self-attention
self-attention������
��ע�������Ƶ�������һ��������,���������Ĵ�С����Ŀ���ǿɱ�ġ�
���ִ�������
����һ:one-hot ����,one-hot vector ��ά�Ⱦ������е��ʵ�����,ÿ�����ʶ���һ�����ȵ�����,ֻ�Dz�ͬ�����ڲ�ͬλ���� 1 ��ʾ�������������ȡ,��Ϊ���ʺܶ�,ÿһ��vector ��ά�Ⱦͻ�ܳ�,���Ҳ�����������ϡ���ά����,��Ҫ�Ŀռ�̫����,���ҿ���������֮��Ĺ�����
������:word embedding,������������Ϣ,ÿ���ʻ��Ӧ��������һ��һ����,�������ͽӽ��ĵ���,��������ӽ�,���ǵ��˵���֮��Ĺ�����https://youtu.be/X7PH3NuYW0Q

��������
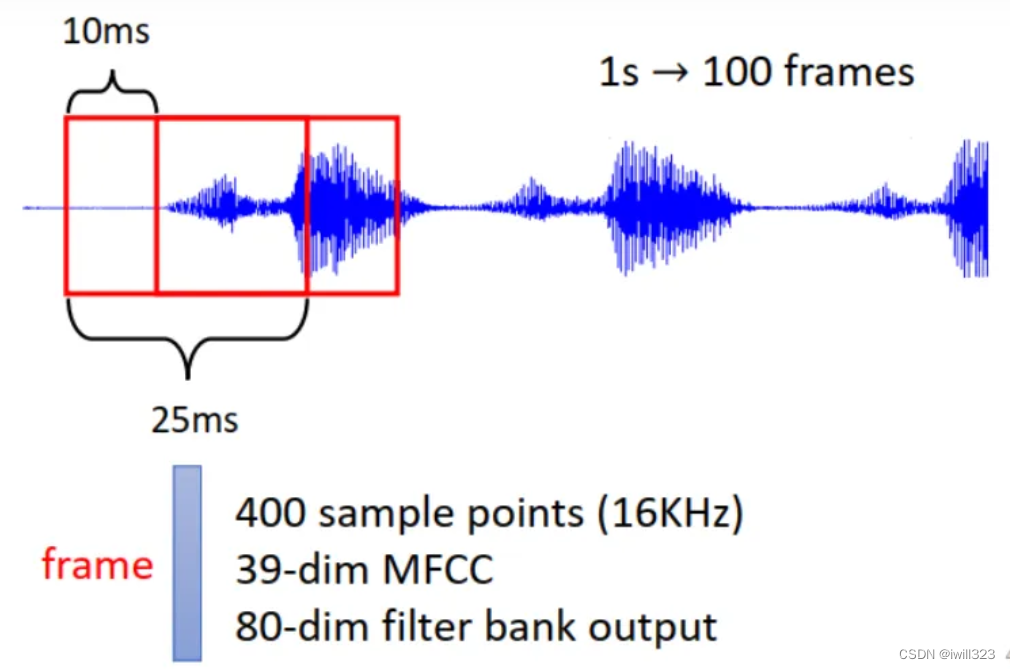
��һ������Ѷ��ȡһ����Χ,�����Χ����һ��Window,�����Window�e�����Ѷ������һ������,��������ͽ���һ��Frame,ͨ�����Window�ij�����25ms���������ƶ� 10ms,�����ڵ���������һ���µ�frame������ 1s �������� 100 ��������
ͼ
�罻�������һ�� Graph(ͼ����),���е�ÿһ���ڵ�(�û�)����������������ʾ����,��� Graph ���� vector set��

��ע�������Ƶ����
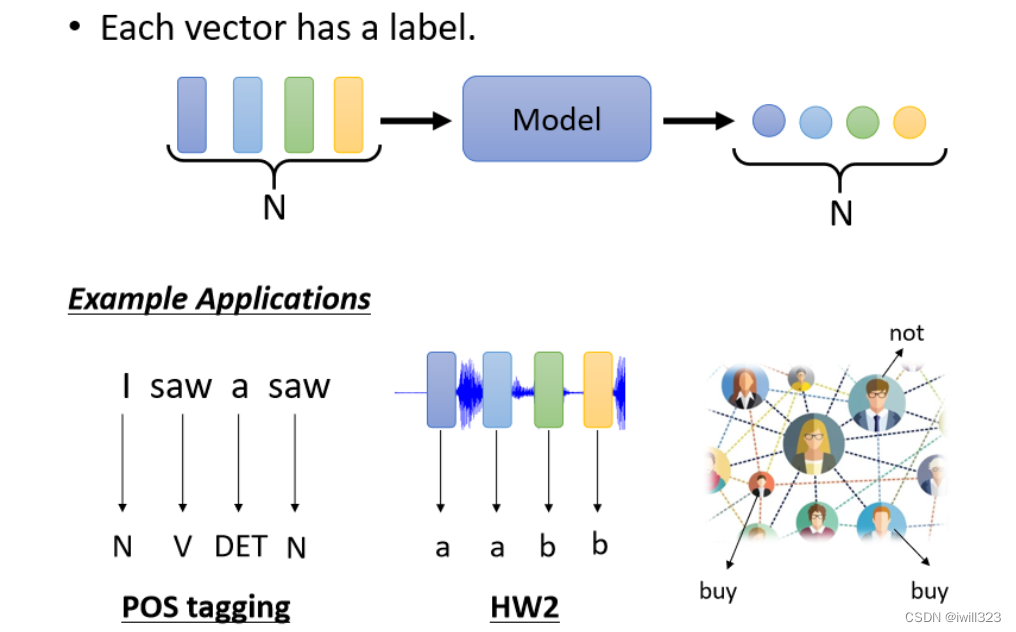
������г���������������ͬ
ÿ��������������Ӧһ�������ǩ,���������������һ����������Ԥ��ÿ�����ʵĴ���,Ԥ��ÿ������������,Ԥ��ij���˻�Ṻ����Ʒ��
������г���Ϊ1
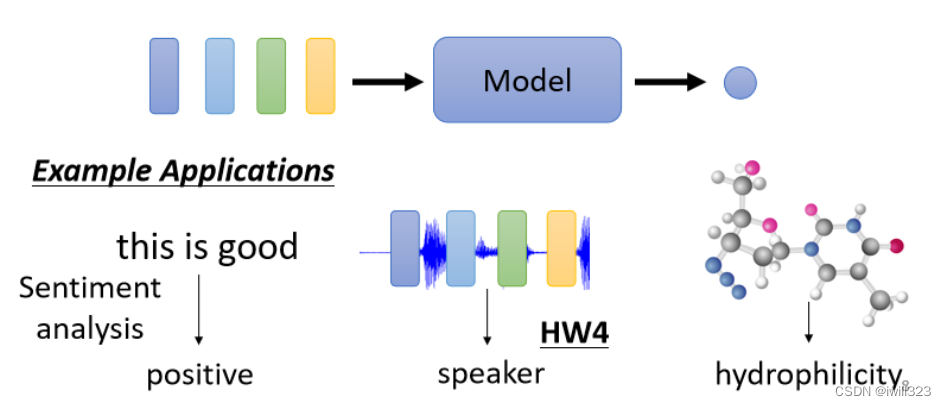
