����
����ʶ���Ǽ������ֽ���ĵ�����Ƭ��������Դ���ա����Ⲣʶ��ɶ������ֵ�����,Ŀǰ�Ƚ��ܹ�ע������д����ʶ����д����ʶ����һ�����͵�ͼ���������,�Ѿ����㷺Ӧ���ڻ���ʶ����д��������ʶ�������,���������ҵ����ʱ��,�����˹���Ч�ʺ�������
�ڴ����� ͼ1 ��ʾ����д��������ļ�ͼ���������ʱ,����ʹ�û���MNIST���ݼ�����д����ʶ��ģ�͡�MNIST�����ѧϰ����������õij������ݼ�,����50 000��ѵ��������10 000������������

ͼ1:��д����ʶ������ʾ��ͼ
- ��������:һϵ����д����ͼƬ,����ÿ��ͼƬ����28x28�����ؾ���
- �������:�����˴�С��һ���;��д���,�����Ӧ��0~9�����ֱ�ǩ��
������д����ʶ���������ģ��
ʹ�÷ɽ������д����ʶ��ģ������Ĵ���ṹ�� ͼ2 ��ʾ,��ʹ�÷ɽ���ɷ���Ԥ��ģ�����������һ��,������ҽ���ϸ����ÿ������ľ���ʵ�ַ������Ż�˼·��
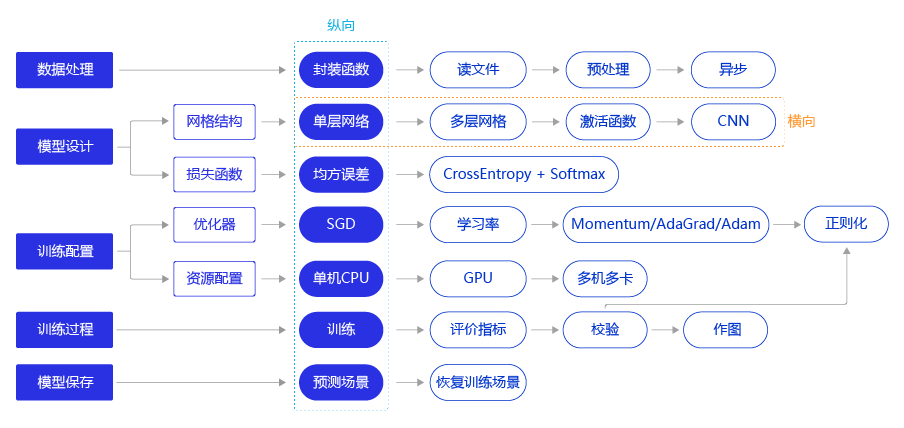
ͼ2:���ѧϰģ�Ϳ�������
�������ݲ��������ݼ�
MNIST���ݼ��Ǵ�NIST��Special Database 3(SD-3)��Special Database 1(SD-1)����������Yann LeCun���˴�SD-1��SD-3�и�ȡһ��������ΪMNISTѵ�����Ͳ��Լ�,����ѵ��������250λ��ͬ�ı�עԱ,��ѵ�����Ͳ��Լ��ı�עԱ��ȫ��ͬ��
MNIST���ݼ���json��ʽ�洢�ڱ���,�����ݴ洢�ṹ�� ͼ3 ��ʾ��
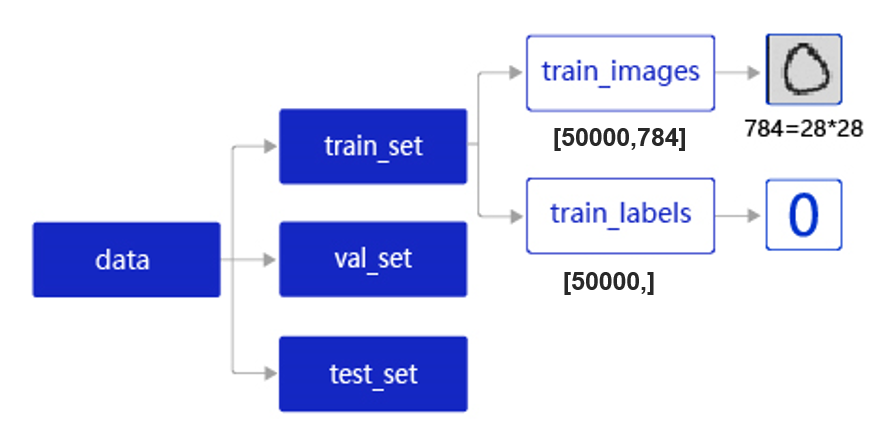
ͼ3:MNIST���ݼ��Ĵ洢�ṹ
data��������Ԫ�ص��б�:train_set��val_set�� test_set,����50 000��ѵ��������10 000����֤������10 000������������ÿ������������д����ͼƬ�Ͷ�Ӧ�ı�ǩ��
- train_set(ѵ����):����ȷ��ģ�Ͳ�����
- val_set(��֤��):���ڵ���ģ�ͳ�����(��������ṹ������Ȩ�ص�����ѡ��)��
- test_set(���Լ�):���ڹ���Ӧ��Ч��(û����ģ����Ӧ�ù�������,������ģ������ʵ����Ӧ�õ�Ч��)��
train_set��������Ԫ�ص��б�:train_images��train_labels��
- train_images:[50 000, 784]�Ķ�ά�б�,����50 000��ͼƬ��ÿ��ͼƬ��һ������Ϊ784��������ʾ,������28*28�ߴ�����ػҶ�ֵ(�ڰ�ͼƬ)��
- train_labels:[50 000, ]���б�,��ʾ��ЩͼƬ��Ӧ�ķ����ǩ,��0~9֮���һ�����֡�
�ڶ�ȡ�ļ�����Ϊmnist.json.gz��MNIST����,����ֳ�ѵ��������֤���Ͳ��Լ�,ʵ�ַ���������ʾ��
#���ݴ�������֮ǰ�Ĵ���,���벿�����ݴ����Ŀ�
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import gzip
import json
import random
import numpy as np
# �������ݼ��ļ�λ��
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
# ����json�����ļ�
data = json.load(gzip.open(datafile))
print('mnist dataset load done')
# ��ȡ������������ѵ����,��֤��,���Լ�
train_set, val_set, eval_set = data
# �۲�ѵ��������
imgs, labels = train_set[0], train_set[1]
print("ѵ�����ݼ�����: ", len(imgs))
# �۲���֤������
imgs, labels = val_set[0], val_set[1]
