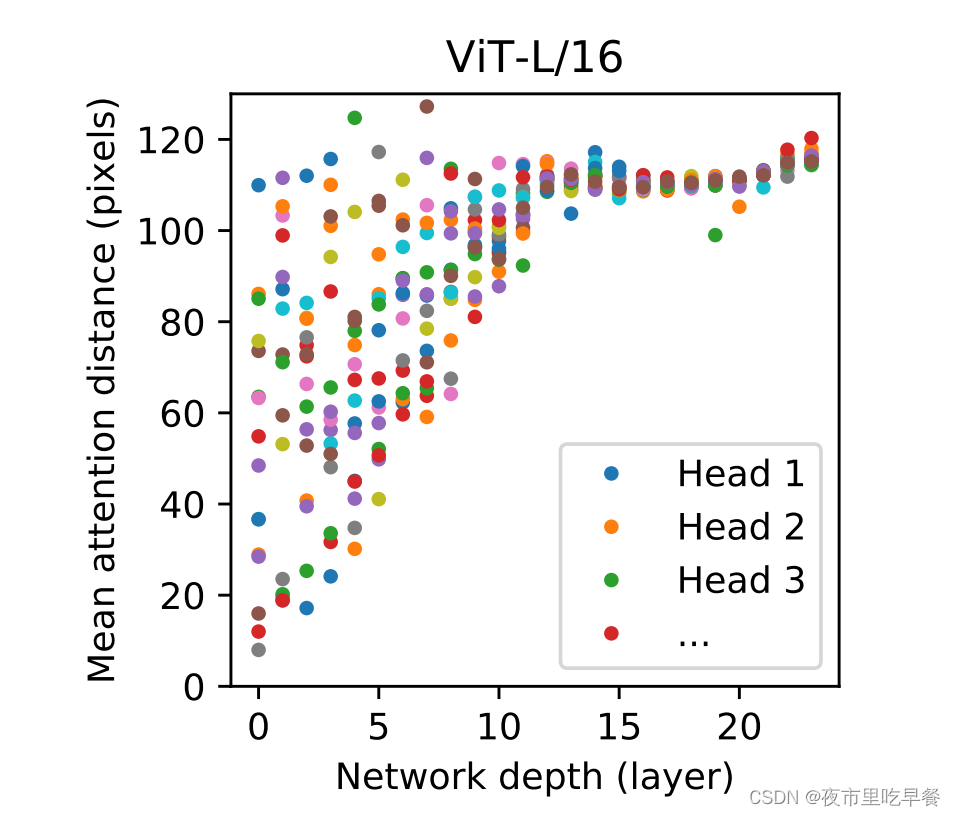
我们来看Vit-L 16 ,这个模型,vit large只有24层,所以横坐标的网络深度就是从0到24,这些五颜六色的点就是每一层Transformer block里面的多头自注意力的头,对于vit large来说,我们一共有16个头,所以每一列呢,其实就有16个点,纵轴画的是一个叫mean attention distance的东西,就是平均注意力的距离,这个是如何定义的呢?