�������ɸ�����,���ֻ���һ����ǩ�����������з���,Ԥ��һ������������,Ԥ��һ�����ӵ����ʡ�
ģ�;���������г���
��֪�����������,ȫ���ɻ����Լ��������������,�����������ʶ����seq2seq����

Self-attention ԭ��
�����������г��ȵ����Ҳ�� Sequence Labeling,Ҫ��Sequence�����ÿһ���������һ��Label��
ģ����Ҫ����Sequence��ÿ��������������,���ܸ�����ȷ��label�����ÿ������һ��window,�����Ϳ�����ģ�Ϳ���window �ڵ���������Ѷ�������ijһ�������ǿ���һ��window�Ϳ��Խ����,����Ҫ����һ����Sequence���ܹ����,��Ҫ��Window����һ��,��ôwindow�ͻ��г��ж�,���ܾ�Ҫ���ǵ����window,�����ᵼ��FC�IJ�������,�����ܵ���over-fitting��

Self-Attention(����dz��ɫ���ο�)���һ����Sequence����Ѷ,�м�����������͵õ������������,���Ƕ��ǿ���һ����Sequence�Ժ�ŵõ���,�����������ͨ��ȫ���Ӳ������ǩ��
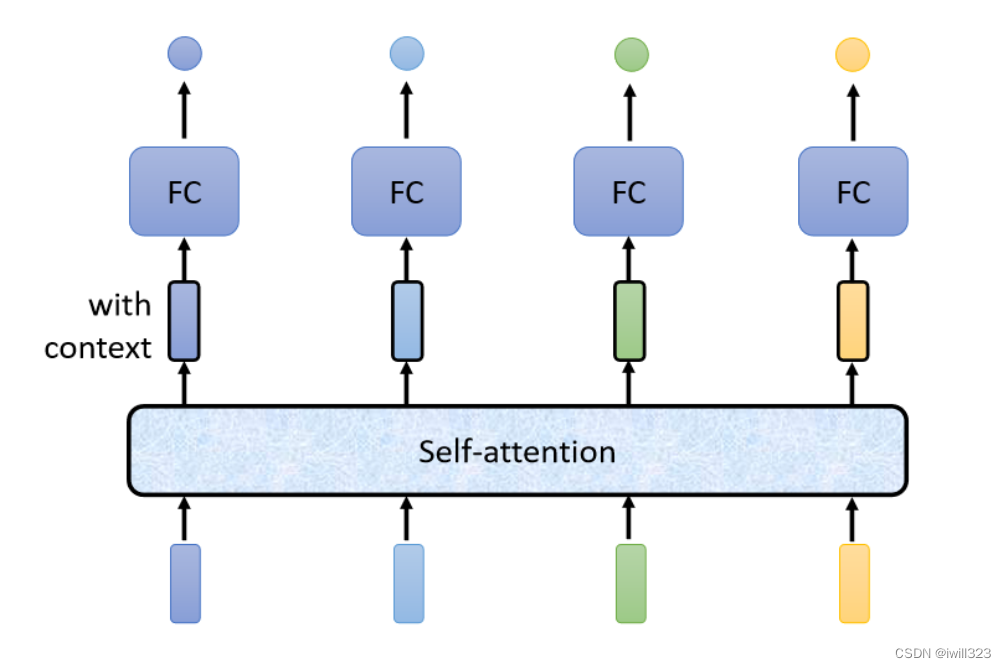
����fc�����Self-Attention����ʹ�á����� self-attention �Ĺ����Ǵ������� sequence ����Ѷ,��FC ���Ǵ���ijһ��λ�õ���Ѷ,��fc��ʹ��Self-Attention,�ܹ�������Sequence��Ѷ�ٴ���һ�Ρ�
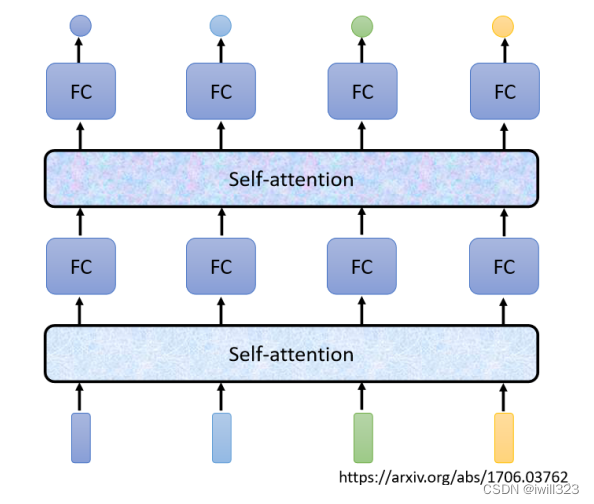
�й�Self-Attention,��֪������ص�����,���ǡ�Attention is all you need��?