print("��֤���ݼ�����: ", len(imgs))
# �۲���Լ�����
imgs, labels = val= eval_set[0], eval_set[1]
print("�������ݼ�����: ", len(imgs))
# ��ӡ
loading mnist dataset from ./work/mnist.json.gz ......
mnist dataset load done
ѵ�����ݼ�����: 50000
��֤���ݼ�����: 10000
�������ݼ�����: 10000
ѵ����������������������
- ѵ����������: �Ƚ�������˳����б��,����ID����index_list��Ȼ��index_list����,���������˳���ȡ���ݡ�
˵��:
ͨ������ʵ�鷢��,ģ�Ͷ������ֵ�����ӡ�������̡�ѵ�����ݵ����,Խ�ӽ�ģ��ѵ������,����������ݶ�ģ�Ͳ�����Ӱ��Խ��Ϊ�˱���ģ�ͼ���Ӱ��ѵ��Ч��,��Ҫ�����������������
- ������������: �����ú�����batch_size,�ٽ�����ת��ɷ���ģ������Ҫ���np.array��ʽ���ء�ͬʱ,�ڷ�������ʱ��Python����������Ϊ
yieldģʽ,�Լ����ڴ�ռ�á�
��ִ��������������֮ǰ,��Ҫ�Ƚ����ݴ��������װ��load_data����,����������á�load_data������ģ��:train��valid��eval,��Ϊ��Ӧ���ص�������ѵ��������֤�������Լ���
imgs, labels = train_set[0], train_set[1]
print("ѵ�����ݼ�����: ", len(imgs))
# ������ݼ�����
imgs_length = len(imgs)
# �������ݼ�ÿ�����ݵ����,������Ŷ�ȡ����
index_list = list(range(imgs_length))
# ��������ʱ�õ������δ�С
BATCHSIZE = 100
# �������ѵ�����ݵ��������
random.shuffle(index_list)
# ��������������,������������
def data_generator():
imgs_list = []
labels_list = []
for i in index_list:
# �����ݴ�����ϣ��������
img = np.array(imgs[i]).astype('float32')
label = np.array(labels[i]).astype('float32')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
# ���һ��batchsize������,������
yield np.array(imgs_list), np.array(labels_list)
# ������ݶ�ȡ�б�
imgs_list = []
labels_list = []
# ���ʣ�����ݵ���ĿС��BATCHSIZE,
# ��ʣ������һ��һ����СΪlen(imgs_list)��mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
#��ӡ
ѵ�����ݼ�����: 50000
����������
��ʵ��Ӧ����,ԭʼ���ݿ��ܴ��ڱ�ע��ȷ���������һ��ʽ��ͳһ������������������ݴ������̺�,����Ҫ��������У��,һ�������ַ�ʽ:
- ����У��:����һЩУ����������ݵIJ�����
- �˹�У��:�ȴ�ӡ����������,�۲��Ƿ������õĸ�ʽ���ٴ�ѵ���Ľ����֤���ݴ����Ͷ�ȡ����Ч�ԡ�
������
���´�����ʾ,������ݼ��е�ͼƬ�����ͱ�ǩ��������,˵����������������,��ʹ��assert���У��ͼ�������ͱ�ǩ�����Ƿ�һ�¡�
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(label))
��װ���ݶ�ȡ�봦������
����,���ǴӶ�ȡ���ݡ��������ݼ���������ѵ�����ݡ��������ݶ�ȡ���Լ���������У��,�����һ����һ���Ե����ݴ�������,���潫��Щ�������һ��������ʵ��,������������ѵ��ʱֱ�ӵ��á�
# �������ݼ���ȡ��
# �������ݼ���ȡ��
def load_data(mode='train'):
# ��ȡ�����ļ�
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
data = json.load(gzip.open(datafile))
# ��ȡ���ݼ��е�ѵ����,��֤���Ͳ��Լ�
train_set, val_set, eval_set = data
# ���ݼ���ز���,ͼƬ�߶�IMG_ROWS, ͼƬ����IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28
# ��������mode��������ʹ��ѵ����,��֤�����Dz���
if mode == 'train':
imgs = train_set[0]
labels = train_set[1]
elif mode == 'valid':
imgs = val_set[0]
labels = val_set[1]
elif mode == 'eval':
imgs = eval_set[0]
labels = eval_set[1]
# �������ͼ�������
imgs_length = len(imgs)
# ��֤ͼ�������ͱ�ǩ�����Ƿ�һ��
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs), len(labels))
index_list = list(range(imgs_length))
# ��������ʱ�õ���batchsize
BATCHSIZE = 100
# ��������������
def data_generator():
# ѵ��ģʽ��,����ѵ������
if mode == 'train':
random.shuffle(index_list)
imgs_list = []
labels_list = []
# ����������ȡ����
for i in index_list:
# ��ȡͼ��ͱ�ǩ,ת����ߴ������
img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
# �����ǰ���ݻ���ﵽ��batch size,�ͷ���һ����������
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
# ������ݻ����б�
imgs_list = []
labels_list = []
# ���ʣ�����ݵ���ĿС��BATCHSIZE,
# ��ʣ������һ��һ����СΪlen(imgs_list)��mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
��ƾ���������ṹ
ʹ�þ����ȫ����������ᵼ���������ݶ�ʧ��ͼ�����ؼ�Ŀռ���Ϣ,��Ӱ���������ͼ�����ݵ����⡣���ڼ�����Ӿ�����,Ч����õ�ģ����Ȼ�Ǿ��������硣��������������Ӿ�������ص����������ṹ�Ż�,����ֱ�Ӵ���ԭʼ��ʽ��ͼ������,�������ؼ�Ŀռ���Ϣ,��˸��ʺϴ����Ӿ����⡣
�����������ɶ��������ͳػ������,�� ͼ4 ��ʾ�������㸺����������ɨ�������ɸ������������ʾ,�ػ������Щ������ʾ���й���,������ؼ���������Ϣ�������㼤���ʹ��Relu,ȫ���Ӳ㼤���ʹ��softmax��
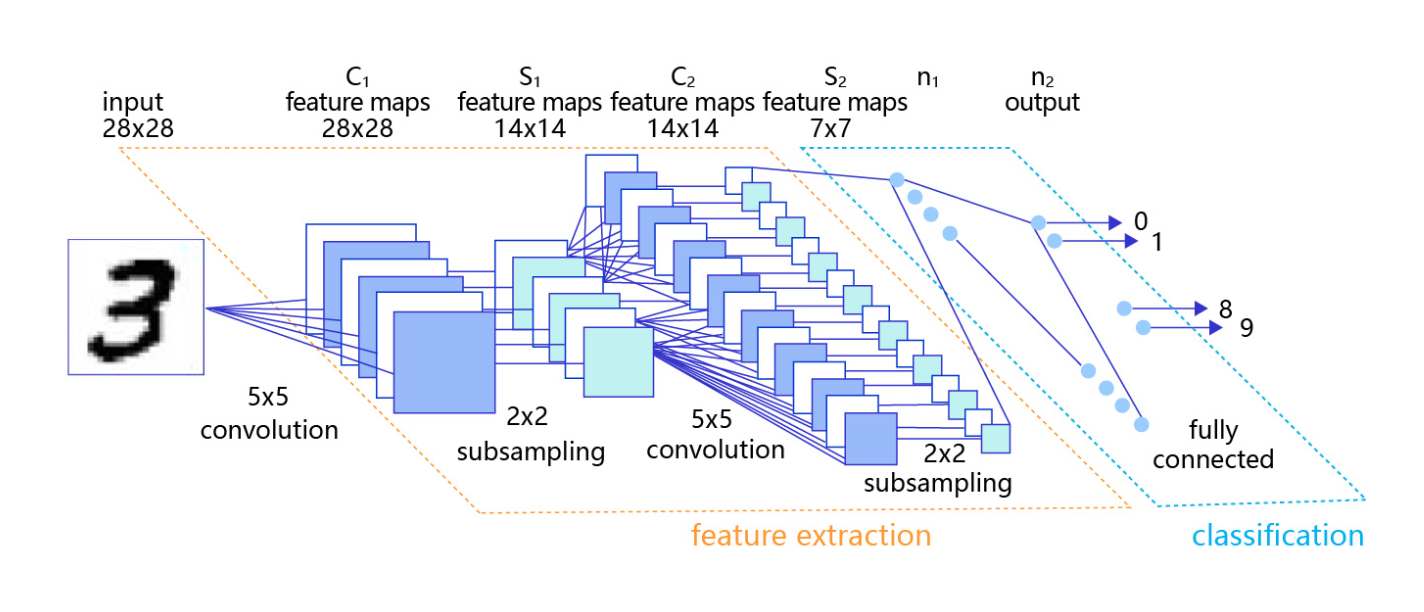
ͼ4:��д����ʶ�����������
˵��:
train_loader��ÿ�ε���ʱ������shapeΪ[batch_size, 784],�����Ҫ����������ʽreshapeΪͼ��������ʽ[batch_size, 1, 28, 28],���еڶ�ά����ͼ���ͨ����(��MNIST���ݼ���ÿ��ͼƬ��ͨ����Ϊ1,��ͳRGBͼƬͨ����Ϊ3)��
��������ͳػ���������ʵ��������ʾ��
# ����ģ�ͽṹ
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear
# ������������ʵ��
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# ���������,�������ͨ��out_channels����Ϊ20,�����˵Ĵ�Сkernel_sizeΪ5,��������stride=1,padding=2
self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
# ����ػ���,�ػ��˵Ĵ�Сkernel_sizeΪ2,�ػ�����Ϊ2
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# ���������,�������ͨ��out_channels����Ϊ20,�����˵Ĵ�Сkernel_sizeΪ5,��������stride=1,padding=2
self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)
# ����ػ���,�ػ��˵Ĵ�Сkernel_sizeΪ2,�ػ�����Ϊ2
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# ����һ��ȫ���Ӳ�,���ά����10
self.fc = Linear(in_features=980, out_features=10)
# ��������ǰ��������,�����������ʹ�óػ���,���ʹ��ȫ���Ӳ�����������
# �����㼤���ʹ��Relu,ȫ���Ӳ㼤���ʹ��softmax
def forward(self, inputs, label):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.reshape(x, [x.shape[0], 980])
x = self.fc(x)
if label is not None:
acc = paddle.metric.accuracy(input=F.softmax(x), label=label)
return x, acc
else:
return x
�����������ʧ����
��֮ǰ�ķ�����,���Ǹ����˷���Ԥ��ģ�͵���ʧ����-��������Ԥ��Ч������,��Ȼ��ʧ�����½�,ģ�͵�Ԥ��ֵ�ƽ���ʵֵ,��ģ�͵�����Ч���������롣�������,��ͬ�����ѧϰ������Ҫ�и������˵���ʧ�����������Է���Ԥ�����д����ʶ����������Ϊ��,��ϸ�������е�Ե������:
- ����Ԥ���ǻع�����,����д����ʶ���Ƿ�������,ʹ�þ��������Ϊ�����������ʧ������������Ч���ϵ�ȱǷ��
- ���ۿ����Ǵ���0���κθ�����,����д����ʶ������ֻ������0~9֮���10������,�൱��һ�ֱ�ǩ��
- �ڷ���Ԥ��İ�����,���ڷ��۱�����һ��������ʵ��ֵ,�����ģ���������ֵ����ʵ���۲����Ϊ��ʧ����(Loss)�Ƿ��ϵ����ġ������ڷ�������,��ʵ����Ƿ����ǩ,��ģ�������ʵ��ֵ,���������������Ϊ��ʧ���߱��������塣
��ô,ʲô�Ƿ�������ĺ��������?�������������ǡ�ij����������µķ�����ʡ�,������һ������˵��,�� ͼ2 ��ʾ��

ͼ2:�۲����ݺͱ������֮��Ĺ�ϵ
�ڱ�������,ҽ������������С x x x��Ϊ�������� y y y�IJο��ж�(�жϵ������кܶ�,������Сֻ������֮һ),��ô���ǹ۲��ģ���жϵĽ���� x x x�� y y y�ı�ǩ(1Ϊ����,0Ϊ����)����������ݱ���Ĺ����Dz�ͬ��С������,���ڶ��������ĸ��ʡ��۲���������ʵ���ɳ����µĽ��,����ģ��Ӧ����������ʵ����,������ڸ÷����ǩ�ĸ��ʡ�
������
��ģ�����Ϊ�����ǩ�ĸ���ʱ,ֱ���Ա�ǩ�������Ƚ�Ҳ��������,���Ǹ�ϰ��ʹ�ý����������Ϊ�����������ʧ������
��������ʧ����������ǻ��������Ȼ˼��:�����ʵõ��۲����ļ�������ġ����������?�ٸ�������˵,�� ͼ7 ��ʾ��������������ͬ�ĺ���,������99������,1������;�Һ�����99������,1������һ������ȡ����һ������,���������Ӧ���Ǵ��ĸ�������ȡ����?