假如说我们图像上有两个点,a和b,那么这个mean attention distance dab就相当于是lab,这两个点之间真正的pixel之间差的距离,乘以他们之间的attention weights,因为自注意力是全局再做,所以说每个像素点跟每个像素点都会有一个自注意力权重,那么dab的大小就能反映这个模型到底能不能注意到很远的两个pixel,这个图里的规律还是明显的,假如我们先看头几层,头几层就说有的自注意力头注意的距离还是挺近的,可能20个pixel,但是有的头能达到120pixel,这也就证明了自注意力真的能在网络最底层,就在最刚开始的时候就已经注意到全局上的信息了,而不是像卷积神经网络一样,刚开始第一层的是receptive field (感受野),非常小,就只能看到附近的这些pixel,随着网络越来越深入呢,网络学到的特征也会变得越来越high level,越来越具有语义信息,我们可以看到,在网络的后半部分他的自注意力距离都非常远了,也就意味着它已经学到了带有语义性的概念,而不是靠临近的这个像素点去进行判断,为了验证这一点,作者又画了另外一个图,就是下图

这里面,是用网络最后一层output token去做的这些图,发现如果用输出的token这个自注意力折射回原来的这个输入图片,我们其实可以看到他真的学到了概念,比如说第一个里面的这个狗,它已经注意到了狗,还有这个飞机
对于全局来说,因为输出token是融合了所有信息,这个全局的特征,所以模型已经可以关注到那些图像区域,哪些区域呢?就是跟分类最后有关的区域,
文章最后,作者做了一个尝试,如何用自监督的方式,去训练一个vision transformer,
这篇论文算上附录,一共有22页,在这么多结果中,作者把别的结果也都放在了附录里面,而把自监督放在了正文里,可见其重要性,它之所以重要是因为在NLP领域,transformer模型确实起到了很大推动作用,但是真正让transformer火起来的另外一个成功因素是大规模的自监督训练,这两个缺一不可,
Nlp的自监督无非是就是完形填空和预测下一个单词,因为这篇论文整体仿照bert,所以作者想说,咱能不能也借鉴这个bert这个目标函数去创建一个专属于vision 的目标函数,bert其实就是完形填空,mask language modeling,一个句子给我,我们把一些句子抹掉,然后我们通过一个模型,最后在把它预测出来,同样道理,这篇论文就搞了一个masked patch prediction,意思就是说我有一个图片,我们已经画成patch了,而这时候我们把某些patch随机抹掉,通过这个模型以后,我们再把整个patch给重建出来,
这真的很激动人心,因为它不论是从模型上,还是从目标函数上,CV和NLP真的就做到了大一统
但是他们这个模型,比如vit base一个patch size 16的模型,在ImageNet上大概只能达到80%的准确率,相当于从头来训练这个vision transformer呢,它已经提高了2%,但是跟最好的这种有监督的训练方式来说还差4%,作者把跟对比学习的结合当做是future work,
对比学习其实是2020年cv圈里最火的一个topic,是所有自监督学习方法里表现最好的,所以紧接着vit Moco v3就出来了,还有Dino,这两篇论文都是用contrastive方式去训练了一个vision transformer
三、回顾总结
这篇论文写的还是相当简洁明了的,在有这么多内容和结果的情况下,做到了有轻有重,最重要的结果放到了正文里,图和表也都做的一目了然
内容上来说,vision transformer真的挖了一个巨坑,我们可以从多个角度去分析他,或者提高他,或者和推广它,比如从任务角度来说,vision transformer只做了分类,接下来,很自然我们可以拿来去做检测、分割和甚至别的领域的任务
那如果是从改变结构的角度来说呢我们可以去改刚开始的tokenization,我们也可以修改中间的这个transformer block,后来就有人把self-attention换成了mlp,而且还是可以工作的很好,有一篇论文叫做mataformer,他觉得transformer 真正work的原因是transformer的这个架构,而不是某些特殊的算子,所以他就把这个self -attention呢,直接换成了一个池化操作,然后他发现用一个甚至不能学习的池化操作,也就是它提出的这个poll former的这个模型,也能在视觉领域取得很好的效果,所以在模型的改进上也是大有可为,而如果从目标函数来讲那就更是了,我们可以继续走有监督,也可以尝试很多不同的自监督训练方式
更重要的是他打破了CV和NLP之间的鸿沟,挖了一个更大的多模态的坑,加下来可以用它去做视频,去做音频,甚至可以做一些基于touch的这种信号,就各种modality的信号都可以拿来使用,
卷积、自注意力或者MLP,究竟鹿死谁手还犹未可知,期待下一个积极出现的一个改进版的vision transformer,可能真的就是一个简洁高效的通用的视觉骨干网络,而且可以完全不用标注任何信息