"横纵式"教学法
在本教程中,我们采用了专门为读者设计的创新性的“横纵式”教学法进行深度学习建模介绍,如 图4 所示。
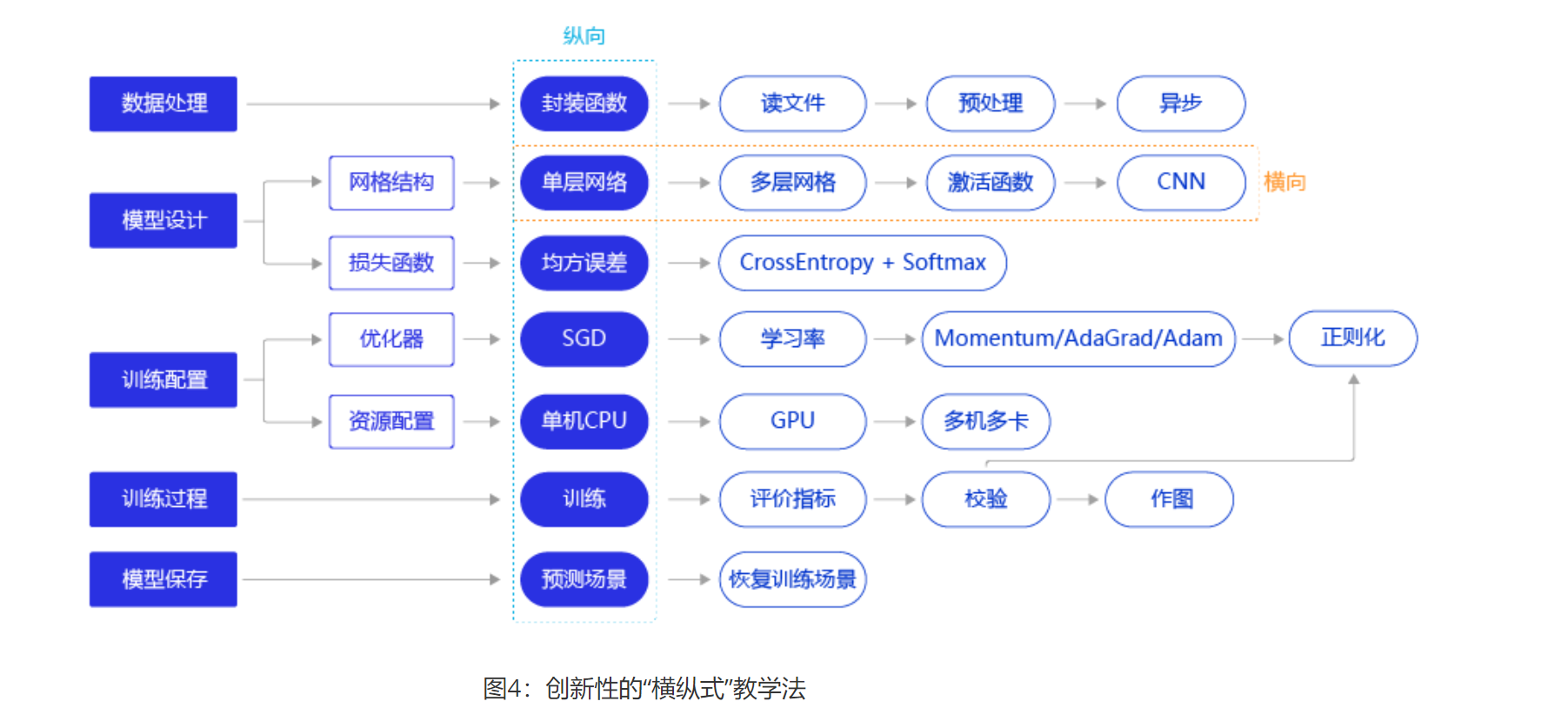
在“横纵式”教学法中,纵向概要介绍模型的基本代码结构和极简实现方案。横向深入探讨构建模型的每个环节中,更优但相对复杂的实现方案。例如在模型设计环节,除了在极简版本使用的单层神经网络(与房价预测模型一样)外,还可以尝试更复杂的网络结构,如多层神经网络、加入非线性的激活函数,甚至专门针对视觉任务优化的卷积神经网络。
这种“横纵式”教学法的设计思路尤其适用于深度学习的初学者,具有如下两点优势:
- 帮助读者轻松掌握深度学习内容:采用这种方式设计教学案例,读者在学习过程中接收到的信息是线性增长的,在难度上不会有阶跃式的提高。
- 模拟真实建模的实战体验:先使用熟悉的模型构建一个可用但不够出色的基础版本(Baseline),再逐渐分析每个建模环节可优化的点,一点点的提升优化效果,让读者获得真实建模的实战体验。
相信在本章结束时,大家将会对深入实践深度学习建模有一个更全面的认识,接下来我们将逐步学习建模的方法。
一、加载类库
在数据处理前,首先要加载飞桨平台与“手写数字识别”模型相关的类库,实现方法如下。
#加载飞桨和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import numpy as np
import matplotlib.pyplot as plt
二、数据处理
飞桨提供了多个封装好的数据集API,涵盖计算机视觉、自然语言处理、推荐系统等多个领域,帮助读者快速完成深度学习任务。如在手写数字识别任务中,通过paddle.vision.datasets.MNIST可以直接获取处理好的MNIST训练集、测试集,飞桨API支持如下常见的学术数据集:
- mnist
- cifar
- Conll05
- imdb
- imikolov
- movielens
- sentiment
- uci_housing
- wmt14
- wmt16
通过paddle.vision.datasets.MNIST API设置数据读取器,代码如下所示。
飞桨将维度是28×28的手写数字图像转成向量形式存储,因此使用飞桨数据加载器读取到的手写数字图像是长度为784(28×28)的向量。
# 设置数据读取器,API自动读取MNIST数据训练集
train_dataset = paddle.vision.datasets.MNIST(mode='train')
# 通过如下代码读取任意一个数据内容,观察打印结果。
train_data0 = np.array(train_dataset[0][0])
train_label_0 = np.array(train_dataset[0][1])
# 显示第一batch的第一个图像
import matplotlib.pyplot as plt
plt.figure("Image") # 图像窗口名称
plt.figure(figsize=(2,2))
# Colormap是MATLAB里面用来设定和获取当前色图的函数,binary为二值图
plt.imshow(train_data0, cmap=plt.cm.binary)
