目录
1.介绍深度估计
深度估计目的的从一张2D图像中获取每个点距离拍摄源的位置远近(通常用颜色的深浅可视化)。

?常用的数据集
室内数据集NYU-V2-Depth, 包含464个场景,120k个尺寸为?? ? 480*640RGB图像与深度图对。249个训练? 场景,215测试场景。距离拍摄源的距离? 为[0 - 10] m。
室外数据集kitti 包含61个场景,32个场景 用于训练,29个场景697张图片用于测试。距离拍摄源的距离为[0 - 80]m。
2.深度值的预处理
本文以NYU为例,在我们使用PIL读取的image and depth 中,用OpenCV读取需要转化BGR to RGB,我们首先需要对它做一下标准化处理,PIL to Tensor 图像的像素值会分布在 0 - 1之间(opencv 读取的结果也需要转化为tensor? 在torchvision.transforms包里有封装好的py函数),这也是现在学习率普遍为1e-4的原因。有的文章还采用image的标准化处理,将 tensor值分布在 -1 - 1之间。
为了防止网络过拟合,通常对image进行处理(翻转,明暗,色调,大小)。
用OpenCV的包里测试一下
import albumentations as A
basic_transform = [
A.HorizontalFlip(),
A.RandomBrightnessContrast(),
A.RandomGamma(),
A.HueSaturationValue()
]
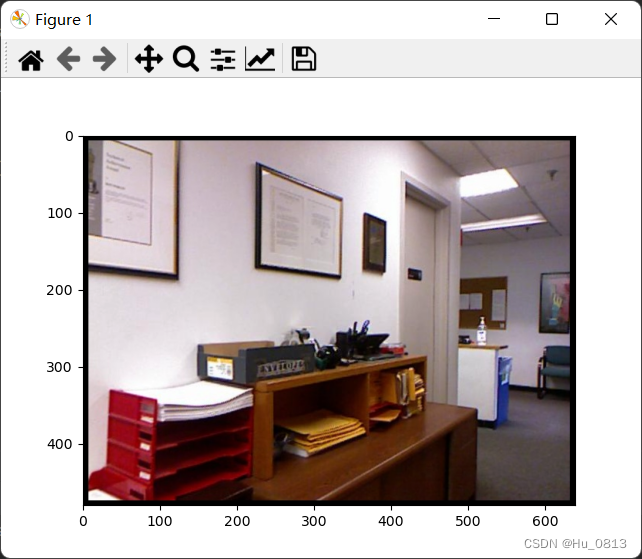
我们先用从cv2得到下面这张图像