self-attentionģ�͵��ڲ�ʵ��
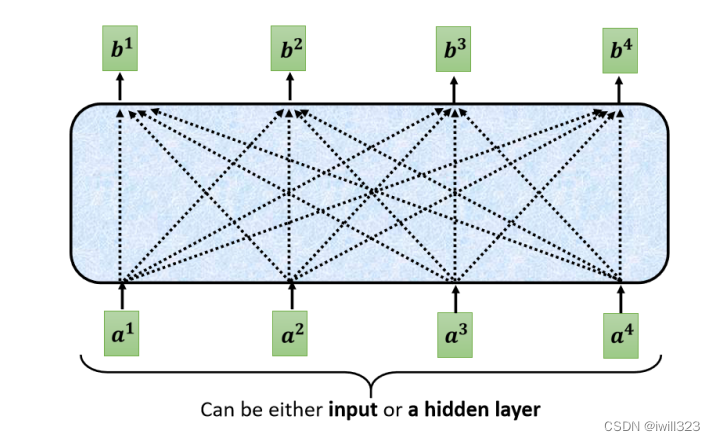
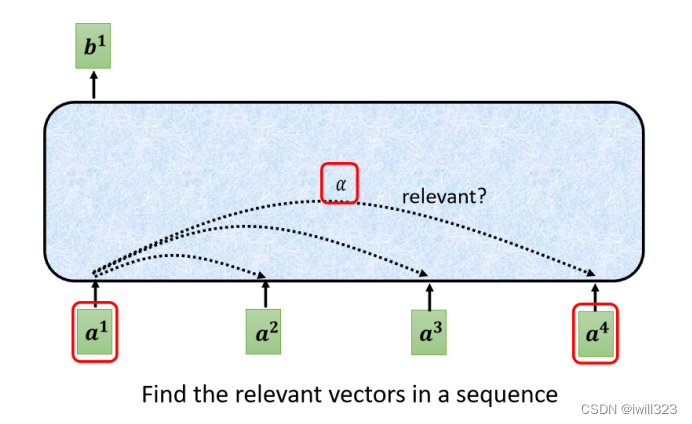
���b1,������ a1~a4 ����Ѷ,Ҳ�������������sequence�Ų��������ġ���ô b1 ����ο��� a1~a4 ����Ѷ����?Ѱ�� a �� a1 ֮�������� ��,Ҳ������� a (����a1�Լ�)�Դ��� a1 ��Ӱ��̶�,Ӱ��̶ȴ�ľͶ�ǵ���Ѷ��
����Լ���
����������е���� additive���ַ���,��Ҫ���۵�������������������������ֱ�˲�ͬ�ľ���,�õ�һ���µ�����,������������������������� ����
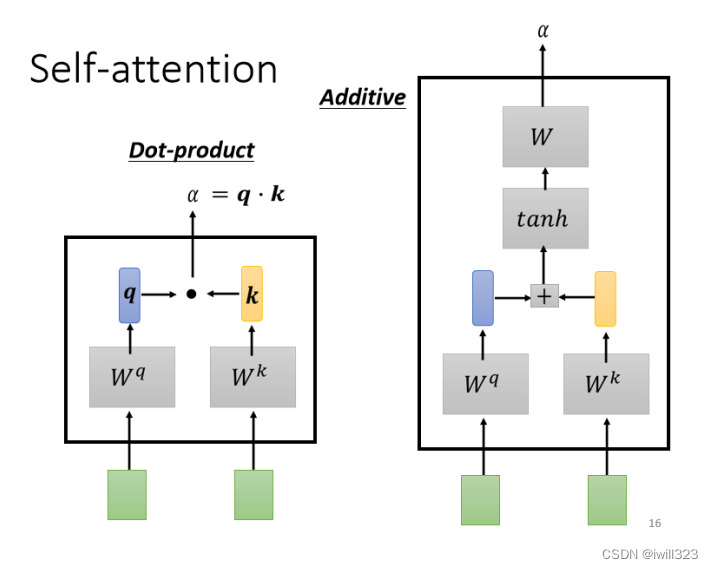
���:ͨ������?ai?���?qi?(query) ��?ki?(key),qi?�� sequence �����е�?ki?�����,�õ�?��?,����ͼ��ʾ��query�Dz�ѯ����˼,�������� a �� a1������ԡ�?��?Ҳ����Ϊ attention score��ע��:?q1?Ҳ���Լ���?k1?���,����Ҫ����a1������ a �������,��Ҫ�����Լ����Լ�������ԡ�?
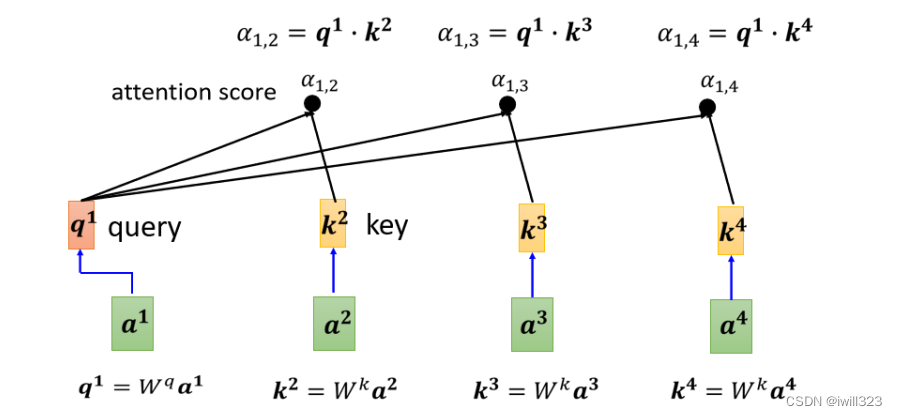
?��?�پ��� softmax ,�õ���һ���Ľ��?����?��softmaxҲ���Ի��������� activation function

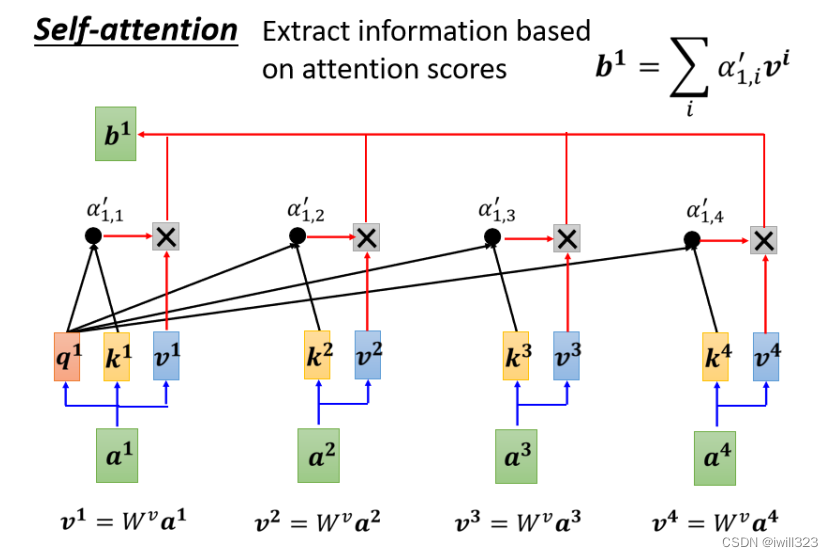
����self-attention���
ÿ�� a ����W �����γ����� v,Ȼ���ø��� v �˶�Ӧ�� ���� ,�ٰѽ���Ӻ��������� b1 �ˡ�ijһ�������õ���attention scoreԽ��,����˵���a1��a2�Ĺ����Ժ�ǿ,�õ��Ħ���ֵ�ܴ�,��ô������Ȩƽ���Ժ�,�õ���b1��ֵ,�Ϳ��ܻ�ȽϽӽ�v2��
self-attention������̾��ǻ��� ���� ��ȡ��Ѷ,˭�� ���� Խ��,˭�� v �Ͷ���� b1 ��Ӱ�����
?