plt.axis('on') # 关掉坐标轴为 off
plt.title('image') # 图像题目
plt.show()
print("图像数据形状和对应数据为:", train_data0.shape)
print("图像标签形状和对应数据为:", train_label_0.shape, train_label_0)
print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(train_label_0))

飞桨API的使用方法
熟练掌握飞桨API的使用方法,是使用飞桨完成各类深度学习任务的基础,也是开发者必须掌握的技能。
飞桨API文档获取方式及目录结构
登录“飞桨官网->文档->API文档”,可以获取飞桨API文档。在飞桨最新的版本中,对API做了许多优化,目录结构与说明,如 图3 所示。
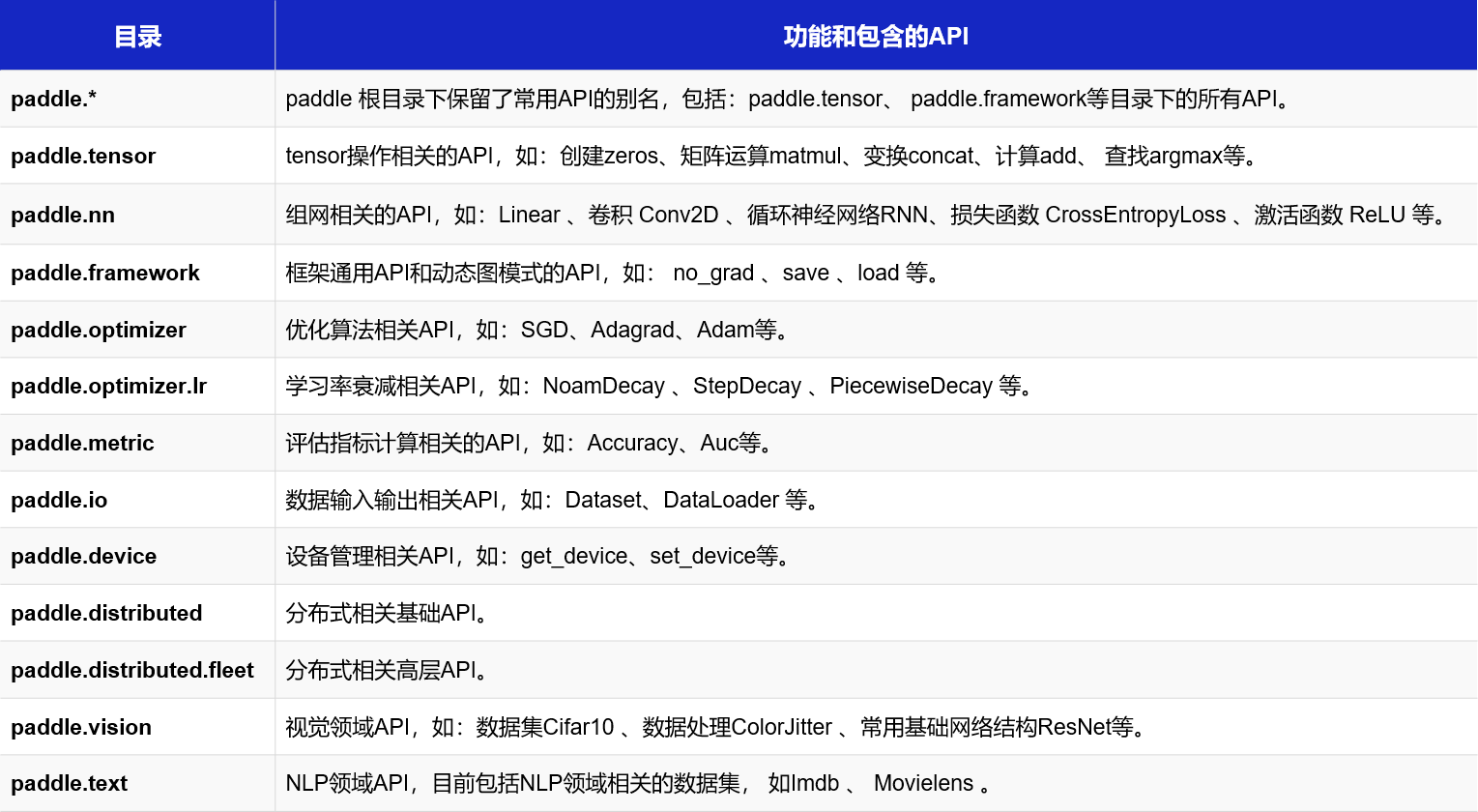
图3:飞桨API文档目录
三、模型设计
**在房价预测深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。**在手写数字识别中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28×28)数据,输出为1维数据,如 图5 所示。
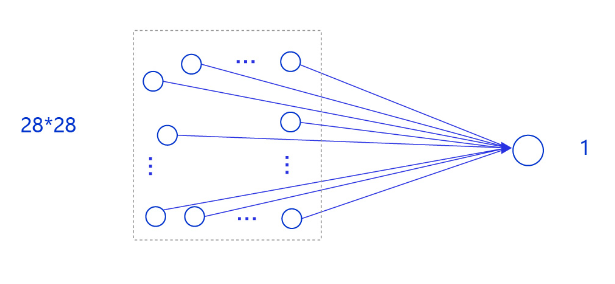
图5:手写数字识别网络模型
输入像素的位置排布信息对理解图像内容非常重要(如将原始尺寸为28×28图像的像素按照7×112的尺寸排布,那么其中的数字将不可识别),因此网络的输入设计为28×28的尺寸,而不是1×784,以便于模型能够正确处理像素之间的空间信息。
说明:
**事实上,采用只有一层的简单网络(对输入求加权和)时并没有处理位置关系信息,因此可以猜测出此模型的预测效果可能有限。**在后续优化环节介绍的卷积神经网络则更好的考虑了这种位置关系信息,模型的预测效果也会有显著提升。
下面以类的方式组建手写数字识别的网络,实现方法如下所示。
# 定义mnist数据识别网络结构,同房价预测网络
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一层全连接层,输出维度是1
self.fc = paddle.nn.Linear(in_features=784, out_features=1)
# 定义网络结构的前向计算过程
def forward(self, inputs):
outputs = self.fc(inputs)
return outputs
四、训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001),实现方法如下所示。
# 声明网络结构
model = MNIST()
def train(model):
# 启动训练模式
model.train()
# 加载训练集 batch_size 设为 16
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=16,
