深度学习论文: SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers及其PyTorch实现
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
PDF: https://arxiv.org/pdf/2105.15203.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
SegFormer使用一种分层特征表示的方法,每个transformer层的输出特征尺寸逐层递减,通过这种方式捕获不同尺度的特征信息。并且舍弃了ViT中的position embedding操作,避免了测试图像与训练图像尺寸不同而导致模型性能下降的问题。在decoder部分采用简单的MLP结构,聚合transformer层不同尺度的特征,可以同时融合局部注意力和全局注意力。

2 SegFormer
SegFormer由两个主要部分组成:
- (1)采用分级Transformer编码器生成高分辨率粗特征和低分辨率细特征;
- (2)一个轻量级的All-MLP解码器,融合这些多级特征,生成最终的语义分割掩码。
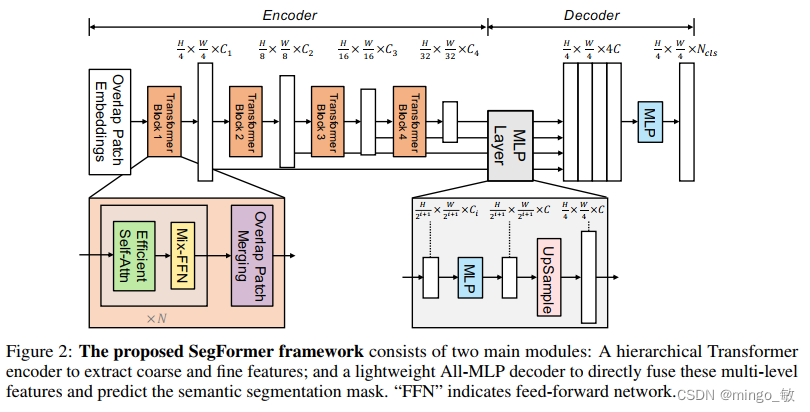
2-1 Hierarchical Transformer Encoder
2-1-1 Hierarchical Feature Representation
给定分辨率为H×W×3的输入图像,我们通过patch merging获得一系列层次化的特征图。
2-1-2 Overlapped Patch Merging
通过Overlapped Patch Merging来实现特征图尺寸递减的操作,减少特征图的尺寸的同时增加特征图的通道数。但是这种操作的弊端是不能保留不同patch之间的连续信息。
2-1-3 Efficient Self-Attention
由于Attention操作的复杂度与序列长度的平方成正比,文中采用一种序列减少操作(先reshape在通过一个线性层)降低序列长度,以此来减少计算的复杂度。
参考资料:
1 Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
2-1-4 Mix-FFN
Mix-FFN结构通过添加一个3×3卷积和一个MLP层到FFN中,为Transformer层提供位置信息。
2-2 Lightweight All-MLP Decoder
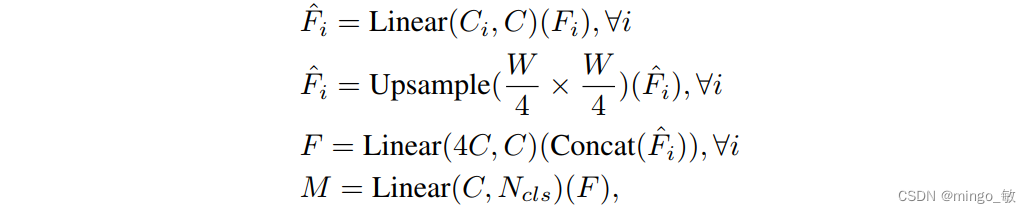
ALL-MLP Decoder包含四步:
- 将transformer各层的输出转换成统一的维度。
- 将特征上采样到1/4然后进行拼接。
- 使用一个MLP融合拼接后的不同特征。
- 最后使用一个MLP生成遮罩。
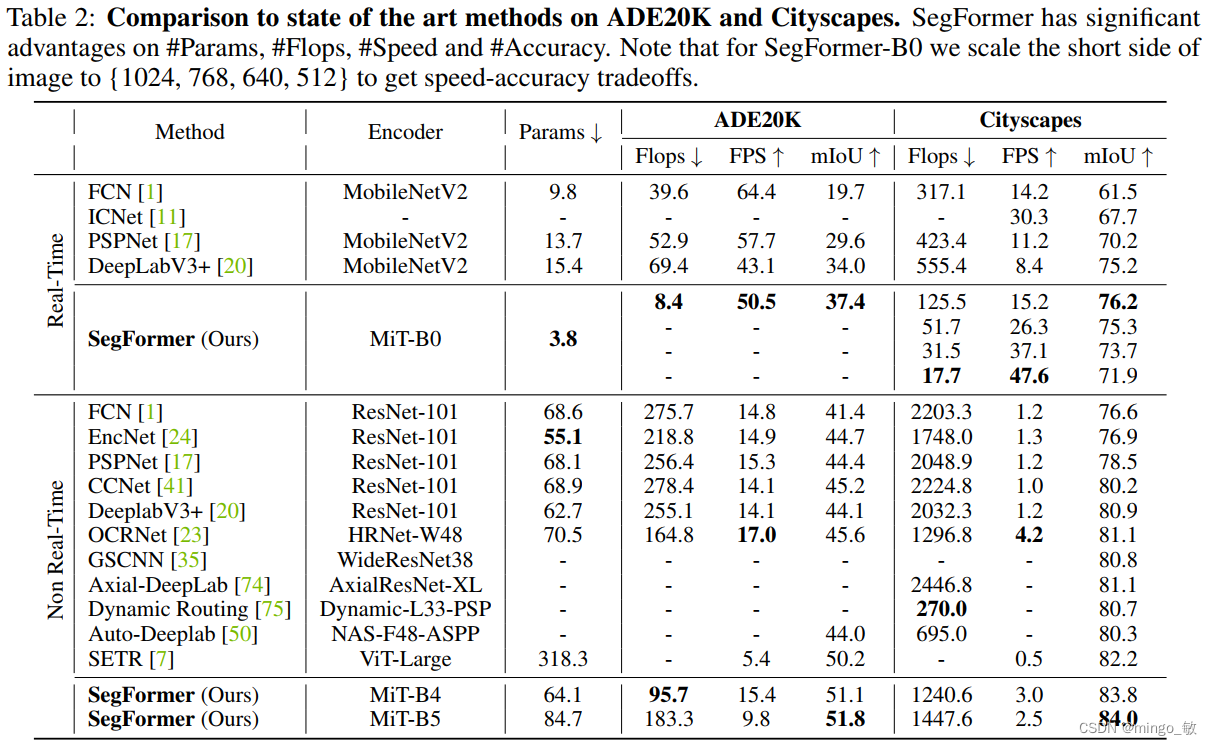
3 Experiments