import cv2
import matplotlib.pyplot as plt
image = cv2.imread(r"F:\Datasets\nyu_depth_v2\test\office\rgb_00008.jpg")
# image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.show()
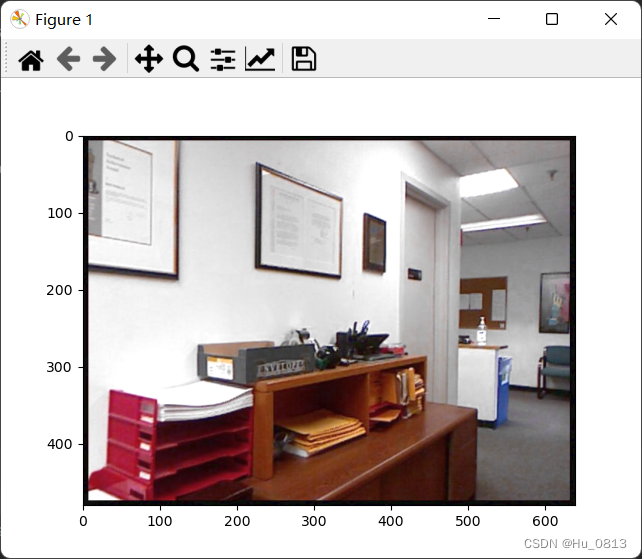
# image-BGR to RGB. Then augment of images and to tensor?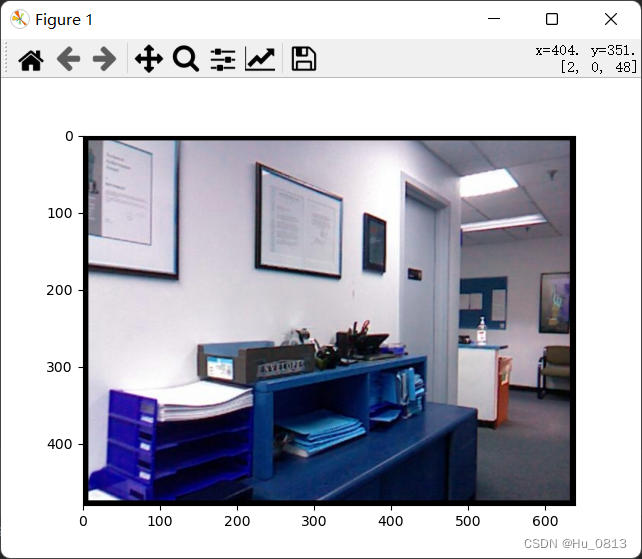
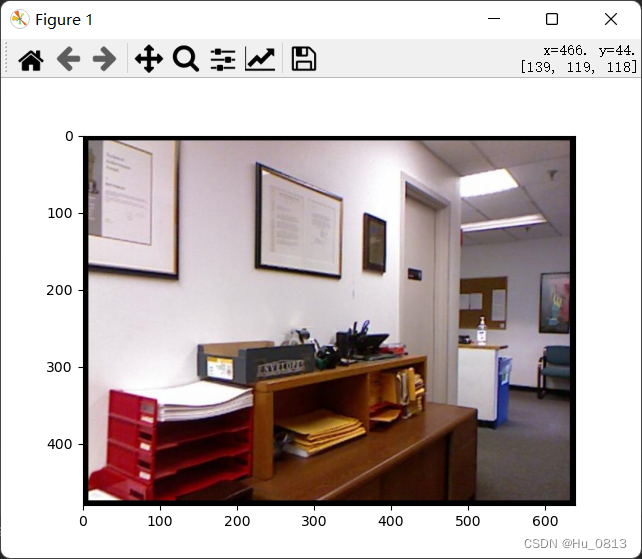
image = A.HorizontalFlip(p=1)(image=image)["image"]
plt.imshow(image)
plt.show()
# albumentations need (image = 'name of image') to convert (key-value)
3.train
训练过程都大同小异, contrary between predict of model and GT , lr的更改 需要在 for 循环里更改
input_RGB = batch['image']
depth_gt = batch['depth']
pred = model(input_RGB)
optimizer.zero_grad()
loss_d = criterion_d(pred, depth_gt)
loss_d.backward()4. 损失函数
这一部分的改变基本不大,大部分都是基于尺度不变损失进行微改的,也可以用L1,L2 hurb损失。
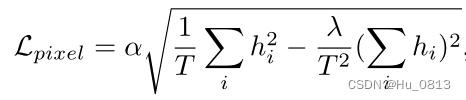
少数有使用 grad and normal 作为辅助损失让model 更加关注相关部分学习情况。
[1]使用了三种损失 L1+grad+normal。[2]使用了回归+尺度不变
5.可视化
很多文章都会放可视化的结果,毕竟在人的视觉感知里,带有色彩的图像远远比数据更加吸引注意力。在可视化中,需要注意的是,如果我们对图像进行了标准化处理,我们在可视化之前需要反标准化,并且乘以相应的距离(255),不然得到的结果可能有色彩的差距,毕竟 plt.show(cmp='jet')显示的只是相对差异。贴一下目前的sota BinsFormer。

6.评估准则

前三者是误差评估,Lower is better 最后一个是准确度评估 higher is better
对于准确性评估,只测量 GT 中的非零值,也就是我们首先需要用mask将预测值和真实值的非零值对应起来(避免分母为0 出现nan值),可以用逻辑与作为mask.
valid_mask = torch.logical_and(gt_depth > min_depth_eval, gt_depth < max_depth_eval) 比较 pred[valid_mask] 与 gt_depth[valid_mask] 避免nan值 Thresholded accuracy : thresh = torch.max((target / pred), (pred / target)) d1 = torch.sum(thresh < 1.25).float() / len(thresh) d2 = torch.sum(thresh < 1.25 ** 2).float() / len(thresh) d3 = torch.sum(thresh < 1.25 ** 3).float() / len(thresh) 误差值计算: diff = pred - target REL = torch.mean(torch.abs(diff) / target) RMSE = torch.sqrt(torch.mean(torch.pow(diff, 2))) log10 = torch.mean(torch.abs(torch.log10(pred) - torch.log10(target)))
Reference
1.Revisiting Single Image Depth Estimation Toward Higher Resolution Maps
3. BinsFormer: Revisiting Adaptive Bins for MDE