shuffle=True)
# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
五、训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
# 图像归一化函数,将数据范围为[0, 255]的图像归一化到[0, 1]
def norm_img(img):
# 验证传入数据格式是否正确,img的shape为[batch_size, 28, 28]
assert len(img.shape) == 3
batch_size, img_h, img_w = img.shape[0], img.shape[1], img.shape[2]
# 归一化图像数据
img = img / 255
# 将图像形式reshape为[batch_size, 784]
img = paddle.reshape(img, [batch_size, img_h*img_w])
return img
import paddle
# 确保从paddle.vision.datasets.MNIST中加载的图像数据是np.ndarray类型
# 设置加载图像的后端,必须为 pil 或者 cv2 。
paddle.vision.set_image_backend('cv2')
# 声明网络结构
model = MNIST()
def train(model):
# 启动训练模式
model.train()
# 加载训练集 batch_size 设为 16
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=16,
shuffle=True)
# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
images = norm_img(data[0]).astype('float32') # shape=[16, 28, 28] =====> shape=[16,784]
labels = data[1].astype('float32') # shape=[16, 1]
#前向计算的过程
predicts = model(images)
# 计算损失
loss = F.square_error_cost(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了1000批次的数据,打印下当前Loss的情况
if batch_id % 1000 == 0:
print("epoch_id: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
train(model)
# 能够获取模型中的所有参数,包括可学习参数和不可学习参数,其返回值是一个有序字典 OrderedDict。
paddle.save(model.state_dict(), './mnist.pdparams')
另外,从训练过程中损失所发生的变化可以发现,**虽然损失整体上在降低,但到训练的最后一轮,损失函数值依然较高。可以猜测手写数字识别完全复用房价预测的代码,训练效果并不好。**接下来我们通过模型测试,获取模型训练的真实效果。