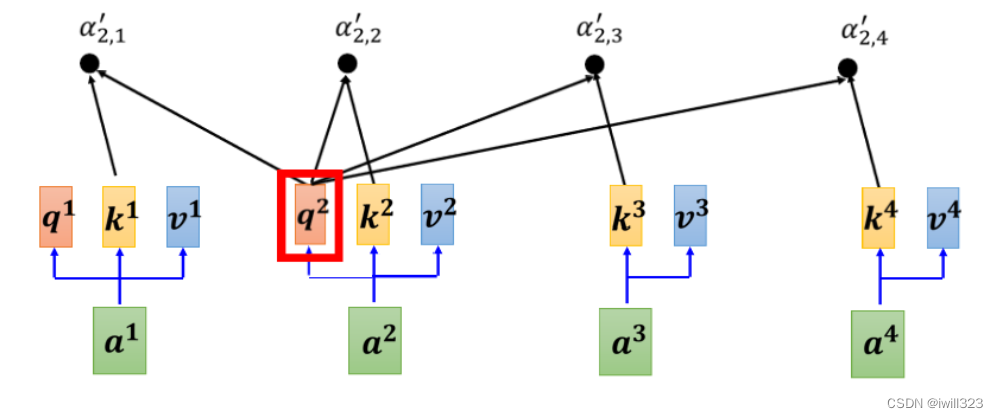
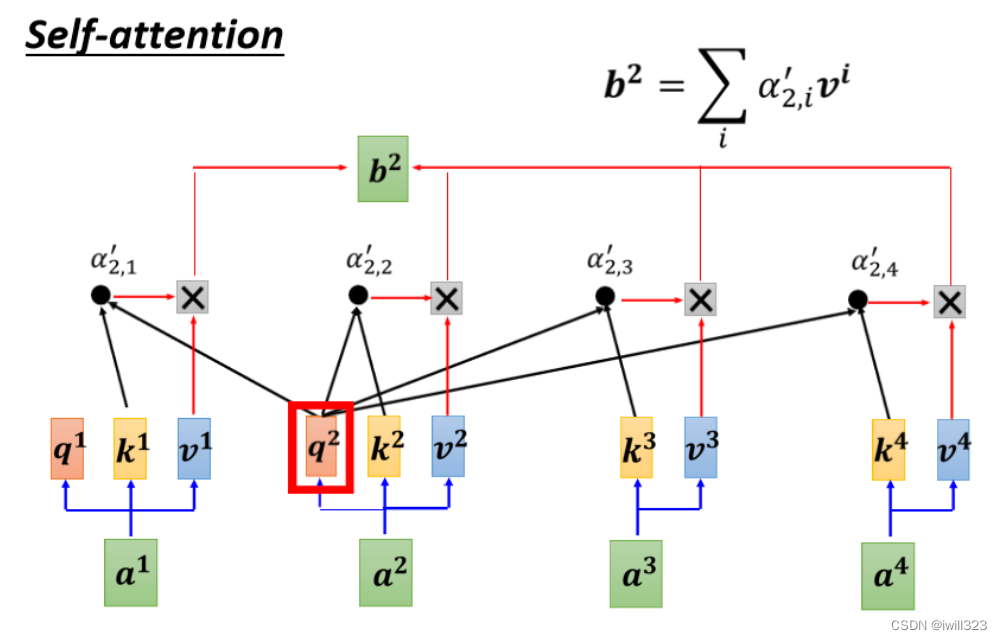
�����ֻ�����һ�� b �Ĺ��̡���� b2 �Ĺ��̺���� b1 ��һ����,ֻ�����ı��� query���ѡ�b��Ȼ���ǵ�����sequence����Ѷ,���Dz�ͬ b �ļ���û���Ⱥ�˳��,����ƽ�м��������
?
����ʵ��
���涼����Ե��� b �������ô�����,��Զ�� b ���,��ʵ������δ洢�����ƽ�м�����?
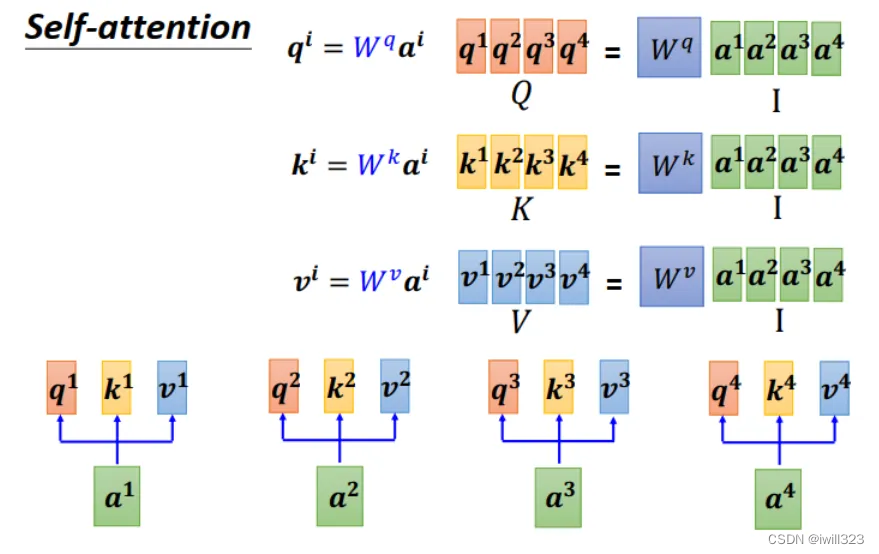
ǰ���н������� W ����,�����������ǹ�������,��Ҫ��ѧ�����ġ����������������һ���γ� I ����,I �����벻ͬ�� W ������˺�,�õ�Q��K��V��������
?