ͼ7:��������Ȼ��˼��
���Ŵ�Ҽ�˼�������ó��������Ǵ��Һ���ȡ����,��Ϊ���Һ���ȡ��һ������ĸ��ʸ��� ( P ( D �O h ) ) (P(D|h)) (P(D�Oh)),���Թ۲쵽һ������������Ǵ��Һ���ȡ���� ( P ( h �O D ) ) (P(h|D)) (P(h�OD))�� D D D�ǹ۲������,���������; h h h��ģ��,�����ҺС�����DZ�Ҷ˹��ʽ�������˼��:
P ( h �O D ) �� P ( h ) ? P ( D �O h ) P(h|D) �� P(h) \cdot P(D|h) P(h�OD)��P(h)?P(D�Oh)
˵��:
����ʡ�Թ�ʽ�Ƶ�����,���ٴ�ҿ����¹����еķ��ա�
��������:
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
����ѧϰ��
�����ѧϰ������ģ����,ͨ��ʹ�ñ�������ݶ��½��㷨���²���,ѧϰ�ʴ����������·��ȵĴ�С,����������ѧϰ������ʱ,ģ�͵���Ч�������,�����ܴﵽ��Ч����á�ѧϰ�ʺ����ѧϰ���������й�,���ʵ�ѧϰ��������Ҫ������ʵ��͵��ξ��顣̽��ѧϰ������ֵʱ��Ҫע����������:
- ѧϰ�ʲ���ԽСԽ����ѧϰ��ԽС,��ʧ�����ı仯�ٶ�Խ��,��ζ��������Ҫ���Ѹ�����ʱ���������,�� ͼ2 ��ͼ��ʾ��
- ѧϰ�ʲ���Խ��Խ����ֻ�������������е�һ�����μ����ݶ�,�������ᵼ�¼�������ݶȲ���ȫ�����ŵķ���,�Ҵ��ڲ������ڽӽ����Ž�ʱ,�����ѧϰ�ʻᵼ�²��������Ž⸽����,��ʧ��������,�� ͼ2 ��ͼ��ʾ��
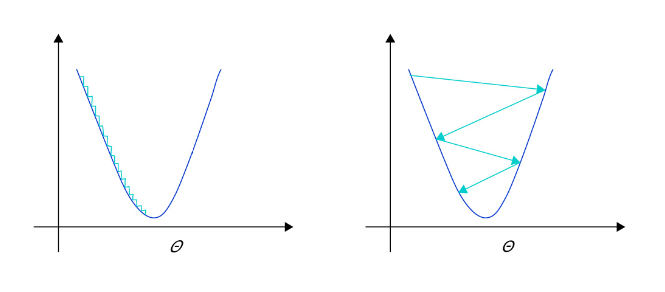
ͼ2: ��ͬѧϰ��(��������/��С)��ʾ��ͼ
��ѵ��ǰ,�������������һ���ض��������ó�������ѧϰ���Ǻ�����,�����ѵ��ʱ���Գ��Ե�С�����,ͨ���۲�Loss�½�������жϺ�����ѧϰ��,����ѧϰ�ʵĴ���������ʾ��
ѧϰ�ʵ������Ż��㷨
ѧϰ�����Ż�����һ������,����ѧϰ�ʿ�����һ���dz��鷳������,��Ҫ���ϵĵ�������,�۲�ѵ��ʱ���Loss�ı仯�������о�Ա�IJ��ϵ�ʵ��,��ǰ�Ѿ��γ������ֱȽϳ�����Ż��㷨:SGD��Momentum��AdaGrad��Adam,Ч���� ͼ3 ��ʾ��
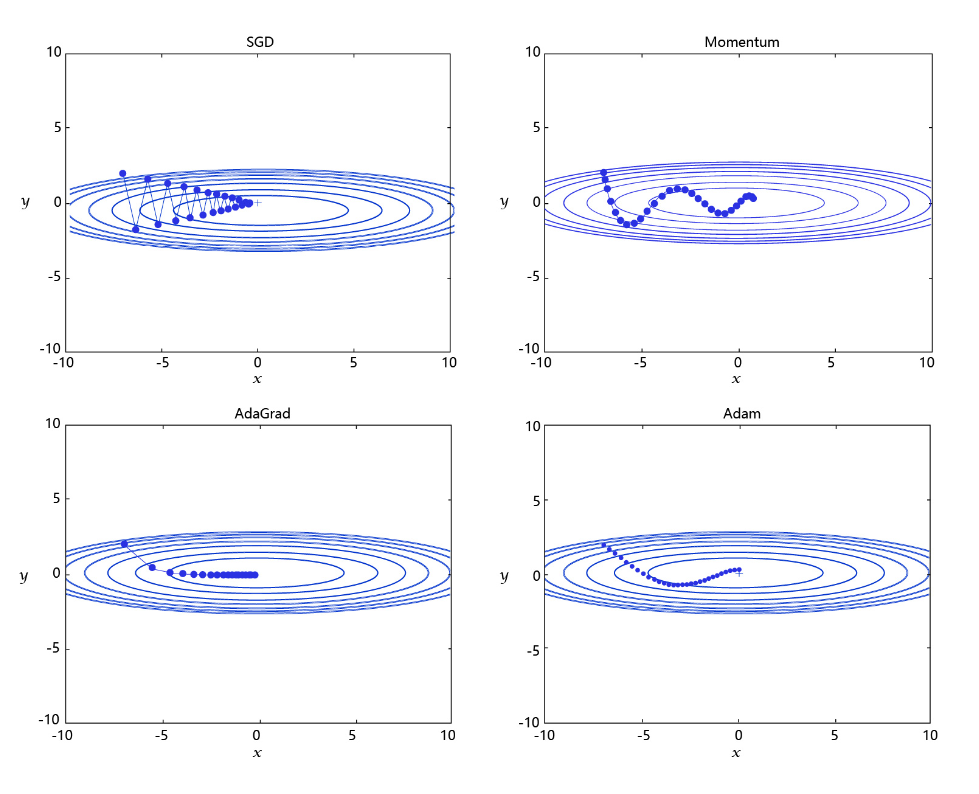
ͼ3: ��ͬѧϰ���㷨Ч��ʾ��ͼ
-
SGD: ����ݶ��½��㷨,ÿ��ѵ����������,����ƫ��µIJ���������������
-
Momentum: �����������������ĸ���,�ۻ��ٶ�,������,ʹ�������µķ�����ȶ���
ÿ�����ε����ݺ��г������,�����ݶȸ��µķ����ϴ���������������������ĸ���,���ݶ��½��Ĺ��̼���һ���ġ����ԡ��ۻ�,�Ϳ��Լ��ٸ���·���ϵ���,��ÿ�θ��µ��ݶ��ɡ���ʷ����ݶȵ��ۻ����͡������ݶȡ���Ȩ��ӵõ�����ʷ����ݶȵ��ۻ����������Ǵ�ȫ���ӽǸ���ȷ�ķ���,���롰���ԡ��������������,Ҳ��Ϊ��������Ϊ��Momentum����ԭ�����Ʋ�ͬƷ�ƺͲ��ʵ�������һ�����������,��ͷ������е�Ͷ��(�ó���Զ����Ͷ��)ϲ����������ı����ϸߡ�һ������Ҫ��ԭ����,�ص�������Դ�,���������ܵ����Ƶ�С�����λ�紵��Ӱ�졣
- AdaGrad: ���ݲ�ͬ�����������Ž��Զ��,��̬����ѧϰ�ʡ�ѧϰ�����½�,���ݸ������仯��С����ѧϰ�ʡ�
ͨ������ѧϰ�ʵ�ʵ����Է���:��ij����������ֵ�������Ž��Զʱ(����Ϊ�ݶȵľ���ֵ�ϴ�),���������������µIJ�����һЩ,�Ա�������������Ž⡣��ij����������ֵ�������Ž�Ͻ�ʱ(����Ϊ�ݶȵľ���ֵ��С),�������������ĸ��²���СһЩ,�Ա����ϸ�ıƽ����Ž⡣�����ڴ�߶�����,רҵ�˶�Ա��һ�˿���ʱ,ͨ���������һ��Զ��,���������ڶ��ڸ��������ڶ�������붴�ڽϽ�����ʱ,����������ϸ�µ��Ƹ�,���⽫���ɡ��������,�������µIJ���Ӧ�������Ż���������,���ٵij̶��뵱ǰ�ݶȵĴ�С�йء��������˼���д���Ż��㷨��Ϊ��AdaGrad��,Ada��Adaptive����д,��ʾ����Ӧ�������仯������˼��RMSProp����AdaGrad�����ϵĸĽ�,ѧϰ�������ݶȱ仯����Ӧ,���AdaGradѧϰ�ʼ����½������⡣
- Adam: ���ڶ���������Ӧѧϰ�������Ż�˼·��������,��˿��Խ�����˼·�������,����ǵ�ǰ�㷺Ӧ�õ��㷨��
˵��:
�����������δ���ھ��尸��������Ч,����ģ�͵����Ǻ��б�Ҫ��,���ŵ�ģ��������������һ�������ۡ��͡����顱��ָ����ʵ������ġ�
���ǿ��Գ���ѡ��ͬ���Ż��㷨ѵ��ģ��,�۲�ѵ��ʱ�����ʧ�仯�����,����ʵ�����¡�
#�����Ż��㷨�����÷���,������һ����Ч��
# opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())
# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())
opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
��Դ���õ�GPUѵ��
ͨ��paddle.device.set_device API,������GPU��ѵ������CPU��ѵ����
paddle.device.set_device (device)
����
device (str):�˲���ȷ���ض��������豸,������cpu�� gpu:x������xpu:x������,x��GPU��XPU�ı�š���device��cpuʱ, ������CPU������;��device��gpu:xʱ,������GPU�����С�
#��ʹ��GPU����ʱ,���Խ�use_gpu�������ó�True
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
����������,����ģ�����
���������
�������������ޡ�����Ҫʹ��ǿ��ģ�͵ĸ�������,ģ�ͺ����׳��ֹ���ϵı���,����ѵ�����ϵ���ʧС,����֤������Լ��ϵ���ʧ�ϴ�,�� ͼ2 ��ʾ��
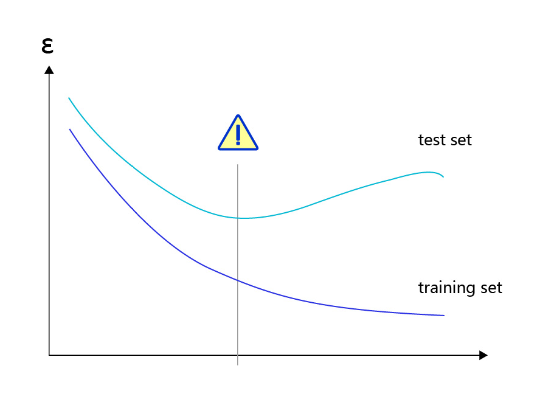
ͼ2:���������,ѵ�����Ͻ���,����������Ƚ�����
��֮,���ģ����ѵ�����Ͳ��Լ��Ͼ���ʧ�ϴ�,���ΪǷ��ϡ�����ϱ�ʾģ��������,ѧϰ����ѵ�������е�һЩ���,����Щ��������ʵ�ķ�������(���ƹ㵽���Լ��ϵĹ���)��Ƿ��ϱ�ʾģ�ͻ�����ǿ��,��û�кܺõ������֪��ѵ������,��������������ˡ���ΪǷ���������۲�ͽ��,ֻҪѵ��loss������,�Ͳ���ʹ�ø�ǿ���ģ�ͼ���,���ʵ�������Ǹ���Ҫ�����ù���ϵ����⡣
���¹����ԭ��
��ɹ���ϵ�ԭ����ģ��������,��ѵ��������̫�ٻ����е�����̫�ࡣ
��ͼ3 ��ʾ,����Ļع�ģ����һ���¶Ƚϻ���������,Ƿ��ϵ�ģ��ֻ��ϳ�һ��ֱ��,��Ȼû�в�����ʵ�Ĺ���,������ϵ�ģ����ϳ����ںܶ�յ��������,��Ȼ�ǹ�������,Ҳû����ȷ������ʵ���ɡ�
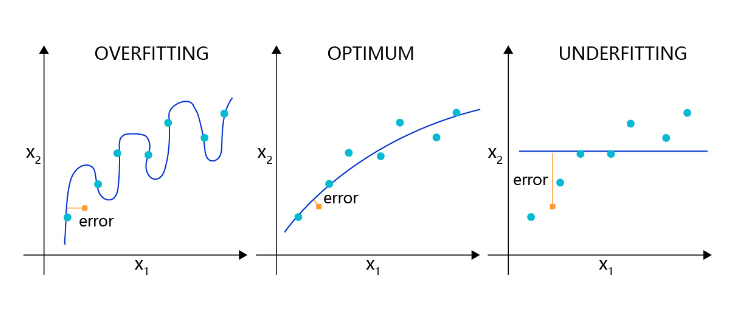
ͼ3:�ع�ģ�͵Ĺ����,�����Ƿ���״̬�ı���
��ͼ4 ��ʾ,����ķ���ģ����һ����Բ�ε�����,Ƿ�����ֱ����Ϊ����߽�,��Ȼû�в�����ʵ�ı߽�,������ϵ�ģ����ϳ���Ť���ķ���߽�,��Ȼ�����е�ѵ��������ȷ����,����һЩ��Ϊ��������������������Э,�߸��ʲ�����ʵ�Ĺ��ɡ�
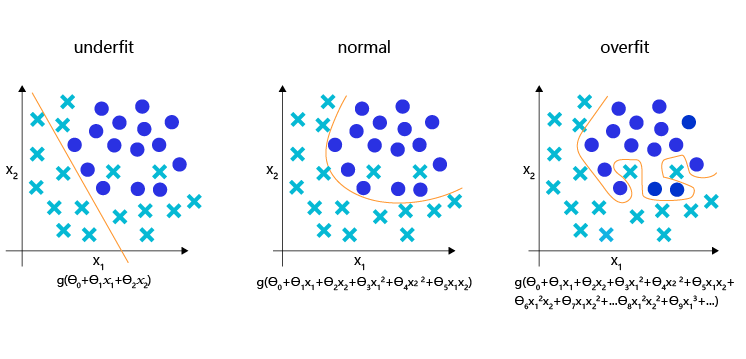
ͼ4:����ģ�͵�Ƿ���,��������״̬�ı���
������
Ϊ�˷�ֹģ�����,��û�������������Ŀ�����,ֻ�ܽ���ģ�͵ĸ��Ӷ�,����ͨ�����Ʋ��������������ȡֵ(����ֵ����С)ʵ�֡�
������˵,��ģ�͵��Ż�Ŀ��(��ʧ)����Ϊ����Բ�����ģ�ijͷ��������Խ���ȡֵԽ��ʱ,�óͷ����Խ��ͨ�������ͷ����Ȩ��ϵ��,����ʹģ���ڡ���������ѵ����ʧ���͡�����ģ�͵ķ���������֮��ȡ��ƽ�⡣����������ʾģ����û�м�������������Ȼ��Ч��������Ĵ���,������ģ����ѵ�����ϵ���ʧ��
�ɽ�֧��Ϊ���в�������ͳһ��������,Ҳ֧��Ϊ�ض��IJ������������ǰ�ߵ�ʵ�����´�����ʾ,�����Ż���������weight_decay��������ʵ�֡�ʹ�ò���coeff�����������Ȩ��,Ȩ��Խ��ʱ,��ģ���Ӷȵijͷ�Խ�ߡ�
#�����Ż��㷨�����Լ���������,��������,����regularization_coeff�����������Ȩ��
opt = paddle.optimizer.Adam(learning_rate=0.01, weight_decay=paddle.regularizer.L2Decay(coeff=1e-5), parameters=model.parameters())
��������
def train(model):
model.train()
#�����Ż��㷨�����Լ���������,��������,����regularization_coeff�����������Ȩ��
opt = paddle.optimizer.Adam(learning_rate=0.01, weight_decay=paddle.regularizer.L2Decay(coeff=1e-5), parameters=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#������,��ø��Ӽ��
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
#ǰ�����Ĺ���,ͬʱ�õ�ģ�����ֵ�ͷ���ȷ��
predicts, acc = model(images, labels)
#������ʧ,ȡһ������������ʧ��ƽ��ֵ
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
#ÿѵ����100���ε�����,��ӡ�µ�ǰLoss�����
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(), acc.numpy()))
#����,���²����Ĺ���
avg_loss.backward()
opt.step()
opt.clear_grad()
#����ģ�Ͳ���
paddle.save(model.state_dict(), 'mnist.pdparams')
model = MNIST()
train(model)
ģ��Ԥ��
# ��ȡһ�ű��ص�����ͼƬ,ת���ģ������ĸ�ʽ
def load_image(img_path):
# ��img_path�ж�ȡͼ��,��תΪ�Ҷ�ͼ
im = Image.open(img_path).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
# ͼ���һ��
im = 1.0 - im / 255.
return im
# ����Ԥ�����
model = MNIST()
params_file_path = 'mnist.pdparams'
img_path = 'work/example_0.jpg'
# ����ģ�Ͳ���
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# ��������
model.eval()
tensor_img = load_image(img_path)
#ģ�ͷ���10�������ǩ�Ķ�Ӧ����
results = model(paddle.to_tensor(tensor_img))
#ȡ�������ı�ǩ��ΪԤ�����
lab = np.argsort(results.numpy())
print("����Ԥ���������: ", lab[0][-1])