六、模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
- 声明实例
- 加载模型:加载训练过程中保存的模型参数,
- 灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
- 获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从’./work/example_0.png’文件中读取样例图片,并进行归一化处理。
# 导入图像读取第三方库
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
img_path = './work/example_0.jpg'
# 读取原始图像并显示
im = Image.open(img_path)
plt.imshow(im)
plt.show()
# 将原始图像转为灰度图
im = im.convert('L')
print('原始图像shape: ', np.array(im).shape)
# 使用Image.ANTIALIAS(高质量)方式采样原始图片
im = im.resize((28, 28), Image.ANTIALIAS)
plt.imshow(im)
plt.show()
print("采样后图片shape: ", np.array(im).shape)
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
# print(np.array(im))
im = im.resize((28, 28), Image.ANTIALIAS)
# reshape(1,-1)转化成1行
im = np.array(im).reshape(1, -1).astype(np.float32)
# 图像归一化,保持和数据集的数据范围一致
im = 1 - im / 255
return im
# 定义预测过程
model = MNIST()
params_file_path = 'mnist.pdparams'
img_path = './work/example_0.jpg'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入数据
model.eval()
tensor_img = load_image(img_path)
result = model(paddle.to_tensor(tensor_img))
print('result',result)
# 预测输出取整,即为预测的数字,打印结果
print("本次预测的数字是", result.numpy().astype('int32'))
从打印结果来看,模型预测出的数字是与实际输出的图片的数字不一致。这里只是验证了一个样本的情况,如果我们尝试更多的样本,可发现许多数字图片识别结果是错误的。因此完全复用房价预测的实验并不适用于手写数字识别任务!
接下来我们会对手写数字识别实验模型进行逐一改进,直到获得令人满意的结果。