�� k����ת��һ��,��ȥ�� q���������,�����ó��� �� �Ż���һ����ֵ,������������
�ȿ�����ĸ�ʽ��,ת�ú�� k����:1x n;q����:n x1,����������˺�� �� :1x1��
�ٿ��ұ��ĸ�ʽ��,ת�ú�� K����:4x n;q����:n x1,����������˺�� �� ��ɾ���:4x1��
?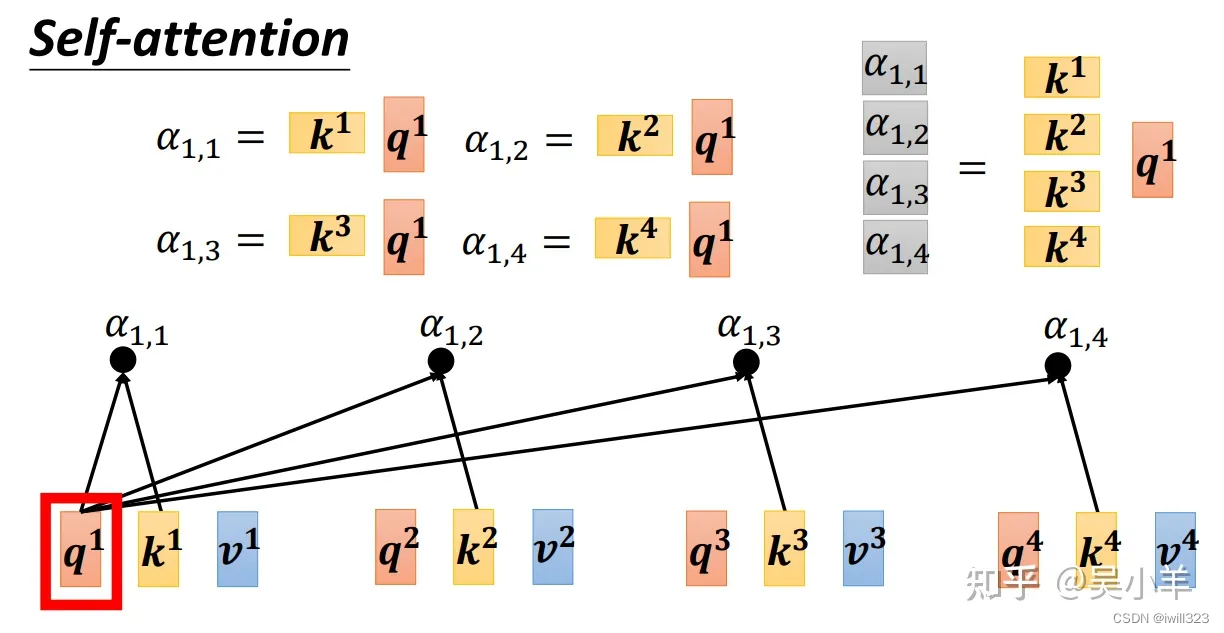
����ֻ�漰 q1,��û��q2~q3,���ڰ������� q �ӽ���,�����ͼ��ʽ�ӡ�
��attention �ķ������Կ����������������ˡ���ת�ú�� K����,ȥ���� Q����,�õ�һ������ �� �� A����,A����softmax�õ� A�� ����ÿһ��column �� softmax,��ÿһ�� column �e���ֵ����� 1������� softmax����Ψһ��ѡ��,��ȫ����ѡ�������IJ���,����˵ ReLU ֮���,�õ��Ľ��Ҳ����Ƚϲ�
ת�ú�� K����:4x n;Q����:n x4;���Եõ��� A����:4x4��
?
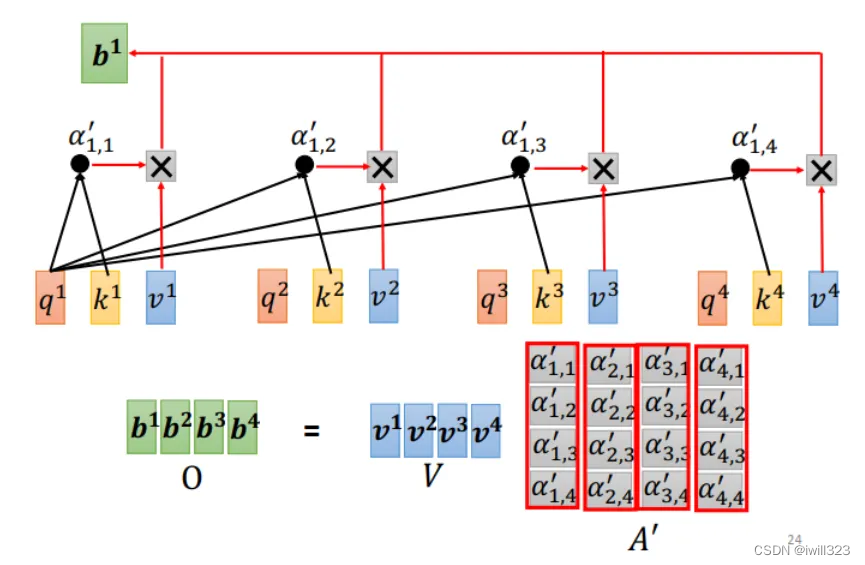
Ȼ���� A�� ������� V����,�õ�������� O����!
V����:n x4;A�� ����:4x4;���Եõ��� O����:n x4
?
��
�����漸��ͼ�ܽ���,������ͼ�����ľ��ǹ���

��Ҫע�����:
(1)Self-attention ������ I,����� O
(2)?Wq?,?Wk?,?Wv?��Ҫѧϰ�IJ���,�����IJ������������˞��趨�õ�,����Ҫ�� training data �ҳ���,�� I �� O �������� Self-attention
(3)A' ���� Attention Matrix,�����������������IJ���,���� sequence ����Ϊ L,���е� vector ά��Ϊ d,��ô��Ҫ���� L x d x L �Ρ�
Multi-head Self-attention
��ʱ��Ҫ���Ƕ��������,Ҫ�ж�� q,��ͬ�� q ������Ҳ�ͬ���������ԡ���ͼΪ 2 heads �����,?(q,k,v)?��һ���ɶ���,��һ��ķ���һ����,�ڶ���ķ���һ���㡣����Ա����,���Բ���Ҳ������,ԭ��ֻ��Ҫ���� W����,������Ҫ���� W������ͼ�����һ������ԵĹ���
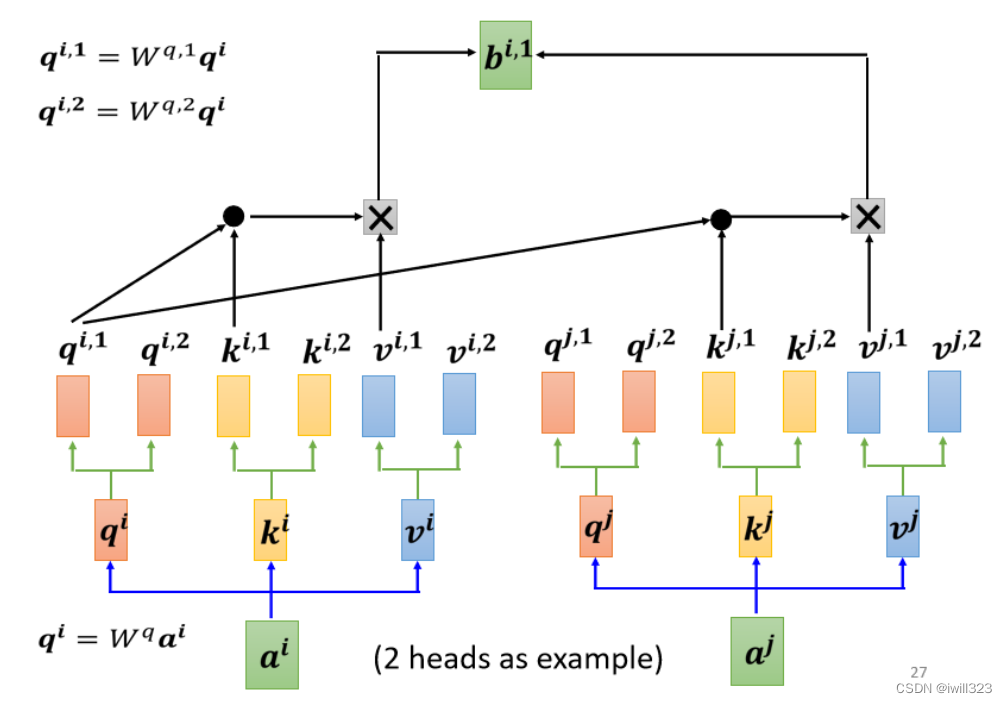
��ͼ�Ǽ���ڶ�������ԵĹ���
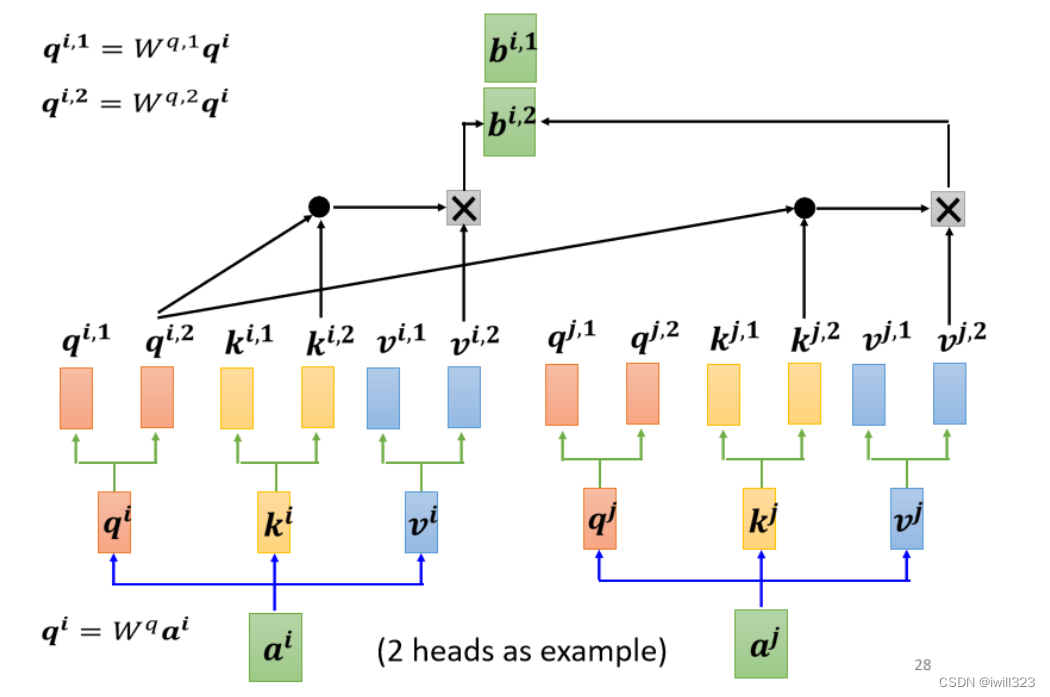
�뵥���� self attention ���,Multi-head Self-attention ������һ��:�ɶ�������ϵõ�һ����������ոյõ������� b���һ������,�ٳ��Ծ���,���һ�� bi,Ŀ�ľ��ǽ���ͬ����������������һ��,��Ϊһ������,��Ϊ a1 ����� b1��
The Illustrated Transformer �C Jay Alammar �C Visualizing machine learning one concept at a time.һ���о���һ�� 2 heads ������,չʾ��Ӧ�� Multi-head Self-attention ʱ���ǵĶ��������

λ�ñ���Positional Encoding
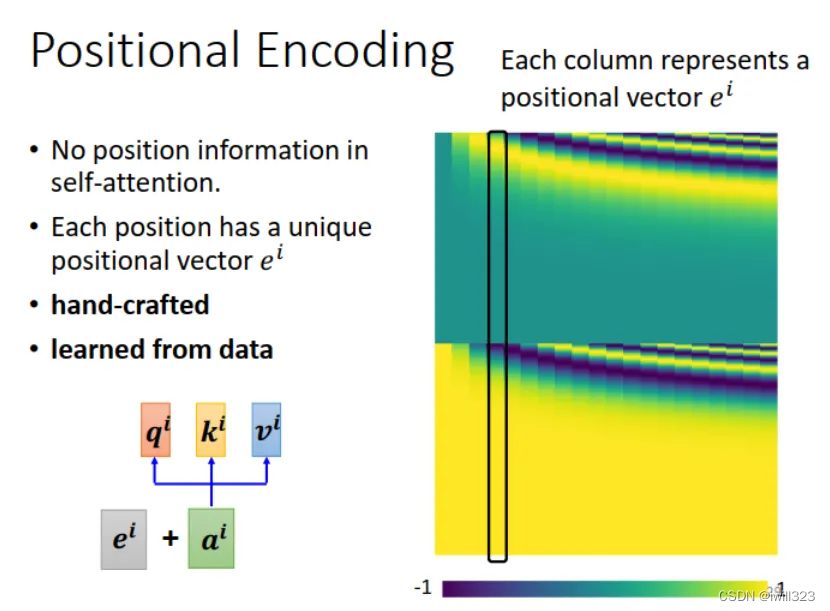
self-attention û�п���λ����Ϣ,ֻ���㻥����ԡ�����ij���ִ�,�������ھ��ס����С���β, self-attention �ļ���������һ���ġ�����,��ʱ Sequence �е�λ����Ϣ����ͦ��Ҫ�ġ�
�������:��ÿһ��λ���趨һ��λ������ ei,��λ����Ϣ?ei?���뵽����?ai?��,��� ei ��������Ϊ�趨������,Ҳ������ͨ��ѧϰ���ɵġ�����ͼ�еĺ�ɫ������,ÿһ�� column �ʹ���һ�� e ��
Self-attention ��Ӧ��
NLP
Self-attention �� NLP �й㷺Ӧ��,�綦�������� Transformer, BERT ��ģ�ͼܹ��ж�ʹ���� Self-attention��
����ʶ��
����������ʱ��Ҳ������ Self-attention,������� Self-attention��һЩСС�ĸĶ�����ΪҪ��һ���仰��ʾ��һ�������Ļ�,�����������ܻ�dz�����ÿһ������������ 10 ms �ij���,1 ��犵�����Ѷ�ž��� 100������,5 ��犵�����Ѷ�ž� 500 �������ˡ������������������ L������,��ôattention matrix��С����L*L,������� attention matrix��Ҫ�� L ���� L �ε��ڻ�,������ѵ����
�Ľ�:Truncated Self-attention,������Ѷ��ʱ��,����һ���仰,ֻ��һ��С�ķ�Χ,�������Ʒ�Χ�ڵ�����ԡ���ͼ��ʾ,����ȫ�� sequence �ϼ��� attention score,����������һ����Χ�ڼ��㡣�����ΧӦ��Ҫ��������趨�ġ��е�����CNN�и������˼��

ͼ����
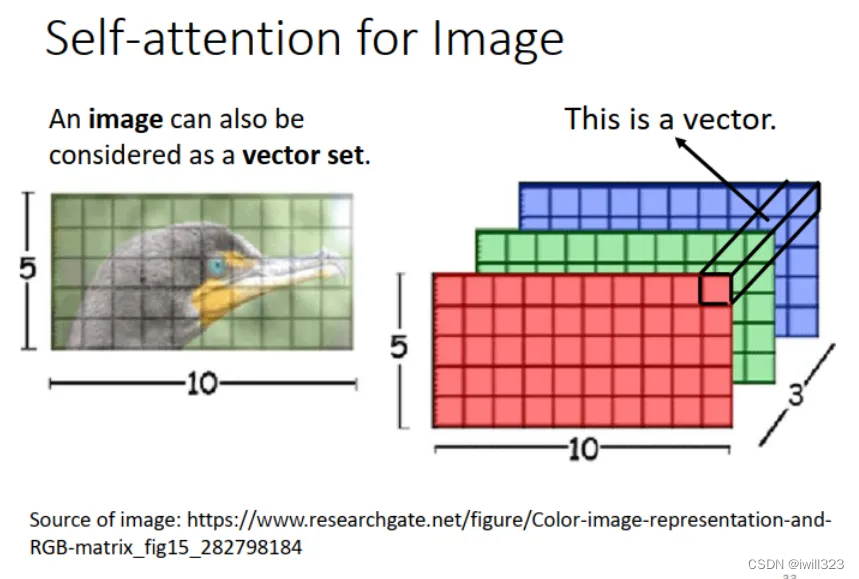
ͼƬҲ���Կ����ɲ�ͬ������ɵ�����������ͼ��ʾ,��ÿһ��λ�õ�����(W,H,D)����һ����ά������,һ��ͼ����� vector set,������ Self-attention ������һ��ͼƬ
?
graph
Graph �������˞����ijЩ domain knowledge ��������,�߶μ���ʾ�ڵ�֮��������,֪����Щ node ֮������������,����graph�Ѿ�֪������֮��������,ʹ��self-attention ʱ����Ҫ��ȥѧ�����,����Attention Matrix �����ʱ��,ֻ������ edge ������ node �ͺá�Self-attention���� Graph �����ʱ��,��ʵ����һ�� Graph Neural Network,Ҳ����һ�� GNN
?

Self-attention ����������ĶԱ�
self-attention �� CNN
CNN ���Կ��ɼ�� self-attention��CNN ����ֻ�������Ұ�е�����Ե�self-attention��
��һ�����ص㵱��һ������,CNN ֻ�������Ұ��Χ�ڵ������,������������ĵ��������ֻ�������ڵ�����,����Ұ�Ĵ�С����Ϊ�趨,����ͼ��ʾ��Self-attention ��� attention score �Ĺ���,���ǵIJ���һ������Ұ����Ϣ,��������ͼƬ����Ϣ,�����Լ�����˵,����� pixel ������,��Щ��������ص�,�൱�ڻ����Լ�ѧϰ��ȷ������Ұ�ķ�Χ��С���� Self-attention �ĽǶ�����,CNN���ڸ���Ұ���������� sequence �� Self-attention�����, CNN ģ���Ǽ�� Self-attention��

���������֤��,ֻҪ�趨���ʵIJ���,self-attention ���������� CNN һģһ�������顣Self-attention ֻҪ��ijЩ���,���ͻ��� CNN
?
?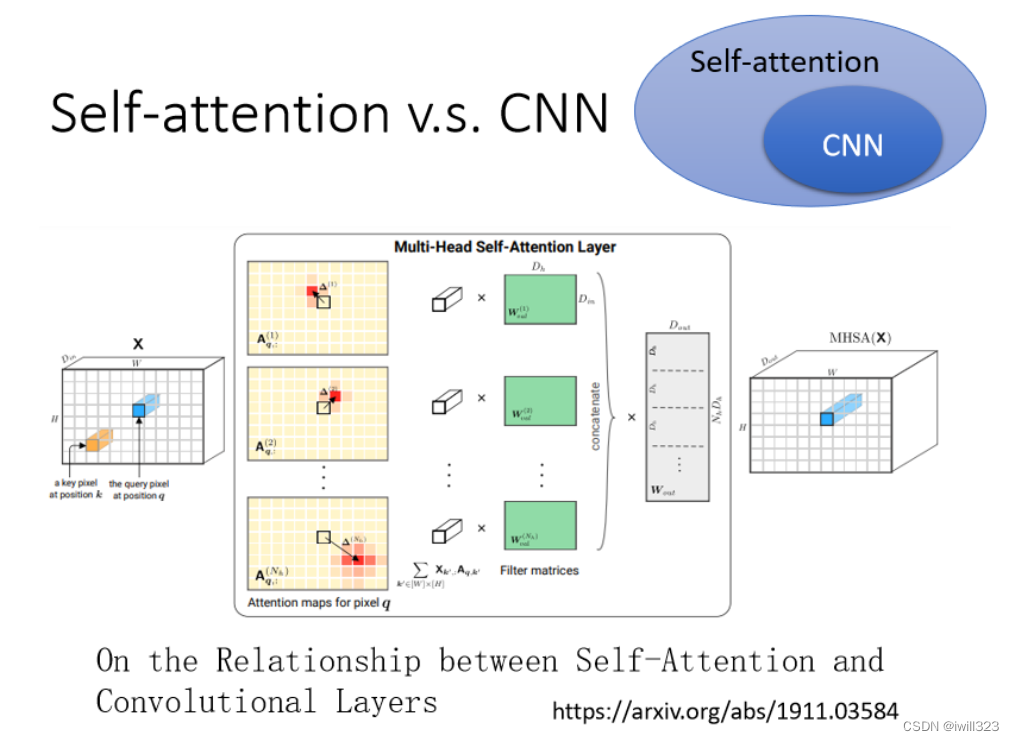
���� self attention�Ǹ� flexible �� CNN,�� CNN ���������Ƶ� Self-attention����ͼ�ò�ͬ�� data ����ѵ�� CNN �� Self-attention,������ѵ�����϶���,������ȷ�ʡ����Կ�������������ʱ,CNN�ı��ֱ� self-attention��;������������ʱ,Ч�����෴��Ϊʲô��?��Ϊ self-attention �ĵ��Ը���,����������ʱ,���������ռ�Ƚϴ�,������������ʱ����overfitting��

self-attention �� RNN
Recurrent Neural Network�� Self-attention ����������ʵҲ�dz���,���ǵ����붼��һ�� vector
sequence
����:
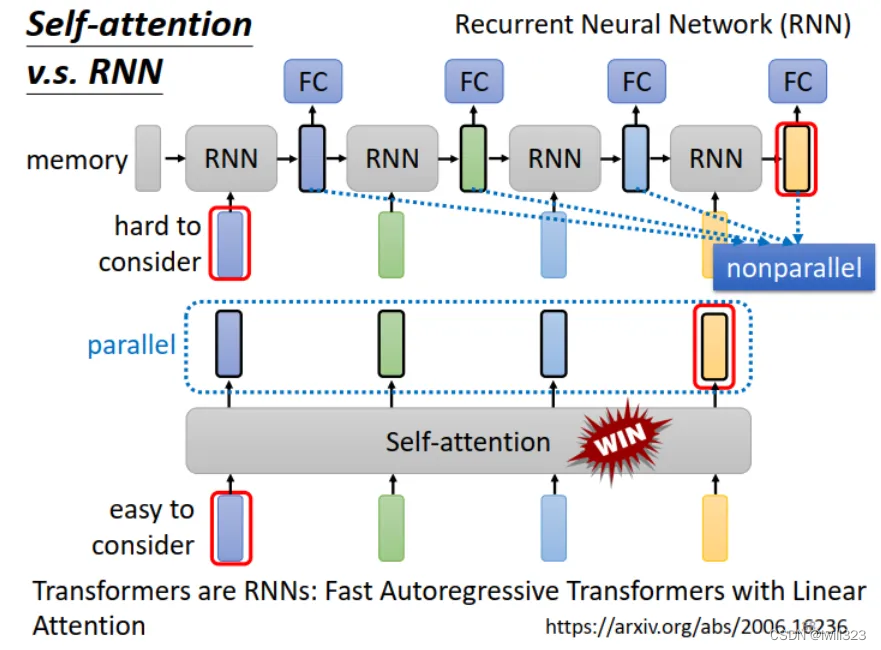
(1)����ͼ��ʾ,���RNN ���һ������Ҫ��ϵ��һ������,�Ƚ���,��Ҫ�ѵ�һ�����������һֱ������ memory �С������ self-attention ��˵,���� Sequence ������λ�õ�������������ϵ,���벻�����⡣
(2)RNN ǰ����������Ϊ���������,���Ҫ���μ���,�����д����� self-attention �����ƽ�Юa����,������Ҫ��˭��������Ű������������,���Բ��м���,�����ٶȸ�����
����RNN�Ѿ�������̭��,���˾��RNN����ij���self-attention�ܹ���
self-attention ����
Self-attention ������������������dz��ش�,�������ƽ��performance �� speed �Ǹ���Ҫ�����⡣���Ҵ�����������ٶ�,�����кܶ��ʽ�����µ� xxformer,�ٶȻ��ԭ����Transformer ��,���� performance ���;��������� performance������������ԭ���� Transformer��performance ��һ��,�����ٶȻ�ȽϿ졣���Կ�һ��Efficient Transformers: A Survey ��ƪ paper
?

?
?
�ο�: